本书由“行行”整理,如果你不知道读什么书或者想获得更多免费电子书请加小编微信或QQ:2338856113 小编也和结交一些喜欢读书的朋友 或者关注小编个人微信公众号名称:幸福的味道 为了方便书友朋友找书和看书,小编自己做了一个电子书下载网站,网站的名称为:周读 网址: www.ireadweek.com
目录
谁适合阅读本书?
我们了解你在想什么
我们了解你的大脑在想什么
元认知:对思考的思考
我们的做法
你的任务:征服大脑
自述
技术顾问组
致谢
Acme化妆品公司需要你出力
首席执行官希望数据分析师帮他提高销量
数据分析就是仔细推敲证据
确定问题
客户将帮助你确定问题
Acme公司首席执行官给了你一些反馈
把问题和数据分解为更小的组块
现在再来看看了解到的情况
评估组块
分析从你介入的那一刻开始
提出建议
报告写好了
首席执行官欣赏你的工作
一则新闻
首席执行官确信的观点让你误入歧途
你对外界的假设和你确信的观点就是你的心智模型
统计模型取决于心智模型
心智模型应当包括你不了解的因素
首席执行官承认自己有所不知
Acme给你发来了一长串原始数据
深入挖掘数据
泛美批发公司确认了你的印象
回顾你的工作
你的分析让客户做出了英明的决策
咖啡业的寒冬到了!
星巴仕董事会将在三个月内召开
星巴仕调查表
务必使用比较法
比较是破解观察数据的法宝
价值感是导致销售收入下滑的原因吗?
一位典型客户的想法
观察分析法充满混杂因素
店址可能对分析结果有哪些影响
拆分数据块,管理混杂因素
情况比预料的更糟!
你需要做一个实验,指出哪种策略最有效
星巴仕首席执行官已经急不可待
星巴仕降价了
一个月后……
以控制组为基准
避免解雇123
让我们重新认真做一次实验
一个月后……
实验照样会毁于混杂因素
精心选择分组,避免混杂因素
随机选择相似组
随机访谈
准备就绪,开始实验
结果在此
星巴仕找到了与经验吻合的销售策略
现在是浴盆玩具游戏时间
你能控制的变量受到约束条件的限制
决策变量是你能控制的因素
你碰到了一个最优化问题
借助目标函数发现目标
你的目标函数
列出有其他约束条件的产品组合
在同一张图形里绘制多种约束条件
合理的选择都出现在可行区域里
新约束条件改变了可行区域
用电子表格实现最优化
Solver一气呵成解决最优化问题
利润跌穿地板
你的模型只是描述了你规定的情况
按照分析目标校正假设
提防负相关变量
新方案立竿见影
你的假设立足于不断变化的实际情况
新军队需要优化网站
结果面世,信息设计师出局
前一位信息设计师提交的三份信息图
这些图形隐含哪些数据?
体现数据!
这是前一位设计师主动提供的意见
数据太多绝不会成为你的问题
让数据变美观也不是你要解决的问题
数据图形化的根本在于正确比较
你的图形已经比打入冷宫的图形更有用
使用散点图探索原因
最优秀的图形都是多元图形
同时展示多张图形,体现更多变量
图形很棒,但网站掌门人仍不满意
优秀的图形设计有助于思考的原因
实验设计师出声了
实验设计师们有自己的假设
客户欣赏你的工作
订单从四面八方滚滚而来!
给我来块“皮肤”……
我们何时开始生产新手机皮肤?
PodPhone不希望别人看透他们的下一步行动
我们得知的全部信息
电肤的分析与数据相符吗?
电肤得到了机密《战略备忘录》
变量之间可以正相关,也可以负相关
现实世界中的各种原因呈网络关系,而非线性关系
假设几个PodPhone备选方案
用手头的资料进行假设检验
假设检验的核心是证伪
借助诊断性找出否定性最小的假设
无法一一剔除所有假设,但可以判定哪个假设最强
你刚刚收到一条图片短信……
即将上市!
医生带来恼人的消息
让我们逐条细读正确性分析
蜥蜴流感到底有多普遍?
你计算的是假阳性
这些术语说的都是条件概率
你需要算算
1%的人患蜥蜴流感
你患蜥蜴流感的几率仍然非常低
用简单的整数思考复杂的概率
搜集到新数据后,用贝叶斯规则处理基础概率
贝叶斯规则可以反复使用
第二次试验结果:阴性
新试验的正确性统计值有变化
新信息会改变你的基础概率
放心多了!
背水投资公司需要你效力
分析师们相互叫阵
主观概率体现专家信念
主观概率可能表明:根本不存在真正的分歧
分析师们答复的主观概率
首席执行官不明白你在忙些什么
首席执行官欣赏你的工作
标准偏差量度分析点与平均值的偏差
这条新闻让你措手不及
贝叶斯规则是修正主观概率的好办法
首席执行官完全知道该怎么处理这条新信息了
俄罗斯股民欢欣鼓舞!
邋遢集向市议会提交了报告
邋遢集确实把镇上打扫得干干净净
邋遢集已经计量了自己的工作效果
他们的任务是减少散乱垃圾量
计量垃圾量不可行
问题刁钻,回答简单
数据邦市的散乱垃圾结构复杂
无法建立和运用统一的散乱垃圾计量模型
启发法是从直觉走向最优化的桥梁
使用快省树
是否有更简单的方法评估邋遢集的成就?
固定模式都具有启发性
分析完毕,准备提交
看来你的分析打动了市议会的议员们
员工年度考评即将到来
伸手要钱形式多样
这是历年加薪记录
直方图体现每组数据的发生频数
直方图不同区间之间的缺口即数据点之间的缺口
安装并运行R
将数据加载到R程序
R创建了美观的直方图
用数据的子集绘制直方图
加薪谈判有回报
谈判要求加薪对你意味着什么?
你打算怎么花这些钱?
以获取大幅度加薪为目的进行分析
稍等片刻……加薪计算器!
这个算法的玄机在于预测加薪幅度
用散点图比较两种变量
直线能为客户指明目标
使用平均值图形预测每个区间内的数值
回归线预测出人们的实际加薪幅度
回归线对于具有线性相关特点的数据很有用
你需要用一个等式进行精确预测
让R创建一个回归对象
回归方程与散点图密切相关
加薪计算器的算法正是回归方程
你的加薪计算器没有照计划行事……
客户大为恼火
你的加薪预测算法做了什么?
客户组成
要求加薪25%的家伙不在模型范围内
如何对待想对数据范围以外的情况进行预测的客户
由于使用外插法而惨遭解雇的家伙冷静下来了
你只解决了部分问题
扭曲的加薪结果数据看起来是什么样子?
机会误差=实际结果与模型预测结果之间的偏差
误差对你和客户都有好处
机会误差访谈
定量地指定误差
用均方根误差定量表示残差分布
R模型知道存在均方根误差
R的线性模型汇总展示了均方根误差
分割的根本目的是管理误差
优秀的回归分析兼具解释功能和预测功能
相比原来的模型,分区模型能更好地处理误差
你的客户纷纷回头
《数据邦新闻》希望分析销量
这是他们保存的运营跟踪数据
你需要知道数据表之间的相互关系
数据库就是一系列相互有特定关系的数据
找到一条贯穿各种关系的路线,以便进行必要的比较
创建一份穿过这条路径的电子表格
通过汇总将文章数目和销量关联起来
看来你的散点图确实画得很好
复制并粘贴所有这些数据是件痛苦的事
用关系数据库管理关系
《数据邦新闻》利用你的关系图建立了一个RDBMS
《数据邦新闻》用SQL提取数据
RDBMS数据可以进行无穷无尽的比较
你上了封面
刚从停业的竞争对手那儿搞到一份客户名单
数据分析不可告人的秘密
Head First猎头公司想为自己的销售团队搞到这份名单
清理混乱数据的根本在于准备
一旦组织好数据,就能修复数据
将#号作为分隔符
Excel通过分隔符将数据分成多个列
用SUBSTITUTE替换“^”字符
所有的“姓”都整理好了
用SUBSTITUTE替换名字模式太麻烦了
用嵌套文本公式处理复杂的模式
R能用正则表达式处理复杂的数据模式
用sub指令整理“名”
现在可以向客户交货了
可能尚未大功告成……
为数据排序,让重复数值集中出现
这些数据有可能来源于某个关系数据库
删除重复名字
你创建了美观、整洁、具有唯一性的记录
Head First猎头公司正在一网打尽各种人才!
再见……
其一:统计知识大全
其二:Excel技巧
其三:耶鲁大学教授Edward Tufte (爱德华·塔夫特)的图形原则
其四:数据透视表
其五:R社区
其六:非线性与多元回归
其七:原假设-备择假设检验
其八:随机性
其九:Google Docs
其十:你的专业技能
R起步
在Excel中安装数据分析工具
如果你不知道读什么书,
就关注这个微信号。

微信公众号名称:幸福的味道
加小编微信一起读书
小编微信号:2338856113
【幸福的味道】已提供200个不同类型的书单
1、 历届茅盾文学奖获奖作品
2、 每年豆瓣,当当,亚马逊年度图书销售排行榜
3、 25岁前一定要读的25本书
4、 有生之年,你一定要看的25部外国纯文学名著
5、 有生之年,你一定要看的20部中国现当代名著
6、 美国亚马逊编辑推荐的一生必读书单100本
7、 30个领域30本不容错过的入门书
8、 这20本书,是各领域的巅峰之作
9、 这7本书,教你如何高效读书
10、 80万书虫力荐的“给五星都不够”的30本书
关注“幸福的味道”微信公众号,即可查看对应书单和得到电子书
也可以在我的网站(周读)www.ireadweek.com 自行下载
备用微信公众号:一种思路

内容简介
《深入浅出数据分析》以类似“章回小说”的活泼形式,生动地向读者展现优秀的数据分析人员应知应会的技术:数据分析基本步骤、实验方法、最优化方法、假设检验方法、贝叶斯统计方法、主观概率法、启发法、直方图法、回归法、误差处理、相关数据库、数据整理技巧;正文之后,意犹未尽地以三篇附录介绍数据分析十大要务、R工具及ToolPak工具,在充分展现目标知识以外,为读者搭建了走向深入研究的桥梁。
本书构思跌宕起伏,行文妙趣横生,无论读者是职场老手,还是业界新人;无论是字斟句酌,还是信手翻阅,都能跟着文字在职场中走上几回,体味数据分析领域的乐趣与挑战。
978-0-596-15393-9 Head First Date Analysis © 2009 by O'Reilly Media,Inc. Simplified Chinese edition,jointly published by O'Reilly Media ,Inc. and Publishing House of Electronics Industry,2010. Authorized translation of the English edition,2009 O'Reilly Media,Inc.,the owner of all rights to publish and sell the same. All rights reserved including the rights of reproduction in whole or in part in any form.
本书中文简体版专有出版权由O'Reilly Media,Inc. 授予电子工业出版社,未经许可,不得以任何方式复制或抄袭本书的任何部分。
本书荐辞
“是时候写一本通俗易懂、内容全面的数据分析知识指南了,好让概念的学习变得既简单又有趣。借助各种成熟的技术和免费的工具,数据分析将改变你思考问题和解决问题的方式。概念对理论有用,对实践更有用。”
——Anthony Rose,Support Analytics公司总裁
“《深入浅出数据分析》写得漂亮,读者可以学到分析现实问题的系统性方法。从卖咖啡到开橡皮玩具厂,再到要求老板涨工资,此书告诉我们如何发现和解密数据在日常生活中的强大作用。从图形图表到Excel和R计算机程序,《深入浅出数据分析》想尽办法让各个层次的读者都体会到系统化的数据分析对于制定大大小小的决策的强大作用。”
——Eric Heilman,乔治敦预备学校统计学教师
“被堆积如山的数据压得喘不过气了?让Michael Milton做你的老师吧,在办公工具里添上数据分析工具,抢占技术先机。《深入浅出数据分析》将告诉你如何将原始数据转变成真正的知识。别再抽签算卦了——几套软件,一本《深入浅出数据分析》,就能让你做出正确的决策。”
——Bill Mietelski,软件工程师
深入浅出系列图书美誉
“Kathy和Bert合著的《深入浅出Java》(Head First Java )让白纸黑字摇身一变,成为读者领略过的最接近GUI的作品。作者以幽默、新潮的风格,让学习Java成为不断追问‘他们接下来打算怎么办呢?’的愉快体验。”
——Warren Keuffel,《软件开发杂志》
“《深入浅出Java》(Head First Java )引人入胜的风格会把一无所知的你变成斗志昂扬的Java战士,不仅如此,书中还收入了大量实用事例,这样的实用事例在其他文章中只会留给恐怖的‘读者练习’。此书睿智、幽默、新潮而实用——能在讲授对象序列化和网络加载协议知识的同时有这样的主张并坚持做到的书籍并不多见。
——Dan Russell博士,IBM Almaden研究中心用户科学和用户体验研究室主任(兼斯坦福大学人工智能教师)
“此书明快,风趣,玩世不恭,引人入胜。细心读——你可能确实能学到东西!”
——Ken Arnold,曾任Sun Microsystems高级工程师,与Java创始人James Gosling合著《Java编程语言》( The Java Programming Language )
“如醍醐灌顶,脑海中堆积如山的书本知识一下子消化了。”
——Ward Cunningham,维基百科发明人,Hillside Group创立人
“正合我们这些喜欢研究技术、生活随意的程序员的口味,实用开发策略的称手参考书——让我的大脑尽情运转,无须硬着头皮应付迂腐乏味的专家说教。”
——Travis Kalanick,Scour网站和Red Swoosh网站创始人,获麻省理工学院TR100(《技术回顾》世界百名青年创新学者)称号
“有的书是用来买的,有的书是用来藏的,还有的书是用来摆在案头的。感谢O'Reilly和Head First的员工,他们出了最高等级的书——深入浅出(Head First )系列,让人爱不释手、百读不厌。《深入浅出SQL》(Head First SQL )是我最心爱的书,都快翻烂了。”
——Bill Sawyer,Oracle公司ATG课程经理
“本书的透彻、幽默和睿智令人钦佩,连编程门外汉也能借助这样的书想出办法解决问题。”
—— Cory Doctorow,博客网站BoingBoing撰稿人合作编辑,著有《魔法王国的故事》( Down and Out in the Magic Kingdom )及《人来人往的城市》( Someone Comes to Town,Someone Leaves Town )
“昨天收到书就开始读……一读就停不下来了,真是酷毙了。书很有趣,内容扎实,切中肯綮。印象太好了。”
——Erich Gamma,IBM 杰出工程师,《设计模式》( Design Patterns )合著者
“我读过的最有趣、最高明的软件设计图书之一。”
—— Aaron LaBerge,ESPN.com技术副主席
“过去要犯着错误摸索前进的漫长学习过程,现在干净利落地浓缩在一本迷人的平装书中。”
——Mike Davidson,Newsvine,Inc. 首席执行官
“每一章都凝聚着优雅的设计,每一条原理无不饱含实用价值与闪光智慧。”
——Ken Goldstein,迪斯尼在线执行副总裁
“我♥《深入浅出HTML + CSS & XHTML》(Head First HTML with CSS & XHTML )。它以‘有趣’的模式,将全部知识倾囊相授。”
——Sally Applin,UI设计师、艺术家
“通常,阅读设计模式方面的书或文章时,我都得头悬梁锥刺股才能保证注意力集中。这本书却是个例外,听起来可能有点怪,这本书让学习设计模式变得盎然有趣。
“当其他设计模式方面的书籍还在教读者呀呀学语时,这本书却已在踏浪高歌‘加油,兄弟!’”
——Eric Wuehler
“我实实在在爱这本书。不瞒大家说,我当着老婆的面亲了这本书。”
——Satish Kumar
O'Reilly其他相关图书
Analyzing Business Data with Excel
Excel Scientific and Engineering Cookbook
Access Data Analysis Cookbook
O'Reilly深入浅出系列其他图书
Head First Java
Head First Object-Oriented Analysis and Design (OOA&D)
Head First HTML with CSS and XHTML
Head First Design Patterns
Head First Servlets and JSP
Head First EJB
Head First PMP
Head First SQL
Head First Software Development
Head First JavaScript
Head First Ajax
Head First Physics
Head First Statistics
Head First Rails
Head First PHP & MySQL
Head First Algebra
Head First Web Design
Head First Networking
谨将此书献给我的祖母Jane Reese Gibbs
作者简介

Michael Milton将自己的大半职业生涯献给了非盈利机构,帮助这些机构解析和处理从赞助人那里收集来的数据,提高融资能力。
Michael Milton拥有新佛罗里达学院哲学学位及耶鲁大学宗教伦理学学位。多年来,他博览群书,这些书籍虽字字珠玑,却枯燥乏味;蓦然抬首,深入浅出(Head First )系列图书让他眼前一亮,他欣然抓住机会,写出了这本同样字字珠玑,兼振奋人心的书。
走出图书馆和书店,人们会看到他在跑步、摄影,以及亲手酿制啤酒。
译者序
2010年2月,春节将至,我向博文视点的某个邮箱寄出了一封请求参加翻译任何一本图书的邮件。很快,有人回信了,内容简单明了:请下载并试译第1章1~17页内容。落款是博文视点编辑徐定翔。于是我试译,寄出,然后等待。春节过去了,一切都从节日的慵懒中苏醒过来——包括我的试译结果——它来了:通过。合作事项很快商定,工作就这样开始了。
如今已是2010年8月,稿件已如期交付,按照出版惯例,我可以占用一点篇幅,谈谈这本书。
正如O'Reilly出版社的Head First系列的其他图书那样,本书在语言组织、排版设计方面非常有特色,用“新颖”二字形容毫不为过,用“周到”二字形容也十分妥当。
其构思跌宕起伏,其行文妙趣横生,无论读者是职场老手,还是业界新人;无论是字斟句酌,还是信手翻阅,相信都能跟着文字在职场中走上几回,体味数据分析领域的乐趣与挑战。一本技术图书,在传道授业之外,又为读者送上了章回小说的精彩。
这些设计巧妙的“章回”生动地向读者展现了数据分析基本步骤、实验方法、最优化方法、假设检验方法、贝叶斯统计方法、主观概率法、启发法、直方图法、回归法、误差处理、相关数据库、数据整理技巧,此后意犹未尽,又以3篇附录介绍数据分析十大要务、R工具及ToolPak工具,在尽情展现目标知识以外,为读者搭建了走向深入研究的桥梁。
与我们司空见惯的很多书籍不一样,本书更愿意引导读者进行思考,而不愿向读者灌输现成的条条框框去禁锢读者的想象空间。在本书点到即止的启发下,读者很有可能跃跃欲试,急不可待地要把目光投向更宽、更深的知识领域,发掘更多的数据分析知识,以便早日成为数据分析达人。
文章字里行间流露出作者传道授业的热忱,以下仅举两例:
一是设法克服术语的障碍。这一点,英语使用者恐怕比中文使用者体会更深,层出不穷的英语术语甚至让以英语为母语的读者感到厌倦和头痛,作者深知这一点,于是尽量用浅显的语言表述,解除英语读者的心头之患;至于中文,感谢祖国语言的优秀特性,倘若作为译者的我没有在这里帮倒忙,术语方面的问题甚至可以忽略不计了(为方便读者审评,部分术语翻译对照表可在此下载:http://images.china-pub.com/ebook195001-200000/197047/shuyu.pdf )。
二是设法实现理论与实践的转化。理论如何向实践转化,一向是学习者的难题。然而本书精心构思的“章回”体裁,却让理论知识与实际操作水乳交融,职场气息扑面而来,除了谈分析,作者也谈经济、谈局势、谈心理、谈做人,涉猎广泛,面面俱到。
能够理解,作者希望这本书成为读者书架上的常备手册,在读者走进数据分析领域之初,或是遇到从业疑难时,提供力所能及的帮助。我也如此希望。
最后,请容我借本序致谢:
感谢博文视点。
感谢徐定翔编辑对我的信任和指教。
感谢家人对我的理解和支持。
李芳
2010年8月
序言

本节回答一个热门问题:“作者为什么非要把这些东西写进一本讲数据分析的书里?”
谁适合阅读本书?
请先回答几个问题:
1 你觉得,数据中隐含了无穷的智慧,只要有合适的工具,就能利用这些智慧,对吗?
2 你想学习、理解和记忆如何创建靓丽的图形、试验假设条件、进行回归分析或整理混乱的数据,对吗?
3 你喜欢笑语喧哗的晚宴甚于枯燥、无聊的学术演讲,对吗?
如果以上问题全部回答“对!”——这本书适合你。
谁该和本书说拜拜?
请先回答几个问题:
1 你是一个经验老道的数据分析师,正在调查数据分析领域最前沿的课题,对吗?
2 你从未用过Microsoft Excel或OpenOffice calc,对吗?
3 你惧怕尝试新事物,宁可上山打虎也不愿标新立异,对吗?你认为要是用拟人的手法叙述控制组和目标函数,技术书籍就难免有失严肃,对吗?
只要有一个问题回答“对!”——你与本书无缘 。

[营销部捎话——只要有信用卡就可以买书哦。]
我们了解你在想什么
“这怎么能是一本严肃的数据分析图书呢?”
“这些图都是用来干嘛的?”
“我真能这样学数据分析吗?”
我们了解你的大脑在想什么

你的大脑渴望新事物。大脑总是不停地搜索、探查、等待 不同寻常的事物,它天生如此,这正是你活力的来源。
那么,大脑怎么对待你所碰到的常规、普通、一般的事情呢?——它会竭尽全力阻止这些事情,以免干扰自己真正的 工作——记录重要 事项。大脑不会费力保存这些琐事;这些琐事从来不会成功地闯过“明显不重要事项”的关卡。
你的大脑如何知道 哪件事重要?假想有一天你出门旅行,迎面扑来一只吊睛白额大虎,你的头脑和身体会有什么反应?
神经元发动……情绪激动……化学物质激增
于是,你的大脑知道——
这事绝对重要!记住!

但,想像你是呆在家里,或者是呆在图书馆里,也就是说,是在一个安全、温暖、没有老虎的地方。
你正在复习迎考,要不然就是在努力弄明白一些艰深的技术,你的老板认为花个把星期就能搞定,顶多十天。
唯一的问题是:你的大脑想好好帮你一把,它试图保证不让这种“明显 不重要”的内容去破坏珍稀的资源,这些珍稀的资源最好用来保存真正“重大 ”的事情,像老虎啊,像火灾险情啊,像你绝不该在大学生网站Facebook的网页上贴上那些聚会照片啊。没有什么便当的办法可以告诉大脑“喂,大脑,我对你感激之至,可惜啊,不管这本书多无聊,也不管我的情感地动仪如何纹丝不动,我真的 希望你把这些材料都记住。”
我们认为该系列图书的读者都是学习者 。
既然要学习,怎样才能学会呢?首先,你得搞懂,然后,切勿遗忘;一字一句硬塞不是办法。根据最新的认知科学、神经生物学及教育心理学研究结果,学习远不仅仅是读书认字。Head First 知道怎么让你的脑筋动起来。
下面是部分深入浅出( Head First )教学原则:
将知识图形化。 图形比单调的文字好记得多,可以提高学习效率(记忆学习和转移学习的学习效率最多能提高89%);图形还能让知识更容易理解,相比将文字放在页脚和下一页,将文字放在相关图形当中或图形周围, 学习者成功解决相关问题的可能性将成倍增长。
采用对话式的个性化风格。 最近的研究表明,要是回避一本正经的语气,代之以对话般的风格,以第一人称平易近人地给学生上课,学生的课后测验成绩最多可提高40%。多讲几个故事,少来一点高谈阔论,语气宜随和。别太郑重其事。想想看,一局笑语喧哗的晚宴和一场演讲,哪一样更让你惦记?
引导读者深入思考: 换句话说,除非读者主动调动自己的神经元,否则脑袋里不会发生什么大变化。只有激发读者的兴趣,引起读者的好奇,刺激读者的灵感,读者才能解决问题,得出结论,获得新知识。为此,讲授者要设计各种难题、练习,提出引人深思的提问,还要多让读者做一些让左右脑半球和多种感官都动起来的活动。
牢牢吸引读者的注意力。 大家都有这样的体验——“我是真想学,但看完第一页就晕了”。大脑注意的是不同寻常的、有趣的、奇怪的、引人注意的、出人意料的事情。学习一种新颖艰深的技术不一定非得枯燥不可,如果它不是这样乏味,大脑会学得更快。
影响读者的情感。 现已知道,人的记忆能力在很大程度上取决于要记忆的内容对情感的影响。我们关心什么,就会记住什么;我们对什么事有感觉,就会记住什么。这里讲的情感并非天灾人祸给人带来的撕心裂肺的伤痛情感,而是惊讶、好奇、感觉有趣、想追根究底之类的情感,以及在猜对一个字谜、在学会别人感觉难以学会的事情或是在意识到自己懂的东西居然比工程部那位开口闭口“我比你有技术”的张三还多时,油然而生的“我是老大”的感觉。
元认知:对思考的思考

如果真想学东西,而且想学得更快更深入,就要关注自己如何集中注意力。要思考自己的思考方式;研究自己的研究方式。
大多数人在成长过程中都不曾学习元认知和学习理论方面的知识。人们期望 我们学知识,但极少有人教 我们如何学。
但想象得到,捧着本书的你,的确想学习数据分析知识,同时可能不想花费太多时间。要想利用在本书中读到的知识,就得记住读过的知识,为此必须理解 这些知识。为了淋漓尽致地发挥本书或任何 书本或学习经验的作用,请管好你的大脑,请管好大脑对待本书的态度。
诀窍在于让大脑把正在学习的新资料当做“正经大事”——对幸福至关重要的大事,像老虎一样重要的大事。若非如此,你就会陷入一场持久战:你竭力要记住新知识,大脑却竭力要把这些新知识踢出去。
既然如此,如何让大脑像对待吃人的老虎一样对待数据分析知识呢?
有两种办法,一种缓慢而乏味,一种迅速而有效。慢办法是简单记忆。你显然明白,只要不停地把同样的东西往大脑里灌,即使是最乏味的知识,也能学会、记牢。只要重复灌的次数足够多,大脑就会想:“这些东西给他的感觉 并不重要,但他不停地看这些相同的东西,一遍,一遍,再一遍。 因此我猜这些东西肯定很重要。”
快办法是做一切增进大脑活动 的事,尤其是不同类型 的大脑活动。上一页讲了很多这样的活动,事实证明,这些活动全都能促使大脑以有利于己的方式工作。例如,研究表明,将文字放在文字所描述的图片当中(相反的做法是将文字放在页面中的其他位置,如注释位置或正文位置),会促使大脑努力搞清楚文字和图片之间的关系,进而发动更多神经元。更多神经元发动=更有机会让大脑明白 某件事值得注意,可能还值得记住。
对话式的写作风格对此很有帮助。人们在与人对话时注意力会更集中,原因是别人期待他们有所表现。令人惊讶的是,大脑不一定会在意 “对话”是在人和书之间进行!反之,要是写作风格了无新意,乏味枯燥,大脑的感觉就和在挤满消极听众的屋子里听演讲没什么两样:没必要保持清醒。
不过,图形和对话式风格只是起步……
我们的做法
我们使用丰富的图片 ,这是因为,大脑追逐图像,而非文字。在大脑的活动中,一张图片胜过千言万语。当同时使用图片和文字进行说明时,我们将文字填写在图片当中,当文字出现在它所描述的事物当中 时,大脑的工作更有效率;相反,若将说明性文字放在注释或其他正文当中,则无此效果。
我们使用反复论述法 ,即以不同的 方式、通过不同的媒介对同一主题进行反复描述,给读者营造丰富的感受 ,目的是让这些主题有更多机会印在大脑的多个区域。
我们以出人意料的 方式叙述概念和使用图片,因为,大脑追逐新鲜事物;我们在图片和创意中或多或少加入了一些情感性 的内容,因为,大脑关注情感的生物化学反应。让人有所感触 的东西更可能让人记住,即使这点感触不过是一丝幽默 、一丝惊讶 或一丝兴趣 。
我们使用个性化的对话式写作风格 ,因为,当大脑认为你是在进行对话而不是在消极地听报告时,就会调整到注意力更集中的状态。即使在读书 时,大脑也是这个习惯。
我们安排了80多个活动 ,因为,相比读 书,在做 事时,大脑经过调整,能学会和记住更多东西。我们安排的练习有难度,但不会让人束手无策,这正是大多数人愿意做的练习。

我们使用多种教学风格 ,因为,有的人 可能喜欢一步一步按顺序来,有的人可能喜欢先看懂大图,还有一些人可能只想看看例子。我们将以多种方式反复讲述相同的主题,不管读者的个人爱好如何,他们都 将因此受益匪浅。
我们安排了让左右脑半球 分别负责的内容,因为,大脑开动部位越多,就学得越多,记得越多,注意力更持久。由于一侧大脑工作往往意味着另一侧大脑得到休息,左右半脑的分工合作使得长时间学习的学习效率得到提高。
我们还安排了一些场景 和练习,在场景中展现不同的观点 ,因为,当大脑被迫进行评估和判断时,会调整到深入学习状态。
我们在练习中安排了一些难点 ,即提出一些无法简单回答的问题 。因为,你的大脑在不得不处理 某件事情时,会调整到学习和记忆状态。开动脑筋吧,“光看 别人做运动无法让自己体态 健美”。别担心,我们尽力保证,你努力学习的都是该学的,你不会为了对付一个费解的例子或为了分析一段用词过于晦涩或行文过于简练的段落而多用一个脑细胞 。
我们以人物 为例,把人物安排在场景、实例、图片等内容中。至于原因嘛,因为你是 人群中的一员啊,你的大脑对人 比对事 更关注。
你的任务:征服大脑
我们的工作到此为止,剩下的就看你的了。从下面这些提示出发,顺从大脑的判断,看看哪些对你有用,哪些对你没用,尝试一下新事物吧。
把这张图剪下来,贴在冰箱上。
1 慢慢读。理解的内容越多,要记忆的内容越少。
忌死读 。停一停,想一想,碰到书中的提问时,别直接翻看答案;想象真的有人在问你这个问题。强迫自己的大脑想得越深,学会、记住的概率就越大。
2 自己做练习,自己记笔记。
我们安排了练习和笔记,但是,要是我们替你完成,就像让别人替你锻炼身体一样;只动眼不动手也不可取,要动动笔 。大量证据证明,学习时的身体动作能提高学习效率。
3 阅读“世上没有傻问题”部分。
世上没有傻问题。这些问题并非可看可不看,这是核心内容的组成部分! 请勿忽略。
4 请将下面这段话作为最后一段床头阅读文字,或起码作为最后一段高深的床头阅读文字。
有一部分学习过程(尤其是短暂记忆转变为长期记忆的过程)发生在放下书本之后 ,大脑需要有自己的时间进行更多处理。如果在这段处理时间内学新东西,将会丢失一些刚学会的东西。
5 开口大声讨论。
说话会刺激大脑的其他部分。如果你正在努力理解一些知识,或者正在努力增加以后记住这些知识的概率,请大声说出这些知识。还有一种更好的做法,试着向别人大声解释这些知识。你会学得更快,可能还会发现一些阅读时不曾发现的名堂。
6 大量喝水。
充沛的体液会让大脑处于最佳工作状态,脱水(早在感到口渴前就会发生)则会让认知功能下降。
7 聆听大脑的声音。
留意你的大脑是否超负荷工作。若你发现自己开始心不在焉,或者刚刚读过的东西转眼忘记,就该休息。一旦过了某个学习点,哪怕拼命塞,也无法提高学习效率,反而有可能影响学习。
8 找到感觉。
大脑需要知道事情是否重要 。让自己融入各种场景,为照片设想旁注,就连抱怨一个并不好笑的玩笑,也比什么感觉都没有强。
9 勤加练习!
学会数据分析的唯一办法就是勤加练习,这正是本书的要求。数据分析是一门技术,精于此道的唯一办法就是大量实践。本书将给你带来大量实践机会:每一章中都有一个等待你解决的问题,千万别跳过这些问题不看——大量学习都发生在解决问题的过程中。我们为每一个问题提供了答案,要是卡了壳(有些细微之处很容易给人带来麻烦),别不敢看!不过,请尽量先解决问题再看答案,务必让你的办法行之有效,然后才继续看书中的下一部分内容。
自述
本书是经验之谈,并非参考书籍,我们故意抽掉了会妨碍讲述书中相关知识的东西。本书对你已经见识过和学习过的知识作了一些假设,因此第一次通读本书的时候,需要从头读起。
本书并非软件工具指导书。
许多以“数据分析”为题的图书都是顺着Excel函数表把认为和数据分析有关的部分一路讲下去,然后针对每个函数给几个实例。但《深入浅出数据分析》讲的是如何成为数据分析师 ,尽管你在本书中会学到相当多的软件工具,但它们不过是手段而已,目的是学习如何进行出色的数据分析。
我们希望你懂得如何使用基本的电子表格公式。
用过电子表格的SUM求和公式吗?要是没用过,你可能先要突击一下才能开始学习本书。尽管许多章节根本不要求使用电子表格,但其他有此要求的章节却假定你会使用各种公式。要是熟悉SUM工具,那么你基础不错。
本书超越统计学。
本书充满统计知识,作为数据分析师,你应该尽量多掌握一些统计知识,读完《深入浅出数据分析》之后,最好再读一读《深入浅出统计学》(Head First Statistics )。不过,数据分析不仅涵盖统计学,还牵涉许多其他领域,本书中选用的非统计题材主要用于讲解来源于现实生活的具体、实用的数据分析经验。
活动并非可做可不做。
练习和活动不是点缀,而是本书的核心组成部分。这些练习和活动有的是为了帮助记忆,有的是为了帮助加深理解,还有的是为了帮助应用所学知识,切勿忽略 。
反复论述是刻意而重要的安排。
深入浅出系列图书有一个明显特色:我们希望你真正 掌握学到的知识,我们希望你在看完本书的同时就记住学到的知识。大多数参考书都不把记忆和回忆当做一个目标,但本书的目标是学会 ,所以,常常会看到同一概念多次出现。
本书意犹未尽。
我们乐于看到你在书籍合作网站上找到更多实用而有趣的资料,下列网站可为你提供这些资料:
http://www.headfirstlabs.com/books/hfda/.
“动动脑”练习没有答案。
有一些“动动脑”练习没有标准答案;另有一些练习可以参考“动动脑”活动的学习经验部分判断自己的答案是否正确,以及在什么情况下会正确。部分“动动脑”练习给出了提示,为你指明正确方向。
技术顾问组

技术顾问:
Eric Heilman ,美国乔治敦大学沃尔什外交学院优秀毕业生,国际经济学学位。在哥伦比亚特区读大学期间,曾在美国国务院和白宫国家经济委员会工作。他在芝加哥大学完成经济学毕业论文,目前在位于美国马里兰州贝塞斯达(Bethesda)的乔治敦大学预备学校任统计分析和数学教师。
Bill Mietelski ,软件工程师,三度担任深入浅出(Head First )技术顾问。他急不可待地想给自己的高尔夫技术做个数据分析,好在球场上一领风骚。
Anthony Rose ,在数据分析领域从业近十年,目前任Support Analytics公司总裁、数据分析及图表顾问。Anthony拥有财务与管理专业工商管理硕士学位,他对数据分析的热爱由此开始。工作之余,他常常出现在马里兰州哥伦比亚市的高尔夫球场上,陶醉在好书中,品味着美味的葡萄酒,或者和年幼的女儿们及迷人的妻子一起消磨时光。
致谢
我的编辑:
Brian Sawyer ,一位不可思议的编辑。和Brian一起工作就像和舞蹈家共舞,各种各样重要的工作纷至沓来,虽令人不十分理解,看上去却很不错,让人干得兴高采烈。我们的合作振奋人心,他的支持、反馈和创意是无价之宝。

O'Reilly团队:
Brett McLaughlin 一开始就看到了这个项目的前途,引领项目走过艰难岁月,始终如一地支持项目。Brett孜孜不倦地强调你 对深入浅出(Head First )书籍的体验,让人备受鼓舞。他运筹帷幄。

Karen Shaner 提供后勤支持,在剑桥寒冷的清晨给我们带来很多快乐。Brittany Smith 贡献了一些非常棒的图形元素,供我们反复使用。
给我启示的睿智者:
本书有大量出色的创意,许多创意在以“数据分析”为题的书籍中颇不常见,但这些创意很少是我个人的独创。我从Dietrich Doerner、Gerd Gigerenzer、Richards Heuer、Edward Tufte等超级智星的的作品中汲取了大量经验。把他们的作品统统读一遍吧!“反查”(anti-resume)这个创意出自Nassim Taleb的《黑天鹅》(真希望他出第二部,带来更多创意);Richards Heuer 好心地给我回信讨论本书,还给我出了很多有用的主意。
朋友与同事:
感谢Lou Barr 为本书提供知识产权、职业道德、逻辑学及美学支持;Vezen Wu给我讲解关系模型;Aron Edidin在我大学求学期间曾赞助我学习一门超棒的情报分析课;我的牌友Paul、Brewster、Matt、Jon和Jason给我上了关于均衡使用启发法和最优化决策法的昂贵一课。

离开这些人我没法活:
技术顾问组 工作出色,他们揪出成堆的错误,提出大量建议,给予我巨大支持。在本书撰写过程中,我对一位心思缜密的统计师——我的朋友Blair Christian 依赖甚深,书中每一页都能看到他的影子。谢谢你为我做的一切,Blair。
我的家人Michael Sr.、Elizabeth、Sara、Gary 和Marie 给了我巨大的支持,尤其要感谢我的妻子Julia的坚定支持,她是我的一切。谢谢我的全家!

1 分解数据
数据分析引言

数据无处不在。
如今,不管是不是自称数据分析师,人人都得处理堆积如山的数据。熟谙一切数据分析技术方法的分析者会比其他人技高一筹 :他们知道如何处理 所有的数据材料,如何将原始数据转变成推进现实工作 的妙策,如何分解和构建 复杂的问题和数据集,进而牢牢把握工作中的各种问题的要害。
Acme化妆品公司需要你出力
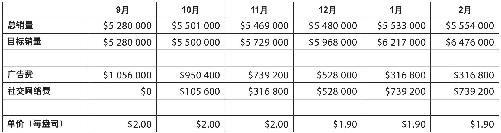
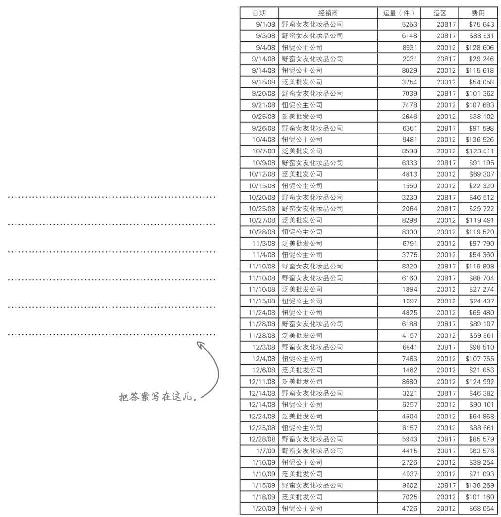
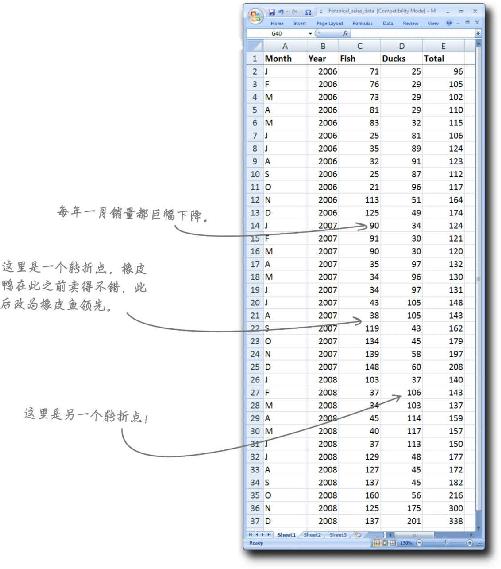
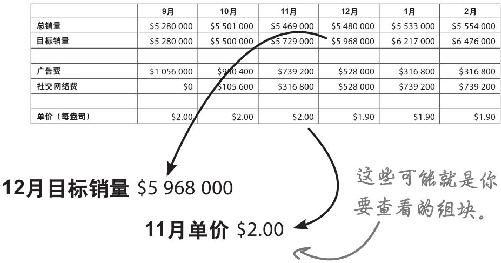
这是你走上数据分析师岗位的第一天,刚刚收到了首席执行官发来的销售数据,需要查阅一下。数据反映了Acme公司旗舰产品——貌洁超强保湿霜的销售情况。
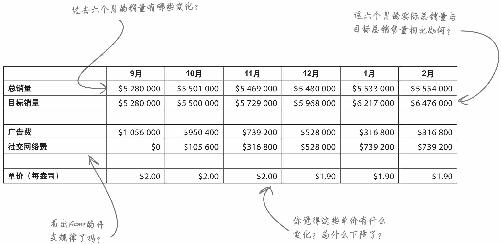
看看这些数据,不必抽丝剥茧——只要放慢速度就行。
看出什么了吗?表格让你对Acme的业务了解了多少?对Acme的貌洁超强保湿霜了解了多少?
优秀的数据分析师总想看到 数据。
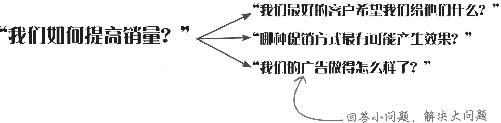
首席执行官希望数据分析师帮他提高销量
他希望你“帮他分析分析 ”。
这要求很含糊 ,不是吗?听起来挺简单,可你的工作会那么顺吗?不错,他希望提高销量;不错,他认为这些数据中有些东西能帮助实现这个目标。可到底是哪些东西呢?怎么帮呢?

动动脑
想想首席执行官主要想从你这里得到什么,同时思考这个问题:做数据分析到底意味着什么?
数据分析就是仔细推敲证据

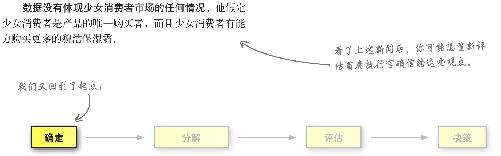
但是,所有优秀的分析师,无论专长及目标如何,都会在工作过程中按顺序执行下面这个固定基本流程 ,同时通过经验数据来仔细推敲各种问题。
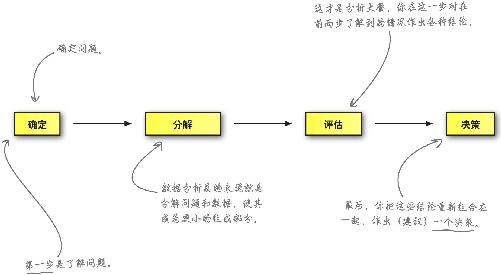
在本书的每一章中 ,你会一次又一次地按顺序执行这些步骤,很快,这些步骤就会完全成为你的第二本能。
所有的数据分析师最终都会被打造成能作出更好决策 的人才,你要学的就是在浩如烟海的数据中洞察先机,作出更好决策。
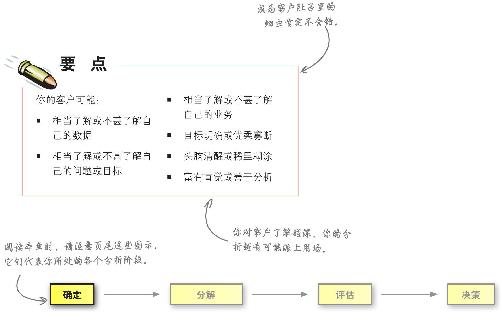
确定问题
未明确 确定自己的问题或目标就进行数据分析就如同未定下目的地就上路旅行一样。
当然,您可能会碰到一些有意思的现象,有时还可能盼着能兜来兜去地撞上点好东西,但是,谁会说你将有所发现?
见过长达百万页 、图表不计其数的分析报告吗?
偶尔,分析师的确会需要几百张纸或一小时的幻灯片来阐述一个观点,但如此一来,分析师常常不够注重 自己要解决的问题,他们抛给别人一些信息,借此推卸自己解决问题 和建议决策 的义务。
有时情况更糟糕:问题根本没有确定下来,而且分析师不想让别人意识到他只是在数据中兜圈子。
你如何确定问题?
客户将帮助你确定问题
客户是分析结果的服务对象。你的客户可能是你的上司、你所在公司的首席执行官,或甚至就是你本人。
客户将根据你的分析作决策,你需要尽量从他那里多了解一些信息,才能确定问题 。
本文中这位首席执行官想提高销量,但这只是最初答案。你需要更多更确切地摸清他的心思,才能拟定一个能够解决问题的分析方案。

世上没有 傻问题
问: 我总是在数据里兜来兜去。您是说我得先在脑子里有些特定的目标,才能哪怕只是过一眼我的数据?
答: 没必要先在脑子里形成问题才去浏览数据。但要记住,仅仅过一眼 并不是数据分析。数据分析总的来说就是认清问题,以及继而解决问题。
问: 我听说过探索性数据分析,就是从数据中找出一些可能想进一步进行评估的点子。这种数据分析方法中并没有什么“问题确定”步骤!
答: 确实有这种分析方法。在探索性数据分析中,问题就是要找到一些值得进行测试的假设条件,这完全是个具体问题。
问: 很好。给我多讲讲对自己的问题不甚了解的客户吧。那种人也需要数据分析师吗?
答: 当然!
问: 听起来似乎那种人更需要专业帮助。
答: 的确如此,优秀的数据分析师帮助客户思考自己的问题;他们不会等着客户告诉他们该做什么。要是有人能够向客户指出他们毫无察觉的问题,客户会真心诚意地感谢此人。
问: 听起来挺傻。谁想多搞出些问题?
答: 聘用数据分析师的人认为,具备分析技能的人能够改善他们的业务。有些人把问题视为机会,而向客户指出如何发现机会的数据分析师则能让客户赢得竞争优势。
动动笔
总体问题是我们需要提高销量。为了更好地摸清这位首席执行官的真正意图,你想问这位首席执行官什么问题呢?写出5个问题。
Acme公司首席执行官给了你一些反馈
这份邮件对你的问题进行了答复。其中有很多知识点……

把问题和数据分解为更小的组块
数据分析的下一步就是把从客户那里了解到的问题和手头的数据放在一起,把这些问题分解为颗粒 级的小问题,让它们在分析时发挥最大作用。
![]()
将大问题划分为小问题
你需要将问题划分为可管理、可解决 的组块。你面对的问题常常含糊不清 ,例如:
你无法直接回答大问题。但是,通过回答从大问题分解 出来的小问题,你就可以找到大问题的答案。
将数据分解为更小的组块
数据的处理也是如此。人们无意告诉你你所需要的精确答案的量化值,你必须自己提炼重要的因子。
如果你拿到的是汇总 情况,就像Acme给你的那些数据,你就会想知道哪些因子对你至关重要。

让我们给分解工作来个特写……
现在再来看看了解到的情况
让我们从数据开始。你手头有一份Acme销售数据汇总,尝试分解最重要因子的最好起步办法是找出高效的比较因子。
找到感兴趣的比较对象,分解汇总数据。
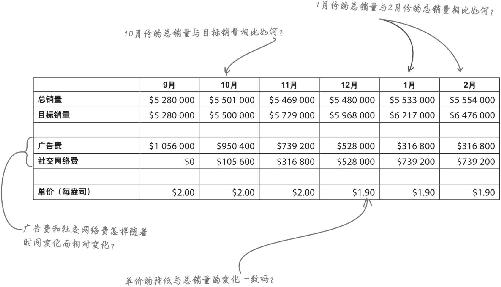
进行有效的比较是数据分析的核心,本书通篇都在讲述这个工作。
在这个案例中,你想通过比较各项汇总数据在脑子里形成一个概念 ,即Acme公司的貌洁超强保湿霜业务是如何开展的。
![]()
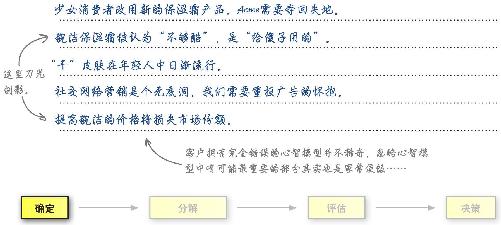
你已经确定了问题:想出提高销量的办法 。但通过这个问题几乎无法知道别人对你的工作期望,于是你从首席执行官那里搞到了大量有用的言论。
这些言论给出了关于如何开展化妆品业务的重要基准假设 。希望首席执行官关于这些假设的看法是正确的,因为它们将是分析的基础 !首席执行官的论点里最重要的有哪些呢?

动动笔
根据你所得到的分析数据,总结一下客户确信无疑的观点以及你的想法。分析以上邮件和你的数据,将它们分解为能够描述你的现状的更小的组块。
动动笔解答
清点一下你和客户确信无疑的观点。你发现了什么?
你对数据的想法
评估组块
好戏上场了。你知道需要想办法,你知道哪些数据组块能让你做到这一点。现在,仔细、专注地看看这些组块,形成自己的判断。
![]()
正如分解时一样,评估分解组块的关键就是比较 。
通过对这些因子进行相互比较,你看出了什么?

你几乎拥有所有合适的组块,唯独缺少重要的一块……
分析从你介入的那一刻开始
让自己介入分析的意思是作出自己的明确假设 ,并且以自己的信用为自己的结论打赌 。
无论你正在构建复杂的模型还是在作简单的决策,数据分析就是你的一切:你的信念,你的判断,你的信用。

在撰写最终报告的时候,一定要提到你自己,这样客户才知道你的结论出自何处。
![]()
提出建议
作为数据分析师,你的工作就是让自己和客户仔细研究你对数据的评估,洞察先机,从而有能力作出更好的决策 。
为了实现这个目的,你必须将自己的设想和判断以合适的格式整合起来,供客户拮取。
也就是说,你的作品要能简单则简单,但不可简单过头!你的工作是确保自己的意见传达到位 ,让人们根据你的意见作出正确的决策。
你提交给客户的报告要以得到客户理解、鼓励客户以数据为基础作出明智的决策为重点。
动动笔
看看你在前面几页搜集到的信息。
你建议Acme如何提高销量?为什么?
报告写好了
首席执行官会怎么想呢?
![]()
首席执行官欣赏你的工作

你的报告简炼、专业、直截了当
报告说清楚了首席执行官的需求,甚至比首席执行官本人说得更清楚。
你审视数据,通过首席执行官把事情弄得更明白,把首席执行官确信的观点和你自己对数据的理解相比较,然后提出决策建议。
干得好!
你的建议将给Acme的业务带来哪些影响?
Acme的销量会上升吗?
一则新闻

表面上来这对Acme是个好消息,但是,如果市场已经饱和,再多投广告可能就不会有太大效果。

很难想象少女消费者市场广告会有效 。要是绝大部分少女消费者每天都用貌洁保湿霜,而且用两次以上,销量还有机会提高吗?
你需要寻找别的机会提高销量,但首先需要搞清楚你的分析有何差池。
考考你
你在分析过程中得到了一些错误的或不完整的信息 ,使你对上述有关少女消费者的情况把握不准。是哪些信息不完整呢?
首席执行官确信的观点让你误入歧途
这是首席执行官嘴里的貌洁销售情况:

看看这些确信观点与数据的吻合情况,二者一致还是矛盾?所描述的内容有差别吗?
你对外界的假设和你确信的观点就是你的心智模型
在这个案例中,心智模型带来了问题,如果新闻报道是真实的,那么首席执行官关于少女消费者市场的确信观点就是错误的,而这些确信观点正是你用来解释数据的模型。
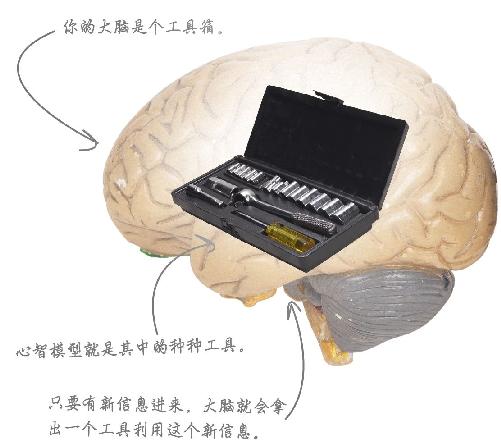
现实世界非常复杂,因此我们用心智模型 来理解现实。你的大脑就像一个工具箱,只要有新信息进来,大脑就会拿出一个工具利用这个新信息。
心智模型可能是一些与生俱来的先天禀赋,也可能是后天学会的理论,不管是哪种情况,都会大大影响 你对数据的解释。

心智模型有时助益良多,有时带来麻烦。本书就是你妥善利用心智模型的速成班。
重中之重是明确心智模型,并且像对待数据一样严肃认真地对待 心智模型。
务必尽量明确你的心智模型。
统计模型取决于心智模型
心智模型决定你的观察结果,是你观察现实的棱镜。
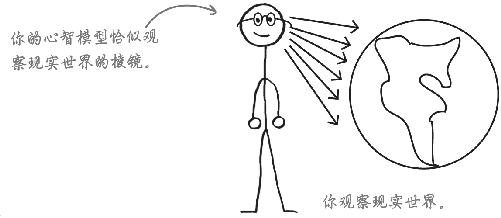
你无法看到一切 ,因此你的大脑必须做出选择,以便集中注意力,这就是所谓的心智模型大大决定观察结果 。
如果你了解 自己的心智模型,那么你发现重点、开发最相关最有用统计模型的可能性就更大。
你的统计模型取决于 你的心智模型,如果用了错误的心智模型,分析就会胎死腹中。
最好使用正确的心智模型!
![]()
动动笔
让我们再次审视这些数据,想一想,有没有其他的心智模型适合这些数据。
1 列出一些假设情况:若貌洁保湿霜的确是少女消费者喜爱的润肤品,则假设成立。
2 列出一些假设情况:若貌洁保湿霜处于在竞争中失去顾客的危险境地,则假设成立。
动动笔解答
你刚才用新眼光观察了汇总数据。不同的 心智模型该如何与之契合呢?
1 列出一些假设情况:若貌洁保湿霜的确是少女消费者喜爱的润肤品,则假设成立。
2 列出一些假设情况:若貌洁保湿霜处于在竞争中失去顾客的危险境地,则假设成立。
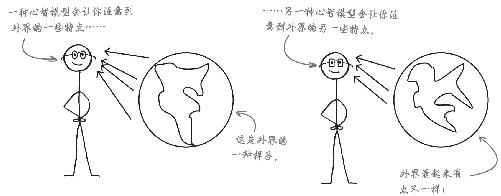
心智模型应当包括你不了解的因素
一定要指出不确定 因素,只要能明确不确定因素,你就会小心防范并想办法填补知识空白,继而提出更好的建议。
考虑不确定因素及盲点会让人感觉不爽,但回报显著。这种“反查”方法会揭示出未知 信息,而不是已知信息,例如,你要雇用一个舞蹈家,他不会跳的舞可能比会跳的舞更让你感兴趣。
数据分析也是如此,了解自己的知识缺陷非常重要。
未雨绸缪方能防备不测风云。
动动笔
为了搞清楚首席执行官不知道 的事情,你会问哪些问题?
首席执行官承认自己有所不知

还有谁可能买貌洁保湿霜?
除了少女消费者,有其他买家吗?
世上没有 傻问题
问: 首席执行官最后一句话挺搞笑:数据分析让人感觉自己所知甚少,这话不对吧?
答: 这要看你怎么对待。如今越来越多的问题能够通过数据分析技术解决,而在过去,人们要靠直觉来解决这些问题。
问: 所以和以前相比,心智模型越来越不可信了?
答: 许多由心智模型完成的工作都是为了帮助你填补信息空白。好的一面是,数据分析工具让你有能力以系统而自信的方式填补这些空白,因此,“指定大量不确定因素”这一做法的目的就是帮助你发现盲点,这要求拥有过硬的数据工作经验。
问: 但我非得用心智模型来填补“对外界的了解”这项知识的空白吗?
答: 确实如此……
问: 我这么说是因为,即使我目前对外界的运行规律了如指掌,但十分钟后外界就会变成另外一个样子。
答: 对极了。你无法无所不知,世界总是在不断变化,这就是严谨地指定问题并管理心智模型不确定因素之所以成为工作重点的原因。你只有那么些时间、那么些资源来解决分析问题,因此,回答上述问题将有助你有效率、有效果地完成工作。
问: 通过统计模型了解到的信息能为心智模型所用吗?
答: 当然能。今天的研究所发现的事实和现象往往成为明天的研究的假设情况。这样想:你不可避免地会从统计模型得出错误结论,人无完人嘛。当这些结论成为心智模型的一部分后,你希望它们突显出来,这样才能认明情况,以便在需要时回头改变这种结论。
问: 所以心智模型可以通过经验进行试验?
答: 对,而且应该进行试验。你无法试验每一件事,但可以试验模型中的每一件事。
问: 如何改变心智模型?
答: 你即将了解……
首席执行官下令搞来了更多数据,帮助你寻找少女消费者以外的市场。让我们看一看。
Acme给你发来了一长串原始数据
所获得的新数据若未经过任何处理,即称为原始数据 ,为了让他人提供的数据在你要进行的数据运算中发挥作用,几乎总是要调节数据 。
千万要保存原始数据 ,避免进行任何数据处理。即使是最好的数据分析师也会失误,必须能够将自己的工作结果与原始数据进行比较。

放轻松
数据多往往是好现象
在密集的数据中兜圈子很容易让人“迷路”,要是你迷失了目标,忘记了假设,只要集中注意力完成该完成的数据处理就能扭转局势,优秀的数据分析的根本在于密切关注需要了解的数据。
![]()
练习
好好看看这些数据,想一想首席执行官的心智模型 。这些数据符合所有顾客都是少女消费者的想法吗?还是看得出有其他的消费者?
练习解答
从数据中看出什么了?首席执行官“只有豆蔻年华的少女消费者才买貌洁保湿霜”的想法对吗?还是看得出有其他的消费者?
可以肯定地看到,Acme将产品卖给各家公司,这些公司再将产品卖给年轻的消费者。野蛮女友化妆品公司和忸怩公主公司看来肯定名副其实,可名单上还有一家经销商——泛美批发公司,单从名字无法看出其客户群,但可能值得调查一下。
深入挖掘数据
要看的数据很多,但任务很明确:找出除少女消费者以外购买产品的群体。
你发现了一家名叫泛美批发公司的公司,它是谁?谁买它的产品?
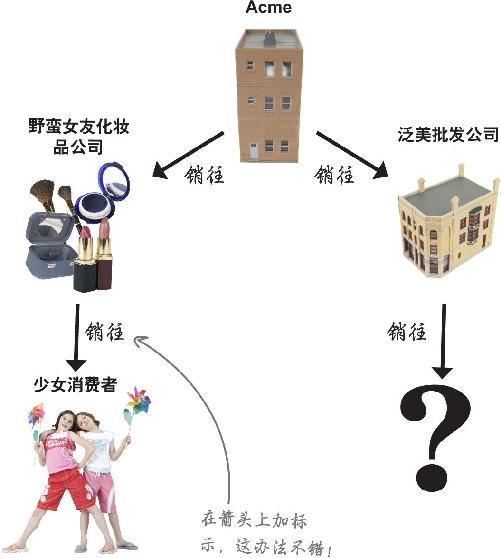
练习
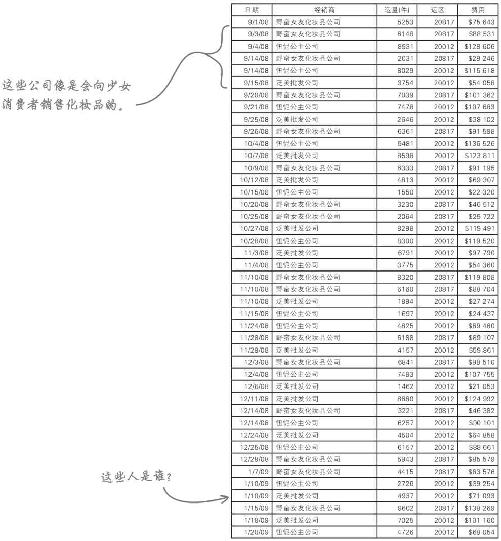
泛美批发公司应Acme的要求发来了这份貌洁客户明细表。这些信息能帮助你弄清楚谁在购买产品吗?
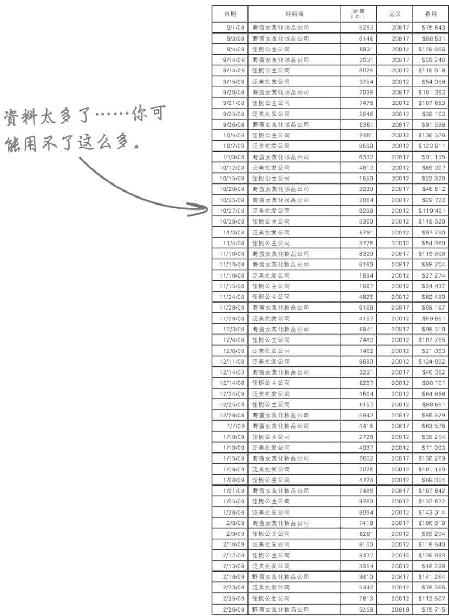
泛美批发公司貌洁保湿霜半年销售明细(至2009年2月)
练习解答
泛美批发公司的销售明细告诉你是谁在购买貌洁保湿霜了吗?
泛美批发公司貌洁保湿霜半年销售明细(至2009年2月)
看来是男人在买貌洁保湿霜!Acme原来的销售表没有显示出是男人在买保湿霜,但泛美批发公司却将貌洁保湿霜转卖给了剃须品经销商!
泛美批发公司确认了你的印象

这恐怕是大买卖。
看来,有一个群体在买貌洁保湿霜,而Acme竟还没有意识到。
一切顺利的话,就靠这个潜在群体提高Acme的销量了。
![]()

你已经进入分析冲刺阶段。
现在该写报告了。记住,让客户详细地浏览你的思考过程——你是如何得出这个看法的?
根据这个看法,你建议客户如何改进业务?这条信息如何能帮助他提高销量 ?
动动笔
心智模型有哪些改变?
有何证据证明你的结论?
有难以排解的不确定因素吗?
动动笔解答
你如何扼要复述你的工作?你对首席执行官提出了哪些建议以期提高销量?
一开始,我试图想办法提高少女消费者市场的销量,因为我们相信这些消费者是貌洁保湿霜唯一的客户群。当我们发现少女消费者市场已经饱和后,我深入挖掘数据,寻找提高销量的源泉。在这个过程中,我改变了心智模型,结果表明热衷于使用貌洁的人比我们意识到的要多——尤其是上了年纪的男人。由于这个消费群并不宣扬自己对产品的热衷,我建议大幅度增加对这个群体的广告宣传,用更易被男性接受的特色销售同样的产品,这将提高销量。
世上没有 傻问题
问: 如果为了解决问题而需要获得更详细的信息,我该做到什么程度呢?是不是要亲自去采访客户?
答: 对新数据的挖掘深度最终取决于你自己的最佳判断,在这个例子中,你不断摸索,终于找到了新的市场领域,这个发现足以让你制定有说服力的销售策略。我们将在后续章节中进一步讨论何时该停止搜集数据。
问: 看来,起初的错误心智模型是第一次分析失败的罪魁祸首。
答: 是啊,最初的错误假设注定了分析会得出错误的答案,因此,从一开始就务必要基于正确的假设建立模型显得如此重要,并且,要做好准备,一旦所得到的数据有违你的假设,就要立即回头重新详加思考。
问: 分析会有大结局吗?我所追求的是定论。
答: 数据分析肯定会得出重大问题的答案,但绝不会料事如神,即使你今天无所不知,明天又会有新情况。向年长男子促销的建议可能在今天是有效的,但Acme永远需要分析师为他们出点子抓销售。
问: 听起来挺没劲。
答: 恰好相反!分析师好比侦探,总有一些秘密等着他们去发现,这正是数据分析的乐趣所在!回顾问题、提炼模型、基于新模型观察外界,这些都是分析师工作的基本组成部分,并非特例,而是规律。
![]()
回顾你的工作
下面最后看一眼你所经历的所有步骤,目的是得出如何帮助Acme提高貌洁保湿霜销量的结论。

你的分析让客户做出了英明的决策
看了你的报告后,首席执行官迅即调动营销团队创建“须洁”品牌——无非就是“貌洁”保湿霜换个新名字罢了。
Acme旋风般地把须洁保湿霜推向老年男子市场,下面是结果:
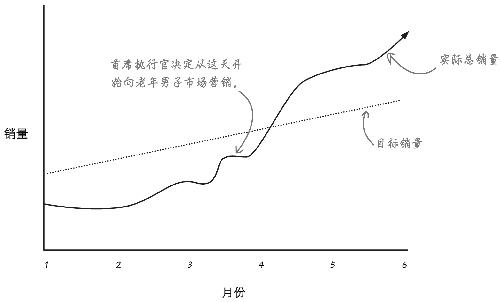
销量一飞冲天!两个月的销量超过了你在文章开头看到的所有目标销量。
你的分析出成果了!
![]()
2 实验
检验你的理论

你能向别人揭示自己坚信的信念吗?
正在进行实证 检验?做个好实验吧,再没有什么办法能像一个好实验那样,既能解决问题又能揭示事物的真正运行规律。一个好实验往往能让你摆脱对观察数据 的无限依赖,能帮助你理清因果联系;可靠的实证数据 将让你的分析判断更有说服力。
咖啡业的寒冬到了!
时局艰难,连星巴仕咖啡店 也在经历剧痛,那可一向是享受极品咖啡的去处。然而,在过去几个月里,实际销量与目标销量背道而驰,骤然下滑。
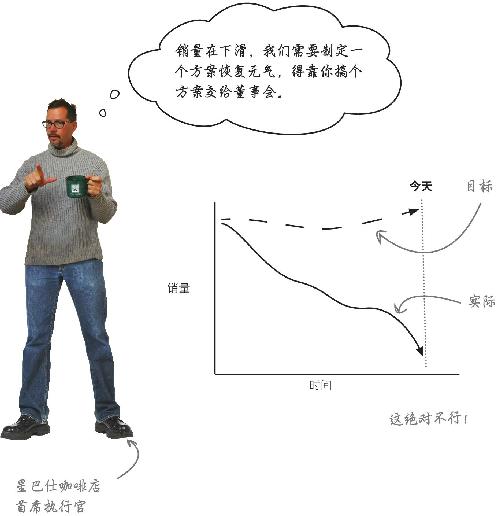
星巴仕首席执行官打电话把你叫来,让你帮忙想办法恢复销量。
星巴仕董事会将在三个月内召开
要在三个月内拿出一个扭转乾坤的方案,时间已不多,但必须如此。
我们不完全知道销量为何下降,但必定与经济环境有某种关系。无论如何,你得想出恢复销量 的办法。
该从哪儿着手呢?

动动笔
请看以下选项。你认为哪些做法会是最好的起点 ?为什么?
动动笔解答
为了想出提高星巴仕咖啡销量的办法,你认为哪种做法是最好的起点?
会见首席执行官,弄清楚星巴仕在如何进行商务运营。
肯定是个好起点。他在生意上足智多谋。
进行一次客户调查,弄清楚客户的想法。
能这样也不错。你得摸透客户的心思,让他们多买咖啡。
弄清楚目标销量是怎么计算出来的。
能弄清楚这一点很有意思,但恐怕这不是你该考虑的第一件事。
会见董事长。
真是不知深浅啊。你真正的客户是首席执行官,爬到他头上去是要冒风险的。
给自己泡一大杯热气腾腾的星巴仕咖啡。
星巴仕咖啡味道极棒,为什么不来一杯?
市场部每个月做一次客户调查。

人们在调查中的说法不一定符合他们的实际做法,但问问他人的感受总不会有坏处。

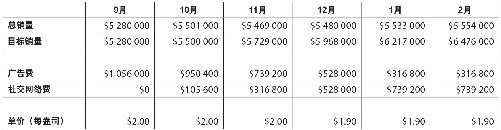
星巴仕调查表
这就是市场调查表:市场部每月对大量客户进行抽样调查。

你会怎样汇总这份调查数据?
务必使用比较法
统计与分析最基本的原理之一就是比较法 ,它指出,数据只有通过相互比较才会有意义。

这是一份2008年下半年市场调查汇总表 ,表中数字是各家分店参加调查的人对各个调查项给出的平均分。
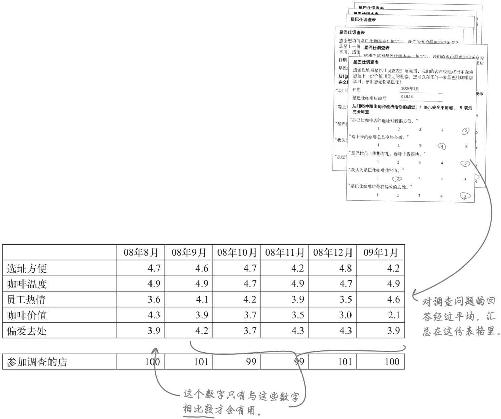
小心!
必须进行明确的比较。
如果一份统计数据看起来颇有意思,或看起来有用,你就需要针对这份统计数据与其他统计数据的比较情况,解释为什么会有这种作用。
如果不搞清楚这一点,就等于是在假设客户会自己进行这种比较,这会是一个不合格的分析。
比较是破解观察数据的法宝
比较越多,分析结果越正确 ,对于观察研究 尤其如此,星巴仕研究就是一例。

练习
查看对开页上的调查数据,比较几个月内的平均值。
注意到某种规律了吗?
有什么信息能说明销量下降的原因吗?
练习解答
现在你已经细细看过数据,可以找出数据蕴含的规律了。
注意到某种规律了吗?
除了“咖啡价值”,所有的变量都在有限的范围内波动。例如“咖啡温度”,最高得分4.9,最低得分4.7,波动不大。相反,“咖啡价值”则降幅巨大。12月得分是8月得分的一半,这是一个巨大的变化。
有什么信息能说明销量下降的原因吗?
这么说吧,如果一般人认为咖啡的价值与价格不相称,他们就不愿意在星巴仕多花钱。由于经济衰退,人们手头的钱少了,于是他们发现星巴仕咖啡并无出色的价值。
价值感是导致销售收入下滑的原因吗?
纵观这些数据,除了星巴仕咖啡价值感这个变量,星巴仕的顾客对其他方面都感觉良好。
看起来,星巴仕没有给人们物超所值的感觉,这可能是导致购买量下降的原因。也许经济环境让人们钱包变瘪了,于是他们对价格更为敏感。
让我们把这个理论称为“价值问题”。
星巴仕咖啡
这是2008年下半年市场调查汇总表。表中数字是在各家分店参加调查的人对各个调查项给出的平均分。
动动脑
你认为感知价值的下降是销量下降的原因吗?
世上没有 傻问题
问: 我怎么知道价值下降确实会导致咖啡销量下降?
答: 你没法知道。但目前只有感知价值数据与销量的下降相吻合。销量和感知价值看起来像是在并肩下落,但你无法确定是价值的下降导致了销量的下降,目前,这只是理论上的判断。
问: 会不会有其他作用因素?可能价值问题并不像看上去那么简单。
答: 几乎可以肯定会有其他因素在起作用,使用观察研究方法时,应当假定其他因素会混杂你的结论,因为你无法像控制实验那样控制这些因素。后面几页会进一步讨论这些行话。
问: 会不会正好相反呢?可能正是销量下降让人们认为咖啡没有什么价值。
答: 问得非常好,很有可能正好相反。分析师们的一个很好的经验法则是,当你开始怀疑因果关系的走向时(如价值感的下降导致销量下降),请进行反方向思考(如销量下降导致价值感下降),看看结果怎么样。
问: 那么我如何看出是谁导致了谁?
答: 我们将在本书中大量讨论如何判定原因,但现在你该知道的是,当涉及判定因果关系时,观察研究法并不是那么强大有力。一般情况下,需要使用其他工具才能进行判定。
问: 听起来观察研究法没什么意思。
答: 完全不是这么回事!观察数据无所不在,要是因为观察研究法有不足之处就忽视这种方法,那可是疯了。真正重要的是,你要了解观察研究法的局限性,这样才不会得出错误的结论。

SoHo区的区域经理不同意
SoHo区是一个富人区,也是几家利润丰厚的星巴仕分店的所在地,负责这几家分店的经理不相信价值感问题的真实性。
你认为她为什么不同意?是她的顾客在说谎吗?是数据记录不正确吗?还是观察研究法本身有问题?
一位典型客户的想法

吉姆: 别把SoHo区星巴仕放在心上。那些家伙不知道怎么看数据,数据是不会撒谎的。
弗兰克: 我可不愿这么快下结论,有时候一线人员的直觉比统计数据更能说明问题。
乔: 完全正确。其实,我正想丢开所有的数据,有些东西看起来很可疑。
吉姆: 你有什么特别的理由认为这些数据有问题?
乔: 我没理由。味道可疑?
弗兰克: 看,我们需要回头看看我们对典型客户或一般客户的释义。
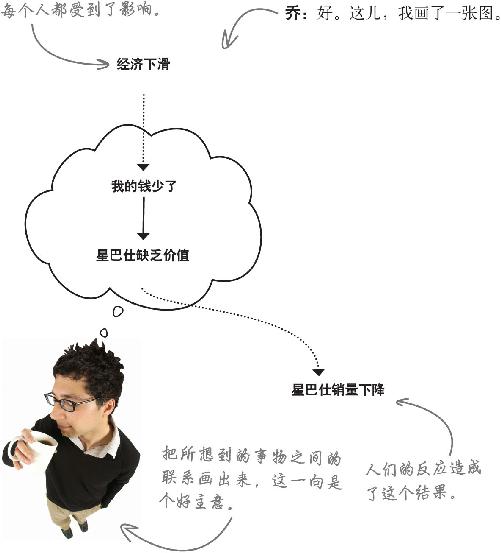
弗兰克: 这一连串的事情没有发生在SoHo区 居民的身上,有什么原因吗?
吉姆: 可能SoHo区的居民没受到经济环境的打击,住那儿的人富得冒油,还自私自利。
乔: 喂,我女朋友住在SoHo区。
弗兰克: 搞不懂你怎么说动这等风流人物和你约会的。吉姆,你可能说对了,要是有人理财能力强的话,可能就不那么容易相信星巴仕缺乏价值。
看起来,SoHo区星巴仕店的顾客可能和其他星巴仕店的顾客不一样 ……
观察分析法充满混杂因素
混杂因素 就是研究对象的个人差异,它们不是你试图进行比较的因素,最终会导致分析结果的敏感度变差。
在这个案例中,你对不同时间 段内的星巴仕顾客进行相互比较,星巴仕的客户显然互不相同——因为他们是不同的人。
但是,如果他们的相互差异表现在你力求了解的某个变量方面,这种差异就是混杂因素,本例中的混杂因素是店址 。
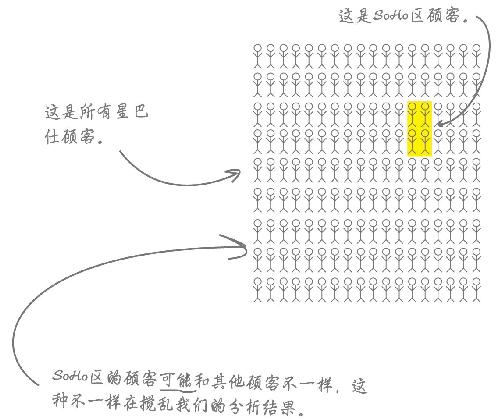
动动笔
重新绘制对开页中的因果图,将SoHo店和其他店分开,校正选址混杂因素 。
假定SoHo区区域经理是正确的,即SoHo区顾客并没有感受到价值问题。那么这种现象对销量有何影响呢?
店址可能对分析结果有哪些影响
这是一张经过重新整理的图形,图中表现了可能会发生的事情。用这样的图来形象地表示你的理论 ,的确非常棒,能让你自己和你的客户顺着你的思路去想。
考考你
怎样处理一下数据才能看出是否SoHo区星巴仕分店的价值感仍然良好?更概括地说,怎样处理一下观察研究数据才能让混杂因素得到控制?
世上没有 傻问题
问: 在这个案例中,的确是客户的财富而不是咖啡店的店址影响了分析结果吗?
答: 当然,而且这二者很可能有关系。如果你能得到每位顾客有多少钱的数据,或者能知道每位顾客花多少钱会感到舒坦,你就能再次进行分析,看出以财富为基础划分群组会得出什么结果。但由于我们无法得到这些信息,就只好使用店址。此外,由于我们的理论是越富有的人越愿意在SoHo区消费,因此店址能说明问题。
问: 除了店址,有没有别的变量可能混杂这些数据?
答: 肯定有。混杂因素是观察研究法绕不开的问题。作为分析师,你的工作就是不断考虑混杂因素对分析结果的影响。如果你认为混杂因素的影响微不足道,很好;但如果有理由相信这些混杂因素正在引发问题,那么,你就需要相应调整自己的结论。
问: 如果混杂因素难以发现怎么办?
答: 这正是问题所在。混杂因素通常不会故意在你眼前晃悠。为了让自己的数据尽量有说服力,你需要自己动手把这些隐藏的混杂因素挖出来。在本例中,我们很幸运,因为地址这个混杂因素其实就在数据里,因此我们可以处理和管理这个数据。通常我们无法得到混杂因素信息,这会严重动摇整个分析的根基,让你无法得到正确结论。
问: 我要做到什么程度才算查清了混杂因素?
答: 这与其说是科学,莫如说是艺术。你不妨就自己正在研究的问题问自己一些常识性问题,借此想象哪些变量可能会影响你的分析结果。正如数据分析和统计学中的各种手段一样,无论你的量化技术多么出神入化,真正的重点却永远在于:分析结论要有意义 。只要结论有意义,而且你已经彻头彻尾地查找过混杂因素,那么你就已经做了观察研究法要求你做的一切工作。其他类型的分析,如后文所述,可以让你做出更大胆的结论。
问: 如果我研究的不是价值感而是其他对象,同样对于这些数据,店址是否不会成为混杂因素?
答: 完全正确。记住,只是在这个例子中,店址才是一个混杂因素,但在其他例子中可能并没有作用。例如,在这里我们没有理由相信“咖啡温度让人感觉恰恰好”这个因素在每个地方都不一样。
问: 我仍然觉得观察研究法有很多很严重的问题。
答: 观察分析法是有很大局限性。这种特别的研究方法的作用在于帮助你更好地了解星巴仕的客户,只要你控制好数据中的店址问题,研究就会更有说服力。
拆分数据块,管理混杂因素
为了控制 观察研究混杂因素,有时候,将数据拆分为更小的数据块是个好想法。
这些小数据块更具同质性 。换句话说,这些小数据块不包含那些有可能扭曲你的分析结果及让你产生错误想法的内部偏差。
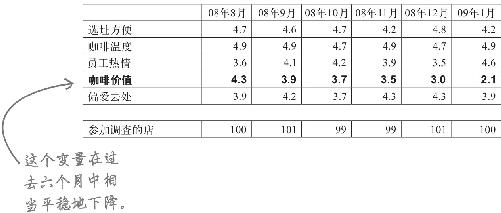
现在再来看看星巴仕的调查数据,这一次将其他地区的数据列在相应的表格里。
星巴仕咖啡店:所有分店
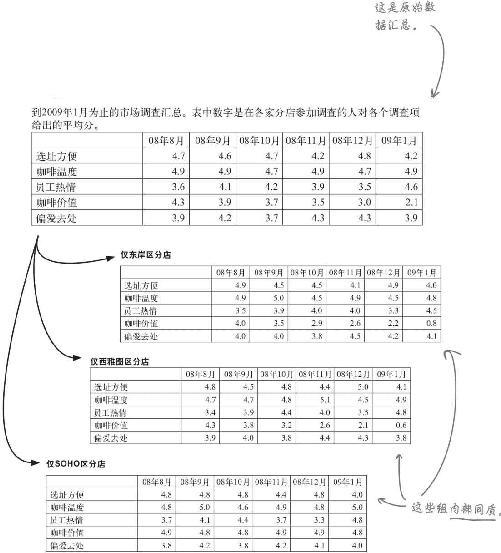
练习
请看对开页的分组数据。
东岸区分店平均得分和星巴仕所有分店平均得分有何差异?
将所有数据组的咖啡感知价值相互之间比较,情况如何?
SoHo区区域经理“客户对星巴仕咖啡感觉很好”的判断正确吗?
练习解答
查看已经按店址分组的调查数据,你能看出什么?
东岸区分店平均得分和星巴仕所有分店平均得分有何差异?
除了价值感得分,所有的分数都在同样窄小的范围内波动。与所有地区平均分相比,东岸区的价值感平均分一落千丈!
将所有数据组的咖啡感知价值相互之间比较,情况如何?
西雅图区和东岸区一样直线下滑。相反,SoHo区显得一切正常,SoHo区的价值感平均得分轻而易举地击败了所有区域的平均分,看上去这个区域的顾客非常满意星巴仕的价值。
SoHo区区域经理“客户对星巴仕咖啡感觉很好”的判断正确吗?
数据完全证实了SoHo区区域经理所坚信的顾客对星巴仕价值的想法。听取她的反馈并且因为她有这样的反馈而以其他方式观察数据,还真是个不错的主意。
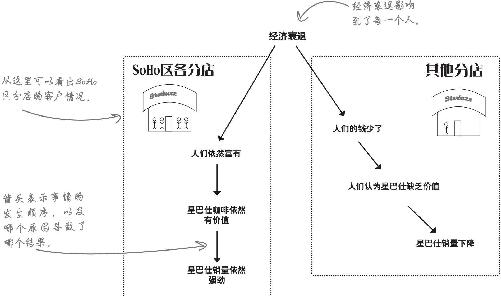
情况比预料的更糟!
为了解决你们所发现的问题,大人物们都行动起来了。

首席财务: 情况比我们预料的还糟糕,糟透了。除了SoHo区,各个区的价值感都已经彻底跌穿地板。
营销副总: 没错。第一张表体现了所有区的数据,确实让价值感看上去比实际的要好 。SoHo区把数据向好的方向扭曲了。
首席财务: 只要把人人都是富翁的SoHo区剥离出来,就可以看出SoHo区的顾客都对价格很满意,但其他顾客却都在徘徊中甩手离去。
营销副总: 所以我们要搞清楚该怎么办。
首席财务: 我来告诉你该怎么办——大减价。
营销副总: 什么?!?
首席财务: 你没听错,我们得大减价。这样人们就会觉得价值不错了。

营销副总: 我不知道你是从哪个星球来的,但我们得考虑品牌。
首席财务: 我来自商业星球,我们把这叫做供与求,你大概想回学校重修这些词的意思吧。减价,然后需求上升。
营销副总: 要是削减成本,短期内我们可能会看到销量回升,但会永远损失利润。我们需要想办法在价格不变的情况下说服人们:星巴仕有价值。
首席财务: 这是疯话。我现在说的是经济,钞票。有激励人们才有反应。你这种前怕狼后怕虎的想法是不会把我们救出困境的。
你手头的数据是否能让你明了哪种策略将提高销量?
你需要做一个实验,指出哪种策略最有效
请再看一下上一页最后一个问题:

你没有任何观察数据能够表明,如果试着照营销副总裁或首席财务官的建议去做,将会发生什么情况。
如果你想对与数据相符合但并未在数据中充分体现的事情做出结论,就需要用理论将它们联系起来。
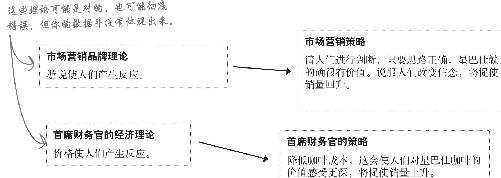
尽管这二位都狂热地相信自己的理论及根据这些理论制定的策略,你却没有数据支持任何一种理论。
为了进一步弄清楚哪种策略更好,你将需要做一个实验 。
你需要对这些策略进行实验,目的是了解哪种策略将提高销量。
星巴仕首席执行官已经急不可待

不管你是不是已经做好准备,他要动手了!
让我们看看他的战术怎么展开……
星巴仕降价了
在首席财务官的提示下,首席执行官下令所有分店在二月集体降价,所有星巴仕分店的咖啡价格统统降低0.25美元。

这种改变会引起销量暴增吗?何以见得?
一个月后……
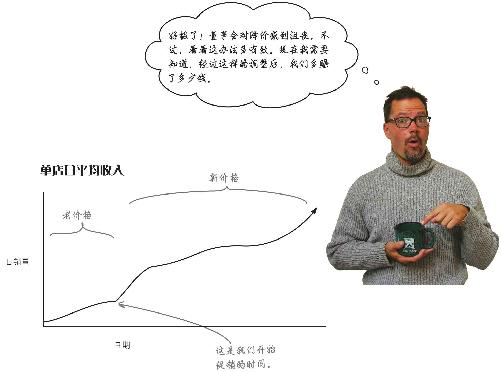
练习
要是能知道星巴仕二月份降价比不降价多赚了多少 就好了。你认为销量中有数据能帮助搞清楚这一点吗?为什么?
练习
销量中有数据能帮助你搞清楚价格调整到3.75美元以后多赚了多少钱吗?
销量中不会有这种数据,销量数据都来自3.75美元的咖啡售价,无法与假定数据——也就是4.00美元的咖啡售价产生的销售收入进行比较。
以控制组为基准
对于多赚了多少钱,你毫无头绪 。相对于“要是首席执行官未下令减价而本该产生的销量”,现在这个销量可能是暴涨,也可能是暴跌,然而终究难成定论。
难成定论的原因是,首席执行官下令集体降价,这违背了比较法 。好的实验总是有一个控制组(对照组) ,使分析师能够将检验情况与现状进行比较。
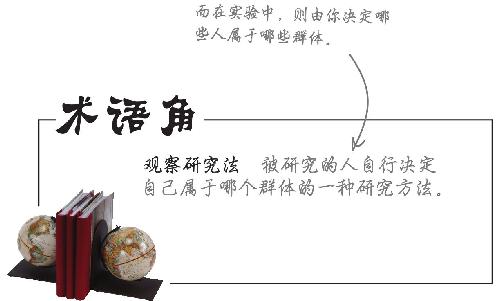
术语角
控制组( Control group ) 一组体现现状的处理对象,未经过任何新的处理(也称对照组)。
没有控制组就意味着没有比较,没有比较就意味着无法对所发生的情况进行判断。
世上没有 傻问题
问: 我们不能拿二月份的数据和一月份的数据进行比较吗?
答: 当然可以。要是你们感兴趣的只是二月份的销量是否比一月份的高,是能有答案的。但在不加以控制的情况下,这些数据无法体现其与价格下降的内在联系。
问: 拿今年二月份的数据和去年二月份的数据进行比较怎么样?
答: 你在这个问题和最后一个问题中谈到的都是历史控制法,这种方法取用过去的数据,并将这些数据作为控制数据;与此相反的是同期控制法,在这种方法中,控制组与实验组在同样的时期内经历同样的事。历史控制法通常偏向于你力图进行检验的对象的成功方面,因为很难选出和你所测试的组真正相似的控制组。总体上说,你应该对历史控制法表示怀疑。
问: 一定要用控制组吗?从来没有一个案例是不用控制组也行得通的吗?
答: 世上有很多无法控制的事。例如选举投票,选民不能同时选两个候选人,你不能先看看谁比谁进展更好,然后再回头去选更为成功的一位。虽说选举方式无法改变,却不表示不能一对一地分析各种迹象,但是,如果能够做一个与此类似的实验,就能对自己的选择更为自信!
问: 那医学试验怎么说?假设你想试用一种新药,并且相信这种药物非常有效,难道你不给分在控制组里的病人治疗,而任由他们生病或等死?
答: 这是一个考虑了法律伦理学的好问题。缺乏控制数据(或使用历史控制数据)的医学研究所青睐的疗法随后往往被同期控制实验表明没有效果或甚至有害。无论你对一种治疗方法的感情如何,除非做控制实验(对照实验),否则无法确定进行治疗是否比不进行任何治疗更有效。最糟糕的情况是,对于实际上于人有损的治疗,要停止推广。
问: 就像给病人进行放血治疗一样吗?
答: 对极了。历史上最早的控制实验中就有一些将放血疗法与让病人静养相比较。坦白说,使用了几百年的放血疗法让人厌恶极了,现在,因为做了控制实验,我们知道这是一种错误的疗法。
问: 观察研究法有控制数据吗?
答: 当然有。记住观察研究法的定义:这种研究方法让研究对象自己决定他们属于哪个组,而不是由研究者来决定。例如,如果想做一个关于吸烟的研究,你无法让某些人成为烟民或不成为烟民,决定是否抽烟的是人们自己。在这种情况下,选择不做烟民的人就是你观察研究法中的控制组。
问: 我经历过各种各样的情况,销量都在一个月内上涨,据说是由于我们上一个月做的一些工作,而且,因为别人说我们做得不错,大家都感觉良好。但你现在却说我们对自己做得是好是坏完全没有头绪?
答: 你们可能是做得不错。商业生活中免不了有凭直觉办事的时候,有时你无法控制实验,必须依赖基于观察数据的判断。但是,只要能做实验就做吧。在下决定的时候,再没有比可靠的数据更能为你的判断和直觉提供补充了。在这个例子中,你还没有得到可靠的数据,却有一位渴望答案的首席执行官。
首席执行官仍然想知道新策略让他多赚了多少钱……你该如何答复呢?
吉姆: 首席执行官要求我们弄清楚,二月份赚的钱中有多少是不减价本来赚不到的,我们得给这家伙一个答案。
弗兰克: 喔,这可是个棘手问题。我们对于多赚了多少钱毫无头绪,可能赚了不少,但也可能赔了钱。我们算是丢人现眼了,惹麻烦了。

乔: 怎么会,我们完全可以把销售收入和历史控制数据相比校,可能不会非常令人满意,但他会开心的,这就是一切意义所在。
弗兰克: 客户开心就是一切意义所在?看来你是想明哲保身。要是我们给他错误的答案,问题最终还是会落到我们头上。
乔: 随你怎么说。
弗兰克: 我们将不得不向他坦白事实,这不会是个美差。
吉姆: 看,其实我们已经有眉目了。我们只需为三月份设定一个控制组,然后再做一次实验。
弗兰克: 但首席执行官对二月份的进展感觉良好,因为他对这些进展有误会,我们必须打消他这种良好的自我感觉。
吉姆: 我想我们能让他清醒地思考,而不是嗤之以鼻。
避免解雇123
免不了要报告坏消息是数据分析师工作的一部分,不过,同样的消息却可以用各种不同的方式来表达。
让我们直说吧:如何才能既说出坏消息,又不被炒鱿鱼?
顶级数据分析师懂得妥当地报告有可能令人沮丧的消息。

说法1: 没什么坏消息。

说法2: 情况不妙,我们撤吧!

说法3: 事情不尽如人意,但只要我们处理得当,坏消息就会变成好消息。
哪一种说法不至于让你被炒鱿鱼?
今天?
明天?
下一次?
让我们
重新
认真做一次实验
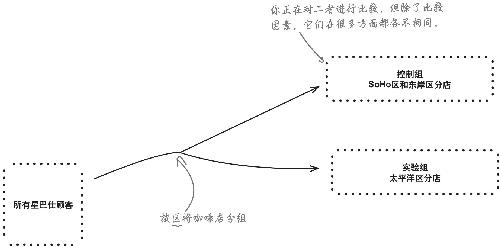
我们正在做三月份的实验,这一次,营销部把所有的星巴仕分店分成了控制组和实验组。
实验组包括太平洋区所有分店,控制组包括SoHo区和东岸区所有分店。

实验组
太平洋区

控制组
SoHo区和东岸区

一个月后……
事情看起来非常顺!实验可能会让你看到想要的答案——减价的效果。
有混杂因素吗?
记住,混杂因素是所研究的各个组之间的差异,而不是试图进行比较的因素。
动动笔
请观察前一页的设计和以上结果。
这些变量会成为分析结果的混杂因素吗?
文化
店址
咖啡温度
天气
动动笔解答
这些变量会成为分析结果的混杂因素吗?
文化
所有分店的文化都应该相同。
咖啡温度
每家分店的咖啡温度也应该一样。
店址
店址肯定是混杂因素。
天气
有可能!天气是选址要考虑的因素之一。
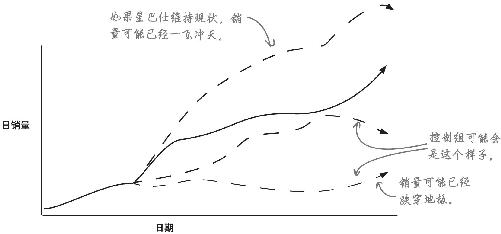
实验照样会毁于混杂因素
由于你刚刚走出观察研究的世界着手实验,所有还没有摆脱混杂因素的羁绊。
为了有效地进行比较,各个组必须相同 ,否则无异于拿苹果和橙子比!
混杂因素
你的实验结果显示,实验组的营业收入提高了,这可能是因为咖啡减价后人们增加了消费;但由于组与组之间无法相互比较 ,因此也有可能是其他原因造成营业收入增高——天气可能造成东岸区的人不出门,太平洋区的经济可能正在腾飞。到底是什么原因?由于有混杂因素 的存在,你永远也找不到答案。
精心选择分组,避免混杂因素
正如观察分析法一样,避免混杂因素完全要靠正确将咖啡店分组。但怎么分才好呢?
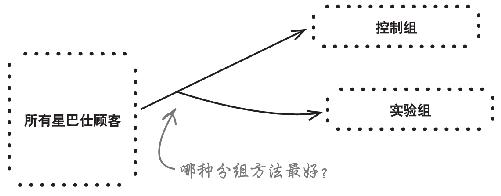
动动笔
这里有四种分组方法。你怎么看待每种方法在避免形成混杂因素上的作用?你认为哪一种分组方法最好?
轮流按不同的价格给顾客结账。这样一来,一半顾客进入实验组,一半顾客进入控制组,店址不再成为混杂因素。
使用历史控制法,将这个月的所有店作为控制组,下个月的所有店作为实验组。
将不同的店随机分配给控制组和实验组。
将大的地理区域分成小的地理区域,随机将这些微区域分进控制组和实验组。
动动笔解答
你认为哪一种分组方法最好?
轮流按不同的价格给顾客结账。这样一来,一半顾客进入实验组,一半顾客进入控制组,店址不再成为混杂因素。
顾客要拍桌子了——谁愿意比排在自己前面的那位多付钱?顾客的愤怒将会混杂你的分析结果。
使用历史控制法,将这个月所有店作为控制组,下个月所有店作为实验组。
我们已经讲过历史控制法为什么会带来问题。谁知道这几个月里会发生什么事使分析结果毁掉?
将不同的店随机分配给控制组和实验组。
这看起来有希望,但并不十分恰当。人们只会去便宜点的星巴仕店喝咖啡,而不会去控制组,店址仍是混杂因素。
将大的地理区域分成小的地理区域,随机将这些微区域分进控制组和实验组。
要是分割区域足够大,使人们不至于为喝上便宜点的咖啡而往来奔波;同时又足够小,使各个分割区域彼此相似,就能避开店址混杂因素。这是最好的办法。
看来这和随机法有些关系,让我们仔细看看……
随机选择相似组
从对象池中随机选择对象是避免混杂因素的极好办法。
在将对象随机分配到各个组里以后,最终的结果是:可能成为混杂因素的那些因素最终在控制组和实验组中具有同票同权 。
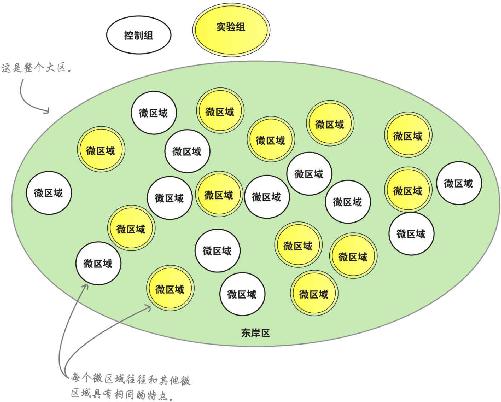
通过随机选择组成各个组的成员,组与组之间将非常相似,因而具有可比性 。
随机访谈
本周访问:
天啊,太随机了吧!
Head First: 随机先生,感谢您接受我们的采访。很明显您频繁出现在数据分析中,您能来真是太好了。
随机先生: 哦,我每一秒钟的行程都有点说不准,我没有真正的计划。我能来这里嘛,嗯,像是滚骰子滚过来的。
Head First: 有意思。这么说您对于自己没有什么计划或设想?
随机先生: 正是如此,东一榔头西一棒子就是我的风格。
Head First: 那你为什么在实验设计中这么有用呢?数据分析讲究的不就是秩序和方法吗?
随机先生: 当分析师通过我的力量来选择属于实验组或设计组的人或商店(或者诸如此类)时,我的魔法会让所得到的分组互为同类。我甚至还能收拾隐形的混杂因素,毫无问题。
Head First: 说说看?
随机先生: 假设有半数人受某种隐性混杂因素的影响,这种混杂因素叫做X因素,挺吓人的,对吧?X因素会大大扰乱你的分析结果。你不知道这种因素是什么,也没有任何关于它的数据,但这种因素一直存在,随时会冒出来。
Head First: 但观察分析法免不了有这种风险。
随机先生: 当然,但是,假定你在实验中利用我来将人群分进实验组和控制组,结果是,两个组中的X因素最终分量一样。如果总人数中有半数人含有这种隐性因素,那么,划分后的每个组中也有半数人含有这种隐性因素。这就是随机法的力量。
Head First: 这么说X因素可能仍然会影响分析结果,但对两个组的影响是完全一样的,这意味着可以对自己的检验目标进行有效的比较?
随机先生: 的确如此,随机控制 是各种实验的黄金标准。没有它你也能做实验,但要是有了它,你就能做得最好。随机控制实验能让你最大限度地接近数据分析的核心:证明因果关系。
Head First: 您是说随机控制实验能证明 因果关系吗?
随机先生: 喔,“证明”是一个非常非常重的词,我得回避这种说法,但请想想随机控制实验能让你得到的结果:你在检验两个组,除了要检验的变量,两个组在各个方面都一样,如果两个组的检验结果有任何不同,除了归结于这个变量还能归结于什么呢?
Head First: 那我怎么进行随机分配呢?假定我有一份数据表,想要随机选择表中数据,将表一分为二,该怎么做?
随机先生: 很简单。在你的电子数据表程序中,创建一列,称为随机(Random),将下面这个公式输入第一个单元格:=RAND(),对表中的每个数据复制和粘贴这个公式,再对随机列进行排序。行了!然后就可以将数据表分成控制组和多个实验组,实验组的个数根据需要决定。这就万事俱备了!
动动笔
现在该设计你的实验了。既然你已经了解了观察研究法和实验研究法、控制组和实验组、混杂因素和随机性,你就应当能够设计合适的实验,找到想要的答案。
你试图证明什么?为什么?
你的控制组和实验组将是什么样子?
如何避免混杂因素?
你的分析结果会是什么样子?
动动笔解答
你刚设计好自己的第一个随机控制实验。
它会如你所愿好好发挥作用吗?
你试图证明什么?为什么?
实验的目的是为了弄清楚下面哪种做法能提高销量:
维持现状、减价或尝试说服顾客星巴仕咖啡很有价值。我们准备用一个月的时间进行这个实验:就定在三月。
你的控制组和实验组将是什么样子?
控制组内的分店将照常工作——没有什么特别之处。一个实验组将由三月份降价的分店组成,另一个实验组将由派雇员游说客户“星巴仕咖啡很有价值”的分店组成。
如何避免混杂因素?
通过精心选择各个组来避免混杂因素。我们将把每个星巴仕地区分为多个微区域,然后随机将微区域池中的成员分配给控制组和实验组。于是,三个组的情况将大致相同。
你的分析结果会是什么样子?
这要等我们做完实验才有可能知道,不过,结果可能是:一个实验组或两个实验组都表现出比控制组更高的销量。
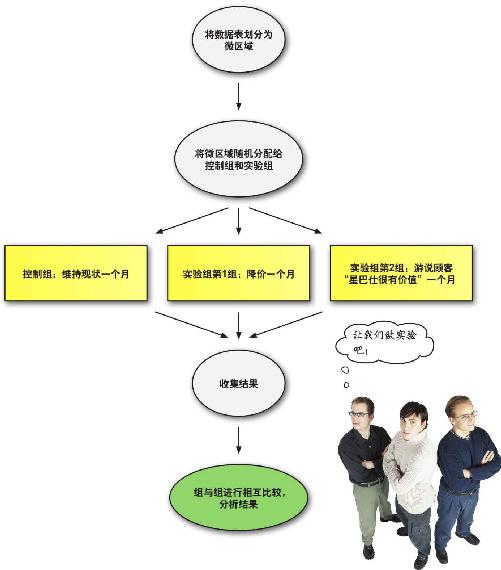
准备就绪,开始实验
在进行实验前,让我们最后再看一眼我们的整个程序,总结一下哪个策略最好。
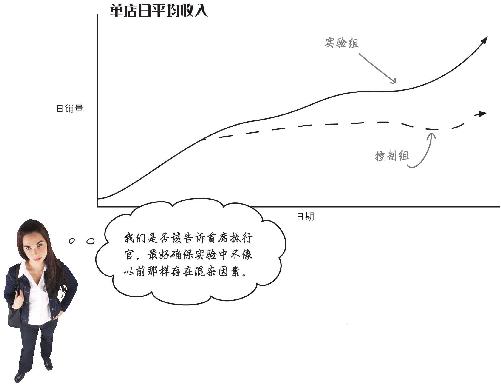
结果在此
星巴仕依计行事,用了几个星期做这个实验。与其他两个组相比,价值游说组的日营业收入立即上升,而降价组的营业收入其实是与控制组持平。
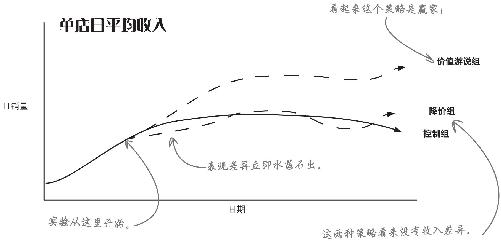
这张图非常有用,因为它进行了有效的比较 。你选择了同样的组,然后区别对待,于是现在的确可以将不同咖啡店营业收入上的差异归因于正在检验的因素。
这些结果非常棒!
价值游说看来比降价和维持现状带来了更高的销量,看来你已经找到答案。
星巴仕找到了与经验吻合的销售策略
在你开始这段实验历程的时候,星巴仕局面混乱。你小心地评估观察调查数据,从星巴仕几个大人物那里了解到更多的业务信息,从而创建了随机控制实验 。
实验进行了有效的比较,表明游说人们星巴仕咖啡有价值是比降价和维持现状更有效的提高销量的办法。

3 最优化
寻找最大值

有些东西人人都想多多益善。
为此我们上下求索。要是能用数字表示我们不断追求的东西——利润、钱、效率、速度等,实现更高目标的机会就在眼前。有一种数据分析工具能够帮助我们调整决策变量,找出解决方案 和优化点,使我们最大限度地达到目标。本章将使用这样一种工具,并通过强大的电子表格软件包Solver来实现这个工具。
现在是浴盆玩具游戏时间
你受雇于浴盆宝公司,这家公司执全国橡皮鸭和橡皮鱼浴盆玩具生产之牛耳,信不信由你,浴盆玩具是一项正正经经的业务,利润丰厚。
厂家想多赚点,听说时下盛行通过数据分析打理业务,于是给你来了电话。

动动笔
这是你的客户浴盆宝公司给你发来的电子邮件,说明了他们雇佣你的原因。
你需要哪些数据 才能解决这个问题?
动动笔解答
发件人:浴盆宝
收件人:Head First
主题:请提供产品组合分析
亲爱的分析师:
能联系上您真是太好了!
我们想尽量提高利润,为此必须确保橡皮鸭和橡皮鱼的产量都正合适。我们需要您帮忙找出理想的产品组合:这两种产品我们各应该生产多少?
期待您开始工作,我们对您仰慕已久。
致礼
浴盆宝
你需要哪些数据 才能解决这个问题?
首先,最好能够知道橡皮鸭和橡皮鱼的赢利能力,是否一种产品比另一种产品利润更高?除此之外,最好能知道约束这个问题的其他因素。生产这些产品需要多少橡胶?生产这些产品需要多少时间?
数据放大
细看一下你需要了解的信息。
可以将所需要的数据分成两类:无法控制的因素 ,可以控制的因素。
接着是客户为了尽量提高利润而要你弄清楚的基本问题。最后,就是你能控制 的:这两个问题的答案。
你需要得到有关能控制的因素和不能控制的因素的可靠数字。
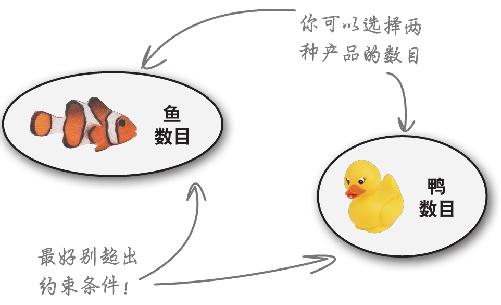
你能控制的变量受到约束条件的限制
这些考虑事项被称为约束条件 ,因为它们将决定问题的有关参数。你最终追求的无非是利润 ,而找到正确的产品组合就是确定下个月利润水平的办法。
但选择哪种产品组合将会受到约束条件的限制 。

决策变量是你能 控制的因素
约束条件不会告诉你如何实现最大利润;它们只告诉你在实现利润最大化的过程中无法 做到的事。
相反,决策变量却是你能 控制的因素。你可以选择生产多少只橡皮鸭,多少条橡皮鱼;在不超出约束条件的情况下,你的工作就是选择一个组合,实现最大利润。
动动脑
既然如此,你觉得应该怎么处理约束条件和决策变量才能找出实现最大利润的办法?
你碰到了一个最优化问题
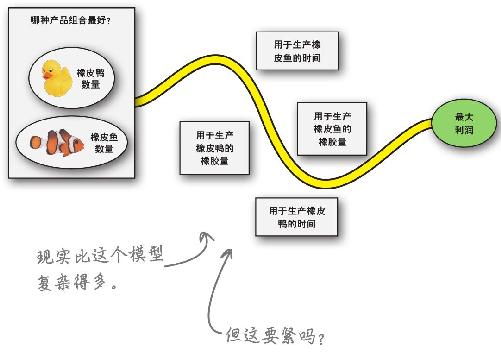
当你希望尽量多获得(或少获得)某种东西,而为了实现这个目的需要改变其他一些量的数值,你就碰到了一个最优化问题 。
在本例中,你想通过改变决策变量,即所生产的橡皮鸭和橡皮鱼的数量,实现利润 最大化。
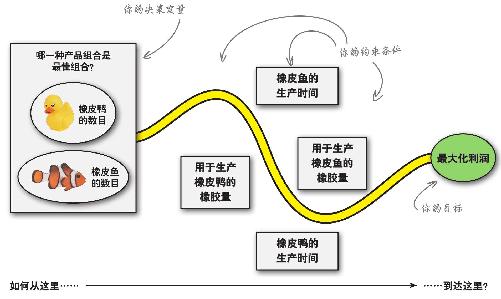
然而,为了实现利润最大化,你必须遵守约束条件:两种玩具的生产时间和橡胶供应量。
为了解决一个最优化问题,你需要将决策变量、约束条件及希望最大化的目标合并成一个目标函数。
借助目标函数发现目标
你希望最大化或最小化的对象就是目标,目标函数 则可以帮助你找出最优化结果。
你的目标函数用数学方法来表达是这个样子:
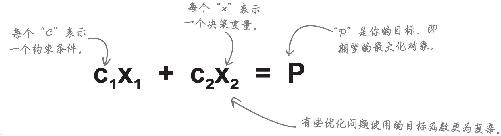
别吓坏了!整个等式的意思是,通过将每个决策变量乘以一个约束条件,就能算出可能实现的最大值“P”(利润)。
约束条件和决策变量在这个等式中共同作用,形成橡皮鸭和橡皮鱼的利润,最终形成你的目标:总利润。
任何最优化问题都有一些约束条件和一个目标函数。
考考你
你认为应将哪些特定值作为约束条件,“c 1 ”和“c 2 ”?
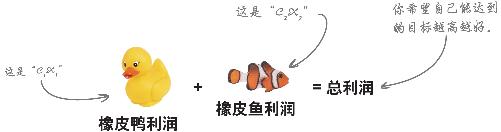
你的目标函数
需要放入目标函数的约束条件是每种玩具的利润 。
下面是另一种认识该数学函数的方法。
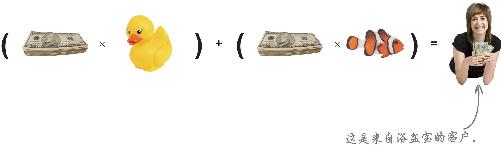
通过销售橡皮鸭和橡皮鱼获得的利润等于每只橡皮鸭的利润乘以橡皮鸭的数量再加上每条橡皮鱼的利润乘以橡皮鱼的数量。

现在可以试着做一些产品组合。你可以在等式中填入一些代表每种产品利润的数值,以及一些假定的数量。

这个目标函数说明下个月 将赚得700美元的利润。我们还要用这个目标函数试算许多其他产品组合。

列出有其他约束条件的产品组合
橡胶量和时间量限制了能够生产的橡皮鱼的数量,着手考虑这些约束条件的最好途径是想象一些假定的产品组合 。让我们从时间 约束条件开始。

假设的产品组合1可能是:生产100只橡皮鸭和200条橡皮鱼。你可以在条形图中绘制出这一产品组合(以及其他两种产品组合)的时间约束条件。
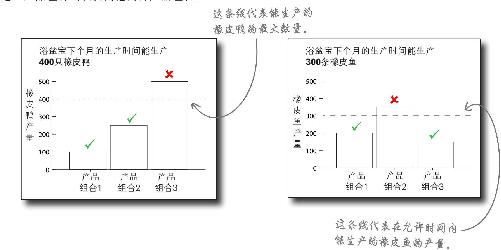
产品组合1并未超出任何约束条件,但其他两种组合超出了约束条件:产品组合2橡皮鱼的产量太高,产品组合3橡皮鸭的产量太高。
通过这种方法观察约束条件已经是一个进步,但我们需要更好的观察方法。我们还有更多的约束条件需要管理,如果能在一张图形里观察两种 约束条件,那就更好了。
考考你
你打算如何在一张图形里把橡皮鸭和橡皮鱼假设产品组合的约束条件都形象地表示出来?
在同一张图形里绘制多种约束条件
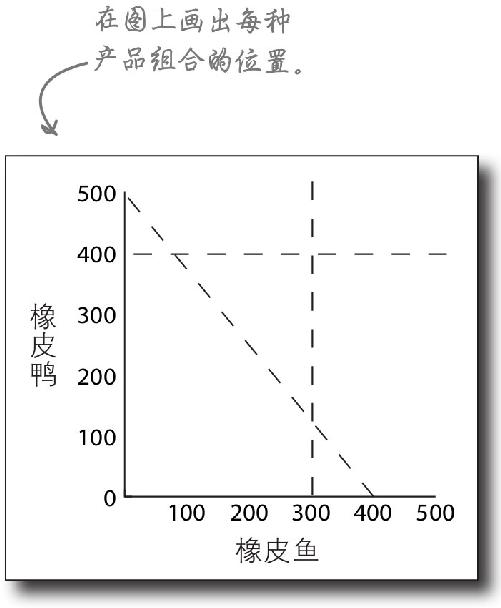
我们可以把两种时间约束条件画在同一张图形里,图中不再用条形图代表每种产品组合,而是用虚线代表。这样的图形能够方便地同时表示两种时间约束条件 。
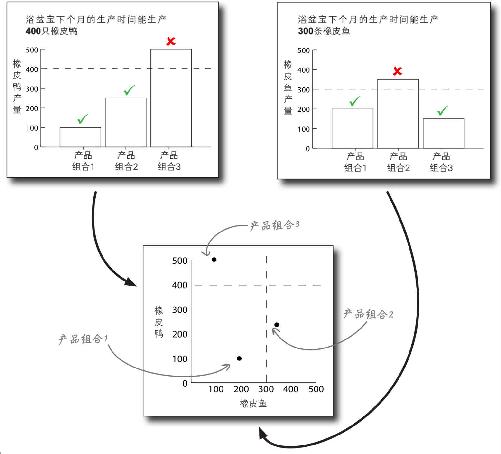
我们还可以用这张图形来表示橡胶量约束条件。实际上,可以将任何数量的约束条件 画在这张图形上,然后考虑有可能采用的产品组合。
合理的选择都出现在可行区域里
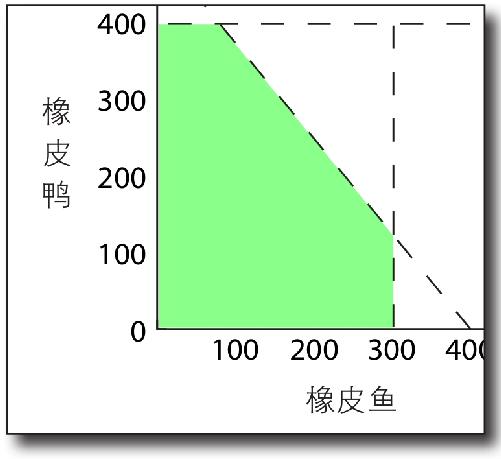
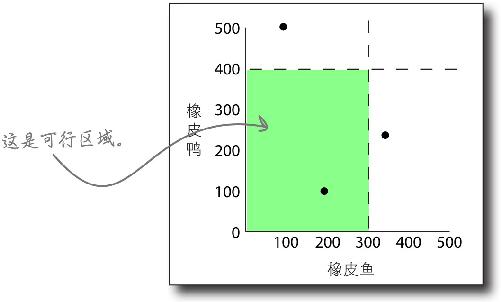
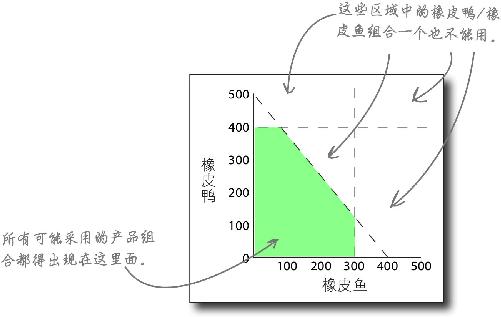
以Y轴表示橡皮鸭,以X轴表示橡皮鱼,这样就能很方便地看出哪种产品组合是可行的 。实际上,产品组合所在的由约束线围成的空间被称为可行区域 。
每当在图形中增加约束条件,可行区域就会发生变化,你则可以通过可行区域来找出最优点 。
动动笔
让我们增加一些其他的约束条件,这些条件表明,按照给定的橡胶量能够生产的橡皮鱼和橡皮鸭的数量。
这是浴盆宝的说法:
1 画一个点代表一个产品组合:这个组合将包含400条橡皮鱼。按照她的说法,如果生产400条橡皮鱼,就没有可以用来生产橡皮鸭的橡胶了。
2 画一个点代表一个产品组合:这个组合将包含500只橡皮鸭。如果生产500只橡皮鸭,橡皮鱼的产量将为零。
3 画一条线将这两个点连起来。
动动笔解答
新的约束条件在图上看起来怎么样?
1 画一个点代表一个产品组合:这个组合将包含400条橡皮鱼。按照她的说法,如果生产400条橡皮鱼,就没有可以用来生产橡皮鸭的橡胶了。
2 画一个点代表一个产品组合:这个组合将包含500只橡皮鸭。如果生产500只橡皮鸭,橡皮鱼的产量将为零。
3 画一条线将这两个点连起来。
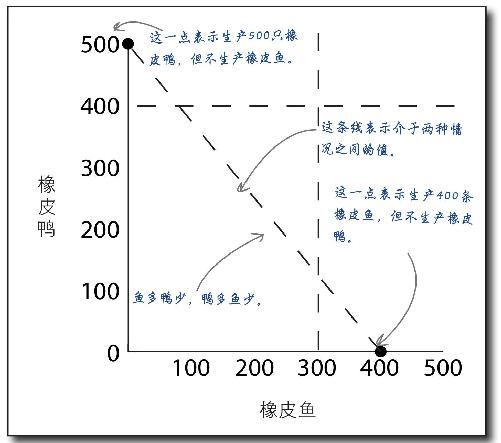
问得好。关于橡胶供应量:我们的橡胶够生产500只橡皮鸭或400条橡皮鱼。如果我们真的生产400条橡皮鱼,就没有橡胶可以生产橡皮鸭了,反过来也是一样。
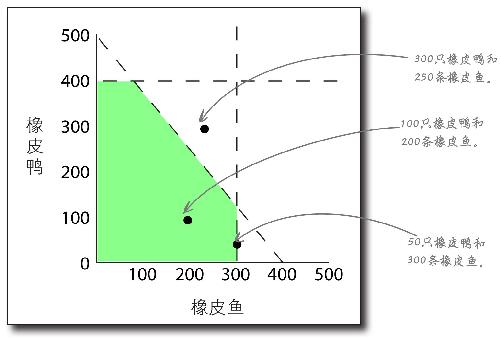
新约束条件改变了可行区域
增加橡胶量约束条件后,可行区域的形状变了 。
在增加约束条件之前,比如,你本来能生产400只橡皮鸭和300条橡皮鱼。但现在,由于橡胶短缺,这种产品组合不再可能实现。
动动笔
下面是几种可能采用的产品组合。
这些组合在可行区域里吗?
在图上为每种产品组合画一个点。
各种产品组合将带来多少利润?
用下面的等式来确定每种产品组合的利润。
100只橡皮鸭和200条橡皮鱼利润:
300只橡皮鸭和250条橡皮鱼利润:
50只橡皮鸭和300条橡皮鱼利润:
动动笔解答
你刚才画出了三种橡皮鸭和橡皮鱼的产品组合,并计算了利润。发现什么了?
300只橡皮鸭和250条橡皮鱼。
利润: (5美元利润×300只鸭)+(4美元利润×250条鱼)=$2500太糟了,这个产品组合不在可行区域里。
100只橡皮鸭和200条橡皮鱼。
利润: (5美元利润×100只鸭)+(4美元利润×200条鱼)=$1300这种产品组合肯定行得通。
50只橡皮鸭和300条橡皮鱼。
利润: (5美元利润×50只鸭)+(4美元利润×300条鱼)=$1450这种产品组合能行得通,而且能赚更多的钱。
现在,你唯一需要做 的就是尝试每一种可能采用的产品组合,然后看看哪一种利润最高,对吗?

你不必一一尝试。
因为Microsoft Excel和OpenOffice都有称手的小函数,可以麻利地解决最优化问题。具体用法请看下一页……
用电子表格实现最优化
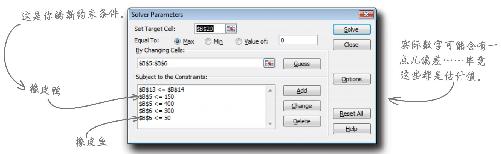
Microsoft Excel和OpenOffice都有称手而小巧的函数插件,英文叫做Solver ,中文叫做求解器,可以麻利地解决最优化问题。
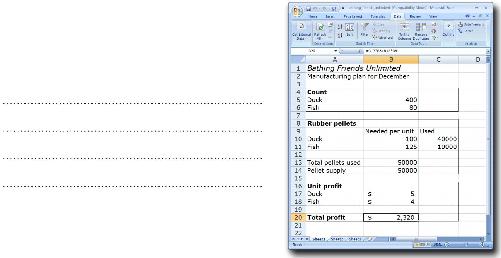
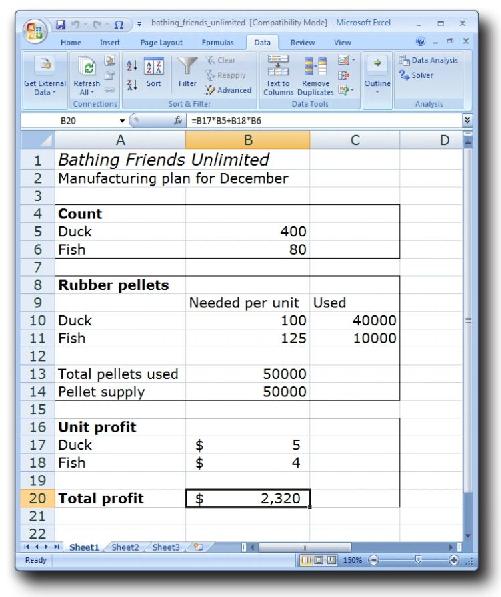
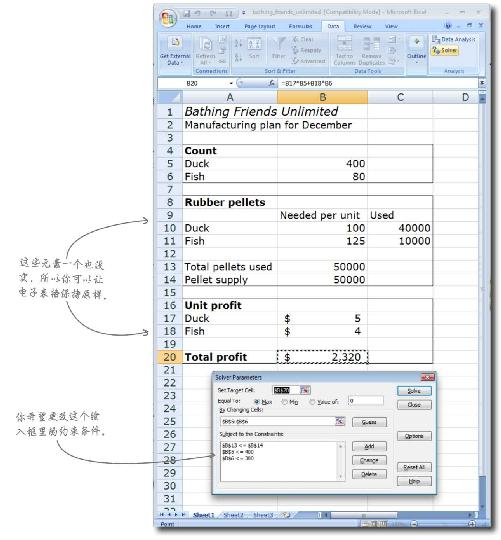
只要插入约束条件,写下目标函数,其他的算术工作就交给Solver吧。请看这张电子表格,其中有你从浴盆宝公司收集到的所有数据。
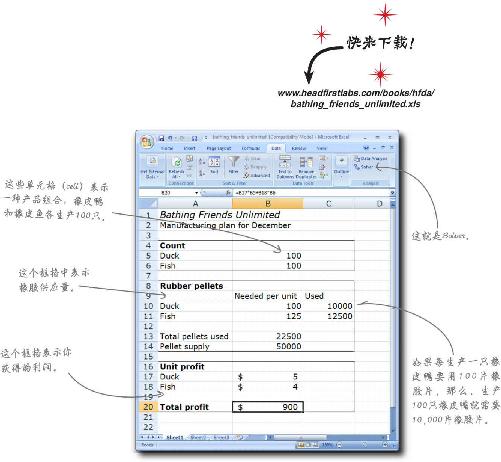
这个电子表格里有几个简单的公式。首先,这里有一些数字可以算出橡胶需求量。浴盆玩具的构成单位是橡胶片,单元格“B10:B11”的公式用于计算所需要的橡胶片的数量。
第二,单元格“B20”的公式用于将橡皮鱼的数量和橡皮鸭的数量分别与相应的单件利润相乘,得出总利润。

动动笔
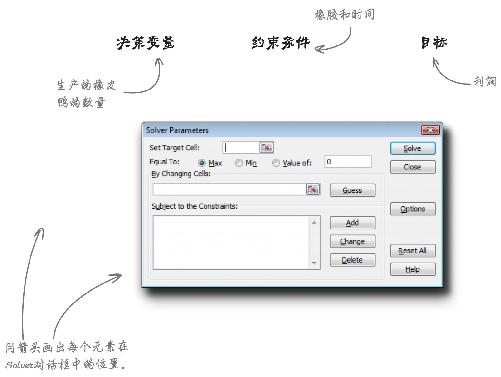
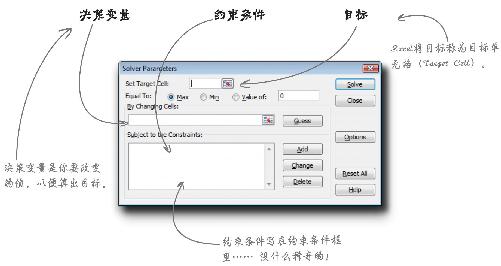
让我们看一下Solver对话框,搞清楚它是如何按照你刚学会的原理进行工作的。
用箭头画出每个元素在Solver对话框中的位置。
你认为目标函数 会写在哪里?
动动笔解答
Solver对话框中的空白位置该如何与你刚刚学会的最优化概念对应起来呢?
用箭头画出每个元素在Solver对话框中的位置。
你认为目标函数 会写在哪里?
目标函数写在电子表格的一个单元格里,返回值即所求的目标。这里的目标函数所求的目标就是总利润。
一试身手
既然已经定义好最优模型,现在就该将组成模型的元素插入Excel,让Solver来为你完成这个数字游戏。
1 设定你的目标单元格,使其指向你的目标函数。
2 找出你的决策变量,将决策变量添加到“Changing Cells”(更改单元格)空白处。
3 添加约束条件。
4 单击Solve(求解)!
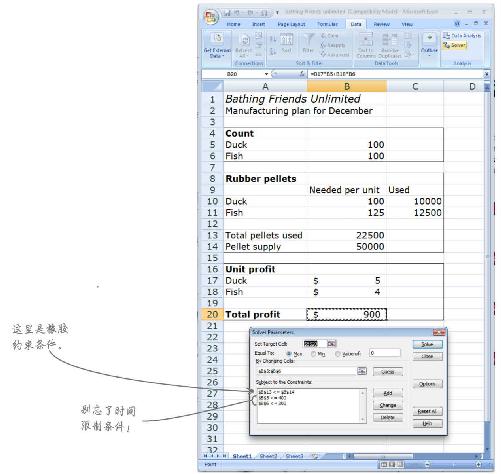
单击Solve(求解),结果如何?
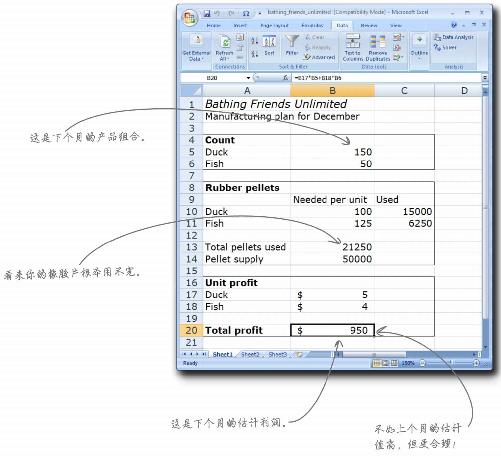
Solver一气呵成解决最优化问题
干得好。Solver一眨眼就能为你找到最优化解决方案。要是浴盆宝想实现最大利润,只要生产400只橡皮鸭和80条橡皮鱼就行了。
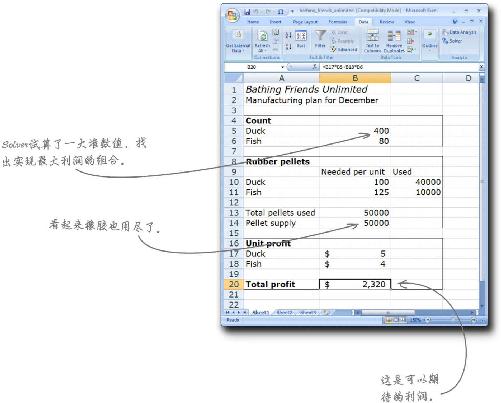
而且,如果你比较一下Solver的计算结果和你自己画的图,就会发现,Solver所认为的最精确点位于可行区域的外限上。
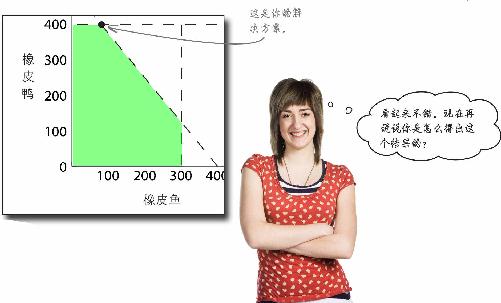
最好向客户解释一下你都忙了些什么……
动动笔
你该如何向客户解释自己忙了些什么呢?描述一下这些图形,它们有什么意义,它们能得出什么结果?
动动笔解答
该怎么给客户解释你所发现的结果呢?
图中的阴影部分表示在给定约束条件下可能采用的所有橡皮鸭/橡皮鱼产品组合,约束条件用虚线表示。但这张图并没有指出具体方案。
这张电子表格显示了Excel计算出的最优化产品组合。在不超过约束条件的情况下,在所有产品组合中,生产400只橡皮鸭和80条橡皮鱼能实现最大利润。
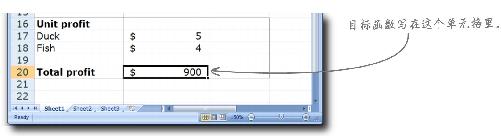
利润跌穿地板
你刚从浴盆宝得知关于你的分析结果的消息……
发件人:浴盆宝
收件人:Head First
主题:你的“分析”带来的结果
亲爱的分析师:
坦白地说,我们惊呆了。我们所生产的80条橡皮鱼全部卖光了,却只卖出了20只橡皮鸭,就是说我们只得到了420美元的利润,你应该看得出来,这比你为我们估计的2 320美元的利润要低得多。显然,我们想要比这更好的结果。
我们以前从来没有经历过这样的橡皮鸭销量,所以我们暂且不责怪你,除非我们自己能够对所发生的情况进行评估。你也许也想自行分析一下。
致礼
浴盆宝

这可真是个坏消息 。橡皮鱼卖光了,却没有人买橡皮鸭。看起来你出差错了。

你的模型怎么解释这种情况?
你的模型只是描述了你规定的情况
你的模型告诉你如何实现最大利润,但仅仅是在你所规定的约束条件下 。
你的模型接近事实,但永远无法完美,有时候,这种不完美会导致问题。
我们最好记住一位著名统计学家说的这段赖皮话:
“一切模型都是错误的,但其中一些是有用的。”
——George Box
你的分析工具不可避免地会简化实际情况,但如果你的假设 和数据都是正确的,那么这些工具就相当可靠。
你的目标应该是尽量创建最有用的模型 ,让模型的不完美相对于分析目标变得无足轻重。

按照分析目标校正假设
你无法规定全部假设条件,但只要缺失一个重要的假设条件,分析结果就可能毁掉。
你要不停地追问自己:规定的假设条件应该详尽到什么程度?这由分析的重要性来决定。

动动笔
为了让你的最优化模型重新产生效果,需要加入哪些假设条件?
动动笔解答
有没有一种假设可以帮助你优化模型?
模型中没有任何因素表明人们真正会购买此产品 。这个模型描述了时间、橡胶量、利润,但得有人购买产品,模型才会生效。然而正如我们所见,实际情况并不是这样,所以,我们需要增加一个体现人们会买什么产品的假设。
世上没有 傻问题
问: 万一不靠谱的假设成真,也就是人们什么都乐意买,结果会怎么样呢?最优化方法会有效吗?
答: 可能会。如果你可以假设 所生产的每一件产品都将卖掉,那么,利润最大化工作将主要围绕调整产品组合展开。
问: 可要是我设定一个目标函数指出如何让橡皮鸭和橡皮鱼的产量最大,结果会怎么样呢?会不会是这样:要是样样东西都能卖出去,我们该算计的就是如何生产更多产品。
答: 这是一个很好的想法,但要记住你有约束条件。浴盆宝的联系人告诉过你,能够生产的橡皮鸭和橡皮鱼的数量既受时间的限制,也受橡皮供应量的限制,这些都是你的约束条件。
问: 最优化听起来很狭义。只有在你有一个想实现最大化的数值,而且有一些称手的等式可以用来找出相应的正确数值的时候,才能使用最优化这个工具。
答: 但你可以用开阔得多的思维方式来思考最优化。最优化思维方法的最终目的是得出自己希望实现的目标,然后小心地鉴别会影响实现这个目标的约束条件。通常,约束条件能够以定量方式来表现,于是Solver之类的算法软件就能发挥作用了。
问: 这么说,只要我的问题能够以定量方式来表示,Solver就能为我完成优化工作。
答: Solver可以解决许多定量问题,但Solver主要是一个解决线性编程问题的工具,优化问题还有许多其他类型,可以用各种算法来求解。要是你想多学几招,可在网上搜索运算研究。
问: 要是我用最优化方法来处理这个新模型,人们就能买到想买的东西吗?
答: 是的,前提是我们得知道如何把人们的喜好添加到最优化模型中。
练习
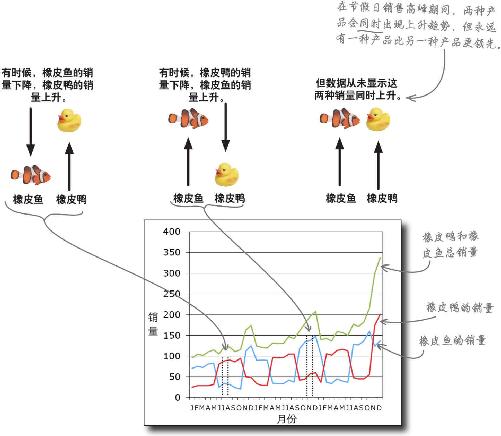
这里有一些橡皮鸭和橡皮鱼的历史销售数据。
这些信息可能会告诉你为什么人们看起来没有兴趣购买橡皮鸭。
这些时间内的销量变化规律是否能告诉你为什么上个月橡皮鸭卖得不好?
练习解答
你从这些新数据中看出什么了?
这些时间内的销量变化规律是否能告诉你为什么上个月橡皮鸭卖得不好?
橡皮鸭和橡皮鱼的销量似乎背道而驰,一个上升,另一个则下降,上个月的情况是人人都想要橡皮鱼。
提防负相关变量
我们不知道为什么 橡皮鸭和橡皮鱼的销量看上去南辕北辙,但可以肯定它们是负相关关系 。一种产品越多,就意味着另一种产品越少。
不要假定两种变量是不相关 的。创建模型时,务必要规定假设中的各种变量的相互关系。
动动脑
你打算在你的优化模型中加入哪种约束条件来体现橡皮鸭销量和橡皮鱼销量之间的负相关关系?
强化练习
你需要增加一个新约束条件,用于估计 某个月的橡皮鸭和橡皮鱼的需求量 。
1 看看这些历史销售数据,估计一下下个月的橡皮鸭和橡皮鱼的最高销量,同时假设 下个月的销量仍然保持前几个月的销售趋势。
2 再用一次Solver,这次加上新的约束条件。无论是橡皮鸭还是橡皮鱼,你认为有希望达到的最大销量 是多少?
强化练习解答
你又一次运行了自己的最优化模式,这次将橡皮鸭和橡皮鱼的估计销量整合进来了。你发现什么了?
1 看看这些历史销售数据,估计一下下个月的橡皮鸭和橡皮鱼的最高销量,假设 下个月的销量与前几个月的销量相似。
2 再用一次Solver,这次加上新的约束条件。例如,如果你认为下个月售出的橡皮鱼的数量不会超过50条,就一定要加上一个约束条件,告诉Solver,所建议的橡皮鱼的产量不得超过50条。
下面是Solver给出的结果:
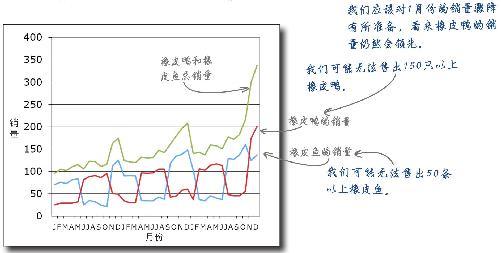
新方案立竿见影
新方案表现出色。每一只橡皮鸭和橡皮鱼都几乎是一离开生产线就立即卖掉了,这样一来,再没有积压的库存,客户完全有理由相信,利润最大化模型让他们心想事成。



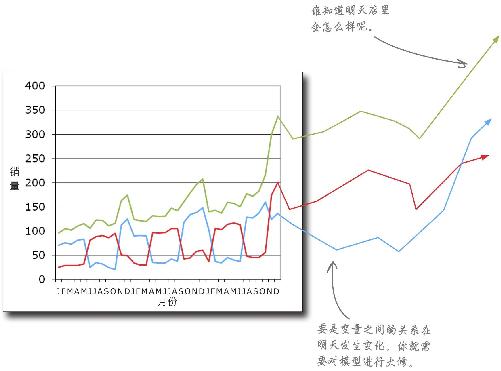
你的假设立足于不断变化的实际情况
你所使用的所有数据都是观察数据,你无法预知未来。
你的模型现在是在起作用,但可能会突然失灵。你需要做好准备,以便在必要的时候重新构建分析方法,反复不断地进行构建正是分析师的工作。
做好修改模型的准备!
4 数据图形化
图形让你更精明

数据表远非你所需。
你的数据庞杂晦涩,各种变量让你目不暇接,应付堆积如山的电子表格不只令人厌倦不堪,而且确实浪费时间。相反,与仅仅使用电子表格不同,一幅用纸不多、栩栩如生的清晰图像,却能让你摆脱“一叶障目,不见泰山”的烦恼。
新军队需要优化网站
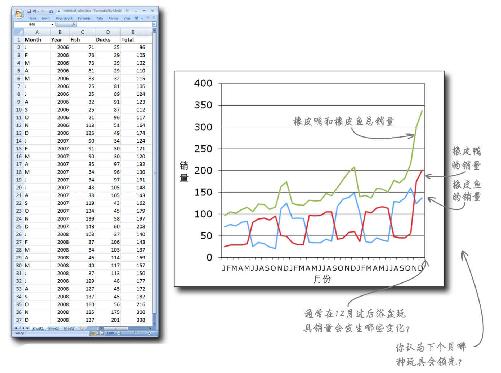
新军队是一家在线服装零售商,刚刚进行过一次测试网页外观的实验:在一个月的时间里,每一位浏览网站的人都随机浏览到下列三种主页设计 之一。
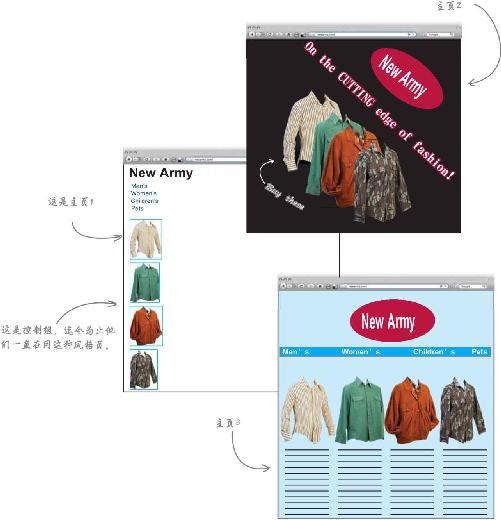
他们让实验设计师们一鼓作气进行了一系列测试,希望这些测试帮助他们找到网站设计的归宿,他们想挑出最优秀的风格页,让销量最大化,让人们成为网站的回头客。
结果面世,信息设计师出局
既然已经通过受控的随机实验搞到了大堆炫目的数据,就要想个办法将这些数据的价值统统体现出来。
于是他们雇用了一位信息设计牛人 ,让他汇总这些资料,以便从调研信息中刺探情报。岂料事情并不尽如人意。

你需要重新设计分析图表,这可能是一个艰难的任务,因为新军队的实验设计师是一帮要求苛刻的精英,他们拿出了大量实在的数据 。
在开始工作前,让我们先看看打入冷宫的设计,知道哪种图形不管用也许能让我们对某些东西先知先觉。
让我们看看这些打入冷宫的设计……
前一位信息设计师提交的三份信息图
信息设计师将这三份设计图交给了新军队。看看这些设计,你有什么印象?能看出为什么客户难免无法释怀吗?
这些图形隐含哪些数据?
每当你观察一张新图片,一上来就该问 “图片中隐含了哪些数据?”你所关心的是数据的质量及其含义,你讨厌炫目的设计,它们会妨碍你作出分析判断。
动动脑
你认为这些图片隐含着哪类数据?
体现数据!
你无法从这些图片上看出隐含了哪些数据。要是你是客户,面对连包含了哪些数据都说不上来的图片,怎么能指望作出有用的判断呢?
体现数据。 创建优秀数据图形的第一要务就是促使客户谨慎思考并制定正确决策,优秀的数据分析由始至终都离不开“用数据思考 ”。
新军队的数据其实不可谓不丰富,数据中包含了各种各样有价值的资料供你绘制图形。
这是前一位设计师主动提供的意见
你没有要求提供这些信息,可看来已经到手了:出局的信息设计师想对这个项目说上两句。也许他在不知不觉地帮你……

动动笔
看来,小唐认为,对于力图设计出优秀数据图形的人来说,数据过多倒是个问题。你觉得他是不是在花言巧语?为什么?
动动笔解答
小唐说数据太多会给绘制优秀图形带来极大困难,有道理吗?
并非全无道理。数据分析的根本在于总结数据,而一些总结工具,例如求平均值,不管数据寥寥可数还是不计其数,都同样有效。要是你手头有林林种种的数据可供相互比较,这的确很妙。像所有其他工具一样,图形会有利于这种数据分析。
数据太多绝不会成为你的问题
庞杂的数据很容易让人抓狂。

不过要学会处理貌似庞杂的数据同样并非难事。
要是你手头数据庞杂,而且对于如何处理这些数据没有把握,这时只要记住你的分析目标就行了:记住目标,目光停留在和目标有关的数据上,无视其他。

哦,真的吗?你认为作为数据分析师 ,你的工作就是给客户带来美感吗?
让数据变美观也不是你要解决的问题
只要数据图形能解决客户的问题,不管是精美扎眼还是平平无奇,都会对客户有吸引力。
正如进行任何优秀的数据分析一样,制作优秀的数据图形也需要明确起步点。
动动脑
如何通过一大堆充满变数的数据来评估你的目标?究竟从哪里开始呢?
数据图形化的根本在于正确比较
为了形成优秀的图形,首先要明确能够实现客户目标的基本比较对象。现在看一看客户最重要的电子表格:
尽管新军队的数据不止这三张表格,但通过对这三张表进行比较,却能够直接回答他们想知道的答案。让我们马上尝试比较……
动动笔
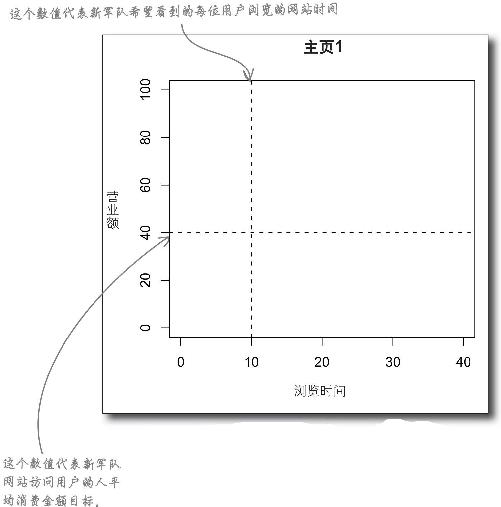
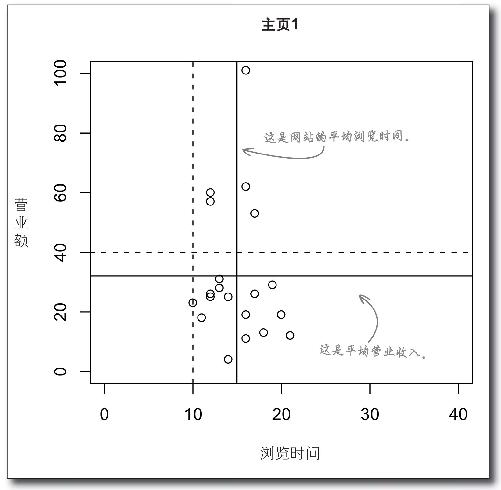
观察下面这张描述主页1访问结果的统计图,X轴上的点代表访问用户。
用电子表格的求平均值公式(AVG)算出主页1的平均营业额和浏览时间数值,在图上用水平和垂直线条表示这些数值。
你所看到的结果与目标营业收入和浏览时间相比怎样?
动动笔解答
如何用图形表示主页1的营业收入和浏览时间?
你所看到的结果与目标营业收入和浏览时间相比怎样?
从平均值看来,人们在主页1上的浏览时间高于新军队为该统计值设定的目标;另一方面,每位网站访问用户带来的平均营业额则低于新军队设定的目标。
你的图形已经比打入冷宫的图形更有用
现在看到的是一张不错的图形,这肯定对你的客户有用。这是一个优秀的数据图形实例,因为它……
使用散点图探索原因
散点图是探索性数据分析 的奇妙工具,统计学家用这个术语描述在一组数据中寻找一些假设条件进行测试的活动。
分析师喜欢用散点图发现因果关系 ,即一个变量影响另一个变量的关系。通常用散点图的X轴代表自变量(我们假想为原因的变量),用Y轴代表应变量(我们假想为结果的变量)。
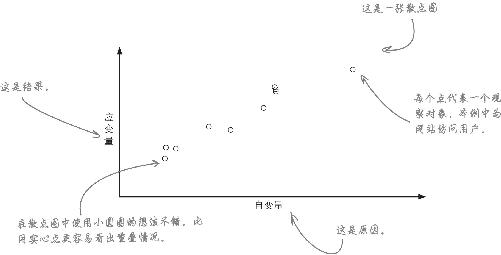
你不必论证 自变量是影响应变量的原因,因为我们终归是在探索数据,而原因正是我们的探索目标。

最优秀的图形都是多元图形
如果一个图形能对三个以上变量进行比较,这张图形就是多元图形,再加上有效的比较是数据分析的基础,于是尽量让图形多元化 最有可能促成最有效的比较,在本例中,你拥有丰富的变量。
动动脑
你如何令自己创建的散点图多元化?