本章主要内容
正如本书第1章所言,Web服务就是一个向其他软件程序提供服务的程序。本章将扩展这一定义,并展示如何使用Go语言来编写或使用Web服务。因为XML和JSON是Web服务最常使用的数据格式,所以我们首先会学习如何创建以及分析这两种数据格式,接着我们将会讨论SOAP风格的服务以及REST风格的服务,并在之后学习如何创建一个使用JSON传输数据的简单的Web服务。
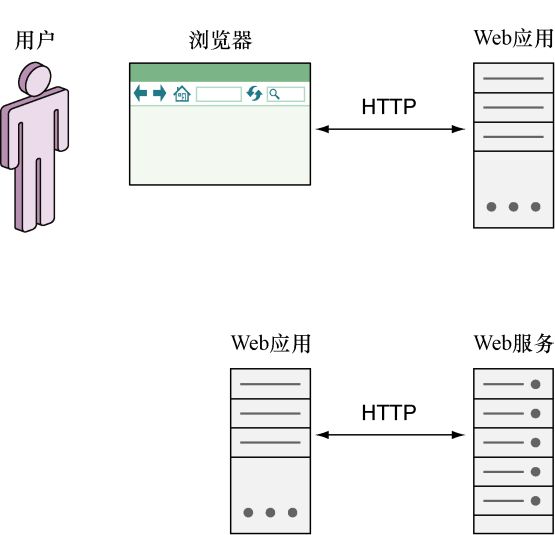
通过Go语言编写的Web服务向其他Web服务或应用提供服务和数据,是Go语言的一种常见的用法。所谓的Web服务,一言以蔽之,就是一种与其他软件程序进行交互的软件程序。这也就是说,Web服务的终端用户(end user)不是人类,而是软件程序。正如“Web服务”这一名字所暗示的那样,这种软件程序是通过HTTP进行通信的,如图7-1所示。
图7-1 Web应用与Web服务的不同之处
有趣的是,虽然Web应用并没有一个确切的定义,但Web服务的定义却可以在W3C工作组发布的《Web服务架构》(Web Service Architecture)文档中找到:
Web服务是一个软件系统,它的目的是为网络上进行的可互操作机器间交互(interoperable machine-to-machine interaction)提供支持。每个Web服务都拥有一套自己的接口,这些接口由一种名为Web服务描述语言(web service description language,WSDL)的机器可处理格式描述。其他系统需要根据Web服务的描述,使用SOAP消息与Web服务交互。为了与其他Web相关标准实现协作,SOAP消息通常会被序列化为XML并通过HTTP传输。
——《Web服务架构》,2004年2月11日
从这一定义来看,似乎所有Web服务都应该基于SOAP来实现,但实际中却存在着多种不同类型的Web服务,其中包括基于SOAP的、基于REST的以及基于XML-RPC的,而基于REST的和基于SOAP的Web服务又是其中最为流行的。企业级系统大多数都是基于SOAP的Web服务实现的,而公开可访问的Web服务则更青睐基于REST的Web服务,本章稍后将会对此进行讨论。
基于SOAP的Web服务和基于REST的Web服务都能够完成相同的功能,但它们各自也拥有不同的长处。基于SOAP的Web服务出现的时间较早,W3C工作组已经对其进行了标准化,与之相关的文档和资料也非常丰富。除此之外,很多企业都对基于SOAP的Web服务提供了强有力的支持,并且基于SOAP的Web服务还拥有数量颇丰的扩展可用(因为这些扩展的名字绝大多数都是像WS-Security和WS-Addressing这样以WS为前缀的,所以这些扩展被统称为WS-*)。基于SOAP的服务不仅健壮、能够使用WSDL进行明确的描述、拥有内置的错误处理机制,而且还可以通过UUDI(Universal Description, Discovery, and Integration,统一描述、发现和集成)(一种目录服务)规范发布。
在拥有以上众多优点的同时,SOAP的缺点也是非常明显的:它不仅笨重,而且过于复杂。SOAP的XML报文可能会变得非常冗长,导致难以调试,使用户只能通过其他工具对其进行管理,而基于SOAP的Web服务可能会因为额外的资源损耗而无法高效地运行。此外,WSDL虽然在客户端和服务器之间提供了坚实的契约,但这种契约有时候也会变成一种累赘:为了对Web服务进行更新,用户必须修改WSDL,而这种修改又会引起SOAP客户端发生变化,最终导致Web服务的开发者即使在进行最细微的修改时,也不得不使用版本锁定(version lock-in)以防止发生意外。
跟基于SOAP的Web服务比起来,基于REST的Web服务就显得灵活多了。REST本身并不是一种结构,而是一种设计理念。很多基于REST的Web服务都会使用像JSON这样较为简单的数据格式而不是XML,从而使Web服务可以更高效地运行,并且基于REST的Web服务实现起来通常会比基于SOAP的Web服务简单得多。
基于SOAP的Web服务和基于REST的Web服务的另一个区别在于,前者是功能驱动的,而后者是数据驱动的。基于SOAP的Web服务往往是RPC(Remote Procedure Call,远程过程调用)风格的;但是,正如之前所说,基于REST的Web服务关注的是资源,而HTTP方法则是对这些资源执行操作的动词。
ProgrammableWeb是一个流行的API检测网站,它会对互联网上公开可用的API进行检测。在编写本书的时候,ProgrammableWeb的数据库搜集了12 987个公开可用的API,其中2 061个(占比16%)为基于SOAP的API,而6 967个(占比54%)为基于REST的API [1] 。可惜的是,因为企业很少会对外发布与内部Web服务有关的信息,所以想要调查清楚各种Web服务在企业中的使用情况是非常困难的。
为了满足不同的需求,很多开发者和公司最终还是会同时使用基于SOAP的Web服务和基于REST的Web服务。在这种情况下,SOAP将用于实现内部应用的企业集成(enterprise integration),而REST则用于服务外部以及第三方的开发者。这一策略的优势在于,它最大限度地利用了REST(速度快并且构建简单)以及SOAP(安全并且健壮)这两种技术的优点。
SOAP是一种协议,用于交换定义在XML里面的结构化数据,它能够跨越不同的网络协议并在不同的编程模型中使用。SOAP原本是Simple Object Access Protocol(简单对象访问协议)的首字母缩写,但这实际上是一个名不符实的名字,因为这种协议处理的并不是对象,并且时至今日它也已经不再是一种简单的协议了。在最新版的SOAP 1.2规范中,这种协议的官方名称仍然为SOAP,但它已经不再代表Simple Object Access Protocol了。
因为SOAP不仅高度结构化,而且还需要严格地进行定义,所以用于传输数据的XML可能会变得非常复杂。WSDL是客户端与服务器之间的契约,它定义了服务提供的功能以及提供这些功能的方式,服务的每个操作以及输入/输出都需要由WSDL明确地定义。
虽然本章主要关注的是基于REST的Web服务,但出于对比需要,我们也会了解一下基于SOAP的Web服务的运作机制。
SOAP会将它的报文内容放入到信封(envelope)里面,信封相当于一个运输容器,并且它还能够独立于实际的数据传输方式存在。因为本书只会对SOAP Web服务进行考察,所以我们将通过HTTP协议来说明被传输的SOAP报文。
下面是一个经过简化的SOAP请求报文示例:
POST /GetComment HTTP/1.1
Host: www.chitchat.com
Content-Type: application/soap+xml; charset=utf-8
<?xml version="1.0"?>
<soap:Envelope
xmlns:soap="http://www.w3.org/2001/12/soap-envelope"
soap:encodingStyle="http://www.w3.org/2001/12/soap-encoding">
<soap:Body xmlns:m="http://www.chitchat.com/forum">
<m:GetCommentRequest>
<m:CommentId>123</m:CommentId>
</m:GetCommentRequest >
</soap:Body>
</soap:Envelope>
因为前面已经介绍过HTTP报文的首部,所以这里给出的HTTP首部对你来说应该不会感到陌生。需要注意的是,Content-Type
的值被设置成了application/soap+xml
,而HTTP请求的主体就是SOAP报文本身,至于SOAP报文的主体则包含了请求报文。在这个例子中,报文请求的是ID为123
的评论:
<m:GetCommentRequest>
<m:CommentId>123</m:CommentId>
</m:GetCommentRequest >
这条SOAP报文示例经过了简化,实际的SOAP请求通常会复杂得多。下面展示的则是一条简化后的SOAP响应报文示例:
HTTP/1.1 200 OK
Content-Type: application/soap+xml; charset=utf-8
<?xml version="1.0"?>
<soap:Envelope
xmlns:soap="http://www.w3.org/2001/12/soap-envelope"
soap:encodingStyle="http://www.w3.org/2001/12/soap-encoding">
<soap:Body xmlns:m="http://www.example.org/stock">
<m:GetCommentResponse>
<m:Text>Hello World!</m:Text>
</m:GetCommentResponse>
</soap:Body>
</soap:Envelope>
跟请求报文一样,响应报文也被包含在了SOAP报文的主体里面,它的内容为文本“Hello World!”:
<m:GetCommentResponse>
<m:Text>Hello World!</m:Text>
</m:GetCommentResponse>
正如上面的例子所示,与报文有关的所有数据都会被包含在信封里面。对基于SOAP的Web服务来说,这意味着它传输的所有信息都会被包裹在SOAP信封里面,然后再发送。顺带一提,虽然SOAP 1.2允许通过HTTP的GET
方法发送SOAP报文,但大多数基于SOAP的Web服务都是通过HTTP的POST
方法发送SOAP报文的。
下面展示的是一个WSDL报文示例,这种报文不仅详细,而且还很冗长,即使对简单的服务来说也是如此。基于SOAP的Web服务之所以没有基于REST的Web服务那么流行,其中一部分原因就与此有关——一个基于SOAP的Web服务越复杂,它对应的WSDL报文就越冗长。
<?xml version="1.0" encoding="UTF-8"?>
<definitions name ="ChitChat"
targetNamespace="http://www.chitchat.com/forum.wsdl"
xmlns:tns="http://www.chitchat.com/forum.wsdl"
xmlns:soap="http://schemas.xmlsoap.org/wsdl/soap/"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns="http://schemas.xmlsoap.org/wsdl/">
<message name="GetCommentRequest">
<part name="CommentId" type="xsd:string"/>
</message>
<message name="GetCommentResponse">
<part name="Text" type="xsd:string"/>
</message>
<portType name="GetCommentPortType">
<operation name="GetComment">
<input message="tns:GetCommentRequest"/>
<output message="tns:GetCommentResponse"/>
</operation>
</portType>
<binding name="GetCommentBinding" type="tns:GetCommentPortType">
<soap:binding style="rpc"
transport="http://schemas.xmlsoap.org/soap/http"/>
<operation name="GetComment">
<soap:operation soapAction="getComment"/>
<input>
<soap:body use="literal"/>
</input>
<output>
<soap:body use="literal"/>
</output>
</operation>
</binding>
<service name="GetCommentService" >
<documentation>
Returns a comment
</documentation>
<port name="GetCommentPortType" binding="tns:GetCommentBinding">
<soap:address location="http://localhost:8080/GetComment"/>
</port>
</service>
</definitions>
位于报文开头的是报文对自身的定义,该定义给出了报文各个部分的名字,以及这些部分的类型:
<message name="GetCommentRequest">
<part name="CommentId" type="xsd:string"/>
</message>
<message name="GetCommentResponse">
<part name="Text" type="xsd:string"/>
</message>
在此之后,报文通过GetComment
操作定义了GetCommentPortType
端口,该操作的输入报文为GetCommentRequest
,而输出报文则为GetCommentResponse
:
<portType name="GetCommentPortType">
<operation name="GetComment">
<input message="tns:GetCommentRequest"/>
<output message="tns:GetCommentResponse"/>
</operation>
</portType>
最后,报文在位置http://localhost:8080/GetComment定义了一个GetCommentService
服务,并将它与GetCommentPortType
端口以及GetCommentsBinding
地址进行绑定:
<service name="GetCommentService" >
<documentation>
Returns a comment
</documentation>
<port name="GetCommentPortType" binding="tns:GetCommentBinding">
<soap:address location="http://localhost:8080/GetComment"/>
</port>
</service>
在实际中,SOAP请求报文通常会由WSDL生成的SOAP客户端负责生成;同样地,SOAP响应报文通常也是由WSDL生成的SOAP服务器负责生成。具体语言的客户端(如一个Go SOAP客户端)通常也会由WSDL负责生成,而其他代码则会通过使用这个客户端与服务器进行交互。这样做的结果是,只要WSDL是明确定义的,那么它生成的SOAP客户端通常也会是健壮的;与此同时,这种做法的缺陷是,开发人员每次修改服务器,即使是修改返回值的类型这样微小的修改,客户端都需要重新生成。重复生成客户端的过程通常都是冗长而乏味的,这也解释了为什么SOAP Web服务通常很少会出现大量的修改——因为对大型的SOAP Web服务来说,频繁的修改将是一场噩梦。
本章接下来不会再对基于SOAP的Web服务做进一步的介绍,但我们会学习如何使用Go语言创建以及分析XML。
REST(Representational State Transfer,具象状态传输)是一种设计理念,用于设计那些通过标准的几个动作来操纵资源,并以此来进行相互交流的程序(很多REST使用者都会把操纵资源的动作称为“动词”,也就是verb)。
在大多数编程范型里面,程序员都是通过定义函数然后在主程序中有序地调用这些函数来完成工作的。在面向对象编程(OOP)范型中,程序员要做的事情也是类似的,主要的区别在于,程序员通过创建称为对象 (object)的模型来表示事物,然后定义称为方法 (method)的函数并将它们附着到模型之上。REST是以上思想的进化版,但它并不是把函数暴露(expose)为可调用的服务,而是以资源 (resource)的名义把模型暴露出来,并允许人们通过少数几个称为动词 的动作来操纵这些资源。
在使用HTTP协议实现REST服务时,URL将用于表示资源,而HTTP方法则会用作操纵资源的动词,具体如表7-1所示。
表7-1 使用HTTP方法与Web服务进行通信
|
HTTP方法 |
作用 |
使用示例 |
|---|---|---|
|
|
在一项资源尚未存在的情况下创建该资源 |
|
|
|
获取一项资源 |
|
|
|
重新给定URL上的资源 |
|
|
|
删除一项资源 |
|
刚开始学习REST的程序员在第一次看到REST使用的HTTP方法与数据库的CRUD操作之间的映射关系时,常常会对此感到非常惊奇。需要注意的是,这种映射并不是一对一映射,而且这种映射也不是唯一的。比如说,在
创建一项新的资源时用户既可以使用POST
,也可以使用PUT
,这两种做法都符合REST风格。
POST
和PUT
的主要区别在于,在使用PUT
时需要准确地知道哪一项资源将会被替换,而使用POST
只会创建出一项新资源以及一个新URL。换句话说,POST
用于创建一项全新的资源,而PUT
则用于替换一项已经存在的资源。
正如第1章所言,PUT
方法是幂等的,无论同一个调用重复执行多少次,服务器的状态都不会发生任何变化。无论是使用PUT
创建一项资源,还是使用PUT
修改一项已经存在的资源,给定的URL上面都只会有一项资源被创建出来。相反地,因为POST
并不是幂等的,所以每调用POST
一次,它就会创建一项新资源以及一个新URL。
对刚开始学习REST的程序员来说,另一个需要注意的地方是,REST并不是只能通过表7-1提到的4个HTTP方法实现,比如,不太常见的PATCH
方法就可以用于对一项资源进行部分更新。
下面是一个REST请求示例:
GET /comment/123 HTTP/1.1
注意,这个GET
请求并没有与之相关联的主体,而与这个GET
请求相对应的SOAP请求则正好相反:
POST /GetComment HTTP/1.1
Host: www.chitchat.com
Content-Type: application/soap+xml; charset=utf-8
<?xml version="1.0"?>
<soap:Envelope
xmlns:soap="http://www.w3.org/2001/12/soap-envelope"
soap:encodingStyle="http://www.w3.org/2001/12/soap-encoding">
<soap:Body xmlns:m="http://www.chitchat.com/forum">
<m:GetCommentRequest>
<m:CommentId>123</m:CommentId>
</m:GetCommentRequest >
</soap:Body>
</soap:Envelope>
这是因为在发送第一个请求的时候,我们使用了HTTP的GET
方法作为动词来获取资源(在这个例子中,资源就是一条博客评论)。对于这个GET
请求,即使Web服务返回一个SOAP响应,它也会被认为是一个REST风格的响应:这是因为REST跟SOAP不同,前者关注的是API的设计,而后者关注的则是被发送报文的格式。不过,因为SOAP报文构建起来非常麻烦,所以人们在使用REST API的时候通常都是返回JSON,或者返回一些比SOAP报文要简单得多的XML,而很少会返回SOAP报文。
正如WSDL跟SOAP的关系一样,基于REST的Web服务也拥有相应的WADL(Web Application Description Language,Web应用描述语言),这种语言可以对基于REST的Web服务进行描述,甚至能够生成访问这些服务的客户端。但是跟WSDL不同的是,WADL没有得到广泛的使用,也没有进行标准化。此外,WADL也拥有Swagger、RAML(Restful API Modeling Language,REST风格API建模语言)和JSON-home这样的同类竞争产品。
在刚开始接触REST的时候,你可能会意识到这种设计理念非常适用于那些只执行简单的CRUD操作的应用,但REST是否适用于更为复杂的服务呢?除此之外,它又是如何对过程或者动作进行建模的呢?
举个例子,在使用REST设计的情况下,一个应用要如何才能激活一个用户的账号呢?因为REST只允许用户使用指定的几个HTTP方法操纵资源,而不允许用户对资源执行任意的动作,所以应用是无法发送像下面这样的请求的:
ACTIVATE /user/456 HTTP/1.1
有一些办法可以绕过这个问题,下面是最常用的两种方法:
(1)把过程具体化 [2] ,或者把动作转换成名词,然后将其用作资源;
(2)将动作用作资源的属性。
对于上面列举的例子,我们可以把对用户的激活动作转换为对资源的激活动作,然后通过向资源发送HTTP方法来执行激活动作,这样一来,我们就可以通过以下方法激活指定的用户:
POST /user/456/activation HTTP/1.1
{ "date": "2015-05-15T13:05:05Z" }
这段代码将创建一个被激活的资源(activation resource),以此来表示用户的激活状态。这种做法的另一个好处是,它可以为被激活的资源添加额外的属性。比如,在上面展示的例子中,我们就将一个日期附加给了被激活的资源。
如果用户的激活与否可以通过用户账号的一个状态来确定,那么我们只需要将激活动作用作资源的属性,然后通过HTTP的PATCH
方法对该资源进行部分更新即可,就像这样:
PATCH /user/456 HTTP/1.1
{ "active" : "true" }
这段代码将把用户资源的active
属性设置为true
。
在对SOAP风格的Web服务和REST风格的Web服务有了基本的了解之后,接下来就让我们看看Go语言是如何实现这两种服务的。首先,本节会介绍如何创建和处理SOAP Web服务会用到的XML数据,而下一节则会介绍如何创建和处理 REST Web服务会用到的JSON数据。
XML可以以结构化的形式表示数据,它跟本书前面提到的HTML一样,都是一种流行的标记语言。XML可能是在表示、发送和接收结构化数据方面使用最广泛的一种格式,这种格式获得了W3C组织的正式推荐,W3C发布的XML 1.0规范中给出了这一格式的具体定义。
因为我们经常会用到其他人提供的Web服务,或者需要处理诸如RSS这样基于XML的数据源,所以无论你最终是否会编写或使用Web服务,学习如何创建和分析XML都是一项非常重要的技能。即使你不需要开发自己的XML Web服务,学会如何使用Go与XML进行交互也是非常有用的一件事。比如说,你可能会需要从一个RSS新闻源里面获取数据,并将其用作自己的数据源之一。在这种情况下,你必须懂得如何分析XML并从中提取出自己想要获取的信息。
无论是使用XML、JSON还是其他格式,使用Go语言分析结构化数据的方法都是相似的。对XML和JSON进行操作需要分别用到encoding
库中的XML子包和JSON子包,现在,就让我们来看看encoding/xml
子包的使用方法。
因为分析XML是刚开始接触XML时经常会做的一件事,所以我们就以学习如何分析XML为开始。在Go语言里面,用户首先需要将XML的分析结果存储到一些结构里面,然后通过访问这些结构来获取XML记录的数据。下面是分析XML时常见的两个步骤:
(1)创建一些用于存储XML数据的结构;
(2)使用xml.Unmarshal
将XML数据解封(unmarshal)到结构里面,如图7-2所示。
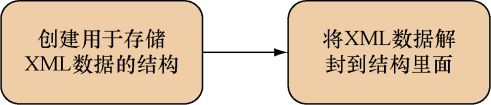
图7-2 使用Go对XML进行分析:将XML解封至结构
代码清单7-1展示了一个简单的XML文件post.xml
。
代码清单7-1 一个简单的XML文件post.xml
<?xml version="1.0" encoding="utf-8"?>
<post id="1">
<content>Hello World!</content>
<author id="2">Sau Sheong</author>
</post>
代码清单7-2展示了分析这个XML所需的代码,这些代码存储在文件xml.go
里。
代码清单7-2 对XML进行分析
package main
import (
"encoding/xml"
"fmt"
"io/ioutil"
"os"
)
type Post struct { //#A ❶
XMLName xml.Name `xml:"post"`
Id string `xml:"id,attr"`
Content string `xml:"content"`
Author Author `xml:"author"`
Xml string `xml:",innerxml"`
}
type Author struct {
Id string `xml:"id,attr"`
Name string `xml:",chardata"`
}
func main() {
xmlFile, err := os.Open("post.xml")
if err != nil {
fmt.Println("Error opening XML file:", err)
return
}
defer xmlFile.Close()
xmlData, err := ioutil.ReadAll(xmlFile)
if err != nil {
fmt.Println("Error reading XML data:", err)
return
}
var post Post
xml.Unmarshal(xmlData, &post) ❷
fmt.Println(post)
}
❶ 定义一些结构,用于表示数据
❷ 将XML 数据解封到结构里面
分析程序定义了用于表示数据的Post
结构和Author
结构。因为程序想要在获取作者信息的同时也获取作者信息所在元素的id
属性,所以程序使用了单独的Author
结构来表示帖子的作者,但并没有使用单独的Content
结构来表示帖子的内容。如果我们不打算获取作者信息的id
属性,也可以定义一个下面这样的Post
结构,并直接使用字符串来表示帖子的作者信息(代码中的加粗行):
type Post struct {
XMLName xml.Name `xml:"post"`
Id string `xml:"id,attr"`
Content string `xml:"content"`
Author string `xml:"author"`
Xml string `xml: ",innerxml"`
}
Post
结构中每个字段的定义后面都带有一段使用反引号(`)包围的信息,这些信息被称为结构标签
(struct tag),Go语言使用这些标签来决定如何对结构以及XML元素进行映射,如图7-3所示。
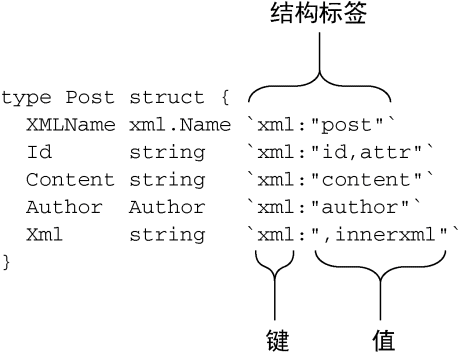
图7-3 结构标签用于定义XML和结构之间的映射
结构标签是一些跟在字段后面,使用字符串表示的键值对:它的键是一个不能包含空格、引号("
)或者冒号(:
)的字符串,而值则是一个被双引号(""
)包围的字符串。在处理XML时,结构标签的键总是为xml
。
为什么使用反引号来包围结构标签
因为Go语言使用双引号(
"")和反引号(`)来包围字符串,使用单引号(')来包围rune(一种用于表示Unicode码点的int32类型),并且因为结构标签内部已经使用了双引号来包围键的值,所以为了避免进行转义,Go语言就使用了反引号来包围结构标签。
出于创建映射的需要,xml
包要求被映射的结构以及结构包含的所有字段都必须是公开的,也就是,它们的名字必须以大写的英文字母开头。以上面展示的代码为例,结构的名字必须为Post
而不能是post
,至于字段的名字则必须为Content
而不能是content
。
下面是XML结构标签的其中一些使用规则。
(1)通过创建一个名字为XMLName
、类型为xml.Name
的字段,可以将XML元素的名字存储在这个字段里面(在一般情况下,结构的名字就是元素的名字)。
(2)通过创建一个与XML元素属性同名的字段,并使用'xml:"<name
>,attr"
'作为该字段的结构标签,可以将元素的<name
>
属性的值存储到这个字段里面。
(3)通过创建一个与XML元素标签同名的字段,并使用'xml:",chardata"'
作为该字段的结构标签,可以将XML元素的字符数据存储到这个字段里面。
(4)通过定义一个任意名字的字段,并使用'xml:",innerxml"'
作为该字段的结构标签,可以将XML元素中的原始XML存储到这个字段里面。
(5)没有模式标志(如,attr
、,chardata
或者,innerxml
)的结构字段将与同名的XML元素匹配。
(6)使用'xml:"a>b>c"'
这样的结构标签可以在不指定树状结构的情况下直接获取指定的XML元素,其中a
和b
为中间元素,而c
则是想要获取的节点元素。
要一下子了解这么多规则并不容易,特别是对最后几条规则来说更是如此,所以我们最好还是来看一些实际应用这些规则的例子。
代码清单7-3给出了表示帖子XML元素的post
变量及其对应的Post
结构。
代码清单7-3 用于表示帖子的简单的XML元素
<post id="1">
<content>Hello World!</content>
<author id="2">Sau Sheong</author>
</post>
而下面是post
元素对应的Post
结构:
type Post struct {
XMLName xml.Name `xml:"post"`
Id string `xml:"id,attr"`
Content string `xml:"content"`
Author Author `xml:"author"`
Xml string `xml:",innerxml"`
}
分析程序定义了与XML元素post
同名的Post
结构,虽然这种做法非常常见,但是在某些时候,结构的名字与XML元素的名字可能并不相同,这时用户就需要一种方法来获取元素的名字。为此,xml
包提供了一种机制,使用户可以通过定义一个名为XMLName
、类型为xml.Name
的字段,并将该字段映射至元素自身来获取XML元素的名字。在Post
结构的例子中,这一映射就是通过'xml:"post"'
结构标签来完成的。根据规则1——“使用XMLName
字段存储元素的名字”,分析程序将元素的名字post
存储到了Post
结构的XMLName
字段里面。
XML元素post
拥有一个名为id
的属性,根据规则2——“使用结构标签
将xml:"<name>,`` ``attr"```</code>存储属性的值”,分析程序通过结构标签<code>
xml:"id,attr"`id
属性的值存储到了Post
结构的Id
字段里面。
post
元素包含了一个content
子元素,这个子元素没有属性,但它包含了字符数据Hello World!
,根据规则5——“没有模式标志的结构字段将与同名的XML元素进行匹配”,分析程序通过结构标签'xml:"content"'
将content
子元素包含的字符数据存储到了Post
结构的Content
字段里面。
根据规则4——“使用结构标签'xml:",innerxml"'
可以获取原始XML”,分析程序定义了一个Xml
字段,并使用'xml:",innerxml"'
作为该字段的结构标签,以此来获得被post
元素包含的原始XML:
<content>Hello World!</content>
<author id="2">Sau Sheong</author>
子元素author
拥有id
属性,并且包含字符数据Sau Sheong
,为了正确地构建映射,分析程序专门定义了Author
结构:
type Author struct {
Id string `xml:"id,attr"`
Name string `xml:",chardata"`
}
根据规则5,author
子元素被映射到了带有'xml:"author"'
结构标签的Author
字段。在Author
结构中,属性id
的值被映射到了带有'xml:"id,attr"'
结构标签的Id
字段,而字符数据Sau Sheong
则被映射到了带有'xml:",chardata"'
结构标签的Name
字段。
俗话说,百闻不如一见。在详细了解了整个分析程序之后,接下来就让我们实际运行一下这个程序。在终端里面执行以下命令:
go run xml.go
如果一切正常,这一命令应该会返回以下结果:
{{ post} 1 Hello World! {2 Sau Sheong}
<content>Hello World!</content>
<author id="2">Sau Sheong</author>
}
让我们逐一地分析这些结果。首先,因为post
变量是Author
结构的一个实例,所以整个结果都被包围在了一对大括号({}
)里面。post
结构的第一个字段是另一个类型为xml.Name
的结构,这个结构在结果中表示为{ post }
。在此之后展示的数字1
为Id
字段的值,而"Hello World!"
则是Content
字段的值。再之后展示的是存储在Author
结构里面的内容,{2 Sau Sheong}
。结果最后展示的是XML元素post
内部包含的原始XML。
前面的内容列举了规则1至规则5的使用示例,现在让我们来看看规则6是如何运作的。规则6声称,使用结构标签'xml:"a>b>c"',
可以在不指定树状结构的情况下,越过中间元素a
和b
直接访问节点元素c
。
代码清单7-4展示的是另一个XML示例,这个XML也存储在名为post.xml
的文件中。
代码清单7-4 带有嵌套元素的XML文件
< ?xml version="1.0" encoding="utf-8"?>
< post id="1">
< content>Hello World!< /content>
< author id="2">Sau Sheong< /author>
< comments>
< comment id="1">
< content>Have a great day!< /content>
< author id="3">Adam< /author>
< /comment>
< comment id="2">
< content>How are you today?< /content>
< author id="4">Betty< /author>
< /comment>
< /comments>
< /post>
这个XML文件的前半部分内容跟之前展示的XML文件是相同的,而加粗显示的则是新出现的代码,这些新代码定义了一个名为comments
的XML子元素,并且这个元素本身也包含多个comment
子元素。这一次,分析程序需要获取帖子的评论列表,但为此专门创建一个Comments
结构可能会显得有些小题大做了。为了简化实现代码,分析程序将根据规则6对comments
这个XML子元素进行跳跃式访问。代码清单7-5展示了经过修改的Post
结构,修改后的Post
结构带有新增的字段以及实现跳跃式访问所需的结构标签。
代码清单7-5 带有comments
结构字段的Post
结构
type Post struct {
XMLName xml.Name `xml:"post"`
Id string `xml:"id,attr"`
Content string `xml:"content"`
Author Author `xml:"author"`
Xml string `xml:",innerxml"`
Comments []Comment `xml:"comments>comment"`
}
正如代码中的加粗行所示,分析程序为了获取帖子的评论列表,在Post
结构中增加了类型为Comment
结构切片的Comments
字段,并通过结构标签'xml:"comments>comment"'
将这个字段映射至名为comment
的XML子元素。根据规则6,这一结构标签将允许分析程序跳过XML中的comments
元素,直接访问comment
子元素。
Comment
结构和Post
结构非常相似,它的具体定义如下:
type Comment struct {
Id string `xml:"id,attr"`
Content string `xml:"content"`
Author Author `xml:"author"`
}
在定义了进行语法分析所需的结构以及映射关系之后,现在是时候将XML数据解封到这些结构里面了。因为负责执行解封操作的Unmarshal
函数只接受字节切片(也就是字符串)作为参数,所以分析程序首先要做的就是将XML文件转换为字符串,这一操作可以通过以下代码来实现(在执行这些代码时,XML文件必须与Go文件处于同一目录之下):
xmlFile, err := os.Open("post.xml")
if err != nil {
fmt.Println("Error opening XML file:", err)
return
}
defer xmlFile.Close()
xmlData, err := ioutil.ReadAll(xmlFile)
if err != nil {
fmt.Println("Error reading XML data:", err)
return
}
在将XML文件的内容读取到xmlData
变量里面之后,分析程序可以通过执行以下代码来解封XML数据:
var post Post
xml.Unmarshal(xmlData, &post)
如果你曾经使用其他编程语言分析过XML,那么你应该会知道,这种做法虽然能够很好地处理体积较小的XML文件,但是却无法高效地处理以流(stream)方式传输的XML文件以及体积较大的XML文件。为了解决这个问题,我们需要使用Decoder
结构来代替Unmarshal
函数,通过手动解码XML元素的方式来解封XML数据,这个过程如图7-4所示。

图7-4 使用Go分析XML:将XML解码至结构
代码清单7-6展示了如何使用Decoder
分析前面提到的XML文件。
代码清单7-6 使用Decoder
分析XML
package main
import (
"encoding/xml"
"fmt"
"io"
"os"
)
type Post struct {
XMLName xml.Name `xml:"post"`
Id string `xml:"id,attr"`
Content string `xml:"content"`
Author Author `xml:"author"`
Xml string `xml:",innerxml"`
Comments []Comment `xml:"comments>comment"`
}
type Author struct {
Id string `xml:"id,attr"`
Name string `xml:",chardata"`
}
type Comment struct {
Id string `xml:"id,attr"`
Content string `xml:"content"`
Author Author `xml:"author"`
}
func main() {
xmlFile, err := os.Open("post.xml")
if err != nil {
fmt.Println("Error opening XML file:", err)
return
}
defer xmlFile.Close()
decoder := xml.NewDecoder(xmlFile) ❶
for { ❷
t, err := decoder.Token() ❸
if err == io.EOF {
break
}
if err != nil {
fmt.Println("Error decoding XML into tokens:", err)
return
}
switch se := t.(type) { ❹
case xml.StartElement:
if se.Name.Local == "comment" {
var comment Comment
decoder.DecodeElement(&comment, &se) ❺
}
}
}
}
❶ 根据给定的XML 数据生成相应的解码器
❷ 每迭代一次解码器中的所有XML 数据
❸ 每进行一次迭代,就从解码器里面获取一个token
❹ 检查token 的类型
❺ 将XML 数据解码至结构
虽然这段代码只演示了如何解码comment
元素,但这种解码方式同样可以应用于XML文件中的其他元素。这个新的分析程序会通过Decoder
结构,一个元素接一个元素地对XML进行解码,而不是像之前那样,使用Unmarshal
函数一次将整个XML解封为字符串。
对XML进行解码首先需要创建一个Decoder
,这一点可以通过调用NewDecoder
并向其传递一个io.Reader
来完成。在上面展示的代码清单中,程序就把os.Open
打开的xmlFile
文件传递给了NewDecoder
。
在拥有了解码器之后,程序就会使用Token
方法来获取XML流中的下一个token:在这种情景下,token实际上就是一个表示XML元素的接口。为了从解码器里面取出所有token,程序使用一个无限for
循环包裹起了从解码器里面获取token的相关动作。当解码器包含的所有token都已被取出时,Token
方法将返回一个表示文件数据或数据流已被读取完毕的io.EOF
结构作为结果,并将返回值中的err
变量的值设置为nil
。
分析程序从解码器里取出token之后会对该token进行检查以确认其是否为StartElement
,也就是,判断该token是否为XML元素的起始标签。如果是的话,那么程序会继续对这个token进行检查,看它是否就是XML中的comment
元素。在确认了自己遇到的是comment
元素之后,程序就会将整个token解码至Comment
结构,从而得到与解封XML元素相同的结果。
因为手动解码XML文件需要做更多工作,所以这种方法并不适用于处理小型的XML文件。但如果程序面对的是流式XML数据,或者体积非常庞大的XML文件,那么解码将是从XML里提取数据唯一可行的办法。
在结束本小节并转向讨论如何创建XML之前,还有一点需要说明一下,那就是:本节介绍的分析规则只是XML分析规则的一部分,如果你想要更详细地了解这些规则,可以去查看xml
库的文档,或者直接阅读xml
库的源码。
在上一节中,我们花了不少时间学习如何分析XML,幸运的是,因为创建XML正好就是分析XML的逆操作,所以上一节介绍的知识在本节也是适用的。在上一节中,我们学习的是怎样把XML解封到结构里面,而这一节我们要学习的则是怎样把Go结构封装(marshal)至XML;同样,上一节我们学习的是怎样把XML解码至Go结构,而本节我们要学习的则是怎样把Go结构编码至XML,这个过程如图7-5所示。
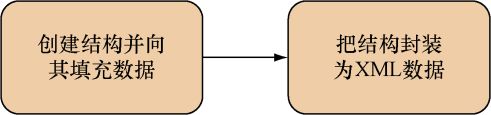
图7-5 使用Go创建XML:创建结构并将其封装至XML
首先让我们来看看封装操作是如何进行的。代码清单7-7展示了文件xml.go
包含的代码,这些代码会创建一个名为post.xml
的XML文件。
代码清单7-7 使用Marshal
函数生成XML文件
package main
import (
"encoding/xml"
"fmt"
"io/ioutil"
)
type Post struct {
XMLName xml.Name `xml:"post"`
Id string `xml:"id,attr"`
Content string `xml:"content"`
Author Author `xml:"author"`
}
type Author struct {
Id string `xml:"id,attr"`
Name string `xml:",chardata"`
}
func main() {
post := Post{
Id: "1",
Content: " Hello World!", ❶
Author: Author{
Id: "2",
Name: "Sau Sheong",
},
}
output, err := xml.Marshal(&post)
if err != nil { ❷
fmt.Println("Error marshalling to XML:", err)
return
}
err = ioutil.WriteFile("post.xml", output, 0644)
if err != nil {
fmt.Println("Error writing XML to file:", err)
return
}
}
❶创建结构并向里面填充数据
❷ 把结构封装为由字节切片组成的XML 数据
正如代码所示,封装XML和解封XML时使用的结构以及结构标签是完全相同的:封装操作只不过是把处理过程反转了过来,然后根据结构创建相应的XML罢了。封装程序首先需要创建表示帖子的post
结构,并向结构里面填充数据,然后只要调用Marshal
函数,就可以根据Post
结构创建相应的XML了。作为例子,下面就是Marshal
函数根据Post
结构创建出的XML数据,这些数据包含在了post.xml
文件里面:
<post id="1"><content>Hello World!</content><author id="2">Sau Sheong</author></post>
虽然样子并不是特别好看,但函数生成出来的的的确确就是一段XML。如果想要让程序生成更好看的XML,那么可以使用MarshalIndent
函数代替Marshal
函数:
output, err := xml.MarshalIndent(&post, "", "\t")
MarshalIndent
函数跟Marshal
函数一样,都接受一个指向结构的指针作为自己的第一个参数,但除此之外,MarshalIndent
函数还接受两个额外的参数,这两个参数分别用于指定添加到每个输出行前面的前缀以及缩进,其中缩进的数量会随着元素的嵌套层次增加而增加。在处理相同的Post
结构时,MarshalIndent
函数将产生以下更为美观的输出:
<post id="1">
<content>Hello World!</content>
<author id="2">Sau Sheong</author>
</post>
因为这段XML缺少了XML声明,所以从格式上来说这段XML并不完全正确。虽然xml
库不会自动为Marshal
或者MarshalIndent
生成的XML添加XML声明,但用户可以很轻易地通过xml.Header
常量将XML声明添加到封装输出之前:
err = ioutil.WriteFile("post.xml", []byte(xml.Header + string(output)), 0644)
通过把xml.Header
添加到输出结果之前,并将这些内容全部写入post.xml
文件,我们就得到了一段带有XML声明的XML:
<?xml version="1.0" encoding="UTF-8"?>
<post id="1">
<content>Hello World!</content>
<author id="2">Sau Sheong</author>
</post>
正如我们可以手动将XML解码到Go结构里面一样,我们同样可以手动将Go结构编码到XML里面,图7-6展示了这个过程,代码清单7-8则展示了一个简单的编码示例。

图7-6 使用Go创建XML:通过使用编码器来将结构编码至XML
代码清单7-8 手动将Go结构编码至XML
package main
import (
"encoding/xml"
"fmt"
"os"
)
type Post struct {
XMLName xml.Name `xml:"post"`
Id string `xml:"id,attr"`
Content string `xml:"content"`
Author Author `xml:"author"`
}
type Author struct {
Id string `xml:"id,attr"`
Name string `xml:",chardata"`
}
func main() {
post := Post{
Id: "1", ❶
Content: "Hello World!",
Author: Author{
Id: "2",
Name: "Sau Sheong",
},
}
xmlFile, err := os.Create("post.xml") ❷
if err != nil {
fmt.Println("Error creating XML file:", err)
return
}
encoder := xml.NewEncoder(xmlFile) ❸
encoder.Indent("", "\t")
err = encoder.Encode(&post) ❹
if err != nil {
fmt.Println("Error encoding XML to file:", err)
return
}
}
❶ 创建结构并向里面填充数据
❷ 创建用于存储数据的XML 文件
❸ 根据给定的XML 文件,创建出相应的编码器
❹ 把结构编码至文件
跟之前一样,程序首先创建了将要被编码的Post
结构,接着通过os.Create
创建出了将要写入的XML文件,然后使用NewEncoder
函数创建了一个包裹着XML文件的编码器。在设置好相应的前缀和缩进之后,程序就会使用编码器的Encode
方法对传入的Post
结构进行编码,最终创建出包含以下内容的post.xml
文件:
<post id="1">
<content>Hello World!</content>
<author id="2">Sau Sheong</author>
</post>
通过这一节的学习,读者应该已经了解了如何分析和创建XML。需要注意的是,本节讨论的只是分析和创建XML的基础知识,如果想要知道关于这方面的更多信息,可查看相应的文档以及源码(别担心,阅读源码并没有想象中那么可怕)。
JSON(JavaScript Object Notation)是衍生自JavaScript语言的一种轻量级的文本数据格式,这种格式的主要设计理念是既能够轻易地被人类读懂,又能够简单地被机器读取。JSON最初由Douglas Crockford定义,现在则由RFC 7159和ECMA-404描述。虽然接受和返回JSON数据并不是实现REST Web服务的唯一选择,但大多数REST Web服务都是这样做的。
在与REST Web服务打交道的时候,我们常常会以某种形式与JSON不期而遇,要么就是为了创建JSON,要么就是为了处理JSON,又或者两者皆有。处理JSON在Web应用中非常常见:无论是从Web服务里面获取数据,还是通过第三方身份验证服务登录Web应用,又或者对其他服务进行控制,通常都需要处理JSON数据。
跟处理JSON一样,创建JSON也非常常见:Go语言经常会被用于创建为前端应用提供服务的Web服务后端,其中就包括基于JavaScript的前端应用,而这些应用常常会运行着React.js和Angular.js这样的JavaScript库。除此之外,Go语言还会被用于为物联网以及诸如智能手表这样的可穿戴设备创建Web服务。因为在很多情况下,这些前端应用都是基于JSON开发的,所以它们与后端进行交互最自然的方式当然也是使用JSON。
正如Go语言提供对XML的支持一样,Go语言也通过encoding/json
库提供对JSON的支持。和上一节一样,我们首先会学习如何分析JSON,然后再学习如何创建JSON数据。
分析JSON的步骤和分析XML的步骤基本相同——分析程序首先要做的就是把JSON的分析结果存储到一些结构里面,然后通过访问这些结构来提取数据。下面是分析JSON的两个常见步骤(这个过程如图7-7所示):
图7-7 使用Go分析JSON:创建结构并将JSON解封到结构里面
(1)创建一些用于包含JSON数据的结构;
(2)通过json.Unmarshal
函数,把JSON数据解封到结构里面。
跟映射XML相比,把结构映射至JSON要简单得多,后者只有一条通用的规则:对于名字为<name>
的JSON键,用户只需要在结构里创建一个任意名字的字段,并将该字段的结构标签设置为'json:"<name>"',
就可以把JSON键<name>
的值存储到这个字段里面。接下来,就让我们来看一个实际的例子。
代码清单7-9展示了一个名为post.json
的JSON文件,我们接下来就要对这个文件进行分析。因为这个JSON文件包含的数据跟之前分析的XML文件包含的数据是相同的,所以这些数据对你来说应该不会感到陌生。
代码清单7-9 要分析的JSON文件
{
"id" : 1,
"content" : "Hello World!",
"author" : {
"id" : 2,
"name" : "Sau Sheong"
},
"comments" : [
{
"id" : 3,
"content" : "Have a great day!",
"author" : "Adam"
},
{
"id" : 4,
"content" : "How are you today?",
"author" : "Betty"
}
]
}
代码清单7-10展示了json.go文件
包含的代码,这些代码会分析post.json
文件,并将其包含的JSON数据解封至相应的结构。需要注意的是,除了结构标签之外,这个程序使用的结构跟之前分析XML时使用的结构并无不同。
代码清单7-10 JSON分析程序
package main
import (
"encoding/json"
"fmt"
"io/ioutil"
"os"
)
type Post struct {
Id int `json:"id"` ❶
Content string `json:"content"`
Author Author `json:"author"`
Comments []Comment `json:"comments"`
}
type Author struct {
Id int `json:"id"`
Name string `json:"name"`
}
type Comment struct {
Id int `json:"id"`
Content string `json:"content"`
Author string `json:"author"`
}
func main() {
jsonFile, err := os.Open("post.json")
if err != nil {
fmt.Println("Error opening JSON file:", err)
return
}
defer jsonFile.Close()
jsonData, err := ioutil.ReadAll(jsonFile)
if err != nil {
fmt.Println("Error reading JSON data:", err)
return
}
var post Post
json.Unmarshal(jsonData, &post) ❷
fmt.Println(post)
}
❶ 定义一些结构,用于表示数据
❷ 将JSON 数据解封至结构
为了将JSON键id
的值映射到Post
结构的Id
字段,程序将该字段的结构标签设置成了'json:"id"',
这种设置基本上就是将结构映射至JSON数据所需完成的全部工作。跟分析XML时一样,分析程序通过切片来嵌套多个结构,从而使一篇帖子可以包含零个或多个评论。除此之外,JSON的解封操作也跟XML的解封操作一样,都可以通过调用Unmarshal
函数来完成。
我们可以通过执行以下命令来运行这个JSON分析程序:
go run json.go
如果一切正常,应该会看到以下结果:
{1 Hello World! {2 Sau Sheong} [{3 Have a great day! Adam} {4 How are you today? Betty}]}
跟分析XML时一样,用户除了可以使用Unmarshal
函数来解封JSON,还可以使用Decoder
手动地将JSON数据解码到结构里面,以此来处理流式的JSON数据,图7-8以及代码清单7-11展示了这个过程的具体实现。

图7-8 使用Go分析JSON:将JSON解码至结构
代码清单7-11 使用Decoder
对JSON进行语言分析
jsonFile, err := os.Open("post.json")
if err != nil {
fmt.Println("Error opening JSON file:", err)
return
}
defer jsonFile.Close()
decoder := json.NewDecoder(jsonFile) ❶
for { ❷
var post Post
err := decoder.Decode(&post) ❸
if err == io.EOF {
break
}
if err != nil {
fmt.Println("Error decoding JSON:", err)
return
}
fmt.Println(post)
}
❶ 根据给定的JSON 文件,创建出相应的解码器
❷ 遍历JSON 文件,直到遇见EOF 为止
❸ 将JSON 数据解码至结构
通过调用NewDecoder
并传入一个包含JSON数据的io.Reader
,程序创建出了一个新的解码器。在把指向Post
结构的引用传递给解码器的Decode
方法之后,被传入的结构就会填充上相应的数据,然后这些数据就可以为程序所用了。当所有JSON数据都被解码完毕时,Decode
方法将会返回一个EOF
,而程序则会在检测到这个EOF
之后退出for
循环。
我们可以通过执行以下命令来运行这个JSON解码器:
go run json.go
如果一切正常,将会看到以下结果:
{1 Hello World! {2 Sau Sheong} [{1 Have a great day! Adam} {2 How are you today? Betty}]}
最后,在面对JSON数据时,我们可以根据输入决定使用Decoder
还是Unmarshal
:如果JSON数据来源于io.Reader
流,如http.Request
的Body
,那么使用Decoder
更好;如果JSON数据来源于字符串或者内存的某个地方,那么使用Unmarshal
更好。
正如上一个小节所示,分析JSON的方法和分析XML的方法是非常相似的。同样地,如图7-9所示,创建JSON的方法和创建XML的方法也是相似的。
图7-9 使用Go创建JSON:创建结构并将其封装为JSON数据
代码清单7-12展示了把Go结构封装为JSON数据的具体代码。
代码清单7-12 将结构封装为JSON
package main
import (
"encoding/json"
"fmt"
"io/ioutil"
)
type Post struct { ❶
Id int `json:"id"`
Content string `json:"content"`
Author Author `json:"author"`
Comments []Comment `json:"comments"`
}
type Author struct {
Id int `json:"id"`
Name string `json:"name"`
}
type Comment struct {
Id int `json:"id"`
Content string `json:"content"`
Author string `json:"author"`
}
func main() {
post := Post{
Id: 1,
Content: "Hello World!",
Author: Author{
Id: 2,
Name: "Sau Sheong",
},
Comments: []Comment{
Comment{
Id: 3,
Content: "Have a great day!",
Author: "Adam",
},
Comment{
Id: 4,
Content: "How are you today?",
Author: "Betty",
},
},
}
output, err := json.MarshalIndent(&post, "", "\t\t") ❷
if err != nil {
fmt.Println("Error marshalling to JSON:", err)
return
}
err = ioutil.WriteFile("post.json", output, 0644)
if err != nil {
fmt.Println("Error writing JSON to file:", err)
return
}
}
❶ 创建结构并向里面填充数据
❷ 把结构封装为由字节切片组成的JSON 数据
跟处理XML时的情况一样,这个封装程序使用的结构和之前分析JSON时使用的结构是相同的。程序首先会创建一些结构,然后通过调用MarshalIndent
函数将结构封装为由字节切片组成的JSON数据(json
库的MarshalIndent
函数和xml
库的MarshalIndent
函数的作用是类似的)。最后,程序会将封装所得的JSON数据存储到指定的文件中。
正如我们可以通过编码器手动创建XML一样,我们也可以通过编码器手动将Go结构编码为JSON数据,图7-10展示了这个过程。

图7-10 使用Go创建JSON数据:通过编码器把结构编码为JSON
代码清单7-13展示了json.go文件
中包含的代码,这些代码可以根据给定的Go结构创建相应的JSON文件。
代码清单7-13 使用Encoder
把结构编码为JSON
package main
import (
"encoding/json"
"fmt"
"io"
"os"
)
type Post struct { ❶
Id int `json:"id"`
Content string `json:"content"`
Author Author `json:"author"`
Comments []Comment `json:"comments"`
}
type Author struct {
Id int `json:"id"`
Name string `json:"name"`
}
type Comment struct {
Id int `json:"id"`
Content string `json:"content"`
Author string `json:"author"`
}
func main() {
post := Post{
Id: 1,
Content: "Hello World!",
Author: Author{
Id: 2,
Name: "Sau Sheong",
},
Comments: []Comment{
Comment{
Id: 3,
Content: "Have a great day!",
Author: "Adam",
},
Comment{
Id: 4,
Content: "How are you today?",
Author: "Betty",
},
},
},
jsonFile, err := os.Create("post.json") ❷
if err != nil {
fmt.Println("Error creating JSON file:", err)
return
}
encoder := json.NewEncoder(jsonFile) ❸
err = encoder.Encode(&post)
if err != nil { ❹
fmt.Println("Error encoding JSON to file:", err)
return
}
}
❶ 创建结构并向里面填充数据
❷ 创建用于存储数据的JSON 文件
❸ 根据给定的JSON文件创建出相应的编码器
❹ 把结构编码到JSON文件里面
跟之前一样,程序会创建一个用于存储JSON数据的JSON文件,并通过把这个文件传递给NewEncoder
函数来创建一个编码器。接着,程序会调用编码器的Encode
方法,并向其传递一个指向Post
结构的引用。在此之后,Encode
方法会从结构里面提取数据并将其编码为JSON数据,然后把这些JSON数据写入创建编码器时给定的JSON文件里面。
关于分析和创建XML和JSON的介绍到这里就结束了。虽然最近这两节介绍的内容可能会因为模式相似而显得有些乏味,但这些基础知识对于接下来的一节学习如何创建Go Web服务是不可或缺的,因此花时间学习和掌握这些知识是非常值得的。
创建Go Web服务并不是一件困难的事情:如果你仔细地阅读并理解了前面各个章节介绍的内容,那么掌握接下来要介绍的知识对你来说应该是轻而易举的。
本节将要构建一个简单的基于REST的Web服务,它允许我们对论坛帖子执行创建、获取、更新以及删除操作。具体来说,我们将会使用第6章介绍过的CRUD函数来包裹起一个Web服务接口,并通过JSON格式来传输数据。除了本章之外,后续的章节也会沿用这个Web服务作为例子,对其他概念进行介绍。
代码清单7-14展示了实现Web服务需要用到的数据库操作,这些操作和6.4节介绍过的操作基本相同,只是做了一些简化。这些代码定义了Web服务需要对数据库执行的所有操作,它们都隶属于main
包,并且被放置到了data.go文件
中。
代码清单7-14 使用data.go
访问数据库
package main
import (
"database/sql"
_ "github.com/lib/pq"
)
var Db *sql.DB
func init() { ❶
var err error
Db, err = sql.Open("postgres", "user=gwp dbname=gwp password=gwp sslmode=
disable")
if err != nil {
panic(err)
}
}
func retrieve(id int) (post Post, err error) { ❷
post = Post{}
err = Db.QueryRow("select id, content, author from posts where id = $1",
id).Scan(&post.Id, &post.Content, &post.Author)
return
}
func (post *Post) create() (err error) { ❸
statement := "insert into posts (content, author) values ($1, $2) returning
id"
stmt, err := Db.Prepare(statement)
if err != nil {
return
}
defer stmt.Close()
err = stmt.QueryRow(post.Content, post.Author).Scan(&post.Id)
return
}
func (post *Post) update() (err error) { ❹
_, err = Db.Exec("update posts set content = $2, author = $3 where id =
$1", post.Id, post.Content, post.Author)
return
}
func (post *Post) delete() (err error) { ❺
_, err = Db.Exec("delete from posts where id = $1", post.Id)
return
}
❶ 连接到数据库
❷ 获取指定的帖子
❸ 创建一篇新帖子
❹ 更新指定的帖子
❺ 删除指定的帖子
正如所见,这些代码跟前面代码清单6-6展示过的代码非常相似,只是在函数名和方法名上稍有区别,因此我们在这里就不再一一解释了。如果你需要重温一下这些代码的作用,那么可以去复习一下6.4节。
在拥有了对数据库执行CRUD操作的能力之后,让我们来学习一下如何实现真正的Web服务。代码清单7-15展示了整个Web服务的实现代码,这些代码保存在文件server.go
中。
代码清单7-15 定义在server.go文件
内的Go Web服务
package main
import (
"encoding/json"
"net/http"
"path"
"strconv"
)
type Post struct {
Id int `json:"id"`
Content string `json:"content"`
Author string `json:"author"`
}
func main() {
server := http.Server{
Addr: "127.0.0.1:8080",
}
http.HandleFunc("/post/", handleRequest)
server.ListenAndServe()
}
func handleRequest(w http.ResponseWriter, r *http.Request) { ❶
var err error
switch r.Method {
case "GET":
err = handleGet(w, r)
case "POST":
err = handlePost(w, r)
case "PUT":
err = handlePut(w, r)
case "DELETE":
err = handleDelete(w, r)
}
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
}
func handleGet(w http.ResponseWriter, r *http.Request) (err error) { ❷
id, err := strconv.Atoi(path.Base(r.URL.Path))
if err != nil {
return
}
post, err := retrieve(id)
if err != nil {
return
}
output, err := json.MarshalIndent(&post, "", "\t\t")
if err != nil {
return
}
w.Header().Set("Content-Type", "application/json")
w.Write(output)
return
}
func handlePost(w http.ResponseWriter, r *http.Request) (err error) { ❸
len := r.ContentLength
body := make([]byte, len)
r.Body.Read(body)
var post Post
json.Unmarshal(body, &post)
err = post.create()
if err != nil {
return
}
w.WriteHeader(200)
return
}
func handlePut(w http.ResponseWriter, r *http.Request) (err error) { ❹
id, err := strconv.Atoi(path.Base(r.URL.Path))
if err != nil {
return
}
post, err := retrieve(id)
if err != nil {
return
}
len := r.ContentLength
body := make([]byte, len)
r.Body.Read(body)
json.Unmarshal(body, &post)
err = post.update()
if err != nil {
return
}
w.WriteHeader(200)
return
}
func handleDelete(w http.ResponseWriter, r *http.Request) (err error) { ❺
id, err := strconv.Atoi(path.Base(r.URL.Path))
if err != nil {
return
}
post, err := retrieve(id)
if err != nil {
return
}
err = post.delete()
if err != nil {
return
}
w.WriteHeader(200)
return
}
❶ 多路复用器负责将请求转发给正确的处理器函数
❷ 获取指定的帖子
❸ 创建新的帖子
❹ 更新指定的帖子
❺ 删除指定的帖子
这段代码的结构非常直观:handleRequest
多路复用器会根据请求使用的HTTP方法,把请求转发给相应的CRUD处理器函数,这些函数都接受一个ResponseWriter
和一个Request
作为参数,并返回可能出现的错误作为函数的执行结果;handleRequest
会检查这些函数的执行结果,并在发现错误时通过StatusInternalServerError
返回一个500状态码。
接下来,让我们首先从帖子的创建操作开始,对Go Web服务的各个部分进行详细的解释,handlePost
函数如代码清单7-16所示。
代码清单7-16 用于创建帖子的函数
func handlePost(w http.ResponseWriter, r *http.Request) (err error) {
len := r.ContentLength
body := make([]byte, len) ❶❷
r.Body.Read(body)
var post Post
json.Unmarshal(body, &post) ❸
err = post.create() ❹
if err != nil {
return
}
w.WriteHeader(200)
return
}
❶ 读取请求主体,并将其存储在字节切片中; ❷创建一个字节切片
❸ 把切片存储的数据解封至Post 结构
❹ 创建数据库记录
handlePost
函数首先会根据内容的长度创建出一个字节切片,然后将请求主体记录的JSON字符串读取到字节切片里面。之后,函数会声明一个Post
结构,并将字节切片存储的内容解封到这个结构里面。这样一来,函数就拥有了一个填充了数据的Post
结构,于是它调用结构的Create
方法,把记录在结构中的数据存储到了数据库里面。
为了调用Web服务,我们需要用到第3章介绍过的cURL,并在终端中执行以下命令:
curl -i -X POST -H "Content-Type: application/json" -d '{"content":"My first
➥post","author":"Sau Sheong"}' http://127.0.0.1:8080/post/
这个命令首先会把Content-Type
首部设置为application/json
,然后通过POST
方法,向地址http://127.0.0.1/post/
发送一条主体为JSON字符串的HTTP请求。如果一切顺利,应该会看到以下结果:
HTTP/1.1 200 OK
Date: Sun, 12 Apr 2015 13:32:14 GMT
Content-Length: 0
Content-Type: text/plain; charset=utf-8
不过这个结果只能证明处理器函数在处理这个请求的时候没有发生任何错误,却无法说明帖子真的已经创建成功了。为了验证这一点,我们需要通过执行以下SQL查询来检视一下数据库:
psql -U gwp -d gwp -c "select * from posts;"
如果帖子创建成功了,应该会看到以下结果:
id | content | author
----+---------------+------------
1 | My first post | Sau Sheong
(1 row)
除了handlePost
函数之外,我们的Web服务的每个处理器函数都会假设目标帖子的id
已经包含在了URL里面。比如说,当用户想要获取一篇帖子时,Web服务接收到的请求应该指向以下URL:
/post/<id>
而这个URL中的<id>
记录的就是帖子的id
。代码清单7-17展示了函数是如何通过这一机制来获取帖子的。
代码清单7-17 用于获取帖子的函数
func handleGet(w http.ResponseWriter, r *http.Request) (err error) {
id, err := strconv.Atoi(path.Base(r.URL.Path))
if err != nil {
return
}
post, err := retrieve(id) ❶
if err != nil {
return
}
output, err := json.MarshalIndent(&post, "", "\t\t") ❷
if err != nil {
return
}
w.Header().Set("Content-Type", "application/json") ❸
w.Write(output)
return
}
❶ 从数据库里获取数据,并将其填充到Post 结构中
❷ 把Post 结构封装为JSON 字符串
❸ 把JSON 数据写入ResponseWriter
handleGet
函数首先通过path.Base
函数,从URL的路径中提取出字符串格式的帖子id
,接着使用strconv.Atoi
函数把这个id
转换成整数格式,然后通过把这个id
传递给retrivePost
函数来获得填充了帖子数据的Post
结构。
在此之后,程序通过json.MarshalIndent
函数,把Post
结构转换成了JSON格式的字节切片。最后,程序把Content-Type
首部设置成了application/json
,并把字节切片中的JSON数据写入ResponseWriter
,以此来将JSON数据返回给调用者。
为了观察handleGet
函数是如何工作的,我们需要在终端里面执行以下命令:
curl -i -X GET http://127.0.0.1:8080/post/1
这条命令会向给定的URL发送一个GET
请求,尝试获取id
为1
的帖子。如果一切正常,那么这条命令应该会返回以下结果:
HTTP/1.1 200 OK
Content-Type: application/json
Date: Sun, 12 Apr 2015 13:32:18 GMT
Content-Length: 69
{
"id": 1,
"content": "My first post",
"author": "Sau Sheong"
}
在更新帖子的时候,程序同样需要先获取帖子的数据,具体细节如代码清单7-18所示。
代码清单7-18 用于更新帖子的函数
func handlePut(w http.ResponseWriter, r *http.Request) (err error) {
id, err := strconv.Atoi(path.Base(r.URL.Path))
if err != nil {
return
}
post, err := retrieve(id) ❶
if err != nil {
return
}
len := r.ContentLength
body := make([]byte, len)
r.Body.Read(body) ❷
json.Unmarshal(body, &post) ❸
err = post.update() ❹
if err != nil {
return
}
w.WriteHeader(200)
return
}
❶ 从数据库里获取指定帖子的数据,并将其填充至Post 结构
❷ 从请求主体中读取JSON 数据
❸ 把JSON 数据解封至Post 结构
❹ 对数据库进行更新
在更新帖子时,handlePut
函数首先会获取指定的帖子,然后再根据PUT
请求发送的信息对帖子进行更新。在获取了帖子对应的Post
结构之后,程序会读取请求的主体,并将主体中的内容解封至Post
结构,最后通过调用Post
结构的update
方法更新帖子。
通过在终端里面执行以下命令,我们可以对之前创建的帖子进行更新:
curl -i -X PUT -H "Content-Type: application/json" -d '{"content":"Updated
➥post","author":"Sau Sheong"}' http://127.0.0.1:8080/post/1
需要注意的是,跟使用POST
方法创建帖子时不一样,这次我们需要通过URL来指定被更新帖子的ID。如果一切正常,这条命令应该会返回以下结果:
HTTP/1.1 200 OK
Date: Sun, 12 Apr 2015 14:29:39 GMT
Content-Length: 0
Content-Type: text/plain; charset=utf-8
现在,我们可以通过再次执行以下SQL查询来确认更新是否已经成功:
psql -U gwp -d gwp -c "select * from posts;"
如无意外,应该会看到以下内容:
id | content | author
----+--------------+------------
1 | Updated post | Sau Sheong
(1 row)
代码清单7-19展示了Web服务的帖子删除操作的实现代码,这些代码会先获取指定的帖子,然后通过调用delete
方法来删除帖子。
代码清单7-19 用于删除帖子的函数
func handleDelete(w http.ResponseWriter, r *http.Request) (err error) {
id, err := strconv.Atoi(path.Base(r.URL.Path))
if err != nil {
return
}
post, err := retrieve(id) ❶
if err != nil {
return
}
err = post.delete() ❷
if err != nil {
return
}
w.WriteHeader(200)
return
}
❶ 从数据库里获取指定帖子的数据,并将其填充至Post 结构
❷ 从数据库里删除这个帖子
注意,无论是更新帖子还是删除帖子,Web服务在操作执行成功时都会返回200状态码。但是,如果处理器函数在处理请求时出现了任何错误,那么该错误将被返回至handleRequest
多路复用器,然后由多路复用器向客户端返回一个500状态码。
通过执行下面的cURL调用,我们可以删除前面创建的帖子:
curl -i -X DELETE http://127.0.0.1:8080/post/1
如果一切正常,那么这个cURL调用将返回以下结果:
HTTP/1.1 200 OK
Date: Sun, 12 Apr 2015 14:38:59 GMT
Content-Length: 0
Content-Type: text/plain; charset=utf-8
现在,如果我们再次执行之前的SQL查询,就会发现之前创建的帖子已经不复存在了:
id | content | author
----+---------+--------
(0 rows)
[1] SOAP API的搜集结果可以通过访问 www.programmableweb.com/category/all/apis?data_format=21176 查看,而REST API的搜集结果可以通过访问www.programmableweb.com/category/all/apis?data_format= 21190查看。
[2] 具体化指的是将抽象的概念转换为实际的数据模型或对象。——译者注