表5-1 内置函数

本章的目的是完全覆盖自本书开始处所提及的Go过程式编程。Go语言可以用于写纯过程式程序,用于写纯面向对象程序,也可以用于写过程式和面向对象相结合的程序。学习 Go语言的过程式编程至关重要,因为与 Go语言的并发编程一样,面向对象编程也是建立在面向过程的基础之上的。
前面几章描述并阐明了Go语言内置的数据类型,在这一过程中,我们接触了Go语言的表达式语句和控制结构,以及许多轻量的自定义函数。本章中我们将更详细地讲解 Go语言的表达式语句和控制结构,同时更加详细地讲解创建和使用自定义的函数。表5-1提供了一个Go语言的内置类型函数的列表,其中大部分已在本章内容中覆盖 [1] 。
本章有些知识点在前面的章节中已经提及过,而有些知识点涉及 Go语言编程的其他方面则在接下来的章节中讲解,读者需要根据实际情况参阅前后章节的相关内容。
形式上讲,Go语言的语法需要使用分号(;)来作为上下文中语句的分隔结束符。然而,如我们所见,在实际的Go 程序中,很少使用到分号。那是因为编译器会自动在以标识符、数字字面量、字母字面量、字符串字面量、特定的关键字(break、continue、fallthrough和return)、增减操作符(++或者--)或者是一个右括号、右方括号和右大括号(即)、]、})结束的非空行的末尾自动加上分号。
有两个地方必须使用分号,即当我们需要在一行中放入一条或者多条语句时,或者是使用原始的for循环时(参见5.3节)。
自动插入分号的一个重要结果是一个右大括号无法自成一行。
// 正确代码 // 错误代码 (不能通过编译)
for i := 0; i < 5; i++ { for i := 0; i < 5; i++
fmt.Println(i) {
} fmt.Println(i)
}
上面右边的代码不能编译,因为编译器会往 ++ 后面插入一个分号。类似地,如果我们有一个无限循环(for),其左括号从下一行开始,那么编译器就会在for后面加上一个分号,代码同样不能编译。
表5-1 内置函数
括号放置的美学,通常引来无限多的讨论,但Go语言中不会。这部分是因为自动插入的分号限制了左括号的放置,部分是因为许多Go语言的用户使用gofmt程序将Go代码标准格式化。事实上,Go标准库中的所有源代码都使用了gofmt,这就是为什么这些代码有一个如此紧凑而一致的结构的原因,虽然这些是许多不同程序员的工作 [2] 。
Go语言支持表2-4中所列的++(递增)和--(递减)操作符。它们都是后置操作符,也就是说,它们必须跟随在一个它们所作用的操作数后面,并且它们没有返回值。这些限制使得该操作符不能用于表达式,也意味着不能用于语意不明的上下文中。例如,我们不能将该操作符用于一个函数的语句中,或者在Go语言中写出类似i=i++这样的代码(虽然我们能够在C和C++中这样做,其中其结果是未定义的)。
赋值通过使用 = 赋值操作符来完成。变量可以使用 =和一个var连接起来创建和赋值。例如, var x int = 5创建了一个int型的变量x,并将其赋值为5。(使用var x int = 5或者x :=5所达到的目的完全一样。)被赋值变量的类型必须与其所赋的值的类型相兼容。如果使用了=而没有使用var关键字,那么其左边的变量必须是已存在的。可以为多个逗号分隔的变量赋值,我们也可以使用空标识符(_)来接受赋值,它与任意类型兼容,并且会将赋给它的值忽略。多重赋值使得交换两个变量之间的数据变得更加简单,它不需要显式地指明一个临时变量,例如a, b = b, a。
快速声明操作符(:=)用于同时在一个语句中声明和赋值一个变量。多个逗号分隔的变量用法大多数情况下跟 = 赋值操作符一样,除了必须至少有一个非空变量为新的。如果有一个变量已经存在了,它就会直接被赋值,而不会新建一个变量,除非该:= 操作符位于作用域的起始处,如if或者for语句中的初始化语句(参见5.2.1节和5.3节)。
a, b, c := 2, 3, 5
for a := 7; a < 8; a++{ // a无意间覆盖了外部a的值
b := 11 // b无意间覆盖了外部b的值
c = 13 // c为外部的c值 √
fmt.Printf("inner: a→%d b→%d c→%d\n", a, b, c)
}
fmt.Printf("outer: a→%d b→%d c→%d\n", a, b, c)
inner: a→7 b→11 c→13
outer: a→2 b→3 c→13
这个代码片段展示了:= 操作符是如何创建“影子”变量的。在上面的代码中,for 循环里面,变量a和b覆盖了外部作用域中的变量,虽然合法,但基本上可确定是一个失误。另一方面,上面代码只创建了一个变量c(在外部作用域中),因此它的使用是正确的,并且也是所预期的。我们马上会看到,覆盖其他变量的变量可以很方便,但是粗心地使用可能会引起问题。
正如我们将在后面章节所讨论的,我们可以在有一到多个命名返回值的函数中写无需声明返回值的return语句。这种情况下,返回值将是命名的返回值,它们在函数入口处被初始化为其类型的零值,并且可以在函数体中通过赋值语句来改变它们。
func shadow() (err error) { // 该函数不能编译
x, err := check1() // 创建x,并对err进行赋值
if err != nil {
return // 正确地返回err
}
if y, err := check2(x); err != nil { // 创建了变量y和一个内部err变量
return // 内部err变量覆盖了外部err变量,因此错误地返回了nil
} else {
fmt.Println(y)
}
return // 返回nil
}
在shadow()函数的第一个语句中,创建了变量x并将其赋值。但是err变量只是简单地将其赋值,因为它已经被声明为 shadow()函数的返回值了。这之所以能够工作,是因为:=操作符必须至少创建一个非空的变量,而该条件在这里能够满足。因此,如果err变量非空,就会正确地返回。
一个if语句的简单语句(即跟在if后面且在条件之前的可选语句)创建了一个新的作用域(参见5.2.1节)。因此,变量y和err都被重新创建了,后者是一个影子变量。如果err为非空,则返回外部作用域中的err(即声明为shadow()函数返回值的err变量),其值为nil,因为调用check1()函数的时候它被赋值了,而调用check2()的时候,赋值的是err的影子变量。
所幸的是,函数的影子变量问题只是个幻影,因为在我们使用裸的return语句而此时又有任一返回值被影子变量覆盖时,Go编译器会给出一个错误消息并中止编译。因此,该函数无法通过编译。
一个简单的办法是在函数开始处声明变量(例如var x, y int或者x, y := 0, 0),然后把调用 check1()和调用 check2()函数时的:= 换成 =。(关于该方法的一个例子,请看自定义的americanise()函数。)
另一个解决方法是使用一个非命名的返回值。这迫使我们返回一个显式的值,因此在本例中,前两个语句的返回值都是return err(每一个语句返回一个不同的但都是正确的err值),同时最后一个返回语句为return nil。
Go语言提供了一种在不同但相互兼容的类型之间相互转换的方式,并且这种转换非常有用并且安全。非数值类型之间的转换不会丢失精度。但是对于数值类型之间的转换,可能会发生丢失精度或者其他问题。例如,如果我们有一个x := uint16(65000),然后使用转换y := int16(x),由于x超出了int16的范围,y的值被毫无悬念地设置成-536,这也可能不是我们所想要的。
下面是类型转换的语法:
resultOfType := Type(expression)
对于数字,本质上讲我们可以将任意的整型或者浮点型数据转换成别的整型或者浮点型(如果目标类型比源类型小,则可能丢失精度)。同样的规则也适用于 complex128和complex64类型之间的转换。我们已经在2.3节讲解了数字转换的内容。
一个字符串可以转换成一个[]byte(其底层为 UTF-8的字节)或者一个[]rune(它的Unicode码点),并且[]byte和[]rune都可以转换成一个字符串类型。单个字符是一个rune类型数据(即 int32),可以转换成一个单字符的字符串。字符串和字符的类型转换的内容已在第3章中阐述过(参见表3-2、表3-8和表3-9)。
让我们看一个更加直观的小例子,它从一个简单的自定义类型开始。
type StringSlice []string
该类型也有一个自定义的StringSlice.String() 函数(没给出),它返回一个表示一个字符串切片的字符串,该字符串切片以组合字面量语法的形式创建了自定义的StringSlice类型。
fancy := StringSlice("Lithium", "Sodium", "Potassium", "Rubidium")
fmt.Println(fancy)
plain := []string(fancy)
fmt.Println(plain)
StringSlice{"Lithium", "Sodium", "Potassium", "Rubidium"}
[Lithium Sodium Potassium Rubidium]
StringSlice变量fancy使用它自身的StringSlice.String()函数打印。但一旦我们将其转换成一个普通的[]string切片,那就像任何其他[]string一样被打印了。(创建带自身方法的自定义类型的内容将在第6章提到。)
如果表达式与类型Type的底层类型一样,或者如果表达式是一个可以用类型Type表达的无类型常量,或者如果Type是一个接口类型并且该表达式实现了Type接口,那么将一种类型的数据转换成其他类型也是可以的 [3] 。
一种类型的方法集是一个可以被该类型的值调用的所有方法的集合。如果该类型没有方法,则该集合为空。Go语言的interface{}类型用于表示空接口,即一个方法集为空集的类型的值。由于每一种类型都有一个方法集包含空的集合(无论它包含多少方法),一个interface{}的值可以用于表示任意Go类型的值。此外,我们可以使用类型开关、类型断言或者Go语言的reflect包的类型检查(参见9.4.9节)将一个interface{}类型的值转换成实际数据的值(参见5.2.2.2节) [4] 。
在处理从外部源接收到的数据、想创建一个通用函数及在进行面向对象编程时,我们会需要使用interface{}类型(或自定义接口类型)。为了访问底层值,有一种方法是使用下面中提到的一种语法来进行类型断言:
resultOfType, boolean := expression.(Type) // 安全类型断言
resultOfType := expression.(Type) // 非安全类型断言,失败时panic()
成功的安全类型断言将返回目标类型的值和标识成功的true。如果安全类型断言失败(即表达式的类型与声明的类型不兼容),将返回目标类型的零值和false。非安全类型断言要么返回一个目标类型的值,要么调用内置的panic()函数抛出一个异常。如果异常没有被恢复,那么该函数会导致程序终止。(异常的抛出和恢复的内容将在后面阐述,参见5.5节。)
这里有个小程序用来解释用到的语法。
var i interface{} = 99
var s interface{} = []string{"left", "right"}
j := i.(int) // j是int类型的数据(或者发生了一个panic())
fmt.Printf("%T→%d\n", j, j)
if i, ok := i.(int); ok {
fmt.Printf("%T→%d\n", i, j) // i是一个int类型的影子变量
}
if s, ok := s.([]string); ok {
fmt.Printf("%T→%q\n", s, s) // s是一个[]string类型的影子变量
}
int→99
int→99
[]string→["left" "right"]
做类型断言的时候将结果赋值给与原始变量同名的变量是很常见的事情,即使用影子变量。同时,只有在我们希望表达式是某种特定类型的值时才使用类型断言。(如果目标类型可以是许多类型之一,我们可以使用类型开关,参见5.2.2.2节。)
注意,如果我们输出原始的i和s变量(两者都是interface{}类型),它们可以以int和[]string类型的形式输出。这是因为当fmt包的打印函数遇到interface{}类型时,它们会足够智能地打印实际类型的值。
Go语言提供了3种分支语,即if、switch和select,后者将在后面深入讨论(参见5.4 节)。分支效果也可以通过使用一个映射来达到,它的键可以用于选择分支,而它的值是对应的要调用的函数,我们会在本章末尾看到更多细节(参见5.6.5节)。
Go语言的if语句语法如下:
if optionalStatement1; booleanExpression1 {
block1
} else if optionalStatement2; booleanExpression2 {
block2
} else {
block3
}
一个if语句中可能包含零到多个else if子句,以及零到多个else子句。每一个代码块都由零到多个语句组成。
语句中的大括号是强制性的,但条件判断中的分号只有在可选的声明语句optionalStatement1 出现的情况下才需要。该可选的声明语句用 Go语言的术语来说叫做“简单语句”。这意味着它只能是一个表达式、发送到通道(使用<-操作符)、增减值语句、赋值语句或者短变量声明语句。如果变量是在一个可选的声明语句中创建的(即使用:=操作符创建的),它们的作用域会从声明处扩展到if语句的完成处,因此它们在声明它们的if或者else if语句以及相应的分支中一直存在着,直到该if语句的末尾。
布尔表达式必须是bool型的。Go语言不会自动转换非布尔值,因此我们必须使用比较操作符。例如,if i == 0。(布尔类型和比较操作符参见表2-3。)
我们已经看过了使用if语句的大量例子,在本书的后续章节中将看到更多。不过,让我们再看两个小例子,第一个演示了可选简单语句的用处,第二个解释了Go语言中if语句的习惯用法。
// 经典用法 // 啰嗦用法
if α := compute(); α < 0 { {
fmt.Printf("(%d)\n", -α) α := compute()
} else { if α < 0 {
fmt.Println(α) fmt.Printf("(%d)\n", -α)
} } else {
fmt.Println(α)
}
}
这两段代码的输出一模一样。右边的代码必须使用额外的大括号来限制变量 α的作用域,然而左边的代码中的if语句自动地限制了变量的作用域。
第二个关于if语句的例子是ArchiveFileList()函数,它来自于archive_file_list示例(在文件archive_file_list/archive_file_ list.go中)。随后,我们会使用该函数的实现来对比if和switch语句。
func ArchiveFileList(file string) ([]string, error) {
if suffix := Suffix(file); suffix == ".gz" {
return GzipFileList(file)
} else if suffix == ".tar" || suffix == ".tar.gz" || suffix == ".tgz" {
return TarFileList(file)
} else if suffix == ".zip" {
return ZipFileList(file)
}
return nil, errors.New("unrecognized archive")
}
该函数读取一个从命令行指定的文件,对于那些可以处理的压缩文件(.gz、.tar、.tar.gz、.zip),它会打印压缩文件的文件名,并以缩进格式打印该压缩文件所包含文件的列表。
第一个if语句中声明的suffix变量的作用域扩展到了整个if…else if …语句中,因此它在每一个分支中都是可见的,就像前例中的α 变量一样。
该函数本可以在末尾添加一个else语句,但在Go语言中使用这里所给的结构是非常常用的:一个if语句带零到多个else if语句,其中每一个分支都带有一个return语句,随后紧接的是一个return语句而非一个包含return语句的else分支。
func Suffix(file string) string {
file = strings.ToLower(filepath.Base(file))
if i := strings.LastIndex(file, "."); i > -1 {
if file[i:] == ".bz2" || file[i:] == ".gz" || file[i:] == ".xz" {
if j := strings.LastIndex(file[:i], ".");
j > -1 && strings.HasPrefix(file[j:], ".tar") {
return file[j:]
}
}
return file[i:]
}
return file
}
为了完整性考虑,这里也提供了Suffix()函数的实现。它接受一个文件名(可能包含路径),返回其小写的后缀名(也叫扩展名),即文件名中从点号开始的最后部分。如果一个文件名没有点号,则将文件名返回(路径除外)。如果文件名以.tar.bz2、.tar.gz 或者.tar.xz结尾,则这些就是返回的后缀。
Go语言中有两种类型的switch语句:表达式开关(expression switch)和类型开关(type switch)。表达式开关语句对于C、C++和Java程序员来说比较熟悉,然而类型开关语句是Go语言专有的。两者在语法上非常相似,但不同于C、C++和Java的是,Go语言的switch语句不会自动地向下贯穿(因此不必在每一个case子句的末尾都添加一个break语句)。相反,我们可以在需要的时候通过显式地调用fallthrough语句来这样做。
5.2.2.1 表达式开关
Go语言的表达式开关(switch)语法如下:
switch optionalStatement; optionalExpression {
case expressionList1: block1
…
case expressionListN: blockN
default: blockD
}
如果有可选的声明语句,那么其中的分号是必要的,无论后面可选的表达式语句是否出现。每一个块由零到多个语句组成。
如果switch语句未包含可选的表达式语句,那么编译器会假设其表达式值为true。可选的声明语句与if语句中使用的简单语句是相同类型的。如果变量都是在可选的声明语句中创建的(例如,使用:=操作符),它们的作用域将会从其声明处扩展到整个switch语句的末尾处。因此它们在每个case语句和default语句中都存在,并在switch语句的末尾处消失。
将case语句排序最有效的办法是,从头至尾按最有可能到最没可能的顺序列出来,虽然这只有在有很多case子句并且该switch语句重复执行的情况下才显得重要。由于case子句不会自动地向下贯穿,因此没必要在每一个case语句块的末尾都加上一个break语句。如果需要case语句向下贯穿,我们只需简单地使用一个fallthrough语句。default语句是可选的,并且如果出现了,可以放在任意地方。如果没有一个 case 表达式匹配,则执行给出的default语句;否则程序将从switch语句之后的语句继续往下执行。
每一个case语句必须有一个表达式列表,其中包含一个或者多个分号分隔的表达式,其类型与switch语句中的可选表达式类型相匹配。如果没有给出可选的表达式,编译器会自动将其设置为true,即一个布尔类型,这样每一个case子句中的表达式的值就必须是一个布尔类型。
如果一个case或者default语句有一个break语句,switch语句的执行会被立即跳出,其控制权被交给switch语句后面的语句,或者如果break语句声明了一个标签,控制权就会交给声明标签处的最里层for、switch或者select语句。
这里有个关于switch语句的非常简单的例子,它没有可选的声明和可选表达式。
func BoundedInt(minimum, value, maximum int) int {
switch {
case value < minimum:
return minimum
case value > maximum:
return maximum
}
return value
}
由于没有可选的表达式语句,编译器会将表达式语句的值设为 true。这意味着 case 语句中的每一个表达式都必须计算为布尔类型。这里两个表达式语句都使用了布尔比较操作符。
switch {
case value < minimum:
return minimum
case value > maximum
return maximum
default:
return value
}
panic("unreachable")
这是上面 BoundedInt()函数的一种替代实现。其 switch 语句现在包含了每一种可能的情况,因此控制权永远不会到达switch语句的末尾。然而,Go语言希望在函数的末尾出现一个return语句或者panic(),因此我们使用了后者来更好地表达函数的语意。
前面节中的ArchiveFileList()函数使用了一个if语句来决定调用哪个函数。这里有一个原始的基于switch语句的版本。
switch suffix := Suffix(file); suffix { ∥ 原始的非经典用法
case ".gz":
return GzipFileList(file)
case ".tar":
fallthrough
case ".tar.gz":
fallthrough
case ".tgz":
return TarFileList(file)
case ".zip":
return ZipFileList(file)
}
switch语句同时有一个声明语句和一个表达式语句。本例中表达式语句是string类型,因此每一个 case 语句的表达式列表必须包含一个或者多个以逗号分隔的字符串才能匹配。我们使用了fallthrough语句来保证所有的tar类型文件都使用同一个函数来执行。
变量suffix的作用域从声明处扩展至每一个case子句(如果有default,其作用域也会扩展至default子句)中,同时在switch语句的末尾处结束,因为从那之后suffix变量就不再存在了。
switch Suffix(file) { // 经典用法
case ".gz":
return GzipFileList(file)
case ".tar", ".tar.gz", ".tgz":
return TarFileList(file)
case ".zip":
return ZipFileList(file)
}
这里有个更加紧凑也更加实用的使用switch的版本。与使用一个声明和一个表达式语句不同的是,我们只是简单地使用一个表达式:一个返回字符串的Suffix()的函数。同时,我们也不使用 fallthrough 语句来处理所有的tar 文件,而是使用逗号分隔的所有能够匹配的文件后缀来作为case语句的表达式列表。
Go语言的表达式switch语句比C、C++以及Java中的类似语句都更有用,很多情况下可以用于代替if语句,并且还更紧凑。
5.2.2.2 类型开关
注意,我们之前提到过类型断言(参见5.1.2节),当我们使用interface{}类型的变量时,我们常常需要访问其底层值。如果我们知道其类型,就可以使用类型断言,但如果其类型可能是许多可能类型中的一种,那我们就可以使用类型开关语句。
Go语言的类型开关语法如下:
switch optionalStatement; typeSwitchGuard {
case typeLis1: block1
...
case typeListN: blockN
default: blockD
}
可选的声明语句与表达式开关语句和if语句中的一样。同时这里的case语句与表达式切换语句中的case语句工作方式也一样,不同的是这里列出一个或者以多个逗号分隔的类型。可选的default子句和fallthrough语句与表达式切换语句中的工作方式也一样,通常,每一个块也包含零到多条语句。
类型开关守护(guard)是一个结果为类型的表达式。如果表达式是使用:=操作符赋值的,那么创建的变量的值为类型开关守护表达式中的值,但其类型则决定于 case 子句。在一个列表只有一个类型的case子句中,该变量的类型即为该类型;在一个列表包含两个或者更多个类型的case子句中,其变量的类型则为类型开关守护表达式的类型。
这种类型开关语句所支持的类型测试对于面向对象程序员来说可能比较困惑,因为他们更依赖于多态。Go语言在一定程度上可以通过鸭子类型支持多态(将在第6章看到),但尽管如此,有时使用显式的类型测试是更为明智的选择。
这里有个例子,显示了我们如何调用一个简单的类型分类函数以及它的输出。
classifier(5, -17.9, "ZIP", nil, true, complex(1, 1))
param #0 is an int
param #1 is a float64
param #2 is a string
param #3 is nil
param #4 is a bool
param #5's type is unknown
classifier()函数使用了一个简单的类型开关。它是一个可变参函数,也就是说,它可以接受不定数量的参数。并且由于其参数类型为 interface{},所传的参数可以是任意类型的。(本章稍后将讲解可变参函数以及带省略符函数,参见5.6节。)
func classifier(items…interface{}) {
for i, x := range items {
switch x.(type) {
case bool:
fmt.Printf("param #%d is a bool\n", i)
case float64:
fmt.Printf("param #%d is a float64\n", i)
case int, int8, int16, int32, int64:
fmt.Printf("param #%d is an int\n", i)
case uint, uint8, uint16, uint32, uint64:
fmt.Printf("param #%d is an unsigned int\n", i)
case nil:
fmt.Printf("param #%d is nil\n", i)
case string:
fmt.Printf("param #%d is a string\n", i)
default:
fmt.Printf("param #%d's type is unknow\n", i)
}
}
}
这里使用的类型开关守护与类型断言里的格式一样,即 variable.(Type),但是使用type关键字而非一个实际类型,以用于表示任意类型。
有时我们可能想在访问一个 interface{}的底层值的同时也访问它的类型。我们马上会看到,这可以通过将类型开关守护进行赋值(使用:= 操作符)来达到这个目的。
类型测试的一个常用案例是处理外部数据。例如,如果我们解析JSON格式的数据,我们必须将数据转换成相对应的Go语言数据类型。这可以通过使用Go语言的json.Unmarshal()函数来实现。如果我们向该函数传入一个指向结构体的指针,该结构体又与该JSON数据相匹配,那么该函数就会将JSON数据中对应的数据项填充到结构体的每一个字段。但是如果我们事先并不知道JSON数据的结构,那么就不能给json.Unmarshal()函数传入一个结构体。这种情况下,我们可以给该函数传入一个指向interface{}的指针,这样json.Unmarshal()函数就会将其设置成引用一个map[string]interface{}类型值,其键为JSON字段的名字,而值为对应的保存为interface{}的值。
这里有个例子,给出了如何反序列化一个其内部结构未知的原始JSON对象,如何创建和打印JSON对象的字符串表示。
MA := []byte('{"name": "Massachusetts", "area": 27336, "water": 25.7, "senators":
["John Kerry", "Scott Brown"]}')
var object interface{}
if err := json.Unmarshal(MA, &object); err != nil {
fmt.Println(err)
} else {
jsonObject := object.(map[string]interface{}) ①
fmt.Println(jsonObjectAsString(jsonObject))
}
{"senators": ["John Kerry", "Scott Brown"], "name": "Massachusetts",
"water": 25.700000, "area": 27336.000000}
如果反序列化时未发生错误,则 interface{}类型的object 变量就会指向一个map[string]interface{}类型的变量,其键为 JSON 对象中字段的名字。jsonObject AsString()函数接收一个该类型的映射,同时返回一个对应的JSON 字符串。我们使用一个未检查的类型断言语句(标识①)来将一个interface{}类型的对象转换成map[string] interface{}类型的jsonObject变量。(注意,为了适应书页的宽度,这里给出的输出切分成了两行。)
func jsonObjectAsString(jsonObject map[string]interface{}) string{
var buffer bytes.Buffer
buffer.WriteString("{")
comma := ""
for key, value := range jsonObject{
buffer.WriteString(comma)
switch value := value.(type){ // 影子变量 ①
case nil: ②
fmt.Fprintf(&buffer, "%q: null", key)
case bool:
fmt.Fprintf(&buffer, "%q: %t", key, value)
case float64:
fmt.Fprintf(&buffer, "%q: %f", key, value)
case string:
fmt.Fprintf(&buffer, "%q: %q", key, value)
case []interface{}:
fmt.Fprintf(&buffer, "%q: [", key)
innerComma := ""
for _, s := range value{
if s, ok := s.(string); ok { ∥影子变量③
fmt.Fprintf(&buffer, "%s%q", innerComma, s)
innerComma = ", "
}
}
buffer.WriteString("]")
}
comma = ", "
}
buffer.WriteString("}")
return buffer.String()
}
该函数将一个JSON对象转换成用一个映射来表示,同时返回一个对应的JSON格式中对象的数据的字符串表示。表示JSON对象的映射里的JSON数组使用[]interface{}类型来表示。关于JSON数组,该函数做了一个简化的假设:它假设数组中只包含字符串类型的项。
为了访问数据,我们在for...range(参见5.3节)循环来访问映射的键和值,同时使用类型开关来获得和处理每种不同类型的值。类型开关守护(①)将其值(interface{}类型)赋值给一个新的value变量,其类型与其相匹配的case子句的类型相同。在这种情况下使用影子变量是个明智的选择(虽然我们可以轻松地创建一个新的变量)。因此,如果 interface{}值的类型是布尔型,其内部值为布尔值,那么将匹配第二个case子句,其他case子句的情况也类似。
为了将数据写回缓冲区,我们使用了 fmt.Fprintf()函数,因为这个函数比buffer.WriteString(fmt.Sprintf(...))(②)函数来得方便。fmt.Fprintf()函数将数据写入到其第一个 io.Writer 类型的参数。虽然 bytes.Buffer 不是 io.Writer,但*bytes.Buffer却是一个io.Writer,因此我们传入buffer的地址。这些内容将在第6章详细阐述。简而言之,io.Writer是一个接口,任何提供了Write()方法的值都可以满足该接口。bytes.Buffer.Write()方法需要一个指针类型的接收器(即一个*bytes.Buffer 而非一个bytes.Buffer 值),因此只有*bytes.Buffer 才能够满足该接口,这也意味着我们必须将buffer的地址传入fmt.Fprintf()函数,而非buffer本身。
如果该JSON对象包含JSON数组,我们使用for...range循环来迭代[]interface{}数组的每一个项,同时也使用已检查的类型断言来判断(③),这样就能保证只有在数据为字符串类型时我们才将其添加到输出结果中。我们再一次使用了影子变量(这次是字符串类型的s),因为我们需要的不是接口,而是该接口所引用的值。(类型断言的内容我们已经讲过,参见5.1.2节。)当然,如果我们事先知道原始JSON对象的结构,我们可以很大程度上简化代码。我们可以使用一个结构体来保存数据,然后使用一个方法以字符串的形式将其输出。下面是在这种情况下反序列化并将其数据输出的例子。
var state State
if err := json.Unmarshal(MA, &state); err != nil {
fmt.Println(err)
}
fmt.Println(state)
{"name": "Massachusetts", "area": 27336, "water": 25.700000,
"senators": ["John Kerry", "Scott Brown"]}
这段代码看起来跟之前的代码很像。然而,这里不需要jsonObjectAsString()函数,相反我们需要定义一个 State 类型和一个对应的State.String()方法。(同样地,我们将其输出结果分行以适应书页的宽度。)
type State struct{
Name string
Senators []string
Water float64
Area int
}
该结构体与我们之前所看到的近似。然而请注意,这里每个字段的起始字符必须以大写字母开头,这样就能够将其导出(公开),因为json.Unmarshal()函数只能填充可导出的字段。同时,虽然Go语言的encoding/json包并不区分不同的数据类型(它会把所有JSON的数字当成float64类型),但json.Unmarshal()函数足够聪明,会自动填充其他数据类型的字段。
func (state State) String() string{
var senators []string
for _, senator := range state.Senators{
senators := append(senators, fmt.Sprintf("%q", senator))
}
return fmt.Sprintf(
'{"name": %q, "area": %d, "water": %f, "senators": [%s]}',
state.Name, state.Area, state.Water, strings.Join(senators, ", "))
}
该方法返回一个表示State值的JSON字符串。
大部分 Go 程序应该都不需要类型断言和类型开关,即使需要,应该也很少用到。其中一个使用案例是,我们传入一个满足某个接口的值,同时想检查下它是否满足另外一个接口。(该主题将在第6章阐述,例如6.5.2节。)另一个使用案例是,数据来自于外部源但必须转换成Go语言的数据类型。为了简化维护,最好总是将这些代码与其他程序分开。这样就使得程序完全地工作于 Go语言的数据类型之上,也意味着任何外部源数据的格式或类型改变所导致的代码维护工作可以控制在小范围内。
Go语言使用两种类型的for 语句来进行循环,一种是无格式的for 语句,另一种是for...range语句。下面是它们的语法:
for { //无限循环
block
}
for booleanExpression { // while循环
block
}
for optionalPreStatement; booleanExpress; optionalPostStatement{ // ①
block
}
for index, char := range aString{ //一个字符一个字符地迭代一个字符串 ②
block
}
for index := range aString{ // 一个字符一个字符地迭代一个字符串 ③
block // char, size := utf8.DecodeRuneInString(aString[index:])
}
for index, item := range anArrayOrSlice { // 数组或者切片迭代 ④)
block
}
for index := range anArrayOrSlice { // 数组或者切片迭代 ⑤
block // item := anArrayOrSlice[index]
}
for key, value := range aMap{ // 映射迭代 // ⑥
block
}
for key := range aMap { // 映射迭代 // ⑦
block // value := aMap[key]
}
for item := range aChannel { // 通道迭代
block
}
for循环中的大括号是必须的,但分号只在可选的前置或者后置声明语句都存在的时候才需要(①),两个声明语句都必须是简短的声明语句。如果变量是在一个可选的声明语句中创建的,或者用来保存一个 range 子句中产生的值(例如,使用:= 操作符),那么它们的作用域就会从其声明处扩展到for语句的末尾。
在无格式的for循环语法(①)中,布尔表达式的值必须是bool类型的,因为Go语言不会自动转换非bool型的值。(布尔表达式和比较操作符的内容已在之前的表2-3中列出。)第二个for...range循环迭代一个字符串的语法(③)给出了字节偏移的索引。对于一个7位的ASCII字符串s,如其值为“XabYcZ”,该语句产生的输出为0、1、2、3、4和5。但是对于一个UTF-8的字符串类型s,例如其值为“XαβYγZ”,则产生的索引值为0、1、3、5、6、8。第一个迭代字符串的for...range循环语法(②)在大多数情况下都比第二种语法(③)方便。
对于非空切片或者索引而言,第二个迭代数组或者切片的for...range循环语法(⑤)获取索引从0到len(slice) - 1的项。该语法与第一个迭代数组或者切片的语法(④)都非常有用。这两个语法能够解释为什么Go程序中更少使用普通的for循环(①)。
迭代映射的键-值对(⑥)或键(⑦)的for...range循环以任意顺序的形式得到映射中的项或者键。如果需要有序的映射,解决方案之一是使用第二种语法(⑦)创建一个由键组成的切片,然后将切片排序。我们已经在前面章节中看过一个相关的例子(参见4.3.4节)。另一种解决方案是优先使用一个有序数据结构。例如,一个有序映射。我们将在下章看一个类似的例子(参见6.5.3节)。
如果以上语法(②~⑦)作用于一个空字符串、数组、切片或映射,那么for循环就什么也不做,控制流程将从下一条语句继续。
一个for循环可以随时使用一个break语句来终止,这样控制权将传送给for循环语句的下一条语句。如果 break 语句声明了一个标签,那么控制权就会进入包含该标签的最内层for、switch或者select语句中。也可以通过使用一个continue语句来使得程序的控制权回到for循环的条件或者范围子句,以进行下一次迭代(或者结束循环)。
我们已经在看到过很多for语句的使用案例,其中包含for...range循环、无限循环以及在Go语言中使用得不是很多的普通for循环(因为其他循环更为方便)。当然,在本书的后续章节以及本章的后面节中,我们也会看到很多使用for循环的例子,因此这里我们就只看一个小例子。
假设我们有一个二维切片(即其类型为[][]int),想要从中搜索看看是否包含某个特定的值。这里有两种搜索的方法。两者都使用第二种遍历数组或切片的for...range循环语法(⑤)。

标签是一个后面带一个冒号的标识符。这两个代码段的功能一样,但是右边的代码比左边的代码更加简短和清晰,因为一旦成功搜索到目标值(x),它就会使用一个声明了一个标签的break 子句跳转到外层循环。如果我们的循环嵌套得很深(例如,迭代一个三维的数据),使用带标签的中断语句的优势就更加明显。
标签可以作用于for、switch以及select语句。break和continue语句都可以声明标签,并且都可用于for循环里面。同时,也可以在switch和select语句里面使用break语句,无论是裸的break语句还是声明了一个标签的break语句。
标签也可以独立出现在程序中,它们可能用做goto语句的目标(使用goto label语法)。如果一个 goto 语句跳过了任何创建变量的语句,则程序的行为是未定义的。幸运的话程序会崩溃,但它也可能继续运行并输出错误的结果。一个使用 goto 语句的案例是用于自动生成代码,因为在这种情况下goto语句非常方便,并且无需顾虑意大利面式代码问题(spaghetti code,指代码的控制结构特别复杂难懂)。虽然在写本书时有超过30个Go语言的源代码文件中使用了goto语句,但本书的例子中不会出现goto语句,我们提倡避免它 [5] 。
Go语言的通信与并发特性将在第7章讲解,但是为了过程式编程讲解的完整性,我们在这里描述下它的基本语法。
goroutine 是程序中与其他goroutine 完全相互独立而并发执行的函数或者方法调用。每一个Go 程序都至少有一个goroutine,即会执行main 包中的main()函数的主goroutine。goroutine非常像轻量级的线程或者协程,它们可以被大批量地创建(相比之下,即使是少量的线程也会消耗大量的机器资源)。所有的goroutine共享相同的地址空间,同时Go语言提供了锁原语来保证数据能够安全地跨goroutine共享。然而,Go语言推荐的并发编程方式是通信,而非共享数据。
Go语言的通道是一个双向或者单向的通信管道,它们可用于在两个或者多个goroutine之间通信(即发送和接收)数据。
在goroutine和通道之间,它们提供了一种轻量级(即可扩展的)并发方式,该方式不需要共享内存,因此也不需要锁。但是,与所有其他的并发方式一样,创建并发程序时务必要小心,同时与非并发程序相比,对并发程序的维护也更有挑战。大多数操作系统都能够很好地同时运行多个程序,因此利用好这点可以降低维护的难度。例如,将多份程序(或者相同程序的多份副本)的每一个操作作用于不同的数据上。优秀的程序员只有在其带来的优点明显超过其所带来的负担时才会编写并发程序。
goroutine使用以下的go语句创建:
go function(arguments)
go func(parameters) { block } (arguments)
我们必须要么调用一个已有的函数,要么调用一个临时创建的匿名函数。与其他函数一样,该函数可能包含零到多个参数,并且如果它包含参数,那么必须像其他函数调用一样传入对应的参数。
被调用函数的执行会立即进行,但它是在另一个goroutine上执行,并且当前goroutine的执行(即包含该go语句的goroutine)会从下一条语句中立即恢复。因此,执行一个go语句之后,当前程序中至少有两个goroutine在运行,其中包括原始的goroutine(初始的主goroutine)和新创建的goroutine。
少数情况下需要开启一串的goroutine,并等待它们完成,同时也不需要通信。然而,在大多数情况下,goroutine之间需要相互协作,这最好通过让它们相互通信来完成。下面是用于发送和接收数据的语法:
channel <- value // 阻塞发送
<-channel // 接收并将其丢弃
x := <-channel // 接收并将其保存
x, ok := <-channel // 功能同上,同时检查通道是否已关闭或者是否为空
非阻塞的发送可以使用select语句来达到,或者在一些情况下使用带缓冲的通道。通道可以使用内置的make()函数通过以下语法来创建:
make(chan Type)
make(chan Type, capacity)
如果没有声明缓冲区容量,那么该通道就是同步的,因此会阻塞直到发送者准备好发送和接收者准备好接收。如果给定了一个缓冲区容量,通道就是异步的。只要缓冲区有未使用空间用于发送数据,或还包含可以接收的数据,那么其通信就会无阻塞地进行。
通道默认是双向的,但如果需要我们可以使得它们是单向的。例如,为了以编译器强制的方式更好地表达我们的语义。在第7章中我们将看到如何创建单向的通道,然后在任何适当的时候都使用单向通道。
让我们结合一个小例子理解上文中讨论的语法 [6] 。我们将创建返回一个通道的createCounter()函数。当我们从中接收数据时,该通道会发送一个int类型数据。通道返回的第一个值是我们传送给createCounter()函数的值,往后返回的每一个值都比前面一个大1。下面展示了我们如何创建两个独立的counter 通道(每个都在它们自己的goroutine 里执行)以及它们产生的结果。
counterA := createCounter(2) // counterA是chan int类型的
counterB := createCounter(102) // counterB是chan int类型的
for i := 0; i < 5; i++ {
a := <-counterA
fmt.Printf("(A→%d, B→%d)", a, <-counterB)
}
fmt.Println()
(A→2, B→102) (A→3, B→103) (A→4, B→104) (A→5, B→105) (A→6, B→106)
我们用两种方式展示了如何从通道获取数据。第一种接收方式将获取的数据保存到一个变量里,第二种接收方式将接收的值直接以参数的形式传递给一个函数。
这两个 createCounter()函数的调用是在主 goroutine 中进行的,而另外两个由createCounter()函数创建的goroutine 初始时都被阻塞。在主 goroutine 中,只要我们一从这两个通道中接收数据,就会发生一次数据发送,然后我们就能接收其值。然后,发送数据的goroutine再次阻塞,等待一个新的接收请求。这两个通道是无限的,即它们可以无限地发送数据。(当然,如果我们达到了int型数据的极限,下一个值就会从头开始。)一旦我们想要接收的五个值都从通道中接收完成,通道将继续阻塞以备后续使用。
如果不再需要了,我们如何清理用于计数器通道的goroutine 呢?这需要让它跳出无限循环,以终止发送数据,然后关闭它们使用的通道。我们将在下一节提供一种方法。当然,第 7章中我们将深入讨论更多关于并发的内容。
func createCounter(start int) chan int{
next := make(chan int)
go func(i int) {
for {
next <- i
i++
}
}(start)
return next
}
该函数接收一个初始值,然后创建一个通道用于发送和接收int型数据。然后,它将该初始值传入在一个新的goroutine中执行的匿名函数。该匿名函数有一个无限循环,它简单地发送一个int型数据,并在每次迭代中将该int型数据加1。由于通道创建时其容量为0,因此该发送会阻塞直到收到一个从通道中接收数据的请求。该阻塞只会影响匿名函数所在的goroutine,因此程序中剩下的其他goroutine对此一无所知,并且将继续运行。一旦该goroutine被设置为运行状态(当然,从这点来看它会立即阻塞),紧接着该函数的下一条语句会立即执行,将通道返回给其调用者。
有些情况下我们可能有多个goroutine并发执行,每一个goroutine都有其自身通道。我们可以使用select语句来监控它们的通信。
select语句
Go语言的select语句语法如下 [7] :
select {
case sendOrReceive1: block1
...
case sendOrReceiveN: blockN
default: blockD
}
在一个 select 语句中,Go语言会按顺序从头至尾评估每一个发送和接收语句。如果其中的任意一语句可以继续执行(即没有被阻塞),那么就从那些可以执行的语句中任意选择一条来使用。如果没有任意一条语句可以执行(即所有的通道都被阻塞),那么有两种可能的情况。如果给出了default语句,那么就会执行default语句,同时程序的执行会从select语句后的语句中恢复。但是如果没有default语句,那么select语句将被阻塞,直到至少有一个通信可以继续进行下去。
一个select语句的逻辑结果如下所示。一个没有default语句的select语句会阻塞,只有当至少有一个通信(接收或者发送)到达时才完成阻塞。一个包含 default 语句的select 语句是非阻塞的,并且会立即执行,这种情况下可能是因为有通信发生,或者如果没有通信发生就会执行default语句。
为了了解和掌握该语法,让我们来看两个简短的例子。第一个例子有些刻意为之,但能够让我们很好地理解select语句是如何工作的。第二个例子给出了更为符合实际的用法。
channels := make([]chan bool, 6)
for i := range channels {
channels[i] = make(chan bool)
}
go func() {
for {
channels[rand.Intn(6)] <- true
}
}()
在上面的代码片段中,我们创建了6个用于发送和接收布尔数据的通道。然后我们创建了一个goroutine,其中有一个无限循环语句,在循环中每次迭代都随机选择一个通道并发送一个true值。当然,该goroutine会立即阻塞,因为这些通道不带缓冲且我们还没从这些通道中接收数据。
for i := 0; i < 36; i++ {
var x int
select {
case <-channels[0]:
x = 1
case <-channels[1]:
x = 2
case <-channels[2]:
x = 3
case <-channels[3]:
x = 4
case <-channels[4]:
x = 5
case <-channels[5]:
x = 6
}
fmt.Printf("%d", x)
}
fmt.Println()
6 4 6 5 4 1 2 1 2 1 5 5 4 6 2 3 6 5 1 5 4 4 3 2 3 3 3 5 3 6 5 2 2 3 6 2
上面代码片段中,我们使用 6 个通道来模拟一个公平骰子的滚动(严格地讲,是一个伪随机的骰子)。其中的select语句等待通道发送数据,由于我们没有提供一个default语句,该select语句会阻塞。一旦有一个或者更多个通道准备好了发送数据,那么程序会以伪随机的形式选择一个case语句来执行。由于该select语句在一个普通for循环内部,它会执行固定数量的次数。
接下来让我们看一个更加实际的例子。假设我们要对两个独立的数据集进行同样的昂贵计算,并产生一系列结果。下面是执行该计算的函数框架。
func expensiveComputation(data Data, answer chan int, done chan bool) {
// 设置……
finished := false
for !finished {
// 计算……
answer <- result
}
done <- true
}
该函数接收需要计算的数据和两个通道。answer 通道用于将每个结果发送回监控代码中,而done通道则用于通知监控代码计算已经完成。
// 设置 ……
const allDone = 2
doneCount := 0
answerα := make(chan int)
answerβ := make(chan int)
defer func() {
close(answerα)
close(answerβ)
}()
done := make(chan bool)
defer func() { close(done) }()
go expensiveComputation(data1, answerα, done)
go expensiveComputation(data2, answerβ, done)
for doneCount != allDone {
var which, result int
select {
case result = <-answerα:
which = 'α'
case result = <-answerβ:
which = 'β'
case <-done:
doneCount++
}
if which != 0 {
fmt.Printf("%c→%d ", which, result)
}
}
fmt.Println()
α→3 β→3 α→0 β→9 α→0 β→2 α→9 β→3 α→6 β→1 α→0 β→8 α→8 β→5 α→0 β→0 α→3
上面这些代码设置了通道,并开始执行计算,监控进度,然后在程序的末尾进行清理。以上代码没出现一个锁。
开始时我们创建两个通道answerα和answerβ 来接收结果,以及另一个通道done来跟踪计算是否完成。我们创建一个匿名函数来关闭这些通道,并使用defer 语句来保证它们在不再需要用到时才被关闭,即外层函数返回时。接下来,我们进行昂贵的计算(分别在它们自己的goroutine里进行),每一个计算使用的都是独立分配的数据、独立的结果通道以及共享的done通道。
我们本可以让每一个计算都使用相同的answer通道,但如果真那样做的话我们就不知道哪个计算返回的是哪个结果了(当然这可能也没关系)。如果我们想让每个计算共享相同的通道,同时又想为不同的结果标记其源头,我们可以使用一个操作一个结构体的通道,例如,type Answer struct{id, answer int}。
这两个计算开始于各自的goroutine中(但是是阻塞的,因为它们的通道是非缓冲的)之后,我们就可以从它们那里获取结果。每次迭代时,for循环中的which和result值都是全新的,而其阻塞的select语句会任意选择一个已准备好的case语句执行。如果一个结果已经准备好了,我们会设置which来标记它的源头,并将该源头与结果打印出来。如果done通道准备好了,我们将 doneCount 计数器加 1。当其值达到我们预设的需要计算的个数时,就表示所有计算都完成了,for循环结束。
一旦跳出for循环后,我们就知道两个进行计算的goroutine都不会再发送数据到通道里去(因为它们完成时会自动跳出它们自身的无限循环,参见5.4节)。当函数返回时,defer语句中会自动将通道关闭,而其所使用的资源也会被释放。这样,垃圾回收器就会清理这几个goroutine,因为它们不再需要执行,并且所使用的通道也已被关闭。
Go语言的通信和并发特性非常灵活而功能强大,第7章将专门阐述该主题。
defer语句用于延迟一个函数或者方法(或者当前所创建的匿名函数)的执行,它会在外围函数或者方法返回之前但是其返回值(如果有的话)计算之后执行。这样就有可能在一个被延迟执行的函数内部修改函数的命名返回值(例如,使用赋值操作符给它们赋新值)。如果一个函数或者方法中有多个defer语句,它们会以LIFO(Last In Firs Out,后进先出)的顺序执行。
defer语句最常用的用法是,保证使用完一个文件后将其成功关闭,或者将一个不再使用的通道关闭,或者捕获异常。
var file *os.File
var err error
if file, err = os.Open(filename); err != nil {
log.Println("failed to open the file", err)
return
}
defer file.Close()
这段代码摘自wordfrequency程序的updateFrequencies()函数,我们在之前的章节中讨论过它。这里展示了一个典型的模式,即在打开文件并在文件打开成功后用延迟执行的方式保证将其关闭。
该模式创建了一个值,并在该值被垃圾收集之前延迟执行一些关闭函数来清理该值(例如,释放一些该值所使用的资源)。这个模式在 Go语言中是一个标准做法 [8] 。虽然很少用到,我们当然也可以将该模式应用于自定义类型,为类型定义Close()或者Cleanup()方法,并将该方法用defer语法调用。
panic和recover
通过内置的panic()和recover()函数,Go语言提供了一套异常处理机制。类似于其他语言(例如,C++、Java和Python)中所提供的异常机制,这些函数也可以用于实现通用的异常处理机制,,但是这样做在Go语言中是不好的风格。
Go语言将错误和异常两者区分对待。错误是指可能出错的东西,程序需以优雅的方式将其处理(例如,文件不能被打开)。而异常是指“不可能”发生的事情(例如,一个应该永远为true的条件在实际环境中却是false的)。
Go语言中处理错误的惯用法是将错误以函数或者方法最后一个返回值的形式将其返回,并总是在调用它的地方检查返回的错误值(不过通常在将值打印到终端的时候会忽略错误值。)
对于“不可能发生”的情况,我们可以调用内置的panic()函数,该函数可以传入任何想要的值(例如,一个字符串用于解释为什么那些不变的东西被破坏了)。在其他语言中,这种情况下我们可能使用一个断言,但在Go语言中我们使用panic()。在早期开发以及任何发布阶段之前,最简单同时也可能是最好的方法是调用 panic()函数来中断程序的执行以强制发生错误,使得该错误不会被忽略因而能够被尽快修复。一旦开始部署程序时,任何情况下可能发生错误都应该尽一切可能避免中断程序。我们可以保留所有 panic()函数但在包中添加一个延迟执行的recover()调用来达到这个目的。在恢复过程中,我们可以捕捉并记录任何异常(以便这些问题保留可见),同时向调用者返回非nil的错误值,而调用者则会试图让程序恢复到健康状态并继续安全运行。
当内置的panic()函数被调用时,外围函数或者方法的执行会立即中止。然后,任何延迟执行的函数或者方法都会被调用,就像其外围函数正常返回一样。最后,调用返回到该外围函数的调用者,就像该外围调用函数或者方法调用了 panic()一样,因此该过程一直在调用栈中重复发生:函数停止执行,调用延迟执行函数等。当到达main()函数时不再有可以返回的调用者,因此这时程序会终止,并将包含传入原始panic()函数中的值的调用栈信息输出到os.Stderr。
上面所描述的只是一个异常发生时正常情况下所展开的。然而,如果其中有个延迟执行的函数或者方法包含一个对内置的recover()函数(可能只在一个延迟执行的函数或者方法中调用)的调用,该异常展开过程就会终止。这种情况下,我们就能够以任何我们想要的方式响应该异常。有种解决方案是忽略该异常,这样控制权就会交给包含了延迟执行的recover()调用的函数,该函数然后会继续正常执行。我们通常不推荐这种方法,但如果使用了,至少需要将该异常记录到日志中以不完全隐藏该问题。另一种解决方案是,我们完成必要的清理工作,然后手动调用 panic()函数来让该异常继续传播。一个通用的解决方案是,创建一个 error值,并将其设置成包含了recover()调用的函数的返回值(或返回值之一),这样就可以将一个异常(即一个panic())转换成错误(即一个error)。
绝大多数情况下,Go语言标准库使用error值而非异常。对于我们自己定义的包,最好别使用 panic()。或者,如果要使用 panic(),也要避免异常离开这个自定义包边界,可以通过使用recover()来捕捉异常并返回一个相应的错误值,就像标准库中所做的那样。
一个说明性的例子是 Go语言中最基本的正则表达式包 regexp。该包中有一些函数用于创建正则表达式,包括regexp.Compile()和regexp.MustCompile()。第一个函数返回一个编译好的正则表达式和nil,或者如果所传入的字符串不是个合法的正则表达式,则返回nil和一个error值。第二个函数返回一个编译好的正则表达式,或者在出问题时抛出异常。第一个函数非常适合于当正则表达式来自于外部源时(例如,当来自于用户输入或者从文件读取时)。第二个函数非常适合于当正则表达式是硬编码在程序中时,这样可以保证如果我们不小心对正则表达式犯了个错误,程序会因为异常而立即退出。
什么时候应该允许异常终止程序,什么时候又应该使用recover()来捕捉异常?有两点相互冲突的利益需要考虑。作为一个程序员,如果程序中有逻辑错误,我们希望程序能够立马崩溃,以便我们可以发现并修改该问题。但一旦程序部署好了,我们就不想让我们的程序崩溃。
对于那些只需通过执行程序(例如,一个非法的正则表达式)就能够捕捉的问题,我们应该使用panic()(或者能够发生异常的函数,如regexp.MustCompile())、因为我们永远不会部署一个一运行就崩溃的程序。我们要小心只在程序运行时一定会被调用到的函数中才这样做,例如main包中的init()函数(如果有的话)、main包中的main()函数,以及任何我们的程序所导入的自定义包中的init()函数,当然也包括这些函数所调用的任何函数或者方法。如果我们在使用测试套件,我们当然可以把异常的使用扩展至测试套件会调用到的任何函数或者方法。自然地,我们必须保证无论程序的控制流程如何进行,潜在的异常的情况总是能够被适当地处理。
对于任何特殊情况下可能运行也可能不运行的函数或者方法,如果调用了panic()函数或者调用了发生异常的函数或者方法,我们应该使用 recover()以保证将异常转换成错误。理想情况下,recover()函数应该在尽可能接近于相应 panic()的地方被调用,并在设置其外围函数的error返回值之前尽可能合理的将程序恢复到健康状态。对于main包的main()函数,我们可以放入一个“捕获一切”的recover()函数,用于记录任何捕获的异常。但不幸的是,延迟执行的recover()函数被调用后程序会终止。稍后我们会看到,我们可以绕过这个问题。
接下来让我们看两个例子,第一个演示了如何将异常转换成错误,第二个例子展示了如何让程序变得更健壮。
假设我们有如下函数,它在我们所使用的某个包的深处。但我们没法更改这个包,因为它来自于一个我们无法控制的第三方。
func ConvertInt64ToInt(x int64) int {
if math.MinInt32 <= x && x <= math.MaxInt32{
return int(x)
}
panic(fmt.Sprintf("%d is out of the int32 range", x))
}
该函数安全地将一个int64类型的值转换成一个int类型的值,如果该转换产生的结果非法,则报告发生异常。
为什么一个这样的函数优先使用 panic()呢?我们可能希望一旦有错就强制崩溃,以便尽早弄清楚程序错误。另一种使用案例是,我们有一个函数调用了一个或者多个其他函数,一旦出错我们希望尽快返回到原始调用函数,因此我们让被调用的函数碰到问题时抛出异常,并在调用处使用recover()捕获该异常(无论异常来自哪里)。正常情况下,我们希望包报告错误而非抛出异常,因此常用的做法是在一个包内部使用panic(),同时使用recover()来保证产生的异常不会泄露出去,而只是报告错误。另一种使用案例是,将类似panic("unreachable")这样的调用放在一个我们从逻辑上判断不可能到达的地方(例如函数的末尾,而该函数总是会在到达末尾之前通过return语句返回),或者在一个前置或者后置条件被破坏时才调用panic()函数。这样做可以保证,如果我们破坏了函数的逻辑,立马就能够知道。
如果以上理由没有一个成立,那么当问题发生时我们就应该避免崩溃,而只是返回一个非空的error值。因此,在本例中,如果转换成功,我们希望返回一个int型值和一个nil,如果失败则返回一个int值和一个非空的错误值。下面是一个包装函数,能够实现我们想要的功能。
func IntFromInt64(x int64) (i int, err error){
defer func(){
if e := recover(); e != nil{
err = fmt.Errorf("%v", e)
}
}()
i = ConvertInt64ToInt(x)
return i, nil
}
该函数被调用时,Go语言会自动地将其返回值设置成其对应类型的零值,如在这里是0和nil。如果对自定义的ConvertInt64ToInt()函数正常返回,我们将其值赋值给i返回值,并返回i和一个表示没错误发生的nil值。但是如果ConvertInt64ToInt()函数抛出异常,我们可以在延迟执行的匿名函数中捕获该异常,并将err设置成一个错误值,其文本为所捕获错误的文本表示。
如IntFromInt64()函数所示,可以非常容易将异常转换成错误值。
对于我们第二个例子,我们考虑如何让一个 Web 服务器在遇到异常时仍能够健壮地运行。我们回顾下第2章中的statistics例子(参见2.4节)。如果我们在那个服务器端犯了个程序错误,例如,我们意外地传入了一个nil值作为image.Image值,并调用它的一个方法,我们可能得到一个如果不调用 recover()函数就会导致程序中止的异常。如果网站对我们来说非常重要,特别是我们希望在无人值守的情况下持续运行时,这当然是让人非常不满意的场景。我们期望的是即使出现异常服务器也能继续运行,同时将任何异常都以日志的形式记录下来,以便将我们进行跟踪并在有时间时将其修复。
我们创建了一个statistics例子的修改版(事实上,是statistics_ans解决方案的修改版),保存在文件statistics_nonstop/statistics.go中。为了测试需要,我们所做的修改是在网页上添加一个额外的“Panic!”按钮,点击后可产生一个异常。其中所做的最重要的修改是,我们让服务器可以从异常恢复。为了更好地查看发生了什么,每当成功响应一个客户端,或者当我们得到一个错误的请求时,或者如果服务器重启了,我们都以日志的形式将其记录下来。下面是一个常规日志的小样本。
[127.0.0.1:41373] served OK
[127.0.0.1:41373] served OK
[127.0.0.1:41373] bad request: '6y' is invalid
[127.0.0.1:41373] served OK
[127.0.0.1:41373] caught panic: user clicked panic button!
[127.0.0.1:41373] served OK
为了让输出结果更适合于阅读,我们告诉log包不要打印时间戳。
在了解我们对代码做了什么更改之前,让我们简单地回顾下原始代码。
func main(){
http.HandleFunc("/", homePage)
if err := http.ListenAndServe(":9001", nil); err != nil {
log.Fatal("failed to start server", err)
}
}
func homePage(writer http.ResponseWriter, request *http.Request) {
// …
}
虽然我们所要展示的技术可应用于创建有多个网页的网站,但这里这个网站只有一个网页。如果发生了异常而没有被recover()捕获,即该异常被传播到了main()函数,服务器就会终止,这就是我们所要阻止的。
func homePage(writer http.ResponseWriter, request *http.Request) {
defer func() { // 每一个页面都需要
if x := recover(); x != nil {
log.Printf("[%v] caught panic: %v", request.RemoteAddr, x)
}
}()
// …
}
对于能够健壮地应对异常的Web服务器而言,我们必须保证每一个页面响应函数都有一个调用 recover()的匿名函数。这可以阻止异常的蔓延。然而,这不会阻止页面响应函数返回(因为延迟执行的语句只是在函数的返回语句之前执行),但这不重要,因为每次页面被请求时,http.ListenAndServer()函数会重新调用页面响应函数。
当然,对于一个含有大量页面处理函数的网站,添加一个延迟执行的函数来捕获和记录异常会产生大量重复的代码,并且容易被遗漏。我们可以通过将每个页面处理函数都需要的代码包装为一个函数来解决这个问题。使用包装函数,只要改变下http.HandleFunc()函数的调用,我们可以从页面处理函数中移除恢复代码。
http.HandleFunc("/", logPanics(homePage))
这里我们使用原始的homePage()函数(即未调用延迟执行recover()的版本),它依赖于logPanics()包装函数来处理异常。
func logPanics(function func(http.ResponseWriter,
*http.Request)) func(http.ResponseWriter, *http.Request) {
return func(writer http.ResponseWriter, request *http.Request) {
defer func() {
if x := recover(); x != nil {
log.Printf("[%v] caught panic: %v", request.RemoteAddr, x)
}
}()
function(writer, request)
}
}
该函数接收一个 HTTP 处理函数作为其唯一参数,创建并返回一个匿名函数。该匿名函数包含一个延迟执行的(同时也是)匿名函数以捕获并记录异常,然后调用所传入的处理函数。这跟我们在上面修改过的homePage()函数中所看到的效果一样,它添加了一个延迟执行的异常捕获器和日志记录器,但是更为方便,因为我们无需为每一个页面处理函数添加一个延迟执行函数。相反,我们使用logPanics()包装器将每个页面处理函数传入http.HandleFucn()。
文件statistics_nonstop2/statistics.go中有使用该技术的statistics程序的版本。匿名函数的内容将在下一节中关于闭包的节中详细阐述(参见5.6.3节)。
函数是面向过程编程的根本,Go语言原生支持函数。Go语言的方法(在第6章描述)和函数是很相似的,所以本章的主题和过程编程以及面向对象编程都相关。下面是函数定义的基本语法。
func functionName(optionalParameters) optionalReturnType {
body
}
func functionName(optionalParameters) (optionalReturnValues) {
body
}
函数可以有任意多个参数,如果没有参数那么圆括号是空的,否则要写成这样:params1 type1,..., paramsN typeN,其中params1是参数,type1是参数类型,多个参数之间要用逗号分隔开。参数必须按照给定的顺序来传递,没有和Python的命名参数相同的功能。不过Go语言里也可以实现一种类似的效果,后面就可以看到(5.6.1.3节)。
如果要实现可变参数,可以将最后一个参数的类型之前写上省略号,也就是说,函数可以接收任意多个那个类型的值,在函数里,实际上这个参数的类型是[]type。
函数的返回值也可以是任意个,如果没有,那么返回值列表的右括号后面是紧接着左大括号的。如果只有一个返回值可以直接写返回的类型,如果有两个或者多个没有命名的返回值,必须使用括号而且得这样写(type1,..., typeN)。如果有一个或者多个命名的返回值,也必须使用括号,要写成这样(values1 type1,..., valuesN typeN),其中values1是一个返回值的名称,多个返回值之间必须使用逗号分隔开。函数的返回值可以全部命名或者全都不命名,但不能只是部分命名的。
如果函数有返回值,则函数必须至少有一个return语句或者最后执行panic()调用。如果返回值不是命名的,则return语句必须指定和返回值列表一样多的值。如果返回值是命名的,则return语句可以像没有命名的返回值方式一样或者是一个空的return语句。注意尽管空的return语句是合法的,但它被认为是一种拙劣的写法,我们这本书所有的例子都没有这样写。
如果函数有返回值,则函数的最后一个语句必须是一个return语句或者panic()调用。如果函数是以抛出异常结束,Go 编译器会认为这个函数不需要正常返回,所以也就不需要这个return语句。但是如果函数是以if语句或switch语句结束,且这个if语句的else分支以return语句结尾或者switch语句的default分支以return语句结尾的话,Go编译器还无法意识到它们后面已经不需要return语句。对于这种情况的解决方法有几种,要么不给if语句和switch语句添加对应的else语句和default分支,要么将return语句放到if或者switch后面,或者在最后简单地加上一句panic("unreachable")语句,我们前面看到过这种做法(5.2.2.1节)。
我们之前见过的函数都是固定参数和指定类型的,但是如果参数的类型是interface{},我们就可以传递任何类型的数据。通过使用接口类型参数(无论是自定义接口类型还是标准库里定义的接口类型),我们可以让所创建的函数接受任何实现特定方法集合的类型作为参数,我们在6.3节会继续讨论这个问题。
这一节我们来了解关于函数参数的其他内容。第一个小节关于如何将函数的返回值作为其他函数的参数,第二小节讨论可变参数,最后我们讨论如何实现可选参数。
5.6.1.1 将函数调用作为函数的参数
如果我们有一个函数或者方法,接收一个或者多个参数,我们可以理所当然地直接调用它并给它相应的参数。另外,我们可以将其他函数或者方法调用作为一个函数的参数,只要该作为参数的函数或者方法的返回值个数和类型与调用函数的参数列表匹配即可。
下面是一个例子,一个函数要求传入三角形的边长(以 3 个整型数的方式),然后使用海伦公式计算出三角形的面积。
for i := 1; i <= 4; i++ {
a, b, c := PythagoreanTriple(i, i+1)
∆1 := Heron(a, b, c)
∆2 := Heron(PythagoreanTriple(i, i+1))
fmt.Printf("∆1 == %10f == ∆2 == %10f\n", ∆1, ∆2)
}
∆1 == 6.000000 == ∆2 == 6.000000
∆1 == 30.000000 == ∆2 == 30.000000
∆1 == 84.000000 == ∆2 == 84.000000
∆1 == 180.000000 == ∆2 == 180.000000
首先我们使用欧几里德的勾股函数来获得边长,然后将这3个边长作为Heron()的参数,应用海伦公式来计算面积。我们重复一次这个计算过程,不过这次我们是直接将PythagoreanTriple()函数作为Heron()函数的参数,交由Go语言将PythagoreanTriple()函数的3个返回值转换成Heron()函数的参数。
func Heron(a, b, c int) float64 {
α, β, γ := float64(a), float64(b), float64(c)
s := (α + β + γ) / 2
return math.Sqrt(s * (s - α) * (s - β) * (s - γ))
}
func PythagoreanTriple(m, n int) (a, b, c int) {
if m < n {
m, n = n, m
}
return (m * m) - (n * n), (2 * m * n), (m * m) + (n * n)
}
为了阅读完整性,这里给出了 Heron()和PythagoreanTriple()函数的实现。这里PythagoreanTriple()函数使用了命名返回值(算是对该函数文档的一些补充)。
5.6.1.2 可变参数函数
所谓可变参数函数就是指函数的最后一个参数可以接受任意个参数。这类函数在最后一个参数的类型前面添加有一个省略号。在函数里面这个参数实质上变成了一个对应参数类型的切片。例如,我们有一个签名是Join(xs...string)的函数,xs的类型其实是[]string。
下面是一个使用可变参数的例子,它返回输入的整数里最小的一个。我们将分析它的调用过程以及输出的结果。
fmt.Println(MinimumInt1(5, 3), MinimumInt1(7, 3, -2, 4, 0, -8, -5))
3 –8
MinimumInt1()函数可以传入一个或者多个整型数,然后返回其中最小的一个。
func MinimumInt1(first int, rest...int) int {
for _, x := range rest {
if x < first {
first = x
}
}
return first
}
我们可以很容易地实现一个任意参数(即使不传参数也可以)的函数,例如MinimumInt0 (ints...int),或者至少是两个整型数的函数,例如,MinimunInt2(forst, second, int, rest...int)。
假如我们有一个[]int类型的切片,我们可以这样使用MinimunInt1()函数。
numbers := []int{7, 6, 2, -1, 7, -3, 9}
fmt.Println(MinimumInt1(numbers[0], numbers[1:]...))
-3
函数MinimunInt1()至少需要一个int型的参数,当调用一个可变参数函数或者方法时,我们可以在一个slice后面放一个省略号,这样就把切片变成了一系列参数,每个参数对应切片里的一项。(我们之前在4.2.3节讨论Go语言内置的append()函数时讨论过。)所以我们这里实际上就是将numbers[1:]...展开成独立的每一个参数6,-2,-1,7,-3,9了,而这些都会被保存在rest这个切片里面。如果我们使用刚才提到过的MinimunInt0()函数,我们简单地调用MinimumInt0(numbers...)即可。
5.6.1.3 可选参数的函数
Go语言并没有直接支持可选参数。但是,要实现它也不难,只需增加一个额外的结构体即可,而且Go语言能保证所有的值都会被初始化为零值。
假设我们有一个函数用来处理一些自定义的数据,默认就是简单地处理所有的数据,但有些时候我们希望可以指定处理第一个或者最后一个项,还有是否记录函数的行为,或者对于非法的项做错误处理,等等。
一个办法就是创建一个签名为 ProcessItems(items Items, first, last int, audit bool, errorHandler func(item Item))的函数。在这个设计里,如果last的值为0的话意味着需要取到最后一个item而不用管这个索引值,而errorHandler函数只有在不为nil时才会被调用。也就是说,不管在哪调用它,如果希望是默认行为的话,只需要写ProcessItems(items, 0, 0, false, nil)就可以了。
一个比较优雅的做法就是这样定义函数 ProcessItems(items Items, options Options),其中Options结构体保存了所有其他参数的值,初始值均为零值。这样大部分调用都可以被简化为 ProcessItems(items, Options{})。然后在我们需要指定一个或者多个额外参数的场合,我们可以为 Options 结构指定一到多个字段的值(我们会在 6.4节详细描述结构体)。让我们来看看如何用代码实现,先从Options结构开始。
type Options struct {
First int // 要处理的第一项
Last int // 要处理的最后一项(O意味着要从第一项开始处理所有项)
Audit bool // 如果为trne,所有动作都被记录
ErrorHandler func(item Item) // 如果不是nil,对每一个坏项周用一次
}
一个结构体能够聚合或者嵌入一个或者多个任何类型的字段(关于聚合和嵌入的区别将在第6章详细描述)。这里,Options结构体聚合了两个int型字段、一个bool型字段以及一个签名为func(Item)的函数,其中Item是某自定义类型。
ProcessItems(items, Options{})
errorHandler := func(item Item) { log.Println("Invalid:", item) }
ProcessItems(items, Options{Audit: true, ErrorHandler: errorHandler})
这块代码调用了两次自定义函数ProcessItems(),第一次调用使用默认的选项(例如,处理所有的项,但是不记录任何的动作,对于非法的记录也不调用错误处理函数来处理),第二次调用时创建了一个Options值,其中Options的First字段和Last字段是0(也就是告诉这个函数要处理所有的项),但设置了Audit和ErrorHandler字段这样函数就能记录它的行为而且当发现非法的项时能够做一些相应的处理。
这种利用结构体来传递可选参数的技术在标准库里也有用到,例如,image.jpeg.Encode()函数,我们在后面的6.5.2节还会看到这种技术。
Go语言为特定目的保留了两个函数名: init()函数(可以出现在任何的包里)和main()函数(只在main包里)。这两个函数既不可接收任何参数,也不返回任何结果,一个包里可以有很多init()函数。但是我写这本书的时候,Go编译器只支持每个包最多一个init()函数,所以我们推荐你在一个包里最多只用一个init()函数。
init()函数和main()函数是自动执行的,所以我们不应该显式调用它们。对程序或者包来说init()是可选的,但是每一个程序必须在main包里包含一个main()函数。
Go程序的初始化和执行总是从main包开始,如果main包里导入了其他的包,则会按顺序将它们包含进 main 包里。如果一个包被其他的包多次导入的话,这个包实际上只会被导入一次(例如,有好些包都会导入 fmt 这个包,一旦导入之后再遇到就不会再次导入)。当一个包被导入时,如果它自己还导入了其他的包,则还是先将其他的包导入进来,然后再创建这个包的一些常量和变量。再接着就是调用init()函数了(如果有多个就调用多次),最终所有的包都会被导入到main包里(包括这些包所导入的包等),这时候main这个包的常量和变量也会被创建,init()函数会被执行(如果有或者多个的话)。最后,main包里的main()函数会被执行,程序开始运行。这些事件的过程如图5-1所示。
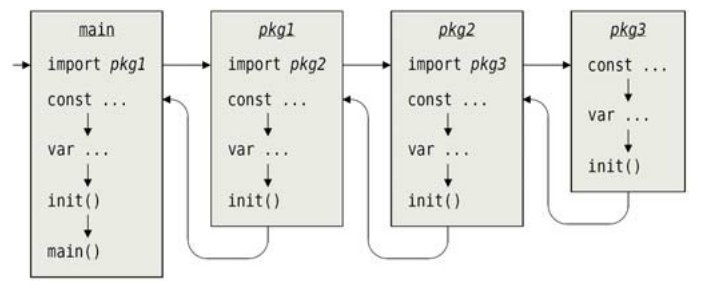
图5-1 程序的启动顺序
我们可以在init()函数里写一些go语句,但是要注意的是init()函数会在main()函数之前执行,所以init()中不应该依赖任何在main()函数里创建的东西。
让我们来看一个例子(从第1章的americanise/americanise.go文件里截取),看看实际会发生什么事情。
package main
import (
"bufio"
"fmt"
//...
"strings"
)
var britishAmerican = "british-american.txt"
func init() {
dir, _ := filepath.Split(os.Args[0])
britishAmerican = filepath.Join(dir, britishAmerican)
}
func main() {
//...
}
Go程序从main包开始,因为main包里导入了其他的包,所以它先按顺序从bufio包开始把其他的包导进来。bufio包自身也导入了一些其他的包,所以这些导入会先完成。在导入每一个包时总是先会去将这个包的所有依赖包导入,然后才创建包级别的常量和变量,再接着执行这个包的init()函数。bufio包导入完成后fmt包会被导入。fmt包里它自己也导入了strings包,所以当Go语言会忽略main包导入strings包的语句,因为strings包之前已被导入。
当所有的包被导入后,包级别的britishAmerican变量会被创建,然后main包里的init()函数会被调用。最后main()函数被调用,程序开始执行。
所谓闭包就是一个函数“捕获”了和它在同一作用域的其他常量和变量。这就意味着当闭包被调用的时候,不管在程序什么地方调用,闭包能够使用这些常量或者变量。它不关心这些捕获了的变量和常量是否已经超出了作用域,所以只要闭包还在使用它,这些变量就还会存在。
在Go语言里,所有的匿名函数(Go语言规范中称之为函数字面量)都是闭包。
闭包的创建方式和普通函数在语法上几乎一致,但有一个关键的区别:闭包没有名字(所以func关键字后面紧接着左括号)。通常都是通过将闭包赋值给一个变量来使用闭包,或者将它放到一个数据结构里(如映射或者切片)。
我们已经见过好几个闭包的例子,例如,当我们使用defer语句或者匿名函数的时候。我们在这本书的一些例子里也创建过闭包,如americanise例子里使用的makeReplacerFunction()函数(1.6 节),在第 3 章中当我们将匿名函数作为参数传递给 strings.FieldsFunc()或者strings.Map()函数时(3.6.1节),还有这一章之前的createCounter()函数和logPanics()函数。不过我们在这里还会介绍一些简单的例子。
闭包的一种用法就是利用包装函数来为被包装的函数预定义一到多个参数。例如,假如我们想给大量文件增加不同后缀,本质上就是要包装 string的+连接操作符,一个参数会不断变化(文件名)而另一个参数为固定值(后缀名)。
addPng := func(name string) string { return name + ".png" }
addJpg := func (name string) string { return name + ".jpg" }
fmt.Println(addPng("filename"), addJpg("filename"))
filename.png filename.jpg
addPng和addJpg变量都是对匿名函数(即闭包)的引用。这种引用可以像上述代码段中说明的那样像正常命名的函数那样被调用。
现实环境中当我们需要创建很多类似的函数时,相比一个个单独创建,我们经常会用到一个工厂函数(factory function),工厂函数返回一个函数。下面就是一个工厂函数的例子。它返回一个函数。如果接收到的文件名不带后缀名,那么这个函数就为它增加一个后缀名。
func MakeAddSuffix(suffix string) func(string) string {
return func(name string) string {
if !strings.HasSuffix(name, suffix) {
return name + suffix
}
return name
}
}
工厂函数MakeAddSuffix()返回的闭包在创建时捕获了suffix变量。这个返回的闭包接收一个字符串参数(如文件名)并返回添加了被捕获的suffix的的文件名。
addZip := MakeAddSuffix(".zip")
addTgz := MakeAddSuffix(".tar.gz")
fmt.Println(addTgz("filename"), addZip("filename"), addZip("gobook.zip"))
filename.tar.gz filename.zip gobook.zip
这里创建了两个闭包addZip()和addTgz()并调用了它们。
递归函数就是调用自己的函数,还有相互递归函数就是相互调用对方的函数。Go语言完全支持递归函数。
递归函数通常有相同的结构:一个跳出条件和一个递归体,所谓跳出条件就是一个条件语句,例如 if 语句等,根据传入的参数判断是否需要停止递归,而递归体则是函数自身所做的一些处理,包括最少也得调用自身一次(或者调用它相互递归的另一个函数),而且递归调用时所传入的参数一定不能和当前函数传入的一样,在跳出条件里还会检查是否可以结束递归。
递归函数非常便于实现递归的数据结构例如二叉树,但是对于数值计算而言可能会性能比较低下。
我们从一个非常简单(性能也比较低)的示例开始介绍一下如何实现递归。首先我们看一个对递归函数的调用和相应输出,然后我们再看看递归函数本身。
for n := 0; n < 20; n++ {
fmt.Print(Fibonacci(n), " ")
}
fmt.Println()
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597 2584 4181
Fibonacci()函数返回一个包含n个数字的斐波那契数列。
func Fibonacci(n int) int {
if n < 2 {
return n
}
return Fibonacci(n-1) + Fibonacci(n-2)
}
上面的if 语句是这个递归函数的跳出条件,用它来保证递归最终是可以结束的。这是因为不管我们当初指定的n是什么,每一次递归调用函数自身的时候,传给递归函数的n值都会减少,因此n的值在某个时刻必然会小于2。
举个例子,如果我们调用Fibonacci(4),跳出条件不会被触发,函数返回两个递归调用Fibonacci(3)和Fibonacci(2)的和,前者会递归调用 Fibonacci(2)(同理, Fibonacci(2)也会调用Fibonacci(1)和Fibonacci(0))和Fibonacci(1),后者则会递归调用Fibonacci(1)和Fibonacci(0),一旦n小于2则递归就会返回,这个过程可以用图5-2来描述。
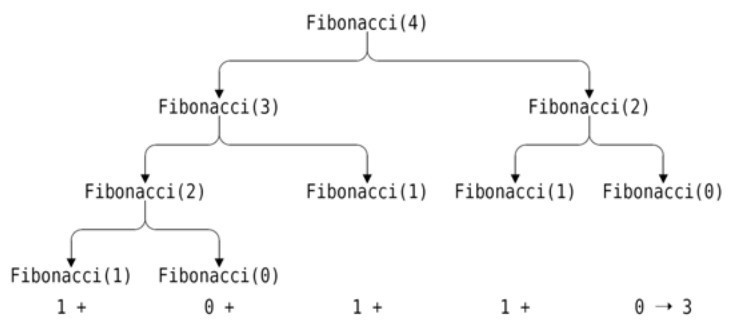
图5-2 递归的Fibonacci
显然,Fibonacci()做了很多重复的计算,尽管我们只是输入了一个很小的数如4。我们后面会看到如何避免这个问题(参见5.6.7节)。
Hofstadter 男女序列就是一个使用相互递归函数的例子,下面的代码将每个序列中的前 20个整数打印出来:
females := make([]int, 20)
males := make([]int, len(females))
for n := range females {
females[n] = HofstadterFemale(n)
males[n] = HofstadterMale(n)
}
fmt.Println("F", females)
fmt.Println("M", males)
F [1 1 2 2 3 3 4 5 5 6 6 7 8 8 9 9 10 11 11 12]
M [0 0 1 2 2 3 4 4 5 6 6 7 7 8 9 9 10 11 11 12]
下面是产生以上序列的两个相互递归函数。
func HofstadterFemale(n int) int {
if n <= 0 {
return 1
}
return n - HofstadterMale(HofstadterFemale(n-1))
}
func HofstadterMale(n int) int {
if n <= 0 {
return 0
}
return n - HofstadterFemale(HofstadterMale(n-1))
}
通常在函数的开始处都会有一个跳出条件用来确保递归能够正常结束,在递归发生的地方我们递归传入的参数是一个不断减少的值,最终跳出条件会被满足。
其他语言实现的Hofstadter 函数通常会有一个问题,那就是 HofstadterFemale()函数是在HofstadterMale()之前定义的,但是HofstadterFemale()却调用了HofstadterMale()函数。这些编程语言将要求我们预声明HofstadterMale()函数。Go语言没有这样的限制,因为Go语言允许函数以任何顺序定义。
我们再来看最后一个递归的例子,它判断一个单词是否是一个回文单词(也就是单词反转后和原单词是一模一样的,如“PULLUP”和“ROTOR”都是回文单词)。
func IsPalindrome(word string) bool {
if utf8.RuneCountInString(word) <= 1 {
return true
}
first, sizeOfFirst := utf8.DecodeRuneInString(word)
last, sizeOfLast := utf8.DecodeLastRuneInString(word)
if first != last {
return false
}
return IsPalindrome(word[sizeOfFirst : len(word)-sizeOfLast])
}
函数第一部分是一个跳出条件:如果单词的长度为0或者1,那么就认为这是一个回文,所以直接返回 true。而函数体所用的算法,是比较首字母和尾字母,如果它们不同,那么这个单词肯定不是回文,我们可以立即返回false。但是如果首字符和尾字符是相同的,那我们就递归判断这个单词的一个字串(去掉首尾两个字符)是否是回文。
举个例子,我们传入一个字符串“PULLUP”,函数首先比较首字符“P”和尾字符“P”,然后它调用自己判断子字符串“ULLU”,再比较“U”和“U”,然后再递归调用判断子字符串“LL”,比较“L”和“L”,最后它递归调用时传的是一个空的字符串。同样,对于“ROTOR”这个字符串,首先函数是比较首字符“R”和尾字符“R”,然后递归判断“OTO”,比较首字符“O”和尾字符“O”,最后递归判断一个单子符“T”。这两种情况,函数都返回 true。但对“DECIDED”字符串,函数先比较“D”和“D”,然后递归判断“ECIDE”,比较“E”和“E”,当判断到“C”和“D”的时候,它返回了false。
回忆一下我们在3.6.3节讲到的utf8.DecodeRuneInString()函数,它返回字符串的第一个字符(rune类型)和它占用的字节数。utf8.DecodeLastRuneInString()函数也类似,作用于最后一个字符,利用这两个大小,我们可以安全地将每个字符都切割出来,因为它们不会意外将一个多字节表示的字符切割成两个。
当一个函数使用尾部递归,也就是在最后执行一句递归调用,这种情况下我们可以简单地将它转换成一个循环。使用循环的好处就是可以减少递归调用的开销,因为有限的栈空间对函数的深度递归是很有影响的,虽然由于 Go语言使用了自己的内存管理机制导致这个栈空间的限制相对不严重一些。(顺便提一下,后面我们有个练习让大家将递归函数IsPalindrome()转换成使用循环的方式实现。)当然,有些时候递归是实现算法的最好方式,我们将在第6章介绍omap.insert()函数的时候看到这样的一个例子。
在Go语言里,函数属于第一类值(first-class value),也就是说,你可以将它保存到一个变量(实际上是个引用)里,这样我们就可以在运行时决定要执行哪一个函数。再者,Go语言能够创建闭包意味着我们可以在运行时创建函数,所以我们对同一个函数可以有两个或者多个不同的实现(例如使用不同的算法),在使用的时候创建它们其中的一个就行。我们在下一节讨论这两种方法。
5.6.5.1 使用映射和函数引用来制造分支
在 5.2.1节和5.2.2.1节中我们看过了 ArchiveFileList()的所有代码,它就是根据文件的后缀名然后调用对应的函数。这个函数的版本1首先用的是一个if语句,总共7行代码,最简洁的那个版本用的是swtich语句,5行代码。但万一我们需要处理的文件后缀名多了怎么办,如果是 if的话我们需要为每个额外的else if 分支增加两行代码,是switch的话我们需要为每个额外的情况增加一行代码(或者两行,使用 gofmt 格式化分支代码的话)。如果这个函数用于文件管理的话,它很可能需要处理几百种文件后缀,从而导致这个函数就非常长。
var FunctionForSuffix = map[string]func(string) ([]string, error){
".gz": GzipFileList, ".tar": TarFileList, ".tar.gz": TarFileList,
".tgz": TarFileList, ".zip": ZipFileList}
func ArchiveFileListMap(file string) ([]string, error) {
if function, ok := FunctionForSuffix[Suffix(file)]; ok {
return function(file)
}
return nil, errors.New("unrecognized archive")
}
现在这个版本的ArchiveFileList 函数使用了映射,这个映射的键是字符串(文件后缀),值则是签名为 func(string) ([]string, error)的函数(所有自定义函数GzipFileList()、TarFileList()和ZipFileList()都是这种类型)。
这个函数使用[]索引操作符根据给定的前缀从FunctionForSuffix结构里得到对应的函数,如果这个前缀存在则ok的值为true,否则为false。如果存在匹配的函数的话,执行这个函数并将文件名作为参数传递给它,返回它的结果。
这个函数比使用if或者switch语句的更具有扩展性,不管有多少个文件的前缀处理函数在FunctionForSuffix里,这个函数都可以保持不变。这不像一个很大的if或者switch语句,不但事情变得条理清晰,还可以动态地往映射里增加其他的项,而且映射查询的速度不会随着项的增加而降低 [9] 。
5.6.5.2 动态函数的创建
在运行时动态地选择函数的另一个场景便是,当我们有两个或者更多的函数实现了相同的功能时,比如使用了不同的算法等,我们不希望在程序编译时静态绑定到其中任一个函数(例如允许我们动态地选择它们来做性能测试或回归测试)。
举个例子,如果我们使用一个 7 位的ASCII 字符,我们可以写一个更加简单的IsPalindrome()函数,而在运行时动态地创建一个我们所需要的版本。
一种做法就是声明一个和这个函数签名相同的包级别的变量,然后创建一个appropriate()函数和一个init()函数。
var IsPalindrome func(string) bool // 保存到函数的引用
func init() {
if len(os.Args) > 1 && (os.Args[1] == "-a" || os.Args[1] == "--ascii") {
os.Args = append(os.Args[:1], os.Args[2:]...) // 去掉参数
IsPalindrome = func(s string) bool { // 简单的ASCII版本
if len(s) <= 1 {
return true
}
if s[0] != s[len(s)-1] {
return false
}
return IsPalindrome(s[1 : len(s)-1])
}
} else {
IsPalindrome = func(s string) bool { // UTF-8版本
// …… 同前……
}
}
}
我们根据命令行选项来决定 IsPalindrome()的实现方式。如果指定了“-a”或者“--ascii”参数,我们将它从os.Args切片里移除(这样其他代码不需要知道和关心这个参数),然后创建一个作用于ASCII码的IsPalindrome()函数。这个移除的过程有些隐晦,我们是将os.Args的第一个参数和第三个之后的参数组合成一个新的os.Args,还有我们不能在append()函数里使用os.Args[0],因为append()的第一个参数必须是一个切片,所以我们用了os.Args[:1],这个切片只有一个项,那就是os.Args[0](参见4.2.1节)。
如果ASCII选项没有出现,我们就创建一个和之前一样的函数,既能处理ASCII编码的字符串也能处理UTF-8编码的字符串。程序其他部分IsPalindrome()函数可以正常地被调用,但是实际上什么代码会被执行完全取决于我们创建的是哪个版本的函数。(这个例子的源码在palindrome/palindrome.go里。)
这一章前面的部分我们创建过一个函数,找出输入整数里最小的一个并返回。同样,我们可以将这个函数应用到不同的数据类型上,甚至是字符串,只要这个类型的值支持 < 操作符就行。在C++里我们会习惯创建一个泛型函数,根据类型来确定参数,这样就可以让编译器按我们的需要来创建多个版本的函数(例如,每种类型一个函数)。在我写这本书的时候,Go语言还不支持类型参数化,所以我们不得不为每一种类型都实现一个函数,如 MinimunInt()、MinimumFloat()、MinimumString()等。这导致对于每个类型都得有一个对应的函数(和C++一样,只不过在Go语言里每个函数必须有唯一的函数名)。
为了提高运行时的效率,Go语言提供了多种替代方法来避免创建一些除了处理的数据类型不同外其他完全相同的函数。对于那些不经常使用或者速度已经足够快的小函数而言,这些替代方法会非常便利。
下面就是一个支持泛型的Minimum()函数的例子。
i := Minimum(4, 3, 8, 2, 9).(int)
fmt.Printf("%T %v\n", i, i)
f := Minimum(9.4, -5.4, 3.8, 17.0, -3.1, 0.0).(float64)
fmt.Printf("%T %v\n", f, f)
s := Minimum("K", "X", "B", "C", "CC", "CA", "D", "M").(string)
fmt.Printf("%T %q\n", s, s)
int 2
float64 -5.4
string "B"
这个函数返回一个interface{}类型的值,我们使用一个非检查类型断言(5.1.2节)将这个值转换成我们所期望的值。
unc Minimum(first interface{}, rest...interface{}) interface{} {
minimum := first
for _, x := range rest {
switch x := x.(type) {
case int:
if x < minimum.(int) {
minimum = x
}
case float64:
if x < minimum.(float64) {
minimum = x
}
case string:
if x < minimum.(string) {
minimum = x
}
}
}
return minimum
}
该函数接受至少一个值(first),以及零到多个其他值(rest)。我们使用interface{}作为参数的类型,这样我们可以传入任意类型的数据。首先我们假设第一个值是最小的,然后遍历其他的参数,若发现有比当前最小值更小的,就把它设为当前最小值,最后返回minimum,它也是 interface{}类型的,所以我们需要在调用端用非检查类型断言来将它转换成一个内置数据类型。
但这段代码仍有很多地方是重复的,如if语句里的每一个case分支,但如果有太多重复的代码我们可以简单地在每一个case分支上设置一个布尔类型(例如,change = true),然后在switch语句后面增加一个if change语句,用来包含所有公用的代码。
很明显,使用 Minimum()函数比那些类型特定的最小函数损失了一点效率,但是这种技术非常值得了解,因为在只需定义一次函数的好处抵得过类型测试的损耗和转换的不便利性时它会变得很有价值。
还有一个比较头疼的问题,上面的泛型函数处理不了实际类型为切片的interface{}参数。举个例子,下面的函数传入一个切片和与切片的项类型相同的值,返回这个值在切片里第一次出现的索引,如果不存在就返回−1。
func Index(xs interface{}, x interface{}) int {
switch slice := xs.(type) {
case []int:
for i, y := range slice {
if y == x.(int) {
return i
}
}
case []string:
for i, y := range slice {
if y == x.(string) {
return i
}
}
}
return -1
}
下面是一个使用Index()函数的例子及其输出结果(源代码在contains/contains.go测试程序里)。
xs := []int{2, 4, 6, 8}
fmt.Println("5 @", Index(xs, 5), " 6 @", Index(xs, 6))
ys := []string{"C", "B", "K", "A"}
fmt.Println("Z @", Index(ys, "Z"), " A @", Index(ys, "A"))
5 @ -1 6 @ 2
Z @ -1 A @ 3
我们真正要做的只是希望能够通用的方式对待切片。我们可以仅用一个循环然后在里面用特定类型(type-specific)测试呢?下面的IndexReflectX()函数就是为了这个目的创建。如果我们将上述代码片段中的Index()调用替换为 IndexReflectX()调用,这段代码将输出相同的结果。
func IndexReflectX(xs interface{}, x interface{}) int { // 啰唆的方法
if slice := reflect.ValueOf(xs); slice.Kind() == reflect.Slice {
for i := 0; i < slice.Len(); i++ {
switch y := slice.Index(i).Interface().(type) {
case int:
if y == x.(int) {
return i
}
case string:
if y == x.(string) {
return i
}
}
}
}
return -1
}
这个函数用到Go语言的反射功能(由reflect包提供,9.4.9节),将xs interface{}转换成一个切片类型的reflect.Value。我们可以遍历这个切片得到我们所关心的项。这里我们轮流访问每一个项,使用reflect.Value.Interface()函数将它的值以interface{}类型提取出来,然后马上在switch里赋值给y。这就确保了y和切片里的项具有相同的类型(例如,int或者string),后面就可以直接和非检查类型断言的x值进行比较。
实际上,reflect包可以做的事情比这多得多,显然我们可以这样简化一下这个函数。
func IndexReflect(xs interface{}, x interface{}) int {
if slice := reflect.ValueOf(xs); slice.Kind() == reflect.Slice {
for i := 0; i < slice.Len(); i++ {
if reflect.DeepEqual(x, slice.Index(i)) {
return i
}
}
}
return -1
}
这里我们是使用 reflect.DeepEqual()函数来做比较的,这个函数的功能非常强大,还可以用来比较数组、切片和结构体。
下面是一个特定类型的函数,在一个切片里查找某一项的索引。
func IntSliceIndex(xs []int, x int) int {
for i, y := range xs {
if x == y {
return i
}
}
return -1
}
相比泛型函数,这种写法是很简洁的,但是如果我们想增加一种类型,就不得不创建一个额外的函数,而这个函数仅仅是函数名和参数类型不同罢了。
我们可以通过使用自定义类型将泛型函数的好处(仅需实现一次算法)和类型特定函数的简便性和高效率结合在一起。下一章我们会详细介绍这种技术。
下面两个函数都是在一个切片里查找特定项的索引,其中一个是特定类型的实现,另一个是泛型实现。
func IntIndexSlicer(ints []int, x int) int {
return IndexSlicer(IntSlice(ints), x)
}
func IndexSlicer(slice Slicer, x interface{}) int {
for i := 0; i < slice.Len(); i++ {
if slice.EqualTo(i, x) {
return i
}
}
return -1
}
IntIndexSlicer()函数传入一个[]int型的切片和一个int型的整数,然后将它们传给泛型函数IndexSlicer()。IndexSlicer()操作一个Slicer类型的值。Slicer是一个自定义的接口。任何类型可以通过实现 Slicer 方法(Slicer.EqualTo()和Slicer.Len())来实现此接口。
type Slicer interface {
EqualTo(i int, x interface{}) bool
Len() int
}
type IntSlice []int
func (slice IntSlice) EqualTo(i int, x interface{}) bool {
return slice[i] == x.(int)
}
func (slice IntSlice) Len() int { return len(slice) }
我们需要在泛型函数IndexSlicer()里实现Slicer接口的这两个方法。
IntSlice是[]int的别名,这也就是为什么IntIndexSlicer()函数能直接将接收到的[]int类型值直接赋给IntSlice而不需要显式转换,并且提供这两个方法以实现Slicer接口。IntSlice.EqualTo()方法需要传入一个索引和一个值,如果这个值和切片里索引处的值相等,就返回 true。Slicer 接口指定这个值是一个通用的interface{}类型而不是int,这样其他类型的切片也可以实现Slicer接口(如FloatSlice和StringSlice),所以我们必须将这个值转换成实际的类型。这里使用非检查类型断言是安全的,因为我们知道这个值最终来自于对 IntSliceIndex()函数的调用,而 IntSliceIndex()函数的参数为int类型。
我们也可以为其他类型的切片实现Slicer接口,然后它们也可以使用IndexSlicer()函数。
type StringSlice []string
func (slice StringSlice) EqualTo(i int, x interface{}) bool {
return slice[i] == x.(string)
}
func (slice StringSlice) Len() int { return len(slice) }
StringSlice和IntSlice唯一不同的地方就是切片的类型([]string和[]int)和非检查类型断言(string和int)。FloatSlice也是一样的([]float64和float64)。
其实最后一个例子所用的技术在之前我们讨论自定义排序的时候就见过了(参见4.2.4节),用来实现标准库的sort包里的排序函数。关于自定义接口和自定义类型将会在第6章详细描述。
当我们使用切片或者映射时,通常可以创建泛型函数,这样就不用使用类型测试和类型断言。或者,将我们的泛型函数写成高阶函数,对所有特定的类型相关逻辑进行抽象,这将在下一节描述。
所谓高阶函数就是将一个或者多个其他函数作为自己的参数,并在函数体里调用它们。让我们来看一个最简单的高阶函数,但它的功能不是马上就能看得出来的。
func SliceIndex(limit int, predicate func(i int) bool) int {
for i := 0; i < limit; i++ {
if predicate(i) {
return i
}
}
return -1
}
这个函数很普通,返回 predicate()为真时的索引值,所以这个函数能做 Index()、IndexReflect()、IntSliceIndex()的所有工作,还有上一节的IniIndexSlicer()函数,但没有一行多余的代码,也没有类型开关和类型断言。
SliceIndex()函数并不知道而且也不需要关心切片或者项的类型,实际上,这些对函数来说是透明的,它只知道一个长度信息和它的第二个参数,也就是个对于任意给定索引值返回一个布尔值的函数,表明这个索引是否是调用者所期望的。
下面是函数调用的4个样例和它们输出的结果。
xs := []int{2, 4, 6, 8}
ys := []string{"C", "B", "K", "A"}
fmt.Println(
SliceIndex(len(xs), func(i int) bool { return xs[i] == 5 }),
SliceIndex(len(xs), func(i int) bool { return xs[i] == 6 }),
SliceIndex(len(ys), func(i int) bool { return xs[i] == "Z" }),
SliceIndex(len(ys), func(i int) bool { return xs[i] == "A" }))
-1 2 -1 3
传给SliceIndex()的第二个参数的匿名函数是一个闭包,所以它们引用的xs和ys切片必须和这个函数被创建的地方在同一作用域(Go语言标准库里的sort.Search()函数使用同样的技术)。
实际上,SliceIndex()就是一个能直接处理切片的通用函数。
i := SliceIndex(math.MaxInt32,
func(i int) bool { return i > 0 && i%27 == 0 && i%51 == 0 })
fmt.Println(i)
459
上面的代码使用了SliceIndex()来查找能被27和51整除的最小自然数,这种做法有些微妙。SliceIndex()函数从0开始遍历到math.MaxInt32,每一次遍历,它都调用匿名函数,一旦匿名函数返回 true,SliceIndex()函数就马上将当前的值返回,这个值就是我们要寻找的自然数。
除查找未排序切片外,另一种有用的场景是过滤掉不关心的数据。下面是一个高阶过滤函数,通过匿名函数来判断传入的[]int切片的某项是保留还是丢弃。
readings := []int{4, -3, 2, -7, 8, 19, -11, 7, 18, -6}
even := IntFilter(readings, func(i int) bool { return i%2 == 0 })
fmt.Println(even)
[4 2 8 18 -6]
这里,我们过滤掉所有的奇数。
func IntFilter(slice []int, predicate func(int) bool) []int {
filtered := make([]int, 0, len(slice))
for i := 0; i < len(slice); i++ {
if predicate(slice[i]) {
filtered = append(filtered, slice[i])
}
}
return filtered
}
IntFilter()函数有两个参数,一个是[]int 切片,另一个是 predicate()函数,返回true则表示保留,否则反之。最后返回一个新的切片,包含了过滤后的所有数据。
对切片进行过滤是一个很常用的功能,所以如果IntFilter()函数只能处理[]int型切片的话那就太可惜了。幸运的是,使用我们设计SliceIndex()函数的那种技术,我们完全可以创建一个通用的过滤函数。
func Filter(limit int, predicate func(int) bool, appender func(int)) {
for i := 0; i < limit; i++ {
if predicate(i) {
appender(i)
}
}
}
和SliceIndex()函数一样,Filter()函数也不知道自己所操作的数据实际是什么, Filter()的过滤和追加功能依赖于它传进来的predicate()函数和appender()函数。
readings := []int{4, -3, 2, -7, 8, 19, -11, 7, 18, -6}
even := make([]int, 0, len(readings))
Filter(len(readings), func(i int) bool { return readings[i]%2 == 0 },
func(i int) { even = append(even, readings[i]) })
fmt.Println(even)
[4 2 8 18 -6]
这段代码和之前那段代码的处理过程是完全一样的,只是在这里我们必须在Filter()函数外创建一个新的even切片。我们传给Filter()的第一个匿名函数只有一个索引参数,如果切片里索引处的项是个偶数的话就返回 true。第二个匿名函数是将索引处对应的项追加到开始时创建的新的切片里去。当匿名函数被传入时even和readings两个切片要在当前作用域里,这样匿名函数才能够捕获到以便访问它们。
parts := []string{"X15", "T14", "X23", "A41", "L19", "X57", "A63"}
var Xparts []string
Filter(len(parts), func(i int) bool { return parts[i][0] == 'X' },
func(i int) { Xparts = append(Xparts, parts[i]) })
fmt.Println(Xparts)
[X15 X23 X57]
注意这里处理的是字符串而不是整数,可见Filter()函数能支持不同的数据类型。
var product int64 = 1
Filter(26, func(i int) bool { return i%2 != 0 },
func(i int) { product *= int64(i) })
fmt.Println(product)
7905853580625
这是最后一个关于过滤的例子,和SliceIndex()函数差不多,Filter()并非只能用来处理切片,这里我们就用它来计算范围[1, 25]内所有奇数的乘积。
纯记忆函数
所谓纯函数就是对同一组输入总是产生相同的结果,不存在任何副作用。如果一个纯函数执行时开销很大而且频繁地使用相同的参数进行调用,我们可以使用记忆功能来降低处理的开销。记忆技术就是保存计算的结果,当执行下一个相同的计算时,我们能够返回保存的结果而不是重复执行一次计算过程。
使用递归来计算斐波纳契数列的开销非常大,而且重复地计算相同的过程,就像之前图 5-2里看到的。这种情况下最容易的解决方法就是使用一个非递归的算法,但为了展示我们如何使用记忆功能,我们先创建一个使用递归的具有记忆功能的斐波纳契函数。
type memoizeFunction func(int,...int) interface{}
var Fibonacci memoizeFunction
func init() {
Fibonacci = Memoize(func(x int, xs...int) interface{} {
if x < 2 {
return x
}
return Fibonacci(x-1).(int) + Fibonacci(x-2).(int)
})
}
Memoize()函数(很快就会讲到)可以记忆任何传入至少一个 int 参数并返回一个interface{}的函数。为了方便,我们为这种函数创建了memoizeFunction类型,并声明一个 Fibonacci 变量用来保存这个类型的函数。然后,在程序的init()函数里,我们创建了一个计算斐波纳契数列的匿名函数,并立即将它传给 Memoize()函数。相应地,Memoize()函数返回一个memoizeFunction类型的函数,然后赋值给Fibonacci变量。
在这个特定例子里,我们只需传一个参数给Fibonacci函数,所以我们可以忽略所有其他传入的整数(即忽略 xs,在这个例子里它应该是一个空的切片)。还有,当我们将递归的结果汇总的时候,我们必须使用非检查类型断言将返回值从interface{}类型转换成int类型。
现在我们可以像其他函数那样使用 Fibonacci(),而且得益于记忆功能,它不会重复执行相同的计算过程。
fmt.Println("Fibonacci(45) =", Fibonacci(45).(int))
Fibonacci(45) = 1134903170
我们使用非检查类型断言将它的interface{}类型的返回值转换成int(严格来说,这里不需要做转换,因为fmt包实现得非常优雅,它会自动处理这些事情,不过我这样写大家可以看到它实际是怎么用的)。
func Memoize(function memoizeFunction) memoizeFunction {
cache := make(map[string]interface{})
return func(x int, xs...int) interface{} {
key := fmt.Sprint(x)
for _, i := range xs {
key += fmt.Sprintf(",%d", i)
}
if value, found := cache[key]; found {
return value
}
value := function(x, xs...)
cache[key] = value
return value
}
}
我们这里用的Memoize()是最核心的函数,它将memoizeFunction类型的函数(函数签名为func(int,...int) interface{})作为参数然后返回一个相同签名的函数。
我们使用一个映射结构来保存预先计算的结果,映射的键是字符串,值是一个interface{}。映射被Memoize()返回的匿名函数捕获,也就是闭包。映射的键是将所有的整型参数组合并用逗号分隔的字符串(Go语言的映射要求键必须完全支持==和!=操作,字符串符合这个要求,但是切片不可以,参见4.3节)。键准备好之后我们看看是否在映射里有对应的“键/值”对,如果有我们就不需要重复计算,只需简单返回缓存的结果;否则我们就执行传给Memoize()函数的function 函数,再将结果缓存到映射。这样就不需要再次重复计算这个结果。最后,我们返回计算出来的值。
记忆功能对那些开销大的纯函数(不管它们有没有递归)而言是非常有用的,因为它们浪费了大部分的时间来计算一些参数相同的过程。例如,如果我们需要将大量整数转换成罗马数字而大部分这些整数都是重复的,这种情况就可以用 Memoize()函数来避免重复的计算。最好统计那些开销大的计算的花费时间(比如使用time包或性能测试工具),以便判断是否记忆功能(或任何其他可能的优化)是值得使用的。
var RomanForDecimal memoizeFunction
func init() {
decimals := []int{1000, 900, 500, 400, 100, 90, 50, 40, 10, 9, 5, 4, 1}
romans := []string{"M", "CM", "D", "CD", "C", "XC", "L", "XL", "X",
"IX", "V", "IV", "I"}
RomanForDecimal = Memoize(func(x int, xs...int) interface{} {
if x < 0 || x > 3999 {
panic("RomanForDecimal() only handles integers [0, 3999]")
}
var buffer bytes.Buffer
for i, decimal := range decimals {
remainder := x / decimal
x %= decimal
if remainder > 0 {
buffer.WriteString(strings.Repeat(romans[i], remainder))
}
}
return buffer.String()
})
}
RomanForDecimal是一个memoizeFunction类型的全局变量(当然,只是在他所在的包里,参见第9章),在init()函数里创建。decimals和romans切片是init()函数的本地变量,但是只要RomanForDecimal()函数还在使用,它们就会一直存在,因为RomanForDecimal是一个捕获了这两个变量的闭包。
Go语言的函数和方法真是难以置信的灵活和强大,提供了好几种方法来根据需求实现泛型。
这一节要讲解的例子就是如何对字符串进行排序。这个函数之所以特别(以及标准库的sort.Strings()函数为何无法满足此需求)是因为这个字符串是按照等级来排序的,也就是它们内部缩进的级别(源码在文件indent_sort/indent_sort.go里)。
注意 SortedIndentStrings()函数有一个很重要的前提就是,字符串的缩进是通过读到的空格和缩进的个数来决定的,所以我们只需处理单字节的空白,而不必考虑怎么处理多字节的空白(如果我们真的想要处理多字节的空白字符,一种比较容易的方法就是,在将它们传入SortedIndentedStrings()函数前将字符串里的空白串替换成一个简单的空格或者缩进符,例如,使用strings.Map()函数)。
我们来看一下main函数和输出结果。为了方便对比,我们将排序前的结果放在左边,排序后的结果放在右边。
func main() {
fmt.Println("| Original | Sorted |")
fmt.Println("|-----------------|-----------------|")
sorted := SortedIndentedStrings(original) // 最初是[]string
for i := range original { // 在全局变量中设置
fmt.Printf("|%-19s|%-19s|\n", original[i], sorted[i])
}
}
| Original | Sorted |
|------------------|------------------|
|Nonmetals |Alkali Metals |
| Hydrogen | Lithium |
| Carbon | Potassium |
| Nitrogen | Sodium |
| Oxygen |Inner Transitionals|
|Inner Transitionals| Actinides |
| Lanthanides | Curium |
| Europium | Plutonium |
| Cerium | Uranium |
| Actinides | Lanthanides |
| Uranium | Cerium |
| Plutonium | Europium |
| Curium |Nonmetals |
|Alkali Metals | Carbon |
| Lithium | Hydrogen |
| Sodium | Nitrogen |
| Potassium | Oxygen |
其中,函数SortedIndentedStrings()和它的辅助函数与类型使用到了递归函数、函数引用以及指向切片的指针等。尽管我们很容易看出程序做了哪些事情,但是要真正实现这个需求还是要有一些思考的。我们使用了本章介绍过的一些 Go语言的函数特性,还用到了第 4章介绍过的一些技巧,这些技巧在第6章将会更全面地介绍。
在我们给出的参考答案里,最关键的地方就是自定义的Entry和Entries类型。对于在原切片里的每一个字符串,我们为它创建一个Entry的“键/值”结构,键字段是用来排序的,值字段保存原字符串,而children字段则是该字符串的孩子Entry切片(children可能为空,如果不为空,它包含的Entry自身也还可能包含子Entry,以此类推)。
type Entry struct {
key string
value string
children Entries
}
type Entries []Entry
func (entries Entries) Len() int { return len(entries) }
func (entries Entries) Less(i, j int) bool {
return entries[i].key < entries[j].key
}
func (entries Entries) Swap(i, j int) {
entries[i], entries[j] = entries[j], entries[i]
}
sort.Interface接口定义了3个方法Len()、Less()和Swap()。它们的函数签名和Entries中的同名方法是一样的。这就意味着我们可以使用标准库里的sort.Sort()函数来对一个Entries进行排序。
func SortedIndentedStrings(slice []string) []string {
entries := populateEntries(slice)
return sortedEntries(entries)
}
导出(公有)的SortIndentedStrings()函数就做了这个工作,虽然我们已经对它进行了重构,让它把所有东西都传递给辅助函数。函数populateEntries()传入一个[]string并返回一个对应的Entries([]Entry 类型)。而函数 sortedEntries()需要传入一个Entries,然后返回一个排过序的[]string(根据缩进的级别进行排序)。
func populateEntries(slice []string) Entries {
indent, indentSize := computeIndent(slice)
entries := make(Entries, 0)
for _, item := range slice {
i, level := 0, 0
for strings.HasPrefix(item[i:], indent) {
i += indentSize
level++
}
key := strings.ToLower(strings.TrimSpace(item))
addEntry(level, key, item, &entries)
}
return entries
}
populateEntries()函数首先以字符串的形式得到给定切片里的一级缩进(如4个空格的字符串)和它占用的字节数,然后创建一个空的Entries,并遍历切片里的每一个字符串,判断该字符串的缩进级别,再创建一个用于排序的键。下一步,函数调用自定义函数addEntry(),将当前字符串的级别、键、字符串本身,以及指向 entries的地址作为参数参数,这样addEntry()就能创建一个新的Entry并能够正确地将它追加到entries里去。最后返回entries。
func computeIndent(slice []string) (string, int) {
for _, item := range slice {
if len(item) > 0 && (item[0] == ' ' || item[0] == '\t') {
whitespace := rune(item[0])
for i, char := range item[1:] {
if char != whitespace {
return strings.Repeat(string(whitespace), i), i
}
}
}
}
return "", 0
}
computeIndent()主要是用来判断缩进使用的是什么字符,例如空格或者缩进符等,以及一个缩进级别占用多少个这样的字符。
因为第一级的字符串可能没有缩进,所以函数必须迭代所有的字符串。一旦它发现某个字符串的行首是空格或者缩进,函数马上返回表示缩进的字符以及一个缩进所占用的字符数。
func addEntry(level int, key, value string, entries *Entries) {
if level == 0 {
*entries = append(*entries, Entry{key, value, make(Entries, 0)})
} else {
addEntry(level-1, key, value,
&((*entries)[entries.Len()-1].children))
}
}
addEntry()是一个递归函数,它创建一个新的Entry,如果这个Entry的level是0,那就直接增加到entries里去,否则,就将它作为另一个Entry的孩子。
我们必须确定这个函数传入的是一个*Entries而不是传递一个entries引用(切片的默认行为),因为我们是要将数据追加到entries里。追加到一个引用会导致无用的本地副本且原来的数据实际上并没有被修改。
如果level是0,表明这个字符串是顶级项,因此必须将它直接追加到*entries。实际上情况要更复杂一些,因为level是相对传入的*entries而言的,第一次调用addEntry()时,*entries是一个第一级的Entries,但函数进入递归后,*entries就可能是某个Entry的孩子。我们使用内置的append()函数来追加新的Entry,并使用*操作符获得 entries指针指向的值,这就保证了任何改变对调用者来说都是可见的。新增的Entry包含给定的key和value,以及一个空的子Entries。这是递归的结束条件。
如果level大于0,则我们必须将它追加到上一级Entry的children字段里去,这里我们只是简单地递归调用addEntry()函数。最后一个参数可能是我们目前为止见到的最复杂的表达式了。
子表达式entries.Len() - 1产生一个int型整数,表示*entries指向的Entries值的最后一个条目的索引位置(注意 Entries.Len()传入的是一个 Entries 值而不是*Entries指针,不过Go语言也可以自动对entries指针进行解引用并调用相应的方法,这一点是很优雅的)。完整的表达式(&(...)除外)访问了 Entries 最后一个 Entry的children字段(这也是一个Entries类型)。所以如果把这个表达式作为一个整体,实际上我们是将Entries里最后一个Entry的children字段的内存地址作为递归调用的参数,因为addEntry()最后一个参数是 *Entries类型的。
为了帮助大家弄清楚到底发生了什么,下面的代码和上述代码中else代码块中的那个调用是一样的。
theEntries := *entries
lastEntry := &theEntries[theEntries.Len()-1]
addEntry(level-1, key, value, &lastEntry.children)
首先,我们创建theEntries变量用来保存*entries指针指向的值,这里没有什么开销因为不会产生复制,实际上theEntries相当于一个指向Entries值的别名。然后我们取得最后一项的内存地址(即一个指针)。如果不取地址的话就会取到最后一项的副本,这不是我们期望的。最后递归调用addEntry()函数,并将最后一项的children字段的地址作为参数传递给它。
func sortedEntries(entries Entries) []string {
var indentedSlice []string
sort.Sort(entries)
for _, entry := range entries {
populateIndentedStrings(entry, &indentedSlice)
}
return indentedSlice
}
当调用sortedEntries()函数的时候,Entries显示的结构和原先程序输出的字符串是一样的,每一个缩进的字符串都是上一级缩进的子级,而且还可能有下一级的缩进,依次类推。
创建了Entries之后,SortedIndentStrings()函数调用上面这个函数去生成一个排好序的字符串切片[]string。这个函数首先创建一个空的[]string 用来保存最后的结果,然后对entries进行排序。Entries实现了sort.Interface接口,因此我们可以直接使用sort.Sort()函数根据Entry的key字段来对Entries进行排序(这是Entries.Less()的实现方式)。这个排序只是作用于第一级的Entry,对其他未排序的孩子Entry是没有任何影响的。
为了能够对children字段以及children的children等进行递归排序,函数遍历第一级的每一个项并调用populateIndentedStrings()函数,传入这个Entry类型的项和一个指向[]string切片的指针。
切片可以传递给函数并由函数更新内容(如替换切片里的某些项),但是我们这里需要往切片里新增一些数据。Go语言内置的append()函数有时候返回一个新的切片的引用(比如当原先的切片的容量不足时)。所以这里我们用了另一种处理方式,将一个指向切片的指针(也就是指针的指针)作为参数传进去,并将指针指向的内容设置为append()函数的返回结果,这里可能是一个新的切片,也可能是原先的切片(如果我们不使用指针的话,我们只能得到一个对于调用方不可见的本地切片)。另一种办法就是传入切片的值,然后返回append()之后的切片,但是必须将返回的结果赋值给原来的切片变量(例如slice = function(slice))。不过这么做的话,很难正确地使用递归函数。
func populateIndentedStrings(entry Entry, indentedSlice *[]string) {
*indentedSlice = append(*indentedSlice, entry.value)
sort.Sort(entry.children)
for _, child := range entry.children {
populateIndentedStrings(child, indentedSlice)
}
}
这个函数将项追加到创建的切片,然后对项的孩子进行排序,并递归调用自身对每一个孩子做同样的处理。这就相当于对每一项的孩子以及孩子的孩子等都做了排序,所以整个字符串切片就是已经排好序的了。
至此我们已经讲完了所有 Go语言的内置数据类型和过程式编程,下一章我们在这基础上对Go语言面向对象编程的特色进行讲解,之后章节还会学习Go语言对并发编程的支持。
第5章有4个练习。第一个需要修改我们上面的其中一个例子,部分代码在本章中已经呈现过,另外还需要创建一些新的函数。所有的练习都很短,第一个还非常简单,第二个比较直接明了,但第3个和第4个则非常具有挑战性。
(1)复制 archive_file_list 目录到例如 my_archive_file_list,然后修改archive_file_list/archive_file_list.go 文件:因为我们要实现一个不同的ArchiveFileList()函数,所以除了ArchiveFileListMap()将被改名为ArchiveFileList()这个函数外,其他的代码都要删除掉。然后增加处理.tar.bz2文件的功能(使用bzip2压缩的tar 包)。总共需要删除main()函数的11行代码,删除4个函数,导入一个额外的包,为 FunctionForSuffix 映射增加一项,并在 TarFileList()函数里增加少量的代码。参考答案在archive_file_list_ans/archive_file_list.go文件里。
(2)创建一个非递归版本的IsPalindrome()函数,这个函数在之前的章节里讲过。palindrome_ans/palindrome.go文件里的参考答案只有10行代码长,和递归版本在结构上是完全不一样的,不过它只处理ASCII编码的字符。另外,非递归的UTF-8版本有14行代码左右,和递归的很相似,不过要有点耐心。
(3)创建一个CommonPrefix()函数,接受一个[]string字符串切片并返回切片里所有字符串的共同前缀(如果不存在,就返回一个空的字符串)。参考答案在common_prefix/common_prefix.go文件里,大概22行代码,使用[][]rune来保存字符串,确保当我们遍历时即使字符串里包含非ASCII编码的字符我们也可以正确地得到一个完整的字符。参考答案使用一个 bytes.Buffer 来构建结果。尽管程序虽然简短,这并不意味着很容易(下一个练习还有其他的例子)。
(4)创建一个CommonPathPrefix()函数,传入一个保存了路径的字符串切片[]string,并返回一个所有传入路径字符串的公共前缀(同样可能为空),这个前缀由零到多个完整的路径组件组成。参考答案在common_prefix/common_prefix.go文件里,包含27行代码,用了一个[][]string 来保存所有的路径字符串并使用 filepath.Separator 来辨别平台特定的路径分隔符,并返回一个[]string类型的结果,可以使用filepath.Join()函数将它们组合成一个完整的路径。虽然程序真的很短,但还是很有挑战性的(下面有一些示例)。
这是上面common_prefix练习3和练习4程序的输出结果。每两行的第一行是一个字符串切片,第二行则是由 CommonPrefix()函数和CommonPathPrefix()函数产生的公共前缀,以及这两个公共前缀是否相等的标识。
$./common_prefix
["/home/user/goeg" "/home/user/goeg/prefix" "/home/user/goeg/prefix/extra"]
char×path prefix: "/home/user/goeg" == "/home/user/goeg"
["/home/user/goeg" "/home/user/goeg/prefix" "/home/user/prefix/extra"]
char×path prefix: "/home/user/" != "/home/user"
["/pecan/π/goeg" "/pecan/π/goeg/prefix" "/pecan/π/prefix/extra"]
char×path prefix: "/pecan/π/" != "/pecan/π"
["/pecan/π/circle" "/pecan/π/circle/prefix" "/pecan/π/circle/prefix/extra"]
char×path prefix: "/pecan/π/circle" == "/pecan/π/circle"
["/home/user/goeg" "/home/users/goeg" "/home/userspace/goeg"]
char×path prefix: "/home/user" != "/home"
["/home/user/goeg" "/tmp/user" "/var/log"]
char×path prefix: "/" == "/"
["/home/mark/goeg" "/home/user/goeg"]
char×path prefix: "/home/" != "/home"
["home/user/goeg" "/tmp/user" "/var/log"]
char×path prefix: "" == ""
[3].也可能有别的更为模糊的转换,这些都在Go语言规范文档中有描述(golang org/doc/go-spec.html)。
[7].Go语言中的select语句与POSI中的select()函数无关,后者是用于监控文件描述符的——这跟syscall包中的Select()函数的功能是一样的。
[8].在C++中,析构函数用于回收资源。在Java和Python中,资源的回收是不确定的,因为它们并不能保证何时甚至是否finalizer()或者_del_()方法会被调用。
[9].在一款轻载的AMD-64四核3GHz机器上,我们发现在同样需要处理50个以上分支的情况下,使用映射的速度会稳定的超过switch语句。