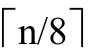 个字节,字节序为最低有效字节首先存储。对于有符号整数,MP使用二进制补码表示,比特位n-1为符号位。
个字节,字节序为最低有效字节首先存储。对于有符号整数,MP使用二进制补码表示,比特位n-1为符号位。三个与算术有关的接口,最后一个是MP,该接口导出的函数实现了无符号整数和(二进制补码)有符号整数的多精度算术。类似于XP,MP公开了对n-bit整数的表示,MP函数可以对给定长度的整数进行操作。与XP不同的是,MP整数长度的单位是比特位,而MP接口函数同时实现了有符号和无符号算术。类似于AP接口函数,MP接口函数会强制实施常见的已检查的运行时错误。
MP同样面向需要扩展精度算术的应用程序,但此类应用程序可能有一些附加的要求,例如,可能需要对内存分配进行更细粒度控制,同时需要无符号和有符号操作,或必须模拟二进制补码下的n-bit算术运算。这种应用程序的例子,包括编译器和使用加密功能的应用程序。一些现代加密算法需要操作包含数百个数位的固定精度整数。
而一些编译器必须使用多精度整数。交叉编译器可能运行在X平台上,却在为Y平台生成代码。如果Y平台上的整数长度比X平台大,编译器可以使用MP来操作Y平台上的整数。另外,编译器还必须使用多精度算术将浮点常数转换为与其最接近的浮点值。
MP接口比较庞大,包括49个函数和两个异常,因为它导出了针对n-bit有符号/无符号整数的一整套算术函数。
〈mp.h 〉≡ #ifndef MP_INCLUDED #define MP_INCLUDED #include <stdarg.h> #include <stddef.h> #include "except.h" #define T MP_T typedef unsigned char *T; 〈exported exceptions 258〉 〈exported functions 258〉 #undef T #endif
类似于XP接口,MP公开了n-bit整数的表示,即
个字节,字节序为最低有效字节首先存储。对于有符号整数,MP使用二进制补码表示,比特位n-1为符号位。
不同于XP接口函数,MP中的函数实现了常见的已检查的运行时错误,例如,向该接口中任意函数传递的MP_T为NULL,都是已检查的运行时错误。但是,如果传递的MP_T参数太小,以至于无法保存n-bit整数,则是未检查的运行时错误。
MP自动初始化来对32位整数执行算术操作。可以调用
〈exported functions
258〉≡
extern int MP_set(int n);
修改MP的设置,使得后续调用执行n-bit算术。MP_set返回此前设定的整数长度。如果n小于2,则造成已检查的运行时错误。在初始化后,大多数应用程序只使用同一长度的扩展整数。例如,交叉编译器可能使用128位算术来操作常数。这种设计迎合了此类应用程序的需求,这简化了其他MP函数的用法,同样简化了其参数列表。省略n是显而易见的简化,但更重要的简化是对源和目标参数不再有限制∶同一MP_T实例总是可以作为源和目标同时出现。消除这些约束是可能的,因为其中一些函数所需的临时空间只依赖于n,因而可以通过MP_set只分配一次。
这种设计也避免了内存分配。MP_set可能引发Mem_Failed异常,但在其他48个MP函数中,仅有4个会进行内存分配。其中之一是
〈exported functions
258〉+≡
extern T MP_new(unsigned long u);
该函数会分配一个适当大小的MP_T实例,将其初始化为u,并返回该实例。
〈exported functions
258〉+≡
extern T MP_fromint (T z, long v);
extern T MP_fromintu(T z, unsigned long u);
这两个函数将z设置为v或u,并返回z。MP_new、MP_fromint和MP_fromintu可能引发下述异常:
〈exported exceptions
258〉≡
extern const Except_T MP_Overflow;
引发该异常的条件是n个比特位无法容纳u或v。MP_new和MP_fromintu在u大于2n -1时引发MP_Overflow异常,而MP_fromint在v小于-2n-1 或大于2n-1 -1时引发MP_Overflow异常。
所有的MP接口函数都在引发异常之前计算结果。多余的比特位只是被丢弃掉。例如,
MP_T z; MP_set(8); z = MP_new(0); MP_fromintu(z, 0xFFF);
将z设置为0xFF并引发MP_Overflow异常。如果这种操作是适当的,客户程序可以使用TRY-EXCEPT语句忽略该异常。例如,
MP_T z;
MP_set(8);
z = MP_new(0);
TRY
MP_fromintu(z, 0xFFF);
EXCEPT(MP_Overflow) ;
END_TRY;
将z设置为0xFF并忽略溢出异常。
这种惯例不适用于下述两个函数
〈exported functions
258〉+≡
extern unsigned long MP_tointu(T x);
extern long MP_toint (T x);
这两个函数将x的值转换为有符号或无符号long型返回。当返回类型无法容纳x的值时,这两个函数都会引发MP_Overflow异常,而且当异常发生时,无法获得转换的部分结果。客户程序可以使用
〈exported functions
258〉+≡
extern T MP_cvt (int m, T z, T x);
extern T MP_cvtu(int m, T z, T x);
将x转换为适当大小的MP_T实例。MP_cvt和MP_cvtu将x转换为m-bit的z中有符号或无符号MP_T实例,并返回z。当m个比特位无法容纳x时,这两个函数会引发MP_Overflow异常,但在引发异常前,这两个函数会将部分结果设置到z。这样,
unsigned char z[sizeof (unsigned)];
TRY
MP_cvtu(8*sizeof (unsigned), z, x);
EXCEPT(MP_Overflow) ;
END_TRY;
会将z设置为x中最低8 * sizeof(unsigned)个比特位,而不管x本身长度如何。
在m超出x中比特位的数目时,MP_cvtu用0填充结果的高位,而MP_cvt用x的符号位填充结果的高位。如果m小于2,则造成已检查的运行时错误,如果z太小而无法容纳m个比特位的整数,则造成未检查的运行时错误。
算术函数如下
〈exported functions
258〉+≡
extern T MP_add (T z, T x, T y);
extern T MP_sub (T z, T x, T y);
extern T MP_mul (T z, T x, T y);
extern T MP_div (T z, T x, T y);
extern T MP_mod (T z, T x, T y);
extern T MP_neg (T z, T x);
extern T MP_addu(T z, T x, T y);
extern T MP_subu(T z, T x, T y);
extern T MP_mulu(T z, T x, T y);
extern T MP_divu(T z, T x, T y);
extern T MP_modu(T z, T x, T y);
函数名以u结尾者实现了无符号算术,而其他函数则实现了二进制补码符号算术。无符号和有符号运算之间唯一的差别是二者的溢出语义,将在下文详述。MP_add、MP_sub、MP_mul、MP_div和MP_mod以及处理无符号整数的对应函数,分别计算z=x+y、z=x-y、z=x·y、z=x/y和z=x mod y,并返回z。斜体表示x、y和z的值。MP_neg将z设置为x的反,并返回z。如果x和y符号不同,MP_div和MP_mod向负无穷大方向舍入,因而x mod y的结果总是正数。
除了MP_divu和MP_modu之外,所有这些函数在z无法容纳计算结果时,都会引发MP_Overflow异常。当x<y时,MP_subu引发MP_Overflow异常,当x和y符号不同且结果的符号不同于x的符号时,MP_sub引发MP_Overflow异常。当y为0时,MP_div、MP_divu、MP_mod和MP_modu将引发下列异常。
〈exported exceptions
258〉+≡
extern const Except_T MP_Dividebyzero;
当y=0时,
〈exported functions
258〉+≡
extern T MP_mul2u(T z, T x, T y);
extern T MP_mul2 (T z, T x, T y);
这两个函数返回的乘积都是乘数的两倍长:二者都计算z=x·y,其中z有2n个比特位,并返回z。因而,结果不会溢出。如果z长度太小,而无法容纳2n个比特位,将造成未检查的运行时错误。请注意,由于z必须能够容纳2n个比特位,它不能通过MP_new分配。
下述便捷函数可以接受一个unsigned long或long作为第二个操作数:
〈exported functions
258〉+≡
extern T MP_addi (T z, T x, long y);
extern T MP_subi (T z, T x, long y);
extern T MP_muli (T z, T x, long y);
extern T MP_divi (T z, T x, long y);
extern T MP_addui(T z, T x, unsigned long y);
extern T MP_subui(T z, T x, unsigned long y);
extern T MP_mului(T z, T x, unsigned long y);
extern T MP_divui(T z, T x, unsigned long y);
extern long MP_modi (T x, long y);
extern unsigned long MP_modui(T x, unsigned long y);
这些函数实际上等价于对应的更通用的函数(只要将后者的第二个操作数初始化为y),也会引发类似的异常。例如,
MP_T z, x; long y; MP_muli(z, x, y);
等效于
MP_T z, x;
long y;
{
MP_T t = MP_new(0);
int overflow = 0;
TRY
MP_fromint(t, y);
EXCEPT(MP_Overflow)
overflow = 1;
END_TRY;
MP_mul(z, x, t);
if (overflow)
RAISE(MP_Overflow);
}
但便捷函数并不进行内存分配操作。请注意,如果y太大,这些便捷函数都会引发MP_Overflow异常,包含MP_divui和MP_modui在内,但这些函数都是在计算z之后才引发异常。
〈exported functions
258〉+≡
extern int MP_cmp (T x, T y);
extern int MP_cmpi (T x, long y);
extern int MP_cmpu (T x, T y);
extern int MP_cmpui(T x, unsigned long y);
上述几个比较x和y,针对x<y、x=y或x>y的情形,分别返回小于零、等于零或大于零的值。MP_cmpi和MP_cmpui并不要求MP_T实例一定能容纳y值,它们只是比较x和y。
下列函数将其输入的MP_T参数当做n比特位的字符串处理:
〈exported functions
258〉+≡
extern T MP_and (T z, T x, T y);
extern T MP_or (T z, T x, T y);
extern T MP_xor (T z, T x, T y);
extern T MP_not (T z, T x);
extern T MP_andi(T z, T x, unsigned long y);
extern T MP_ori (T z, T x, unsigned long y);
extern T MP_xori(T z, T x, unsigned long y);
MP_and、MP_or、MP_xor,以及对应的用“立即数”(指直接传递unsigned long参数)作为参数的函数,分别将z设置为x和y的按位与、按位或、异或,并返回z。MP_not将z设置为等于x按位取反,并返回z。这些函数从不引发异常,在y过大时,对应的便捷函数将忽略可能发生的溢出。例如,
MP_T z, x; unsigned long y; MP_andi(z, x, y);
等效于
MP_T z, x;
unsigned long y;
{
MP_T t = MP_new(0);
TRY
MP_fromintu(t, y);
EXCEPT(MP_Overflow) ;
END_TRY;
MP_and(z, x, t);
}
但这些便捷函数也都不进行内存分配操作。以下是三个移位操作函数
〈exported functions
258〉+≡
extern T MP_lshift(T z, T x, int s);
extern T MP_rshift(T z, T x, int s);
extern T MP_ashift(T z, T x, int s);
这三个函数实现了逻辑移位和算术移位。MP_lshift将z设置为x左移s个比特位,MP_rshift将z设置为x右移s个比特位。这两个函数都用0填充空出的比特位,并返回z。MP_ashift类似于MP_rshift,但用x的符号位填充空出的比特位。传递负的s值,是一个已检查的运行时错误。
下列函数负责MP_T与字符串的转换。
〈exported functions
258〉+≡
extern T MP_fromstr(T z, const char *str,
int base, char **end);
extern char *MP_tostr (char *str, int size,
int base, T x);
extern void MP_fmt (int code, va_list *app,
int put(int c, void *cl), void *cl,
unsigned char flags[], int width, int precision);
extern void MP_fmtu (int code, va_list *app,
int put(int c, void *cl), void *cl,
unsigned char flags[], int width, int precision);
MP_fromstr将str中的字符串解释为base基数下的一个无符号整数,将z设置为该整数,并返回z。该函数忽略字符串开头的空白,并处理其后以base为基数的一个或多个数位。对大于10的基数来说,小写和大写字母用于指定超过9的数位。MP_fromstr类似于strtoul:如果end不是NULL,MP_fromstr将*end设置为扫描结束处字符的地址。如果str没有指定一个有效的整数,且end不是NULL,MP_fromstr将*end设置为str,并返回NULL。如果str中的字符串指定了一个过大的整数,MP_fromstr将引发MP_Overflow异常。str为NULL,或者base小于2或大于36,都是已检查的运行时错误。
MP_tostr用一个0结尾字符串填充str[0..size - 1],该字符串表示在基数base下的x,最后返回str。如果str为NULL,MP_tostr忽略size并分配必要的字符串,客户程序负责释放该字符串。如果base小于2或大于36,或str不是NULL,而size太小导致str无法容纳生成的0结尾字符串,则造成已检查的运行时错误。在str是NULL时,MP_tostr可能引发Mem_Failed异常。
MP_fmt和MP_fmtu是Fmt风格的转换函数,用于输出MP_T实例。二者都消耗一个MP_T和一个基数,MP_fmt将有符号MP_T转换为字符串,MP_fmtu将无符号MP_T转换为字符串,前者使用类似于printf的%d限定符,后者使用类似于printf的%u限定符。这两个函数都可能引发Mem_Failed异常。app或flags是NULL,则为已检查的运行时错误。
mpcalc类似于calc,只是对n-bit整数执行有符号和无符号计算而已。它示范了MP接口的用法。类似于calc,mpcalc使用了波兰后缀表示法(Polish suffix notation):值被推入栈上,运算符将其操作数从栈中弹出,并将运算结果再次推入栈上。值是当前输入基数下的一个或多个连续的数位,而支持的运算符如下。
~ 取反
& 与
+ 加法
| 或
- 减法
^ 异或
* 乘法
< 左移
/ 除法
> 右移
% 取模
! 否
i 设置输入基数
o 设置输出基数
k 设置精度
c 清空栈
d 复制栈顶部的值
p 输出栈顶部的值
f 自顶向下,输出栈上所有的值
q 退出
空格字符用于分隔值,其他情况下忽略空格,其他字符被作为无法识别的运算符处理。栈的大小只受可用内存的限制,但发生栈下溢会出现诊断消息。
命令nk指定了mpcalc操作的整数的长度,其中n至少为2,默认值为32。当执行k运算符时,栈必须为空。i和o运算符指定了输入输出基数,二者的默认值都是10。当输入基数超出10时,一个值的第一个数位必须在0到9之间(含)。
如果输出基数为2、8或16,+-*/和%运算符执行无符号算术,而p和f运算符输出无符号值。对所有其他基数,+-*/和%执行有符号算术,p和f输出有符号值。~运算符总是执行有符号算术,而&|^!<和>运算符总是将其操作数解释为无符号数。
mpcalc在出现溢出和除以零时,会通知用户。溢出情况下的结果,是值的最低n个比特位。对于除以零,结果为零。
mpcalc的整体结构与calc非常相似:它解释输入、计算值、并管理一个栈。
〈mpcalc.c 〉≡ #include <ctype.h> #include <stdio.h> #include <string.h> #include <stdlib.h> #include <limits.h> #include "mem.h" #include "seq.h" #include "fmt.h" #include "mp.h" 〈mpcalc data 264〉 〈mpcalc functions 264〉
包含seq.h表明,mpcalc使用序列来实现栈:
〈mpcalc data 264〉≡ Seq_T sp; 〈initialization 264〉≡ sp = Seq_new(0);
值通过调用Seq_addhi压栈,通过调用Seq_remhi从栈中弹出。在序列为空时,mpcalc不能调用Seq_remhi,因此它将所有的弹栈操作都封装在一个函数中,其中检查了栈下溢的情形。
〈mpcalc functions
264〉≡
MP_T pop(void) {
if (Seq_length(sp) > 0)
return Seq_remhi(sp);
else {
Fmt_fprint(stderr, "?stack underflow\n");
return MP_new(0);
}
}
类似于calc的pop函数,mpcalc的pop函数总是返回一个MP_T实例,即使栈为空也是如此,因为这样做简化了错误检查。
mpcalc的主循环需要处理MP接口的异常,因此比calc的主循环复杂一点。类似于calc的主循环,mpcalc的主循环读取下一个值或运算符,如果读取到运算符,则执行对应的操作。它也准备了一些MP_T实例,用于保存操作数和结果,它使用TRY-EXCEPT语句来捕获异常。
〈mpcalc functions 264〉+≡ int main(int argc, char *argv[]) { int c; 〈initialization 264〉 while ((c = getchar()) != EOF) { volatile MP_T x = NULL, y = NULL, z = NULL; TRY switch (c) { 〈cases 265〉 } EXCEPT(MP_Overflow) Fmt_fprint(stderr, "?overflow\n"); EXCEPT(MP_Dividebyzero) Fmt_fprint(stderr, "?divide by 0\n"); END_TRY; if (z) Seq_addhi(sp, z); FREE(x); FREE(y); } 〈clean up and exit 265〉 } 〈clean up and exit 265〉≡ 〈clear the stack 265〉 Seq_free(&sp); return EXIT_SUCCESS;
x和y用于表示操作数,z用于表示结果。如果在处理一个运算符之后x和y不是NULL,那么二者保存了由栈中弹出的操作数,因而必须释放。如果z不是NULL,则其中保存了结果,必须压栈。这种方法允许TRY-EXCEPT语句只出现一次,而无需对处理每个运算符的代码都使用。
一个输入字符或者为空格,或者是值的第一个数位,或者是运算符,或是其他(将导致错误)。这里是易于处理的情形:
〈cases 265〉≡ default: if (isprint(c)) Fmt_fprint(stderr, "?'%c'", c); else Fmt_fprint(stderr, "?'\\%03o'", c); Fmt_fprint(stderr, " is unimplemented\n"); break; case ' ': case '\t': case '\n': case '\f': case '\r': break; case 'c':〈clear the stack 265〉 break; case 'q':〈clean up and exit 265〉 〈clear the stack 265〉≡ while (Seq_length(sp) > 0) { MP_T x = Seq_remhi(sp); FREE(x); }
数字字符标识值的开始,mpcalc收集各个数位,并调用MP_fromstr将其转换为MP_T实例。ibase是当前输入基数。
〈cases 265〉≡ case '0': case '1': case '2': case '3': case '4': case '5': case '6': case '7': case '8': case '9': { char buf[512]; z = MP_new(0); 〈gather up digits into buf 266〉 MP_fromstr(z, buf, ibase, NULL); break; } 〈gather up digits into buf 266〉≡ { int i = 0; for ( ; 〈c is a digit in ibase 266〉; c = getchar(), i++) if (i < (int)sizeof (buf) - 1) buf[i] = c; if (i > (int)sizeof (buf) - 1) { i = (int)sizeof (buf) - 1; Fmt_fprint(stderr, "?integer constant exceeds %d digits\n", i); } buf[i] = '\0'; if (c != EOF) ungetc(c, stdin); }
发现超长值时,会通知用户,并截断该值。对字符c来说,如果下述调用的结果不是NULL,c即为ibase基数下的一个数位:
〈c is a digit in
ibase 266〉≡
strchr(&"zyxwvutsrqponmlkjihgfedcba9876543210"[36-ibase],
tolower(c))
处理大部分算术运算符的case语句都具有同样的形式:
〈cases 265〉+≡ case '+': 〈pop x & y, set z 266〉 (*f->add)(z, x, y); break; case '-': 〈pop x & y, set z 266〉 (*f->sub)(z, x, y); break; case '*': 〈pop x & y, set z 266〉 (*f->mul)(z, x, y); break; case '/': 〈pop x & y, set z 266〉 (*f->div)(z, x, y); break; case '%': 〈pop x & y, set z 266〉 (*f->mod)(z, x, y); break; case '&': 〈pop x & y, set z 266〉 MP_and(z, x, y); break; case '|': 〈pop x & y, set z 266〉 MP_or (z, x, y); break; case '^': 〈pop x & y, set z 266〉 MP_xor(z, x, y); break; case '!': z = pop(); MP_not(z, z); break; case '~': z = pop(); MP_neg(z, z); break; 〈pop x & y, set z 266〉≡ y = pop(); x = pop(); z = MP_new(0);
f指向一个结构实例,其中保存了一些函数指针,具体指向哪些函数取决于mpcalc是执行有符号算术还是无符号算术。
〈mpcalc data
264〉+≡
int ibase = 10;
int obase = 10;
struct {
const char *fmt;
MP_T (*add)(MP_T, MP_T, MP_T);
MP_T (*sub)(MP_T, MP_T, MP_T);
MP_T (*mul)(MP_T, MP_T, MP_T);
MP_T (*div)(MP_T, MP_T, MP_T);
MP_T (*mod)(MP_T, MP_T, MP_T);
} s = { "%D\n",
MP_add, MP_sub, MP_mul, MP_div, MP_mod },
u = { "%U\n",
MP_addu, MP_subu, MP_mulu, MP_divu, MP_modu },
*f = &s;
obase是输出基数。最初,输入输出两个基数都是10,f指向s,其中的函数指针指向执行有符号算术的MP函数。i运算符可以改变ibase,o运算符可以改变obase,这两个运算符都可能修改f,使之指向u或s:
〈cases
265〉+≡
case 'i': case 'o': {
long n;
x = pop();
n = MP_toint(x);
if (n < 2 || n > 36)
Fmt_fprint(stderr, "?%d is an illegal base\n",n);
else if (c == 'i')
ibase = n;
else
obase = n;
if (obase == 2 || obase == 8 || obase == 16)
f = &u;
else
f = &s;
break;
}
如果x不能转换为为long(即MP_toint引发MP_Overflow异常),或MP_toint返回的结果整数不是一个合法的基数,那么基数不会改变。
s和u两个结构实例中也包含了一个Fmt风格的格式串,用于输出MP_T实例。mpcalc将MP_fmt注册到%D格式限定符,而将MP_fmtu注册到%U限定符:
〈initialization
264〉+≡
Fmt_register('D', MP_fmt);
Fmt_register('U', MP_fmtu);
因而f->fmt可以访问到适当的格式串,运算符p和f使用这些格式串输出MP_T实例。请注意,p将其操作数从栈中弹出到z中,而主循环中的代码又将该值压回栈中。
〈cases
265〉+≡
case 'p':
Fmt_print(f->fmt, z = pop(), obase);
break;
case 'f': {
int n = Seq_length(sp);
while (--n >= 0)
Fmt_print(f->fmt, Seq_get(sp, n), obase);
break;
}
对照calc的代码(参见18.2节),比较二者对运算符f的处理,当用Seq_T表示栈时,很容易输出栈中全部的值。
移位运算符会检查非法的移位数量,并就地移位其操作数:
〈cases 265〉+≡ case '<': { 〈get s & z 268〉; MP_lshift(z, z, s); break; } case '>': { 〈get s & z 268〉; MP_rshift(z, z, s); break; } 〈get s & z 268〉≡ long s; y = pop(); z = pop(); s = MP_toint(y); if (s < 0 || s > INT_MAX) { Fmt_fprint(stderr, "?%d is an illegal shift amount\n", s); break; }
如果MP_toint引发MP_Overflow异常,或s是负数或超出最大的int值,操作数z只是被压回栈上。
余下的case语句,用于处理运算符k和d:
〈cases
265〉+≡
case 'k': {
long n;
x = pop();
n = MP_toint(x);
if (n < 2 || n > INT_MAX)
Fmt_fprint(stderr,
"?%d is an illegal precision\n", n);
else if (Seq_length(sp) > 0)
Fmt_fprint(stderr, "?nonempty stack\n");
else
MP_set(n);
break;
}
case 'd': {
MP_T x = pop();
z = MP_new(0);
Seq_addhi(sp, x);
MP_addui(z, x, 0);
break;
}
同样,对z赋值后,该值会被主循环中的代码压栈。
〈mp.c 〉≡ #include <ctype.h> #include <string.h> #include <stdio.h> #include <stdlib.h> #include <limits.h> #include "assert.h" #include "fmt.h" #include "mem.h" #include "xp.h" #include "mp.h" #define T MP_T 〈macros 270〉 〈data 269〉 〈static functions 281〉 〈functions 270〉 〈data 269〉≡ const Except_T MP_Dividebyzero = { "Division by zero" }; const Except_T MP_Overflow = { "Overflow" };
XP接口将一个(二进制下)n-bit数表示为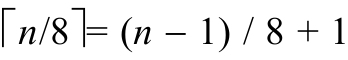 个字节,最低有效字节在先(n总是正数)。下图说明了MP接口如何解释这些字节。图中最右侧为最低有效字节,由此向左,地址逐渐增大。
个字节,最低有效字节在先(n总是正数)。下图说明了MP接口如何解释这些字节。图中最右侧为最低有效字节,由此向左,地址逐渐增大。
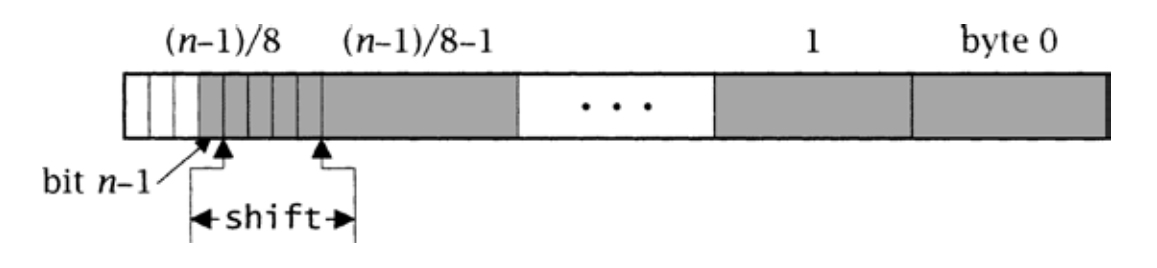
符号位为比特位n-1,即字节(n-1)/8中的比特位(n-1) mod 8。给定n,MP除了将n保存为nbits之外,还计算三个其关注的值:nbytes,容纳n个比特位所需的字节数;shift,计算符号位时,最高有效字节必须右移的比特位数;和msb,一个掩码,其中有shift+1个比特位置位,用于检测溢出。当n为32时,这些值分别是:
〈data
269〉+≡
static int nbits = 32;
static int nbytes = (32-1)/8 + 1;
static int shift = (32-1)%8;
static unsigned char msb = 0xFF;
根据上述的建议,MP使用nbytes和shift访问符号位:
〈macros
270〉≡
#define sign(x) ((x)[nbytes-1]>>shift)
这些值通过MP_set改变:
〈functions 270〉≡ int MP_set(int n) { int prev = nbits; assert(n > 1); 〈initialize 270〉 return prev; } 〈initialize 270〉≡ nbits = n; nbytes = (n-1)/8 + 1; shift = (n-1)%8; msb = ones(n); 〈macros 270〉+≡ #define ones(n) (~(~0UL<<(((n)-1)%8+1)))
将~0左移(n-1)%8+1个比特位,形成如下的掩码:一连串值为1的比特位,后接(n-1) mod 8+1个值为0的比特位,取反后,掩码的最低位部分,有(n-1) mod 8+1个置位的比特位。之所以用这种方法定义ones宏,是因为除了传递给MP_set的值之外,它还用作其他的n值。
MP_set还分配了一些临时空间,供算术函数使用,如MP_div。因而,该分配操作只在MP_set中进行一次,而不是在各个算术函数中重复进行。MP_set分配了足够的空间,可容纳一个占2·nbyte+2字节的临时MP_T实例,和三个占用nbyte字节的临时MP_T实例。
〈data 269〉+≡ static unsigned char temp[16 + 16 + 16 + 2*16+2]; static T tmp[] = {temp, temp+1*16, temp+2*16, temp+3*16}; 〈initialize 270〉+≡ if (tmp[0] != temp) FREE(tmp[0]); if (nbytes <= 16) tmp[0] = temp; else tmp[0] = ALLOC(3*nbytes + 2*nbytes + 2); tmp[1] = tmp[0] + 1*nbytes; tmp[2] = tmp[0] + 2*nbytes; tmp[3] = tmp[0] + 3*nbytes;
当nbytes不超过16时(或当n不超过128时),MP_set可以使用静态分配的temp。否则,它必须为临时变量分配空间。temp是必需的,因为MP的初始化语义,已经隐含了MP_set(32)的语义。
大部分MP函数都调用XP接口函数,来对nbyte字节的数值执行实际的算术运算,接下来检查结果是否超过nbits个比特位。MP_new和MP_fromintu说明了这种策略。
〈functions 270〉+≡ T MP_new(unsigned long u) { return MP_fromintu(ALLOC(nbytes), u); } T MP_fromintu(T z, unsigned long u) { unsigned long carry; assert(z); 〈set z to u 271〉 〈test for unsigned overflow 271〉 return z; } 〈set z to u 271〉≡ carry = XP_fromint(nbytes, z, u); carry |= z[nbytes-1]& ~msb; z[nbytes-1] &= msb;
如果XP_fromint返回非零的carry值,那么nbytes个字节无法容纳u。如果carry为0,那么nbytes个字节可以容纳u,但nbits个比特位不见得能容纳u。MP_fromintu必须确保,在z的最高有效字节中,8 - (shift + 1)个最高有效比特位都是0。MP_set已经将msb设置为一个掩码,在最低有效位部分有shift+1个1,因此~msb可用于隔离出MP_fromintu所需的各比特位,然后需要将该值按位或到carry中,以判断是否有溢出。测试无符号溢出时,只需要检测carry:
〈test for unsigned overflow
271〉≡
if (carry)
RAISE(MP_Overflow);
请注意,MP_fromintu在检测溢出之前,已经设置了z的值,按照接口说明,所有MP函数都必须在引发异常之前设置其结果。
检验有符号溢出稍微有点复杂,因为这取决于涉及的操作。MP_fromint说明了一个简单情形。
〈functions 270〉+≡ T MP_fromint(T z, long v) { assert(z); 〈set z to v 272〉 if (〈v is too big 272〉) RAISE(MP_Overflow); return z; }
首先,MP_fromint将z初始化为v的值,并注意只向XP_fromint传递正值:
〈set z to v 272〉≡ if (v == LONG_MIN) { XP_fromint(nbytes, z, LONG_MAX + 1UL); XP_neg(nbytes, z, z, 1); } else if (v < 0) { XP_fromint(nbytes, z, -v); XP_neg(nbytes, z, z, 1); } else XP_fromint(nbytes, z, v); z[nbytes-1] &= msb;
前两个if子句处理负值:z首先设置为v的绝对值,然后求补(将1作为XP_neg的第四个参数)。MP_fromint必须专门处理大部分负整数,因为它不能对其取反。如果v为负数,z的最高位部分各个比特位都是1,过多的比特位必须丢弃。许多MP函数使用上文给出的z[ nbytes - 1] &= msb惯用法,来丢弃z的最高有效字节中过多的比特位。
对于MP_fromint,当nbits小于long的位宽且v超出了z的表示范围时,将出现符号溢出。
〈v is too big
272〉≡
(nbits < 8*(int)sizeof (v) &&
(v < -(1L<<(nbits-1)) || v >= (1L<<(nbits-1))))
上式中的两个移位表达式,分别计算了位宽为n的有符号整数中最小的负数和最大的正数。
MP_toint和MP_cvt说明了检查符号溢出的另一个例子:
〈functions
270〉+≡
long MP_toint(T x) {
unsigned char d[sizeof (unsigned long)];
assert(x);
MP_cvt(8*sizeof d, d, x);
return XP_toint(sizeof d, d);
}
如果d无法容纳x,MP_cvt将引发MP_Overflow异常,如果d可以容纳x,XP_toint返回期望值。
MP_cvt进行了两种转换:它会将位宽较大的MP_T实例转换为位宽较小的MP_T实例,同样也包括相反的过程。
〈functions 270〉+≡ T MP_cvt(int m, T z, T x) { int fill, i, mbytes = (m - 1)/8 + 1; assert(m > 1); 〈checked runtime errors for unary functions 273〉 fill = sign(x) ? 0xFF : 0; if (m < nbits) { 〈narrow signed x 273〉 } else { 〈widen signed x 274〉 } return z; } 〈checked runtime errors for unary functions 273〉≡ assert(x); assert(z);
如果m小于nbits,MP_cvt将“缩窄”x,并将其赋值给z。这种情况必须检查符号溢出。如果x中的比特位m-1 [1] 到比特位nbits-1,或者为全0,或者为全1,那么m个比特位即可容纳x,即,如果x中过多的比特位都等于x的符号位,那么即可将x当做位宽为m的整数处理。在下述的代码块中,如果x为负数,fill为0xFF,否则fill为0 ,因此,如果比特位x [m - 1..nbits - 1] [2] 都是1或都是0,x[i] ^ fill应该为0。
〈narrow signed x 273〉≡ int carry = (x[mbytes-1]^fill) & ~(ones(m) >> 1) [3] ; for (i = mbytes; i < nbytes; i++) carry |= x[i]^fill; memcpy(z, x, mbytes); z[mbytes-1] &= ones(m); if (carry) RAISE(MP_Overflow);
如果x在范围内,carry最终的值为0,否则,carry的一些比特位将变为1。对carry的初始赋值,忽略了z中非符号位的比特位 [4] 。
如果m不小于nbits,MP_cvt将“加宽”x,并将其赋值给z。这种情况下不会发生溢出,但MP_cvt必须扩展x的符号位,符号位由fill给出。
〈widen signed
x 274〉≡
memcpy(z, x, nbytes);
z[nbytes-1] |= fill& ~msb;
for (i = nbytes; i < mbytes; i++)
z[i] = fill;
z[mbytes-1] &= ones(m);
MP_tointu使用一种类似的方法:它通过调用MP_cvtu将x转换为一个MP_T实例,后者的位宽等同于unsigned long,然后调用XP_toint返回其值。
〈functions
270〉+≡
unsigned long MP_tointu(T x) {
unsigned char d[sizeof (unsigned long)];
assert(x);
MP_cvtu(8*sizeof d, d, x);
return XP_toint(sizeof d, d);
}
同样,MP_cvtu或者“缩窄”x,或者“加宽”x,然后将其赋值给z。
〈functions 270〉+≡ T MP_cvtu(int m, T z, T x) { int i, mbytes = (m - 1)/8 + 1; assert(m > 1); 〈checked runtime errors for unary functions 273〉 if (m < nbits) { 〈narrow unsigned x 274〉 } else { 〈widen unsigned x 274〉 } return z; }
当m小于nbits时,如果x的比特位m到nbits-1中,有任何一个比特位为1,都会造成溢出,检查该情形的代码类似于MP_cvt中使用的代码,但要简单些:
〈narrow unsigned x 274〉≡ int carry = x[mbytes-1]& ~ones(m); for (i = mbytes; i < nbytes; i++) carry |= x[i]; memcpy(z, x, mbytes); z[mbytes-1] &= ones(m); 〈test for unsigned overflow 271〉
当m不小于nbits时,不可能发生溢出,z中多余的比特位将清零:
〈widen unsigned
x 274〉≡
memcpy(z, x, nbytes);
for (i = nbytes; i < mbytes; i++)
z[i] = 0;
如MP_cvtu和MP_cvt的代码所示,与对应的有符号算术函数相比,无符号算术函数更易于实现,因为它们不需要处理符号,而且溢出的检查更为简单。无符号加法说明了一种容易的情形,XP_add完成了所有的工作。
〈functions 270〉+≡ T MP_addu(T z, T x, T y) { int carry; 〈checked runtime errors for binary functions 275〉 carry = XP_add(nbytes, z, x, y, 0); carry |= z[nbytes-1]& ~msb; z[nbytes-1] &= msb; 〈test for unsigned overflow 271〉 return z; } 〈checked runtime errors for binary functions 275〉≡ assert(x); assert(y); assert(z);
减法同样简单,但出现“悬挂”借位(最高位出现借位)时,将引发MP_Overflow异常:
〈functions 270〉+≡ T MP_subu(T z, T x, T y) { int borrow; 〈checked runtime errors for binary functions 275〉 borrow = XP_sub(nbytes, z, x, y, 0); borrow |= z[nbytes-1]& ~msb; z[nbytes-1] &= msb; 〈test for unsigned underflow 275〉 return z; } 〈test for unsigned underflow 275〉≡ if (borrow) RAISE(MP_Overflow);
MP_mul2u是最简单的乘法函数,因为其中不可能出现溢出。
〈functions 270〉+≡ T MP_mul2u(T z, T x, T y) { 〈checked runtime errors for binary functions 275〉 memset(tmp[3], '\0', 2*nbytes); XP_mul(tmp[3], nbytes, x, nbytes, y); memcpy(z, tmp[3], (2*nbits - 1)/8 + 1); return z; }
MP_mul2u将结果计算到tmp[3]中,然后将tmp[3]复制到z;这使得在调用时,可以将x或y用作z,如果MP_mul2u将结果直接计算到z中,这样就行不通了。因而,在MP_set中分配临时空间的做法,不仅隔离了分配操作,也避免了对x和y的限制。
MP_mul也调用了XP_mul来计算一个两倍长度的结果保存到tmp[3],然后将该结果的位宽“缩窄”到nbits,并将其赋值给z。
〈functions 270〉+≡ T MP_mulu(T z, T x, T y) { 〈checked runtime errors for binary functions 275〉 memset(tmp[3], '\0', 2*nbytes); XP_mul(tmp[3], nbytes, x, nbytes, y); memcpy(z, tmp[3], nbytes); z[nbytes-1] &= msb; 〈test for unsigned multiplication overflow 276〉 return z; }
如果tmp[3]的比特位nbits到2 * nbits - 1中,有任何比特位是1,乘积都会溢出。基本上,可以用MP_cvtu中测试类似情况的方法,来检测这种情况:
〈test for unsigned multiplication overflow
276〉≡
{
int i;
if (tmp[3][nbytes-1]& ~msb)
RAISE(MP_Overflow);
for (i = 0; i < nbytes; i++)
if (tmp[3][i+nbytes] != 0)
RAISE(MP_Overflow);
}
通过将y复制到一个临时变量,MP_divu避免了XP_div对其参数的限制:
〈functions 270〉+≡ T MP_divu(T z, T x, T y) { 〈checked runtime errors for binary functions 275〉 〈copy y to a temporary 276〉 if (!XP_div(nbytes, z, x, nbytes, y, tmp[2], tmp[3])) RAISE(MP_Dividebyzero); return z; } 〈copy y to a temporary 276〉≡ { memcpy(tmp[1], y, nbytes); y = tmp[1]; }
tmp[2]包含了余数,将被丢弃,y的值首先复制到tmp[1],而后y又设置为指向tmp[1]对应的MP_T实例。tmp[3]是XP_div所需的长度为2 * nbyte + 2个字节的临时变量。MP_modu类似,但它使用tmp[2]来保存商:
〈functions 270〉+≡ T MP_modu(T z, T x, T y) { 〈checked runtime errors for binary functions 275〉 〈copy y to a temporary 276〉 if (!XP_div(nbytes, tmp[2], x, nbytes, y, z, tmp[3])) RAISE(MP_Dividebyzero); return z; }
AP接口的符号—绝对值表示法,强制要求AP_add考虑x和y的符号。二进制补码表示的性质,使得MP_add可以避免这种按情况分析的做法,无论x和y的符号如何,只需要调用XP_add即可。因而,有符号加法几乎与无符号加法相同,唯一重要的区别是对溢出的检测。
〈functions 270〉+≡ T MP_add(T z, T x, T y) { int sx, sy; 〈checked runtime errors for binary functions 275〉 sx = sign(x); sy = sign(y); XP_add(nbytes, z, x, y, 0); z[nbytes-1] &= msb; 〈test for signed overflow 277〉 return z; }
在加法中,当x和y符号相同时,才可能发生溢出。当和值溢出时,其符号不同于x和y的符号:
〈test for signed overflow
277〉≡
if (sx == sy && sy != sign(z))
RAISE(MP_Overflow);
有符号减法的形式与加法相同,但对溢出的检测不同。
〈functions 270〉+≡ T MP_sub(T z, T x, T y) { int sx, sy; 〈checked runtime errors for binary functions 275〉 sx = sign(x); sy = sign(y); XP_sub(nbytes, z, x, y, 0); z[nbytes-1] &= msb; 〈test for signed underflow 278〉 return z; }
对于减法来说,当x和y符号不同时,才可能发生下溢。当x为正数而y为负数时,结果应该是正数,当x为负数而y为正数时,结果应该是负数。因而,如果x和y符号不同,而结果的符号与y相同,那么就发生了下溢。
〈test for signed underflow
278〉≡
if (sx != sy && sy == sign(z))
RAISE(MP_Overflow);
对x取反,等效于从零减去x:仅当x为负数时,才可能发生溢出,当结果上溢时,其仍然为负数。
〈functions 270〉+≡ T MP_neg(T z, T x) { int sx; 〈checked runtime errors for unary functions 273〉 sx = sign(x); XP_neg(nbytes, z, x, 1); z[nbytes-1] &= msb; if (sx && sx == sign(z)) RAISE(MP_Overflow); return z; }
MP_neg必须清除z高位部分的过多比特位,因为当x是正数时,这些比特位都将是0。
实现符号乘法最容易的方式是,对负的操作数取反,执行无符号乘法,当两个操作数符号不同时,再对结果取反。对于MP_mul2,不可能发生溢出,因为它计算了一个双倍长度的结果,其细节易于填充:
〈functions 270〉+≡ T MP_mul2(T z, T x, T y) { int sx, sy; 〈checked runtime errors for binary functions 275〉 〈tmp[3] ← x·y 278〉 if (sx != sy) XP_neg((2*nbits - 1)/8 + 1, z, tmp[3], 1); else memcpy(z, tmp[3], (2*nbits - 1)/8 + 1); return z; } 〈tmp[3] ← x·y 278〉≡ sx = sign(x); sy = sign(y); 〈if x < 0, negate x 278〉 〈if y < 0, negate y 279〉 memset(tmp[3], '\0', 2*nbytes); XP_mul(tmp[3], nbytes, x, nbytes, y);
乘积有2 * nbits个比特位,只需要z有(2 * nbits - 1)/8+1个字节。x和y会在必要时取反,取反后的值保存在适当的临时变量中,而后使x或y重新指向临时变量。
〈if x < 0, negate x 278〉≡ if (sx) { XP_neg(nbytes, tmp[0], x, 1); x = tmp[0]; x[nbytes-1] &= msb; } 〈if y < 0, negate y 279〉≡ if (sy) { XP_neg(nbytes, tmp[1], y, 1); y = tmp[1]; y[nbytes-1] &= msb; }
按照惯例,MP接口函数在必要时会将x和y取反,或复制到tmp[0]和tmp[1]中。
MP_mul类似于MP_mul2,但在2 * nbits个比特位的结果中,只有最低位nbits个比特位复制到z。当nbits个比特位无法容纳结果时、或操作数符号相同而结果为负数时,将产生溢出。
〈functions 270〉+≡ T MP_mul(T z, T x, T y) { int sx, sy; 〈checked runtime errors for binary functions 275〉 〈tmp[3] ← x·y 278〉 if (sx != sy) XP_neg(nbytes, z, tmp[3], 1); else memcpy(z, tmp[3], nbytes); z[nbytes-1] &= msb; 〈test for unsigned multiplication overflow 276〉 if (sx == sy && sign(z)) RAISE(MP_Overflow); return z; }
当操作数符号相同时,有符号除法非常类似于无符号除法,因为商和余数都是非负的。仅当被除数是(n-bit数中)最小的负数、且除数为-1时,才会发生溢出,这种情况下,商将是负数。
〈functions 270〉+≡ T MP_div(T z, T x, T y) { int sx, sy; 〈checked runtime errors for binary functions 275〉 sx = sign(x); sy = sign(y); 〈if x < 0, negate x 278〉 〈if y < 0, negate y 279〉 else 〈copy y to a temporary 276〉 if (!XP_div(nbytes, z, x, nbytes, y, tmp[2], tmp[3])) RAISE(MP_Dividebyzero); if (sx != sy) { 〈adjust the quotient 280〉 } else if (sx && sign(z)) RAISE(MP_Overflow); return z; }
MP_div或者对y取反,把结果保存到临时变量中,或者将y直接复制到临时变量中,因为y和z可能指向同一MP_T实例,该函数使用tmp[2]保存余数。
对有符号除法和取模操作来说,比较复杂的情形是,两个操作数符号不同时。在这种情况下,商是负数但必须向负无穷大方向舍入,余数是正数。其中需要进行的校正,与AP_div和AP_mod所作的相同:把商取反,如果余数非零,则将商减1。另外,如果无符号余数非零,y减去该余数,即为正确的余数值。
〈adjust the quotient 280〉≡ XP_neg(nbytes, z, z, 1); if (!iszero(tmp[2])) XP_diff(nbytes, z, z, 1); z[nbytes-1] &= msb; 〈macros 270〉+≡ #define iszero(x) (XP_length(nbytes,(x))==1 && (x)[0]==0)
MP_div并不校正余数,因为余数丢弃掉了。MP_mod所作的刚好相反:它只校正余数,使用tmp[2]来保存商。
〈functions 270〉+≡ T MP_mod(T z, T x, T y) { int sx, sy; 〈checked runtime errors for binary functions 275〉 sx = sign(x); sy = sign(y); 〈if x < 0, negate x 278〉 〈if y < 0, negate y 279〉 else 〈copy y to a temporary 276〉 if (!XP_div(nbytes, tmp[2], x, nbytes, y, z, tmp[3])) RAISE(MP_Dividebyzero); if (sx != sy) { if (!iszero(z)) XP_sub(nbytes, z, y, z, 0); } else if (sx && sign(tmp[2])) RAISE(MP_Overflow); return z; }
算术便捷函数用一个long或unsigned long作为立即操作数,如有必要将其转换为MP_T实例,而后执行对应的算术操作。当y在基数28 下只有单个数位时,这些函数可以使用XP接口导出的单数位函数。但有两种情况可能导致溢出:y太大,或操作本身可能溢出。如果y太大,这些函数必须在引发异常之前完成操作并赋值给z。MP_addui说明了所有便捷函数使用的这种方法:
〈functions 270〉+≡ T MP_addui(T z, T x, unsigned long y) { 〈checked runtime errors for unary functions 273〉 if (y < BASE) { int carry = XP_sum(nbytes, z, x, y); carry |= z[nbytes-1]& ~msb; z[nbytes-1] &= msb; 〈test for unsigned overflow 271〉 } else if (applyu(MP_addu, z, x, y)) RAISE(MP_Overflow); return z; } 〈macros 270〉+≡ #define BASE (1<<8)
如果y只有一个数位,XP_sum可以计算x+y。当nbits小于8且y太大时,该代码也能检测到溢出,因为和值对任何x值来说,都太大了。否则,MP_addui调用applyu将y转换为MP_T实例,以便使用更通用的函数MP_addu。如果y太大,applyu仅会在计算z之后返回1:
〈static functions 281〉≡ static int applyu(T op(T, T, T), T z, T x, unsigned long u) { unsigned long carry; { T z = tmp[2]; 〈set z to u 271〉 } op(z, x, tmp[2]); return carry != 0; }
applyu使用MP_fromintu中的代码将unsigned long操作数转换到tmp[2]中。它保存了转换操作出现的进位,因为转换也可能溢出。接下来它调用其第一个参数指定的函数,如果保存的进位值非零,则返回1,否则返回0。函数op也可能引发异常,但仅当设置z值之后,才会引发异常。
无符号减法和乘法的便捷函数是类似的。当y小于28 时,MP_subui调用MP_diff。
〈functions 270〉+≡ T MP_subui(T z, T x, unsigned long y) { 〈checked runtime errors for unary functions 275〉 if (y < BASE) { int borrow = XP_diff(nbytes, z, x, y); borrow |= z[nbytes-1]& ~msb; z[nbytes-1] &= msb; 〈test for unsigned underflow 275〉 } else if (applyu(MP_subu, z, x, y)) RAISE(MP_Overflow); return z; }
当y太大时,x-y对所有x都会发生下溢,因此在调用XP_diff之前MP_subui不需要检查y是否太大。
MP_mului调用MP_product,但在nbits小于8时,MP_mului必须显式检查y是否太大,因为当x为0时XP_product不会捕获该错误。该检查在计算z之后进行。
T MP_mului(T z, T x, unsigned long y) {
〈checked runtime errors for unary functions
275〉
if (y < BASE) {
int carry = XP_product(nbytes, z, x, y);
carry |= z[nbytes-1]& ~msb;
z[nbytes-1] &= msb;
〈test for unsigned overflow
271〉
〈check if unsigned y is too big
282〉
} else if (applyu(MP_mulu, z, x, y))
RAISE(MP_Overflow);
return z;
}
〈check if unsigned
y is too big
282〉≡
if (nbits < 8 && y >= (1U<<nbits))
RAISE(MP_Overflow);
MP_divui和MP_modui使用了XP_quotient,但它们必须自行检查除数为零的情形(因为XP_quotient只接受非零、单数位的除数),当nbits小于8且y太大时,它们必须检查是否发生了溢出。
〈functions 270〉+≡ T MP_divui(T z, T x, unsigned long y) { 〈checked runtime errors for unary functions 275〉 if (y == 0) RAISE(MP_Dividebyzero); else if (y < BASE) { XP_quotient(nbytes, z, x, y); 〈check if unsigned y is too big 282〉 } else if (applyu(MP_divu, z, x, y)) RAISE(MP_Overflow); return z; }
MP_modui调用XP_quotient,但只是为了计算余数。它会丢弃计算到tmp[2]中的商:
〈functions 270〉+≡ unsigned long MP_modui(T x, unsigned long y) { assert(x); if (y == 0) RAISE(MP_Dividebyzero); else if (y < BASE) { int r = XP_quotient(nbytes, tmp[2], x, y); 〈check if unsigned y is too big 282〉 return r; } else if (applyu(MP_modu, tmp[2], x, y)) RAISE(MP_Overflow); return XP_toint(nbytes, tmp[2]); }
有符号算术的各个便捷函数使用了同样的方法,但调用一个不同的apply函数,其使用MP_fromint的代码将long转换为有符号MP_T实例并保存到tmp[2],而后调用所需的函数,如果立即操作数太大则返回1,否则返回0。
〈static functions 281〉+≡ static int apply(T op(T, T, T), T z, T x, long v) { { T z = tmp[2]; 〈set z to v 272〉 } op(z, x, tmp[2]); return 〈v is too big 272〉; }
当|y|小于28 时,与对应的无符号便捷函数相比,有符号便捷函数需要多做一些工作,因为它们必须处理有符号操作数。单数位XP函数只处理正的单数位操作数,因此有符号便捷函数必须使用操作数的符号来确定调用哪个函数。这里的分析,类似于AP函数所作的分析(参见18.3.1节),但MP的二进制补码表示简化了细节。这里是加法的4种情形。
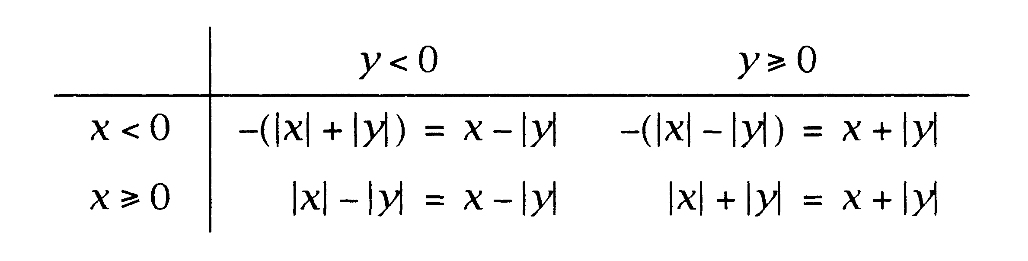
当y为负数时,对任意x,都有x+y等于x-|y|,因此MP_addi可以使用XP_diff来计算和值,当y为非负时,它可以使用XP_sum。
〈functions 270〉+≡ T MP_addi(T z, T x, long y) { 〈checked runtime errors for unary functions 275〉 if (-BASE < y && y < BASE) { int sx = sign(x), sy = y < 0; if (sy) XP_diff(nbytes, z, x, -y); else XP_sum (nbytes, z, x, y); z[nbytes-1] &= msb; 〈test for signed overflow 277〉 〈check if signed y is too big 283〉 } else if (apply(MP_add, z, x, y)) RAISE(MP_Overflow); return z; } 〈check if signed y is too big 283〉≡ if (nbits < 8 && (y < -(1<<(nbits-1)) || y >= (1<<(nbits-1)))) RAISE(MP_Overflow);
有符号减法的情形刚好与加法相反(AP_sub的情形参见18.3.2节):
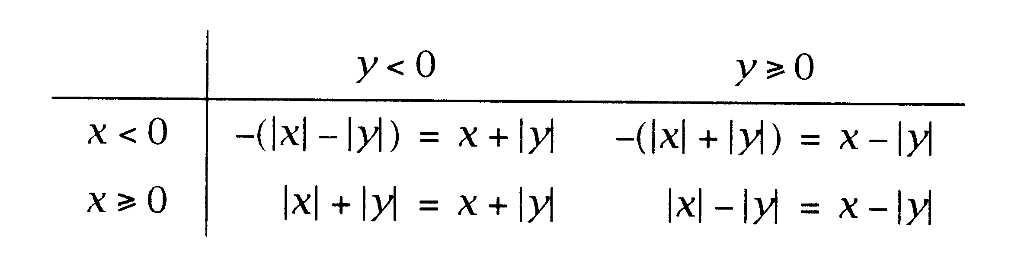
因此,当y为负数时,MP_subi调用XP_sum将|y|加到x,而y为非负时,则调用XP_diff。
〈functions 270〉+≡ T MP_subi(T z, T x, long y) { 〈checked runtime errors for unary functions 275〉 if (-BASE < y && y < BASE) { int sx = sign(x), sy = y < 0; if (sy) XP_sum (nbytes, z, x, -y); else XP_diff(nbytes, z, x, y); z[nbytes-1] &= msb; 〈test for signed underflow 278〉 〈check if signed y is too big 283〉 } else if (apply(MP_sub, z, x, y)) RAISE(MP_Overflow); return z; }
MP_muli使用MP_mul的策略:它对负操作数取反,通过调用XP_product计算乘积,(当操作数符号不同时)再将乘积取反。
〈functions 270〉+≡ T MP_muli(T z, T x, long y) { 〈checked runtime errors for unary functions 275〉 if (-BASE < y && y < BASE) { int sx = sign(x), sy = y < 0; 〈if x < 0, negate x 278〉 XP_product(nbytes, z, x, sy ? -y : y); if (sx != sy) XP_neg(nbytes, z, x, 1); z[nbytes-1] &= msb; if (sx == sy && sign(z)) RAISE(MP_Overflow); 〈check if signed y is too big 283〉 } else if (apply(MP_mul, z, x, y)) RAISE(MP_Overflow); return z; }
MP_divi和MP_modi必须检查除数为0的情形,因为它们调用XP_quotient来计算商和余数。MP_divi丢弃余数,而MP_modi丢弃商:
〈functions 〉+≡ T MP_divi(T z, T x, long y) { 〈checked runtime errors for unary functions 275〉 if (y == 0) RAISE(MP_Dividebyzero); else if (-BASE < y && y < BASE) { int r; 〈z ← x/y, r ← x mod y 285〉 〈check if signed y is too big 283〉 } else if (apply(MP_div, z, x, y)) RAISE(MP_Overflow); return z; } long MP_modi(T x, long y) { assert(x); if (y == 0) RAISE(MP_Dividebyzero); else if (-BASE < y && y < BASE) { T z = tmp[2]; int r; 〈z ← x/y, r ← x mod y 285〉 〈check if signed y is too big 283〉 return r; } else if (apply(MP_mod, tmp[2], x, y)) RAISE(MP_Overflow); return MP_toint(tmp[2]); }
MP_modi调用MP_toint而不是XP_toint,以确保符号的正确扩展。
MP_divi和MP_modi共同使用的代码块用于计算商和余数,并且在x和y符号不同且余数非零时校正商和余数。
〈z ← x/y, r ← x mod y 285〉≡ int sx = sign(x), sy = y < 0; 〈if x < 0, negate x 278〉 r = XP_quotient(nbytes, z, x, sy ? -y : y); if (sx != sy) { XP_neg(nbytes, z, z, 1); if (r != 0) { XP_diff(nbytes, z, z, 1); r = y - r; } z[nbytes-1] &= msb; } else if (sx && sign(z)) RAISE(MP_Overflow);
无符号比较很容易,MP_cmp可以只调用XP_cmp:
〈functions
270〉+≡
int MP_cmpu(T x, T y) {
assert(x);
assert(y);
return XP_cmp(nbytes, x, y);
}
当x和y符号不同时,MP_cmp(x, y)只是返回y和x符号的差:
〈functions
270〉+≡
int MP_cmp(T x, T y) {
int sx, sy;
assert(x);
assert(y);
sx = sign(x);
sy = sign(y);
if (sx != sy)
return sy - sx;
else
return XP_cmp(nbytes, x, y);
}
当x和y符号相同时,MP_cmp可以将其当做无符号数处理,调用XP_cmp进行比较。
进行比较操作的便捷函数无法使用applyu和apply,因为它们计算整数结果,而且不要求其long或unsigned long操作数一定能够放入到一个MP_T实例中。这些函数只是比较一个MP_T实例与一个立即数,当立即数的值太大时,将在比较的结果中反映出来。当unsigned long的位宽不小于nbits时,MP_cmpui将MP_T实例转换为一个unsigned long类型的值,并使用C语言中通常的比较运算符。否则,它将立即数转换为一个MP_T实例(tmp[2]),并调用XP_cmp。
〈functions 270〉+≡ int MP_cmpui(T x, unsigned long y) { assert(x); if ((int)sizeof y >= nbytes) { unsigned long v = XP_toint(nbytes, x); 〈return -1, 0, +1, if v < y, v = y, v > y 286〉 } else { XP_fromint(nbytes, tmp[2], y); return XP_cmp(nbytes, x, tmp[2]); } } 〈return -1, 0, +1, if v < y, v = y, v > y 286〉≡ if (v < y) return -1; else if (v > y) return 1; else return 0;
MP_cmpui在调用XP_fromint之后不必检查溢出,因为仅当y的位宽小于MP_T实例时,才会进行该调用。
当x和y符号不同时,MP_cmpi可以彻底避免比较。否则,它使用MP_cmpui的方法:如果立即数的位宽不小于MP_T实例,则用C语言比较运算符进行比较。
〈functions 270〉+≡ int MP_cmpi(T x, long y) { int sx, sy = y < 0; assert(x); sx = sign(x); if (sx != sy) return sy - sx; else if ((int)sizeof y >= nbytes) { long v = MP_toint(x); 〈return -1, 0, +1, if v < y, v = y, v > y 286〉 } else { MP_fromint(tmp[2], y); return XP_cmp(nbytes, x, tmp[2]); } }
当x和y符号相同且y的位宽小于MP_T的位宽时,MP_cmpi可以安全地将y转换为MP_T实例(tmp[2]),然后调用XP_cmp比较x和tmp[2]。MP_cmpi调用MP_fromint而不是XP_fromint,以便正确地处理y为负值的情形。
二元逻辑函数MP_and、MP_or和MP_xor是最容易实现的MP函数,因为结果的每个字节,都是操作数中对应字节按位运算得出:
〈macros 270〉+≡ #define bitop(op ) \ int i; assert(z); assert(x); assert(y); \ for (i = 0; i < nbytes; i++) z[i] = x[i] op y[i]; \ return z 〈functions 270〉+≡ T MP_and(T z, T x, T y) { bitop(&); } T MP_or (T z, T x, T y) { bitop(|); } T MP_xor(T z, T x, T y) { bitop(^); }
MP_not有些古怪,不符合bitop的模式:
〈functions 270〉+≡ T MP_not(T z, T x) { int i; 〈checked runtime errors for unary functions 273〉 for (i = 0; i < nbytes; i++) z[i] = ~x[i]; z[nbytes-1] &= msb; return z; }
对这三个实现逻辑运算的便捷函数来说,专门为单数位操作数编写特殊处理代码难有所获,而将立即操作数传递给这些函数并不会导致异常。applyu仍然可以使用,其返回值只是被忽略而已。
〈macros 270〉+≡ #define bitopi(op ) assert(z); assert(x); \ applyu(op , z, x, y); \ return z 〈functions 270〉+≡ T MP_andi(T z, T x, unsigned long y) { bitopi(MP_and); } T MP_ori (T z, T x, unsigned long y) { bitopi(MP_or); } T MP_xori(T z, T x, unsigned long y) { bitopi(MP_xor); }
三个移位函数首先确认已检查的运行时错误,然后检查s是否大于等于nbits(这种情况下,结果的各比特位为全0或全1),最后调用XP_lshift或XP_rshift。XP_ashift将空出的比特位填充1,因而实现了算术右移。
〈macros 270〉+≡ #define shft(fill, op ) \ assert(x); assert(z); assert(s >= 0); \ if (s >= nbits) memset(z, fill , nbytes); \ else op (nbytes, z, nbytes, x, s, fill ); \ z[nbytes-1] &= msb; \ return z 〈functions 270〉+≡ T MP_lshift(T z, T x, int s) { shft(0, XP_lshift); } T MP_rshift(T z, T x, int s) { shft(0, XP_rshift); } T MP_ashift(T z, T x, int s) { shft(sign(x),XP_rshift); }
最后四个函数负责字符串与MP_T实例之间的转换。MP_fromstr类似于strtoul,它将字符串解释为某个基数[2~36(含)]下的无符号数。对于大于10的基数来说,字母用于指定大于9的数位。
〈functions 270〉+≡ T MP_fromstr(T z, const char *str, int base, char **end){ int carry; assert(z); memset(z, '\0', nbytes); carry = XP_fromstr(nbytes, z, str, base, end); carry |= z[nbytes-1]& ~msb; z[nbytes-1] &= msb; 〈test for unsigned overflow 271〉 return z; }
XP_fromstr执行转换,(如果end不是NULL)并将*end设置为转换结束处字符的地址。z初始化为0,因为XP_fromstr会将转换得到的值加到z上。
MP_tostr执行反向转换:它接受一个MP_T实例,并给出该实例的值在某个基数(2到36之间,含)下的字符串表示。
〈functions 270〉+≡ char *MP_tostr(char *str, int size, int base, T x) { assert(x); assert(base >= 2 && base <= 36); assert(str == NULL || size > 1); if (str == NULL) { 〈size ← number of characters to represent x in base 289〉 str = ALLOC(size); } memcpy(tmp[1], x, nbytes); XP_tostr(str, size, base, nbytes, tmp[1]); return str; }
如果str是NULL,MP_tostr分配一个足够长的字符串,以容纳x在base基数下的表示。MP_tostr使用AP_tostr的技巧来计算该字符串的长度:str必须至少有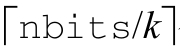 个字符,其中k的选择,要使得在2的各个幂次中,2k
是小于等于base的最大幂次,另外还有加上结尾的一个0字符。
个字符,其中k的选择,要使得在2的各个幂次中,2k
是小于等于base的最大幂次,另外还有加上结尾的一个0字符。
〈size ← number of characters to represent x in
base 289〉≡
{
int k;
for (k = 5; (1<<k) > base; k--)
;
size = nbits/k + 1 + 1;
}
Fmt风格的转换函数格式化一个无符号或有符号的MP_T实例。每个转换函数消耗两个参数:一个MP_T实例,和一个基数值[2~36(含)]。MP_fmtu调用MP_tostr来转换MP_T实例,并调用Fmt_putd来输出转换的结果。回忆前文可知,Fmt_putd以printf的%d转换限定符的风格来输出一个数字。
〈functions
270〉+≡
void MP_fmtu(int code, va_list *app,
int put(int c, void *cl), void *cl,
unsigned char flags[], int width, int precision) {
T x;
char *buf;
assert(app && flags);
x = va_arg(*app, T);
assert(x);
buf = MP_tostr(NULL, 0, va_arg(*app, int), x);
Fmt_putd(buf, strlen(buf), put, cl, flags,
width, precision);
FREE(buf);
}
MP_fmt要做的工作稍多一点,因为它将一个MP_T解释为一个有符号数,但MP_tostr只接受无符号MP_T实例。因而,MP_fmt本身会分配缓冲区,必要时会先在缓冲区中预置一个符号。
〈functions 270〉+≡ void MP_fmt(int code, va_list *app, int put(int c, void *cl), void *cl, unsigned char flags[], int width, int precision) { T x; int base, size, sx; char *buf; assert(app && flags); x = va_arg(*app, T); assert(x); base = va_arg(*app, int); assert(base >= 2 && base <= 36); sx = sign(x); 〈if x < 0, negate x 278〉 〈size ← number of characters to represent x in base 289〉 buf = ALLOC(size+1); if (sx) { buf[0] = '-'; MP_tostr(buf + 1, size, base, x); } else MP_tostr(buf, size + 1, base, x); Fmt_putd(buf, strlen(buf), put, cl, flags, width, precision); FREE(buf); }
多精度算术通常在编译器中使用,有时它是必须使用的。例如,[Clinger,1990]指出,将浮点字面值转换为对应的IEEE浮点表示,在某些情况下需要多精度算术才能实现最佳的精确度。
[Schneier,1996]是一份密码学方面的综述。该书很实用,还对一些描述的算法包括了C语言实现。该书还有很广泛的参考数目,这是深入研究的良好起点。
如17.2.2节所示,两个n数位数的乘积,所花费的时间与n2 成正比。[Press等人,1992]的20.6节说明,可使用快速傅里叶变换来实现乘法,其花费的时间与n lgn lglgn成正比。该书还通过计算倒数1/y并将其乘以x,从而实现了x/y。这种方法需要支持小数部分的多精度数。
19.1 当nbits是8的倍数时,MP接口函数执行了大量不必要的工作。读者是否可以修订MP接口的实现,使得在nbits mod 8=0时,能够避免这些不必要的工作?实现你的方案并测量其好处或成本。
19.2 对于许多应用程序来说,一旦选定nbits,就不会变更。实现一个代码生成器,对给定的nbits值,生成一个接口和实现MP_nbits ,支持位宽nbits的算术运算,其他方面与MP接口相同。
19.3 设计并实现一个接口,支持定点、多精度数的算术运算,这种数包含一个整数部分和一个小数部分。客户程序应该能指定这两部分中数位的数目。务必规定舍入规则的细节。[Press等人,1992]的20.6节包含了可用于本习题的一些有用算法。
19.4 设计并实现一个接口,支持浮点数的算术运算,客户程序可以指定指数和尾数部分的比特位数目。在尝试本习题之前,请阅读[Goldberg,1991]。
19.5 XP和MP接口中的函数并不使用const修饰的参数,原因已经在17.1节中详述。但是,可以用其他方式定义XP_T和MP_T,使之可以与const正确地协作。例如,如果以下述方式定义T
typedef unsigned char T[];
那么const T的语义就表示“常量无符号字符的数组”,继而可用于函数参数,例如MP_add可以声明如下:
unsigned char *MP_add(T z, const T x, const T y);
在MP_add中,x和y的类型是“指向常量无符号字符的指针”,因为形参中的数组类型会“衰变”为对应的指针类型。当然,const无法阻止偶发的别名混用,因为,同一数组可能同时传递给z和x。MP_add的这种声明形式,说明了将T定义为数组类型的不利之处:T无法用作返回类型,客户程序无法声明类型为T的变量。这种数组类型只对参数有用。通过将T定义为unsigned char的typedef,可以避免该问题:
typedef unsigned char T;
使用T的这种定义,MP_add可以声明为下述两种形式:
T *MP_add(T z[], const T x[], const T y[]); T *MP_add(T *z, T *x, T *y);
使用T的这两种定义,重新实现XP及其客户程序、AP、MP、calc和mpcalc。比较修改后程序与原始程序的易读性。
[1] 原文为比特位m,实际上对m位有符号整数来说,比特位m–1是符号位。——译者注
[2] m改为m–1。——译者注
[3] 将ones(m)右移一位,使得carry的初始值可以包含比特位m–1。——译者注
[4] 代码中原本把符号位也忽略了,已更正。——译者注