本章主要内容
Go语言一个广为人知的特点就是,可以更容易地写出错误更少的并发程序。本章将介绍并发这一技术,并讨论Go语言的并发模型以及设计。除此之外,我们还会深入地了解Go语言为实现并发而提供的两个特性,它们分别是goroutine以及通道。在本章的最后,我们还会看到一个使用Go并发提高Web应用性能的例子。
并发 (concurrency)指的是两个或多个任务在同一时间段内启动、运行并结束,并且这些任务可能会互动。以并发形式执行的多个任务会同时存在,这跟顺序执行每次只会存在一个任务的情况正好相反。并发是一个非常庞大且复杂的主题,本章将会简单介绍这一主题。
并行与并发是两个看上去相似但实际上却截然不同的概念,因为并发和并行都可以同时运行多个任务,所以很多人都把这两个概念混淆了。对于并发来说,多个任务并不需要同时开始或者同时结束——这些任务的执行过程在时间上是相互重叠的。并发执行的多个任务会被调度,并且它们会通过通信分享数据并协调执行时间(不过这种通信并不是必须的)。
在并行 (parallelism)中,多个任务将同时启动并执行。并行通常会把一个大任务分割成多个更小的任务,然后通过同时执行这些小任务来提高性能。并行通常需要独立的资源(如CPU),而并发则会使用和分享相同的资源。因为并行考虑的是同时启动和执行多个任务,所以它在直觉上会更易懂一些。并行,正如它的名字所昭示的那样,是一系列相互平行、不会重叠的处理过程。
并发指的是同时处理多项任务,而并行指的是同时执行多项任务。
——Rob Pike,Go语言的作者之一
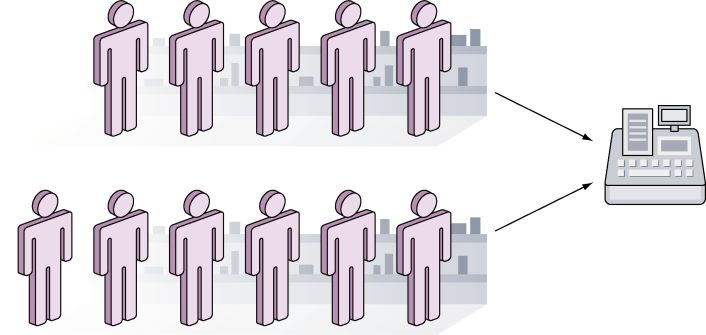
理解并发的另一种方法是把它看作超市里的两条结账通道,但这两条通道上的顾客需要在一个收银台排队等候,并轮流使用这个收银台结账,如图9-1所示。
图9-1 并发——两条结账通道,但是只有一个收银台
另一方面,并行同样拥有两条结账通道,只是每条通道都有一个对应的收银台为顾客服务,如图9-2所示。
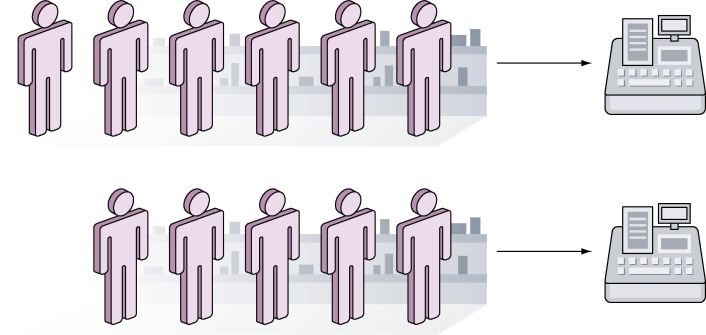
图9-2 并行——两条结账通道,每条都对应一个收银台
尽管并发和并行在概念上并不相同,但它们并不相互排斥,比如Go语言就可以创建出同时具有并发和并行这两种特征的程序。为了让并行程序可以同时运行多个任务,Go语言的用户需要将环境变量GOMAXPROCS
的值设置成大于1
。在Go 1.5版本之前,GOMAXPROCS
默认会被设置为1
,但是从Go 1.5版本开始,GOMAXPROCS
默认将被设置为系统可用的CPU数量。但是,并发程序可以在单个CPU上运行,至于程序包含的多个任务则会通过调度独立地运行,本章稍后就会出现一个这样的例子。需要注意的是,尽管Go语言可以用于创建并行程序,但这门语言在设计时考虑的更多是并发而不是并行。
Go语言通过goroutine和通道这两个主要组件来为并发提供支持,在接下来几节中,我们将会看到使用goroutine、通道以及一些标准库来构建并发程序的具体方法。
goroutine指的是那些独立于其他goroutine运行的函数。这一概念初看上去和线程有些相似,但实际上goroutine并不是线程,它只是对线程的多路复用。因为goroutine都是轻量级的,所以goroutine的数量可以比线程的数量多很多。一个goroutine在启动时只需要一个非常小的栈,并且这个栈可以按需扩展和缩小(在Go 1.4中,goroutine启动时的栈大小仅为2 KB [1] )。当一个goroutine被阻塞时,它也会阻塞所复用的操作系统线程,而运行时环境(runtime)则会把位于被阻塞线程上的其他goroutine移动到其他未阻塞的线程上继续运行。
goroutine的用法非常简单:只要把go
关键字添加到任意一个具名函数或者匿名函数的前面,该函数就会成为一个goroutine。作为例子,代码清单9-1展示了如何在名为goroutine.go
的文件中创建goroutine。
代码清单9-1 goroutine使用示例
package main
func printNumbers1() {
for i := 0; i < 10; i++ {
fmt.Printf("%d ", i)
}
}
func printLetters1() {
for i := 'A'; i < 'A'+10; i++ {
fmt.Printf("%c ", i)
}
}
func print1() {
printNumbers1()
printLetters1()
}
func goPrint1() {
go printNumbers1()
go printLetters1()
}
func main() {
}
goroutine.go文件
中定义了printNumbers1
和printLetters1
两个函数,分别用于循环并打印数字和英文字母,其中printNumbers1
会打印从0
到9
的所有数字,而printLetters1
则会打印从A
到J
的所有英文字母。除此之外,goroutine.go文件
中还定义了print1
和goPrint1
两个函数,前者会依次调用printNumbers1
和printLetters1
,而后者则会以goroutine的形式调用printNumbers1
和printLetters1
。
为了检测这个程序的运行时间,我们将通过测试而不是main
函数来运行程序中的print1
函数和goPrint1
函数。这样一来,我们就不必为了测量这两个函数的运行时间而编写测量代码,这也避免了因为编写计时代码而导致测量不准确的问题。
代码清单9-2展示了测试用例的具体代码,这些代码单独记录在了goroutine_test.go文件
当中。
代码清单9-2 运行goroutine示例的测试文件
package main
import "testing"
func TestPrint1(t *testing.T) { ❶
print1()
}
func TestGoPrint1(t *testing.T) { ❷
goPrint1()
}
❶ 测试顺序执行的函数
❷ 测试对以goroutine 形式执行的函数
通过使用以下命令执行这一测试:
go test –v
我们将得到以下结果:
=== RUN TestPrint1
0 1 2 3 4 5 6 7 8 9 A B C D E F G H I J --- PASS: TestPrint1 (0.00s)
=== RUN TestGoPrint1
--- PASS: TestGoPrint1 (0.00s)
PASS
注意,第二个测试用例并没有产生任何输出,这是因为该用例在它的两个goroutine能够产生输出之前就已经结束了。为了让第二个测试用例能够正常地产生输出,我们需要使用time
包中的Sleep
函数,在第二个测试用例的末尾加上一些延迟:
func TestGoPrint1(t *testing.T) {
goPrint1()
time.Sleep(1 * time.Millisecond)
}
这样一来,第二个测试用例就会在该测试用例结束之前正常地产生输出了:
=== RUN TestPrint1
0 1 2 3 4 5 6 7 8 9 A B C D E F G H I J --- PASS: TestPrint1 (0.00s)
=== RUN TestGoPrint1
0 1 2 3 4 5 6 7 8 9 A B C D E F G H I J --- PASS: TestGoPrint1 (0.00s)
PASS
这两个测试用例都产生了相同的结果。初看上去,是否使用goroutine似乎并没有什么不同,但事实上,这两个测试用例之所以会产生相同的结果,是因为printNumbers1
函数和printLetters1
函数都运行得如此之快,所以是否以goroutine形式运行它们并不会产生任何区别。为了更准确地模拟正常的计算任务,我们将通过time
包中的Sleep
函数人为地给这两个函数加上一点延迟,并把带有延迟的函数重新命名为printNumbers2
和printLetters2
。代码清单9-3展示了这两个新函数,跟原来的函数一样,它们也会被放在goroutine.go文件
中。
代码清单9-3 模拟执行计算任务的goroutine
func printNumbers2() {
for i := 0; i < 10; i++ {
time.Sleep(1 * time.Microsecond ❶
fmt.Printf("%d ", i) ❶
} ❶
} ❶
func printLetters2() { ❶
for i := 'A'; i < 'A'+10; i++ { ❶
time.Sleep(1 * time.Microsecond) ❶
fmt.Printf("%c ", i)❶
}
}
func goPrint2() {
go printNumbers2()
go printLetters2()
}
❶ 添加1 μs 的延迟,用于模拟计算任务
新定义的两个函数通过在每次迭代中添加1s的延迟来模拟计算任务。为了测试新添加的goPrint2
函数,我们将在goroutine_test.go文件
中添加相应的测试用例,并且和之前一样,为了让被测试的函数能够正常地产生输出,测试用例将在调用goPrint2
函数之后等待1μs:
func TestGoPrint2(t *testing.T) {
goPrint2()
time.Sleep(1 * time.Millisecond)
}
现在,运行测试用例将得到以下输出:
=== RUN TestPrint1
0 1 2 3 4 5 6 7 8 9 A B C D E F G H I J --- PASS: TestPrint1 (0.00s)
=== RUN TestGoPrint1
0 1 2 3 4 5 6 7 8 9 A B C D E F G H I J --- PASS: TestGoPrint1 (0.00s)
=== RUN TestGoPrint2
A 0 B 1 C D 2 E 3 F 4 G H 5 I 6 J 7 8 9 --- PASS: TestGoPrint2 (0.00s)
PASS
注意看TestGoPrint2
函数的输出结果,从结果可以看出,程序这次并不是先执行printNumbers2
函数,然后再执行printLetters2
函数,而是交替地执行它们!
如果我们再执行一次这个测试,那么TestGoPrint2
函数的输出结果的最后一行可能会有所不同:这是因为printNumbers2
和printLetters2
都是独立运行的,并且它们都在争先恐后地想要将自己的结果输出到屏幕上,所以随着这两个函数的执行顺序不同,测试产生的结果也会有所不同。唯一的例外是,如果你使用的是Go 1.5之前的版本,那么你每次执行这个测试都会得到相同的结果。
之所以会出现这种情况,是因为Go 1.5之前的版本在用户没有另行设置的情况下,即使计算机拥有多于一个CPU,它默认也只会使用一个CPU。但是从Go 1.5开始,这一情况发生了改变——Go运行时环境会使用计算机拥有的全部CPU。在Go 1.5或以后的版本中,用户如果想要让Go运行时环境只使用一个CPU,就需要执行以下命令:
go test -run x -bench . –cpu 1
在执行了这个命令之后,每次执行TestGoPrint2
都将得到完全相同的结果。
在了解了goroutine的运作方式之后,接下来我们要考虑的就是如何通过goroutine来提高性能。本节在进行性能测试时将沿用上一节定义的print1
、goPrint1
等函数,但为了避免这些函数在并发执行时输出一些乱糟糟的结果,这次我们将把代码中的fmt.Println
语句注释掉。代码清单9-4展示了为print1
函数和goPrint1
函数设置的基准测试用例,这些用例定义在goroutine_test.go文件
中。
代码清单9-4 为无goroutine和有goroutine的函数分别创建基准测试用例
func BenchmarkPrint1(b *testing.B) { ❶
for i := 0; i < b.N; i++ {
print1()
}
}
func BenchmarkGoPrint1(b *testing.B) { ❷
for i := 0; i < b.N; i++ {
goPrint1()
}
}
❶ 对顺序执行的函数进行基准测试
❷ 对以goroutine 形式执行的函数进行基准测试
在使用以下命令进行性能基准测试并跳过功能测试之后:
go test -run x -bench . –cpu 1
我们将看到以下结果:
BenchmarkPrint1 100000000 13.9 ns/op
BenchmarkGoPrint1 1000000 1090 ns/op
(运行这个测试只使用了单个CPU,具体原因本章稍后将会说到。)正如结果所示,函数print1
运行得非常快,只使用了 13.9 ns。令人感到惊讶的是,在使用goroutine运行相同函数时,程序的速度居然慢了如此之多,足足耗费了1090 ns!出现这种情况的原因在于“天下没有免费的午餐”
:无论goroutine有多么的轻量级,启动goroutine还是有一定的代价的。因为printNumbers1
函数和printLetters1
函数是如此简单,它们执行的速度是如此快,所以以goroutine方式执行它们反而会比顺序执行的代价更大。
如果我们对每次迭代都带有一定延迟的printNumbers2
函数和printLetters2
函数执行类似的测试,结果又会如何呢?代码清单9-5展示了goroutine_test.go文件中
为以上两个函数设置的基准测试用例。
代码清单9-5 为无goroutine和有goroutine的带延迟函数分别创建基准测试用例
func BenchmarkPrint2(b *testing.B) { ❶
for i := 0; i < b.N; i++ {
print2()
}
}
func BenchmarkGoPrint2(b *testing.B) { ❷
for i := 0; i < b.N; i++ {
goPrint2()
}
}
❶ 对顺序执行的函数进行基准测试
❷ 对以goroutine 形式执行的函数进行基准测试
在运行这一基准测试之后,我们将得到以下结果:
BenchmarkPrint2 10000 121384 ns/op
BenchmarkGoPrint2 1000000 17206 ns/op
这次的测试结果跟上一次的测试结果有些不同。可以看到,以goroutine方式执行print
Numbers2和printLetters2
的速度是以顺序方式执行这两个函数的速度的差不多7倍。现在,让我们把函数的迭代次数从10次改为100次,然后再运行相同的基准测试:
func printNumbers2() {
for i := 0; i < 100; i++ { ❶
time.Sleep(1 * time.Microsecond)
// fmt.Printf("%d ", i)
}
}
func printLetters2() {
for i := 'A'; i < 'A'+100; i++ { ❷
time.Sleep(1 * time.Microsecond)
// fmt.Printf("%c ", i)
}
}
❶ 迭代100 次而不是10 次
❷ 迭代100 次而不是10 次
下面是这次基准测试的结果:
BenchmarkPrint1 20000000 86.7 ns/op
BenchmarkGoPrint1 1000000 1177 ns/op
BenchmarkPrint2 2000 1184572 ns/op
BenchmarkGoPrint2 1000000 17564 ns/op
在这次基准测试中,print1
函数的基准测试时间是之前的13倍,而goPrint1
函数的速度跟上一次相比没有出现太大变化。另一方面,通过延迟模拟负载的函数的测试结果变化非常之大——以顺序方式执行的函数和以goroutine方式执行的函数之间,两者的执行时间相差了67倍之多。因为这次基准测试的迭代次数比之前增加了10倍,所以print2
函数在进行基准测试时的速度差不多是上次的1/10,但对于goPrint2
来说,迭代10次所需的时间跟迭代100次所需的时间却几乎是相同的。
注意,到目前为止,我们都是在用一个CPU执行测试,但如果我们执行以下命令,改用两个CPU执行带有100次迭代的基准测试:
go test -run x -bench . -cpu 2
那么我们将得到以下结果:
BenchmarkPrint1-2 20000000 87.3 ns/op
BenchmarkGoPrint2-2 5000000 391 ns/op
BenchmarkPrint2-2 1000 1217151 ns/op
BenchmarkGoPrint2-2 200000 8607 ns/op
因为print1
函数以顺序方式执行,无论运行时环境提供多少个CPU,它都只能使用一个CPU,所以它这次的测试结果跟上一次的测试结果基本相同。与此相反,goPrint1
函数这次因为使用了两个CPU来分担计算负载,所以它的性能提高了将近3倍。此外,因为print2
也只能使用一个CPU,所以它这次的测试结果也跟预料中的一样,并没有发生什么变化。最后,因为goPrint2
使用了两个CPU来分担计算负载,所以它这次的测试比之前快了两倍。
现在,如果我们更进一步,使用4个CPU来运行相同的基准测试,结果将会如何?
BenchmarkPrint1-4 20000000 90.6 ns/op
BenchmarkGoPrint1-4 3000000 479 ns/op
BenchmarkPrint2-4 1000 1272672 ns/op
BenchmarkGoPrint2-4 300000 6193 ns/op
正如我们预期的那样,print1
函数和print2
函数的测试结果还是一如既往地没有发生什么变化。但令人惊奇的是,尽管goPrint1
在使用4个CPU时的测试结果还是比只使用一个CPU时的测试结果要好,但使用4个CPU的执行速度居然比使用两个CPU的执行速度要慢。与此同时,虽然只有40%的提升,但goPrint2
在使用4个CPU时的成绩还是比使用2个CPU时的成绩要好。使用更多CPU并没有带来性能提升反而导致性能下降的原因跟之前提到的一样:在多个CPU上调度和运行任务需要耗费一定的资源,如果使用多个CPU带来的性能优势不足以抵消随之而来的额外消耗,那么程序的性能就会不升反降。
从上述测试我们可以看出,增加CPU的数量并不一定会带来性能提升,更重要的是要理解代码,并对其进行基准测试,以了解它的性能特质。
在上一节中,我们了解到程序启动的goroutine在程序结束时将会被粗暴地结束,虽然通过Sleep
函数来增加时间延迟可以避免这一问题,但这说到底只是一种权宜之计,并没有真正地解决问题。虽然在实际的代码中,程序本身比goroutine更早结束的情况并不多见,但为了避免意外,我们还是需要有一种机制,使程序可以在确保所有goroutine都已经执行完毕的情况下,再执行下一项工作。
为此,Go语言在sync
包中提供了一种名为等待组(WaitGroup
)的机制,它的运作方式非常简单直接:
Add
方法为等待组的计数器设置值;
Done
方法对等待组的计数器执行减一操作;
Wait
方法,该方法将一直阻塞,直到等待组计数器的值变为0。
代码清单9-6展示了一个使用等待组的例子,在这个例子中,我们复用了之前展示过的printNumbers2
函数以及printLetters2
函数,并为它们分别加上了1μs的延迟。
代码清单9-6 使用等待组
package main
import "fmt"
import "time"
import "sync"
func printNumbers2(wg *sync.WaitGroup) {
for i := 0; i < 10; i++ {
time.Sleep(1 * time.Microsecond)
fmt.Printf("%d ", i)
}
wg.Done() ❶
}
func printLetters2(wg *sync.WaitGroup) {
for i := 'A'; i < 'A'+10; i++ {
time.Sleep(1 * time.Microsecond)
fmt.Printf("%c ", i)
}
wg.Done() ❷
}
func main() {
var wg sync.WaitGroup ❸
wg.Add(2) ❹
go printNumbers2(&wg)
go printLetters2(&wg)
wg.Wait() ❺
}
❶ 对计数器执行减一操作
❷ 对计数器执行减一操作
❸ 声明一个等待组
❹ 为计数器设置值
❺ 阻塞到计数器的值为0
如果我们运行这个程序,那么它将巧妙地打印出0 A 1 B 2 C 3 D 4 E 5 F 6 G 7 H 8 I 9 J
。这个程序的运作原理是这样的:它首先定义一个名为wg
的WaitGroup
变量,然后通过调用wg
的Add
方法将计数器的值设置成2
;在此之后,程序会分别调用printNumbers2
和printLetters2
这两个goroutine,而这两个goroutine都会在末尾对计数器的值执行减一操作。之后程序会调用等待组的Wait
方法,并因此而被阻塞,这一状态将持续到两个goroutine都执行完毕并调用Done
方法为止。当程序解除阻塞状态之后,它就会跟平常一样,自然地结束。
如果我们在某个goroutine里面忘记了对计数器执行减一操作,那么等待组将一直阻塞,直到运行时环境发现所有goroutine都已经休眠为止,这时程序将引发一个panic:
0 A 1 B 2 C 3 D 4 E 5 F 6 G 7 H 8 I 9 J fatal error: all goroutines are asleep - deadlock!
等待组这一特性不仅简单,而且好用,它对并发编程来说是一种不可或缺的工具。
在前一节,我们学习了如何通过go
关键字,把普通函数转换为goroutine以便让其独立运行,并在9.2.2节学习了如何通过等待组来同步独立运行的多个goroutine。在这一节,我们将要学习的是,如何使用通道在多个不同的goroutine之间通信。
通道就像是一个箱子,不同的goroutine可以通过这个箱子与其他goroutine通信:如果一个goroutine想要把一项信息传递给另一个goroutine,那么它就必须把该信息放置到箱子里,然后另一个goroutine则负责从箱子里取出被放置的信息,就像图9-3所示的那样。
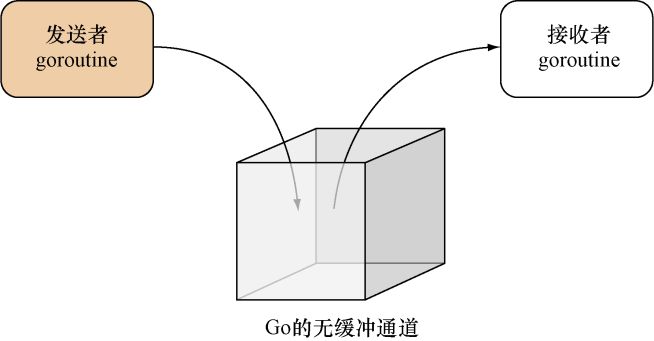
图9-3 把Go的无缓冲通道看作是一个箱子
通道
(channel)是一种带有类型的值(typed value),它可以让不同的goroutine互相通信。通道用make
函数创建,该函数在被调用之后将返回一个指向底层数据结构的引用作为结果值。比如,以下代码就展示了如何创建一个由整数组成的通道:
ch := make(chan int)
make
函数默认创建的都是无缓冲通道(unbuffered channel),如果用户在创建通道时,向make
函数提供了可选的第三个整数参数,那么make
函数将创建出一个带有给定大小的有缓冲通道
(buffered channel)。比如说,以下代码就会创建出一个大小为10的整数有缓冲通道:
ch := make(chan int, 10)
无缓冲通道是同步的,它就像是一个每次只能容纳一件物体的箱子:当一个goroutine把一项信息放入无缓冲通道之后,除非有某个goroutine把这项信息取走,否则其他goroutine将无法再向这个通道放入任何信息。这也意味着,如果一个goroutine想要向一个已经包含了某项信息的无缓冲通道再放入一项信息,那么这个goroutine将被阻塞并进入休眠状态,直到该通道变空为止。
同样地,如果一个goroutine尝试从一个并没有包含任何信息的无缓冲通道中取出一项信息,那么这个goroutine将会被阻塞并进入休眠状态,直到通道不再为空为止。
将信息放入通道的语法是非常直观的,比如,通过执行以下语句,我们可以把数字1
放入通道ch
里面:
ch <- 1
从通道里面取出信息的语法同样非常直观,比如,通过执行以下语句,我们可以从通道ch
里面移除一个值,并将该值赋值给变量i
:
i := <- ch
通道可以是定向的(directional)。在默认情况下,通道将以双向的 (bidirectional)形式运作,用户既可以把值放入通道,也可以从通道取出值;但是,通道也可以被限制为只能执行发送操作 (send-only)或者只能执行接收操作 (receive-only)。比如,以下语句就展示了如何创建一个只能执行发送操作的字符串通道:
ch := make(chan <- string)
而以下语句则展示了如何创建一个只能执行接收操作的字符串通道:
ch := make(<-chan string)
用户除了可以直接创建定向的通道之外,还可以把一个双向通道转变为定向通道,我们将会在本章的末尾看到一个这样的例子。
也许你已经猜到了,通道非常适用于对两个goroutine进行同步,当一个goroutine需要依赖另一个goroutine时,更是如此。事不宜迟,让我们马上来看看代码清单9-7所示的程序:这个程序沿用了上一节展示过的例子,唯一的不同在于,这次的程序使用了通道而不是等待组来对goroutine进行同步。
代码清单9-7 使用通道同步goroutine
package main
import "fmt"
import "time"
func printNumbers2(w chan bool) {
for i := 0; i < 10; i++ {
time.Sleep(1 * time.Microsecond)
fmt.Printf("%d ", i)
}
w <- true ❶
} ❶
func printLetters2(w chan bool) { ❶
for i := 'A'; i < 'A'+10; i++ { ❶
time.Sleep(1 * time.Microsecond) ❶
fmt.Printf("%c ", i) ❶
} ❶
w <- true ❶
}
func main() {
w1, w2 := make(chan bool), make(chan bool)
go printNumbers2(w1)
go printLetters2(w2)
<-w1 ❷
<-w2 ❷
}
❶ 把一个布尔值放入通道,以便解除主程序的阻塞状态
❷ 主程序将一直阻塞,直到通道里面出现可弹出的值为止
先来看看这个程序中的main
函数。它首先创建了w1
和w2
这两个bool
类型的通道,接着以goroutine方式运行了printNumbers2
函数和printLetters2
函数,并将两个通道分别传给了这两个函数。在启动两个goroutine之后,main
函数将会尝试从通道w1
中移除一个值,但由于通道w1
当时并没有包含任何值,所以main
函数将会在此处阻塞。当printNumbers2
即将执行完毕,并将一个true
值放入通道w1
之后,main
函数的阻塞状态才会被解除,并继续尝试从第二个通道w2
中弹出一个值。跟之前一样,在printLetters2
执行完毕并将true
值放入通道w2
之前,main
函数将一直阻塞,直到它成功取得了w2
通道中的true
值之后,阻塞才会解除,然后main
函数才会顺利退出。
需要注意的是,因为我们只是想要在goroutine执行完毕之后解除对main
函数的阻塞,而不是真正地想要使用通道中存储的值,所以程序在从通道w1
和w2
里面取出值之后并没有使用这些值。
代码清单9-7展示的是一个非常简单的例子,这个例子中的程序使用通道只是为了对多个goroutine进行同步,但这些goroutine之间并没有通信。不过在接下来的一节,我们就会看到一个在多个goroutine之间传递消息的例子。
代码清单9-8展示了两个以goroutine形式独立运行的函数,其中一个函数是投掷器(thrower),它接受一个通道作为参数,然后一个接一个地把一组数字发送到通道里;而另一个函数则是捕捉器(catcher),它会从相同的通道里一个接一个地取出一组数字,并把这些数字打印出来。
代码清单9-8 使用通道实现消息传递
package main
import (
"fmt"
"time"
)
func thrower(c chan int) {
for i := 0; i < 5; i++ {
c <- i ❶
fmt.Println("Threw >>", i)
}
}
func catcher(c chan int) {
for i := 0; i < 5; i++ {
num := <-c ❷
fmt.Println("Caught <<", num)
}
}
func main() {
c := make(chan int)
go thrower(c)
go catcher(c)
time.Sleep(100 * time.Millisecond)
}
❶ 把数字值推入通道中
❷ 从通道中取出数字值
运行这个程序将得到以下结果:
Caught << 0
Threw >> 0
Threw >> 1
Caught << 1
Caught << 2
Threw >> 2
Threw >> 3
Caught << 3
Caught << 4
Threw >> 4
在这段输出结果中,某些Caught
语句出现在了Threw
语句的前面,但这并不意味着程序的运行出现了错误——之所以会出现这样的乱象,仅仅是因为运行时环境在向通道推入值或者从通道中取出值之后,调度到了打印语句所致。最重要的是,打印语句中出现的数字都是有序的,这意味着投掷器在向通道“投掷”一个数字之后,捕捉器必须先“捕捉”这个数字,然后才能处理下一个数字。
无缓冲通道或者说同步通道(synchronous channel)使用起来非常简单,而与之相对的有缓冲通道则更复杂一些,后者是一种异步的、先进先出消息队列。如图9-4所示,有缓冲通道就像是一个能够容纳多个同类信息的大箱子:一个goroutine可以持续地向箱子里面推入信息,并且在箱子被填满之前,推入信息的goroutine都不会被阻塞;同样地,一个goroutine可以按照信息被推入的顺序,持续地从箱子里取出信息,并且在箱子被掏空之前,取出信息的goroutine都不会被阻塞。
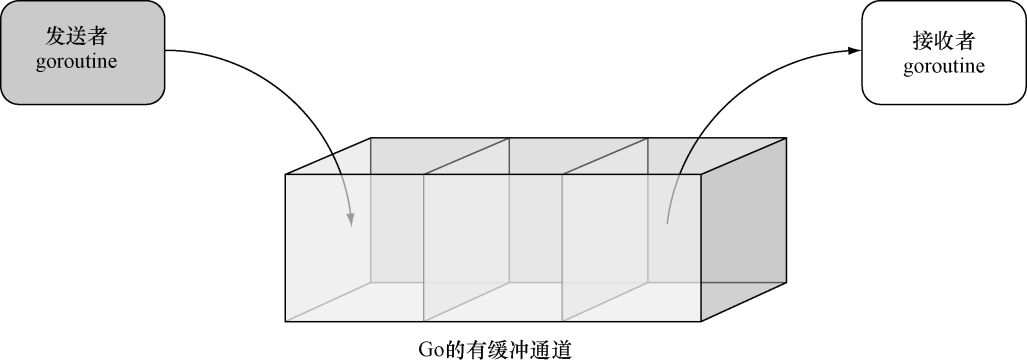
图9-4 将Go的有缓冲通道看作是一个箱子
接下来,就让我们看看有缓冲通道在投掷器和捕捉器的例子中是如何运作的。为此,我们需要对代码清单9-8中,以下这个创建无缓冲通道的语句进行修改:
c := make(chan int)
让它转而创建一个大小为3的有缓冲通道:
c := make(chan int, 3)
运行修改后的程序,我们将得到以下结果:
Threw >> 0
Threw >> 1
Threw >> 2
Caught << 0
Caught << 1
Caught << 2
Threw >> 3
Threw >> 4
Caught << 3
Caught << 4
从输出结果可以看到,投掷器将一直向通道推入数字,直到通道被填满并将其阻塞为止,而捕捉器则会按顺序从通道里取出被推入的数字。如果你在解决某个问题的时候,只有有限数量的工作进程可用,并且你打算限制传入请求的数量,那么有缓冲通道将是一种非常合适的工具。
Go拥有一个特殊的关键字select
,它允许用户从多个通道中选择一个通道来执行接收或者发送操作。select
关键字就像是专门为通道而设的switch
语句,代码清单9-9展示了一个使用select
关键字的例子。
代码清单9-9 从多个通道中选择
package main
import (
"fmt"
)
func callerA(c chan string) {
c <- "Hello World!"
}
func callerB(c chan string) {
c <- "Hola Mundo!"
}
func main() {
a, b := make(chan string), make(chan string)
go callerA(a)
go callerB(b)
for i := 0; i < 5; i++ {
select {
case msg := <-a:
fmt.Printf("%s from A\n", msg)
case msg := <-b:
fmt.Printf("%s from B\n", msg)
}
}
}
这个程序中的callerA
和callerB
两个函数都会接受一个字符串通道作为参数,并向该通道发送信息。在以goroutine方式调用callerA
和callerB
之后,程序会进行5次迭代(次数的多少无关紧要,5是一个随意选取的数字),并且在每次迭代中,Go的运行时环境都会根据通道a
或者通道b
是否有值来决定应该对哪个通道执行取值操作。如果两个通道都有值,那么Go运行环境将随机选择其中一个通道。
我们的计划听上去似乎完美无瑕,但是在实际运行程序的时候,Go 却向我们报告了一个死锁错误:
Hello World! from A
Hola Mundo! from B
fatal error: all goroutines are asleep - deadlock!
出现这个错误的原因我们前面已经提到过了,当一个goroutine取出无缓冲通道中唯一的值之后,无缓冲通道将变为空,之后任何尝试从空通道获取值的goroutine都会被阻塞并进入休眠状态。在这个例子中,main
函数首先在第一次迭代中从通道a
里取出了值,并导致通道a
为空;接着又在第二次迭代中从通道b
里取出了值,并导致通道b
为空;然后在进行第三次迭代时,main
函数发现通道a
和通道b
都为空,于是它就会被阻塞并进入休眠,但由于这时callerA
和callerB
这两个goroutine都已执行完毕,所以通道a
和通道b
将永远也不会再有值,而main
函数也只能永远等待下去——在检测到这一情况之后,Go运行时环境抛出了死锁错误。
解决这个问题并不困难,我们只需要为select
语句添加一个默认分支,让select
语句在所有可选通道都已被阻塞的情况下执行默认分支即可,以下代码中加粗的部分就是新添加的默认分支:
select {
case msg := < -a:
fmt.Printf("%s from A\n", msg)
case msg := < -b:
fmt.Printf("%s from B\n", msg)
default:
fmt.Println("Default")
}
当select
语句没有发现任何可用的通道时,它就会执行默认分支中的代码。对于上面的例子来说,当存储在通道a
和通道b
里面的值都被取出之后,程序就会在下一次迭代中执行默认分支中的代码。但是,如果现在就执行这段代码,就只会看到默认分支打印的输出:这是因为程序太早就调用select
语句了,以至于通道a
和通道b
还没来得及接受callerA
和callerB
发送给它们的值,select
语句就跳过两个还没有值的通道直接执行默认分支了。为了让这个程序能够正确工作,我们需要在每次迭代之前添加1s的延迟,从而使通道能够正常接收goroutine发送给它们的值,以下代码中加粗显示的就是新添加的语句:
for i := 0; i < 5; i++ {
time.Sleep(1 * time.Microsecond)
select {
case msg := < -a:
fmt.Printf("%s from A\n", msg)
case msg := < -b:
fmt.Printf("%s from B\n", msg)
default:
fmt.Println("Default")
}
}
运行这个修改后的程序,死锁将不会再出现:
Hello World! from A
Hola Mundo! from B
Default
Default
Default
从程序输出的结果可以看到,在通道a
和通道b
包含的值都被取出之后,select
语句的前两个分支就会被阻塞,而默认分支则会被执行。
在循环里添加延迟时间的做法初看上去会让人感觉有些奇怪,但这其实只是为了展示select
语句的用法而想出来的权宜之计。在实际中,大部分情况下用户使用的都是无限循环,而不是有限次数的迭代,这时程序的处理方式就会有所不同。比如,如果我们是在一个无限循环中使用select
语句,那么在所有通道都为空之后,程序将无限次执行默认分支,这时我们就可以对默认分支的执行次数进行计数,并在计数到达指定限制时退出循环。
其实在实际中,我们并不需要像上面所说的那样,通过计数器来退出带有select
语句的无限循环,这是因为使用内置的close
函数来关闭通道能够更好地达到这一目的:使用close
函数关闭通道,相当于向通道的接收者表明该通道将不会再收到任何值。只能执行接收操作的通道无法被关闭,尝试向一个已关闭的通道发送信息将会引发一个panic,尝试关闭一个已经被关闭的通道也是如此。尝试从一个已关闭的通道取值总是会得到一个与通道类型相对应的零值,因此从已关闭的通道取值并不会导致goroutine被阻塞。
代码清单9-10展示了一个例子,在这个例子中,我们将会看到关闭通道的方法以及被关闭通道是如何帮助程序跳出无限循环的。
代码清单9-10 关闭通道
package main
import (
"fmt"
)
func callerA(c chan string) {
c <- "Hello World!"
close(c) ❶
} ❶
func callerB(c chan string) { ❶
c <- "Hola Mundo!" ❶
close(c) ❶
}
func main() {
a, b := make(chan string), make(chan string)
go callerA(a)
go callerB(b)
var msg string
ok1, ok2 := true, true
for ok1 || ok2 {
select {
case msg, ok1 = <-a: ❷
if ok1 { ❷
fmt.Printf("%s from A\n", msg) ❷
} ❷
case msg, ok2 = <-b: ❷
if ok2 { ❷
fmt.Printf("%s from B\n", msg)
}
}
}
}
❶ 在函数被调用之后关闭通道
❷ 在通道被关闭之后,变量ok1 和ok2的值将被设置为false
这个新程序不再只迭代5次,并且它也不需要在迭代之前添加时间延迟。在将一个字符串发送至通道之后,程序调用内置的close
函数关闭了该通道。需要注意的是,跟关闭文件或者关闭套接字不一样,关闭通道并不会导致通道的机能完全停止——它的作用就是通知其他正在尝试从这个通道接收值的goroutine,这个通道已经不会再接收到任何值了。
另外需要注意的是,程序在从通道里面取值时,使用的是多值格式(multivalue form):
case value, ok1 = <-a
在执行这条语句时,从通道a
里面取出的值将被赋值给变量value
,而变量ok1
则会被设置为用于表示通道是否仍然处于打开状态的布尔值。如果通道已被关闭,那么 ok1
的值将被设置为false
。
对于关闭通道我们需要知道的最后一点就是,关闭通道并不是必需的。正如之前所说,关闭通道只不过是在告知接收者该通道不会再接收到任何值而已。在代码清单9-10剩余的代码中,程序将通过检测语句来判断通道是否已被关闭,并在通道已被关闭的情况下,跳出循环,不再打印任何信息。下面是执行该程序得出的结果:
Hello World! from A
Hola Mundo! from B
直到目前为止,本章都是在独立的程序中展示如何使用Go的并发特性,但是显然地,这些并发特性不仅可以在独立的程序中使用,还可以在Web应用中使用。在这一节中,我们将把注意力放到Go Web应用上,并学习如何使用并发特性去提高Go Web应用的性能。我们不仅会使用前面已经介绍过的一些基础技术,而且还会了解一些出现在实际Web应用中的并发模式。
在本节中,我们将要创建一个对图片进行马赛克处理,以此来生成马赛克图片的Web应用。对图片进行马赛克 (mosaic)处理,指的是将图片分割成多个(通常是大小相同的)矩形截面,然后使用一些被称为瓷砖图片 (tile picture)的新图片去代替截面原有的图片。马赛克图片的奇妙之处在于,如果人们从足够远的地方观察,或者以斜视的角度观察,就会看到图片在进行马赛克处理之前的样子;相反,如果人们凑近去观察马赛克图片,就会发现它们其实是由成百上千张尺寸更小的瓷砖图片组成。
这个生成马赛克图片的Web应用的基本想法非常简单:它接收用户上传的目标图片 (target picture),然后据此生成相应的马赛克图片。为了让事情保持简单,我们假设瓷砖图片已经事先准备好了,并且它们都已经被裁剪到了合适的大小。
创建马赛克图片的第一步是定义一个马赛克算法,下面是一个无需使用任何第三方库的算法步骤。
(1)通过扫描图片目录,并使用图片的文件名作为键、图片的平均颜色作为值,构建出一个由瓷砖图片组成的散列,也就是一个瓷砖图片数据库。通过计算图片中每个像素红、绿、蓝3种颜色的总和,并将它们除以像素的总数量,我们就得到了一个三元组,而这个三元组就是图片的平均颜色。
(2)根据瓷砖图片的大小,将目标图片切割成一系列尺寸更小的子图片。
(3)对于目标图片切割出的每张子图片,将它们位于左上方的第一个像素设定为该图片的平均颜色。
(4)根据子图片的平均颜色,在瓷砖图片数据库中找出一张平均颜色与之最为接近的瓷砖图片,然后在目标图片的相应位置上使用瓷砖图片去代替原有的子图片。为了找出最接近的平均颜色,程序需要将子图片的平均颜色以及瓷砖图片的平均颜色都转换成三维空间中的一个点,并计算这两点之间的欧几里得距离。
(5)当一张瓷砖图片被选中之后,程序就会把这张图片从瓷砖图片数据库中移除,以此来保证马赛克图片中的每张瓷砖图片都是独一无二、各不相同的。
文件mosaic.go
实现了上述的马赛克算法,我们接下来将逐一分析该文件包含的各个函数。首先,代码清单9-11展示了该文件中用于计算平均颜色的averageColor
函数。
代码清单9-11 averageColor
函数
func averageColor(img image.Image) [3]float64 {
bounds := img.Bounds()
r, g, b := 0.0, 0.0, 0.0
for y := bounds.Min.Y; y < bounds.Max.Y; y++ {
for x := bounds.Min.X; x < bounds.Max.X; x++ {
r1, g1, b1, _ := img.At(x, y).RGBA()
r, g, b = r+float64(r1), g+float64(g1), b+float64(b1) ❶
}
}
totalPixels := float64(bounds.Max.X * bounds.Max.Y)
return [3]float64{r / totalPixels, g / totalPixels, b / totalPixels}
}
❶ 计算出给定图片的平均颜色
averageColor
函数会把给定图片的每个像素中的红、绿、蓝3种颜色相加起来,并将这些颜色的总和除以图片的像素数量,最后把除法计算的结果记录在一个新创建的三元组里面(这个三元组使用包含3个元素的数组表示)。
之后,程序会使用代码清单9-12所示的resize
函数,把图片缩放至指定的宽度。
代码清单9-12 resize
函数
func resize(in image.Image, newWidth int) image.NRGBA { ❶
bounds := in.Bounds()
ratio := bounds.Dx()/ newWidth
out := image.NewNRGBA(image.Rect(bounds.Min.X/ratio, bounds.Min.X/ratio,
➥bounds.Max.X/ratio, bounds.Max.Y/ratio))
for y, j := bounds.Min.Y, bounds.Min.Y; y < bounds.Max.Y; y, j = y+ratio,
j+1 {
for x, i := bounds.Min.X, bounds.Min.X; x < bounds.Max.X; x, i =
➥x+ratio, i+1 {
r, g, b, a := in.At(x, y).RGBA()
out.SetNRGBA(i, j, color.NRGBA{uint8(r>>8), uint8(g>>8), uint8(b>>8),
➥uint8(a>>8)})
}
}
return *out
}
❶ 将给定图片缩放至指定宽度
代码清单9-13展示了tilesDB
函数,这个函数会通过扫描瓷砖图片所在的目录来创建一个瓷砖图片数据库。
代码清单9-13 tilesDB
函数
func tilesDB() map[string][3]float64 { ❶
fmt.Println("Start populating tiles db ...")
db := make(map[string][3]float64)
files, _ := ioutil.ReadDir("tiles")
for _, f := range files {
name := "tiles/" + f.Name()
file, err := os.Open(name)
if err == nil {
img, _, err := image.Decode(file)
if err == nil {
db[name] = averageColor(img)
} else {
fmt.Println("error in populating TILEDB:", err, name)
}
} else {
fmt.Println("cannot open file", name, err)
}
file.Close()
}
fmt.Println("Finished populating tiles db.")
return db
}
❶ 在内存中创建一个瓷砖图片数据库
瓷砖图片数据库是一个映射,这个映射的键为字符串,而值则为三元组(在程序中使用包含3个元素的数组来表示)。tilesDB
函数会打开目录中的每张图片,并根据这些图片的平均颜色在映射中创建相应的记录。为了寻找与目标图片相匹配的瓷砖图片,程序会将tilesDB
函数创建的瓷砖图片数据库以及目标图片的平均颜色传入nearest
函数。
func nearest(target [3]float64, db *map[string][3]float64) string { ❶
var filename string
smallest := 1000000.0
for k, v := range *db {
dist := distance(target, v)
if dist < smallest {
filename, smallest = k, dist
}
}
delete(*db, filename)
return filename
}
❶ 寻找与目标图片平均颜色最接近的瓷砖图片
nearest
函数会把瓷砖图片数据库中的所有记录与目标图片的平均颜色一一进行对比,而两者欧几里得距离最短的那一条记录,就是与目标图片平均颜色最为接近的瓷砖图片。函数会从数据库中移除被选中的瓷砖图片,并把该图片的名字返回给调用者。代码清单9-14展示了用于计算两个三元组之间的欧几里得距离的distance
函数。
代码清单9-14 distance
函数
func distance(p1 [3]float64, p2 [3]float64) float64 { ❶
return math.Sqrt(sq(p2[0]-p1[0]) + sq(p2[1]-p1[1]) + sq(p2[2]-p1[2]))
}
func sq(n float64) float64 { ❷
return n * n
}
❶ 计算两点之间的欧几里得距离
❷ 计算给定数值的平方
因为扫描和载入瓷砖图片数据库是一项非常花时间的操作,所以为了效率起见,比起每次生成马赛克图片的时候都重复一遍这个操作,更合理的做法是只执行一次这个操作,创建出一个瓷砖图片数据库的原本(source),然后在每次生成马赛克图片的时候都根据这个原本复制出一个独立的副本(clone)。代码清单9-15展示了作为瓷砖图片数据库的原本而存在的TILEDB
全局变量,Web应用在启动的时候就会创建并填充这个变量。
代码清单9-15 cloneTilesDB
函数
var TILESDB map[string][3]float64
func cloneTilesDB() map[string][3]float64 { ❶
db := make(map[string][3]float64)
for k, v := range TILESDB {
db[k] = v
}
return db
}
❶ 每次需要生成马赛克图片的时候,就复制出一个瓷砖图片数据库副本
在实现了马赛克生成函数之后,我们接下来就可以实现与之相对应的Web应用了。代码清单9-16展示了这个应用的具体代码,这些代码放在了main.go
文件中。
代码清单9-16 马赛克图片Web应用
package main
import (
"bytes"
"encoding/base64"
"fmt"
"html/template"
"image"
"image/draw"
"image/jpeg"
"net/http"
"os"
"strconv"
"sync"
"time"
)
func main() {
mux := http.NewServeMux()
files := http.FileServer(http.Dir("public"))
mux.Handle("/static/", http.StripPrefix("/static/", files))
mux.HandleFunc("/", upload)
mux.HandleFunc("/mosaic", mosaic)
server := &http.Server{
Addr: "127.0.0.1:8080",
Handler: mux,
}
TILESDB = tilesDB()
fmt.Println("Mosaic server started.")
server.ListenAndServe()
}
func upload(w http.ResponseWriter, r *http.Request) {
t, _ := template.ParseFiles("upload.html")
t.Execute(w, nil)
}
func mosaic(w http.ResponseWriter, r *http.Request) {
t0 := time.Now()
r.ParseMultipartForm(10485760)
file, _, _ := r.FormFile("image") ❶
defer file.Close()
tileSize, _ := strconv.Atoi(r.FormValue("tile_size"))
original, _, _ := image.Decode(file) ❷
bounds := original.Bounds()
newimage := image.NewNRGBA(image.Rect(bounds.Min.X, bounds.Min.X,
bounds.Max.X, bounds.Max.Y))
db := cloneTilesDB() ❸
sp := image.Point{0, 0} ❹
for y := bounds.Min.Y; y < bounds.Max.Y; y = y + tileSize { ❺
for x := bounds.Min.X; x < bounds.Max.X; x = x + tileSize {
r, g, b, _ := original.At(x, y).RGBA()
color := [3]float64{float64(r), float64(g), float64(b)}
nearest := nearest(color, &db)
file, err := os.Open(nearest)
if err == nil {
img, _, err := image.Decode(file)
if err == nil {
t := resize(img, tileSize)
tile := t.SubImage(t.Bounds())
tileBounds := image.Rect(x, y, x+tileSize, y+tileSize)
draw.Draw(newimage, tileBounds, tile, sp, draw.Src)
} else {
fmt.Println("error:", err, nearest)
}
} else {
fmt.Println("error:", nearest)
}
file.Close()
}
}
buf1 := new(bytes.Buffer)
jpeg.Encode(buf1, original, nil) ❻
originalStr := base64.StdEncoding.EncodeToString(buf1.Bytes())
buf2 := new(bytes.Buffer)
jpeg.Encode(buf2, newimage, nil)
mosaic := base64.StdEncoding.EncodeToString(buf2.Bytes())
t1 := time.Now()
images := map[string]string{
"original": originalStr,
"mosaic": mosaic,
"duration": fmt.Sprintf("%v ", t1.Sub(t0)),
}
t, _ := template.ParseFiles("results.html")
t.Execute(w, images)
}
❶ 获取用户上传的目标图片,以及瓷砖图片的尺寸
❷ 对用户上传的目标图片进行解码
❸ 复制瓷砖图数据库
❹ 为每张瓷砖图片设置起始点
❺ 对目标图片分割出的每张子图进行迭代
❻ 将图片编码为JPEG 格式,然后通过base64字符串将其传输至浏览器
mosaic
函数是一个处理器函数,在这个函数里包含了用于生成马赛克图片的主要逻辑:首先,程序会获取用户上传的目标图片,并从表单中获取瓷砖图片的尺寸;接着,程序会对目标图片进行解码,并创建出一张全新的、空白的马赛克图片;之后,程序会复制一份瓷砖图片数据库,并为每张瓷砖图片设置起始点(source point),而这一起始点将在稍后的代码中被image/draw
包所使用。在完成了上述的准备工作之后,程序就可以开始对目标图片分割出的各张瓷砖图片尺寸的子图片进行迭代了。
对于每张被分割的子图片,程序都会把它左上角的第一个像素设置为该图片的平均颜色,然后在瓷砖图片数据库中查找与该颜色最为接近的瓷砖图片。在找到匹配的瓷砖图片之后,被调用的函数就会向程序返回该图片的文件名,然后程序就可以打开这张瓷砖图片并将其缩放至指定的瓷砖图片尺寸了。在缩放操作执行完毕之后,程序就会把最终得到的瓷砖图片绘制到之前创建的马赛克图片上。
在使用上述方法生成出整张马赛克图片之后,程序首先会将其编码为JPEG格式的图片,然后再将图片编码为base64格式的字符串。
之后,程序会将用户上传的目标图片以及新鲜出炉的马赛克图片都发送到代码清单9-17中展示的results.html
模板中。正如代码清单中加粗部分的代码所示,这个模板会通过数据URL以及嵌入Web页面中的base64字符串来显示被传入的两张图片。注意,这里使用的数据URL跟一般URL的作用并不相同,前者用于包含给定的数据,而后者则用于指向其他资源。
代码清单9-17 用于展示马赛克图片生成结果的模板
< !DOCTYPE html>
< html>
< head>
< meta http-equiv="Content-Type" content="text/html; charset=utf-8">
< title>Mosaic< /title>
...
< /head>
< body>
< div class='container'>
< div class="col-md-6">
< img src="data:image/jpg;base64,{{ .original }}" width="100%">
< div class="lead">Original< /div>
< /div>
< div class="col-md-6">
< img src="data:image/jpg;base64,{{ .mosaic }}" width="100%">
< div class="lead">Mosaic – {{ .duration }}
< /div>
< /div>
< div class="col-md-12 center">
< a class="btn btn-lg btn-info" href="/">Go Back< /a>
< /div>
< /div>
< br>
< /body>
< /html>
假设上述程序位于mosaic
目录当中,那么我们可以在构建该程序之后,通过执行以下命令,以只使用一个CPU的方式去运行它,并得到图9-5所示的结果:
GOMAXPROCS=1 ./mosaic
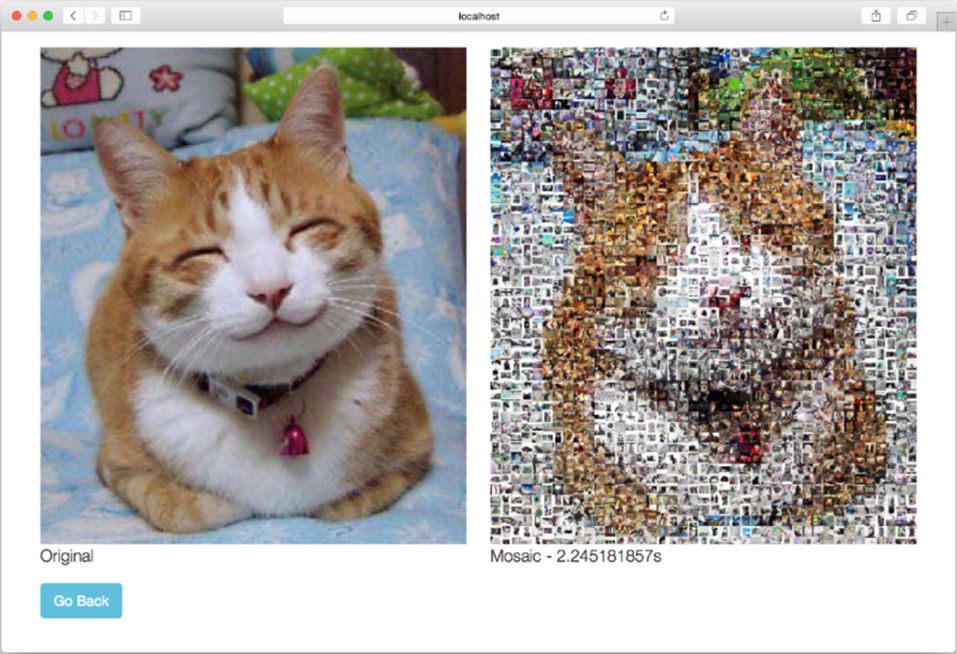
图9-5 基本的马赛克图片生成Web应用
在完成了基本的马赛克图片生成Web应用之后,我们接下来要考虑的就是如何把这个应用改造成相应的并发版本了。
并发的一个常见用途是提高性能。上一节展示的Web应用在为151 KB大小的JPEG图片创建马赛克图片时需要耗费2.25 s,它的性能并不值得称道,但我们可以通过并发来提高它的性能。具体来说,我们将使用以下算法来构建一个并发版本的马赛克图片生成Web应用:
(1)将用户上传的目标图片分割为4等份;
(2)同时对被分割的4张子图片进行马赛克处理;
(3)将处理完的4张子图片重新合并为1张马赛克图片。
图9-6以图示的方式描述了上述步骤。
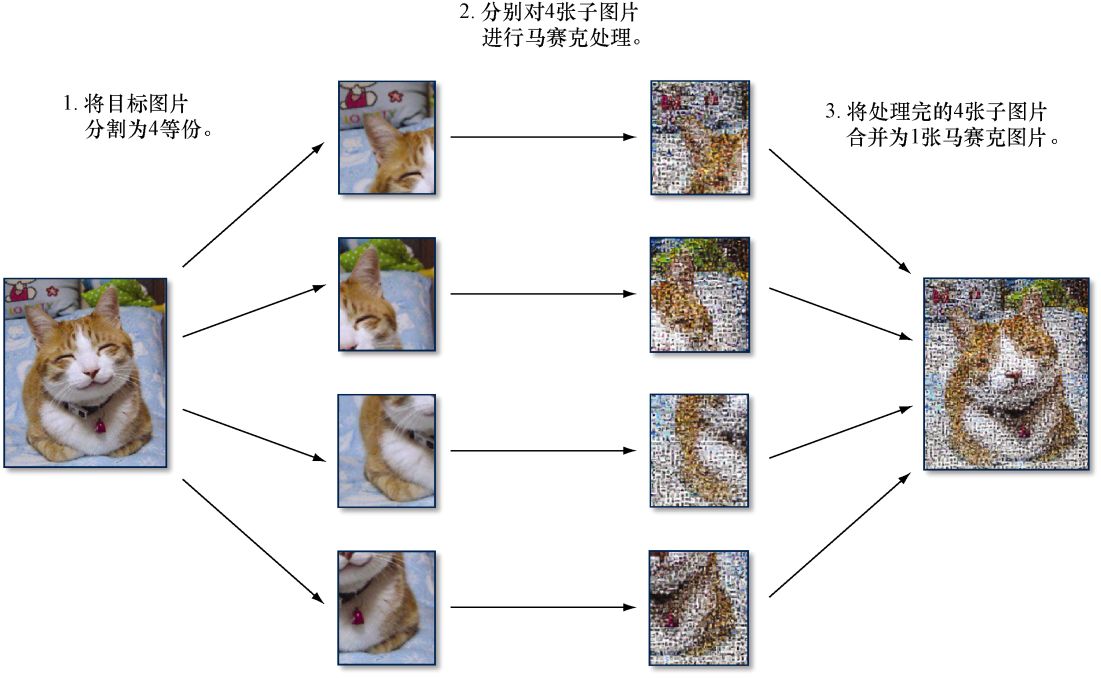
图9-6 能够更快地生成马赛克图片的并发算法
需要注意的是,这个算法并不是提高性能的唯一方法,也不是实现并发版本的唯一方法,但它是一个相对来说比较简单直接的方法。
为了实现这个并发算法,我们需要对mosaic
处理器函数做一些修改。之前展示的程序只有mosaic
这一个创建马赛克图片的处理器函数,但是对并发版的Web应用来说,我们需要从mosaic
函数中分离出cut
和combine
这两个独立的函数,然后再在mosaic
函数中调用它们。代码清单9-18展示了修改后的mosaic
函数。
代码清单9-18 并发版的mosaic
处理器函数
func mosaic(w http.ResponseWriter, r *http.Request) {
t0 := time.Now()
r.ParseMultipartForm(10485760) // max body in memory is 10MB
file, _, _ := r.FormFile("image")
defer file.Close()
tileSize, _ := strconv.Atoi(r.FormValue("tile_size"))
original, _, _ := image.Decode(file)
bounds := original.Bounds()
db := cloneTilesDB()
c1 := cut(original, &db, tileSize, bounds.Min.X, bounds.Min.Y,
➥bounds.Max.X/2, bounds.Max.Y/2)❶
c2 := cut(original, &db, tileSize, bounds.Max.X/2, bounds.Min.Y,
➥bounds.Max.X, bounds.Max.Y/2)❶
c3 := cut(original, &db, tileSize, bounds.Min.X, bounds.Max.Y/2,
➥bounds.Max.X/2, bounds.Max.Y)❶
c4 := cut(original, &db, tileSize, bounds.Max.X/2, bounds.Max.Y/2,
➥bounds.Max.X, bounds.Max.Y)❶
c := combine(bounds, c1, c2, c3, c4) ❷
buf1 := new(bytes.Buffer)
jpeg.Encode(buf1, original, nil)
originalStr := base64.StdEncoding.EncodeToString(buf1.Bytes())
t1 := time.Now()
images := map[string]string{
"original": originalStr,
"mosaic": <-c,
"duration": fmt.Sprintf("%v ", t1.Sub(t0)),
}
t, _ := template.ParseFiles("results.html")
t.Execute(w, images)
}
❶ 以扇形散开方式分割图片以便单独进行处理
❷ 以扇形聚拢方式将多个子图片合并成一个完整的图片
cut
函数会以扇形散开
(fan-out)模式将目标图片分割为多个子图片,如图9-7所示。

图9-7 将目标图片分割为4等份
用户上传的目标图片将被分割为4等份以便独立处理。注意,在mosaic
函数里,程序调用的都是普通函数而不是goroutine,这是因为程序的并发部分存在于被调用函数的内部:cut
函数会在内部以goroutine方式执行一个匿名函数,而这个匿名函数则会返回一个通道作为结果。
需要注意的是,因为我们正在尝试将一个程序转换为相应的并发版本,而并发程序通常都需要同时运行多个goroutine,所以如果程序需要在这些goroutine之间共享一些资源,那么针对这些资源的修改将有可能会导致竞争条件出现。
竞争条件
如果一个程序在执行时依赖于特定的顺序或时序,但是又无法保证这种顺序或时序,此时就会存在竞争条件 (race condition)。竞争条件的存在将导致程序的行为变得飘忽不定而且难以预测。
竞争条件通常出现在那些需要修改共享资源的并发程序当中。当有两个或多个进程或线程同时去修改一项共享资源时,最先访问资源的那个进程/线程将得到预期的结果,而其他进程/线程则不然。最终,因为程序无法判断哪个进程/线程最先访问了资源,所以它将无法产生一致的行为。
虽然竞争条件一般都不太好发现,但修复一个已判明的竞争条件通常来说并不是一件难事。
本节介绍的马赛克图片生成Web应用同样也拥有共享资源:用户在将目标图片上传至Web应用之后,nearest
函数就会从瓷砖图片数据库中寻找与之最为匹配的瓷砖图片,并从数据库中移除被选中的图片以防相同的图片重复出现。这就意味着,如果多个cut
函数中的goroutine同时找到了同一瓷砖图片作为最佳匹配结果,就会产生一个竞争条件。
为了消除这一竞争条件,我们可以使用一种名为互斥
(mutual exclusion,简称“mutex
”)的技术,该技术可以将同一时间内访问临界区(critical section)的进程数量限制为一个。对马赛克图片生成Web应用来说,我们需要在nearest
函数中实现互斥,以此来保证同一时间内只能有一个goroutine对瓷砖图片数据库进行修改。
为了满足这一点,程序需要用到Go标准库sync
包中的Mutex
结构。首先要做的是定义一个DB
结构,并在该结构中封装实际的瓷砖图片数据库以及mutex
标志,具体如代码清单9-19所示。
代码清单9-19 DB
结构
type DB struct {
mutex *sync.Mutex
store map[string][3]float64
}
接着,如代码清单9-20所示,将nearest
函数修改为DB
结构的一个方法。
代码清单9-20 nearest
方法
func (db *DB) nearest(target [3]float64) string {
var filename string
db.mutex.Lock() ❶
smallest := 1000000.0
for k, v := range db.store {
dist := distance(target, v)
if dist < smallest {
filename, smallest = k, dist
}
}
delete(db.store, filename)
db.mutex.Unlock() ❷
return filename
}
❶ 通过加锁设置mutex 标志
❷ 通过解锁移除mutex 标志
需要注意的是,因为在从数据库里移除被选中的图片之前,多个goroutine还是有可能会把相同的瓷砖图片设置为最佳的匹配结果,所以只锁住delete
函数是无法移除竞争条件的,因此修改后的nearest
函数将把寻找最佳匹配瓷砖图片的整个区域(section)都锁住。
代码清单9-21展示了cut
函数的具体代码。
代码清单9-21 cut
函数
func cut(original image.Image, db *DB, tileSize, x1, y1, x2, y2 int) <-chan
image.Image { ❶
c := make(chan image.Image) ❷
sp := image.Point{0, 0}
go func() { ❸
newimage := image.NewNRGBA(image.Rect(x1, y1, x2, y2))
for y := y1; y < y2; y = y + tileSize {
for x := x1; x < x2; x = x + tileSize {
r, g, b, _ := original.At(x, y).RGBA()
color := [3]float64{float64(r), float64(g), float64(b)}
nearest := db.nearest(color) ❹
file, err := os.Open(nearest)
if err == nil {
img, _, err := image.Decode(file)
if err == nil {
t := resize(img, tileSize)
tile := t.SubImage(t.Bounds())
tileBounds := image.Rect(x, y, x+tileSize, y+tileSize)
draw.Draw(newimage, tileBounds, tile, sp, draw.Src)
} else {
fmt.Println("error:", err)
}
} else {
fmt.Println("error:", nearest)
}
file.Close()
}
}
c <- newimage.SubImage(newimage.Rect)
}()
return c
}
❶ 把指向 DB 结构的引用传递给DB结构,而不是仅仅传入一个映射
❷ 这个通道将作为函数的执行结果返回给调用者
❸ 创建匿名的goroutine
❹ 调用DB 结构的nearest 方法来获取最匹配的瓷砖图片
并发版的马赛克图片生成Web应用跟原来的非并发版本拥有相同的逻辑:它首先在cut
函数里创建一个通道,并启动一个匿名goroutine来计算将要被发送至该通道的马赛克处理结果,接着再把这个通道返回给cut
函数的调用者。这样一来,cut
函数创建的通道就会立即返回给mosaic
处理器函数,而通道对应的马赛克子图片则会在处理完毕之后被发送至通道。另外需要注意的是,虽然 cut
函数创建的是一个双向通道,但是如果需要,我们也可以在返回这个通道之前,通过类型转换(typecast)将它转换成一个只能接收信息的单向通道。
在把用户上传的目标图片分割为4等份并将它们分别转换为马赛克图片的一部分之后,程序接下来就会调用代码清单9-22所示的combine
函数,通过扇形聚拢(fan-in)
模式,将4张子图片重新合并成1张完整的马赛克图片。
代码清单9-22 combine
函数
func combine(r image.Rectangle, c1, c2, c3, c4 <-chan image.Image)
<-chan string {
c := make(chan string) ❶
go func() { ❷
var wg sync.WaitGroup ❸
img:= image.NewNRGBA(r)
copy := func(dst draw.Image, r image.Rectangle,
src image.Image, sp image.Point) {
draw.Draw(dst, r, src, sp, draw.Src)
wg.Done() ❹
}
wg.Add(4) ❺
var s1, s2, s3, s4 image.Image
var ok1, ok2, ok3, ok4 bool
for { ❻
select { ❼
case s1, ok1 = <-c1:
go copy(img, s1.Bounds(), s1,
image.Point{r.Min.X, r.Min.Y})
case s2, ok2 = <-c2:
go copy(img, s2.Bounds(), s2,
image.Point{r.Max.X / 2, r.Min.Y})
case s3, ok3 = <-c3:
go copy(img, s3.Bounds(), s3,
image.Point{r.Min.X, r.Max.Y/2})
case s4, ok4 = <-c4:
go copy(img, s4.Bounds(), s4,
image.Point{r.Max.X / 2, r.Max.Y / 2})
}
if (ok1 && ok2 && ok3 && ok4) { ❽
break
}
}
wg.Wait() ❾
buf2 := new(bytes.Buffer)
jpeg.Encode(buf2, img, nil)
c <- base64.StdEncoding.EncodeToString(buf2.Bytes())
}()
return c
}
❶ 这个函数将返回一个通道作为执行结果
❷ 创建一个匿名goroutine
❸ 使用等待组去同步各个子图片的复制操作
❹ 每复制完一张子图片,就对计数器执行一次减一操作
❺ 把等待组计数器的值设置为4
❻ 在一个无限循环里面等待所有复制操作完成
❼ 等待各个通道的返回值
❽ 当所有通道都被关闭之后,跳出循环
❾ 阻塞直到所有子图片的复制操作都执行完毕为止
跟 cut
函数一样,合并多张子图片的主要逻辑也放到了匿名goroutine中,并且这些goroutine同样会创建并返回一个只能执行接收操作的通道作为结果。这样一来,程序就可以在编码目标图片的同时,对马赛克图片的4个部分进行合并。
在combine
函数创建的匿名goroutine里,程序会构建另一个匿名函数,并将其赋值给变量copy
。copy
函数之后同样会以goroutine方式运行,并将给定的马赛克子图片复制到最终的马赛克图片中。与此同时,因为程序无法得知以goroutine方式运行的copy
函数将于何时结束,所以它使用了等待组来同步这些复制操作。程序首先创建一个WaitGroup
变量wg
,并使用Add
方法将计数器的值设置为4
。之后,每当一个复制操作执行完毕的时候,copy
函数都会调用Done
方法,把等待组计数器的值减1。最后,程序把一个Wait
方法调用放在了最终生成的马赛克图片的编码操作之前,以此来保证程序只会在所有复制goroutine都已执行完毕,并且程序已经拥有了完整的最终马赛克图片之后,才会开始对图片进行编码。
一个需要注意的地方是,combine
函数接受的输入包含了4个来自cut
函数的通道,这些通道包含了马赛克图片的各个组成部分,并且程序不知道这些部分何时才会通过通道传输过来。虽然程序可以按顺序一个接一个从这些通道里接收信息,但这种做法并不符合并发程序的风格。为此,程序使用了select
方法,以先到先服务的方式来接收这些通道发送的信息。
这样做的结果是,程序会在一个无限循环里面进行迭代,并且每次迭代都会使用select
去获取其中一个已就绪通道传送的子图片(如果同时有多个子图片可用,那么Go将随机选择其中一个),然后以goroutine方式执行copy
函数,将接收到的子图片复制到最终生成的马赛克图片当中。因为程序使用了多值格式(multivalue format)来接收通道的返回值,而通道的第二个返回值(即ok1
、ok2
、ok3
和ok4
)可以说明程序是否已经成功地接收了各个通道传送的子图片,所以在无限循环的末尾,程序会通过检测这些返回值来决定是否跳出循环。
因为程序在接收到所有子图片之后,还需要在4个goroutine里分别复制这些子图片,而这些复制操作的完成时间是不确定的。为了解决这个问题,程序会调用之前定义的等待组变量wg
的Wait
方法,对最终生成的马赛克图片的编码操作进行阻塞,直到上述复制操作全部执行完毕为止。
现在,我们终于拥有了一个并发版的马赛克图片生成Web应用,接下来是时候运行一下它了。首先,假设程序位于mosaic_concurrent
目录当中,那么在使用go build
构建该程序之后,我们可以通过执行以下命令,使用单个CPU去运行它:
GOMAXPROCS=1 ./mosaic_concurrent
如果一切正常,将会看到图9-8所示的结果,生成这个结果时使用的目标图片以及瓷砖图片跟之前运行非并发版本时是完全一样的。
由于并发版程序在将4张子图片合并成1张完整的马赛克图片的时候,没有对子图片的毛边进行平滑处理,所以如果你仔细对比就会发现,这次生成的马赛克图片跟之前非并发版本生成的马赛克图片是有一点细微区别的(从彩色显示的电子书上会更为明显地看出这一点)。尽管生成的马赛克图片有些细微的不同,但并发版程序的性能提升是非常明显的——非并发版的马赛克图片生成Web应用处理相同的目标图片耗费了2.25 s,而并发版本只耗费了646 μs,后者的性能比前者提高了几乎有4倍之多。
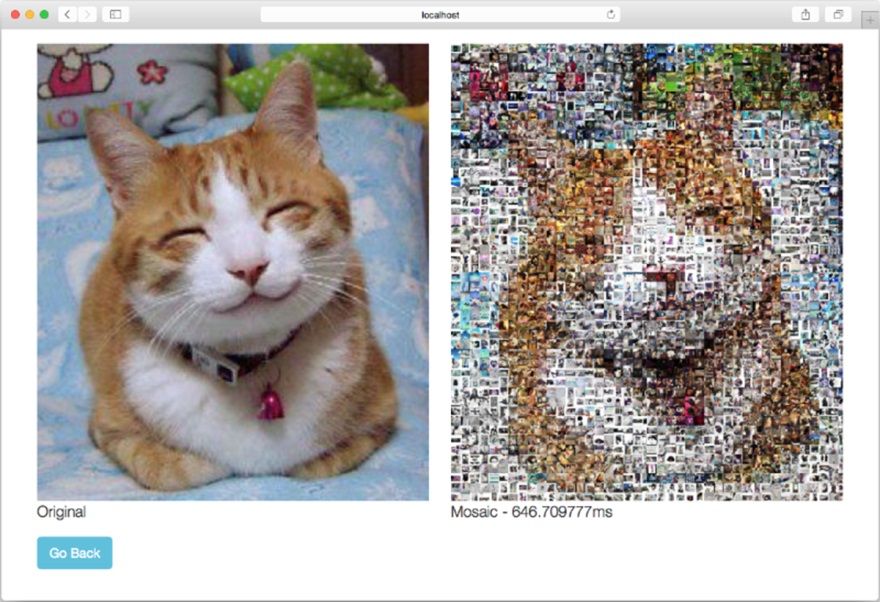
图9-8 并发版的马赛克照片生成Web应用
初看上去,我们所做的似乎 只是将一个函数分割成4个独立运行的goroutine,以此来实现一个并发版本的Web程序,但如果我们再进一步,以并行的方式去运行这个程序,结果又会如何呢?
别忘了,在前面的程序中,我们不仅将一个运行非常耗时的处理器函数分割成了几个独立运行的cut
函数goroutine,而且我们还在combine
函数里使用多个goroutine来独立地组合马赛克图片的各个部分。每当一个cut
函数完成了它的工作之后,它就会将处理的结果发送给与之对应的combine
函数,而后者则会将这一结果复制到最终生成的马赛克图片当中。
除此之外,别忘了,在前面运行非并发版本和并发版本的马赛克图片生成Web应用时,我们都只使用了一个CPU。正如之前所说,并发不是 并行——本节前面的内容已经展示了如何将一个简单的算法分解为相应的并发版本,其中不涉及任何并行计算:尽管这些goroutine能够以并发方式运行,但是因为只有一个CPU可用,所以这些goroutine实际上并没有以并行的方式运行。
为了让故事有一个圆满的结局,现在我们可以通过执行以下命令,以并行的方式,在多个CPU以及进程上运行并发版的马赛克图片生成Web应用:
./mosaic_concurrent
图9-9展示了上述命令的执行结果。
正如结果中打印的时间所示,并行运行的并发程序比单纯的并发程序又获得了大约3倍的性能提升,具体时间从原来的646 μs减少到了现在的216 μs!如果我们把这一结果跟最初的非并发版本所需的2.25 s相比,那么新程序的性能提升足有10倍之多。
对马赛克图片生成Web应用来说,非并发版本跟并发版本使用的图片处理算法是完全相同的。实际上,两个版本的mosaic.go
源码文件差别并不大,它们之间的主要区别在于是否使用了并发特性,这是提高程序性能的关键。
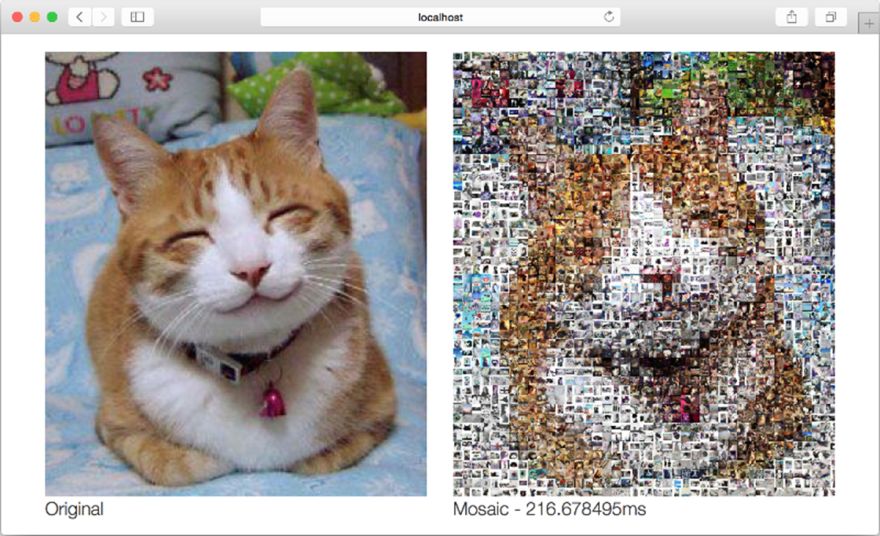
图9-9 使用8个CPU运行并发版的马赛克图片生成Web应用
完成了马赛克图片生成Web应用之后,在接下来的一章,我们要考虑的就是如何部署Web应用和Web服务了。
select
语句可以以先到先服务的方式,从多个通道里选出一个已经准备好执行接收操作的通道。
WaitGroup
同样可以用于对多个通道进行同步。
[1] 原书说Go 1.4 goroutine 的启动栈大小为8 KB,但根据资料,这个栈的大小应该是2 KB才对,所以在译文里面进行了修正。(资料链接:https://golang.org/doc/go1.4#runtime。)——译者注