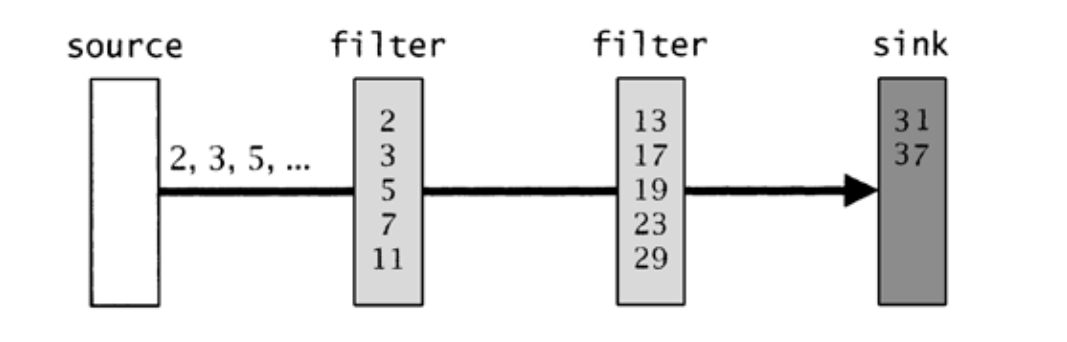
图20-1 素数筛
典型的C程序是顺序的,或者说是单线程 程序。即,程序中只有一个控制流。在执行时,程序的指令计数器(location counter)给出所执行的每条指令的地址。大多数时间,指令计数器给出的地址顺序前移,每次移动一个指令。偶而,跳转或调用指令会导致指令计数器变更为跳转目标地址或所调用函数的地址。指令计数器的值描绘出了一条穿越程序的路径,该路径描述了程序的执行,看起来像是穿过程序的一条线。
一个并发或多线程程序有一个以上的线程,而且在大多数情况下,这些线程至少在概念上是同时执行的。这种并发执行,使得编写多线程应用程序比编写单线程应用程序要复杂得多,因为线程间可能以不确定的方式彼此交互。本章中的三个接口导出了一些函数,可用于创建和管理线程、同步多个协作线程的操作、在线程间通信。
线程对具有内在并发活动的应用程序很有用。图形用户界面是个首要的例子,键盘输入、鼠标移动和点击、显示输出,所有这些活动都是同时发生的。在多线程系统中,可以为每个活动分别分配一个专用线程,无需考虑其他活动。这种方法有助于简化用户界面的实现,因为对这些线程中的每一个来说,除了少数必须与其他线程通信/同步的场合之外,都可以像顺序程序那样来设计和编写这些线程。
在多处理器计算机上,如果应用程序可以自然地分解为相对独立的子任务,那么使用线程可以提高性能。每个子任务在一个单独的线程中运行,所有子任务线程都并发地运行,因而比顺序执行各个子任务要快速。20.2节描述了一个使用这种方法的排序程序。
因为线程有状态 ,它们还可以帮助组织顺序程序的结构:线程包含足够的关联信息,使之可以停止执行,而后在停止处重新恢复执行。例如,典型的UNIX C语言编译器由三部分组成:一个单独的预处理器、一个专属的编译器和一个汇编器。预处理器读取源代码,将头文件包含进来,并展开宏,最后输出结果源代码,编译器读取并解析展开的源代码,生成代码并输出汇编语言,而汇编器读取汇编语言并输出目标码。这些阶段通常通过读写临时文件来彼此通讯。利用线程,每个阶段都可以作为单独的应用程序中的一个独立的线程来运行,这样就消除了临时文件,以及读、写、删除临时文件的开销。编译器本身也可能对词法分析器和语法解析器分别使用单独的线程。20.2节以计算素数为例,说明了在流水线中使用线程的这种用法。
一些系统并不是为多线程应用程序设计的,这限制了线程的用处。例如,大多数UNIX系统使用的是阻塞I/O原语。即当一个线程发出一个读请求时,该线程所属的UNIX进程以及进程中所有的线程都会阻塞,以等待该请求完成。在这些系统上,线程无法将计算与I/O进行重叠。对于信号处理,也有类似的结论。大多数UNIX系统将信号和信号处理程序关联到进程,而不是进程中的各个线程。
线程系统支持用户级 线程或内核级 线程,也可能二者均支持。用户级线程是完全在用户状态实现的,无需操作系统的帮助。用户级线程软件包,通常有一些如上文所述的缺点。从正面来说,用户级线程可以非常高效。下一节描述的Thread接口提供了用户级线程。
内核级线程使用了操作系统设施,以提供诸如非阻塞I/O和线程化信号处理之类(per-thread signal handling)的特性。较新的操作系统有内核级线程支持,可以用于提供线程接口。但这些接口中的一些操作需要系统调用,通常比用户级线程中的类似操作要花费更多代价。
即使在提供内核级线程的系统上,标准库仍然可能不是可重入的或线程安全的。可重入 的函数只修改局部变量和参数。改变全局变量或使用静态变量来保存中间结果的函数是不可重入 的。标准C库中一些函数的典型实现是不可重入的。如果不可重入的函数同时被多次调用 [1] ,函数可能以不可预测的方式修改这些中间值。在单线程程序中,多次调用同时存在,可能是因为直接和间接递归。在多线程程序中,出现多次调用,是因为不同线程可能同时调用同一函数。两个线程同时调用一个不可重入的函数,将修改同一存储区,其结果是未定义的。
线程安全 的函数使用同步机制来管理对共享数据的访问,因而有可能是可重入的或不可重入的。线程安全的函数可能被多个线程同时调用,而无需担忧同步问题。这使得多线程客户程序更容易使用它们,但其缺点是,即使单线程客户程序也需要为同步付出代价。
标准C语言并不要求库函数是可重入的或线程安全的,因此程序员必须作出最坏假定,使用同步原语来确保在任一时刻只有一个线程能访问某个不可重入的库函数。
本书中大部分函数都不是线程安全的,但是它们可重入的。少量函数是不可重入的,如Text_map,多线程客户程序必须自行解决同步问题。例如,如果几个线程共享一个Table_T实例,它们必须确保任一时刻只有一个线程能够对该Table_T实例调用Table接口中的函数,如下文所述。
一些线程接口是同时为用户级和内核级线程设计的。OSF(Open Software Foundation,开放软件基金会)的DCE(Distributed Computing Environment,分布式计算环境),在大多数UNIX变体、Open-VMS、OS/2、Windows NT和Windows 95上,都是可用的。通常,在宿主操作系统支持内核级线程的情况下,DCE线程使用内核级线程,否则,DCE线程实现为用户级线程。DCE线程接口包括50多个函数,比本章中三个接口合起来都大得多,但DCE接口能完成的功能更多。例如,其实现支持线程级信号,并通过适当的同步机制保护了对标准库函数的调用。
Sun公司(Sun Microsystems)的Solaris 2操作系统提供了一种二级线程设施。内核级线程称作轻量级线程(lightweight process),或LWP。UNIX的每个“重量级”进程都至少包含一个LWP,Solaris通过运行进程中的一个或多个LWP,来运行一个UNIX进程。对LWP的内核支持包括非阻塞I/O和LWP级别的信号。用户级线程通过类似Thread的一个接口提供,但比Thread要大一些,其实现在LWP之上运行用户级线程。一个LWP可以服务一个或多个用户级线程。Solaris在LWP之间复用处理器,而LWP本身则在用户级线程之间复用。
POSIX(Portable Operating Systems Interface,可移植操作系统接口)线程接口简称pthreads,它是作为指引性的标准线程接口出现的。大多数厂商现在都提供了pthreads实现,或许是基于他们自己的线程接口。例如,Sun公司使用Solaris 2的LWP来实现pthreads。pthreads的功能是Thread和Sem接口导出功能的一个超集。较大的POSIX线程接口处理了线程级信号,包括几种同步机制,并规定标准C库函数必须是线程安全的。
本章中的三个接口都比较小。之所以将其划分为独立的接口,是因为其中每个接口都有一个彼此相关但截然不同的目的。
理论上,所有的运行线程都是并发执行的,但实际上,线程数目通常大于真实的处理器数目。因而,处理器是根据某种调度策略在运行线程之间复用的。在非抢占调度 (nonpreemptive scheduling)的情况下,运行线程可以执行一个函数,使之变为阻塞状态,或放弃当前占用的处理器。在启用抢占调度 (preemptive scheduling)时,运行线程将隐式放弃占用的处理器。该策略通常利用时钟中断实现,时钟中断将周期性地中断运行线程,并将其处理器分配给其他运行线程。时间片 是运行线程在被抢占之前所运行时间的数量,当被抢占时,上下文切换 将挂起当前线程并恢复另一个(或许是同一个)运行线程。在非抢占调度的情况下,当运行线程阻塞时,也会发生上下文切换。在接口实现支持抢占的情况下,Thread接口将使用抢占调度机制。
原子操作 (atomic action)的执行不会被抢占。开始执行一个原子操作的线程,在完成该操作前,不会被另一个线程打断。如果线程调用了一个原子函数,该调用的执行不会被打断。本章中描述的大多数函数都必须是原子的,这样才能使其结果和作用具有可预测性。但原子函数是可以阻塞的,Sem接口中的同步函数就是这样的例子。
前两段的内容表明,并发程序设计有自身的一些术语,而且经常用不同术语表示同一概念。例如,线程可能叫做轻量级线程、任务(task)、子任务(subtask)、或微任务(microtask),同步机制可能称为事件(event)、条件变量(condition variable)、同步资源(synchronizing resource)和消息(message)。
Thread接口导出了一个异常和支持创造线程的函数。
〈thread.h
〉≡
#ifndef THREAD_INCLUDED
#define THREAD_INCLUDED
#include "except.h"
#define T Thread_T
typedef struct T *T;
extern const Except_T Thread_Failed;
extern const Except_T Thread_Alerted;
extern int Thread_init (int preempt, ...);
extern T Thread_new (int apply(void *),
void *args, int nbytes, ...);
extern void Thread_exit (int code);
extern void Thread_alert(T t);
extern T Thread_self (void);
extern int Thread_join (T t);
extern void Thread_pause(void);
#undef T
#endif
对该接口中所有这些函数的调用都是原子的。
Thread_init初始化线程系统,必须在调用任何其他函数之前调用。调用Thread_init多次,或在调用Thread_init之前调用Thread、Sem和Chan接口中任何其他函数,都会造成已检查的运行时错误。
如果preempt为0,Thread_init将线程系统初始化为只支持非抢占调度,并返回1。如果preempt为1,线程系统将初始化为支持抢占调度。如果系统支持抢占调度,Thread_init将返回1。否则,系统将初始化为非抢占调度,Thread_init返回0。
通常的客户程序在main函数中初始化线程系统。例如,对于需要抢占调度的客户程序来说,main函数通常为如下形式。
int main(int argc, char *argv[]) {
int preempt;
...
preempt = Thread_init(1, NULL);
assert(preempt == 1);
...
Thread_exit(EXIT_SUCCESS);
return EXIT_SUCCESS;
}
Thread_init还可以接受与实现相关的额外参数,通常以“名称—值”对的形式指定。例如,对于支持优先级的实现来说,
preempt = Thread_init(1, "priorities", 4, NULL);
可以将线程系统初始化为具有四个优先级。通常忽略未知的可选参数。使用这种方法的实现,通常要求用NULL指针作为结束参数。
如上述的代码模板所示,线程必须通过调用Thread_exit结束执行。整型参数是一个退出代码,很像是传递给标准库的exit函数的参数。如果有其他线程在等待调用该函数的线程结束,那么这些线程会得到该退出代码,下文将解释这一点。如果系统中只有一个线程,调用Thread_exit等效于调用exit。
Thread_new创建了一个新线程并返回其线程句柄 ,这是一个不透明指针。线程句柄将会传递给Thread_join和Thread_alert函数,Thread_self会返回线程句柄。新线程的运行独立于创建它的线程。在新线程开始执行时,它会执行等效于下述形式的代码:
void *p = ALLOC(nbytes); memcpy(p, args, nbytes); Thread_exit(apply(p));
即会针对args指向的nbytes字节的一个副本 ,来调用apply,系统假定args指向新线程的参数数据。args通常是指向一个结构实例的指针,结构的字段保存了apply的参数,nbytes是该结构的长度。新线程开始执行时,异常栈为空:它并不 继承调用线程中通过TRY-EXCEPT语句建立的异常状态。异常是特定于线程的,在一个线程中执行的TRY-EXCEPT语句无法影响另一个线程中的异常。
如果args不是NULL,而nbytes为0,新线程将执行下述代码的等价形式:
Thread_exit(apply(args));
即会不加修改地将args传递给apply。如果args是NULL,新线程执行下述代码的等价形式:
Thread_exit(apply(NULL));
如果apply是NULL,或args不是NULL且nbytes为负值,则造成已检查的运行时错误。如果args是NULL,则忽略nbytes。
类似于Thread_init,Thread_new也可以有特定于实现的额外参数,通常以“名称—值”对的形式指定。例如:
Thread_T t; t = Thread_new(apply, args, nbytes, "priority", 2, NULL);
上述代码创建了一个优先级为2的新线程。如本例所示,可选参数(的列表)应该以NULL指针结束。
线程的创建是同步 的:在新线程已经创建并接收其参数之后,Thread_new将返回,但此时新线程可能并未开始执行。如果Thread_new因为资源限制无法创建新线程,则引发Thread_Failed异常。例如,线程系统的实现可能会限制同时存在的线程数目,在超出该限制时,Thread_new将引发Thread_Failed异常。
线程调用Thread_exit(code)函数后,将结束该线程的执行。此后,(借助于Thread_join)等待该线程结束的线程将恢复执行,code的值将作为调用Thread_join的结果返回给这些恢复执行的线程。在最后一个线程调用Thread_exit时,整个程序通过调用exit(code)结束。
Thread_join(t)导致调用线程暂停执行,直至线程t通过调用Thread_exit结束。在线程t结束时,调用Thread_join的线程将恢复执行,Thread_join将返回线程t传递给Thread_exit的整型参数。如果t指定了一个不存在的线程,Thread_join立即返回-1。作为一个特例,调用Thread_join(NULL)将等待所有 线程结束,包括那些可能由其他线程创建的线程。在这种情况下,Thread_join将返回0。如果用非NULL的t指定调用Thread_join的线程本身,或有多个线程指定的t值为NULL,则造成已检查的运行时错误。Thread_join可能引发Thread_Alerted异常。
Thread_self返回调用线程的线程句柄。
Thread_pause导致调用线程放弃处理器,使得另一个就绪线程(如果有的话)可以在该处理器上执行。Thread_pause主要用于非抢占调度,对于抢占调度,没有必要调用Thread_pause。
线程有三种状态:运行、阻塞和死亡。新线程开始时为运行状态。如果它调用了Thread_join,则变为阻塞状态,等待另一个线程结束执行。当一个线程调用Thread_exit时,它变为死亡状态。当线程调用由Chan导出的通讯函数或Sem导出的同步函数时,也可能变为阻塞状态。如果没有运行线程,则为已检查的运行时错误。
Thread_alert(t)将设置t的“警报—待决”标志。如果t阻塞,Thread_alert将使t变为可运行,并使之清除其警报—待决标志,并在下一次运行时引发Thread_Alerted异常。如果t已经是运行状态,Thread_alert将使t清除其标志并在下一次调用Thread_join或可以导致阻塞通信或同步函数时引发Thread_Alerted异常。如果传递给Thread_alert的线程句柄为NULL,或指向一个不存在的线程,则造成已检查的运行时错误。
无法结束一个正在运行的线程,线程必须结束本身,或者通过调用Thread_exit,或者通过响应Thread_Alerted。如果一个线程并不捕获Thread_Alerted异常,整个程序将由于未捕获的异常错误而结束。响应Thread_alert异常最常见的方式是结束线程,这可以通过下述一般形式的apply函数完成。
int apply(void *p) {
TRY
...
EXCEPT(Thread_Alerted)
Thread_exit(EXIT_FAILURE);
END_TRY;
Thread_exit(EXIT_SUCCESS);
}
TRY-EXCEPT语句必须由线程本身执行。如下的代码
Thread_T t;
TRY
t = Thread_new(...);
EXCEPT(Thread_Alerted)
Thread_exit(EXIT_FAILURE);
END_TRY;
Thread_exit(EXIT_SUCCESS);
是不正确的,因为其中的TRY-EXCEPT应用到调用线程,而非新线程。
一般信号量,或计数信号量,是底层同步原语。理论上,信号量是一个受保护的整数,可以原子化地加1和减1。可以对一个信号量s进行的两个操作是wait和signal。signal(s)在逻辑上相当于将s原子化地加1。wait(s)等待s变为正数,然后将其原子化地减1:
while (s <= 0)
;
s = s - 1;
当然,实际的实现会导致调用线程阻塞,并不像上述解释那样进行循环。
Sem接口将计数器封装在一个结构中,导出一个初始化函数和两个同步函数:
〈sem.h 〉≡ #ifndef SEM_INCLUDED #define SEM_INCLUDED #define T Sem_T typedef struct T { int count; void *queue; } T; 〈exported macros 300〉 extern void Sem_init (T *s, int count); extern T *Sem_new (int count); extern void Sem_wait (T *s); extern void Sem_signal(T *s); #undef T #endif
一个信号量,就是指向一个Sem_T结构实例的指针。该接口揭示了Sem_T实例的内部结构,但只有这样,才能静态分配Sem_T实例,或将其嵌入到其他结构中。客户程序必须将Sem_T作为不透明类型处理,只能通过该接口中的函数存取Sem_T实例中的字段,直接访问Sem_T的字段,属于未检查的运行时错误。向该接口中任何函数传递的Sem_T指针为NULL,都是已检查的运行时错误。
Sem_init的参数包括指向一个Sem_T实例的指针,和计数器的初始值,该函数接下来初始化信号量的数据结构并将其计数器设置为指定的初始值。在初始化后,指向该Sem_T的指针即可传递给两个同步函数。在同一信号量上调用Sem_init多次,属于未检查的运行时错误。
Sem_new等效于下述代码的原子形式:
Sem_T *s; NEW(s); Sem_init(s, count);
Sem_new可能引发Mem_Failed异常。
Sem_wait接受一个指向Sem_T实例的指针作为参数,并等待其计数器变为正数,而后将其计数器减1并返回。该操作是原子的。如果调用线程的警报—待决标志已经设置,Sem_wait将立即引发Thread_Alerted异常,而不会将计数器减1。如果警报—待决标志是在线程阻塞期间设置的,那么该线程将停止等待并引发Thread_Alerted异常,而不会将计数器减1。在调用Thread_init之前调用Sem_wait,是已检查的运行时错误。
Sem_signal接受一个指向Sem_T实例的指针作为参数,并将Sem_T中的计数器原子化地加1。如果有其他线程在等待计数器变为正数,而Sem_signal操作刚好使计数器变为正数,那么其中某个线程将完成对Sem_wait的调用。在调用Thread_init之前调用Sem_wait,是已检查的运行时错误。
向Sem_wait或Sem_signal传递未初始化的信号量,是未检查的运行时错误。
Sem_wait和Sem_signal操作中隐含的队列机制是先进先出的,而且它是公平的。即,如果有某个线程t阻塞在一个信号量s上,那么与其他在t之后调用Sem_wait(&s)阻塞的线程相比,线程t将先于这些线程恢复执行。
二值信号量,或互斥量 ,也是一个一般信号量,但其计数器为0或1。互斥量用于实现互斥。例如,
Sem_T mutex;
Sem_init(&mutex, 1);
...
Sem_wait(&mutex);
statements
Sem_signal(&mutex);
上述代码创建并初始化一个二值信号量,使用它来确保每次只有一个线程能够执行statements ,这是临界区 (critical region)的一个例子。
这种惯用法是如此之常见,以至于Sem接口为此导出了宏,实现了下述语法形式的LOCK-END_LOCK语句:
LOCK(mutex ) statements END_LOCK
其中mutex 是一个二值信号量,计数器初始化为1。LOCK语句有助于避免在临界区末尾忘记调用Sem_signal,这种错误常见且易导致严重的问题,也有助于避免用错误的信号量调用Sem_signal。
〈exported macros
300〉≡
#define LOCK(mutex) do { Sem_T *_yymutex = &(mutex); \
Sem_wait(_yymutex);
#define END_LOCK Sem_signal(_yymutex); } while (0)
如果statements 可能引发异常,那么不能使用LOCK-END_LOCK,因为如果发生异常,互斥量不会被释放。在这种情况下,正确的惯用法是
TRY
Sem_wait(&mutex);
statements
FINALLY
Sem_signal(&mutex);
END_TRY;
FINALLY子句确保,无论是否发生异常,互斥量都会被释放。一个合理的备选方案是,将这种惯用法合并到LOCK和END_LOCK定义中,但这样会导致,在每次使用LOCK-END_LOCK时,都会带来TRY-FINALLY语句的开销。
互斥量通常嵌入到ADT中,使得能够以线程安全的方式访问ADT。例如,
typedef struct {
Sem_T mutex;
Table_T table;
} Protected_Table_T;
该代码将一个互斥量与一个表关联起来。下述代码
Protected_Table_T tab; tab.table = Table_new(...); Sem_init(&tab.mutex, 1);
创建了一个受保护的表,而
LOCK(tab.mutex)
value = Table_get(tab.table, key);
END_LOCK;
可以从原子化地取得与key关联的值。请注意,LOCK宏的参数是互斥量本身,而非其地址。由于Table_put可能引发Mem_Failed异常,向tab添加数据的操作,应该由如下的代码进行:
TRY
Sem_wait(&tab.mutex);
Table_put(tab.table, key, value);
FINALLY
Sem_signal(&tab.mutex);
END_TRY;
Chan接口提供了同步通信通道,可用于在线程之间传递数据。
〈chan.h
〉≡
#ifndef CHAN_INCLUDED
#define CHAN_INCLUDED
#define T Chan_T
typedef struct T *T;
extern T Chan_new (void);
extern int Chan_send (T c, const void *ptr, int size);
extern int Chan_receive(T c, void *ptr, int size);
#undef T
#endif
Chan_new创建、初始化并返回一个新的通道,这是一个指针。Chan_new可能引发Mem_Failed异常。
Chan_send的参数包括一个通道,一个指针指向保存即将发送数据的缓冲区,以及缓冲区包含的字节数。调用线程会阻塞,直至另一个线程对同一通道调用Chan_receive,当这样的两个线程“会合”时,数据从发送方复制到接收方,两个调用分别返回。Chan_send返回接收方接受的字节数。
Chan_receive的参数包括一个通道,一个指针指向用于接收数据的缓冲区,以及该缓冲区能容纳的最大字节数。调用者会阻塞,直至另一个线程对同一通道调用Chan_send,当两个线程“会合”时,数据从发送方复制到接收方,两个调用分别返回。如果发送方提供的数据多于size字节,过多的字节将丢弃。Chan_receive返回接受的字节数。
Chan_send和Chan_receive都可以接受size为0的情形。向这两个函数传递的Chan_T值为NULL、ptr为NULL或size值为负数,都是已检查的运行时错误。如果调用线程的警报—待决标志已经设置,Chan_send和Chan_receive都会立即引发Thread_Alerted异常。如果警报—待决标志是在线程阻塞期间设置的,线程将停止等待并引发Thread_Alerted异常。在这种情况下,数据可能已经传输,也可能尚未传输。
在调用Thread_init之前调用该接口中的任何函数,都是已检查的运行时错误。
本节中的三个程序,说明了对线程和通道的简单用法,以及使用信号量实现互斥的用法。Chan接口的实现在下一节详述,这是使用信号量实现同步的一个例子。
在抢占调度的情况下,线程是并发执行的,至少在概念上是这样。一组协作线程可以分别处理同一问题的各个部分。在多处理器系统上,这种方法利用并发性来减少整体的执行时间。当然,在单处理器系统上,这种程序实际上会运行得慢一点,这是由于在线程之间切换的开销造成的。但是,这种方法确实说明了Thread接口的用法。
排序是一个很容易分解为各个部分解决的问题。sort生成指定数目的随机整数,并发地排序它们,并检查确认结果已经排序:
〈sort.c 〉≡ #include <stdlib.h> #include <stdio.h> #include <time.h> #include "assert.h" #include "fmt.h" #include "thread.h" #include "mem.h" 〈sort types 303〉 〈sort data 304〉 〈sort functions 303〉 main(int argc, char *argv[]) { int i, n = 100000, *x, preempt; preempt = Thread_init(1, NULL); assert(preempt == 1); if (argc >= 2) n = atoi(argv[1]); x = CALLOC(n, sizeof (int)); srand(time(NULL)); for (i = 0; i < n; i++) x[i] = rand(); sort(x, n, argc, argv); for (i = 1; i < n; i++) if (x[i] < x[i-1]) break; assert(i == n); Thread_exit(EXIT_SUCCESS); return EXIT_SUCCESS; }
time、srand和rand都是标准C库函数。time返回日历时间的某种整数编码,而srand使用该值来设置随机数种子,以用于生成一个伪随机数序列。后续对rand的调用,返回了该序列中的数字。sort首先用n个随机数填充x[0..n - 1]。
sort函数是快速排序的一个实现。教科书对快速排序的实现,首先通过一个“基准”值将数组划分为两个子数组,然后递归调用自身来分别排序每个子数组。当子数组为空时,递归降至最低点。
void quick(int a[], int lb, int ub) {
if (lb < ub) {
int k = partition(a, lb, ub);
quick(a, lb, k - 1);
quick(a, k + 1, ub);
}
}
void sort(int *x, int n, int argc, char *argv[]) {
quick(x, 0, n - 1);
}
partition(a, i, j)任意地选择a[i]作为基准值。它重排a[i..j],使得a[i..k - 1]中所有的值都小于或等于基准v,而a[k+1..j]中所有的值都大于v,a[k]的值为v。
〈sort functions
303〉≡
int partition(int a[], int i, int j) {
int v, k, t;
j++;
k = i;
v = a[k];
while (i < j) {
i++; while (a[i] < v && i < j) i++;
j--; while (a[j] > v ) j--;
if (i < j) { t = a[i]; a[i] = a[j]; a[j] = t; }
}
t = a[k]; a[k] = a[j]; a[j] = t;
return j;
}
partition中最后的交换,将v值置于a[k]中,partition返回k。
对quick的递归调用可以由独立的线程并发地执行。首先,quick的参数必须打包到一个结构中,这样quick可以将其传递给Thread_new:
〈sort types 303〉≡ struct args { int *a; int lb, ub; }; 〈sort functions 303〉+≡ int quick(void *cl) { struct args *p = cl; int lb = p->lb, ub = p->ub; if (lb < ub) { int k = partition(p->a, lb, ub); 〈quick 304〉 } return EXIT_SUCCESS; }
递归调用将在独立的线程中执行,但仅当子数组中元素数目足够时,才值得这样做。例如,对子数组a[lb..k-1]的排序如下:
〈quick
304〉≡
p->lb = lb;
p->ub = k - 1;
if (k - lb > cutoff) {
Thread_T t;
t = Thread_new(quick, p, sizeof *p, NULL);
Fmt_print("thread %p sorted %d..%d\n", t, lb, k - 1);
} else
quick(p);
其中cutoff指定了一个阈值,仅当需要排序的元素数目大于该阈值时,才会在独立线程中排序该子数组。类似地,对子数组a[k+1..ub]的排序如下:
〈quick
304〉+≡
p->lb = k + 1;
p->ub = ub;
if (ub - k > cutoff) {
Thread_T t;
t = Thread_new(quick, p, sizeof *p, NULL);
Fmt_print("thread %p sorted %d..%d\n", t, k + 1, ub);
} else
quick(p);
sort首先调用quick,随着排序过程的进展,quick又衍生出许多线程,sort接下来调用Thread_join等待所有这些线程结束:
〈sort data 304〉≡ int cutoff = 10000; 〈sort functions 303〉+≡ void sort(int *x, int n, int argc, char *argv[]) { struct args args; if (argc >= 3) cutoff = atoi(argv[2]); args.a = x; args.lb = 0; args.ub = n - 1; quick(&args); Thread_join(NULL); }
用n和cutoff的默认值100 000和10 000来执行sort,会衍生出18个线程:
% sort
thread 69f08 sorted 0..51162
thread 6dfe0 sorted 51164..99999
thread 72028 sorted 51164..73326
thread 76070 sorted 73328..99999
thread 6dfe0 sorted 51593..73326
thread 72028 sorted 73328..91415
thread 7a0b8 sorted 51593..69678
thread 7e100 sorted 73328..83741
thread 82148 sorted 3280..51162
thread 69f08 sorted 73328..83614
thread 7e100 sorted 51593..67132
thread 6dfe0 sorted 7931..51162
thread 69f08 sorted 14687..51162
thread 6dfe0 sorted 14687..37814
thread 72028 sorted 37816..51162
thread 69f08 sorted 15696..37814
thread 6dfe0 sorted 15696..26140
thread 76070 sorted 26142..37814
不同的执行会排序不同的值,因此,每次执行时创建线程的数目和quick输出的跟踪记录也有所不同。
sort有一个重要的bug:它未能保护quick中对Fmt_print的调用。Fmt_print不保证是可重入的,C库中许多例程都是不可重入的。如果线程被中断,而后又恢复执行,则不能保证printf或任何其他库例程能正确地工作。
在抢占系统中,任何可以由多个线程访问的数据都必须受到保护。访问必须被限制在临界区中进行,每次只有一个线程允许进入临界区。spin是一个简单的例子,说明了访问共享数据的正确和错误方式。
〈spin.c 〉≡ #include <stdio.h> #include <stdlib.h> #include "assert.h" #include "fmt.h" #include "thread.h" #include "sem.h" #define NBUMP 30000 〈spin types 306〉 〈spin functions 306〉 int n; int main(int argc, char *argv[]) { int m = 5, preempt; preempt = Thread_init(1, NULL); assert(preempt == 1); if (argc >= 2) m = atoi(argv[1]); n = 0; 〈increment n unsafely 306〉 Fmt_print("%d == %d\n", n, NBUMP*m); n = 0; 〈increment n safely 307〉 Fmt_print("%d == %d\n", n, NBUMP*m); Thread_exit(EXIT_SUCCESS); return EXIT_SUCCESS; }
spin衍生m个线程,每个线程都对n加1达NBUMP次。前m个线程并不确保对n的加1操作是原子化的:
〈increment n unsafely 306〉≡ { int i; for (i = 0; i < m; i++) Thread_new(unsafe, &n, 0, NULL); Thread_join(NULL); }
main启动m个线程,每个线程都用指向n的双重指针调用unsafe:
〈spin functions
306〉≡
int unsafe(void *cl) {
int i, *ip = cl;
for (i = 0; i < NBUMP; i++)
*ip = *ip + 1;
return EXIT_SUCCESS;
}
unsafe是错误的,因为*ip = *ip + 1的执行可能被中断。如果刚好在获取*ip的值之后被中断,而同时其他线程对*ip执行了加1操作,那么赋值给*ip的值将是不正确的。
第二批的m个线程都调用下述代码:
〈spin types 306〉≡ struct args { Sem_T *mutex; int *ip; }; 〈spin functions 306〉+≡ int safe(void *cl) { struct args *p = cl; int i; for (i = 0; i < NBUMP; i++) LOCK(*p->mutex) *p->ip = *p->ip + 1; END_LOCK; return EXIT_SUCCESS; }
safe确保每次只有一个线程能执行临界区,即语句*ip = *ip + 1。main初始化了一个二值信号量,所有线程都使用该信号量来进入safe中的临界区:
〈increment n safely 307〉≡ { int i; struct args args; Sem_T mutex; Sem_init(&mutex, 1); args.mutex = &mutex; args.ip = &n; for (i = 0; i < m; i++) Thread_new(safe, &args, sizeof args, NULL); Thread_join(NULL); }
任意时刻都可能发生抢占,因此spin每次执行时,使用unsafe的线程都可能产生不同的结果:
% spin 87102 == 150000 150000 == 150000 % spin 148864 == 150000 150000 == 150000
最后一个例子说明了一个通过通信通道实现的流水线。sieve N计算并输出小于或等于N的素数。例如:
% sieve
100
2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73
79 83 89 97
sieve实现了著名的埃拉托逊斯筛法(Sieve of Eratosthenes)用于计算素数,其中每个“筛子”都是一个线程,用于丢弃某个指定素数的倍数。通道用于连接这些线程以形成流水线,如图20-1所示。源线程(白色方框)生成2以及后续的奇数,并将其顺流水线向下传输。source和sink(暗灰色方框)之间的过滤器(浅灰色方框)用于丢弃指定素数的倍数,并将其他数字沿流水线向下传输。sink也过滤出素数,不过如果一个数通过了sink的过滤器,那么它就是素数。图20-1中的每个方框都是一个线程,每个方框中的数字都是与该线程关联的素数,方框之间形成流水线的线则是通道。
有n个素数关联到sink和每个filter。当sink累积了n个素数时(图20-1中n为5),它会衍生出自身的一个副本,将自身转化为一个filter。图20-2说明了sieve如何扩展,以计算出100以内的素数。
图20-1 素数筛
在sieve初始化线程系统之后,它为source和sink创建线程,用一个新的通道连接它们,并退出:
〈sieve.c 〉≡ #include <stdio.h> #include <stdlib.h> #include "assert.h" #include "fmt.h" #include "thread.h" #include "chan.h" struct args { Chan_T c; int n, last; }; 〈sieve functions 308〉 int main(int argc, char *argv[]) { struct args args; Thread_init(1, NULL); args.c = Chan_new(); Thread_new(source, &args, sizeof args, NULL); args.n = argc > 2 ? atoi(argv[2]) : 5; args.last = argc > 1 ? atoi(argv[1]) : 1000; Thread_new(sink, &args, sizeof args, NULL); Thread_exit(EXIT_SUCCESS); return EXIT_SUCCESS; }
source向其“输出”通道输出整数,通道是通过args结构的c字段传递给source的,这也是source所需的唯一字段:
〈sieve functions
308〉≡
int source(void *cl) {
struct args *p = cl;
int i = 2;
if (Chan_send(p->c, &i, sizeof i))
for (i = 3; Chan_send(p->c, &i, sizeof i); )
i += 2;
return EXIT_SUCCESS;
}
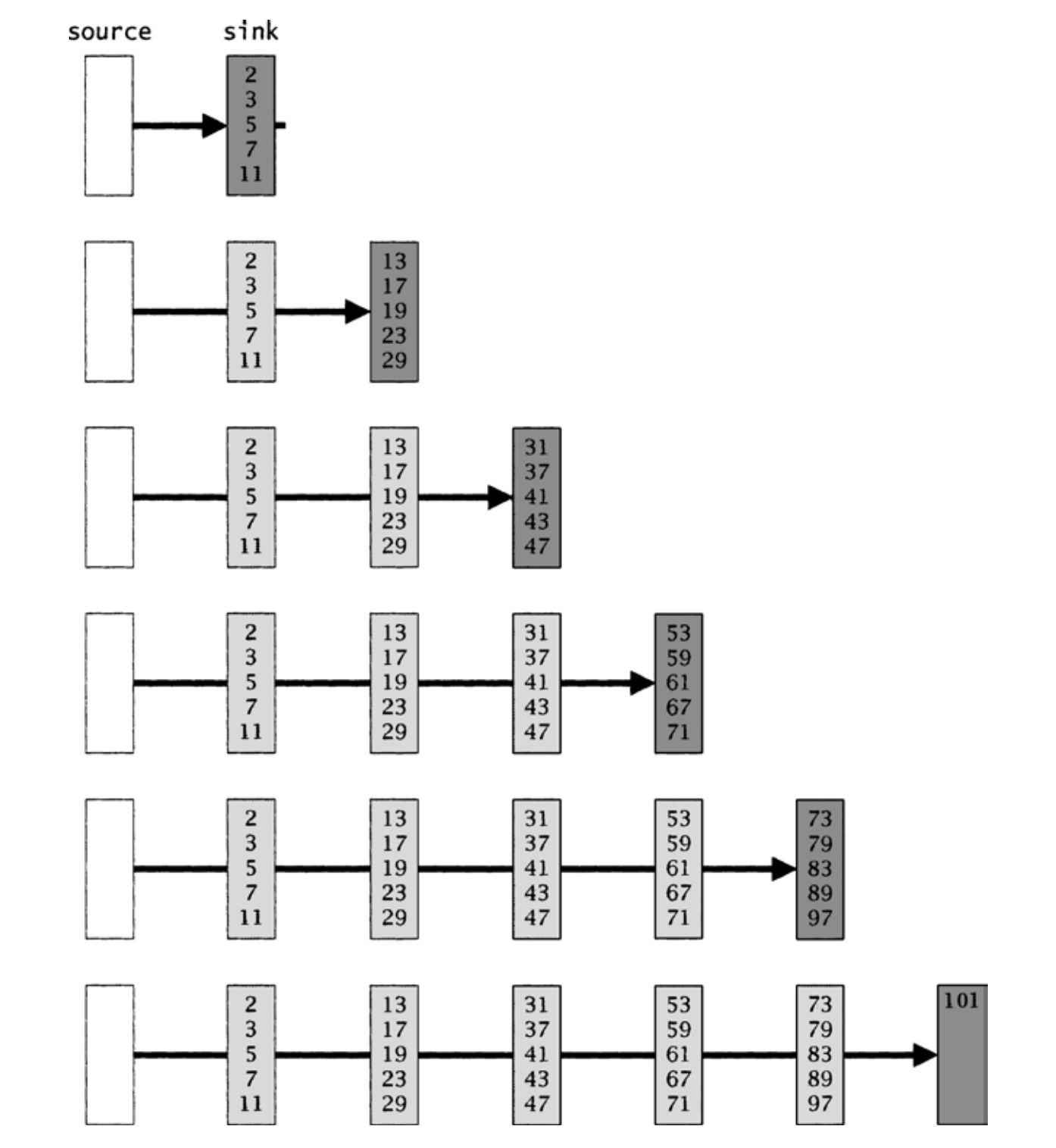
图20-2 用以计算100以内的素数的sieve的变化
只要有接收方接受,source就会发送2和后续的奇数。在sink输出所有素数后,则向Chan_Receive传递0作为缓冲区长度参数,这会通知其上游的过滤器工作已经完成,sink就此结束。每个filter都具有类似的行为,直至source确认其接收方读取到零字节为止,此时source线程将结束。
filter从其输入通道读取整数,并将可能的素数写到输出通道,直至接收该输出的线程不再接收为止。
〈sieve functions 308〉+≡ void filter(int primes[], Chan_T input, Chan_T output) { int j, x; for (;;) { Chan_receive(input, &x, sizeof x); 〈x is a multiple of primes[0...] 310〉 if (primes[j] == 0) if (Chan_send(output, &x, sizeof x) == 0) break; } Chan_receive(input, &x, 0); }
primes[0..n-1]包含了与一个filter相关联的素数。该数组以整数0结尾,因此,进行搜索的循环体会遍历primes,直至判断出x不是素数,或者遇到数组的结束符:
〈x is a multiple of
primes[0...] 310〉≡
for (j = 0; primes[j] != 0 && x%primes[j] != 0; j++)
;
如上述代码所示,当遇到表示数组结束的0时,搜索失败。在这种情况下,x可能 是素数,因此需要将其通过输出通道发送给另一个filter或sink。
所有的操作都在sink中,args的c字段包含了sink的输入通道,n字段给出了各个filter中素数的数目,last字段包含了N,即所需判断素数的范围。sink初始化primes数组并监听其输入:
〈sieve functions 308〉+≡ int sink(void *cl) { struct args *p = cl; Chan_T input = p->c; int i = 0, j, x, primes[256]; primes[0] = 0; for (;;) { Chan_receive(input, &x, sizeof x); 〈x is a multiple of primes[0...] 310〉 if (primes[j] == 0) { 〈x is prime 310〉 } } Fmt_print("\n"); Chan_receive(input, &x, 0); return EXIT_SUCCESS; }
如果x不是primes中某个非零值的倍数,那么x是素数,sink将输出它并将其添加到primes。
〈x is prime 310〉≡ if (x > p->last) break; Fmt_print(" %d", x); primes[i++] = x; primes[i] = 0; if (i == p->n) 〈spawn a new sink and call filter 311〉
当x大于p->last时,所有要求的素数都已经输出,sink可以结束。在此之前,它还要等待从输入通道再读取一个整数,但只读取0个字节(缓冲区长度为0),这将通知上游的线程计算已经完成。
在sink累积了n个素数之后,它将克隆自身并变为一个filter,这需要一个新的通道:
〈spawn a new sink and call filter 311〉≡ { p->c = Chan_new(); Thread_new(sink, p, sizeof *p, NULL); filter(primes, input, p->c); return EXIT_SUCCESS; }
新的通道变为克隆线程的输入通道,以及新filter的输出通道。原本sink的输入通道,即为新的filter的输入通道。当filter返回时,其线程退出。
在sieve中,所有线程之间的切换都发生在Chan_send和Chan_receive中,至少总有一个线程是处于就绪状态的(可运行)。因而,sieve可以在抢占调度和非抢占调度下工作,这是一个简单的例子,示范了如何使用线程来规划应用程序的结构。非抢占线程通常称作协程 (coroutine,或协同例程)。
Chan的实现可以完全建立在Sem的实现之上,因此Chan是与机器无关的。Sem也是与机器无关的,但它依赖于Thread接口实现的内部结构,因此Thread接口的实现也同时实现了Sem接口。单处理器的Thread实现,可以在很大程度上独立于宿主机及其操作系统。如下文详述,只有上下文切换和抢占这两部分的代码中,才能对机器和操作系统依赖。
Chan_T是一个指向结构实例的指针,结构中包含三个信号量、一个指向所需传递消息的指针和一个字节计数:
〈chan.c 〉≡ #include <string.h> #include "assert.h" #include "mem.h" #include "chan.h" #include "sem.h" #define T Chan_T struct T { const void *ptr; int *size; Sem_T send, recv, sync; }; 〈chan functions 312〉
在创建一个新通道时,ptr和size字段是未定义的,信号量send、recv和sync的计数器分别初始化为1、0、0:
〈chan functions
312〉≡
T Chan_new(void) {
T c;
NEW(c);
Sem_init(&c->send, 1);
Sem_init(&c->recv, 0);
Sem_init(&c->sync, 0);
return c;
}
send和recv信号量控制对ptr和size的访问,sync信号量确保消息传输是同步的(Chan接口的规定)。线程通过填充ptr和size字段来发送消息,但仅当安全时才能这样做。send的计数器为1时,发送方才能设置ptr和size字段,send的计数器为0时则不行(例如,在接收方获取消息前)。类似地,recv的计数器为1时,ptr和size字段所包含的指针是有效的,指向一条消息及其长度,如果recv的计数器为0,则不然(例如,在发送方设置ptr和size字段之前)。send和recv不断“震荡”:当recv计数器为0时,send的计数器为1,反之亦然。当接收方已经成功地将一条消息复制到私有的缓冲区中时,sync的计数器为1。
Chan_send发送一条消息,该函数首先在send上等待,而后填充ptr和size字段,接下来通知recv,然后在sync上等待:
〈chan functions
312〉+≡
int Chan_send(Chan_T c, const void *ptr, int size) {
assert(c);
assert(ptr);
assert(size >= 0);
Sem_wait(&c->send);
c->ptr = ptr;
c->size = &size;
Sem_signal(&c->recv);
Sem_wait(&c->sync);
return size;
}
c->size包含一个指针,指向消息的字节计数,接收方可以修改该计数,从而通知发送方传输的字节数。Chan_receive也同样执行三个步骤,与Chan_send的步骤是互补的。Chan_receive接收一条信息,该函数首先在recv上等待,而后将消息复制到其参数指定的缓冲区中并修改字节计数,接下来通知sync和send:
〈chan functions
312〉+≡
int Chan_receive(Chan_T c, void *ptr, int size) {
int n;
assert(c);
assert(ptr);
assert(size >= 0);
Sem_wait(&c->recv);
n = *c->size;
if (size < n)
n = size;
*c->size = n;
if (n > 0)
memcpy(ptr, c->ptr, n);
Sem_signal(&c->sync);
Sem_signal(&c->send);
return n;
}
n是实际上接收的字节数,该值可能为0。上述代码处理了所有三种情形:发送方的size大于接收方的size,两个size相等,接收方的size大于发送方的size。
Thread接口的实现thread.c,其中实现了Thread和Sem接口:
〈thread.c 〉≡ #include <stdio.h> #include <stdlib.h> #include <string.h> #include </usr/include/signal.h> #include <sys/time.h> #include "assert.h" #include "mem.h" #include "thread.h" #include "sem.h" void _MONITOR(void) {} extern void _ENDMONITOR(void); #define T Thread_T 〈macros 315〉 〈types 314〉 〈data 314〉 〈prototypes 317〉 〈static functions 315〉 〈thread functions 316〉 #undef T #define T Sem_T 〈sem functions 330〉 #undef T
其中的空函数_MONITOR和外部函数_ENDMONITOR,将只使用其地址。如下所述,这些地址用于包围临界区,其中的线程代码不能被中断。其中少量代码是用汇编语言编写的,_ENDMONITOR定义在汇编语言文件的末尾,这样临界区就包括了这些汇编代码。其名称以下划线开头,这个惯例用于表示由具体实现定义的汇编语言名称。
线程处理是一个不透明指针,指向Thread_T结构,其中承载了确定线程状态需要的所有信息。该结构通常称之为线程控制块 (thread control block)。
〈types 314〉≡ struct T { unsigned long *sp; /* 必须定义在结构的开头 */ 〈fields 314〉 };
起始的字段包含了与机器和操作系统相关的值。这些字段出现在Thread_T结构的开头,因为它们是由汇编语言代码访问的。将这些字段放置在结构的开头,则较为容易访问,而且添加新字段时无需修改现存的汇编语言代码。大多数机器上,只需要一个这样的字段sp,其中包含了线程的栈指针。
大多数线程操作,都围绕着将线程放入队列和从队列中移除来进行。Thread和Sem接口的设计,用于维护一个简单的不变量:线程或者不在任何队列上,或者仅在一个队列上。这种设计能够避免为队列项分配空间。队列的表示无需其他方式(例如,Seq_T),只需要使用Thread_T结构的循环链表即可。一个例子是就绪队列,其中包含了未分配处理器的运行线程:
〈data 314〉≡ static T ready = NULL; 〈fields 314〉≡ T link; T *inqueue;
图20-3给出了就绪队列上的三个线程,顺序为A、B、C。ready指向队列中最后 一个线程C,该队列通过link字段连接。每个Thread_T结构的inqueue字段指向表示队列的变量,这里是ready,该字段用于将线程从队列中删除。当队列变量为NULL时,队列为空,如ready的初始值所示,可以通过下述宏来检测:
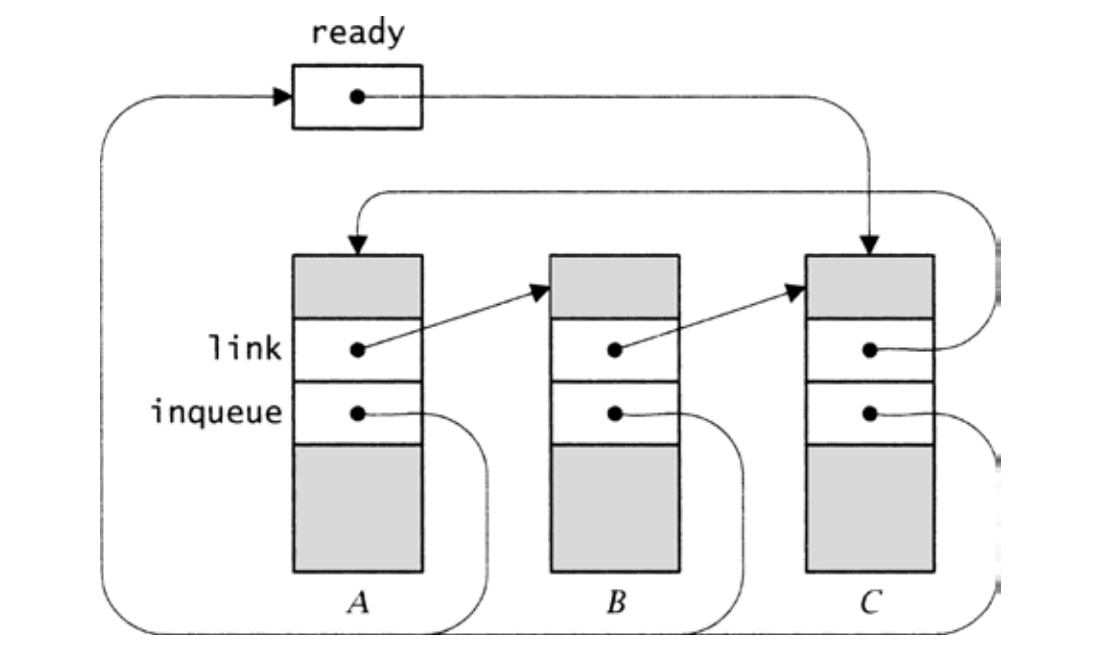
图20-3 就绪队列中的三个线程
〈macros 315〉≡ #define isempty(q ) ((q ) == NULL)
如果线程t在某个队列上,那么t->link和t->inqueue字段不是NULL,否则两个字段都是NULL。下述队列函数使用与link和inqueue字段相关的断言,来确保上文提到的不变量为真。例如,put将一个线程添加到一个空或非空队列:
〈static functions
315〉≡
static void put(T t, T *q) {
assert(t);
assert(t->inqueue == NULL && t->link == NULL);
if (*q) {
t->link = (*q)->link;
(*q)->link = t;
} else
t->link = t;
*q = t;
t->inqueue = q;
}
这样,put(t, & ready)将t添加到就绪队列。put的参数包括队列变量的地址,因而可以修改该变量:在调用put(t, & q)之后,q等于t,而t->inqueue等于&q。
get从一个给定队列中移除第一个元素:
〈static functions
315〉+≡
static T get(T *q) {
T t;
assert(!isempty(*q));
t = (*q)->link;
if (t == *q)
*q = NULL;
else
(*q)->link = t->link;
assert(t->inqueue == q);
t->link = NULL;
t->inqueue = NULL;
return t;
}
上述代码使用inqueue字段来确保线程确实在q中,最后它将link和inqueue字段清零,以标记该线程不再处于任何队列中。
delete是第三个也是最后一个队列函数,该函数将一个线程从其所在的队列移除:
〈static functions
315〉+≡
static void delete(T t, T *q) {
T p;
assert(t->link && t->inqueue == q);
assert(!isempty(*q));
for (p = *q; p->link != t; p = p->link)
;
if (p == t)
*q = NULL;
else {
p->link = t->link;
if (*q == t)
*q = p;
}
t->link = NULL;
t->inqueue = NULL;
}
第一个断言确保t在q中,第二个断言确保该队列是非空的(这是必须的,因为t在q中)。if语句处理了q中只有t一个线程的情形。
Thread_init创建了“根”线程(根线程的Thread_T结构是静态分配的):
〈thread functions 316〉≡ int Thread_init(int preempt, ...) { assert(preempt == 0 || preempt == 1); assert(current == NULL); root.handle = &root; current = &root; nthreads = 1; if (preempt) { 〈initialize preemptive scheduling 328〉 } return 1; } 〈data 314〉+≡ static T current; static int nthreads; static struct Thread_T root; 〈fields 314〉+≡ T handle;
current是当前持有处理器的线程,nthreads是现存线程的数目。Thread_new将nthreads加1,而Thread_exit将其减1。handle字段只是指向线程句柄,它有助于检查句柄的有效性:仅当t等于t->handle时,t标识一个现存的线程。
如果current为NULL,尚未调用Thread_init,因此如上述代码所示,对current为NULL的检测,实现了接口规定的已检查的运行时错误:Thread_init必须调用且仅调用一次。在其他Thread和Sem函数中,对current不是NULL的检测,则实现了接口规定的另一个已检查的运行时错误:Thread_init必须在任何其他Thread、Sem或Chan函数之前调用。例如Thread_self,该函数只是返回current:
〈thread functions
316〉+≡
T Thread_self(void) {
assert(current);
return current;
}
线程之间的切换需要一些机器相关代码,因为(举例来说)每个线程都有自身的栈和异常状态。上下文切换原语有很多可能的设计方案,所有这些都相对简单,因为它们是全部或部分用汇编语言编写的。Thread的实现使用了单一、特定于实现的原语。
〈prototypes
317〉≡
extern void _swtch(T from, T to);
该函数将上下文从from线程切换到to线程,其中from和to是指向Thread_T结构的指针。_swtch类似于setjmp和longjmp:在线程A调用_swtch时,控制转移到线程B。在B调用_swtch以恢复线程A的执行时,A对_swtch的调用返回。因而,A和B可以将_swtch当做通常的函数调用处理。这种简单的设计,也利用了机器的调用序列,这有助于在切换到线程B时保存线程A的状态。唯一的不利之处是,新线程创建时,其状态必须貌似在此前调用过_swtch,因为其第一次运行将是从_swtch返回 。
_swtch仅在一处调用,即静态函数run:
〈static functions 315〉+≡ static void run(void) { T t = current; current = get(&ready); t->estack = Except_stack; Except_stack = current->estack; _swtch(t, current); } 〈fields 314〉+≡ Except_Frame *estack;
run从当前执行线程切换到位于就绪队列头部的线程。它将ready头部的线程从队列移除,设置current,并切换到这个新线程。estack字段包含的指针指向线程异常栈顶部的异常帧,run负责更新Except的全局Except_stack(参见4.2节)。
所有可能导致上下文切换的Thread和Sem函数都会调用run,它们在调用run之前会将当前线程置于ready或另一个适当的队列上。Thread_pause是最简单的例子:它将current置于ready队列上,并调用run。
〈thread functions
316〉+≡
void Thread_pause(void) {
assert(current);
put(current, &ready);
run();
}
如果仅有一个运行线程,Thread_pause将其置于ready队列上,而run则又从就绪队列移除该线程,并切换到该线程。因而,_swtch(t, t)必须能够正常工作。图20-4描述了执行下列调用而导致在线程A、B和C之间发生的上下文切换,假定最初A持有处理器,ready队列包含B和C(顺序如图中方括号所示)。

图20-4中垂直的实线箭头表示各线程持有处理器的时间段,而水平的虚线箭头则表示上下文切换,就绪队列如图中实线箭头旁边的方括号所示。图中每个上下文切换下,都给出了Thread函数及其导致的_swtch调用。
在A调用Thread_pause时,它被添加到ready,B被从ready队列移除并获得处理器。在B运行时,ready包含C A。在B调用Thread_pause时,C被从ready删除并获得处理器。
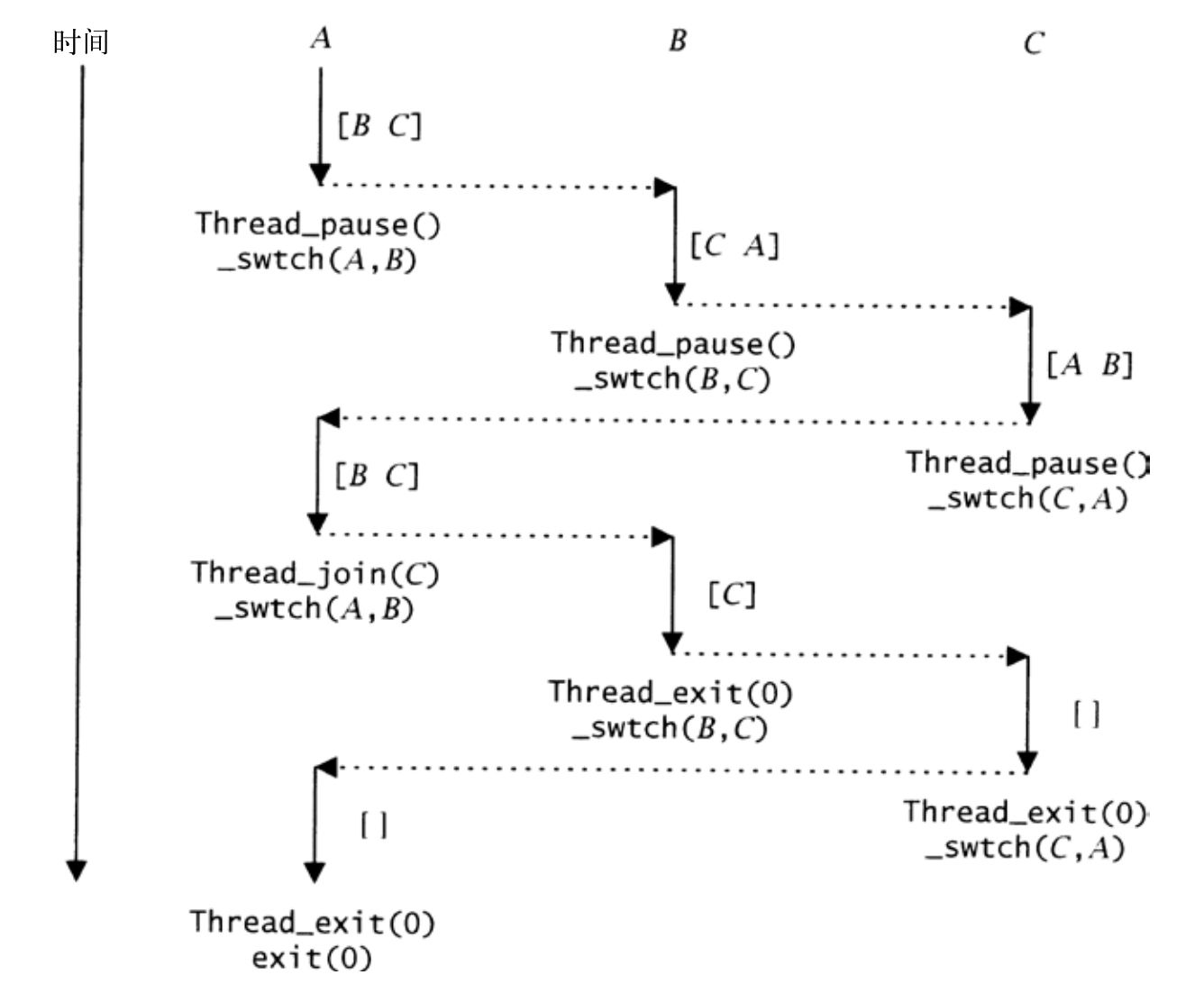
图20-4 在三个线程之间的上下文转接
此时ready包含A B。在C调用Thread_pause之后,ready再次包含B C,此时A恢复运行状态。在A调用Thread_join(C)时,它阻塞直至线程C结束,因此处理器被分配给线程B(此时处于ready的头部)。
到这里,ready仅包含C,因为A处于与C相关的一个队列中。在B调用Thread_exit时,run切换到线程C,而ready变为空队列。线程C通过调用Thread_exit结束,这导致线程A被重新置于ready队列。因而,在Thread_exit调用run时,线程A得到处理器。但A对Thread_exit的调用并不导致上下文切换:此时A是系统中唯一的线程,因此Thread_exit调用了exit。
在ready队列为空,而调用了run时,将发生死锁 ,即,没有可运行线程。死锁是已检查的运行时错误,当对空的就绪队列调用get时,可以检测到死锁。
Thread_join和Thread_exit说明了涉及“汇合队列”(join queue)和就绪队列的队列操作。有两种风格的Thread_join:Thread_join(t)等待线程t结束,并返回t的退出代码,即t传递给Thread_exit的值,t不能是调用Thread_join的线程。Thread_join(NULL)等待所有线程结束,并返回0,程序中只有一个线程能调用Thread_join(NULL)。
〈thread functions 316〉+≡ int Thread_join(T t) { assert(current && t != current); testalert(); if (t) { 〈wait for thread t to terminate 319〉 } else { 〈wait for all threads to terminate 320〉 return 0; } }
如下所述,如果调用线程已经处于“警报—待决”状态,则testalert将引发Thread_Alerted异常。当t不是NULL且指向某个现存的线程时,调用线程将自身置于t的汇合队列上,以等待t结束,否则,Thread_join立即返回-1。
〈wait for thread t to terminate 319〉≡ if (t->handle == t) { put(current, &t->join); run(); testalert(); return current->code; } else return -1; 〈fields 314〉+≡ int code; T join;
仅当t等于t->handle时,t才是一个现存的线程。如下所示,当一个线程结束时,Thread_exit将handle字段清零。当t结束时,Thread_exit将其参数保存到t->join队列中各个Thread_T的code字段中,并随之将这些线程移动到就绪队列。
因而,当这些线程再次执行时,很容易得到退出代码,在各个恢复执行的线程中,Thread_join会返回该值。
当t为NULL时,调用线程被置于join0队列,其中只能包含一个线程,来等待所有其他线程结束:
〈wait for all threads to terminate 320〉≡ assert(isempty(join0)); if (nthreads > 1) { put(current, &join0); run(); testalert(); } 〈data 314〉+≡ static T join0;
调用线程下一次运行时,它将成为程序中唯一的线程。该代码也处理了调用线程已经是系统中唯一线程的情形,即nthreads等于1时。
Thread_exit有很多工作需要完成:它必须释放与调用线程相关的资源,使等待调用线程结束的各个线程回复执行,并使之获得调用线程的退出代码,并检查调用线程是否是系统中最后第二个或最后一个线程。
〈thread functions 316〉+≡ void Thread_exit(int code) { assert(current); release(); if (current != &root) { current->next = freelist; freelist = current; } current->handle = NULL; 〈resume threads waiting for current's termination 320〉 〈run another thread or exit 321〉 } 〈fields 314〉+≡ T next; 〈data 314〉+≡ static T freelist;
对release的调用,以及将current添加到freelist的代码,这两者协作完成了对调用线程资源的释放,细节在下文详述。如果调用线程是根线程,Thread_T实例不能释放,因为其是静态分配的。
将handle字段清零后,即把该线程标记为不存在,等待其结束的各个线程现在可以恢复执行:
〈resume threads waiting for current's termination 320〉≡ while (!isempty(current->join)) { T t = get(¤t->join); t->code = code; put(t, &ready); }
调用线程的退出代码将复制到各个等待线程的Thread_T结构中的code字段,因为接下来将释放current线程。
如果只有两个线程存在而其中之一处于join0队列中,现在可以恢复该等待线程执行。
〈resume threads waiting for current's termination 320〉+≡ if (!isempty(join0) && nthreads == 2) { assert(isempty(ready)); put(get(&join0), &ready); }
断言有助于检测维护nthreads和ready时可能出现的错误:如果join0非空,而nthreads为2,那么ready必定为空,因为在两个现存线程中,一个位于join0中,而另一个则在执行Thread_exit。
Thread_exit结束时,会将nthreads减1,然后调用库函数exit或者运行另一个线程:
〈run another thread or exit
321〉≡
if (--nthreads == 0)
exit(code);
else
run();
Thread_alert将一线程线程标记“警报—待决”状态,这是通过在其Thread_T结构中设置一个标志并将该线程从所属队列删除(如果有所属队列)实现的。
〈thread functions 316〉+≡ void Thread_alert(T t) { assert(current); assert(t && t->handle == t); t->alerted = 1; if (t->inqueue) { delete(t, t->inqueue); put(t, &ready); } } 〈fields 314〉+≡ int alerted;
Thread_alert自身不会引发Thread_Alerted异常,因为调用线程与t所处状态是不同的。线程必须自行引发Thread_Alerted异常并处理该异常,这也是testalert的目的:
〈static functions 315〉+≡ static void testalert(void) { if (current->alerted) { current->alerted = 0; RAISE(Thread_Alerted); } } 〈data 314〉+≡ const Except_T Thread_Alerted = { "Thread alerted" };
每当一个线程即将阻塞,或线程在阻塞之后恢复执行时,都会调用testalert。前一种情况,由Thread_join开头处对testalert的调用说明。后一种情况,总是出现在对run的调用之后,可以由代码块<wait for threadt to terminate 319>和<wait for all threads to terminate 320>中对testalert的调用说明。类似的用法也出现在Sem_wait和Sem_signal中,参见20.3.5节。
最后一个Thread函数是Thread_new。Thread_new的一些部分是与机器相关的,因为它与_swtch交互,但该函数中大部分代码是几乎与机器无关的。Thread_new有4个任务:为一个新线程分配资源,初始化新线程的状态(使之仿佛从_swtch返回并继续执行),将nthreads加1,将新线程添加到ready。
〈thread functions 316〉+≡ T Thread_new(int apply(void *), void *args, int nbytes, ...) { T t; assert(current); assert(apply); assert(args && nbytes >= 0 || args == NULL); if (args == NULL) nbytes = 0; 〈allocate resources for a new thread 322〉 t->handle = t; 〈initialize t's state 324〉 nthreads++; put(t, &ready); return t; }
在这个对Thread接口的单处理器实现中,一个线程需要的唯一资源是Thread_T结构和一个栈。Thread_T结构和一个16KB的栈,通过对Mem接口中ALLOC的一次调用完成:
〈allocate resources for a new thread 322〉≡ { int stacksize = (16*1024+sizeof (*t)+nbytes+15)& ~15; release(); 〈begin critical region 323〉 TRY t = ALLOC(stacksize); memset(t, '\0', sizeof *t); EXCEPT(Mem_Failed) t = NULL; END_TRY; 〈end critical region 323〉 if (t == NULL) RAISE(Thread_Failed); 〈initialize t's stack pointer 323〉 } 〈data 314〉+≡ const Except_T Thread_Failed = { "Thread creation failed" };
该代码有些复杂,因为它必须得维护几个不变量,其中最重要的的是:对Thread接口函数的调用不能被中断。有两个机制协作来维护该不变量:一种机制,处理当控制位于某个Thread接口函数中时出现的中断,如下文所述。另一种机制,处理当控制位于被某个Thread接口函数调用的例程中时出现的中断,由对ALLOC和memset的调用说明。此类调用,都被用于标识临界区的代码块包围(这种代码块分别对critical值加1和减1):
〈begin critical region 323〉≡ do { critical++; 〈end critical region 323〉≡ critical--; } while (0); 〈data 314〉+≡ static int critical;
如20.3.4节所示,当critical非零时发生的中断被忽略。
Thread_new必须自行捕获Mem_Failed异常,并在离开临界区之后引发自身的异常Thread_failed。如果它不捕获该异常,控制将转移到调用者的异常处理程序,此时critical已经被设置为正值,不会再被减1。
Thread_new假定栈向低地址方向增长,它将sp字段初始化为如图20-5所示,顶部的阴影方框是Thread_T结构,底部是args的副本和最初的栈帧,如下所述。
〈initialize t's stack pointer 323〉≡ t->sp = (void *)((char *)t + stacksize); while (((unsigned long)t->sp)&15) t->sp--;
如上述代码块对stacksize的赋值所示,Thread_new初始化栈指针使之对齐到16字节边界,这样做可以适应大多数平台。大多数机器要求栈对齐到四字节或八字节边界,但DEC ALPHA要求16字节对齐。
Thread_new从调用release开始,Thread_exit也调用了该函数。Thread_exit不能释放当前线程的栈,因为Thread_exit正在使用该栈。因此它将线程句柄添加到freelist,将释放操作延迟到下一次调用release:
〈static functions 315〉+≡ static void release(void) { T t; 〈begin critical region 323〉 while ((t = freelist) != NULL) { freelist = t->next; FREE(t); } 〈end critical region 323〉 }
release设计得过于通用:freelist只有一个元素,因为Thread_exit和Thread_new都会调用release。如果只有Thread_new调用release,那么已结束线程的Thread_T实例将会在freelist上累积起来。release使用了一个临界区,因为它调用了Mem接口中的FREE。
接下来,Thread_new初始化新线程的栈,使之包含从args开始的nbytes字节的一个副本,并设置初始栈帧,使之看似刚刚调用过_swtch。后一种初始化是与机器相关的:
〈initialize t's state 324〉≡ if (nbytes > 0) { t->sp -= ((nbytes + 15U)& ~15)/sizeof (*t->sp); 〈begin critical region 323〉 memcpy(t->sp, args, nbytes); 〈end critical region 323〉 args = t->sp; } #if alpha {〈initialize an ALPHA stack 335〉 } #elif mips {〈initialize a MIPS stack 333〉 } #elif sparc {〈initialize a SPARC stack 326〉 } #else Unsupported platform #endif
图20-5中给出的栈,其底部描述了这些初始化操作的结果:深色阴影标识了与机器相关的栈帧,而浅色阴影是args的副本。thread.c和swtch.s是本书中仅有的使用条件编译的模块。
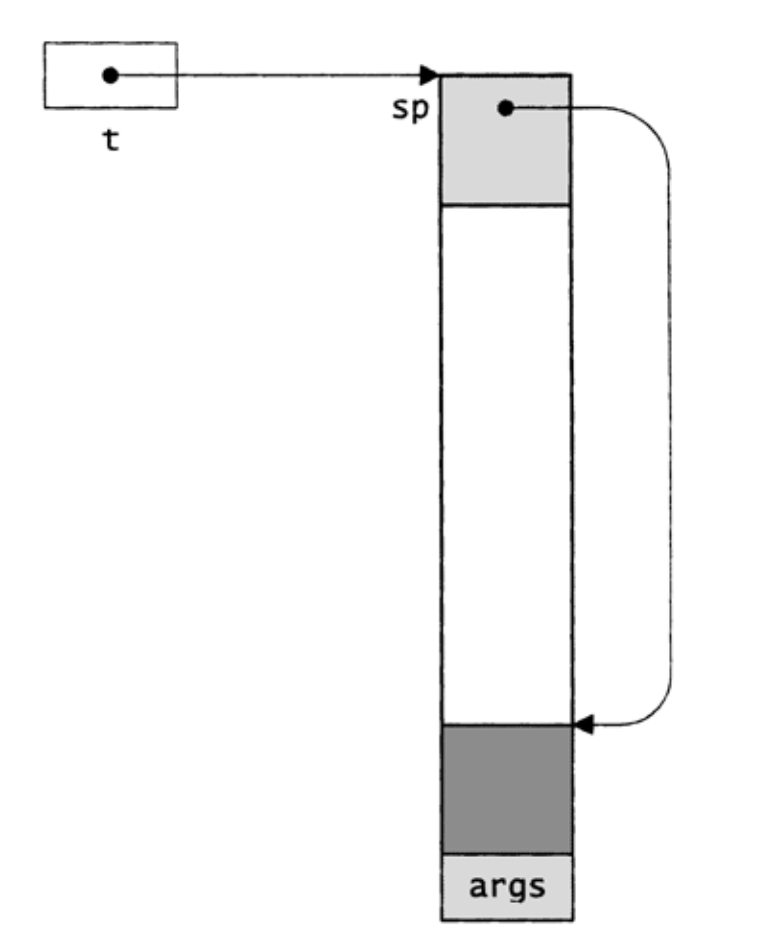
图20-5 Thread_T结构与栈的分配
在列出_swtch汇编语言实现的纲要之后,栈初始化变得更容易理解:
〈swtch.s 〉≡ #if alpha 〈ALPHA swtch 334〉 〈ALPHA startup 334〉 #elif sparc 〈SPARC swtch 325〉 〈SPARC startup 326〉 #elif mips 〈MIPS swtch 332〉 〈MIPS startup 333〉 #else Unsupported platform #endif
_swtch(from, to)必须保存from的状态,恢复to的状态,并使to从最近一次对_swtch的调用返回,以便使to继续执行。调用约定保存了大部分状态,因为它们通常规定在不同调用之间必须保存某些寄存器的值,而一些机器状态信息没有保存,如条件码(condition code register,即处理器中的状态寄存器,亦称为status register或flag register)。因此_swtch只保存其所需,而调用约定又没有保存的那些状态,例如返回地址,它可能将这些值保存到调用线程的栈上。
对应SPARC体系结构的_swtch实现可能是最容易的,因为SPARC调用约定给每个函数都提供了自身的“寄存器窗口”(register window),从而保存了所有的寄存器,_swtch唯一需要保存的寄存器是栈帧指针(frame pointer)和返回地址。
〈SPARC swtch 325〉≡ .global __swtch .align 4 .proc 4 1 __swtch:save %sp,-(8+64),%sp 2 st %fp,[%sp+64+0] ! 保存from的帧指针 3 st %i7,[%sp+64+4] ! 保存from的返回地址 4 ta 3 ! 刷出from的寄存器 5 st %sp,[%i0] ! 保存from的栈指针 6 ld [%i1],%sp ! 加载to的栈指针 7 ld [%sp+64+0],%fp ! 恢复to的帧指针 8 ld [%sp+64+4],%i7 ! 恢复to的返回地址 9 ret ! 使to继续执行 10 restore
上述的行号标识了代码的各行,以便下文解释,这些行号不是汇编语言代码的一部分。按照惯例,汇编语言名称以一个下划线作为前缀,因此_swtch在SPARC平台的汇编语言中写作_swtch。
图20-6给出了_swtch的栈帧布局,所有的SPARC栈帧,在栈帧顶部都至少有64字节,供操作系统在必要时保存函数的寄存器窗口。在_swtch的栈帧长度为72字节,64字节之外余下的两个字,分别保存了帧指针和返回地址。
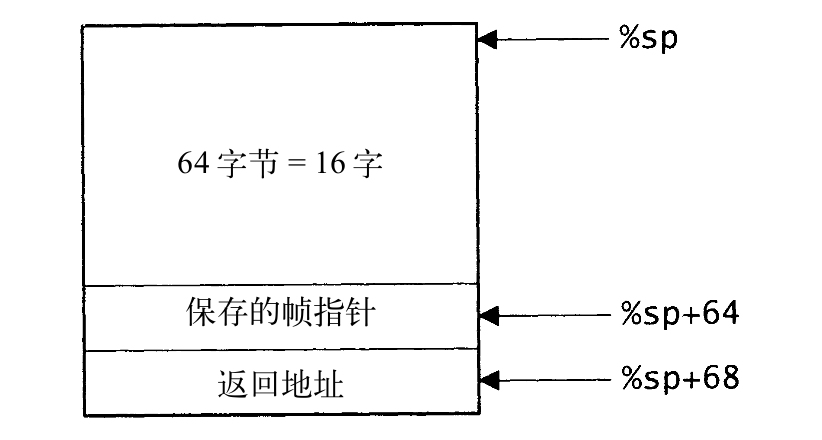
图20-6 _swtch的栈帧布局
_swtch中的第1行为_swtch分配了一个栈帧。第2行和第3行保存from的帧指针(%fp)和返回地址(%i7),二者分别保存到新帧的第十七个和第十八个32位字(偏移量64和68处)。第4行进行了一次系统调用,以便将from的寄存器窗口“刷出”到栈上,为用to的寄存器窗口继续执行,这样做是必需的。这个调用令人遗憾:对用户级线程来说,一个预先推定的好处是,上下文切换不需要内核干预。但在SPARC上,只有内核能够刷出寄存器窗口。
第5行将from的栈指针保存到其Thread_T结构中的sp字段。这个指令说明了为什么该字段需要放置在结构的头部:该代码与Thread_T结构实例的长度和其他字段的位置都是无关的。第6行是斜体,因为它是实际的上下文切换。该指令加载to的栈指针到%sp中(栈指针寄存器)。此后,_swtch是在to的栈上执行。第7行和第8行分别恢复to的帧指针和返回地址,因为%sp现在指向to的栈顶。第9行和第10行构成了常规的函数返回指令序列,控制返回到to线程上一次调用_swtch之后的地址继续执行。
Thread_new必须为_swtch创建一个栈帧,以便其他线程对_swtch的调用能够正确地返回,从而开始新线程的执行,该执行必须调用apply。图20-7给出了Thread_new建立的构造:_swtch的栈帧位于栈顶,其下的栈帧用于下述启动代码。
〈SPARC startup
326〉≡
.global __start
.align 4
.proc 4
1 __start:ld [%sp+64+4],%o0
2 ld [%sp+64],%o1
3 call %o1; nop
4 call _Thread_exit; nop
5 unimp 0
.global __ENDMONITOR
__ENDMONITOR:
_swtch栈帧中的返回地址指向_start,启动代码的栈帧包含apply和args,如图20-7所示。在第一次从_swtch返回时,控制转移到_start(汇编代码中的_start)。启动代码中的第1行将args加载到%o0中,该寄存器在SPARC调用约定中用于传递第一个参数。第2行将apply的地址加载到%o1中,该寄存器在其他情况下并不使用,第3行对apply进行了间接调用。如果apply返回,其退出代码位于%o0中,该值将传递给Thread_exit,Thread_exit从不返回。第5行应该从不执行,如果执行,它将导致异常。_ENDMONITOR将在下文解释。
_swtch和_start中的15行汇编语言,就是SPARC体系结构上所有必需的东西,如图20-7所示,为新线程初始化栈的工作完全可以用C语言完成。两个栈帧是自底向上建立的,如下。
〈initialize a SPARC stack
326〉≡
1 int i; void *fp; extern void _start(void);
2 for (i = 0; i < 8; i++)
3 *--t->sp = 0;
4 *--t->sp = (unsigned long)args;
5 *--t->sp = (unsigned long)apply;
6 t->sp -= 64/4;
7 fp = t->sp;
8 *--t->sp = (unsigned long)_start - 8;
9 *--t->sp = (unsigned long)fp;
10 t->sp -= 64/4;
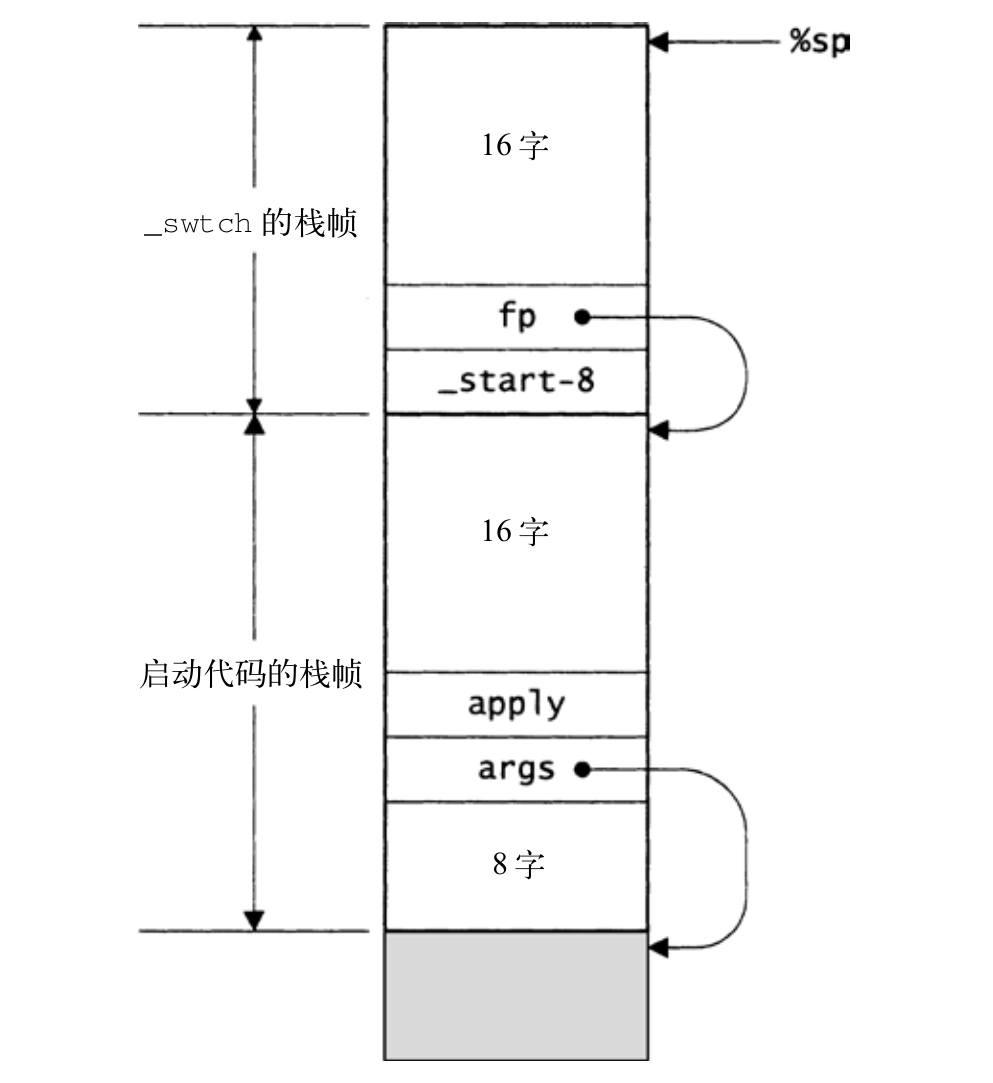
图20-7 SPARC架构上线程启动代码和初始_swtch的栈帧
第2行和第3行创建启动栈帧底部的八个字。第4行和第5行将args的值和apply投入栈中,第6行在启动栈帧的顶部分配了64个字节。此时的栈指针,即为必须通过_swtch恢复的帧指针,因此第7行将该值保存到fp。第8行将返回地址压栈,即%i7的保存值。返回地址是_start之前八个字节,因为SPARC架构中的ret指令在返回时会向%i7中的地址加8。第9行将%fp的保存值压栈,第10行在_swtch栈帧顶部分配64字节,初始化栈帧的工作到此结束。
如果apply是一个有可变数目参数的函数,其入口指令序列将%o0到%o5寄存器中的值保存到栈上,位于其调用者栈帧的偏移量64到88处,即在启动代码的栈帧中。第2行和第3行为此分配了空间,并额外增加了8字节,使得栈指针仍然能够对齐到8字节边界,这是SPARC硬件的要求。
_swtch和_start的MIPS和ALPHA版本,将在20.3.6节讲述。
抢占等效于周期性地隐式调用Thread_pause。Thread中对抢占的实现是UNIX相关的,其中设定了一个周期为50毫秒的“虚拟”时钟中断,由中断处理程序来执行相当于Thread_pause的代码。该定时器是虚拟的,因为仅当进程执行时,该时钟才运转。Thread_init使用UNIX信号设施来初始化时钟中断。第一步是将中断处理程序关联到虚拟定时器信号SIGVTALRM:
〈initialize preemptive scheduling
328〉≡
{
struct sigaction sa;
memset(&sa, '\0', sizeof sa);
sa.sa_handler = (void (*)())interrupt;
if (sigaction(SIGVTALRM, &sa, NULL) < 0)
return 0;
}
sigaction结构有三个字段:sa_handler是SIGVTALRM信号发生时要调用的函数的地址,sa_mask是一个信号集合,指定了在中断处理期间应该阻塞的信号(包括SIGVTALRM在内),sa_flags提供了特定于信号的选项。如下所述,Thread_init将sa_handler设置为interrupt,并将其他字段清零。
sigaction函数是用于将处理程序关联到信号的POSIX标准函数。大多数UNIX变体和一些其他操作系统(如Windows NT),都支持POSIX标准。该函数的三个参数,分别给出了信号的符号名、指向sigaction结构实例(用以修改对信号的处理)的指针和指向另一个sigaction结构实例(用于获取此前对该信号的处理设置)的指针。当第三个参数为NULL时,不会返回此前对该信号处理的设置。
当对该信号的处理设置已经按第二个参数的指定修改完成时,sigaction函数返回0,否则返回-1。当sigaction返回-1时,Thread_init返回0,表示线程系统不支持抢占调度。
在信号处理程序就位后,将初始化虚拟定时器:
〈initialize preemptive scheduling
328〉+≡
{
struct itimerval it;
it.it_value.tv_sec = 0;
it.it_value.tv_usec = 50;
it.it_interval.tv_sec = 0;
it.it_interval.tv_usec = 50;
if (setitimer(ITIMER_VIRTUAL, &it, NULL) < 0)
return 0;
}
itimerval结构中的it_value字段,按秒(tv_sec)和毫秒(tv_msec)为单位,指定了到下一次时钟中断还有多长时间。it_interval字段中的值用于在定时器到期时重置it_value字段。Thread_init将时钟中断设置为每隔50毫秒发生一次。
setitimer函数很像是sigaction函数:其第一个参数指定了影响哪个定时器的行为(因为还有一个实时定时器),第二个参数是一个指向itimerval结构实例(其中包含了新的定时器值)的指针,第三个参数也是一个指向itimerval结构实例(用于获取此前的定时器设置)的指针(如果不需要此前的设置,则指针为NULL)。当定时器设置成功时,setitimer返回0,否则返回-1。
当虚拟定时器到期时,将调用信号处理程序interrupt。当中断结束,即interrupt返回时,定时器重新开始。除非当前线程处于临界区中,或处于某个Thread或Sem函数中,否则interrupt执行的代码与Thread_pause等效。
〈static functions
315〉+≡
static int interrupt(int sig, int code,
struct sigcontext *scp) {
if (critical ||
scp->sc_pc >= (unsigned long)_MONITOR
&& scp->sc_pc <= (unsigned long)_ENDMONITOR)
return 0;
put(current, &ready);
sigsetmask(scp->sc_mask);
run();
return 0;
}
sig参数承载的是信号号码,code为某些信号提供了额外的数据。scp参数是一个指向sig-context结构的指针,结构的sc_pc字段提供了发生中断时的指令计数器。thread.c从空函数_MONITOR开始,而swtch.s中的汇编语言代码以全局符号_ENDMONITOR的定义结束。如果目标文件载入程序的顺序是swtch.s的目标码在thread.c的目标码之后,那么对于被中断的线程来说,如果其指令计数器位于_MONITOR和_ENDMONITOR之间,那么该线程当时正在执行某个Thread或Sem函数。因而,如果critical为非零值,或scp->sc_pc位于_MONITOR和_ENDMONITOR之间,那么interrupt将返回而忽略时钟中断。否则,interrupt将当前线程置于ready队列上,而运行另一个线程。
对sigsetmask的调用,将恢复此前被中断停用的信号(由信号集合scp->sc_mask发出),该集合通常只包含SIGVTALRM信号。该调用是必需的,接下来即将运行的线程可能不是通过中断挂起的。例如,假定线程A显式调用了Thread_pause而挂起,线程B继续执行。在时钟中断发生时,控制进入到interrupt,此时SIGVTALRM信号已经被禁用。B在interrupt中重新启用了SIGVTALRM信号,并放弃处理器给线程A。
如果忽略对sigsetmask的调用,线程A恢复执行时,SIGVTALRM信号将是被禁用 的,因为A是通过Thread_pause挂起的,而不是通过interrupt。在下一次发生时钟中断时,A挂起而B继续执行。在这种情况下,调用sigsetmask是多余的,因为线程B释放了中断,这将恢复信号掩码Thread_T结构中的一个标志可用于避免对sigsetmask的不必要的调用。
中断处理程序的第二个和后续的参数是系统相关的。大多数UNIX变体都支持上述的code和scp参数,但其他POSIX兼容系统可能向处理程序提供不同的参数。
在四个Sem函数中,创建和初始化信号量是比较容易的两个:
〈sem functions
330〉≡
T *Sem_new(int count) {
T *s;
NEW(s);
Sem_init(s, count);
return s;
}
void Sem_init(T *s, int count) {
assert(current);
assert(s);
s->count = count;
s->queue = NULL;
}
Sem_wait和Sem_signal比较简短,但对这两个函数给出正确且公平的实现,需要很强的技巧。信号量操作在语义上相当于下述代码:
Sem_wait(s): while (s->count <= 0)
;
--s->count;
Sem_signal(s): ++s->count;
这些语义会导致简洁、正确,但并不公平的实现,如下所示;这些实现也忽略了警报—待决状态和已检查的运行时错误。
void Sem_wait(T *s) {
while (s->count <= 0) {
put(current, &s->queue);
run();
}
--s->count;
}
void Sem_signal(T *s) {
if (++s->count > 0 && !isempty(s->queue))
put(get(&s->queue), &ready);
}
这些实现是不公平的,因为它们允许“饥饿”发生。假定s初始化为1,二线程A和B都执行下述代码:
for (;;) {
Sem_wait(s);
...
Sem_signal(s);
}
假定线程A处于省略号表示的临界区中,而B处于s->queue队列中。当A调用Sem_signal时,线程B移动到就绪队列。如果B继续执行,其对Sem_wait的调用将返回,而B将进入临界区。但A可能先调用Sem_wait,并获取临界区。如果A在临界区内部执行时被抢占,那么B恢复执行但发现s->count为0,因而又移回s->queue队列上。如果没有某种外部干预,B可能在ready和s->queue两个队列之间无限循环下去,如果有更多线程竞争s,那么造成饥饿的可能性更高。
一种解决方案是,当一个线程从s->queue移动到ready时,要确保该线程获取到信号量。这种方案的实现,可以通过在s->count即将从0变为1时,将一个线程从s->queue移动到ready,但实际上并不对s->count执行加1操作。类似地,当一个被阻塞的线程从Sem_wait中恢复执行时,也并不对s->count执行减1操作。
〈sem functions
330〉+≡
void Sem_wait(T *s) {
assert(current);
assert(s);
testalert();
if (s->count <= 0) {
put(current, (Thread_T *)&s->queue);
run();
testalert();
} else
--s->count;
}
void Sem_signal(T *s) {
assert(current);
assert(s);
if (s->count == 0 && !isempty(s->queue)) {
Thread_T t = get((Thread_T *)&s->queue);
assert(!t->alerted);
put(t, &ready);
} else
++s->count;
}
当s->count为0且线程C移到就绪队列时,C将确保能够获取到该信号量,因为由于s->count为0,其他调用Sem_wait的线程将一直处于阻塞状态。但对于一般信号量来说,线程C未必能先获取到信号量:如果D在C再次运行之前调用Sem_signal,那么就制造了一个“时间窗口”,使得另一个线程可能在C之前获取到信号量,当然线程C也会获取到该信号量。
警报—待决状态,可能使得Sem_wait难于理解。如果在s上阻塞的一个线程被设置为警报—待决状态,那么该线程在Sem_wait中对run的调用将立即返回,同时设置其alerted标志。在这种情况下,该线程是被Thread_Alert(而非Sem_signal)移到ready队列的,因此其恢复执行与s->count的值无关。该线程必须使s处于无扰动状态,并清除自身的alerted标志,而后引发Thread_Alerted异常。
_swtch和_start的MIPS和ALPHA版本,与其SPARC版本相比,在设计上是类似的,但细节上是不同的。
_swtch的MIPS版本如下所示。其栈帧长度为88字节。通过sw $31,48+36($sp)实现的存储指令,保存了“由调用者保存”的浮点与整数寄存器,寄存器31包含了返回地址。用斜体字印刷的指令通过加载to的栈指针来切换上下文,接下来的加载指令恢复了线程to“由调用者保存”的寄存器。
〈MIPS swtch 332〉≡ .text .globl _swtch .align 2 .ent _swtch .set reorder _swtch: .frame $sp,88,$31 subu $sp,88 .fmask 0xfff00000,-48 s.d $f20,0($sp) s.d $f22,8($sp) s.d $f24,16($sp) s.d $f26,24($sp) s.d $f28,32($sp) s.d $f30,40($sp) .mask 0xc0ff0000,-4 sw $16,48+0($sp) sw $17,48+4($sp) sw $18,48+8($sp) sw $19,48+12($sp) sw $20,48+16($sp) sw $21,48+20($sp) sw $22,48+24($sp) sw $23,48+28($sp) sw $30,48+32($sp) sw $31,48+36($sp) sw $sp,0($4) lw $sp,0($5) l.d $f20,0($sp) l.d $f22,8($sp) l.d $f24,16($sp) l.d $f26,24($sp) l.d $f28,32($sp) l.d $f30,40($sp) lw $16,48+0($sp) lw $17,48+4($sp) lw $18,48+8($sp) lw $19,48+12($sp) lw $20,48+16($sp) lw $21,48+20($sp) lw $22,48+24($sp) lw $23,48+28($sp) lw $30,48+32($sp) lw $31,48+36($sp) addu $sp,88 j $31
这里是MIPS的线程启动代码:
〈MIPS startup
333〉≡
.globl _start
_start: move $4,$23 # 寄存器23保存args
move $25,$30 # 寄存器30保存apply
jal $25
move $4,$2 # Thread_exit(apply(p))
move $25,$21 # 寄存器21保存Thread_exit
jal $25
syscall
.end _swtch
.globl _ENDMONITOR
_ENDMONITOR:
该代码与Thread_new中与MIPS相关的部分协作,Thread_new将Thread_exit、args、apply保存到栈帧中适当的位置,以便使之分别加载到寄存器21、23、30。apply的第一个参数通过寄存器4传递,其结果通过寄存器2返回。启动代码并不需要栈帧,因此Thread_new只建立了_swtch的栈帧,但它确实在栈中_swtch栈帧之下的位置分配了4个字,以便处理apply需要可变数目参数的情形。
〈initialize a MIPS stack
333〉≡
extern void _start(void);
t->sp -= 16/4;
t->sp -= 88/4;
t->sp[(48+20)/4] = (unsigned long)Thread_exit;
t->sp[(48+28)/4] = (unsigned long)args;
t->sp[(48+32)/4] = (unsigned long)apply;
t->sp[(48+36)/4] = (unsigned long)_start;
Thread_exit的地址通过寄存器21传递,因为MIPS线程启动代码必须是位置无关的。启动代码将args的地址复制到寄存器4,并在对应的调用(jal指令)前将apply和Thread_exit的地址复制到寄存器25,因为这是MIPS架构上与位置无关的调用指令序列的要求。
ALPHA版本的代码块与对应的MIPS代码块类似。
〈ALPHA swtch 334〉≡ .globl _swtch .ent _swtch _swtch: lda $sp,-112($sp) # 分配_swtch的栈帧 .frame $sp,112,$26 .fmask 0x3f0000,-112 stt $f21,0($sp) # 保存from的寄存器 stt $f20,8($sp) stt $f19,16($sp) stt $f18,24($sp) stt $f17,32($sp) stt $f16,40($sp) .mask 0x400fe00,-64 stq $26,48+0($sp) stq $15,48+8($sp) stq $14,48+16($sp) stq $13,48+24($sp) stq $12,48+32($sp) stq $11,48+40($sp) stq $10,48+48($sp) stq $9,48+56($sp) .prologue 0 stq $sp,0($16) # 保存from的栈指针 ldq $sp,0($17) # 恢复to的栈指针 ldt $f21,0($sp) # 恢复to的寄存器 ldt $f20,8($sp) ldt $f19,16($sp) ldt $f18,24($sp) ldt $f17,32($sp) ldt $f16,40($sp) ldq $26,48+0($sp) ldq $15,48+8($sp) ldq $14,48+16($sp) ldq $13,48+24($sp) ldq $12,48+32($sp) ldq $11,48+40($sp) ldq $10,48+48($sp) ldq $9,48+56($sp) lda $sp,112($sp) # 释放栈帧 ret $31,($26) .end _swtch 〈ALPHA startup 334〉≡ .globl _start .ent _start _start: .frame $sp,0,$26 .mask 0x0,0 .prologue 0 mov $14,$16 # 寄存器14保存args mov $15,$27 # 寄存器15保存apply jsr $26,($27) # 调用apply ldgp $26,0($26) # 重新加载全局指针 mov $0,$16 # Thread_exit(apply(args)) mov $13,$27 # 寄存器13保存Thread_exit地址 jsr $26,($27) call_pal0 .end _start .globl _ENDMONITOR _ENDMONITOR: 〈initialize an ALPHA stack 335〉≡ extern void _start(void); t->sp -= 112/8; t->sp[(48+24)/8] = (unsigned long)Thread_exit; t->sp[(48+16)/8] = (unsigned long)args; t->sp[(48+ 8)/8] = (unsigned long)apply; t->sp[(48+ 0)/8] = (unsigned long)_start;
[Andrews,1991]是一本关于并发程序设计的综合教科书。它描述了与并行系统编程相关的大多数问题及其答案,包括同步机制、消息传递系统和远程过程调用。其中也描述了四种编程语言中为并发程序设计而专门设计的特性。
Thread基于Modula-3的线程接口,后者又源自SRC(DEC的System Research Center)所开发的Modula-2+中的线程设施。[Nelson,1991]中的第4章是线程编程方面的导引,由Andrew Birrell撰写。任何编写基于线程的应用程序的人,都会得益于该文。大多数现代操作系统中的线程设施,都在某些方面是基于SRC所开发的接口。
[Tanenbaum,1995]综述了用户级和内核级线程的设计问题,并给出了实现纲要。其案例研究描述了三个操作系统(Amoeba、Chorus和Mach)中的线程软件包,以及OSF的DCE中的线程。在我们了解到DCE时,DCE最初运行在UNIX的OSF/1变体上,但现在可用于大多数操作系统,包括OpenVMS、OS/2、Windows NT和Windows 95。
[Kleiman, Shah and Smaalders,1996]详述了POSIX线程(IEEE,1995)和Solaris 2线程。这本书面向实践,其中有一章内容阐述线程和库之间的交互,包括很多使用线程将算法并行化的例子,包括排序以及链表/队列/哈希表的线程安全实现。
sieve改编自[McIlroy,1968]用于说明协程程序设计的一个类似例子,协程类似于非抢占线程。协程出现在几种语言中,有时名称也不同。Icon的coexpression就是一个例子[Wampler and Griswold,1983]。[Marlin,1980]综述了许多原来的协程建议方案,并描述了在Pascal变体中的模型实现。
通道基于CSP(communicating sequential processes)([Hoare,1978])。线程和通道也出现在Newsqueak中,这是一种应用性的并发语言。CSP和Newsqueak中的通道比Chan提供的更为强大,因为这两种语言提供的设施,可用于在多个通道上以非确定性方式等待。[Pike,1990]探讨了一个Newsqueak解释器的实现中的精彩之处,并描述了使用随机数来改变抢占的发生频度,这使得线程调度具有非确定性(但比较公平)。[McIlroy,1990]详述了一个Newsqueak程序,该程序将幂级数当做数据流处理,其方法在本质上类似于sieve。
Newsqueak已经用于实现窗口系统,这例证了能从线程受益的那些交互式应用。NeWS窗口系统[Gosling, Rosenthal and Arden,1989]是另一个用带有线程的语言编写的窗口系统的例子。NeWS系统的核心是一个PostScript解释器,其用于渲染文本和图像。NeWS窗口系统自身的大部分是用PostScript变体编写的,该语言包括了非抢占线程扩展。
函数式语言Concurrent ML [Reppy,1997]支持线程和同步通道,这与Chan提供的功能很相似。在非命令式(nonimperative)语言中实现线程,通常比基于栈的命令式语言更为容易。例如,在Standard ML中没有栈,因为被调用者的生存期可能超过调用者,因此不需要什么特别的设置来支持线程。因而,Concurrent ML是完全用Standard ML实现的。
Thread和Sem实现中使用_MONITOR和_ENDMONITOR函数来划分代码边界的想法,来自于[Cormack,1988],其中描述了用于UNIX线程的一个类似但稍有不同的接口。[Stevens,1992]的第10章全面地阐述了信号和信号处理程序,其中描述了不同UNIX变体和POSIX标准之间的差异。
20.1 二值信号量通常称之为锁或互斥量,是最流行的信号量类型。为锁设计一个单独的接口,其实现比一般信号量更简单。请注意警报—待决状态。
20.2 假定线程A锁定x然后尝试锁定y,线程B锁定y然后尝试锁定x。这些线程将陷入死锁:在B解锁y之前A不能继续执行,在A解锁x之前B不能继续执行。扩展前一习题对锁的实现,以检测这些简单类型的死锁。
20.3 不使用信号量,重新实现thread.c中的Chan接口。为通道设计一个适当的表示,直接使用内部队列和线程函数,而非信号量函数。请注意警报—待决状态。设计一个测试套件,以测量这种可能更为高效的实现所带来的好处。对于修订的实现,请量化应用程序的消息活动程度,以便在运行时产生可测量的差异。
20.4 设计并实现一个异步、缓冲式通讯接口,这是一个线程间消息通讯设施,其中发送方并不等待消息被接收,消息被缓冲起来,直至被接收为止。你的设计应该允许消息的生命周期长于其发送线程,即,线程发送一消息消息,然后在消息接收之前线程就退出了。异步通信比Chan同步通信更为复杂,因为它必须处理对缓冲消息的存储管理和更多的错误条件,例如,需要提供一种方法,供线程判断消息是否已经被接收。
20.5 Modula-3支持条件变量 (condition variable)。一个条件变量c关联到一个锁m。原子操作sleep(m, c)导致调用线程解锁m并在c上等待。调用线程必须已经锁定了m。wakeup(c)导致一个或多个在c上等待的线程恢复执行,其中之一重新锁定m并从其对sleep的调用返回。broadcast(c)类似于wakeup(c),但所有 在c上睡眠的线程都恢复执行。警报—待决状态不影响阻塞在条件变量上的线程,除非线程调用alertsleep而不是sleep。当一个已经调用alertsleep的线程被设置为警报—待决状态,则其锁m并引发Thread_Alerted异常。设计并实现一个支持条件变量的接口,使用读者在习题20.1中实现的锁。
20.6 如果你的系统支持非阻塞I/O系统调用,使用它们为C标准I/O库构建一个线程安全的实现。即,举例来说,当一个线程调用fgetc时,该线程等待输入时,其他线程可以执行 [2] 。
20.7 设计一种方法,使得无需使用_MONITOR和_ENDMONITOR,即可使Thread和Sem函数的执行具有原子性。提示:单一的全局临界区标志是不够的。读者将需要为每个线程设置一个临界区标志,而汇编语言代码将需要修改该标志。请务必谨慎,使用这种方法很容易造成一些微妙的错误。
20.8 扩展Thread_new,使之可以接受指定栈长度的可选参数。例如,
t = Thread_new(..., "stacksize", 4096, NULL);
上述代码将创建一个栈长度为4KB的线程。
20.9 按20.1节的建议,向Thread的实现添加优先级支持,以支持少量的优先级。修改Thread_init和Thread_new,使之可以接受指定优先级为可选参数。[Tanenbaum,1995]描述了如何实现一种支持优先级的公平调度策略。
20.10 DCE支持模板,模板实质上是线程属性的关联表。在用DCE的pthread_create创建一个线程时,模板提供了诸如栈长度和优先级这样的属性。模板可以避免在线程创建调用中重复同样的参数,还使得可以在线程创建位置以外之处指定线程属性。使用Table_T为Thread接口设计一种模板设施,并修改Thread_new,使之可以接受一个模板作为其可选参数。
20.11 在共享内存的多处理器机器(如Sequent)上实现Thread和Sem接口。与20.3节详述的实现相比,这种实现复杂得多,因为此时线程是真正在多处理器上并发执行的。实现原子操作将需要某种形式的底层自旋锁机制,以确保对存取共享数据结构的短临界区的独占访问,就像是Thread和Sem函数中所做的那样。
20.12 在海量并行处理器(Massively Parallel Processor,MPP)上实现Thread、Sem和Chan接口,此类机器的例子如Cray T3D,由2n 个DEC ALPHA处理器组成。在MPP上,每个处理器有自身的内存,有某种底层机制(通常实现在硬件中)供一个处理器访问另一个处理器的内存。该习题提出的挑战之一是,确定如何将Thread、Sem和Chan接口所偏爱的共享内存模型映射到MPP提供的分布式内存模型上。
20.13 使用DCE线程实现Thread、Sem和Chan接口。请务必指明Thread_new的实现接受哪些系统相关的可选参数。
20.14 使用LWP在Solaris 2上实现Thread、Sem和Chan接口,根据需要为Thread_new提供可选参数。
20.15 使用POSIX线程(参见[Kleiman, Shah and Smaalders,1996])实现Thread、Sem和Chan接口。
20.16 使用Microsoft的Win32线程接口(参见[Richter,1995])实现Thread、Sem和Chan接口。
20.17 如果读者能够使用SPARC架构上的C编译器,如lcc [Fraser and Hanson,1995],请修改该编译器使之不使用SPARC寄存器窗口,这可以消除_swtch中的ta 3系统调用。当然,读者也需要重新编译读者使用的任何库。测量在运行时带来的改进。提醒读者:这个习题是一个较大的项目。
20.18 Thread_new必须分配一个栈,因为大多数编译系统假定,在一个程序开始执行时,已经分配了一个连续的栈。少数系统,如Cray-2,以内存块为单位来即时分配栈。函数的入口指令序列需要在当前内存块中分配栈帧(如果放得下),否则,需要分配一个新的足够长的内存块,将其连接到当前内存块中。当内存块中最后一个栈帧被删除后,函数的退出指令序列需要解除内存块的连接并释放该内存块。这种方法不仅简化了线程的创建,也自动地检查了栈溢出。修改某个C编译器来使用这种方法,并测量其好处。类似前一道习题,读者将需要重新编译你使用的任何库,这个习题也是一个大项目。
[1] activation引自activation record,指调用函数时栈帧的表示;同时存在多个activation record,即指函数同时被多次调用。——译者注
[2] 这个仅适用于用户级线程,内核级线程是不受I/O阻塞影响的。——译者注