分割的根本目的是管理误差
将数据分拆为几个组称为分割 。如果为几个分组分别创建预测模型比单独使用一个模型更能减小误差,则应进行分割。
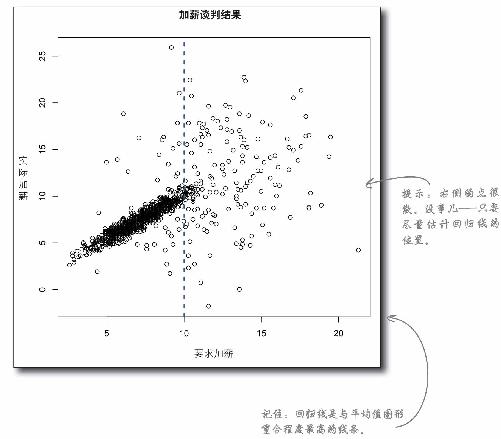
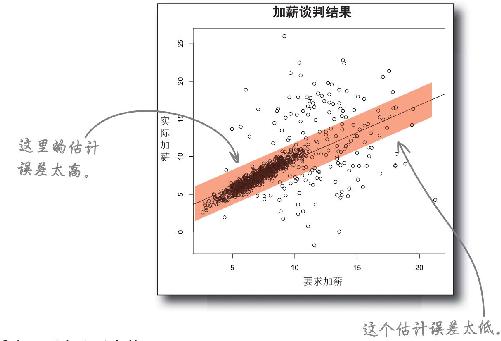
在单独使用一个模型时,要求加薪10%(或以下)的人的估计误差太高 ,而要求加薪10%以上的人的估计误差则太低 !
观察取值区间可以看出,两个分区内的误差迥然不同。实际上,将数据分割为两个分组,并为每个分组建立一个模型,将能对数据分布情况给出更切合实际的解释。
将数据分割为两个分组后,统计结果更敏感,更能体现各个分区内的情况,从而有助于管理误差 。
动动笔
如果把要求加薪10%以下和要求加薪10%以上的人员数据分开,两条回归线很可能具有不同的外观。
这就是分开后的数据。想象一下两组数据的回归线的形状,把它们画出来。
动动笔解答
你已经创建了两条回归线——也就是两个独立的模型!它们外观如何?

考考你
是个好主意。为什么画两条就打住呢?画更多线——多得多,会不会让模型更有作用呢?
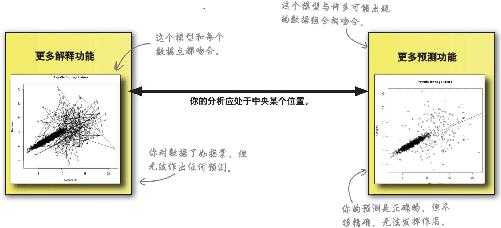
优秀的回归分析兼具解释功能和预测功能
将加薪分析图形分为两个分区既能让分析结果与数据更吻合,又能避免出现有太多解释或太多预测的极端情况,如此一来,你的模型就是有用模型 。
世上没有 傻问题
问: 为什么只把数据分成两组就打住呢?为什么不分成五组?
答: 要是你有很好的理由需要那么做,请动手。
问: 我可以发疯般地把数据分成3000组,让分区正好等于数据点的个数。
答: 当然可以。要是真这么做的话,你认为3000条回归线对于预测人们的加薪幅度有何奇效?
问: 我……
答: 要是真这么做,你可以解释一切。所有的数据点都有来历,所有回归线的均方根误差都为零。可是,这些模型的预测 功能将丧失殆尽。
问: 那么,有一大堆预测功能而没有太多解释功能的分析模型又是一副什么样子?
答: 和你的第一个模型有些像。比如说这样一个模型:不管提出什么加薪要求,都会得到-1000% 到1000% 之间的加薪结果。
问: 听起来真傻。
答: 当然,但这个模型所具有的预测功能不可思议 。很可能你所接待的任何人都不会超出这个范围,但这个模型什么也不能解释 。这样的模型是以解释功能换取预测功能。
问: 所以说零误差似乎就是:没有任何预测能力。
答: 正是!你的分析应该介于具有完全解释功能和具有完全预测功能之间,具体位于这两个极限位置之间的哪个位置取决于你——分析师的最佳判断。你的客户需要什么样的模型?
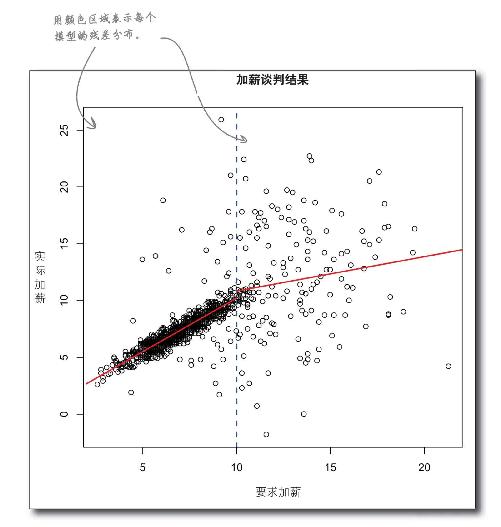
动动笔
分别将这两个模型的均方根误差区域涂上颜色。
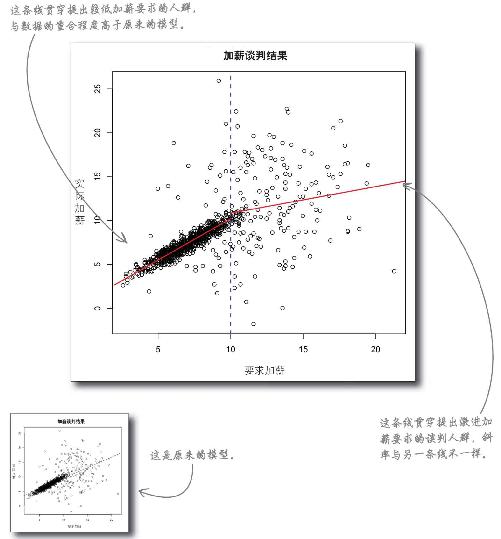
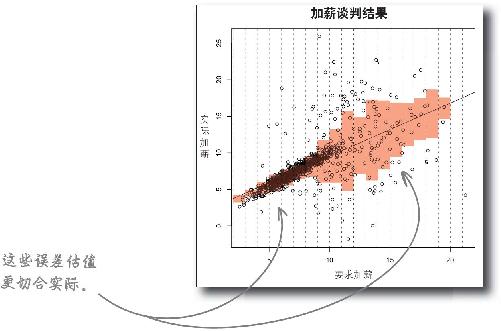
相比原来的模型,分区模型能更好地处理误差
这两个模型更好地描述了人们提出加薪要求后得到的实际加薪,因而功能更强大。
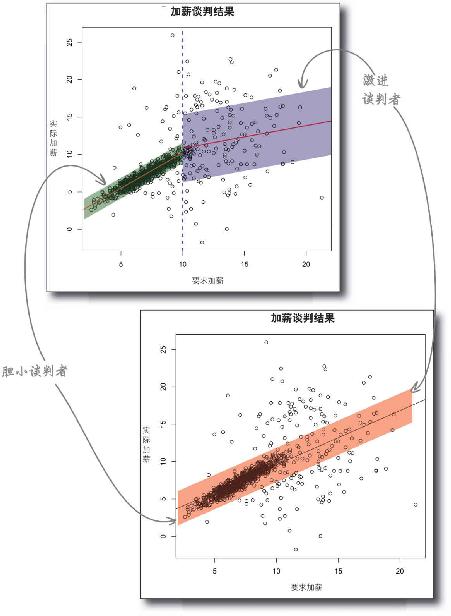
胆小谈判者 的新模型与数据重合得更好。
回归线的斜率更靠谱,均方根误差更低。
激进谈判者 的新模型与数据也重合得更好。
回归线的斜率更靠谱,均方根误差更高,这更好地体现了人们提出高于10%的要求后得到的结果。
让我们在R里实现这些模型……
练习
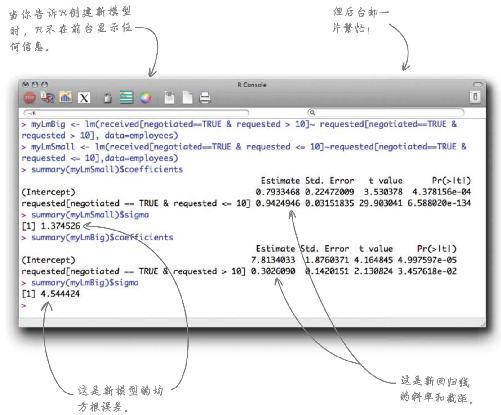
现在是时候在R里实现这些新模型了。只要创建了模型,就能通过系数调整加薪预测算法。
输入下面的指令行,创建与两个分区相对应的新的线性模型对象:
使用下面这些版本的summary()函数查看两个线性模型对象的汇总结果,解释这些指令,说说每条指令完成的工作:
练习解答
你刚才用两个新的回归方程计算了分区数据。发现什么了?
动动笔
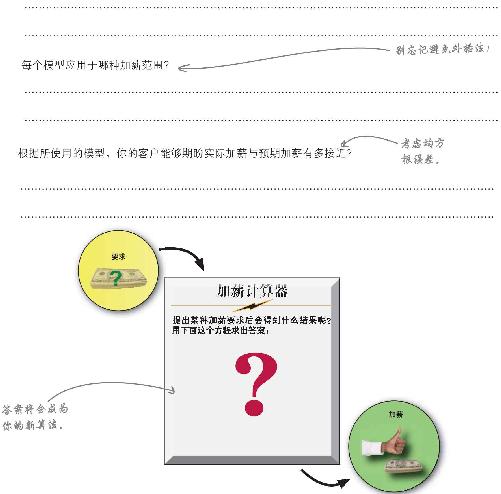
现在,你已经万事俱备,就等创建一个更强大的算法帮助客户了解提出任何加薪要求后所能期待的结果。让我们弃旧迎新,把分析出来的一切信息都用上。
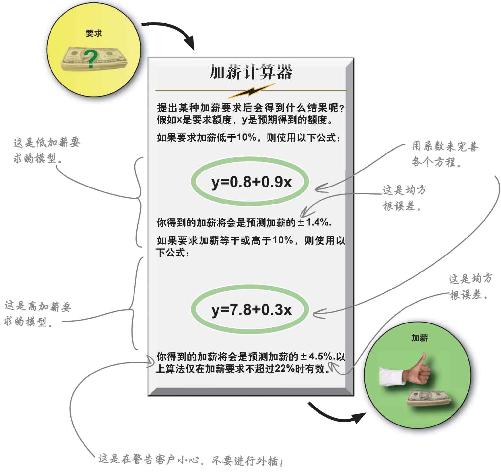
使用新模型的斜率和截距,写出描述这两个新模型的方程式。
动动笔解答
最终的加薪算法是什么样子?
你的客户纷纷回头
新算法确实开始奏效,人人都为此激动不已。

现在,大家可以决定,是要冒着高风险狮子大开口,还是宁可降低要求,图个安稳。
求安稳的人心想事成,而不惧风险的人也能理解他们为什么会有这种结果。
12 关系数据库
你能关联吗?

如何组织变化多端的多变量数据?
一张电子数据表只有两维数据:行和列。如果你的数据包括许多方面,则表格格式 很快就会过时。在本章,你会看出电子表格很难管理多变量数据,还能看到关系数据库 管理系统让多变量数据的存储和检索变得极其简单。
《数据邦新闻》希望分析销量
《数据邦新闻》是时下盛行的一份新闻类杂志,许多居民都看这份杂志。《数据邦新闻》给你出了一个非常特别的题目:他们想把每期杂志的文章数目与销量关联起来,然后找出在每一期刊物上刊登文章的最优数量。
他们希望每一期杂志都能尽量经济有效,要是每一期杂志刊登一百篇文章比刊登五十篇文章带来的销量并无提高,那他们就不刊登这么多;另一方面,要是刊登五十篇文章比刊登十篇文章能带来更大 销量,那他们就会刊登五十篇文章。

要是你能给他们全面分析这些变量,他们将免费 为你的数据分析业务做一年的广告 。
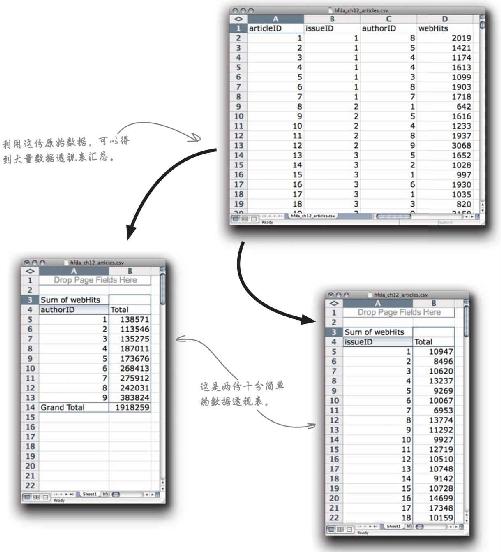
这是他们保存的运营跟踪数据
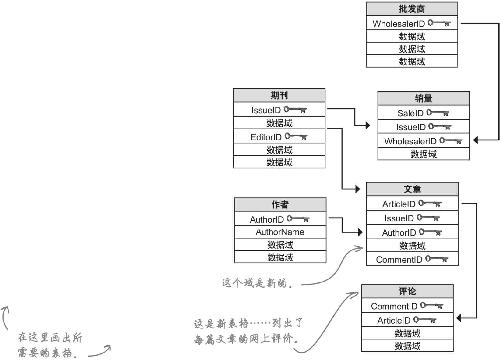
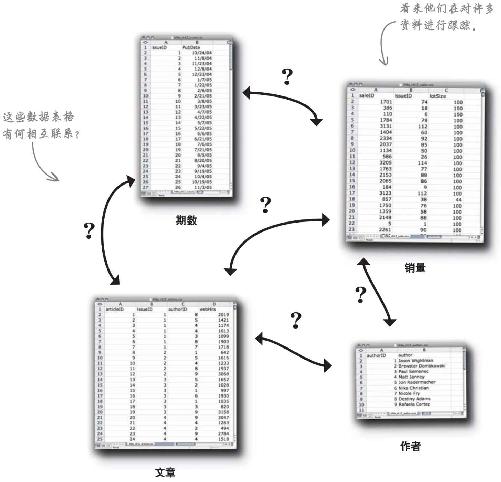
《新闻》给你送来了他们的经营数据,是四张独立的电子表格文件。这些文件相互之间有一定 联系,为了进行分析,你需要弄清楚具体有哪些联系。
动动脑
为了对比文章和销量的关系,需要知道些什么?
你需要知道数据表之间的相互关系
为了得到《新闻》想得到的答案,你创建表格,据此将文章数目 和销量 联系起来。
因此你需要知道这些表格如何相互关联。是哪些特定数据域将这些表格联系起来的?另外,这些关系有何意义 ?

动动笔
用箭头和文字说明每张数据表中记录的数据之间的关系。
动动笔解答
你发现《数据邦新闻》保存的数据表之间有何关系?
数据库就是一系列相互有特定关系的数据
一个数据库 就是一张表格或一组表格,表格以某种方式对数据进行管理,使数据之间的相互关系显而易见;数据库软件则对表格进行管理。可供选择的数据库软件很多。
重要的是要了解附件中要记录的那些数据之间的关系。

找到一条贯穿各种关系的路线,以便进行必要的比较
如果手头有一些相互独立的表格,但这些表格中的数据互有关系,同时又有一个关系到多张表格的问题需要解答,那么,就需要沿着相互关联的表格顺藤摸瓜。
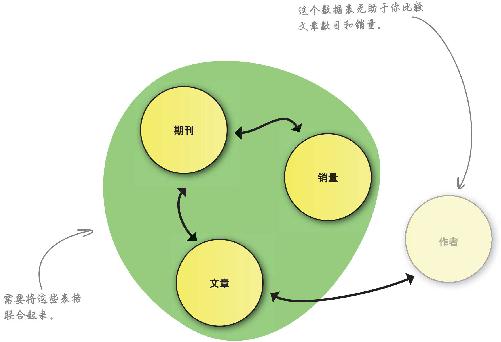
创建一份穿过这条路径的电子表格
一旦知道自己需要哪几个表格,就可以制定一个计划,将数据与公式关联起来。
在本例中,你需要有一份能对每期文章数目和销量进行比较的表格。你将需要写出公式,以便计算需要计算的数值。
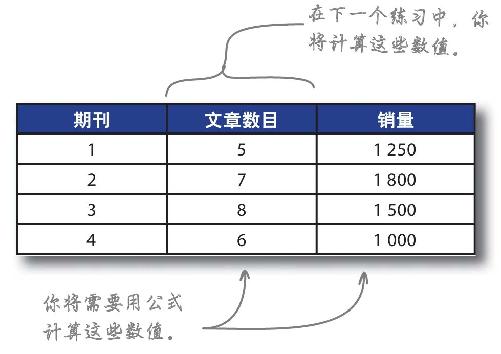
练习
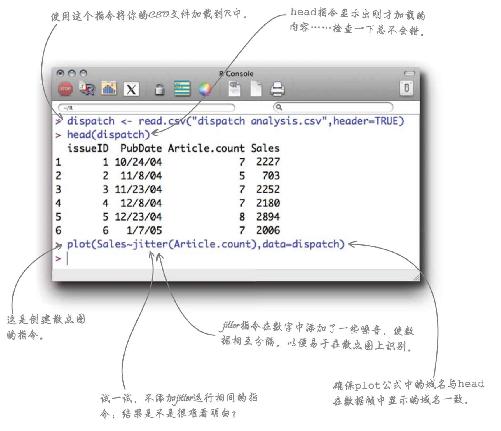
让我们创建一个电子表格,像对开页上的一样,然后首先计算每一期《新闻》的“文章数目”。
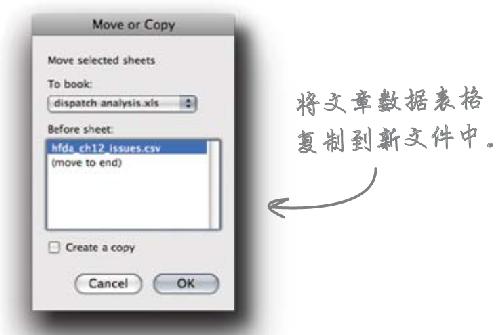
1 打开“hfda_ch12_issues.csv ”文件,保存一份副本,以便工作。记住,可别把原始文件搞乱了!将新文件取名为“dispatch analysis.xls”。
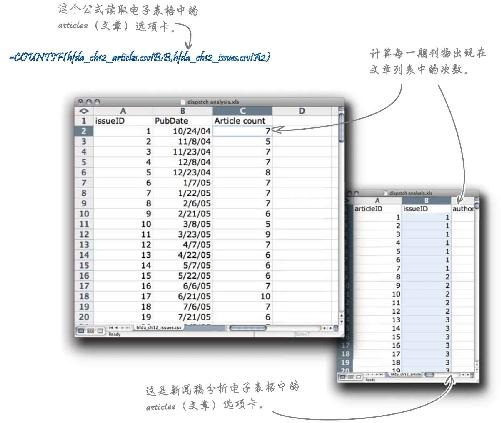
2 打开“hfda_ch12_articles.csv ”,右击表格底部带有文件名的选项卡。命令电子表格程序将文件转移到“dispatch analysis.xls ”文档中。
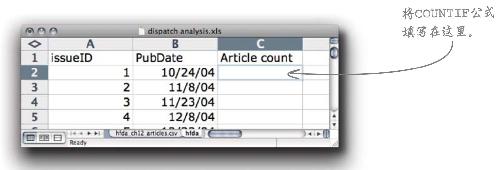
3 在期刊数据表中创建文章数目列,填入COUNTIF公式计算该期刊的文章数目;然后对每一期刊物复制和粘贴该公式。
练习解答
你发现每一期刊物的文章数目情况如何?
1 打开“hfda_ch12_issues.csv ”文件,保存一份副本,以便工作。记住,可别把原始文件搞乱了!将新文件取名为“dispatch analysis.xls”。
2 打开“hfda_ch12_articles.csv ”,右击表格底部带有文件名的选项卡。命令电子表格程序将文件转移到“dispatch analysis.xls ”文档中。
3 在期刊数据表中创建article count(文章数目)列,填入“COUNTIF”公式计算该期刊的文章数目;然后对每一期刊物复制和粘贴该公式。

听上去不错……让我们将销量添加到列表中!
练习
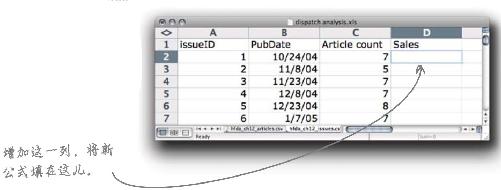
在所创建的电子表格中添加一个总销量域。
1 复制hfda_ch12_sales.csv 文件,使其成为dispatch analysis.xls 中的一个新选项卡。在用于计算文章数目的同一个工作表中,新建一个Sales(销量)列。
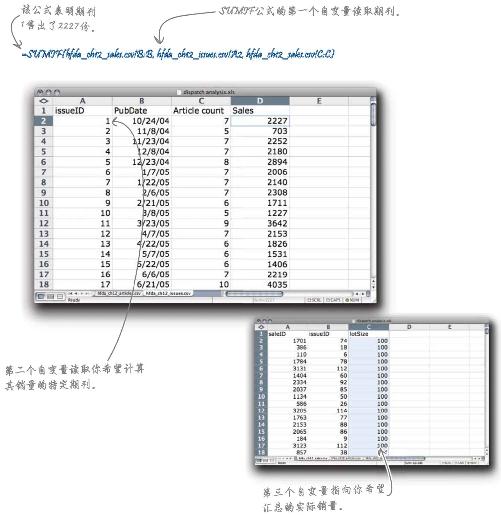
2 使用SUMIF公式计算期刊ID1(issueID 1)的销量数据,将公式填写在单元格C2中。复制该公式,为其余每一期刊物粘贴该公式。
练习解答
你用了哪个公式将销量添加到电子表格中?
通过汇总将文章数目和销量关联起来
这就是你需要的电子表格——可以表明《新闻》每一期刊登的文章数目与期刊销量之间的关系。

当然!让我们给他来一张……
动动笔
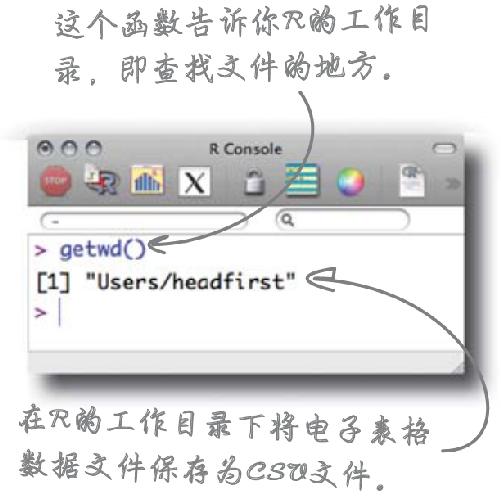
1 打开R,输入getwd()指令,求出R保存数据的位置。然后,在电子表格中找到“File > Save As...”(“文件 > 另存为……”),在该目录下将该数据保存为CSV文件。
执行下列指令,将数据加载到R中:
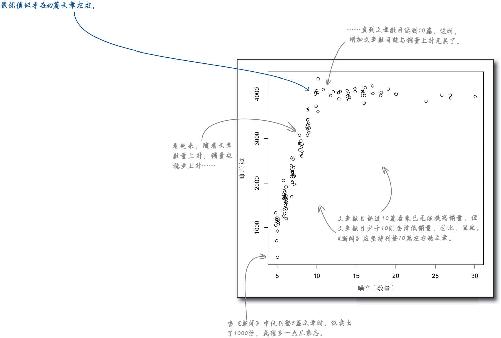
2 加载数据后,执行下列函数,看到一个优化值了吗?
动动笔解答
你在所加载的数据中找到最优值了吗?
看来你的散点图确实画得很好

世上没有 傻问题
问: 人们确实会像这样把数据存储在相互关联的电子表格中吗?
答: 确实如此。有时候你的数据是从更大的数据库中节选的,有时则是人们像上文那样手工关联在一起的。
问: 基本上,只要公式能够读取代码,就有可能通过电子表格把各种数据联系起来,只是繁琐一点。
答: 嗯,不是每次都那么幸运——能够从多个数据表中得到数据,并且这些数据通过精巧的程序代码相互关联。通常得到的数据比较混乱,为了让电子表格和公式同时生效,需要做一些数据清理工作。下一章将更详细地介绍这方面的内容。
问: 有没有能把来自不同表格的数据关联在一起的更好的软件构造?
答: 你认为有,对吗?
复制并粘贴所有这些数据是件痛苦的事
每次有人查询 数据(即提出关于数据的问题)时都要做一遍这个过程也太烦人了。
而且,不是说计算机可以完成所有这些麻烦事吗?

用关系数据库管理关系
关系数据库管理系统 (RDBMS)是最重要最有效的数据管理方法之一。关系数据库是一个大课题,你对它了解越深,就越能发挥存储在其中的数据的作用。
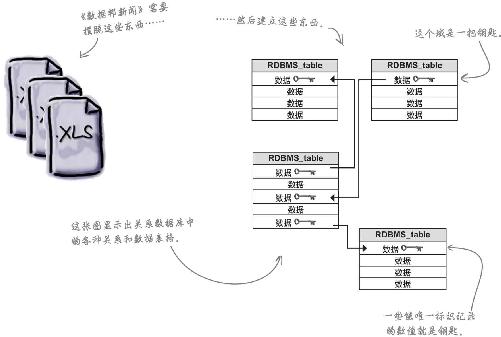
重要的是,要知道,数据库所要求的表格之间的关系都是量化 关系,数据库并不介意期刊如何,作者如何,它只知道一份期刊有多位作者。
RDBMS中的每一行都有一把钥匙,通常称为ID(标识) ,钥匙可以确保这些量化关系不被破坏,一旦建立了RDBMS,请注意:精心构造的关系数据就会成为数据分析的宝库。
如果《数据邦新闻》有一个数据库,要完成上文进行过的分析就容易得多。
《数据邦新闻》利用你的关系图建立了一个RDBMS
现在《新闻》可以将所有的电子表格载入一个真正的RDBMS中了。你的思维成果,加上总编对数据的解释——也就是数据库结构,形成了下面这个关系数据库。

动动笔
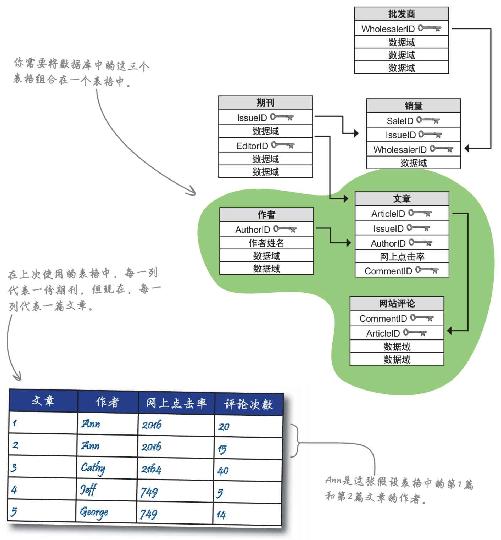
下面是《数据邦新闻》数据库的架构,圈出你需要的表格,将这些表格放到同一张表格中,看看哪一位作者的网站点击率和网站评论最多。
然后在下面画出这个表格,表格中显示用于画散点图的几个域。
动动笔解答
为了计算某个作者在网上的点击率和评价情况,以便以此评估作者的受欢迎程度,你需要把哪几个表格组合在一起?
《数据邦新闻》用SQL提取数据
SQL是Structured Query Language的缩写,即结构化查询语言,是一种关系数据库检索方法。你可以通过输入代码或使用能创建SQL代码的图形界面,令数据库回答你的SQL问题。
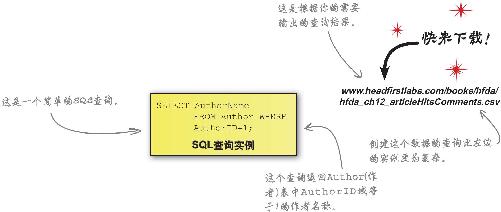
你并不是非懂SQL不可,但懂得SQL绝不是坏事。重要的是,了解数据库中的各个表格 及这些表格的相互关系,进而懂得如何提出正确的问题 。
练习
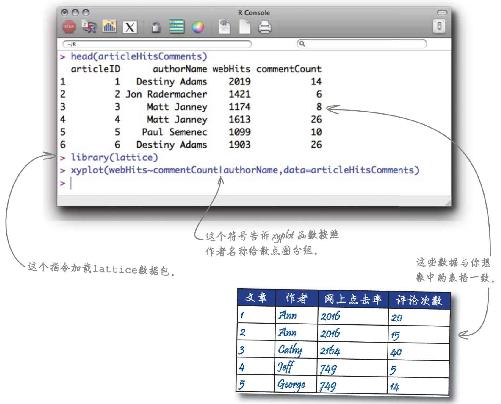
1 使用下面的指令将hfda_ch12_articleHitsComments.csv 电子表格加载到R中,然后用head指令查看数据:
2 这次我们将用更有效的函数创建散点图。用下面这些指令加载lattice数据包,然后运行xyplot公式,绘制lattice散点图。
3 根据这种计算方法,哪些作者表现最好?
练习解答
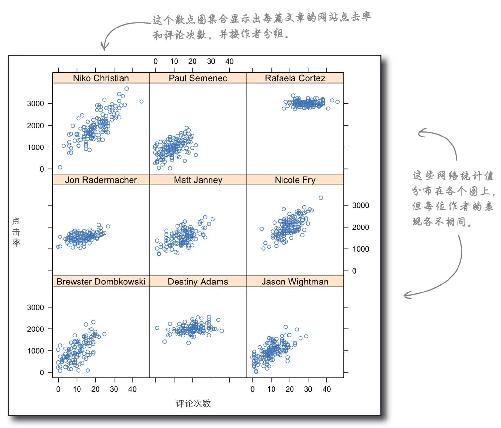
从散点图上看出什么了?是不是某些作者能带来更大销量?
1 将hfda_ch12_articleHitsComments.csv 电子表格载入R。
2 这次我们将用更有效的函数创建散点图。用下面这些指令加载“lattice”数据包,然后运行xyplot公式,绘制lattice散点图。
library(lattice)
xyplot(webHits~commentCount|authorName,data=articleHitsComments)
3 根据这种计算方法,哪些作者表现最好?
很明显,Rafaela Cortez的表现最好,她所有的文章点击率都在3000以上,且大部分文章都有20多篇评论,看来人们真的很喜欢她。其他作者的表现有好有坏,Destiny和Nicole表现较好,Niko的表现数据很散,而Brewster和Jason则显得不太受欢迎。

RDBMS数据可以进行无穷无尽的比较
你刚才根据《新闻》的RDMS数据画出的复杂图形不过是冰山一角,各家公司的数据库会很庞大,绝无虚言。作为分析师,关系数据库意味着你可以进行巨量 比较。
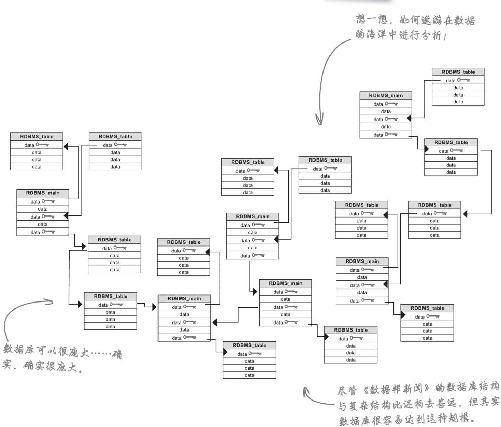
RDBMS能按照你的心思把数据关联在一起进行有效的比较,关系数据库让分析师美梦成真。
你上了封面
你的工作让《数据邦新闻》的作者和编辑们惊奇不已,他们决定把你放在要闻版!干得漂亮。猜猜看,写文章的会是谁?

13 整理数据
井然有序

乱糟糟的数据毫无用处。
许多数据搜集者需要花大量时间整理 数据。不整齐的数据无法进行分割、无法套用公式,甚至无法阅读,被人们视而不见也是常事,对不对?其实,你可以做得更好。只要眼前清楚地浮现 出希望看到的数据外观,再用上一些文本处理工具,就能抽丝剥茧 地整理数据,化腐朽为神奇。
刚从停业的竞争对手那儿搞到一份客户名单
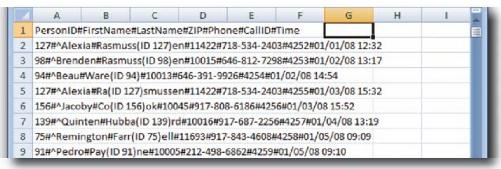
Head First猎头公司是你的最新主顾,该公司从一家停业的竞争对手那儿搞到了一份求职人员名单 。为了得到这份名单他们花了大把钞票,不过这非常值得。这份名单上的人都是人中龙凤,是最炙手可热的人才。
这份名单会是一个金矿……
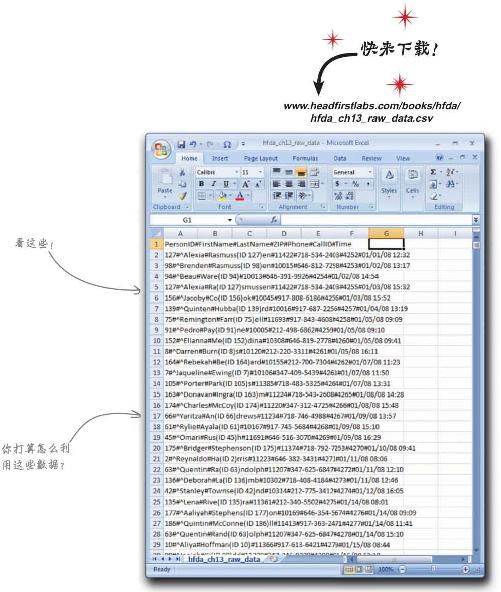
太糟糕了,数据乱糟糟 的!现在这副样子客户没法用,这正是他们找你的原因。你能帮上忙吗?
数据分析不可告人的秘密
数据分析有一个不可告人的秘密——作为数据分析师,你花在数据整理 上的时间多过数据分析 上的时间。到手的数据往往算不上井井有条,因此,需要做一些繁重的文字处理工作,使数据格式符合分析的需要。
动动笔
该怎么从头开始 处理这些乱哄哄的数据呢?看看下面几种可能的办法,写出每种办法的优缺点。
1 开始重新输入。
2 问问客户整理数据的目的。
3 写出一个公式,整理数据。
动动笔解答
你选择第一步做什么?
1 开始重新输入
糟透了。这很费时间,而且誊写时很容易出错,如果这是修复数据的唯一办法,在走这条路之前最好想清楚。
2 问问客户整理数据的目的。
就该这么做。知道客户对数据的意图后,就必定能把数据整理成他们需要的格式。
3 写出一个公式,打造数据。
一旦我们了解客户对数据格式的要求,使用一两个公式来整理肯定有帮助。但让我们先问问客户。
Head First猎头公司想为自己的销售团队搞到这份名单

虽然原始数据乱七八糟,不过,看来他们只想抽取姓名和电话号码。这问题倒不大,让我们动手……
动动笔
下面的数据似乎是一串名单,按照客户的描述,我们需要的正是它,你需要做的是清晰地排列这份名单。
按照希望看到的数据格式,画一张图,显示数据列和数据样例。
动动笔解答
你希望整理好后的数据是什么样子?

凭想象无法让数据井井有条,此话不假。不过,要摆弄混乱的数据,先得想象一个解决方案。让我们看一看修复混乱数据的常规策略 ,然后开始 ……
清理混乱数据的根本在于准备
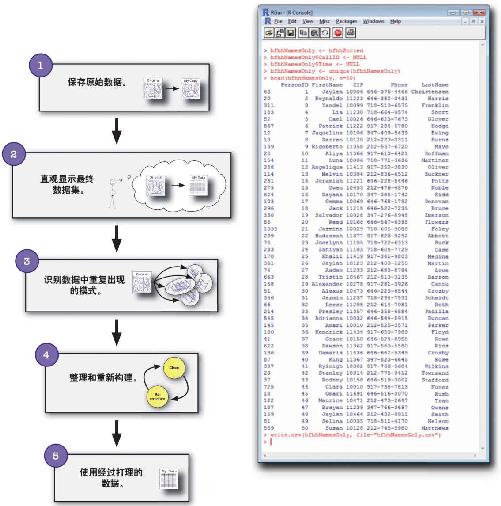
这是不言而喻的,不过,和做其他数据工作一样,整理数据必须首先从复制原始数据开始,这样才方便回头检查。
一旦你确定了你自己想要得到的数据外观,就可以继续从混乱中分辨出数据模式。
最后要做到的是回头逐行修改数据——这可要大费周折,所以要是能够识别重复出现的混乱符号,就能写出公式和函数,然后利用各种模式整理数据。
一旦组织好数据,就能修复数据
然后就可以利用手头的数据模式开始认真修复数据。你会发现,这个过程常常会反复 发生,即,要一次又一次地重新构造和整理数据,直到得到所需要的结果。
动动笔
首先,让我们拆分数据域。有模式可用于拆分各个域吗?
动动笔解答
在数据中发现了哪些模式?
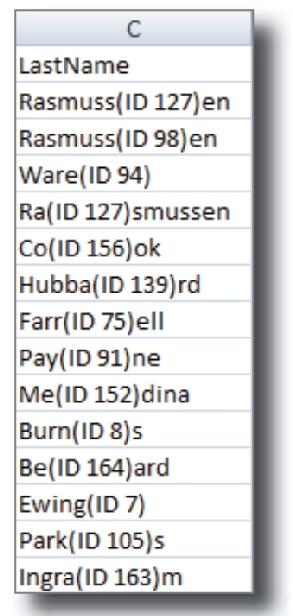
当然!所有的数据域都挤在A列中。每个域之间有一个字符:#。
将#号作为分隔符
Excel有一个称手的工具,当各个数据域以某个分隔符 (即,将域与域隔开的字符)分隔时,这个工具可以将数据拆分为几个列。选择A列数据,按下Data(数据)选项卡下的“Text to Columns”(文本转变为列)按钮……
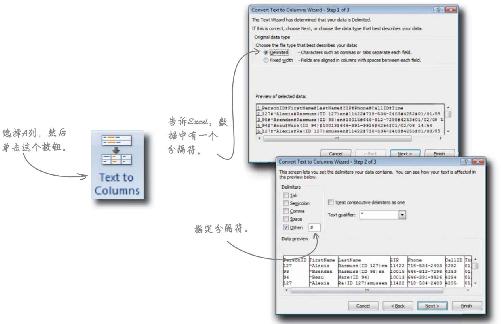
……现在,向导已经启动。第一步先告诉Excel数据以分隔符分开;第二步告诉Excel分隔符即#字符。单击“Finish”(完成)后结果如何呢?
Excel通过分隔符将数据分成多个列
小事一桩。只要各个数据域之间有分隔符隔开,使用Excel的Convert Text to Column Wizard(文本转变为列向导)会非常方便。
不过这些数据仍然有问题。例如,姓和名的域中都有一些多余的符号,必须想个办法除掉这些多余的符号!
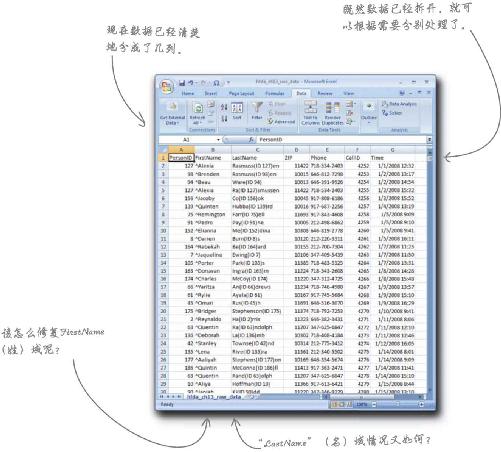
动动笔
你会使用什么模式来修复FirstName列?
动动笔解答
FirstName域中是否有某个造成混乱的模式?
每个名字的开头位置都有一个“^”字符。我们需要弄掉这些符号,得到纯粹的姓。
让我们看看Excel给我们准备了什么……
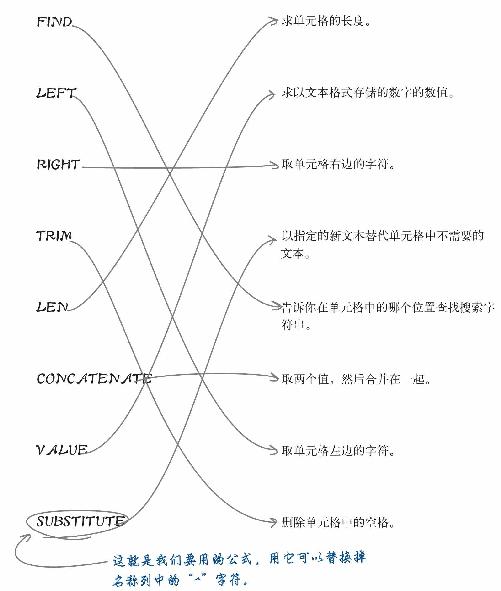
连 连 看
将Excel公式与功能搭配起来。你觉得可以用哪种功能整理名字列?
| FIND | 求单元格的长度。 |
| LEFT | 求以文本格式存储的数字的数值。 |
| RIGHT | 取单元格右边的字符。 |
| TRIM | 以指定的新文本替代单元格中不需要的文本。 |
| LEN | 告诉你在单元格中的哪个位置查找搜索字符串。 |
| CONCATENATE | 取两个值,然后合并在一起。 |
| VALUE | 取单元格左边的字符。 |
| SUBSTITUTE | 删除单元格中的空格。 |
连连看解答
将Excel公式与功能搭配起来。你觉得可以用哪种功能整理名字列?
用SUBSTITUTE替换“^”字符
1 在单元格H2中输入下面公式可修复FirstName域:=SUBSTITUTE(B2,“^”,“”)
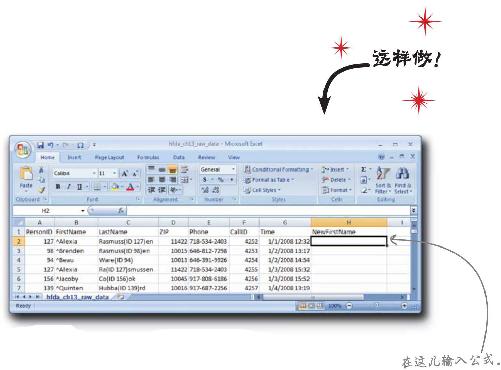
2 复制这个公式,在H列中从头到尾粘贴这个公式。结果如何?
世上没有 傻问题
问: 只有这些公式可用吗?要是我想取出单元格左右两边的字符拼接在一起,该怎么做?似乎没有这种公式。
答: 是没有,不过你可以将文本函数嵌套起来用,这样就能完成更复杂的文本处理。例如,如果想取出单元格“A1”中的第一个和最后一个字符拼接在一起,可以使用下面这个公式:
CONCATENATE(LEFT(A1,1),
RIGHT(A1,1))
问: 这么说我可以把一大堆文本公式嵌套在一起?
答: 可以,这对于处理文本很有效。不过有一个问题:要是数据实在太乱,再把一大堆公式嵌套在一起,整个公式就几乎没法辨认了。
问: 管它呢,只要有效就行,我没打算辨认。
答: 呵,公式越复杂,就越需要小心调整;公式越难辨认,就越难以调整。
问: 那该怎么回避繁复而难以辨认的公式呢?
答: 不要把较小的公式合并成一个大公式,而是把小公式拆成几个不同的单元格,再用一个最终的公式将所有单元格合并起来。通过这种方法,假如有哪里不对,就很容易找出需要调整的公式。
问: 我打赌“R”有更好的文本处理办法。
答: 有是有,不过干嘛要费事去学呢?要是Excel的SUBSTITUTE公式能够完成任务,就省省时间吧,别管R 怎么做了。
所有的“姓”都整理好了
利用Excel的SUBSTITUTE选取每个“姓”中的“^”符号,代之以通过两个引号(“”)指定的空内容。
其他许多软件都是通过以空内容替换冗余字符来实现删除冗余字符。


练习
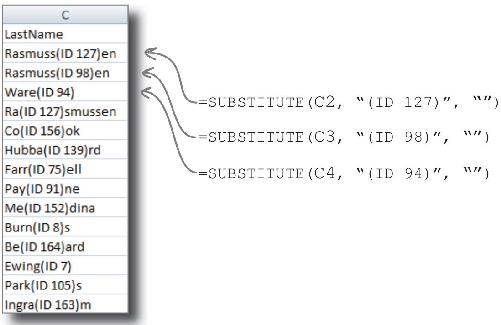
让我们再用用SUBSTITUTE,这次要修复的是“名”。
首先从一片混乱中找出数据模式。你想让SUBSTITUTE替换什么?句法结构如下:
=SUBSTITUTE(参考单元格,被替换的文本,用于替换的文本 )
你能写出一个有效的公式吗?
动动笔解答
能用SUBSTITUTE修复LastName域吗?
SUBSTITUTE对此无效!每个单元格的乱码都不一样,要想让SUBSTITUTE生效,就得为每一个“名”写一个公式。
这就失去了使用公式的意义——使用公式不就是为了摆脱输入输入再输入的麻烦吗!
用SUBSTITUTE替换名字模式太麻烦了
SUBSTITUTE函数的功能是找到某种格式的文本字符串并替换,“名”的问题是每个名称都各不相同 ,难以替换。
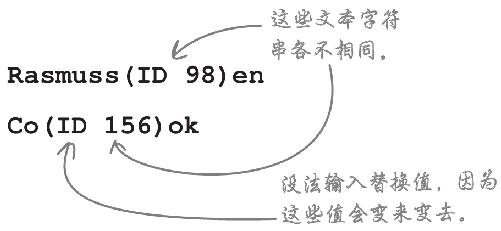
不仅如此,LastName域的复杂模式还在于:不统一的字符串出现在各个单元格的不同位置 上,长度也不一样 。
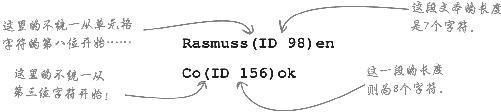
用嵌套文本公式处理复杂的模式
熟悉了Excel的文本公式之后,就可以嵌套 使用,以便处理混乱的数据。实例如下:
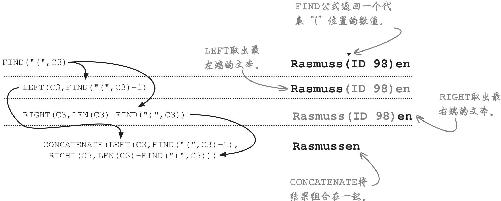
公式行得通 ,但有一个问题 :公式开始变得晦涩难懂。要是能一次性把公式写全,这倒也算不得问题,不过,能有一个既简单又 有效的工具会更好,但CONCATENATE没有做到这一点。

R能用正则表达式处理复杂的数据模式
正则表达式 是一种编程工具,你可以用这个工具指定复杂的模式以便匹配和替换文本字符串,R在这方面非常好用。
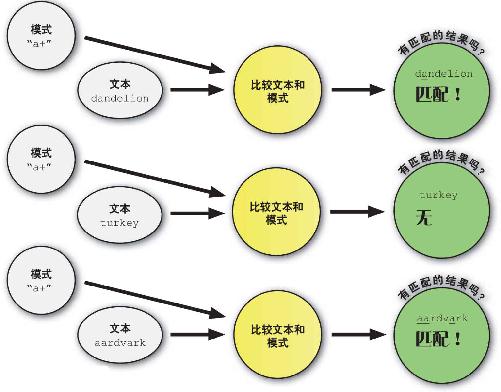
下面是一个用于查找字母“a”的简单的正则表达式模式。在R中输入这个模式 ,R将指出是否存在匹配结果。
技巧
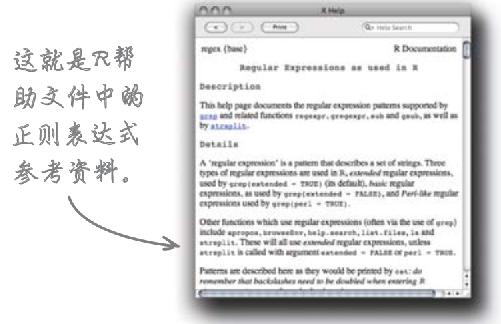
为了进一步了解 正则表达式的完整规定和语法,让我们在R中输入“?regex”。
正则表达式是整理混乱数据的杀手锏,大量平台和编程语言都使用正则表达式——虽说Excel并不使用。
发件人:Head First猎头公司
收件人:分析师
主题:现在就要名单
好好干!这些人很热门,不过已经开始遇冷。
我希望营销团队不要错过打电话的时机!
最好行动起来!方案:
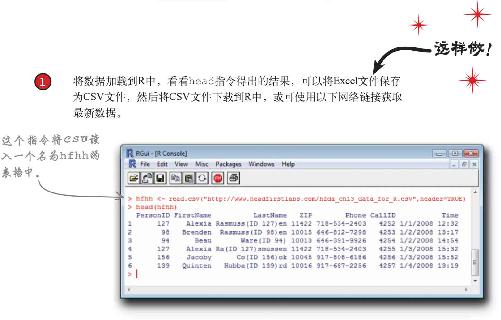
2 运行以下正则表达式指令
NewLastName <- sub(“\\(.*\\)”,””,hfhh$LastName)
3 然后检查一下工作成果:运行head指令,查看表格前几行。
head(NewLastName)
结果如何?
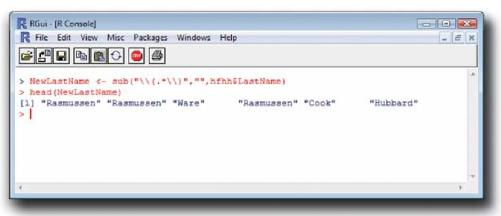
用sub指令整理“名”
sub指令用空格替换所发现的所有指定模式 ,有效地删除了LastName列中的每一个插入文本字符串。
让我们看看语法:

只要能在混乱数据中找到一个模式,就能写出并利用正则表达式得到自己想要的数据结构。
再不必编写长得让人发疯的电子表格公式了!
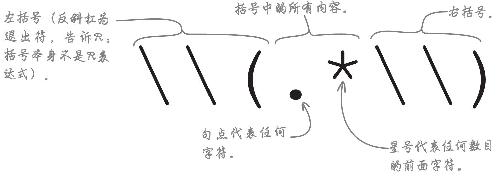
正则表达式细节
正则表达式包括三个部分:左括号、右括号、括号里面的所有内容。
世上没有 傻问题
问: 某些正则表达式似乎的确难以看懂,掌握正则表达式有多难?
答: 正则表达式难懂的原因是它们非常精炼。在语法上精打细算非常有利于处理错综复杂的模式。和其他复杂事物一样,正则表达式易学难精。多花点时间研究正则表达式吧,你会弄明白的。
问: 要是没有电子数据表怎么办?我的数据可能取自PDF、网页或甚至是XML。
答: 这才是正则表达式的用武之地。只要能把信息转变成某种文本文件,就能用正则表达式解析。网页尤其是数据分析工作中常见、地道的信息来源,把HTML 标记模式编制成正则表达式不过是小菜一碟。
问: 其他还有哪些特定平台使用正则表达式?
答: Java 、Perl 、Python、Java-Script …各种各样的编程语言都使用正则表达式。
问: 既然正则表达式在编程语言中广泛使用,为什么Excel不能执行正则表达式?
答: 在Windows 平台上,你可以用Excel自带的VBA编程语言执行正则表达式。但大部分人很快就会不再费心学习Excel编程,而是改用功能更强大的程序,比如R 。哦,由于最新发布的Excel for Mac去掉了VBA,所以,无论如何都不能在Excel for Mac 中使用正则表达式了。
现在可以向客户交货了
最好把最新工作成果写成CSV文件供客户使用。
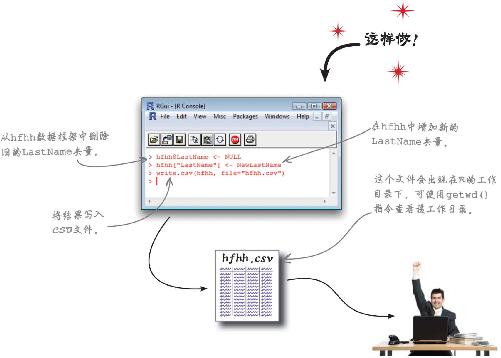
不管客户用的是Excel、OpenOffice还是其他统计软件,都能读取CSV文件。
可能尚未大功告成……
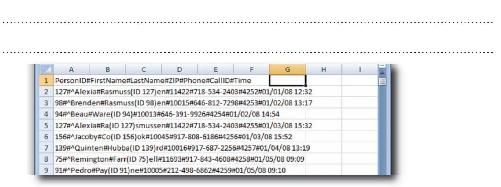
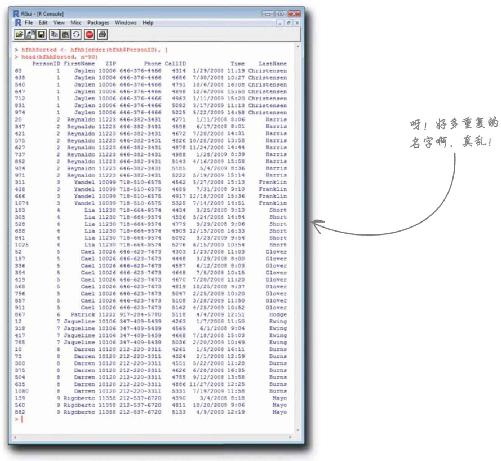
客户对你的工作成果颇有微辞。

他说得对。以Alexia Rasmussen为例:Alexia确实出现了一次以上。当然,可能有两位同名同姓的Alexia Rasmussen,可是,再仔细一看呢,两条记录的“PersonID”都等于“127”,这就表示是同一个人。
有可能Alexia是唯一重复出现的名字 ,而客户正巧看到了这个错误。为了查清究竟,你需要想个办法让自己更轻松地找出重复现象,而不用费力查看这张长长的名单。
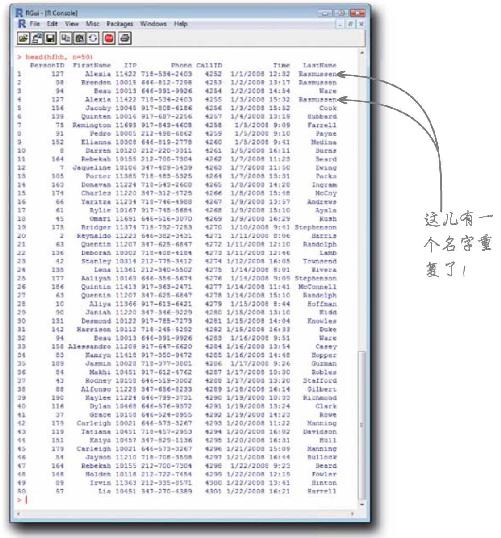
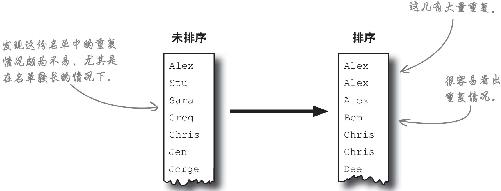
为数据排序,让重复数值集中出现
如果数据量很大,则发现 重复数值颇为不易,给名单排个序的话就容易多了。
练习
让我们通过排序更仔细地看看名单中的重复情况。
在R中,通过子集括号中的order函数可以对数据框架排序。执行下列指令:
由于PersonID域有可能是代表每一个人的特定编号,用它排序再好不过。毕竟,这些数据中可能不止一个叫做“John Smith”的人。
下面,执行head指令看看生成的结果:
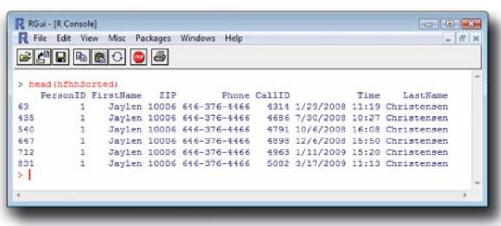
head(hfhhSorted, n=50)
R做了什么?
练习解答
用R按照PersonID对数据框架排序后,发现有重复数据吗?
若手头数据非常混乱,就应该大胆地排序 ,尤其是在记录量很大的情况下,要一次性看清所有的数据往往很难,而按照不同的域对数据进行排序则能够以直观的方式为数据分组,从而发现重复现象或其他疑义。

动动笔
仔细看看这些数据。能说说为什么名字会重复吗?
动动笔解答
你认为相同的名字为什么会重复出现?
要是你看一下最右边的列,就能发现每个数据记录都有一个独特的数据点:某个电话号码的时间标记。这可能意味着,这个数据库中的每一行都代表一个电话号码,由于某些人有好几个电话号码,于是就出现了名字重复的现象。
这些数据有可能来源于某个关系数据库
如果你所拥有的混乱的数据列表中出现重复元素,则这些数据有可能来自一个关系数据库。在本例中,你使用的数据是某个查询的输出结果,且被输出成两个表格。
由于你了解RDBMS架构,你知道,我们之所以看到这些重复现象,是因为查询返回数据的方式 ,而不是因为数据质量低劣 。所以,你现在可以放心地删除这些重复的名称,而不必担心数据中存在本质错误。
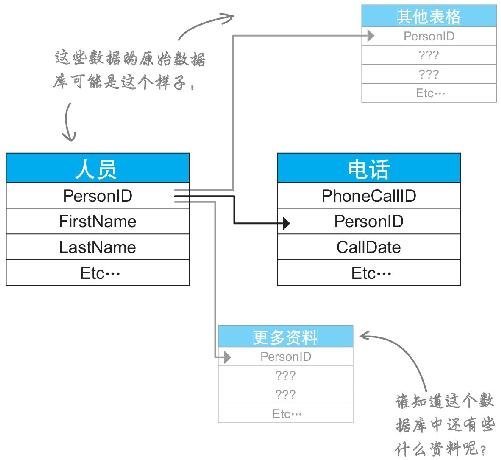
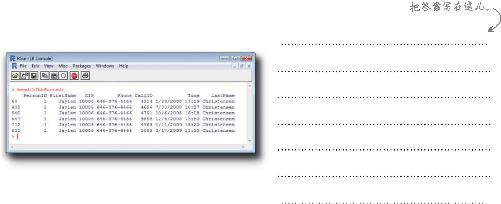
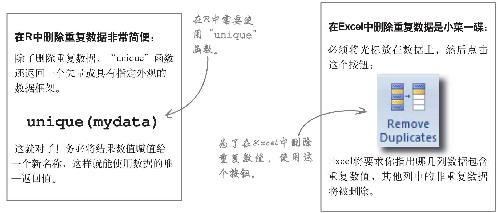
删除重复名字
既然已经知道名字出现重复的原因,就可以开始删除 了。R和Excel都有用于删除重复数据的快捷、简便的函数。
既然你已经有了除去这些烦人的重复名字的工具,就让我们整理名单,然后交给客户吧。
2 删除CallID和Time域,这些域使名字出现重复,而客户并不需要这些域:
hfhhNamesOnly$CallID<-NULL
hfhhNamesOnly$Time<-NULL
3 使用unique函数删除重复的名称:

4 看一看结果,将结果写入一个新的CSV文件:
head(hfhhNamesOnly, n=50)
write.csv(hfhhNamesOnly, file=“hfhhNamesOnly.csv”)
你创建了美观、整洁、具有唯一性的记录
这些数据看起来无懈可击:没有挤在一起的数据列,没有混乱的字符,没有重复现象。这都是按照下列整理混乱数据的基本步骤进行操作的结果:
Head First猎头公司正在一网打尽各种人才!
事实证明,你整理的数据集收效奇特。凭借这份活色生香的名单,Head First猎头公司客户盈门,没有你的数据整理技术,他们决不可能走到这一步。干得漂亮!

再见……

数据邦感谢您的光临!
离别让人黯然神伤。 不过,看到你学以致用,这是我们再高兴不过的事。你的分析师人生刚刚开始,我们已经扶你上马。我们渴望知道你的消息,所以,来Head First图书馆网页上(www.headfirstlabs.com )给我们写几句 吧,让我们知道数据分析为你 做出的贡献!
附录A:尾声
正文未及的十大要诀

你已颇有收获。
但数据分析这门技术不断变迁,学之不尽。由于本书篇幅有限,尚有一些密切相关的知识未予介绍,我们将在本附录中浏览十大知识点。
其一:统计知识大全
统计学领域拥有大量数据分析工具和技术 ,对数据分析极其重要,乃至许多“数据分析”著作其实就是统计学著作。
下面列出本书未提及的统计工具。
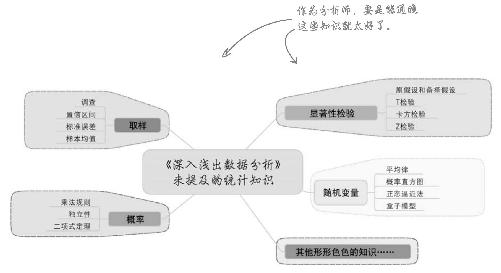
不过,通过本书,你在假设和建模意识方面获得了 长足进步,不仅为使用各种统计工具做好了准备,也了解到了各种统计工具的局限性 。
统计知识越渊博,分析工作越有可能取得辉煌成就。
其二:Excel技巧
本书假定你掌握了基本的电子表格技术,但娴熟的数据分析师应该是一个电子表格忍者 。
与R及回归等概念相比,掌握Excel并不是特别难。你行的!

其三:耶鲁大学教授Edward Tufte (爱德华·塔夫特)的图形原则
优秀的数据分析师会花大量的时间反复拜读数据分析大师的杰作,Edward Tufte不仅在自己的工作上独树一帜,而且对搜集并选入自己著作的其他分析师的作品质量也有独特的看法。下面是他提出的关于分析设计的基本原则:
“体现出比较、对比、差异。”
“体现出因果关系、机制、理由、系统结构。”
“体现出多元数据,即体现出1个或2个变量。”
“将文字、数字、图片、图形全面结合起来。”
“充分描述证据。”
“数据分析报告的成败在于报告内容的质量、相关性和整体性。”
—Edward Tufte
这些引言出自其著作《出色的证据》(Beautiful Evidence )之127、128、130、131、133、136页。其著作可谓数据图形化顶级作品展馆。
另外,其著作《公共政策数据分析》(Data Analysis for Public Policy )可谓回归技术宝典,可在此网址免费下载:http://www.edwardtufte.com/tufte/dapp/ .
其四:数据透视表
数据透视表是电子表格和数据分析软件中极其有效的数据分析工具,是探索性数据分析 和相关数据库 数据汇总的梦幻之作。
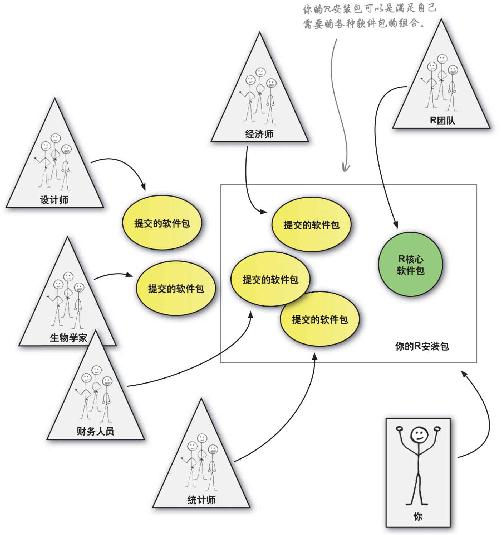
其五:R社区
R不只是一个出色的软件程序,它还是一个出色的软件平台 。其威力来源于全球用户和作者社区,这些用户和作者向社区提交免费软件包 ,其他人则可借助这些成果进行数据分析。
通过运行神奇的数据图形化数据包——lattice 中的“xyplot”函数,你已经体验过这个社区。
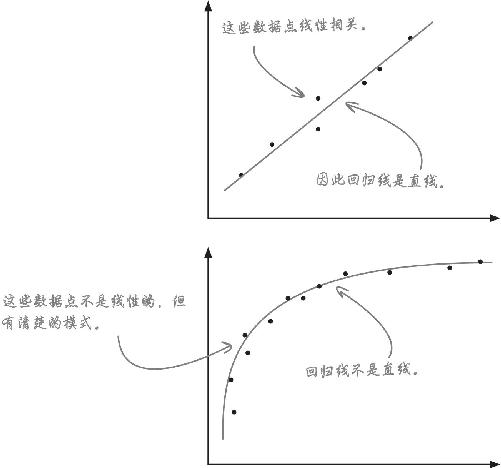
其六:非线性与多元回归
即使数据未呈现线性外观,在某些情况下,也可以使用回归进行预测。一种办法是将数字变形 ,最终使数据线性化;另一种办法是穿过图上的点画一条多项式 回归线,以此取代线性回归线。
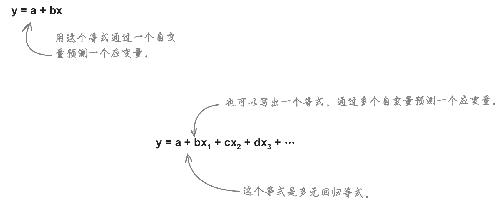
同样,不必限定自己通过唯一的自变量预测一个应变量。有时候,影响变量的因素多种多样 ,为了进行有效预测,可以使用多元回归 技术。
其七:原假设-备择假设检验
尽管第5章介绍的假设检验技术用途广泛,能涵盖各种分析问题,但是,不少人(尤其是学术界与科学界)一听到“假设检验”这几个字,就会想到统计技术中的原假设-备择假设检验 。
使用这个技术的人多于理解这个技术的人,如果想学会,《深入浅出统计学》(Head First Statistics )是个不错的起点。

其八:随机性
随机性是数据分析的重头戏。
原因是随机性几乎无迹可寻 。当人们试图解释事件时,通过以模型套证据,可以解释得很好;但在做决定的时候,仅用解释模型就收效不佳。
要是客户问你为什么会发生某件事,在经过最精心的分析之后,你往往只能老老实实地回答:“这件事可以用结果的随机性来解释。”

其九:Google Docs
我们介绍过Excel、OpenOffice及R,其实Google Docs也很值得一提。Google Docs 不仅有功能完备的在线电子表格,还可通过Gadget 特性提供大量图形。
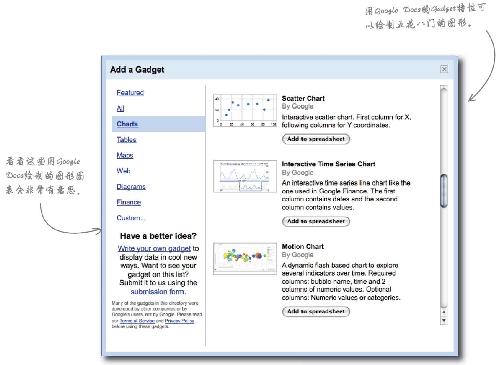
另外,Goolge Docs有很多功能都能帮助你访问实时在线数据资源 。这款免费软件绝对值得一试。
其十:你的专业技能
你学会了本书介绍的各种工具,但与此相比,更令人振奋的是,你将结合自己的专业技能 ,凭借这些工具去发现世界、改造世界。祝你好运。

附录B:安装R
启动R!

强大的数据分析功能靠的是复杂的内部机制。
好在只需几分钟就能安装和启动R,本附录将介绍如何不费吹灰之力安装R。
R起步
强大、免费的开源统计软件R可分以下四步快捷、简便地进行安装。
1 前往 www.r-project.org 下载R。在身边找到一个提供R的镜像并不难(用于Windows、Mac和Linux等环境)。
2 下载好R程序文件后,双击 程序文件,启动R安装程序。
3 在各个窗口中,单击Next(下一步),接受所有R默认安装选项,让安装程序执行安装。
4 单击电脑桌面或Start Menu(开始菜单)上的R图标,准备使用R。
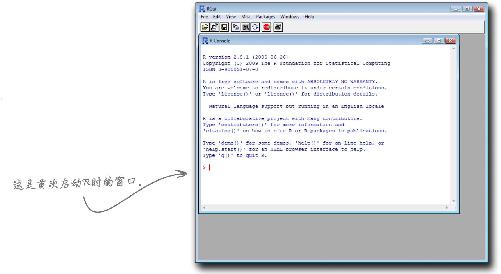
附录C:安装Excel分析工具
ToolPak

Excel有一些最好的功能在默认情况下并不安装。
为了执行第3章的优化和第9章的直方图,需要激活Solver 和Analysis ToolPak ,Excel在默认情况下安装了这两种扩展插件,但若非用户主动操作,这些插件不会被激活。
在Excel中安装数据分析工具
按照下列步骤进行简单操作,就可以在Excel中轻松安装Analysis ToolPak和Solver。
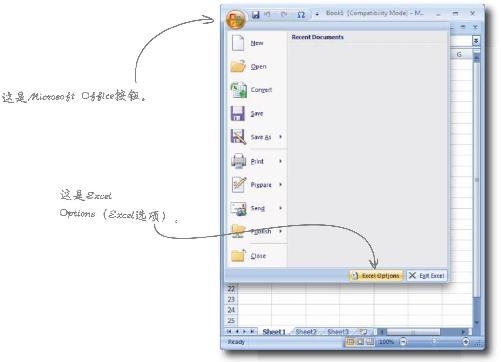
1 单击Microsoft Office按钮,选择Excel Options (Excel选项)。
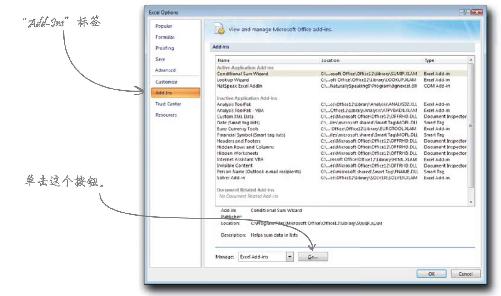
2 选择Add-Ins(插件)标签,单击Manage Excel Add-Ins.(管理Excel插件)旁边的Go... (执行…)。
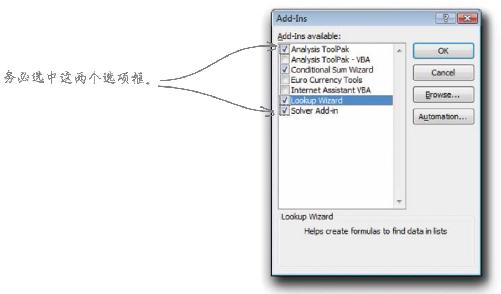
3 务必选中Analysis ToolPak和Solver插件框,然后单击OK (确定)。
4 查看Data(数据)选项卡,确保Data Analysis(数据分析)和Solver按钮可以使用。
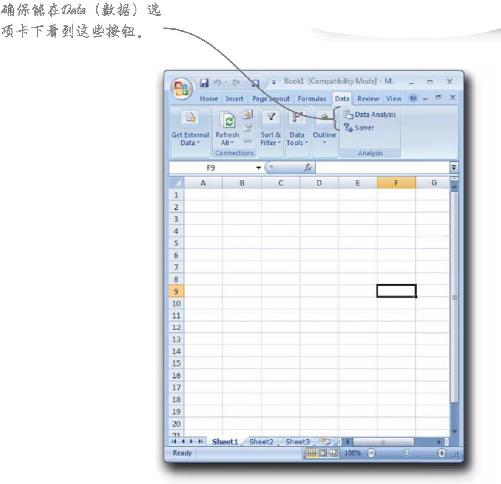
行了!
现在你已经做好准备,可以使用最优化、直方图和其他功能了。
本书由“行行”整理,如果你不知道读什么书或者想获得更多免费电子书请加小编微信或QQ:2338856113 小编也和结交一些喜欢读书的朋友 或者关注小编个人微信公众号名称:幸福的味道 为了方便书友朋友找书和看书,小编自己做了一个电子书下载网站,网站的名称为:周读 网址:www.ireadweek.com
索引
数字
3D scatterplots(三维散点图)
符号
~ 非(概率)
<- 赋值(R)
\ 换码符
| 假定(概率)
| 结果(R)
* 正则表达式通配符
. 正则表达式通配符
? 主题信息(R)
A
accuracy analysis(正确性分析)
Adobe Illustrator
Algorithm(算法)
alternative causal models(可相互换用的因果模型)
analysis(分析)
accuracy(正确性)
definitions of(…的定义)
exploratory data(探索性数据)
process steps(过程步骤)
step 1: define(步骤1:确定)
step 2: disassemble(步骤2:分解)
step 3: evaluate(步骤3:评估)
step 4: decide(步骤4:决策)
purpose of(目的)
Analysis ToolPak(Excel)
“anti-resume”(“反查”)
arrays(lattices)of scatterplots(大量散点图)
association(关系)
vs. causation(因果)
linear(线性)
assumptions(假设)
based on changing reality(基于不断变化的现实)
baseline set of(基准……)
cataloguing(编目)
evaluating and calibrating(评估与校正)
and extrapolation(外插法)
impact of incorrect(错误造成的影响)
inserting your own(本人介入)
making them explicit(使…变得明确)
predictions using(使用…进行预测)
reasonableness of(…的合理性)
reassessing(重新评估)
regarding variable independence(关于自变量与应变量)
casterisk(*)(星号(*))
averages,types of(平均值类型)
=AVG()(Excel/OpenOffice公式)
B
Backslash(反斜杆(\))
baseline expectations(基准期望),(另参见“假设”)
baseline(null)hypothesis(基准(原)假设)
base rate fallacy(基础概率谬误)
base rates(prior probabilities)(基础概率(事前概率))
Bayes' rule and(贝叶斯规则)
Defined(已确定)
how new information affects(新信息带来的影响)
Bayes' rule(贝叶斯规则)
effect of base rate on(基础概率的影响)
overview(概述)
revising probabilities using(修正概率的方法)
theory behind(基本理论)
Beautiful Evidence(Tufte)(《出色的证据》(塔夫特著))
Behind the Scenes(花絮)
R.M.S. error formula(均方根误差公式)
R regression object(R的回归对象)
bell curve(铃形曲线)
blind spots(盲点)
Bullet Points(要点)
client qualities(客户素质)
questions you should always ask(不能不问的问题)
things you might need to predict(可能需要预测的问题)
C
candidate hypothesis(候选假设)
cataloguing assumptions(假设分类)
causation(因果关系)
alternative models(可换用模型)
vs. association(关系)
causal diagrams(因果关系图)
causal networks(因果关系网络)
flipping cause and effect(颠倒因果关系)
and scatterplots(散点图)
searching for causal relationships(寻找因果关系)
chance error(residuals)(机会误差(残差))
defined(已确定)
and managing client expectations(管理客户预期)
and regression(回归)
residual distribution(残差分布)
(同时参见“均方根误差”)
Chance Error Exposed Interview(机会误差访谈)
charting tools,comparing(制图工具,比较)
cleaning data(see raw data)(整理数据(参见“原始数据”))
clients(客户)
assumptions of(假设)
communication with(沟通)
as data(数据)
delivering bad news(说出坏消息)
examples of(实例)
explaining limits of prediction(解释预测局限性)
explaining your work(解释自己的工作)
helping them analyze their business(帮助客户分析业务)
helping you define problem(帮助你确定问题)
Visualizations(图形)
listening to(倾听)
mental models of(心智模型)
professional relationship with(职业关系)
understanding/analyzing your(理解/分析)
cloud function(cloud函数)
code examples(see Ready Bake Code)(代码示例,参见“预编程代码”)
coefficient(系数)
correlation(r)(相关性(r))
defined(已确定)
“cognitive art,”(“认知艺术”)
comparable,defined(可比较,已确定)
comparisons(比较)
break down summary data using(拆分汇总数据)
evaluate using(评估)
of histograms(直方图)
and hypothesis testing(假设检验)
and linked tables(链接各个表格)
making the right(正确处理)
method of(方法)
multivariate(多元)
and need for controls(控制需求)
and observational data(观察数据)
of old and new(新与旧)
RDBMS
valid(正确)
visualizing your(图形)
=CONCATENATE()
conditional probabilities(条件概率)
confounders(混杂因素)
controlling for(控制)
defined(已确定)
and observational studies(观察研究法)
constraints(约束条件)
charting multiple(多元图形)
defined(已确定)
and feasible region(可行区域)
as part of objective function(目标函数的一部分)
product mixes and(产品组合)
quantitative(定量)
in Solver utility(Solver插件)
contemporaneous controls(同期控制法)
control groups(控制组)
controls(控制法)
contemporaneous(同期)
historical(历史)
possible and impossible(可能与不可能)
Convert Text to Column Wizard(Excel:文本转变为列向导)
cor()(R命令)
correlation coefficient(r)(相关系数r)
=COUNTIF()(Excel/OpenOffice公式)
CSV files(CSV文件)
curve,shape of(曲线,形状)
custom-made implementation(定制改装)
D
Data(数据)
constantly changing(不断变化)
diagnostic/nondiagnostic(诊断/非诊断)
distribution of(分布)
dividing into smaller chunks(分解为更小的组块)
duplicate,in spreadsheet(重复,电子表格)
heterogeneous(异质)
importance of comparison of(比较的重要性)
messy(混乱)
observations about(观察)
paired(成对)
quality/replicability of(质量/重复性)
readability of(可读性)
scant(极少量)
segmentation(splitting)of(分区)
subsets(子集)
summary(总结)
“too much,”(太多)
when to stop collecting(何时停止收集)
data analysis(see analysis)(数据分析,参见“分析”)
Data Analysis for Public Policy(《公共政策数据分析》(塔夫特著))
data analyst performance(数据分析师绩效)
empower yourself(提高自身)
insert yourself(本人介入)
not about making data pretty(不以数据美观为目的)
professional relationship with clients(与客户的个人关系)
showing integrity(体现公正)
data art(数据艺术)
databases(数据库)
defined(已确定)
relational databases(关系数据库)
software for(软件)
data cleaning(see raw data)(数据整理(参见“原始数据”))
data visualizations(see visualizations)(数据图形(参见“图形”))
decide(step 4 of analysis process)(决策(分析步骤第4步))
decision variables(决策变量)
define(step 1 of analysis process)(确定(分析步骤第1步))
defining the problem(确定问题)
delimiters(分隔符)
dependent variables(应变量)
diagnosticity(诊断性)
disassemble(step 2 of analysis process)(分解(分析步骤第2步))
distribution,Gaussian(normal)(高斯分布(正态))
distribution of chance error(机会误差分布)
distribution of data(数据分布)
diversity of outcomes(结果差别),
dot(.) ((点(.))
dot plots(点阵图,同时参见“散点图”)
duplicate data,eliminating(重复数据,删除)
E
edit()(R的编辑命令)
equations(方程)
linear(线性)
multiple regression(多元回归)
objective function(目标函数)
regression(回归)
slope(斜率)
error(误差)
managing,through segmentation(通过分区进行管理)
quantitative(量化)
variable across graph(图形中的变量)
(同时参见“机会误差”;均方根误差RMS)
error bands(误差区间)
\(转义符)
Ethics(伦理学)
and control groups(控制组)
showing integrity toward clients(向客户体现公正)
evaluate(step 3 of analysis process)(评估(分析步骤第3步))
evidence(证据)
diagnostic(诊断)
in falsification method(证伪法)
handling new(处理新消息)
model/hypothesis fitting(模型/假设相符)
Excel/OpenOffice
=AVG()
Bayes' rule in(贝叶斯规则)
charting tools in(制图工具)
Chart Output checkbox(图形输出复选框)
=CONCATENATE()
Convert Text to Column Wizard(数据转化为列向导)
=COUNTIF()
Data Analysis(数据分析)
=FIND()
histograms in(直方图)
Input Range field(输入范围域)
=LEFT()
=LEN()
nested searches in(嵌套搜索)
no regular expressions in(非正则表达式)
Paste Special function(“选择性粘贴”功能)
pivot tables in(数据透视表)
=RAND()
Remove Duplicates button(“删除重复”按钮)
=RIGHT()
Solver
Changing Cells field(更改单元格)
installing/activating(安装/激活)
Target Cell field(目标单元格)
specifying a delimiter(指定分隔符)
standard deviation in(标准偏差)
=STDEV()
=SUBSTITUTE()
=SUMIF()
text formulas(文本公式)
=TRIM()
=VALUE()
experiments(实验)
control groups(控制组)
example process flowchart(流程图实例)
vs. observational study(观察研究法)
overview(概要)
randomness and(随机)
for strategy(策略)
exploratory data analysis(探索性数据分析)
extrapolation(外插法)
F
false negatives(假阴性)
false positives(假阳性)
falsification method of hypothesis testing(假设检验证伪法)
fast and frugal trees(快省树)
feasible region(可行区域)
=FIND()(Excel/OpenOffice公式)
Fireside Chat(Bayes' Rule and Gut Instinct)(今夜谈:“贝叶斯规则”先生和“直觉”先生)
flipping the theory(反向理论)
frequentist hypothesis testing(频率论者假设检验)
G
Gadget(Google Docs特性)
Galton,Sir Francis(高尔顿爵士)
Gaps(间隔)
in histograms(直方图)
knowledge(知识)
gaps in histograms(直方图间隔)
Gaussian(normal)distribution(高斯分布(正态分布))
Geek Bits(技巧)
regex specification(正则表达式规定)
slope calculation(斜率计算)
getwd()(R指令)
Google Docs
Granularity(颗粒)
graphics(see visualizations)(图形,参见“图形”)
graph of averages(平均值图形)
groupings of data(数据分组)
H
head()(R指令)
Head First Statistics(《深入浅出统计学》)
help()(R指令)
heterogeneous data(异质数据)
heuristics(启发法)
and choice of variables(选择变量)
defined(已确定)
fast and frugal tree(快省树)
human reasoning as(人类推理)
vs. intuition(直觉)
overview(概述)
rules of thumb(经验)
stereotypes as(固定模式)
strengths and weaknesses of(优缺点)
hist()(R指令)
histograms(直方图)
in Excel/OpenOffice(Excel/OpenOffice中的……)
fixing gaps in(处理缺口)
fixing multiple humps in(处理多个峰)
groupings of data and(数据分组)
normal(bell curve)distribution in(正态分布(铃形曲线))
overlays of(迭加)
overview(概述)
in R(R程序)
vs. scatterplots(散点图)
historical controls(历史控制法)
human reasoning as heuristic(启发式人类推理法)
hypothesis testing(假设检验)
diagnosticity(诊断性)
does it fit evidence(假设是否与证据相符)
falsification method(证伪法)
frequentist(频率论者)
generating hypotheses(建立假设)
overview(概述)
satisficing(满意法)
weighing hypotheses(权衡假设法)
I
Illustrator(Adobe Illustrator)
independent variables(自变量)
intercepts(截距)
internal variation(内部偏差)
interpolation(内插法)
intuition vs. heuristics(直觉与启发法)
inventory of observational data(搜集观察数据)
iterative,defined(反复的,确定的)
J
jitter()(R指令)
K
knowledge gaps(知识缺陷)
L
lattices(arrays)of scatterplots(散点图集)
=LEFT()(Excel/OpenOffice公式)
=LEN()(Excel/OpenOffice公式)
library()(R指令)
linear association(线性相关性)
linear equation(线性方程)
linearity(线性)
linear model object(线性模型对象)
linear programming(线性编程)
linked spreadsheets(关联电子表格)
linked variables(关联变量)
lm()(R指令)
M
measuring effectiveness(计量绩效)
mental models(心智模型)
method of comparison(比较方法)
Microsoft Excel(Excel/OpenOffice程序)
Microsoft Visual Basic for Applications(VBA)
models(模型)
fit of(符合)
impact of incorrect(错误影响)
include what you don't know in(包含不了解的因素)
making them explicit(模型明确化)
making them testable(模型可测试)
mental(心智的)
need to constantly adjust(需要不断调整)
segmented(分区)
statistical(统计的)
with too many variables(变量太多)
multi-panel lattice visualizations(多面板网格图形)
multiple constraints(多种约束条件)
multiple predictive models(多种可预测模型)
multiple regression(多元回归)
multivariate data visualization(多变量数据图形)
N
negatively linked variables(负相关变量)
networked causes(因果关系)
nondiagnostic evidence(非诊断证据)
nonlinear and multiple regression(非线性多元回归)
normal(Gaussian)distribution(正态(高斯)分布)
null-alternative testing(备择检验)
null(baseline)hypothesis(备择假设(原假设))
O
objective function(目标函数)
objectives(目标)
“objectivity,”(目标性)
observational studies(观察研究)
OpenOffice(参见Excel/OpenOffice)
operations research(运算研究)
optimization(最优化)
and constraints(约束条件)
vs. falsification(证伪法)
vs. heuristics(启发法)
overview(概述)
solving problems of(解决问题)
using Solver utility for(Solver功能)
order()(R指令)
outcomes,diversity of(多种结果)
out-of-the-box implementation(现买现用)
overlays of histograms(重迭直方图)
P
paired data(成对数据)
perpetual,iterative framework(反复不断地构建)
pipe character(|字符)
in Bayes' rule(贝叶斯规则)
in R commands(R指令)
pivot tables(数据透视表)
plot()(R命令)
polynomial regression(多项式回归)
positively linked variables(正相关变量)
practice downloads(练习下载:www.headfirstlabs.com/books/hfda/)
bathing_friends_unlimited.xls
hfda_ch04_home_page1.csv
hfda_ch07_data_transposed.xls
hfda_ch07_new_probs.xls
hfda_ch09_employees.csv
hfda_ch10_employees.csv
hfda_ch12_articleHitsComments.csv
hfda_ch12_articles.csv
hfda_ch12_issues.csv
hfda_ch12_sales.csv
hfda_ch13_raw_data.csv
hfda.R
historical_sales_data.xls
prediction(预测)
balanced with explanation(加以解释)
and data analysis(数据分析)
deviations from(偏差)
explaining limits of(解释限制条件)
outside the data range(extrapolation)(超出数据范围(外插))
and regression equations(回归方程)
and scatterplots(散点图)
prevalence,effect of(程度,效果)
previsualizing(想象)
prior probabilities(see base rates [prior probabilities])(事前概率(参见“基础概率[事前概率]”))
probabilities(概率)
Bayes' rule and(贝叶斯规则)
calculating false positives,negatives(计算假阳性、假阴性)
common mistakes in(普通错误)
conditional(条件)
(同时参见“主观概率”)
probability histograms(概率直方图)
product mixes(产品组合)
Q
Quantitative(定量)
Constraints(约束条件)
Errors(误差)
linking of pairs(数据相关)
making goals and beliefs(制定目标,确立信念)
relationships(关系)
relations in RDBMS(相关数据库中的关系)
theory(理论)
querying(查询)
defined(已确定)
linear model object in R(R中的线性模型对象)
SQL
question mark(?)(R中的问号)
R
R
charting tools in(绘图工具)
cloud function(cloud函数)
command prompt(指令提示)
commands(指令)
?
cor()
edit()
getwd()
head()
help()
hist()
jitter()
library()
lm()
order()
plot()
read.csv()
save.image()
sd()
source()
sub()
summary()
unique()
write.csv()
xyplot()
community of users(用户社区)
defaults(默认值)
described(描述)
dotchart function in(dotchart函数)
histograms in(直方图)
installing and running(安装与运行)
pipe character in(|字符)
regular expression searches in(正则表达式搜索)
scatterplot arrays in(散点图集合)
r(correlation coefficient)(相关系数r)
=RAND()(Excel/OpenOffice公式)
randomized controlled experiments(随机控制实验)
Randomness(随机)
Randomness Exposed Interview(随机访谈)
random surveys(随机调查)
rationality(理性)
raw data(原始数据)
disassembling(分解)
evaluating(评估)
flowchart for cleaning(整理流程图)
previsualize final data set(最终数据外观)
using delimiter to split data(使用分隔符分隔数据)
using Excel nested searches(使用Excel嵌套搜索)
using Excel text formulas(使用Excel文本公式)
using R regular expression searches(使用R正则表达式搜索)
using R to eliminate duplicates in(使用R消除重复数据)
RDBMS(关系数据库管理系统)
read.csv()(R指令)
Ready Bake Code(预编代码)
calculate r in R(在R中计算r)
generate a scatterplot in R(在R中生成散点图)
recommendations(建议,参见“客户报告”)
regression(回归)
balancing explanation and prediction in(平衡解释与预测)
and chance error(机会误差)
correlation coefficient(r) and(相关系数r)
Data Analysis for Public Policy(《公共政策数据分析》(塔夫特著))
Linear(线性)
linear correlation and(线性相关)
nonlinear regression(非线性回归)
origin of name(名字来源)
overview(概述)
polynomial(多项式)
and R.M.S. error(均方根误差)
and segmentation(分区)
regression equations(回归方程)
regression lines(回归线)
regular expression searches(正则表达式搜索)
relational database management system(相关数据库管理系统RDBMS)
relational databases(关系数据库)
replicability(重复性)
reports to clients(给客户的报告)
examples of(实例)
guidelines for writing(撰写指南)
using graphics(使用图形)
representative samples(典型抽样)
residual distribution(残差分布)
residuals(残差,参见“机会误差”)
residual standard error(残差标准差,参见“均方根误差”)
=RIGHT()(Excel/OpenOffice公式)
rise(高)
Root Mean Squared(R.M.S.)error(均方根误差)
compared to standard deviation(与标准偏差进行比较)
defined(已确定)
formula for(公式)
improving prediction with(改进预测)
R
regression and(回归)
rules of thumb(经验)
run(边长)
S
Sampling(抽样)
Satisficing(满意法)
save.image()(R指令)
scant data(数据匮乏)
scatterplots(散点图)
3D
creating from spreadsheets in R(在R中用电子表格创建)
drawing lines for prediction in(绘制预测线)
vs. histograms(直方图)
lattices(arrays)of(网格(数组))
magnet chart(数据点图)
overview(概述)
regression equation and(回归方程)
regression lines in(回归线)
sd()(R指令)
segmentation(分区)
segments(分区)
self-evaluations(自评)
sigma(σ,参见“均方根误差”)
slope(斜率)
Solver
Sorting(排序)
source()(R指令)
splitting data(拆分数据)
spread of outcomes(结果分布)
spreadsheets(电子数据表)
charting tools(绘图工具)
linked(关联)
provided by clients(来自客户)
(同时参见Excel/OpenOffice)
SQL(结构化查询语言)
standard deviation(标准偏差)
calculating the(计算)
defined(已确定)
and R.M.S. error calculation(均方根误差计算)
and standard units(标准单位)
=STDEV
standard units(标准单位)
statistical models(统计模型)
=STDEV()(Excel/OpenOffice公式)
stereotypes as heuristics(固定模式,启发式)
strip,defined(区间,已确定)
Structured Query Language(结构化查询语言SQL)
sub()(R指令)
subjective probabilities(主观概率)
charting(绘图)
defined(已确定)
describing with error ranges(描述误差范围)
overcompensation in(过度补偿)
overview(概述)
quantifying(量化)
revising using Bayes' rule(使用贝叶斯规则进行修正)
strengths and weaknesses of(优点和缺点)
subsets of data(数据子集)
=SUBSTITUTE()(Excel/OpenOffice)
=SUMIF()(Excel/OpenOffice公式)
summary()(R指令)
summary data(汇总数据)
surprise information(惊人的信息)
surveys(调查)
T
tag clouds(标签云)
Test Drive(“一试身手”)
Using Excel for histograms(用Excel绘制直方图)
Using R to get R.M.S. error(用R计算均方根误差)
Using Solver(使用Solver)
tests of significance(显著性检验)
theory(理论,参见“心智模型”)
thinking with data(用数据思考)
tilde(~)
ToolPak(Excel)
Transformations(变形)
=TRIM()(Excel/OpenOffice公式)
Troubleshooting(处理问题)
activating Analysis ToolPak(激活Analysis ToolPak)
Data Analysis button missing(数据分析按钮不出现)
gaps in Excel/OpenOffice histograms(Excel/OpenOf-fice直方图缺口)
histogram not in chart format(非图形格式直方图)
read.csv()(R指令)
Solver utility not on menu(菜单中不见Solver功能)
true negatives(真阴性)
true positives(真阳性)
Tufte,Edward(爱德华·塔夫特)
two variable comparisons(两种变量比较)
U
ultra-specified problems(超规范问题)
uncertainty(不确定因素)
unique()(R指令)
Up Close(细节放大)
conditional probability notation(条件概率记法)
confounding(混杂)
correlation(相关)
histograms(直方图)
your data needs(数据需要……)
your regular expression(正则表达式)
V
=VALUE()(Excel/OpenOffice公式)
Variables(变量)
Decision(决策)
Dependent(应变)
Independent(自变)
Linked(相关)
Multiple(多个)
Two(两个)
variation,internal(内部偏差)
vertical bar(|)
in Bayes' rule(贝叶斯规则)
in R commands(R命令)
Visual Basic for Applications(VBA)
Visualizations(图形)
Beautiful Evidence(《可靠的证据》(塔夫特著))
causal diagrams(因果关系图)
data art(数据艺术)
examples of poor(不合格实例)
fast and frugal trees(快省树)
making the right comparisons(正确比较)
multi-panel lattice(多面板网格图)
multivariate(多变量)
overview(概述)
in reports(报告)
software for(软件)
(同时参见“直方图”、“散点图”)
W
Watch it!(小心!)
always keep an eye on your model assumptions(千万对模型假设保持戒心)
always make comparisons explicit(千万要进行明确比较)
does your regression make sense?(回归线有意义吗?)
way off on probabilities(概率错觉)
websites(网站)
to download R(下载R)
Edward Tufte(爱德华·塔夫特)
Head First(深入浅出)
tag clouds(标签云)
whole numbers(整数)
wildcard search(通配符搜索)
write.csv()(R指令)
X
xyplot()(R指令)
Y
y-axis intercept(Y轴截距)
如果你不知道读什么书,
就关注这个微信号。

微信公众号名称:幸福的味道
加小编微信一起读书
小编微信号:2338856113
【幸福的味道】已提供200个不同类型的书单
1、 历届茅盾文学奖获奖作品
2、 每年豆瓣,当当,亚马逊年度图书销售排行榜
3、 25岁前一定要读的25本书
4、 有生之年,你一定要看的25部外国纯文学名著
5、 有生之年,你一定要看的20部中国现当代名著
6、 美国亚马逊编辑推荐的一生必读书单100本
7、 30个领域30本不容错过的入门书
8、 这20本书,是各领域的巅峰之作
9、 这7本书,教你如何高效读书
10、 80万书虫力荐的“给五星都不够”的30本书
关注“幸福的味道”微信公众号,即可查看对应书单和得到电子书
也可以在我的网站(周读)www.ireadweek.com 自行下载
备用微信公众号:一种思路

Table of Contents
谁适合阅读本书?
我们了解你在想什么
我们了解你的大脑在想什么
元认知:对思考的思考
我们的做法
你的任务:征服大脑
自述
技术顾问组
致谢
Acme化妆品公司需要你出力
首席执行官希望数据分析师帮他提高销量
数据分析就是仔细推敲证据
确定问题
客户将帮助你确定问题
Acme公司首席执行官给了你一些反馈
把问题和数据分解为更小的组块
现在再来看看了解到的情况
评估组块
分析从你介入的那一刻开始
提出建议
报告写好了
首席执行官欣赏你的工作
一则新闻
首席执行官确信的观点让你误入歧途
你对外界的假设和你确信的观点就是你的心智模型
统计模型取决于心智模型
心智模型应当包括你不了解的因素
首席执行官承认自己有所不知
Acme给你发来了一长串原始数据
深入挖掘数据
泛美批发公司确认了你的印象
回顾你的工作
你的分析让客户做出了英明的决策
咖啡业的寒冬到了!
星巴仕董事会将在三个月内召开
星巴仕调查表
务必使用比较法
比较是破解观察数据的法宝
价值感是导致销售收入下滑的原因吗?
一位典型客户的想法
观察分析法充满混杂因素
店址可能对分析结果有哪些影响
拆分数据块,管理混杂因素
情况比预料的更糟!
你需要做一个实验,指出哪种策略最有效
星巴仕首席执行官已经急不可待
星巴仕降价了
一个月后……
以控制组为基准
避免解雇123
让我们重新认真做一次实验
一个月后……
实验照样会毁于混杂因素
精心选择分组,避免混杂因素
随机选择相似组
随机访谈
准备就绪,开始实验
结果在此
星巴仕找到了与经验吻合的销售策略
现在是浴盆玩具游戏时间
你能控制的变量受到约束条件的限制
决策变量是你能控制的因素
你碰到了一个最优化问题
借助目标函数发现目标
你的目标函数
列出有其他约束条件的产品组合
在同一张图形里绘制多种约束条件
合理的选择都出现在可行区域里
新约束条件改变了可行区域
用电子表格实现最优化
Solver一气呵成解决最优化问题
利润跌穿地板
你的模型只是描述了你规定的情况
按照分析目标校正假设
提防负相关变量
新方案立竿见影
你的假设立足于不断变化的实际情况
新军队需要优化网站
结果面世,信息设计师出局
前一位信息设计师提交的三份信息图
这些图形隐含哪些数据?
体现数据!
这是前一位设计师主动提供的意见
数据太多绝不会成为你的问题
让数据变美观也不是你要解决的问题
数据图形化的根本在于正确比较
你的图形已经比打入冷宫的图形更有用
使用散点图探索原因
最优秀的图形都是多元图形
同时展示多张图形,体现更多变量
图形很棒,但网站掌门人仍不满意
优秀的图形设计有助于思考的原因
实验设计师出声了
实验设计师们有自己的假设
客户欣赏你的工作
订单从四面八方滚滚而来!
给我来块“皮肤”……
我们何时开始生产新手机皮肤?
PodPhone不希望别人看透他们的下一步行动
我们得知的全部信息
电肤的分析与数据相符吗?
电肤得到了机密《战略备忘录》
变量之间可以正相关,也可以负相关
现实世界中的各种原因呈网络关系,而非线性关系
假设几个PodPhone备选方案
用手头的资料进行假设检验
假设检验的核心是证伪
借助诊断性找出否定性最小的假设
无法一一剔除所有假设,但可以判定哪个假设最强
你刚刚收到一条图片短信……
即将上市!
医生带来恼人的消息
让我们逐条细读正确性分析
蜥蜴流感到底有多普遍?
你计算的是假阳性
这些术语说的都是条件概率
你需要算算
1%的人患蜥蜴流感
你患蜥蜴流感的几率仍然非常低
用简单的整数思考复杂的概率
搜集到新数据后,用贝叶斯规则处理基础概率
贝叶斯规则可以反复使用
第二次试验结果:阴性
新试验的正确性统计值有变化
新信息会改变你的基础概率
放心多了!
背水投资公司需要你效力
分析师们相互叫阵
主观概率体现专家信念
主观概率可能表明:根本不存在真正的分歧
分析师们答复的主观概率
首席执行官不明白你在忙些什么
首席执行官欣赏你的工作
标准偏差量度分析点与平均值的偏差
这条新闻让你措手不及
贝叶斯规则是修正主观概率的好办法
首席执行官完全知道该怎么处理这条新信息了
俄罗斯股民欢欣鼓舞!
邋遢集向市议会提交了报告
邋遢集确实把镇上打扫得干干净净
邋遢集已经计量了自己的工作效果
他们的任务是减少散乱垃圾量
计量垃圾量不可行
问题刁钻,回答简单
数据邦市的散乱垃圾结构复杂
无法建立和运用统一的散乱垃圾计量模型
启发法是从直觉走向最优化的桥梁
使用快省树
是否有更简单的方法评估邋遢集的成就?
固定模式都具有启发性
分析完毕,准备提交
看来你的分析打动了市议会的议员们
员工年度考评即将到来
伸手要钱形式多样
这是历年加薪记录
直方图体现每组数据的发生频数
直方图不同区间之间的缺口即数据点之间的缺口
安装并运行R
将数据加载到R程序
R创建了美观的直方图
用数据的子集绘制直方图
加薪谈判有回报
谈判要求加薪对你意味着什么?
你打算怎么花这些钱?
以获取大幅度加薪为目的进行分析
稍等片刻……加薪计算器!
这个算法的玄机在于预测加薪幅度
用散点图比较两种变量
直线能为客户指明目标
使用平均值图形预测每个区间内的数值
回归线预测出人们的实际加薪幅度
回归线对于具有线性相关特点的数据很有用
你需要用一个等式进行精确预测
让R创建一个回归对象
回归方程与散点图密切相关
加薪计算器的算法正是回归方程
你的加薪计算器没有照计划行事……
客户大为恼火
你的加薪预测算法做了什么?
客户组成
要求加薪25%的家伙不在模型范围内
如何对待想对数据范围以外的情况进行预测的客户
由于使用外插法而惨遭解雇的家伙冷静下来了
你只解决了部分问题
扭曲的加薪结果数据看起来是什么样子?
机会误差=实际结果与模型预测结果之间的偏差
误差对你和客户都有好处
机会误差访谈
定量地指定误差
用均方根误差定量表示残差分布
R模型知道存在均方根误差
R的线性模型汇总展示了均方根误差
分割的根本目的是管理误差
优秀的回归分析兼具解释功能和预测功能
相比原来的模型,分区模型能更好地处理误差
你的客户纷纷回头
《数据邦新闻》希望分析销量
这是他们保存的运营跟踪数据
你需要知道数据表之间的相互关系
数据库就是一系列相互有特定关系的数据
找到一条贯穿各种关系的路线,以便进行必要的比较
创建一份穿过这条路径的电子表格
通过汇总将文章数目和销量关联起来
看来你的散点图确实画得很好
复制并粘贴所有这些数据是件痛苦的事
用关系数据库管理关系
《数据邦新闻》利用你的关系图建立了一个RDBMS
《数据邦新闻》用SQL提取数据
RDBMS数据可以进行无穷无尽的比较
你上了封面
刚从停业的竞争对手那儿搞到一份客户名单
数据分析不可告人的秘密
Head First猎头公司想为自己的销售团队搞到这份名单
清理混乱数据的根本在于准备
一旦组织好数据,就能修复数据
将#号作为分隔符
Excel通过分隔符将数据分成多个列
用SUBSTITUTE替换“^”字符
所有的“姓”都整理好了
用SUBSTITUTE替换名字模式太麻烦了
用嵌套文本公式处理复杂的模式
R能用正则表达式处理复杂的数据模式
用sub指令整理“名”
现在可以向客户交货了
可能尚未大功告成……
为数据排序,让重复数值集中出现
这些数据有可能来源于某个关系数据库
删除重复名字
你创建了美观、整洁、具有唯一性的记录
Head First猎头公司正在一网打尽各种人才!
再见……
其一:统计知识大全
其二:Excel技巧
其三:耶鲁大学教授Edward Tufte (爱德华·塔夫特)的图形原则
其四:数据透视表
其五:R社区
其六:非线性与多元回归
其七:原假设-备择假设检验
其八:随机性
其九:Google Docs
其十:你的专业技能
R起步
在Excel中安装数据分析工具