The control flow (see figure 2.1) of program execution describes how the individual statements of the program code are sequenced: that is, which statement is executed after another. Up to now, we have mostly looked at code that let us deduce this control flow from syntax and a controlling expression. That way, each function can be described using a hierarchical composition of basic blocks. A basic block is a maximum sequence of statements such that once execution starts at the first of these statements, it continues unconditionally until the last, and such that all execution of any statement in the sequence starts with the first.
If we are supposing that all conditionals and loop statements use {} blocks, in a simplified view such a basic block
Observe that in this definition, no exception is made for general function calls: these are seen to temporarily suspend execution of a basic block but not to end it. Among the functions with special control flow that end a basic block are some we know: those marked with the keyword _Noreturn, such as exit and abort. Another such function is setjmp, which may return more than once, as discussed later.
Code that is just composed of basic blocks that are stitched together by if/else[1] or loop statements has the double advantage of being easily readable for us humans, and leads to better optimization opportunities for the compiler. Both can directly deduce the lifetime and access pattern of variables and compound literals in basic blocks, and then capture how these are melded by the hierarchical composition of the basic blocks into their function.
switch/case statements complicate the view a bit.
A theoretical foundation of this structured approach was given quite early for Pascal programs by Nishizeki et al. [1977] and extended to C and other imperative languages by Thorup [1995]. They prove that structured programs (that is, programs without goto or other arbitrary jump constructs) have a control flow that matches nicely into a tree-like structure that can be deduced from the syntactical nesting of the program. Unless you have to do otherwise, you should stick to that programming model.
Nevertheless, some exceptional situations require exceptional measures. Generally, changes to the control flow of a program can originate from
Defined in POSIX systems.
These changes in control flow can mix up the knowledge the compiler has about the abstract state of the execution. Roughly, the complexity of the knowledge that a human or mechanical reader has to track increases from top to bottom in that list. Up to now, we have only seen the first four constructs. These correspond to language features, which are determined by syntax (such as keywords) or by operators (such as the () of a function call). The latter three are introduced by C library interfaces. They provide changes in the control flow of a program that can jump across function boundaries (longjmp), can be triggered by events that are external to the program (interrupts), or can even establish a concurrent control flow, another thread of execution.
Various difficulties may arise when objects are under the effect of unexpected control flow:
Because access to the objects that constitute the state of a program becomes complicated, C provides features that help to cope with the difficulties. In this list, they are noted in parentheses, and we will discuss them in detail in the following sections.
To illustrate most of these concepts, we will discuss some central example code: a recursive descent parser called basic_blocks. The central function descend is presented in the following listing.
60 static 61 char const* descend(char const* act, 62 unsigned dp[restrict static 1], // Bad 63 size_t len, char buffer[len], 64 jmp_buf jmpTarget) { 65 if (dp[0]+3 > sizeof head) longjmp(jmpTarget, tooDeep); 66 ++dp[0]; 67 NEW_LINE: // Loops on output 68 while (!act || !act[0]) { // Loops for input 69 if (interrupt) longjmp(jmpTarget, interrupted); 70 act = skipspace(fgets(buffer, len, stdin)); 71 if (!act) { // End of stream 72 if (dp[0] != 1) longjmp(jmpTarget, plusL); 73 else goto ASCEND; 74 } 75 } 76 fputs(&head[sizeof head - (dp[0] + 2)], stdout); // Header 77 78 for (; act && act[0]; ++act) { // Remainder of the line 79 switch (act[0]) { 80 case LEFT: // Descends on left brace 81 act = end_line(act+1, jmpTarget); 82 act = descend(act, dp, len, buffer, jmpTarget); 83 act = end_line(act+1, jmpTarget); 84 goto NEW_LINE; 85 case RIGHT: // Returns on right brace 86 if (dp[0] == 1) longjmp(jmpTarget, plusR); 87 else goto ASCEND; 88 default: // Prints char and goes on 89 putchar(act[0]); 90 } 91 } 92 goto NEW_LINE; 93 ASCEND: 94 --dp[0]; 95 return act; 96 }
This code serves several purposes. First, it obviously presents several features that we discuss later: recursion, short jumps (goto), long jumps (longjmp), and interrupt handling.
But at least as important, it is probably the most difficult code we have handled so far in this book, and for some of you it might even be the most complicated code you have ever seen. Yet, with its 36 lines, it still fit on one screen, and it is by itself an affirmation that C code can be very compact and efficient. It might take you hours to understand, but please do not despair; you might not know it yet, but if you have worked thoroughly through this book, you are ready for this.
The function implements a recursive descent parser that recognizes {} constructs in text given on stdin and indents this text on output, according to the nesting of the {}. More formally, written in Backus-Nauer-form (BNF)[3] this function detects text as of the following recursive definition
This is a formalized description of computer-readable languages. Here, program is recursively defined to be a sequence of text, optionally followed by another sequence of programs that are inside curly braces.
and prints such a program conveniently by changing the line structure and indentation.
The operational description of the program is to handle text, in particular to indent C code or similar in a special way. If we feed the program text from listing 3.1 into this, we see the following output:
0 > ./code/basic_blocks < code/heron.c 1 | #include <stdlib.h> 2 | #include <stdio.h> 3 | /* lower and upper iteration limits centered around 1.0 */ 4 | static double const eps1m01 = 1.0 - 0x1P-01; 5 | static double const eps1p01 = 1.0 + 0x1P-01; 6 | static double const eps1m24 = 1.0 - 0x1P-24; 7 | static double const eps1p24 = 1.0 + 0x1P-24; 8 | int main(int argc, char* argv[argc+1]) 9 >| for (int i = 1; i < argc; ++i) 10 >>| // process args 11 >>| double const a = strtod(argv[i], 0); // arg -> double 12 >>| double x = 1.0; 13 >>| for (;;) 14 >>>| // by powers of 2 15 >>>| double prod = a*x; 16 >>>| if (prod < eps1m01) x *= 2.0; 17 >>>| else if (eps1p01 < prod) x *= 0.5; 18 >>>| else break; 19 >>>| 20 >>| for (;;) 21 >>>| // Heron approximation 22 >>>| double prod = a*x; 23 >>>| if ((prod < eps1m24) || (eps1p24 < prod)) 24 >>>| x *= (2.0 - prod); 25 >>>| else break; 26 >>>| 27 >>| printf("heron: a=%.5e,\tx=%.5e,\ta*x=%.12f\n", 28 >>| a, x, a*x); 29 >>| 30 >| return EXIT_SUCCESS; 31 >|
So basic_blocks “eats” curly braces {} and instead indents the code with a series of > characters: each level of nesting {} adds a >.
For a high-level view of how this function achieves this, and abstracting away all the functions and variables you do not know yet, have a look at the switch statement that starts on line 79 and the for loop that surrounds it. It switches according to the current character. Three different cases are distinguished. The simplest is the default case: a normal character is printed, the character is advanced, and the next iteration starts.
The two other cases handle { and } characters. If we encounter an opening brace, we know that we have to indent the text with one more >. Therefore, we recurse into the same function descend again; see line 82. If, on the other hand, a closing brace is encountered, we go to ASCEND and terminate this recursion level. The recursion depth itself is handled with the variable dp[0], which is incremented on entry (line 66) and decremented on exit (line 94).
If you are trying to understand this program for the first time, the rest is noise. This noise helps to handle exceptional cases, such as an end of line or a surplus of left or right braces. We will see how all this works in much more detail later.
Before we can look at the details of how the control flow of a program can change in unexpected ways, we must better understand what the normal sequence of C statements guarantees and what it does not. We saw in section 4.5 that the evaluation of C expressions does not necessarily follow the lexicographical order as they are written. For example, the evaluation of function arguments can occur in any order. The different expressions that constitute the arguments can even be interleaved to the discretion of the compiler, or depending on the availability of resources at execution time. We say that function argument expressions are unsequenced.
There are several reasons for establishing only relaxed rules for evaluation. One is to allow for the easy implementation of optimizing compilers. Efficiency of the compiled code has always been a strong point of C compared to other programming languages.
But another reason is that C does not add arbitrary restrictions when they don’t have a convincing mathematical or technical foundation. Mathematically, the two operands a and b in a+b are freely exchangeable. Imposing an evaluation order would break this rule, and arguing about a C program would become more complicated.
In the absence of threads, most of C’s formalization of this is done with sequence points. These are points in the syntactical specification of the program that impose a serialization of the execution. But we will also later see additional rules that force sequencing between the evaluation of certain expressions that don’t imply sequence points.
On a high level, a C program can be seen as a series of sequence points that are reached one after the other, and the code between such sequence points may be executed in any order, be interleaved, or obey certain other sequencing constraints. In the simplest case, for example, when two statements are separated by a ;, a statement before a sequence point is sequenced before the statement after the sequence point.
But even the existence of sequence points may not impose a particular order between two expressions: it only imposes that there is some order. To see that, consider the following code, which is well defined:
3 unsigned add(unsigned* x, unsigned const* y) { 4 return *x += *y; 5 } 6 int main(void) { 7 unsigned a = 3; 8 unsigned b = 5; 9 printf("a = %u, b = %u\n", add(&a, &b), add(&b, &a)); 10 }
From section 4.5, remember that the two arguments to printf can be evaluated in any order, and the rules for sequence points that we will see shortly will tell us that the function calls to add impose sequence points. As a result, we have two possible outcomes for this code. Either the first add is executed first, entirely, and then the second, or the other way around. For the first possibility, we have
The output of such an execution is
0 a = 8, b = 13
For the second, we get
And the output is
0 a = 11, b = 8
That is, although the behavior of this program is defined, its outcome is not completely determined by the C standard. The specific terminology that the C standard applies to such a situation is that the two calls are indeterminately sequenced. This is not just a theoretical discussion; the two commonly used open source C compilers GCC and Clang differ on this simple code. Let me stress this again: all of this is defined behavior. Don’t expect a compiler to warn you about such problems.
Side effects in functions can lead to indeterminate results.
Here is a list of all sequence points that are defined in terms of C’s grammar:
Be careful: commas that separate function arguments are not in this category.
This also holds for a comma that ends the declaration of an enumeration constant.
This sees the function designator on the same level as the function arguments.
There are other sequencing restrictions besides those implied by sequence points. The first two are more or less obvious but should be stated nevertheless:
The specific operation of any operator is sequenced after the evaluation of all its operands.
The effect of updating an object with any of the assignment, increment, or decrement operators is sequenced after the evaluation of its operands.
For function calls, there also is an additional rule that says the execution of a function is always completed before any other expression.
A function call is sequenced with respect to all evaluations of the caller.
As we have seen, this might be indeterminately sequenced, but sequenced nevertheless.
Another source of indeterminately sequenced expressions originates from initializers.
Initialization-list expressions for array or structure types are indeterminately sequenced.
Last but not least, some sequence points are also defined for the C library:
Be aware that library functions that are implemented as macros may not define a sequence point.
The latter two impose rules for C library functions that are similar to those for ordinary functions. This is needed because the C library itself might not necessarily be implemented in C.
We have seen a feature that interrupts the common control flow of a C program: goto. As you hopefully remember from section 14.5, this is implemented with two constructs: labels mark positions in the code, and goto statements jump to these marked positions inside the same function.
We also have seen that such jumps have complicated implications for the lifetime and visibility of local objects. In particular, there is a difference in the lifetime of objects that are defined inside loops and inside a set of statements that is repeated by goto.[8] Consider the following two snippets:
see ISO 9899:2011 6.5.2.5 p16
1 size_t* ip = 0 2 while(something) 3 ip = &(size_t){ fun() }; /* Life ends with while */ 4 /* Good: resource is freed */ 5 printf("i is %d", *ip) /* Bad: object is dead */
versus
1 size_t* ip = 0 2 RETRY: 3 ip = &(size_t){ fun() }; /* Life continues */ 4 if (condition) goto RETRY; 5 /* Bad: resource is blocked */ 6 printf("i is %d", *ip) /* Good: object is alive */
Both define a local object in a loop by using a compound literal. The address of that compound literal is assigned to a pointer, so the object remains accessible outside the loop and can, for example, be used in a printf statement.
It looks as if they both are semantically equivalent, but they are not. For the first, the object that corresponds to the compound literal only lives in the scope of the while statement.
Each iteration defines a new instance of a local object.
Therefore, the access to the object in the *ip expression is invalid. When omitting the printf in the example, the while loop has the advantage that the resources that are occupied by the compound literal can be reused.
For the second example, there is no such restriction: the scope of the definition of the compound literal is the whole surrounding block. So the object is alive until that block is left (takeaway 13.22). This is not necessarily good: the object occupies resources that could otherwise be reassigned.
In cases where there is no need for the printf statement (or similar access), the first snippet is clearer and has better optimization opportunities. Therefore, under most circumstances, it is preferable.
goto should only be used for exceptional changes in control flow.
Here, exceptional usually means we encounter a transitional error condition that requires local cleanup, such as we showed in section 14.5. But it could also mean specific algorithmic conditions, as we can see in listing 17.1.
Here, two labels, NEW_LINE and ASCEND, and two macros, LEFT and RIGHT, reflect the actual state of the parsing. NEW_LINE is a jump target when a new line is to be printed, and ASCEND is used if a } is encountered or if the stream ended. LEFT and RIGHT are used as case labels if left or right curly braces are detected.
The reason to have goto and labels here is that both states are detected in two different places in the function, and at different levels of nesting. In addition, the names of the labels reflect their purpose and thereby provide additional information about the structure.
The function descend has more complications than the twisted local jump structure: it also is recursive. As we have seen, C handles recursive functions quite simply.
Each function call defines a new instance of a local object.
So usually, different recursive calls to the same function that are active simultaneously don’t interact; everybody has their own copy of the program state.

But here, because of the pointers, this principle is weakened. The data to which buffer and dp point is modified. For buffer, this is probably unavoidable: it will contain the data that we are reading. But dp could (and should) be replaced by a simple unsigned argument.[[Exs 1]] Our implementation only has dp as a pointer because we want to be able to track the depth of the nesting in case an error occurs. So if we abstract out the calls to longjmp that we did not yet explain, using such a pointer is bad. The state of the program is more difficult to follow, and we miss optimization opportunities.[[Exs 2]]
Change descend such that it receives an unsigned depth instead of a pointer.
Compare the assembler output of the initial version against your version without dp pointer.
In our particular example, because dp is restrict qualified and not passed to the calls to longjump (discussed shortly) and it is only incremented at the beginning and decremented at the end, dp[0] is restored to its original value just before the return from the function. So, seen from the outside, it appears that descend doesn’t change that value at all.
If the function code of descend is visible on the call side, a good optimizing compiler can deduce that dp[0] did not change through the call. If longjmp weren’t special, this would be a nice optimization opportunity. Shortly we will see how the presence of longjmp invalidates this optimization and leads to a subtle bug.
Our function descend may also encounter exceptional conditions that cannot be repaired. We use an enumeration type to name them. Here, eofOut is reached if stdout can’t be written, and interrupted refers to an asynchronous signal that our running program received. We will discuss this concept later:
32 /** 33 ** @brief Exceptional states of the parse algorithm 34 **/ 35 enum state { 36 execution = 0, //*< Normal execution 37 plusL, //*< Too many left braces 38 plusR, //*< Too many right braces 39 tooDeep, //*< Nesting too deep to handle 40 eofOut, //*< End of output 41 interrupted, //*< Interrupted by a signal 42 };
We use the function longjmp to deal with these situations, and we put the corresponding calls directly at the place in the code where we recognize that such a condition is reached:
Since stdout is line-buffered, we only check for eofOut when we write the '\n' character. This happens inside the short function end_line:
48 char const* end_line(char const* s, jmp_buf jmpTarget) { 49 if (putchar('\n') == EOF) longjmp(jmpTarget, eofOut); 50 return skipspace(s); 51 }
The function longjmp comes with a companion macro setjmp that is used to establish a jump target to which a call of longjmp may refer. The header setjmp.h provides the following prototypes:
<setjmp.h>
_Noreturn void longjmp(jmp_buf target, int condition); int setjmp(jmp_buf target); // Usually a macro, not a function
The function longjmp also has the _Noreturn property, so we are assured that once we detect one of the exceptional conditions, execution of the current call to descend will never continue.
longjmp never returns to the caller.
This is valuable information for the optimizer. In descend, longjmp is called in five different places, and the compiler can substantially simplify the analysis of the branches. For example, after the !act tests, it can be assumed that act is non-null on entry to the for loop.
Normal syntactical labels are only valid goto targets within the same function as they are declared. In contrast to that, a jmp_buf is an opaque object that can be declared anywhere and that can be used as long as it is alive and its contents are valid. In descend, we use just one jump target of type jmp_buf, which we declare as a local variable. This jump target is set up in the base function basic_blocks that serves as an interface to descend; see listing 17.2. This function mainly consists of one big switch statement that handles all the different conditions.
100 void basic_blocks(void) { 101 char buffer[maxline]; 102 unsigned depth = 0; 103 char const* format = 104 "All %0.0d%c %c blocks have been closed correctly\n"; 105 jmp_buf jmpTarget; 106 switch (setjmp(jmpTarget)) { 107 case 0: 108 descend(0, &depth, maxline, buffer, jmpTarget); 109 break; 110 case plusL: 111 format = 112 "Warning: %d %c %c blocks have not been closed properly\n"; 113 break; 114 case plusR: 115 format = 116 "Error: closing too many (%d) %c %c blocks\n"; 117 break; 118 case tooDeep: 119 format = 120 "Error: nesting (%d) of %c %c blocks is too deep\n"; 121 break; 122 case eofOut: 123 format = 124 "Error: EOF for stdout at nesting (%d) of %c %c blocks\n"; 125 break; 126 case interrupted: 127 format = 128 "Interrupted at level %d of %c %c block nesting\n"; 129 break; 130 default:; 131 format = 132 "Error: unknown error within (%d) %c %c blocks\n"; 133 } 134 fflush(stdout); 135 fprintf(stderr, format, depth, LEFT, RIGHT); 136 if (interrupt) { 137 SH_PRINT(stderr, interrupt, 138 "is somebody trying to kill us?"); 139 raise(interrupt); 140 } 141 }
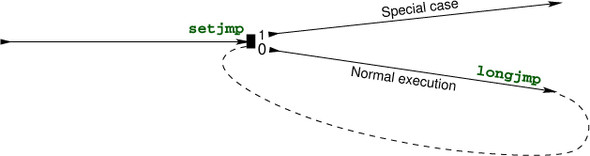
The 0 branch of that switch is taken when we come here through the normal control flow. This is one of the basic principles for setjmp.
When reached through normal control flow, a call to setjmp marks the call location as a jump target and returns 0.
As we said, jmpTarget must be alive and valid when we call longjmp. So for an auto variable, the scope of the declaration of the variable must not have been left; otherwise it would be dead. For validity, all of the context of the setjmp must still be active when we call longjmp. Here, we avoid complications by having jmpTarget declared in the same scope as the call to setjmp.
Leaving the scope of a call to setjmp invalidates the jump target.
Once we enter case 0 and call descend, we may end up in one of the exceptional conditions and call longjmp to terminate the parse algorithm. This passes control back to the call location that was marked in jmpTarget, as if we just returned from the call to setjmp. The only visible difference is that now the return value is the condition that we passed as a second argument to longjmp. If, for example, we encountered the tooDeep condition at the beginning of a recursive call to descend and called longjmp(jmpTarget, tooDeep), we jump back to the controlling expression of the switch and receive the return value of tooDeep. Execution then continues at the corresponding case label.
A call to longjmp transfers control directly to the position that was set by setjmp as if that had returned the condition argument.
Be aware, though, that precautions have been taken to make it impossible to cheat and to retake the normal path a second time.
A 0 as a condition parameter to longjmp is replaced by 1.
The setjmp/longjmp mechanism is very powerful and can avoid a whole cascade of returns from functions calls. In our example, if we allow the maximal depth of nesting of the input program of 30, say, the detection of the tooDeep condition will happen when there are 30 active recursive calls to descend. A regular error-return strategy would return to each of these and do some work on each level. A call to longjmp allows us to shorten all these returns and proceed the execution directly in the switch of basic_blocks.
Because setjmp/longjmp is allowed to make some simplifying assumptions, this mechanism is surprisingly efficient. Depending on the processor architecture, it usually needs no more than 10 to 20 assembler instructions. The strategy followed by the library implementation is usually quite simple: setjmp saves the essential hardware registers, including stack and instruction pointers, in the jmp_buf object, and longjmp restores them from there and passes control back to the stored instruction pointer.[9]
For the vocabulary of this you might want to read or re-read section 13.5.
One of the simplifications setjmp makes is about its return. Its specification says it returns an int value, but this value cannot be used inside arbitrary expressions.
setjmp may be used only in simple comparisons inside controlling expression of conditionals.
So it can be used directly in a switch statement, as in our example, and it can be tested for ==, <, and so on, but the return value of setjmp may not be used in an assignment. This guarantees that the setjmp value is only compared to a known set of values, and the change in the environment when returning from longjmp may just be a special hardware register that controls the effect of conditionals.
As we said, this saving and restoring of the execution environment by the setjmp call is minimal. Only a minimal necessary set of hardware registers is saved and restored. No precautions are taken to get local optimizations in line or even to take into account that the call location may be visited a second time.
Optimization interacts badly with calls to setjmp.
If you execute and test the code in the example, you will see that there actually is a problem in our simple usage of setjmp. If we trigger the plusL condition by feeding a partial program with a missing closing }, we would expect the diagnostic to read something like
0 Warning: 3 { } blocks have not been closed properly
Depending on the optimization level of your compilation, instead of the 3, you will most probably see a 0, independent of the input program. This is because the optimizer does an analysis based on the assumption that the switch cases are mutually exclusive. It only expects the value of depth to change if execution goes through case 0 and thus the call of descend. From inspection of descend (see section 17.4), we know that the value of depth is always restored to its original value before return, so the compiler may assume that the value doesn’t change through this code path. Then, none of the other cases changes depth, so the compiler can assume that depth is always 0 for the fprintf call.
As a consequence, optimization can’t make correct assumptions about objects that are changed in the normal code path of setjmp and referred to in one of the exceptional paths. There is only one recipe against that.
Objects that are modified across longjmp must be volatile.
Syntactically, the qualifier volatile applies similar to the other qualifiers const and restrict that we have encountered. If we declare depth with that qualifier
unsigned volatile depth = 0;
and amend the prototype of descend accordingly, all accesses to this object will use the value that is stored in memory. Optimizations that try to make assumptions about its value are blocked out.
volatile objects are reloaded from memory each time they are accessed.
volatile objects are stored to memory each time they are modified.
So volatile objects are protected from optimization, or, if we look at it negatively, they inhibit optimization. Therefore, you should only make objects volatile if you really need them to be.[[Exs 3]]
Your version of descend that passes depth as a value might not propagate the depth correctly if it encounters the plusL condition. Ensure that it copies that value to an object that can be used by the fprintf call in basic_blocks.
Finally, note some subtleties of the jmp_buf type. Remember that it is an opaque type: you should never make assumptions about its structure or its individual fields.
The typedef for jmp_buf hides an array type.
And because it is an opaque type, we don’t know anything about the base type, jmp_buf_base, say, of the array. Thus:
In a way, this emulates a pass-by-reference mechanism, for which other programming languages such as C++ have explicit syntax. Generally, using this trick is not a good idea: the semantics of a jmp_buf variable depend on being locally declared or on being a function parameter; for example, in basic_blocks, that variable it is not assignable, whereas in descend, the analogous function parameter is modifiable because it is rewritten to a pointer. Also, we cannot use the more-specific declarations from Modern C for the function parameter that would be adequate, something like
jmp_buf_base jmpTarget[restrict const static 1]
to insist that the pointer shouldn’t be changed inside the function, that it must not be 0, and that access to it can be considered unique for the function. As of today, we would not design this type like this, and you should not try to copy this trick for the definition of your own types.
As we have seen, setjmp/longjmp can be used to handle exceptional conditions that we detect ourselves during the execution of our code. A signal handler is a tool that handles exceptional conditions that arise differently: that are triggered by some event that is external to the program. Technically, there are two types of such external events: hardware interrupts, also referred to as traps or synchronous signals, and software interrupts or asynchronous signals.
The first occurs when the processing device encounters a severe fault that it cannot deal with: for example, a division by zero, addressing a non-existent memory bank, or using a misaligned address in an instruction that operates on a wider integer type. Such an event is synchronous with the program execution. It is directly caused by a faulting instruction, so it can always be known at which particular instruction the interrupt was raised.
The second arises when the operating or runtime system decides that our program should terminate, because some deadline is exceeded, a user has issued a termination request, or the world as we know it is going to end. Such an event is asynchronous, because it can fall in the middle of a multistage instruction, leaving the execution environment in an intermediate state.
Most modern processors have a built-in feature to handle hardware interrupts: an interrupt vector table. This table is indexed by the different hardware faults that the platform knows about. Its entries are pointers to procedures, interrupt handlers, that are executed when the specific fault occurs. So if the processor detects such a fault, execution is automatically switched away from the user code, and an interrupt handler is executed. Such a mechanism is not portable, because the names and locations of the faults are different from platform to platform. It is tedious to handle, because to program a simple application, we’d have to provide all handlers for all interrupts.
C’s signal handlers provide us with an abstraction to deal with both types of interrupts, hardware and software, in a portable way. They work similarly to what we describe for hardware interrupts, but
In each item of that list, there are parenthetical reservations, because upon a closer look it appears that C’s interface for signal handlers is quite rudimentary; all platforms have their extensions and special rules.
C’s signal-handling interface is minimal and should only be used for elementary situations.
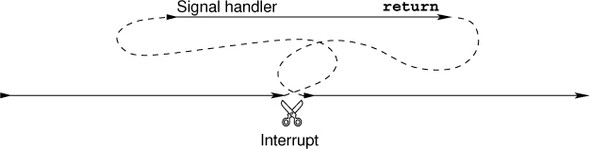
The control flow of a handled signal is shown in figure 17.3. The normal control flow is interrupted at a place that is not foreseeable by the application, a signal handler function kicks in and performs some tasks, and after that the control resumes at exactly the same place and state as when it was interrupted.
The interface is defined in the header signal.h. The C standard distinguishes six different values, called signal numbers. The following are the exact definitions as given there. Three of these values are typically caused by hardware interrupts[10]:
Called computational exceptions by the standard.
<signal.h>
SIGFPE an erroneous arithmetic operation, such as zero divide or an operation resulting in overflow
SIGILL detection of an invalid function image, such as an invalid instruction
SIGSEGV an invalid access to storage
The other three are usually triggered by software or users:
SIGABRT abnormal termination, such as is initiated by the abort function
SIGINT receipt of an interactive attention signal
SIGTERM a termination request sent to the program
A specific platform will have other signal numbers; the standard reserves all identifiers starting with SIG for that purpose. Their use is undefined as of the C standard, but as such there is nothing bad about it. Undefined here really means what it says: if you use it, it has to be defined by some other authority than the C standard, such as your platform provider. Your code becomes less portable as a consequence.
There are two standard dispositions for handling signals, both also represented by symbolic constants. SIG_DFL restores the platform’s default handler for the specific signal, and SIG_IGN indicates that the signal is to be ignored. Then, the programmer may write their own signal handlers. The handler for our parser looks quite simple:
143 /** 144 ** @brief A minimal signal handler 145 ** 146 ** After updating the signal count, for most signals this 147 ** simply stores the signal value in "interrupt" and returns. 148 **/ 149 static void signal_handler(int sig) { 150 sh_count(sig); 151 switch (sig) { 152 case SIGTERM: quick_exit(EXIT_FAILURE); 153 case SIGABRT: _Exit(EXIT_FAILURE); 154 #ifdef SIGCONT 155 // continue normal operation 156 case SIGCONT: return; 157 #endif 158 default: 159 /* reset the handling to its default */ 160 signal(sig, SIG_DFL); 161 interrupt = sig; 162 return; 163 } 164 }
As you can see, such a signal handler receives the signal number sig as an argument and switches according to that number. Here we have provisions for signal numbers SIGTERM and SIGABRT. All other signals are just handled by resetting the handler for that number to its default, storing the number in our global variable interrupt, and then returning to the point where the interrupt occurred.
The type of a signal handler has to be compatible with the following:[11]
There is no such type defined by the standard, though.
71 /** 72 ** @brief Prototype of signal handlers 73 **/ 74 typedef void sh_handler(int);
That is, it receives a signal number as an argument and doesn’t return anything. As such, this interface is quite limited and does not allow us to pass enough information, in particular none about the location and circumstances for which the signal occurred.
Signal handlers are established by a call to signal, as we saw in our function signal_handler. Here, it is just used to reset the signal disposition to the default. signal is one of the two function interfaces that are provided by signal.h:
<signal.h>
sh_handler* signal(int, sh_handler*); int raise(int);
The return value of signal is the handler that was previously active for the signal, or the special value SIG_ERR if an error occurred. Inside a signal handler, signal should only be used to change the disposition of the same signal number that was received by the call. The following function has the same interface as signal but provides a bit more information about the success of the call:
92 /** 93 ** @ brief Enables a signal handler and catches the errors 94 **/ 95 sh_handler* sh_enable(int sig, sh_handler* hnd) { 96 sh_handler* ret = signal(sig, hnd); 97 if (ret == SIG_ERR) { 98 SH_PRINT(stderr, sig, "failed"); 99 errno = 0; 100 } else if (ret == SIG_IGN) { 101 SH_PRINT(stderr, sig, "previously ignored"); 102 } else if (ret && ret != SIG_DFL) { 103 SH_PRINT(stderr, sig, "previously set otherwise"); 104 } else { 105 SH_PRINT(stderr, sig, "ok"); 106 } 107 return ret; 108 }
The main function for our parser uses this in a loop to establish signal handlers for all signal numbers that it can:
187 // Establishes signal handlers 188 for (unsigned i = 1; i < sh_known; ++i) 189 sh_enable(i, signal_handler);
As an example, on my machine this provides the following information at the startup of the program:
0 sighandler.c:105: #1 (0 times), unknown signal number, ok 1 sighandler.c:105: SIGINT (0 times), interactive attention signal, ok 2 sighandler.c:105: SIGQUIT (0 times), keyboard quit, ok 3 sighandler.c:105: SIGILL (0 times), invalid instruction, ok 4 sighandler.c:105: #5 (0 times), unknown signal number, ok 5 sighandler.c:105: SIGABRT (0 times), abnormal termination, ok 6 sighandler.c:105: SIGBUS (0 times), bad address, ok 7 sighandler.c:105: SIGFPE (0 times), erroneous arithmetic operation, ok 8 sighandler.c:98: SIGKILL (0 times), kill signal, failed: Invalid argument 9 sighandler.c:105: #10 (0 times), unknown signal number, ok 10 sighandler.c:105: SIGSEGV (0 times), invalid access to storage, ok 11 sighandler.c:105: #12 (0 times), unknown signal number, ok 12 sighandler.c:105: #13 (0 times), unknown signal number, ok 13 sighandler.c:105: #14 (0 times), unknown signal number, ok 14 sighandler.c:105: SIGTERM (0 times), termination request, ok 15 sighandler.c:105: #16 (0 times), unknown signal number, ok 16 sighandler.c:105: #17 (0 times), unknown signal number, ok 17 sighandler.c:105: SIGCONT (0 times), continue if stopped, ok 18 sighandler.c:98: SIGSTOP (0 times), stop process, failed: Invalid argument
The second function raise can be used to deliver the specified signal to the current execution. We already used it at the end of basic_blocks to deliver the signal that we had caught to the preinstalled handler.
The mechanism of signals is similar to setjmp/longjmp: the current state of execution is memorized, control flow is passed to the signal handler, and a return from there restores the original execution environment and continues execution. The difference is that there is no special point of execution that is marked by a call to setjmp.
Signal handlers can kick in at any point of execution.
Interesting signal numbers in our case are the software interrupts SIGABRT, SIGTERM, and SIGINT, which usually can be sent to the application with a magic keystroke such as Ctrl-C. The first two will call _Exit and quick_exit, respectively. So if the program receives these signals, execution will be terminated: for the first, without calling any cleanup handlers; and for the second, by going through the list of cleanup handlers that were registered with at_quick_exit.
SIGINT will choose the default case of the signal handler, so it will eventually return to the point where the interrupt occurred.
After return from a signal handler, execution resumes exactly where it was interrupted.
If that interrupt had occurred in function descend, it would first continue execution as if nothing had happened. Only when the current input line is processed and and a new one is needed will the variable interrupt be checked and execution wound down by calling longjmp. Effectively, the only difference between the situation before the interrupt and after is that the variable interrupt has changed its value.
We also have a special treatment of a signal number that is not described by the C standard, SIGCONT, but on my operating system, POSIX. To remain portable, the use of this signal number is protected by guards. This signal is meant to continue execution of a program that was previously stopped: that is, for which execution had been suspended. In that case, the only thing to do is to return. By definition, we don’t want any modification of the program state whatsoever.
So another difference from the setjmp/longjmp mechanism is that for it, the return value of setjmp changed the execution path. A signal handler, on the other hand, is not supposed to change the state of execution. We have to invent a suitable convention to transfer information from the signal handler to the normal program. As for longjmp, objects that are potentially changed by a signal handler must be volatile qualified: the compiler cannot know where interrupt handlers may kick in, and thus all its assumptions about variables that change through signal handling can be false.
But signal handlers face another difficulty:
A C statement may correspond to several processor instructions.
For example, a double x could be stored in two usual machine words, and a write (assignment) of x to memory could need two separate assembler statements to write both halves.
When considering normal program execution as we have discussed so far, splitting a C statement into several machine statements is no problem. Such subtleties are not directly observable.[12] With signals, the picture changes. If such an assignment is split in the middle by the occurrence of a signal, only half of x is written, and the signal handler will see an inconsistent version of it. One half corresponds to the previous value, the other to the new one. Such a zombie representation (half here, half there) may not even be a valid value for double.
They are only observable from outside the program because such a program may take more time than expected.
Signal handlers need types with uninterruptible operations.
Here, the term uninterruptible operation refers to an operation that always appears to be indivisible in the context of signal handlers: either it appears not to have started or it appears to be completed. This doesn’t generally mean that it is undivided, just that we will not be able to observe such a division. The runtime system might have to force that property when a signal handler kicks in.
C has three different classes of types that provide uninterruptible operations:
The first is present on all historical C platforms. Its use to store a signal number as in our example for variable interrupt is fine, but otherwise its guarantees are quite restricted. Only memory-load (evaluation) and store (assignment) operations are known to be uninterruptible; other operations aren’t, and the width may be quite limited.
Objects of type sig_atomic_t should not be used as counters.
This is because a simple ++ operation might effectively be divided in three (load, increment, and store) and because it might easily overflow. The latter could trigger a hardware interrupt, which is really bad if we already are inside a signal handler.
The latter two classes were only introduced by C11 for the prospect of threads (see section 18) and are only present if the feature test macro __STDC_NO_ATOMICS__ has not been defined by the platform and if the header stdatomic.h has been included. The function sh_count uses these features, and we will see an example for this later.
<stdatomic.h>
Because signal handlers for asynchronous signals should not access or change the program state in an uncontrolled way, they cannot call other functions that would do so. Functions that can be used in such a context are called asynchronous signal safe. Generally, it is difficult to know from an interface specification whether a function has this property, and the C standard guarantees it for only a handful of functions:
Unless specified otherwise, C library functions are not asynchronous signal safe.
So by the C standard itself, a signal handler cannot call exit or do any form of IO, but it can use quick_exit and the at_quick_exit handlers to execute some cleanup code.
As already noted, C’s specifications for signal handlers are minimal, and often a specific platform will allow for more. Therefore, portable programming with signals is tedious, and exceptional conditions should generally be dealt with in a cascade, as we have seen in our examples:
Since even the list of signals that the C standard specifies is minimal, dealing with the different possible conditions becomes complicated. The following shows how we can handle a collection of signal numbers that goes beyond those that are specified in the C standard:
7 #define SH_PAIR(X, D) [X] = { .name = #X, .desc = "" D "", } 8 9 /** 10 ** @brief Array that holds names and descriptions of the 11 ** standard C signals 12 ** 13 ** Conditionally, we also add some commonly used signals. 14 **/ 15 sh_pair const sh_pairs[] = { 16 /* Execution errors */ 17 SH_PAIR(SIGFPE, "erroneous arithmetic operation"), 18 SH_PAIR(SIGILL, "invalid instruction"), 19 SH_PAIR(SIGSEGV, "invalid access to storage"), 20 #ifdef SIGBUS 21 SH_PAIR(SIGBUS, "bad address"), 22 #endif 23 /* Job control */ 24 SH_PAIR(SIGABRT, "abnormal termination"), 25 SH_PAIR(SIGINT, "interactive attention signal"), 26 SH_PAIR(SIGTERM, "termination request"), 27 #ifdef SIGKILL 28 SH_PAIR(SIGKILL, "kill signal"), 29 #endif 30 #ifdef SIGQUIT 31 SH_PAIR(SIGQUIT, "keyboard quit"), 32 #endif 33 #ifdef SIGSTOP 34 SH_PAIR(SIGSTOP, "stop process"), 35 #endif 36 #ifdef SIGCONT 37 SH_PAIR(SIGCONT, "continue if stopped"), 38 #endif 39 #ifdef SIGINFO 40 SH_PAIR(SIGINFO, "status information request"), 41 #endif 42 };
where the macro just initializes an object of type sh_pair:
10 /** 11 ** @brief A pair of strings to hold signal information 12 **/ 13 typedef struct sh_pair sh_pair; 14 struct sh_pair { 15 char const* name; 16 char const* desc; 17 };
The use of #ifdef conditionals ensures that signal names that are not standard can be used, and the designated initializer within SH_PAIR allows us to specify them in any order. Then the size of the array can be used to compute the number of known signal numbers for sh_known:
44 size_t const sh_known = (sizeof sh_pairs/sizeof sh_pairs[0]);
If the platform has sufficient support for atomics, this information can also be used to define an array of atomic counters so we can keep track of the number of times a particular signal was raised:
31 #if ATOMIC_LONG_LOCK_FREE > 1 32 /** 33 ** @brief Keep track of the number of calls into a 34 ** signal handler for each possible signal. 35 ** 36 ** Don't use this array directly. 37 ** 38 ** @see sh_count to update this information. 39 ** @see SH_PRINT to use that information. 40 **/ 41 extern _Atomic(unsigned long) sh_counts[]; 42 43 /** 44 ** @brief Use this in your signal handler to keep track of the 45 ** number of calls to the signal @a sig. 46 ** 47 ** @see sh_counted to use that information. 48 **/ 49 inline 50 void sh_count(int sig) { 51 if (sig < sh_known) ++sh_counts[sig]; 52 } 53 54 inline 55 unsigned long sh_counted(int sig){ 56 return (sig < sh_known) ? sh_counts[sig] : 0; 57 }
An object that is specified with _Atomic can be used with the same operators as other objects with the same base type, here the ++ operator. In general, such objects are then guaranteed to avoid race conditions with other threads (discussed shortly), and they are uninterruptible if the type has the lock-free property. The latter here is tested with the feature-test macro ATOMIC_LONG_LOCK_FREE.
The user interfaces here are sh_count and sh_counted. They use the array of counters if available and are otherwise replaced by trivial functions:
59 #else 60 inline 61 void sh_count(int sig) { 62 // empty 63 } 64 65 inline 66 unsigned long sh_counted(int sig){ 67 return 0; 68 } 69 #endif