Chapter 7. Customizing Tokio
Throughout this book, we have been using Tokio for examples because not only is it well established, but it also has a clean syntax and you can get async examples running with just a single macro. Chances are, if you have worked on an async Rust codebase, you will have come across Tokio. However, so far we have used this crate only to build a standard Tokio runtime and then send async tasks to that runtime. In this chapter, we will customize our Tokio runtimes in order to have fine-grained control over how our tasks are processed in various threads of a set. We will also test whether our unsafe access to thread state is actually safe in an async runtime. Finally, we will cover how to enable graceful shutdowns when our async runtime finishes.
By the end of this chapter, you will be able to configure a Tokio runtime to solve your specific problem. You will also be able to specify which thread the async task is exclusively processed on so your task can rely on the thread-specific state, potentially reducing the need for locks to access data. Finally, you will be able to specify how the program is shut down when Ctrl-C or kill signals are sent to the program. So, let’s get started with building the Tokio runtime.
Skipping this chapter will not affect your understanding of the rest of the book, as this content covers how to use Tokio to your liking. This chapter does not introduce new async theory.
Building a Runtime
In Chapter 3, we showed how tasks are handled in an async runtime by implementing our own task-spawning function. This gave us a lot of control over the way the tasks were processed. Our previous Tokio examples have merely used the #[tokio::main] macro. While this macro was useful for implementing async examples with minimal code, just implementing #[tokio::main] does not give us much control over how the async runtime is implemented. For us to explore Tokio, we can start with setting up a Tokio runtime that we can choose to call. For our configured runtime, we need the following dependencies:
tokio={version="1.33.0",features=["full"]}
We also need the following structs and traits:
usestd::future::Future;usestd::time::Duration;usetokio::runtime::{Builder,Runtime};usetokio::task::JoinHandle;usestd::sync::LazyLock;
To build our runtime, we can lean on LazyLock for a lazy evaluation so our runtime is defined once, just as we did when building our runtime in Chapter 3:
staticRUNTIME:LazyLock<Runtime>=LazyLock::new(||{Builder::new_multi_thread().worker_threads(4).max_blocking_threads(1).on_thread_start(||{println!("thread starting for runtime A");}).on_thread_stop(||{println!("thread stopping for runtime A");}).thread_keep_alive(Duration::from_secs(60)).global_queue_interval(61).on_thread_park(||{println!("thread parking for runtime A");}).thread_name("our custom runtime A").thread_stack_size(3*1024*1024).enable_time().build().unwrap()});
We get a lot of configuration out of the box, along the following properties:
worker_threads-
The number of threads processing async tasks.
max_blocking_threads-
The number of threads that can be allocated to blocking tasks. A blocking task does not allow switching because it has no
awaitor requires long periods of CPU computation betweenawaitstatements. Therefore, the thread is blocked for a fair amount of time processing the task. CPU-intensive tasks or synchronous tasks are usually referred to as blocking tasks. If we block all our threads, no other tasks can be started. As mentioned throughout the book, this can be OK, depending on the problem your program is solving. However, if we are using async to process incoming network requests for instance, we want to still process more incoming network requests. Therefore, withmax_blocking_threads, we can limit the number of additional threads that can be spawned to process blocking tasks. We can spawn blocking tasks with the runtime’sspawn_blockingfunction. on_thread_start/stop-
Functions that fire when the worker thread starts or stops. This can become useful if you want to build your own monitoring.
thread_keep_alive-
Timeout for blocking threads. Once the time has elapsed for a blocking thread, the task that has overrun that timeout limit will be cancelled.
global_queue_interval-
The number of ticks before a new task gets attention from the scheduler. A tick represents one instance when the scheduler polls a task to see whether it can be run or needs to wait. In our configuration, after 61 ticks have elapsed, the scheduler will take on a new task that has been sent to the runtime. If there are no tasks to poll, the scheduler will take on a new task sent to the runtime without waiting 61 ticks. A trade-off exists between fairness and overhead. The lower the number of ticks, the quicker new tasks sent to the runtime receive attention. However, we will also be checking the queue for incoming new tasks more frequently, which comes with overhead. Our system might become less efficient if we are constantly checking for new tasks instead of making progress with existing ones. We also must acknowledge the number of
awaitstatements per task. If our tasks generally contain manyawaitstatements, the scheduler needs to work through a lot of steps, polling on eachawaitstatement to complete the task. However, if the task has just oneawaitstatement, the scheduler will require less polling to progress the task. The Tokio team has decided that the default tick number should be 31 for single-threaded runtimes and 61 for multithreaded runtimes. The multithreaded suggestion is a higher tick count as multiple threads are consuming tasks, resulting in these tasks getting attention at a quicker rate. on_thread_park-
A function that fires when the worker thread is parked. Worker threads are usually parked when the worker thread has no tasks to consume. The
on_thread_parkfunction is useful if you want to implement your own monitoring. thread_name-
This names the threads that are made by the runtime. The default name is
tokio-runtime-worker. thread_stack_size-
This allows us to determine the amount of memory in bytes that are allocated for the stack of each worker thread. The stack is a section of memory that stores local variables, function return addresses, and the management of function calls. If you know that your computations are simple and you want to conserve memory, reaching for a lower stack size makes sense. The default value for this stack size at the time of this writing is 2 mebibytes (MiB).
enable_time
Now that we have built and configured our runtime, we can define how we call it:
pubfnspawn_task<F,T>(future:F)->JoinHandle<T>whereF:Future<Output=T>+Send+'static,T:Send+'static,{RUNTIME.spawn(future)}
We do not really need this function, as we can directly call our runtime. However, it is worth noting that the function signature is essentially the same as our spawn_task function in Chapter 3. The only difference is that we return a Tokio JoinHandle as opposed to a Task.
Now that we know how to call our runtime, we can define a basic future:
asyncfnsleep_example()->i32{println!("sleeping for 2 seconds");tokio::time::sleep(Duration::from_secs(2)).await;println!("done sleeping");20}
And then we run our program:
fnmain(){lethandle=spawn_task(sleep_example());println!("spawned task");println!("task status: {}",handle.is_finished());std::thread::sleep(Duration::from_secs(3));println!("task status: {}",handle.is_finished());letresult=RUNTIME.block_on(handle).unwrap();println!("task result: {}",result);}
We spawn our task and then wait for the task to finish, using the block_on function from our runtime. We also periodically check whether our task has finished. Running the code gives us the following printout:
thread starting for runtime A thread starting for runtime A sleeping for 2 seconds thread starting for runtime A thread parking for runtime A thread parking for runtime A spawned task thread parking for runtime A task status: false thread starting for runtime A thread parking for runtime A done sleeping thread parking for runtime A task status: true task result: 20
Although this printout is lengthy, we can see that our runtime starts creating worker threads, and also starts our async task before all the worker threads are created. Because we have sent only one async task, we can also see that the idle worker threads are being parked. By the time that we get the result of our task, all our worker threads have been parked. We can see that Tokio is fairly aggressive at parking its threads. This is useful because if we create multiple runtimes but are not using one all the time, that unused runtime will quickly park its threads, reducing the amount of resources being used.
Now that we have covered how to build and customize Tokio runtimes, we can re-create the runtime that we built in Chapter 3:
staticHIGH_PRIORITY:LazyLock<Runtime>=LazyLock::new(||{Builder::new_multi_thread().worker_threads(2).thread_name("High Priority Runtime").enable_time().build().unwrap()});staticLOW_PRIORITY:LazyLock<Runtime>=LazyLock::new(||{Builder::new_multi_thread().worker_threads(1).thread_name("Low Priority Runtime").enable_time().build().unwrap()});
This gives us the layout shown in Figure 7-1.
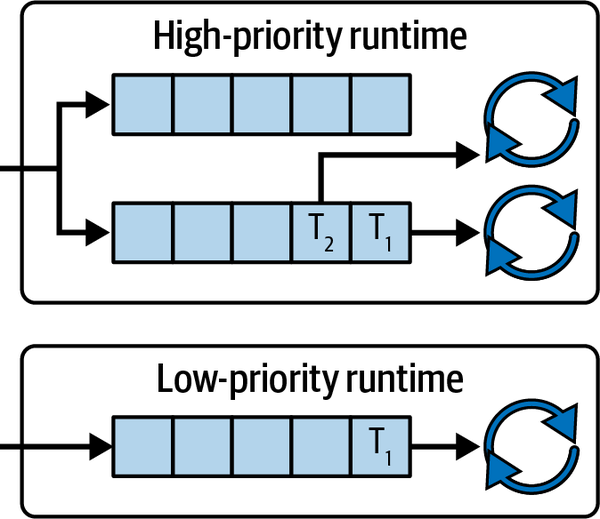
Figure 7-1. Layout of our Tokio runtimes
The only difference between our two Tokio runtimes and our runtime that had two queues with task stealing in Chapter 3, is that the threads from the high-priority runtime will not steal tasks from the low-priority runtime. Also, the high-priority runtime has two queues. The differences are not too pronounced because the threads steal tasks in the same runtime, so it is effectively one queue as long as we do not mind the exact order in which tasks are processed.
We also must acknowledge that the threads get parked when no async tasks remain to be processed. If we have more threads than cores, the OS will manage the resource allocation and context switching among these threads. Simply adding more threads past the number of cores will not result in a linear increase in speed. However, if we have three threads for the high-priority runtime and two threads for the low-priority runtime, we can still distribute the resources effectively. If no tasks were to be processed in the low-priority runtime, those two threads would be parked and the three threads in the high-priority runtime would have more CPU allocation.
Now that we have defined our threads and runtimes, we need to interact with these threads in different ways. We can gain more control over the flow of the task by using local pools.
Processing Tasks with Local Pools
With local pools, we can have more control over the threads that are processing our async tasks. Before we explore local pools, we need to include the following dependency:
tokio-util={version="0.7.10",features=["full"]}
We also need these imports:
usetokio_util::task::LocalPoolHandle;usestd::cell::RefCell;
When using local pools, we tie the spawned async task to the specific pool. This means we can use structs that do not have the Send trait implemented because we are ensuring that the task stays on a specific thread. However, because we are ensuring that the async task runs on a particular thread, we will not be able to exploit task stealing; we will not get the performance of a standard Tokio runtime out of the box.
To see how our async tasks map through our local pool, we first need to define some local thread data:
thread_local!{pubstaticCOUNTER:RefCell<u32>=RefCell::new(1);}
Every thread will have access to its COUNTER variable. We then need a simple async task that blocks the thread for a second, increases the COUNTER of the thread that the async task is operating in, and then prints out the COUNTER and number:
asyncfnsomething(number:u32)->u32{std::thread::sleep(std::time::Duration::from_secs(3));COUNTER.with(|counter|{*counter.borrow_mut()+=1;println!("Counter: {} for: {}",*counter.borrow(),number);});number}
With this task, we will see how configurations of the local pool will process multiple tasks.
In our main function, we still need a Tokio runtime because we still need to await on the spawned tasks:
#[tokio::main(flavor ="current_thread")]asyncfnmain(){letpool=LocalPoolHandle::new(1);...}
Our Tokio runtime has a flavor of current_thread. The flavor at the time of this writing is either CurrentThread or MultiThread. The MultiThread option executes tasks across multiple threads. CurrentThread executes all tasks on the current thread. Another flavor, MultiThreadAlt, also claims to execute tasks across multiple threads but is unstable. So the runtime that we have implemented will execute all tasks on the current thread, and the local pool has one thread in the pool.
Now that we have defined our pool, we can use it to spawn our tasks:
letone=pool.spawn_pinned(||async{println!("one");something(1).await});lettwo=pool.spawn_pinned(||async{println!("two");something(2).await});letthree=pool.spawn_pinned(||async{println!("three");something(3).await});
We now have three handles, so we can await on these handles and return the sum of these tasks:
letresult=async{letone=one.await.unwrap();lettwo=two.await.unwrap();letthree=three.await.unwrap();one+two+three};println!("result: {}",result.await);
When running our code, we get the following printout:
one Counter: 2 for: 1 two Counter: 3 for: 2 three Counter: 4 for: 3 result: 6
Our tasks are processed sequentially, and the highest COUNTER value is 4, meaning that all the tasks were processed in one thread. Now, if we increase the local pool size to 3, we get the following printout:
one three two Counter: 2 for: 1 Counter: 2 for: 3 Counter: 2 for: 2 result: 6
All three tasks started processing as soon as they were spawned. We can also see that the COUNTER has a value of 2 for each task. This means that our three tasks were distributed across all three threads.
We can also focus on particular threads. For example, we can spawn a task to a thread that has the index of zero:
letone=pool.spawn_pinned_by_idx(||async{println!("one");something(1).await},0);
If we spawn all our tasks on the thread with the index of zero, we get this printout:
one Counter: 2 for: 1 two Counter: 3 for: 2 three Counter: 4 for: 3 result: 6
Our printout is the same as the single-threaded pool, even though we have three threads in the pool. If we were to swap the standard sleep for a Tokio sleep, we would get the following printout:
one two three Counter: 2 for: 1 Counter: 3 for: 2 Counter: 4 for: 3 result: 6
Because the Tokio sleep is async, our single thread can juggle multiple async tasks, but the COUNTER access is after the sleep. We can see the COUNTER value is 4, meaning that although our thread juggled multiple async tasks at the same time, our async tasks never traversed over another thread.
With local pools, we can have fine-grained control of where we send our tasks to be processed. Although we are sacrificing task stealing, we may want to use the local pool for the following advantages:
- Handling non-
sendfutures -
If the future cannot be sent between threads, we can process them with a local thread pool.
- Thread affinity
-
Because we can ensure that a task is being executed on a specific thread, we can take advantage of its state. A simple example of this is caching. If we need to compute or fetch a value from another resource such as a server, we can cache this in a specific thread. All tasks in that thread then have access to the value, so all tasks you send to that specific thread will not need to fetch or calculate the value.
- Performance for thread-local operations
-
You can share data across threads with mutexes and atomic reference counters. However, the synchronization of threads carries some overhead. For instance, acquiring a lock that other threads are also acquiring is not free. As we can see in Figure 7-2, if we have a standard Tokio async runtime with four worker threads and our counter is
Arc<Mutex<T>>, only one thread can access the counter at a time.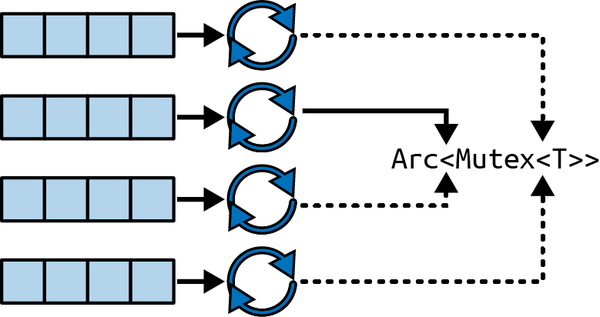
Figure 7-2. A mutex will allow only one Tokio thread to access it at a time
The other three threads will have to wait to get access to
Arc<Mutex<T>>. Keeping the state of the counter local to each thread will remove the need for that thread to wait for access to a mutex, speeding up the process. However, the local counters in each thread would not contain the complete picture. These counters do not know the state of the other counters in other threads. One approach for getting the entire state of the count can be sending an async task that gets the counter to each thread, combining the results of each thread at the end. We cover this approach in “Graceful Shutdowns”. The local access to data within the thread can also aid in the optimizations of CPU-bound tasks when it comes to the CPU caching data. - Safe access to non-
sendresources -
Sometimes the data resource will not be thread-safe. Keeping that resource in one thread and sending tasks into that thread to be processed is a way of getting around this.
Warning
We have highlighted the potential for blocking a thread with a blocking task throughout the book. However, it must be stressed that the damage blocking can do on our local pool can be more pronounced, as we do not have any task stealing. Using the Tokio spawn_blocking function will prevent this.
So far, we have been able to access the state of the thread in our async task by using RefCell. It enables us to access data via Rust checking the borrow rules at runtime. However, this checking carries some overhead when borrowing the data in RefCell. We can remove these checks and still safely access the data with unsafe code, which we will explore in the next section.
Getting Unsafe with Thread Data
To remove the runtime checks for mutable borrows of our thread data, we need to wrap our data in UnsafeCell. This means that we access our thread data directly, without any checks. However, I know what you are thinking. If we are using UnsafeCell, is that dangerous? Potentially yes, so we must be careful to ensure that we are safe.
If we think about our system, we have a single thread processing async tasks that will not transfer to other threads. We must remember that although this single thread can juggle multiple async tasks at the same time through polling, it can actively process only one async task at a time. Therefore, we can assume that while one of our async tasks is accessing the data in UnsafeCell and processing it, no other async task is accessing the data because UnsafeCell is not async. However, we need to make sure that we do not have an await when the reference to the data is in scope. If we do, our thread could context-switch to another task while the existing task still has a reference to the data.
We can test this by exposing a hashmap in unsafe code to thousands of async tasks and increasing the value of a key in each of those tasks. To run this test, we need the following imports:
usetokio_util::task::LocalPoolHandle;usestd::time::Instant;usestd::cell::UnsafeCell;usestd::collections::HashMap;
We then define our thread state:
usestd::cell::UnsafeCell;usestd::collections::HashMap;thread_local!{pubstaticCOUNTER:UnsafeCell<HashMap<u32,u32>>=UnsafeCell::new(HashMap::new());}
Next, we can define our async task that is going to access and update the thread data by using unsafe code:
asyncfnsomething(number:u32){tokio::time::sleep(std::time::Duration::from_secs(numberasu64)).await;COUNTER.with(|counter|{letcounter=unsafe{&mut*counter.get()};matchcounter.get_mut(&number){Some(count)=>{letplaceholder=*count+1;*count=placeholder;},None=>{counter.insert(number,1);}}});}
We add in a Tokio sleep with the duration of the number put in to shuffle the async tasks around, in the order that the tasks are going to access the thread data. We then obtain a mutable reference to the data and perform an operation. Notice the COUNTER.with block where we access the data. This is not an async block, meaning that we cannot use await operations while accessing the data. We cannot context-switch to another async task while accessing the unsafe data. Inside the COUNTER.with block, we use unsafe code to directly access the data and increase the count.
Once our test is done, we need to print out the thread state. Therefore, we need to pass an async task into the thread to perform the print operation, which takes this form:
asyncfnprint_statement(){COUNTER.with(|counter|{letcounter=unsafe{&mut*counter.get()};println!("Counter: {:?}",counter);});}
We now have everything, so all we need to do is run our code in our main async function. First, we set up our local thread pool, which is just a single thread, and 100 thousand sequences of 1 to 5:
letpool=LocalPoolHandle::new(1);letsequence=[1,2,3,4,5];letrepeated_sequence:Vec<_>=sequence.iter().cycle().take(5000).cloned().collect();
This gives us half a million async tasks with varying Tokio sleep durations that we are going to chuck into this single thread. We then loop through these numbers, spinning off tasks that call our async function twice so the task sent to the thread makes the thread context-switch between each function and inside each function:
letmutfutures=Vec::new();fornumberinrepeated_sequence{futures.push(pool.spawn_pinned(move||asyncmove{something(number).await;something(number).await}));}
We are really encouraging the thread to context-switch multiple times when processing a task. This context switching, combined with the varying sleep durations and high number of tasks in total, will lead to inconsistent outcomes in the counts if we have clashes when accessing the data. Finally, we loop through the handles, joining them all to ensure that all the async tasks have executed, and we print out the count with the following code:
foriinfutures{let_=i.await.unwrap();}let_=pool.spawn_pinned(||async{print_statement().await}).await.unwrap();
The end result should be as follows:
Counter: {2: 200000, 4: 200000, 1: 200000, 3: 200000, 5: 200000}
No matter how many times we run them, the counts will always be the same. Here we did not have to perform atomic operations such as compare and swap, with multiple tries if an inconsistency occurs. We also did not need to await on a lock. We didn’t even need to check whether there were any mutable references before making a mutable reference to our data. Our unsafe code in this context is safe.
We can now use the state of a thread to affect our async tasks. However, what happens if our system is shut down? We might want to have a cleanup process so we can re-create our state when we spin up our runtime again. This is where graceful shutdowns come in.
Graceful Shutdowns
In a graceful shutdown, we catch when the program is shutting down in order to perform a series of processes before the program exits. These processes can be sending signals to other programs, storing state, clearing up transactions, and anything else you would want to do before the program exits.
Our first exploration of this topic can be the Ctrl-C signal. Usually when we run a Rust program through the terminal, we can stop our program by pressing Ctrl-C, prompting the program to exit. However, we can overwrite this preemptive exit with the tokio::signal module. To really prove that we have overwritten the Ctrl-C signal, we can build a simple program that has to accept the Ctrl-C signal three times before we exit our program. We can achieve this by building the background async task as follows:
asyncfncleanup(){println!("cleanup background task started");letmutcount=0;loop{tokio::signal::ctrl_c().await.unwrap();println!("ctrl-c received!");count+=1;ifcount>2{std::process::exit(0);}}}
Next, we can run our background task and loop indefinitely with the following main function:
#[tokio::main]asyncfnmain(){tokio::spawn(cleanup());loop{}}
When running our program, if we press Ctrl-C three times, we will get this printout:
cleanup background task started ^Cctrl-c received! ^Cctrl-c received! ^Cctrl-c received!
Our program did not exit until the signal was sent three times. Now we can exit our program on our own terms. However, before we move on, let’s add a blocking sleep to our loop in our background task before we await for the Ctrl-C signal, giving the following loop:
loop{std::thread::sleep(std::time::Duration::from_secs(5));tokio::signal::ctrl_c().await.unwrap();...}
If we were to run our program again, pressing Ctrl-C before the 5 seconds is up, the program would exit. With this, we can deduce that our program will handle the Ctrl-C signal as we want only when our program is directly awaiting the signal. We can get around this by spawning a thread that will manage an async runtime. We then use the rest of the main thread to listen for our signal:
#[tokio::main(flavor ="current_thread")]asyncfnmain(){std::thread::spawn(||{letruntime=tokio::runtime::Builder::new_multi_thread().enable_all().build().unwrap();runtime.block_on(async{println!("Hello, world!");});});letmutcount=0;loop{tokio::signal::ctrl_c().await.unwrap();println!("ctrl-c received!");count+=1;ifcount>2{std::process::exit(0);}}}
Now, no matter what our async runtime is processing, our main thread is ready to act on our Ctrl-C signal, but what about our state? In our cleanup process, we can extract the current state and then write it to a file so we can load the state when the program is started again. Writing and reading files is trivial, so we will focus on the extraction of the state from all the isolated threads we built in the previous section. The main difference from the previous section is that we are going to distribute the tasks over four isolated threads. First, we can wrap our local thread pool in a lazy evaluation:
staticRUNTIME:LazyLock<LocalPoolHandle>=LazyLock::new(||{LocalPoolHandle::new(4)});
We need to define our async task that extracts the state of a thread:
fnextract_data_from_thread()->HashMap<u32,u32>{letmutextracted_counter:HashMap<u32,u32>=HashMap::new();COUNTER.with(|counter|{letcounter=unsafe{&mut*counter.get()};extracted_counter=counter.clone();});returnextracted_counter}
We can send this task through each thread, which gives us a nonblocking way to sum the total number of counts for the entire system (Figure 7-3).
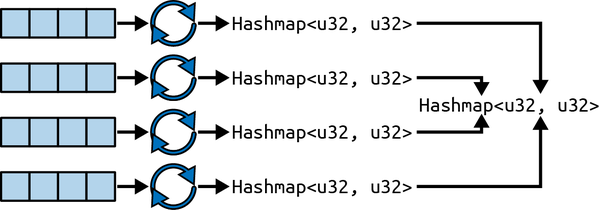
Figure 7-3. Flow of extracting state from all threads
We can implement the process mapped out in Figure 7-3 with the following code:
asyncfnget_complete_count()->HashMap<u32,u32>{letmutcomplete_counter=HashMap::new();letmutextracted_counters=Vec::new();foriin0..4{extracted_counters.push(RUNTIME.spawn_pinned_by_idx(||asyncmove{extract_data_from_thread()},i));}forcounter_futureinextracted_counters{letextracted_counter=counter_future.await.unwrap_or_default();for(key,count)inextracted_counter{*complete_counter.entry(key).or_insert(0)+=count;}}returncomplete_counter}
We call spawn_pinned_by_idx to ensure that we send only one extract_data_from_thread task to every thread.
We are now ready to run our system with the following main function:
#[tokio::main(flavor ="current_thread")]asyncfnmain(){let_handle=tokio::spawn(async{...});tokio::signal::ctrl_c().await.unwrap();println!("ctrl-c received!");letcomplete_counter=get_complete_count().await;println!("Complete counter: {:?}",complete_counter);}
We spawn tasks to increase the counts inside tokio::spawn:
letsequence=[1,2,3,4,5];letrepeated_sequence:Vec<_>=sequence.iter().cycle().take(500000).cloned().collect();letmutfutures=Vec::new();fornumberinrepeated_sequence{futures.push(RUNTIME.spawn_pinned(move||asyncmove{something(number).await;something(number).await}));}foriinfutures{let_=i.await.unwrap();}println!("All futures completed");
Our system is now ready to run. If we run the program until you get the printout that all futures are completed before pressing Ctrl-C, we get the following printout:
Complete counter: {1: 200000, 4: 200000, 2: 200000, 5: 200000, 3: 200000}
Because we know that we sent only one extract task to each thread using the spawn_pinned_by_idx function, and that our total count is the same as it was when we were running all our tasks through one thread, we can conclude that our data extraction is accurate. If we press Ctrl-C before the futures have finished, we should get something similar to this printout:
Complete counter: {2: 100000, 3: 32290, 1: 200000}
We have exited the program before the program finishes, and we get the current state. Our state is now ready to be written before we exit if we want.
While our code facilitates a cleanup when we press Ctrl-C, this signal is not always the most practical method of shutting down our system. For instance, we might have our async system running in the background so our terminal is not tethered to the program. We can shut down our program by sending a SIGHUP signal to our system. To listen for the SIGHUP signal, we need the following import:
usetokio::signal::unix::{signal,SignalKind};
We can then replace the Ctrl-C code at bottom of our main function as follows:
letpid=std::process::id();println!("The PID of this process is: {}",pid);letmutstream=signal(SignalKind::hangup()).unwrap();stream.recv().await;letcomplete_counter=get_complete_count().await;println!("Complete counter: {:?}",complete_counter);
We print out our PID so that we know which PID to send the signal to with the following command:
kill-SIGHUP<pid>
When running the kill command, you should have similar results to when you were pressing Ctrl-C. We can now say that you know how to customize Tokio in the way the runtime is configured, the tasks are run, and the runtime is shut down.
Summary
In this chapter, we went into the specifics of setting up a Tokio runtime and how its settings affect the way it operates. With these specifics, we really got to take control of the runtime’s number of workers and blocking threads and the number of ticks performed before accepting a new task to be polled. We also explored defining different runtimes in the same program so we can choose which runtime to send the task on. Remember, the threads in the Tokio runtime get parked when they are not being used, so we will not be wasting resources if a Tokio runtime is not being constantly used.
We then controlled how our tasks were handled by threads with local pools. We even tested our unsafe access to our thread state in the Tokio runtime to show that accessing the thread state in a task is safe. Finally, we covered graceful shutdowns. Although we do not have to write our own boilerplate code, Tokio still gives us the ability to configure our runtime with a lot of flexibility. We have no doubt that in your async Rust career, you will come across a codebase that is using Tokio. You should now be comfortable customizing the Tokio runtime in the codebase and managing the way your async tasks are being processed. In Chapter 8, we will implement the actor model to solve problems in an async way that is modular.