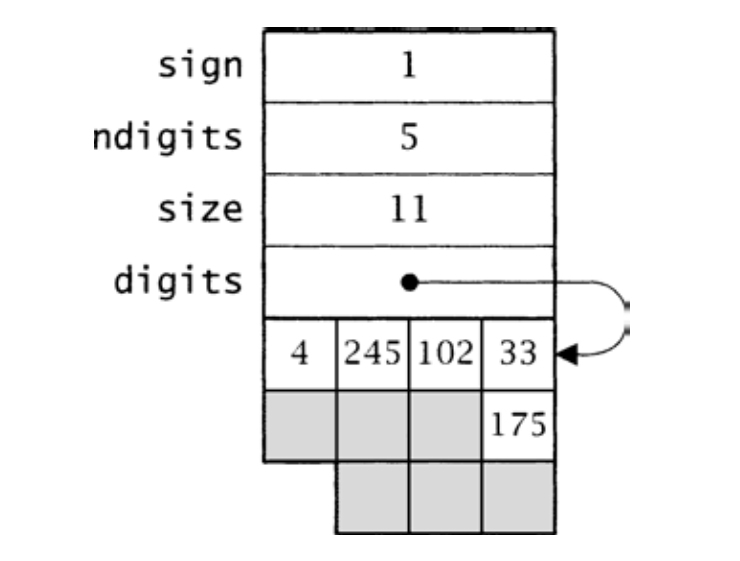
图18-1 值为751 702 468 129的AP_T实例的小端序布局
本章描述了AP接口,该接口提供了任意 精度的有符号整数,以及相关的算术操作。不同于XP_T,AP提供的整数可以是负数或正数,它们可以包含任意数目的数位。可以表示的值只受限于可用的内存。这种整数可以用于需要在极大的范围内使用整数值的应用程序。例如,一些共同基金公司以百分之一美分(一美元的1/10 000)为单位来跟踪股票价格,因而可能需要以百分之一美分为单位来完成所有的计算。这样,32位无符号整数最大只能表示$429 496.729 5,对于一些资金量以十亿计的基金来说,这仅仅是九牛一毛。
当然,AP的实现使用了XP接口,但AP是一个高级接口:它只暴露了一个不透明类型,用以表示任意精度的有符号整数。AP导出了相应的函数,来分配并释放这种整数,以及对这种整数执行通常的算术操作。它还实现了XP忽略的那些已检查的运行时错误。大多数应用程序都应该使用AP接口或下一章描述的MP接口。
AP接口通过不透明指针类型,隐藏了任意精度有符号整数的表示细节:
〈ap.h 〉≡ #ifndef AP_INCLUDED #define AP_INCLUDED #include <stdarg.h> #define T AP_T typedef struct T *T; 〈exported functions 233〉 #undef T #endif
除明确注明的情况之外,向该接口中任一函数传递值为NULL的AP_T,都造成已检查的运行时错误。
AP_T实例由以下函数创建
〈exported functions
233〉≡
extern T AP_new(long int n);
extern T AP_fromstr(const char *str, int base,
char **end);
AP_new创建一个新的AP_T,将其值初始化为n,并返回该实例。AP_fromstr也创建一个新的AP_T实例,将其初始化为通过str和base指定的值,并返回该实例。AP_new和AP_fromstr都可能引发Mem_Failed异常。
AP_fromstr类似C库中的strtol,它将str中的字符串解释为以base为基数的整数。它在处理过程中,会忽略str前部的空格,可以接受一个可选的符号,后接一个或多个以base为基数的数位。对于11和36之间的基数来说,AP_fromstr将小写或大写字母解释为大于九的数位。base小于2或大于36,则为已检查的运行时错误。
如果end不是NULL,*end被设置为指向AP_fromstr结束解释过程的字符处。如果str中的各个字符不是基数base下的整数,那么AP_fromstr将返回NULL,并将*end设置为str(如果end不是NULL)。str是NULL,则造成已检查的运行时错误。
以下函数
〈exported functions
233〉+≡
extern long int AP_toint(T x);
extern char * AP_tostr(char *str, int size,
int base, T x);
extern void AP_fmt(int code, va_list *app,
int put(int c, void *cl), void *cl,
unsigned char flags[], int width, int precision);
提取并输出AP_T实例表示的整数。AP_toint返回一个long int,其符号与x相同,绝对值等于|x|mod (LONG_MAX+1),其中LONG_MAX是long int可以表示的最大值。如果x是LONG_MIN(在使用二进制补码的机器上,等于-LONG_MAX-1),AP_toint返回-((LONG_MAX+1) mod (LONG_MAX+1)),即为0。
AP_tostr将x在基数base下的字符表示填充到str中(以0结尾),并返回str。在base大于10时,大写字母用于表示大于9的数位。base小于2或大于36,则为已检查的运行时错误。
如果str不是NULL,AP_tostr将向str中填充最多size个字符。如果size太小,则造成已检查的运行时错误:即x的字符表示加上一个0字符,需要的空间多于size个字符。如果str是NULL,则忽略size,AP_tostr会分配一个足够大的字符串来保存x的表示,并返回该字符串。客户程序负责释放该字符串。在str是NULL时,AP_tostr可能引发Mem_Failed异常。
AP_fmt可以用作一个转换函数,与Fmt接口中的函数协作,来格式化AP_T。它消耗一个AP_T实例,并根据可选的flags、width和precision来格式化该实例,其工作方式与printf限定符%d格式化整数参数的方式相同。AP_fmt可能引发Mem_Failed异常。app或flags是NULL,则为已检查的运行时错误。
AP_T实例通过下列函数释放:
〈exported functions
233〉+≡
extern void AP_free(T *z);
AP_free释放*z并将*z设置为NULL。如果z或*z为NULL,将造成已检查的运行时错误。
下列函数对AP_T实例执行算术操作。每个函数都返回一个AP_T实例作为结果,这些函数都可能引发Mem_Failed异常。
〈exported functions
233〉+≡
extern T AP_neg(T x);
extern T AP_add(T x, T y);
extern T AP_sub(T x, T y);
extern T AP_mul(T x, T y);
extern T AP_div(T x, T y);
extern T AP_mod(T x, T y);
extern T AP_pow(T x, T y, T p);
AP_neg返回-x,AP_add返回x+y,AP_sub返回x-y,AP_mul返回x*y。在这里和下文中,x和y代表变量x和y表示的整数值。AP_div返回x/y,而AP_mod返回x mod y。除法向左舍入:当x或y之一为负数时,向负无穷大舍入,否则向0舍入,因此余数总是正数。更确切地说,对使得w*y=x的实数w来说,x/y的商q是不大于w的最大整数,而余数则定义为x-y*q。该定义与第2章中所述Arith接口的实现是相同的。对于AP_div和AP_mod,如果y为0,则造成已检查的运行时错误。
当p为NULL时,AP_pow返回xy 。当p不是NULL时,AP_pow返回(xy ) mod p。y为负数,或p不是NULL且小于2,则造成已检查的运行时错误。
下述便捷函数
〈exported functions
233〉+≡
extern T AP_addi(T x, long int y);
extern T AP_subi(T x, long int y);
extern T AP_muli(T x, long int y);
extern T AP_divi(T x, long int y);
extern long AP_modi(T x, long int y);
类似于上面描述的函数,但使用long int类型来表示y。例如,AP_addi(x, y)等效于AP_add (x, AP_new(y))。除法和取模运算的规则,与AP_div和AP_mod相同。这些函数都可能引发Mem_Failed异常。
AP_T可以用下述函数进行移位操作:
〈exported functions
233〉+≡
extern T AP_lshift(T x, int s);
extern T AP_rshift(T x, int s);
AP_lshift返回x左移s个比特位后得到的AP_T实例,该值等于x乘以2s 。AP_rshift返回x右移s个比特位后得到的AP_T实例,该值等于x除以2s 。这两个函数的返回值与x符号相同。s为负数,则造成已检查的运行时错误,移位操作可能引发Mem_Failed异常。
AP_T通过下列函数比较
〈exported functions
233〉+≡
extern int AP_cmp (T x, T y);
extern int AP_cmpi(T x, long int y);
对于x<y、x=y、x>y的情形,这两个函数都会分别返回一个小于0、等于0、大于0的整数。
一个可完成任意精度计算的计算器,说明了AP接口的用法。下一节描述了AP接口的实现,其中说明了XP接口的使用。
计算器calc,使用了波兰后缀表示法(Polish suffix notation):值被推入栈上,运算符将其操作数从栈中弹出,并将运算结果再次推入栈上。一个值由一个或多个连续的十进制数位组成,支持的运算符如下。
~ 取反
+ 加法
- 减法
* 乘法
/ 除法
% 取模
^ 取幂
d 复制栈顶部的值
p 输出栈顶部的值
f 自顶向下,输出栈上所有的值
q 退出
空格字符用于分隔值,其他情况下忽略空格,其他字符被作为无法识别的运算符处理。栈的大小只受可用内存的限制,但发生栈下溢时会输出诊断消息。
calc是一个简单程序,有三个主要任务:解释输入、计算值、管理栈。
〈calc.c 〉≡ #include <ctype.h> #include <stdio.h> #include <string.h> #include <stdlib.h> #include "stack.h" #include "ap.h" #include "fmt.h" 〈calc data 236〉 〈calc functions 236〉
包含stack.h头文件表明,calc使用第2章描述的Stack接口来实现栈。
〈calc data 236〉≡ Stack_T sp; 〈initialization 236〉≡ sp = Stack_new();
在sp为空时calc不能调用Stack_pop,因此它将所有的栈弹出操作封装到一个函数中,在其中检查栈下溢:
〈calc functions
236〉≡
AP_T pop(void) {
if (!Stack_empty(sp))
return Stack_pop(sp);
else {
Fmt_fprint(stderr, "?stack underflow\n");
return AP_new(0);
}
}
该函数总是返回一个AP_T实例(即使栈为空),这简化了calc中其他处的错误检测。
calc中的主循环读取下一个“标记”——值或运算符,并据此执行对应的操作:
〈calc functions 236〉+≡ int main(int argc, char *argv[]) { int c; 〈initialization 236〉 while ((c = getchar()) != EOF) switch (c) { 〈cases 237〉 default: if (isprint(c)) Fmt_fprint(stderr, "?'%c'", c); else Fmt_fprint(stderr, "?'\\%03o'", c); Fmt_fprint(stderr, " is unimplemented\n"); break; } 〈clean up and exit 236〉 } 〈clean up and exit 236〉≡ 〈clear the stack 239〉 Stack_free(&sp); return EXIT_SUCCESS;
输入字符或者是空格、或者是值的第一个数字、或者是运算符,其他的输入字符视为错误,由switch语句中的default子句处理。空格忽略即可:
〈cases
237〉≡
case ' ': case '\t': case '\n': case '\f': case '\r':
break;
数字字符是值的开始,从第一个数字字符开始,calc将其后的各个数字字符都收集到一个缓冲区中,使用AP_fromstr将这一连串数字字符转换为AP_T实例:
〈cases 237〉+≡ case '0': case '1': case '2': case '3': case '4': case '5': case '6': case '7': case '8': case '9': { char buf[512]; 〈gather up digits into buf 239〉 Stack_push(sp, AP_fromstr(buf, 10, NULL)); break; }
每个运算符都从栈上弹出零或多个操作数,压入零或多个结果。其中,加法颇具代表性:
〈cases 237〉+≡ case '+': { 〈pop x and y off the stack 237〉 Stack_push(sp, AP_add(x, y)); 〈free x and y 237〉 break; } 〈pop x and y off the stack 237〉≡ AP_T y = pop(), x = pop(); 〈free x and y 237〉≡ AP_free(&x); AP_free(&y);
很容易犯下将同一AP_T实例多次压栈的错误,这种情况下,基本上不可能知道该释放哪个AP_T。上述代码给出了一个简单的协议,以避免该问题:只有入栈的AP_T实例才是“持久”的,其他的都会通过调用AP_free释放。
减法和乘法在形式上类似于加法:
〈cases 237〉+≡ case '-': { 〈pop x and y off the stack 237〉 Stack_push(sp, AP_sub(x, y)); 〈free x and y 237〉 break; } case '*': { 〈pop x and y off the stack 237〉 Stack_push(sp, AP_mul(x, y)); 〈free x and y 237〉 break; }
除法和取模也比较简单,但必须防止除数为0的情形。
〈cases 237〉+≡ case '/': { 〈pop x and y off the stack 237〉 if (AP_cmpi(y, 0) == 0) { Fmt_fprint(stderr, "?/ by 0\n"); Stack_push(sp, AP_new(0)); } else Stack_push(sp, AP_div(x, y)); 〈free x and y 237〉 break; } case '%': { 〈pop x and y off the stack 237〉 if (AP_cmpi(y, 0) == 0) { Fmt_fprint(stderr, "?%% by 0\n"); Stack_push(sp, AP_new(0)); } else Stack_push(sp, AP_mod(x, y)); 〈free x and y 237〉 break; }
取幂操作必须防止非正数的幂指数:
〈cases 237〉+≡ case '^': { 〈pop x and y off the stack 237〉 if (AP_cmpi(y, 0) <= 0) { Fmt_fprint(stderr, "?nonpositive power\n"); Stack_push(sp, AP_new(0)); } else Stack_push(sp, AP_pow(x, y, NULL)); 〈free x and y 237〉 break; }
复制栈顶部的值,需要首先将其从栈中弹出(以便检测下溢),然后将该值及其副本压栈。复制AP_T实例的唯一途径是将其与0做加法。
〈cases
237〉+≡
case 'd': {
AP_T x = pop();
Stack_push(sp, x);
Stack_push(sp, AP_addi(x, 0));
break;
}
输出一个AP_T实例,需要将AP_cvt关联到一个格式码,并在传递给Fmt_fmt的格式串中使用该格式码,calc使用D作为格式码。
〈initialization 236〉+≡ Fmt_register('D', AP_fmt); 〈cases 237〉+≡ case 'p': { AP_T x = pop(); Fmt_print("%D\n", x); Stack_push(sp, x); break; }
输出栈上所有值的过程,揭示了Stack接口的一个弱点:无法访问栈顶以下的值,或获取栈上值的总数。一个更好的栈接口,可能还需要包括诸如Table_length和Table_map之类的函数,没有这些函数,calc必须创建一个临时栈,将主栈的内容换入临时栈中,在此过程中分别输出各个值,而后再将临时栈的内容换入主栈。
〈cases
237〉+≡
case 'f':
if (!Stack_empty(sp)) {
Stack_T tmp = Stack_new();
while (!Stack_empty(sp)) {
AP_T x = pop();
Fmt_print("%D\n", x);
Stack_push(tmp, x);
}
while (!Stack_empty(tmp))
Stack_push(sp, Stack_pop(tmp));
Stack_free(&tmp);
}
break;
switch语句中余下的case子句,分别处理取反、清空栈、退出等操作:
〈cases 237〉+≡ case '~': { AP_T x = pop(); Stack_push(sp, AP_neg(x)); AP_free(&x); break; } case 'c': 〈clear the stack 239〉 break; case 'q': 〈clean up and exit 236〉 〈clear the stack 239〉≡ while (!Stack_empty(sp)) { AP_T x = Stack_pop(sp); AP_free(&x); }
calc在清空栈时,会释放栈中的AP_T实例,以避免出现无法访问、存储空间永不释放的对象。
calc的最后一个代码块将一连串数字字符读取到buf中:
〈gather up digits into
buf 239〉≡
{
int i = 0;
for ( ; c != EOF && isdigit(c); c = getchar(), i++)
if (i < (int)sizeof (buf) - 1)
buf[i] = c;
if (i > (int)sizeof (buf) - 1) {
i = (int)sizeof (buf) - 1;
Fmt_fprint(stderr,
"?integer constant exceeds %d digits\n", i);
}
buf[i] = 0;
if (c != EOF)
ungetc(c, stdin);
}
如该代码所示,calc遇到超长的数字时会输出错误信息并截断。
AP接口的实现,说明了XP接口的典型用法。对于有符号数,AP接口使用了一种符号—绝对值的表示:一个AP_T实例指向一个结构,其中包括该数的符号及其绝对值(一个XP_T实例):
〈ap.c 〉≡ #include <ctype.h> #include <limits.h> #include <stdlib.h> #include <string.h> #include "assert.h" #include "ap.h" #include "fmt.h" #include "xp.h" #include "mem.h" #define T AP_T struct T { int sign; int ndigits; int size; XP_T digits; }; 〈macros 242〉 〈prototypes 242〉 〈static functions 241〉 〈functions 241〉
sign为1或者-1。size是分配的数位的数目,digits指向这些数位,它可能大于ndigits,即当前使用数位的数目。即,一个AP_T实例表示一个数值,具体的数值由digits[0..ndigits-1]中的XP_T实例给出。AP_T总是规格化的:其最高有效数位总是非零值,除非这个AP_T实例本身表示0。因而,ndigits通常小于size。图18-1给出了一个11数位的AP_T实例,在小端序计算机(字宽32位,字符位宽8位)上表示的数值为751 702 468 129。digits数组中不使用的元素以阴影表示。
图18-1 值为751 702 468 129的AP_T实例的小端序布局
AP_T实例通过下列函数分配:
〈functions
241〉≡
T AP_new(long int n) {
return set(mk(sizeof (long int)), n);
}
该函数调用了静态函数mk完成实际分配操作,mk分配了一个可容纳size个数位的AP_T实例,并将其初始化为0。
〈static functions
241〉≡
static T mk(int size) {
T z = CALLOC(1, sizeof (*z) + size);
assert(size > 0);
z->sign = 1;
z->size = size;
z->ndigits = 1;
z->digits = (XP_T)(z + 1);
return z;
}
在符号—绝对值的表示法中,0有两种表示,按照惯例,AP接口只使用正数表示,如mk中的代码所示。
AP_new调用静态函数set将AP_T实例初始化为long int类型参数的值,set照例将long int类型的最小值作为特例处理:
〈static functions
241〉+≡
static T set(T z, long int n) {
if (n == LONG_MIN)
XP_fromint(z->size, z->digits, LONG_MAX + 1UL);
else if (n < 0)
XP_fromint(z->size, z->digits, -n);
else
XP_fromint(z->size, z->digits, n);
z->sign = n < 0 ? -1 : 1;
return normalize(z, z->size);
}
对z->sign的赋值是一个惯用法,以确保sign的值是1或-1,0的sign值为1。XP_T实例是非规格化的,因为其最高有效数位可能为0。当一个AP函数生成的XP_T实例可能非规格化的时候,它可以调用normalize计算正确的ndigits字段,来修正这种情况:
〈static functions 241〉+≡ static T normalize(T z, int n) { z->ndigits = XP_length(n, z->digits); return z; } 〈prototypes 242〉≡ static T normalize(T z, int n);
AP_T实例通过下列函数释放:
〈functions
241〉+≡
void AP_free(T *z) {
assert(z && *z);
FREE(*z);
}
AP_new是分配AP_T实例的唯一途径,因此,让AP_free“知道”结构本身和digit数组的空间是只调用一次分配操作得到的,事实上是安全的。
取反是最容易实现的算术操作,它说明了在符号—绝对值表示法下会重复出现的一个问题:
〈functions 241〉+≡ T AP_neg(T x) { T z; assert(x); z = mk(x->ndigits); memcpy(z->digits, x->digits, x->ndigits); z->ndigits = x->ndigits; z->sign = iszero(z) ? 1 : -x->sign; return z; } 〈macros 242〉≡ #define iszero(x) ((x)->ndigits==1 && (x)->digits[0]==0)
对x取反只需复制值并翻转符号即可,值为0的情况下例外。iszero宏利用了AP_T实例均为规格化的约束:表示0的AP_T实例只会有一个数位。
x·y的绝对值是|x|·|y|,乘积包含的数位的数目,是x和y中的数位数之和。在x和y符号相同时,或当x和y中至少有一个为0时,乘积结果是正数,否则为负数。符号值为-1或1,因此下述比较
〈x and y have the same sign 243〉≡ ((x->sign^y->sign) == 0)
在x和y符号相同时为true,否则为false。AP_mul调用XP_mul计算|x|·|y|,并计算符号本身:
〈functions 241〉+≡ T AP_mul(T x, T y) { T z; assert(x); assert(y); z = mk(x->ndigits + y->ndigits); XP_mul(z->digits, x->ndigits, x->digits, y->ndigits, y->digits); normalize(z, z->size); z->sign = iszero(z) || 〈x and y have the same sign 243〉 ? 1 : -1; return z; }
回忆前文可知,XP_mul计算了z=z+x·y,而mk将z初始化为规格化的0。
加法更为复杂,因为其中可能需要减法,这取决于x和y的符号和值。下面综述了各种情况。
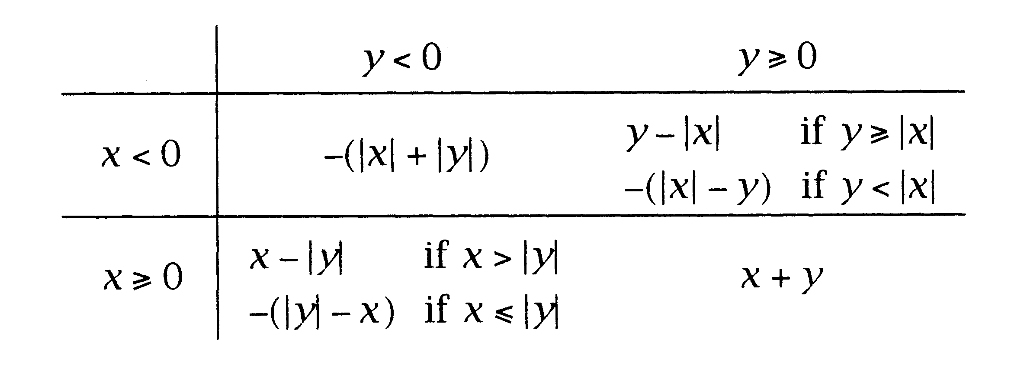
当x和y均为非负值时,|x|+|y|等于x+y,因此对角线上的两种情形,可以通过计算|x|+|y|并将结果的符号设置为x的符号来完成。与x和y中的较长者相比,结果可能多出一个数位。
〈functions 241〉+≡ T AP_add(T x, T y) { T z; assert(x); assert(y); if (〈x and y have the same sign 243〉) { z = add(mk(maxdigits(x,y) + 1), x, y); z->sign = iszero(z) ? 1 : x->sign; } else 〈set z to x+y when x and y have different signs 244〉 return z; } 〈macros 242〉+≡ #define maxdigits(x,y ) ((x )->ndigits > (y )->ndigits ? \ (x )->ndigits : (y )->ndigits)
add调用XP_add完成实际的加法操作:
〈static functions
241〉+≡
static T add(T z, T x, T y) {
int n = y->ndigits;
if (x->ndigits < n)
return add(z, y, x);
else if (x->ndigits > n) {
int carry = XP_add(n, z->digits, x->digits,
y->digits, 0);
z->digits[z->size-1] = XP_sum(x->ndigits - n,
&z->digits[n], &x->digits[n], carry);
} else
z->digits[n] = XP_add(n, z->digits, x->digits,
y->digits, 0);
return normalize(z, z->size);
}
add中的第一个测试确保x是较长的操作数。如果x比y长,XP_add计算n数位的和保存到z->digits[0..n-1]中,并返回进位值。该进位值与x->digits[n..x->ndigits-1]的和,又在计算后保存到z->digits [n..z->size-1]。如果x和y数位的数目相同,如前例XP_add计算n数位的和,进位值即为z的最高有效数位。
加法的其他情形也可以简化。在x<0,y≥0,且|x|>|y|时,x+y的绝对值是|x|-|y|,和的符号为负。在x≥0,y<0,且|x|>|y|时,x+y的绝对值也是|x|-|y|,但其符号为正。在这两种情况下,结果的符号都与x的符号相同。如下所述,sub和cmp分别执行减法和比较操作。结果的数位数目与x相同。
〈set z to x+y when x and y have different signs 244〉≡ if (cmp(x, y) > 0) { z = sub(mk(x->ndigits), x, y); z->sign = iszero(z) ? 1 : x->sign; }
在x<0,y≥0,且|x|≤|y|时,x+y的绝对值是|y|-|x|,和的符号为正。在x≥0,y<0,且|x|≤|y|时,x+y的绝对值也是|y|-|x|,但其符号为负。在这两种情况下,结果的符号都与x的符号相反,其数位数目与y相同。
〈set z to x+y when x and y have different signs 244〉+≡ else { z = sub(mk(y->ndigits), y, x); z->sign = iszero(z) ? 1 : -x->sign; }
减法同样得益于类似的分析。下表给出了减法操作的各种情况。
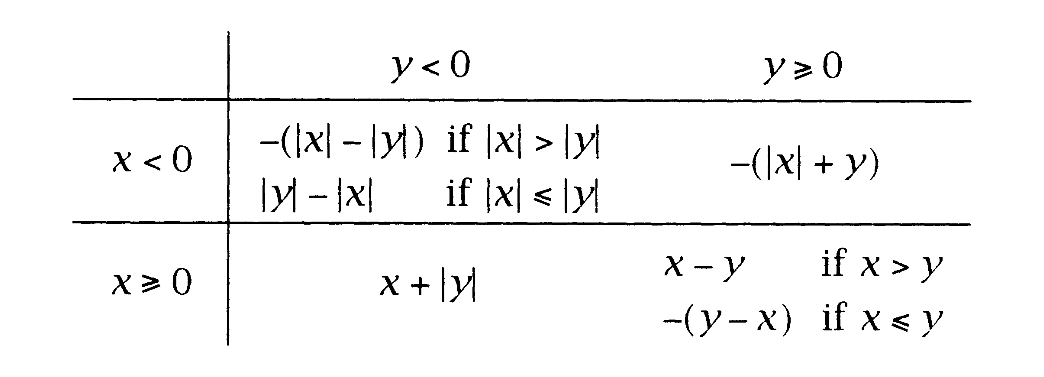
这里,非对角线情形都比较容易,只需要计算|x|+|y|,并将结果的符号设置为x的符号,即可处理:
〈functions 241〉+≡ T AP_sub(T x, T y) { T z; assert(x); assert(y); if (!〈x and y have the same sign 243〉) { z = add(mk(maxdigits(x,y) + 1), x, y); z->sign = iszero(z) ? 1 : x->sign; } else 〈set z to x-y when x and y have the same sign 245〉 return z; }
对角线情形取决于x和y相对大小。当|x|>|y|时,x-y的绝对值是|x|-|y|,其符号与x相同,当|x|≤|y|时,x-y的绝对值是|y|-|x|,而其符号与x相反。
〈set z to x-y when x and y have the same sign 245〉≡ if (cmp(x, y) > 0) { z = sub(mk(x->ndigits), x, y); z->sign = iszero(z) ? 1 : x->sign; } else { z = sub(mk(y->ndigits), y, x); z->sign = iszero(z) ? 1 : -x->sign; }
类似于add,sub也调用XP函数来实现减法,其中y不大于x。
〈static functions
241〉+≡
static T sub(T z, T x, T y) {
int borrow, n = y->ndigits;
borrow = XP_sub(n, z->digits, x->digits,
y->digits, 0);
if (x->ndigits > n)
borrow = XP_diff(x->ndigits - n, &z->digits[n],
&x->digits[n], borrow);
assert(borrow == 0);
return normalize(z, z->size);
}
当x比y长时,对XP_sub的调用计算了n数位的差值,并保存到z->digits[0..n-1]中,同时返回借位值。x->digits[n..x->ndigits-1]与该借位值的差值,则通过XP_diff计算,保存到z->digits[n..z->size-1]中,最终的借位值为0,因为调用sub时,|x|≥|y|总是成立的。如果x和y数位数目相同,同样使用XP_sub计算n数位的差值,但借位值不会向高位传播。
除法类似于乘法,但舍入规则使除法变得比较复杂。当x和y符号相同时,商为|x|/|y|且是正数,余数为|x|mod|y| [1] 。当x和y符号不同时,商是负数,其绝对值为|x|/|y|(当|x|mod|y|为0时)或|x|/|y|+1(当|x|mod|y|不为0时)。当|x|mod|y|为0时,余数为|x|mod|y|,否则余数为|y|-(|x|mod|y|)。因而余数总是正数。商和余数的数位数目,(最多时)分别与x和y的数位数目相同。
〈functions 241〉+≡ T AP_div(T x, T y) { T q, r; 〈q ← x/y, r ← x mod y 246〉 if (!〈x and y have the same sign 243〉 && !iszero(r)) { int carry = XP_sum(q->size, q->digits, q->digits, 1); assert(carry == 0); normalize(q, q->size); } AP_free(&r); return q; } 〈q ← x/y, r ← x mod y 246〉≡ assert(x); assert(y); assert(!iszero(y)); r = mk(y->ndigits); { XP_T tmp = ALLOC(x->ndigits + y->ndigits + 2); XP_div(x->ndigits, q->digits, x->digits, y->ndigits, y->digits, r->digits, tmp); FREE(tmp); } normalize(q, q->size); normalize(r, r->size); q->sign = iszero(q) || 〈x and y have the same sign 243〉 ? 1 : -1;
在x和y符号不同时,AP_div并不校正余数,因为该函数会丢弃余数。AP_mod的行为刚好相反:它只校正余数,而丢弃商。
〈functions 241〉+≡ T AP_mod(T x, T y) { T q, r; (q ← x/y, r ← x mod y 246) if (!〈x and y have the same sign 243〉 && !iszero(r)) { int borrow = XP_sub(r->size, r->digits, y->digits, r->digits, 0); assert(borrow == 0); normalize(r, r->size); } AP_free(&q); return r; }
当第三个参数p为NULL时,AP_pow返回xy 。当p不是NULL时,AP_pow返回(xy ) mod p。
〈functions 241〉+≡ T AP_pow(T x, T y, T p) { T z; assert(x); assert(y); assert(y->sign == 1); assert(!p || p->sign==1 && !iszero(p) && !isone(p)); 〈special cases 248〉 if (p) 〈z← xy mod p 249〉 else 〈z← xy 248〉 return z; } 〈macros 242〉+≡ #define isone(x ) ((x )->ndigits==1 && (x)->digits[0]==1)
为计算z=xy ,一种容易采用的做法是将z设置为1,连续y次用x乘以z。其问题在于,如果y很大,比方说y的十进制表示有200个数位,那么这种方法花费的时间,将远超过宇宙的年龄。数学规则有助于简化计算:
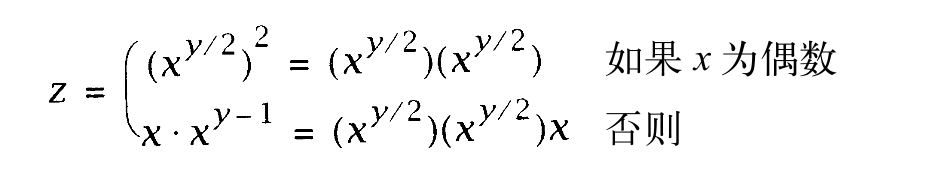
这些规则使得我们可以通过递归方式实现AP_pow,并将中间结果乘方或乘积即可。递归的深度(以及由此得出的操作步数)与lg y成正比。当x或y为0或1时,递归过程到达最低点,因为0y =0,1y =1,x0 =1,x1 =x。前三种特例处理如下:
〈special cases 248〉≡ if (iszero(x)) return AP_new(0); if (iszero(y)) return AP_new(1); if (isone(x)) return AP_new(〈y is even 248〉 ? 1 : x->sign); 〈y is even 248〉≡ (((y)->digits[0]&1) == 0)
递归过程实现了对第四个特例以及上述方程式描述的两种情形的处理:
〈z ← xy 248〉≡ if (isone(y)) z = AP_addi(x, 0); else { T y2 = AP_rshift(y, 1), t = AP_pow(x, y2, NULL); z = AP_mul(t, t); AP_free(&y2); AP_free(&t); if (!〈y is even 248〉) { z = AP_mul(x, t = z); AP_free(&t); } }
y是正数,因此将其右移1位,相当于计算了y/2。中间结果y/2、xy/2 和(xy/2 )(xy/2 )都被释放,以避免出现无法访问的内存。
在p不是NULL时,AP_pow计算了xy mod p。当p>1时,我们实际上不能计算xy ,因为该值可能太大,例如,如果x的十进制表示有10个数位,而y为200,结果xy 的数位数,可能比宇宙中的原子数还多,但xy mod p实际上是一个小得多的数。可使用下述关于模乘法的数学规则,来避免出现过大的数字:
(x·y) mod p=((x mod p)·(y mod p)) mod p
AP_mod和静态函数mulmod可协同实现该规则。mulmod使用AP_mod和AP_mul来实现x·y mod p,请注意释放临时乘积x·y。
〈static functions
241〉+≡
static T mulmod(T x, T y, T p) {
T z, xy = AP_mul(x, y);
z = AP_mod(xy, p);
AP_free(&xy);
return z;
}
p不是NULL时,AP_pow的代码与p为NULL时的代码几乎相同,只是调用了mulmod来执行乘法,并将p传递给对AP_pow的递归调用,且在y为奇数时使用mod p来缩减x。
〈z ← xy mod p 249〉≡ if (isone(y)) z = AP_mod(x, p); else { T y2 = AP_rshift(y, 1), t = AP_pow(x, y2, p); z = mulmod(t, t, p); AP_free(&y2); AP_free(&t); if (!〈y is even 248〉) { z = mulmod(y2 = AP_mod(x, p), t = z, p); AP_free(&y2); AP_free(&t); } }
比较x和y的结果,取决于二者的符号和绝对值。当x<y、x=y、x>y时,AP_cmp分别返回小于零、等于零、大于零的值。当x和y符号不同时,AP_cmp只需返回x的符号,否则,它必须比较二者的绝对值:
〈functions 241〉+≡ int AP_cmp(T x, T y) { assert(x); assert(y); if (!〈x and y have the same sign 243〉) return x->sign; else if (x->sign == 1) return cmp(x, y); else return cmp(y, x); }
当x和y都是正数时,如果|x|<|y|,即有x<y,依次类推。当x和y都是负数时,如果|x|>|y|,则有x<y,这是在第二次调用cmp时逆转参数顺序的原因。在cmp检查操作数长度不同的情形之后,由XP_cmp完成实际的比较:
〈static functions 241〉+≡ static int cmp(T x, T y) { if (x->ndigits != y->ndigits) return x->ndigits - y->ndigits; else return XP_cmp(x->ndigits, x->digits, y->digits); } 〈prototypes 242〉+≡ static int cmp(T x, T y);
AP接口的六个便捷函数,都以一个AP_T实例作为第一个参数,而使用有符号长整数作为第二个参数。每个函数都将长整数传递给set,来初始化一个临时的AP_T实例,然后调用更通用的操作。AP_addi说明了这种方法:
〈functions 241〉+≡ T AP_addi(T x, long int y) { 〈declare and initialize t 250〉 return AP_add(x, set(&t, y)); } 〈declare and initialize t 250〉≡ unsigned char d[sizeof (unsigned long)]; struct T t; t.size = sizeof d; t.digits = d;
上述的第二个代码块,通过声明适当的局部变量,在栈上分配了临时的AP_T实例以及相关的digits数组。这是可能的,因为digits数组的大小受限于unsigned long类型的字节数。
剩余的4个便捷函数也采用了相同的模式:
〈functions 〉+≡ T AP_subi(T x, long int y) { 〈declare and initialize t 250〉 return AP_sub(x, set(&t, y)); } T AP_muli(T x, long int y) { 〈declare and initialize t 250〉 return AP_mul(x, set(&t, y)); } T AP_divi(T x, long int y) { 〈declare and initialize t 250〉 return AP_div(x, set(&t, y)); } int AP_cmpi(T x, long int y) { 〈declare and initialize t 250〉 return AP_cmp(x, set(&t, y)); }
AP_modi比较古怪,它返回了long类型,而不是AP_T或int,另外它必须丢弃AP_mod返回的AP_T实例。
〈functions 241〉+≡ long int AP_modi(T x, long int y) { long int rem; T r; 〈declare and initialize t 250〉 r = AP_mod(x, set(&t, y)); rem = XP_toint(r->ndigits, r->digits); AP_free(&r); return rem; }
两个移位函数都调用了对应的XP函数,来对操作数进行移位操作。对于AP_lshift,结果的符号与操作数相同,结果比操作数多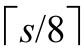 个数位。
个数位。
〈functions
241〉+≡
T AP_lshift(T x, int s) {
T z;
assert(x);
assert(s >= 0);
z = mk(x->ndigits + ((s+7)& ~7)/8);
XP_lshift(z->size, z->digits, x->ndigits,
x->digits, s, 0);
z->sign = x->sign;
return normalize(z, z->size);
}
对于AP_rshift,结果比操作数少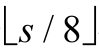 个字节,结果有可能为0,这种情况下其符号必须为正。
个字节,结果有可能为0,这种情况下其符号必须为正。
T AP_rshift(T x, int s) {
assert(x);
assert(s >= 0);
if (s >= 8*x->ndigits)
return AP_new(0);
else {
T z = mk(x->ndigits - s/8);
XP_rshift(z->size, z->digits, x->ndigits,
x->digits, s, 0);
normalize(z, z->size);
z->sign = iszero(z) ? 1 : x->sign;
return z;
}
}
if语句处理了一种特例,即s指定的移位数量大于等于x中现有比特位数目的情形。
AP_toint(x)返回一个long int,其符号与x相同,其绝对值等于|x|mod (LONG_MAX+1)。
〈functions
241〉+≡
long int AP_toint(T x) {
unsigned long u;
assert(x);
u = XP_toint(x->ndigits, x->digits)%(LONG_MAX + 1UL);
if (x->sign == -1)
return -(long)u;
else
return (long)u;
}
其余的AP函数负责AP_T到字符串的双向转换。AP_fromstr将一个字符串转换为一个AP_T实例,它接受一个表示有符号数的字符串,语法如下:
number ={ white }[ - |+ ]{ white } digit { digit }
其中white表示一个空格字符,而digit表示指定基数下的一个数字字符,基数必须在2~36(含)。对于大于10的基数,用字母来表示大于9的数位。AP_fromstr调用了XP_fromstr,当遇到非法字符或0字符时将停止扫描其字符串参数。
〈functions
241〉+≡
T AP_fromstr(const char *str, int base, char **end) {
T z;
const char *p = str;
char *endp, sign = '\0';
int carry;
assert(p);
assert(base >= 2 && base <= 36);
while (*p && isspace(*p))
p++;
if (*p == '-' || *p == '+')
sign = *p++;
〈z ← 0 253〉
carry = XP_fromstr(z->size, z->digits, p,
base, &endp);
assert(carry == 0);
normalize(z, z->size);
if (endp == p) {
endp = (char *)str;
z = AP_new(0);
} else
z->sign = iszero(z) || sign != '-' ? 1 : -1;
if (end)
*end = (char *)endp;
return z;
}
AP_fromstr将endp的地址传递给XP_fromstr,因为它需要知道扫描过程结束于哪个字符,以便检查非法的输入。如果end不是NULL,AP_fromstr将*end设置为endp。
z中比特位的数目是n·lg base,其中n是字符串中数字字符的数目,因而z中的XP_T实例中的digits数组,至少要包含m=(n·lg base)/8个字节。假定base为2k
,那么m=n·lg (2k
)/8=k·n/8。因而,如果我们选择k,使得k值最小,且2k
是大于等于base,那么z需要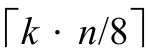 个数位。对于基数base下每个数字表示的比特位数目,k估算了其上界。例如,当base为10时,每个数位承载lg 10≈3.32比特位,k为4。当base从2增长到36时,k的变化范围为1到6。
个数位。对于基数base下每个数字表示的比特位数目,k估算了其上界。例如,当base为10时,每个数位承载lg 10≈3.32比特位,k为4。当base从2增长到36时,k的变化范围为1到6。
〈z ← 0 253〉≡
{
const char *start;
int k, n = 0;
for ( ; *p == '0' && p[1] == '0'; p++)
;
start = p;
for ( ; 〈*p is a digit in
base 253〉; p++)
n++;
for (k = 1; (1<<k) < base; k++)
;
z = mk(((k*n + 7)& ~7)/8);
p = start;
}
〈*p is a digit in
base 253〉≡
( '0' <= *p && *p <= '9' && *p < '0' + base
|| 'a' <= *p && *p <= 'z' && *p < 'a' + base - 10
|| 'A' <= *p && *p <= 'Z' && *p < 'A' + base - 10)
代码块<z←0 253>中第一个for循环,略过了前部连续的数字0。
AP_tostr可以使用类似的技巧,来估计base基数下用字符串表示x所需字符的数目n。x的digits数组中数位的数目是m=(n·lg base)/8。如果我们在2k
小于或等于base的条件下,选择最大的k值,那么m=n·lg (2k
)/8=k·n/8,n为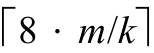 ,外加一个表示字符串结尾的0字符。这里,k估算的是在base基数下每个数位所表示比特位数的下界,因而n则估算了输出所需数位数目的上界。例如,当base为10时,x中的每个数位都可以输出8/lg 10≈2.41个十进制数位,k为3,因此为x中的每个数位分配
,外加一个表示字符串结尾的0字符。这里,k估算的是在base基数下每个数位所表示比特位数的下界,因而n则估算了输出所需数位数目的上界。例如,当base为10时,x中的每个数位都可以输出8/lg 10≈2.41个十进制数位,k为3,因此为x中的每个数位分配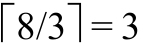 个十进制数位。当base从36变动到2时,k值的变动范围为从5到1。
个十进制数位。当base从36变动到2时,k值的变动范围为从5到1。
〈size ← number of characters in
str 253〉≡
{
int k;
for (k = 5; (1<<k) > base; k--)
;
size = (8*x->ndigits)/k + 1 + 1;
if (x->sign == -1)
size++;
}
AP_tostr用XP_tostr来计算x的字符串表示:
〈functions 241〉+≡ char *AP_tostr(char *str, int size, int base, T x) { XP_T q; assert(x); assert(base >= 2 && base <= 36); assert(str == NULL || size > 1); if (str == NULL) { 〈size ← number of characters in str 253〉 str = ALLOC(size); } q = ALLOC(x->ndigits); memcpy(q, x->digits, x->ndigits); if (x->sign == -1) { str[0] = '-'; XP_tostr(str + 1, size - 1, base, x->ndigits, q); } else XP_tostr(str, size, base, x->ndigits, q); FREE(q); return str; }
最后一个AP函数是AP_fmt,这是一个Fmt风格的转换函数,用于输出AP_T实例。它使用AP_tostr把AP_T值格式化为十进制字符串表示,并调用Fmt_putd输出字符串。
〈functions
241〉+≡
void AP_fmt(int code, va_list *app,
int put(int c, void *cl), void *cl,
unsigned char flags[], int width, int precision) {
T x;
char *buf;
assert(app && flags);
x = va_arg(*app, T);
assert(x);
buf = AP_tostr(NULL, 0, 10, x);
Fmt_putd(buf, strlen(buf), put, cl, flags,
width, precision);
FREE(buf);
}
AP_T类似于某些编程语言中的大整数(bignum)。例如,Icon比较新的版本只有一个整数类型,但根据需要可以使用任意精度算术来表示计算的值。程序员无需区分本机整数和任意精度整数。
用于任意精度算术的设施,通常以标准库或软件包的形式提供。例如,LISP语言系统很久前就包含了bignum软件包,而ML也有类似的软件包。
大多数符号运算系统都会执行任意精度算术,因为这是其目的所在。例如,Mathematica [Wolfram,1988]提供了任意长度的整数,以及分子和分母都是任意长度整数的有理数。另一种符号计算系统Maple V[Char等人,1992]也提供了类似的功能。
18.1 AP_div和AP_mod每次调用时都分配并释放临时空间。修改二者的实现,使之能够共享tmp,只需分配一次,而后可以跟踪其大小,并在必要时扩展其空间。
18.2 AP_pow中使用的递归算法,等效于我们所熟悉的迭代算法(通过重复地乘方和乘积来计算z=xy,参见[Knuth,1981]的4.6.3节):
z ← x, u ← 1 while y > 1 do if y is odd then u ← u·z z← z 2 y← y /2 z← u·z
迭代通常比递归快速,但这种方法真正的好处在于,它只需要为中间值分配比较少的空间。使用这种算法重新实现AP_pow,并测量其在时间和空间方面的改进。x和y至少有多大,这个算法才能显著好于递归算法?
18.3 实现AP_ceil(AP_T x, AP_T y)和AP_floor(AP_T x, AP_T y),二者返回x/y的向上舍入取整和向下舍入取整。其务必规定在x和y符号不同时函数的行为。
18.4 AP接口颇有些“嘈杂”,有些函数有很多参数,很容易混淆输入和输出参数。设计并实现一个新的接口,其中使用Seq_T作为栈,函数从栈中获取操作数。请专注于使接口尽可能干净,但不要省略重要的功能。
18.5 实现一个AP函数,可以在指定范围内生成均匀分布的随机数。
18.6 设计一个接口,其函数用于完成对任意n值的模n算术操作,因此这些函数的参数和返回值来自于从0到n-1的整数集。请注意除法:仅当该集合为有限域时(n为质数),除法才有定义。
18.7 两个n数位的数,计算其乘积的时间与n2 成正比(参见17.2.2节)。A. Karatsuba在1962年说明了如何使乘积运算的时间与n1.58 成正比(参见[Geddes, Czapor and Labahn,1992]的4.3节和[Knuth,1981]的4.3.3节)。一个n数位的数x,可以拆分为高低各n/2数位的和,即,x=aBn/2 +b。乘积xy可以改写为:
xy=(aBn/2 +b)(cBn/2 +d)=acBn +(ad+bc)Bn/2 +bd,
计算改写后的表达式需要4次乘法和1次加法。该中间形式的系数还可以改写为:
ad+bc=ac+bd+(a-b)(d-c).
因而,乘积xy只需要3次乘法(ac、bd和(a-b)(d-c)),两次减法,和两次加法。在n比较大时,减少一次n/2数位的乘法,可以减少乘法的执行时间,但代价是增加了表示中间值所需的空间。使用Karatsuba的算法实现AP_mul一个递归版本,确定对什么样的n值,该算法能够比显著快于“朴素”算法。使用XP_mul进行中间步骤的计算。
[1] 请注意,按本书的定义,当x和y均为负数时,x = y * q + r的关系式并不成立。——译者注