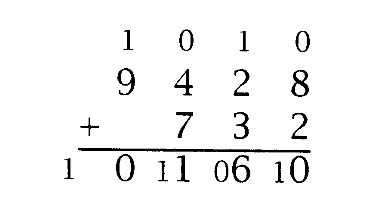
在整数位宽为32位的计算机上,能够表示从-2 147 483 648~+2 147 483 647的有符号整数(使用二进制补码表示),以及从0~4 294 967 295的无符号整数。对很多(可能是大多数)应用程序来说,上述范围已经足够大了,但有一些应用程序需要更大的表示范围。整数的表示范围相对较小,但可以表示其中每一个整数值。浮点数的表示范围很巨大,但只能表示其中相对较少的值。如果对精确值取近似是可接受的,那么可以使用浮点数,例如许多科学应用,但在需要使用一个很大的范围中所有的整数值时,就不能使用浮点数了。
本章描述了一个很底层的接口XP,它导出了一些函数,可用于固定精度扩展整数的算术操作。可以表示的值只受限于可用的内存。该接口用来服务于较高级的接口,如下两章描述的接口。这些高级接口的设计,使之可用于需要巨大范围整数值的应用程序中。
一个n个数位的无符号整数x可以表示为下述多项式:
x=xn-1 bn-1 +xn-2 bn-2 +…+x1 b1 +x0
其中b为基数,0≤xi <b。在无符号整数位宽32位的计算机上,n为32,b为2,每个系数xi 表示为(32个比特位中)对应的比特位。这种表示可以推广,用于以任意基数来表示无符号整数。例如,如果b为10,那么每个xi 是0~9(含)的一个整数,x可以表示为一个数组。数字2 147 483 647可以表示为下列数组
unsigned char x[] = { 7, 4, 6, 3, 8, 4, 7, 4, 1, 2 };
其中xi 保存在x[i]中。数位xi 在x中出现的顺序,是最低位优先,这是实现算术操作最方便的顺序。
选择较大的基数可以节省内存,因为基数越大,数位的范围越大。例如,如果b为216 =65 536,每个数位是一个0~65 535(含)的数,只需要两个数位(4个字节)即可表示2 147 483 647:
unsigned short x[] = { 65535, 32767 };
而以下包含64个数位的十进制数
349052951084765949147849619903898133417764638493387843990820577
可以表示为一个14个元素(28个字节)的数组:
{ 38625, 9033, 28867, 3500, 30620, 54807, 4503,
60627, 34909, 43799, 33017, 28372, 31785, 8 }.
如果b为2k 而k是C语言中某种预定义无符号整数类型的位宽,那么可以使用较小的基数而不会浪费空间。可能更重要的一点是,较大的基数会使某些算术操作的实现复杂化。如下文详述,如果unsigned long类型可以容纳b3 -1,那么即可避免这种复杂化。XP使用的b值为28 ,将每个数位存储在一个无符号字符中,因为标准C语言保证unsigned long位宽至少为32,其中至少包含3个字节,因此unsigned long可以容纳b3 -1=224 -1。使用b=28 ,需要花费4个字节表示2 147 483 647:
unsigned char x[] = { 255, 255, 255, 127 };
需要27个字节表示上述的64个数位的十进制数:
{ 225, 150, 73, 35, 195, 112, 172, 13, 156, 119, 23, 214, 151, 17,
211, 236, 93, 136, 23, 171, 249, 128, 212, 110, 41, 124, 8 }.
XP接口揭示了这些表示细节:
〈xp.h 〉≡ #ifndef XP_INCLUDED #define XP_INCLUDED #define T XP_T typedef unsigned char *T; 〈exported functions 214〉 #undef T #endif
即XP_T是一个由无符号字符构成的数组,包含了一个n位数的的各个数位,基数为28 ,最低位优先。
如下所述,XP接口中的函数以n为输入参数,XP_T实例为输入/输出参数,这些数组必须足够大以便容纳n个数位。向该接口中任何函数传递的XP_T实例为NULL、XP_T实例容量太小、或长度n不是正值,都是未检查的运行时错误。XP是一个危险的接口,因为省略大部分已检查的运行时错误。这种设计有两个原因。XP的目标客户程序是较高级的接口,这些接口很可能已经规定并实现了必要的已检查的运行时错误。其次,XP接口要尽可能简单,以便将其中一些函数以汇编语言实现(如果有性能方面的要求)。后一种考虑,是XP函数不进行内存分配的原因。
以下函数
〈exported functions
214〉≡
extern int XP_add(int n, T z, T x, T y, int carry);
extern int XP_sub(int n, T z, T x, T y, int borrow);
实现了z=x+y+carry和z=x-y-borrow。在此处以及下文,x、y和z指代由数组x、y和z表示的整数值,假定这些整数值包含n个数位。carry和borrow必须为0或1。XP_add将z[0..n-1]设置为x+y+carry的值(和值最多包含n个数位),并返回最高有效位的进位输出。XP_sub将z[0..n - 1]设置为x-y-borrow的值(差值最多n个数位),并返回最高有效位的借位输出。因而,如果XP_add返回1,则n个数位无法容纳x+y+carry的值,而如果XP_sub返回1,那么y>x。如果只考虑这两个函数,x、y或z中任意多个参数,均可为同一XP_T实例。
〈exported functions
214〉+≡
extern int XP_mul(T z, int n, T x, int m, T y);
上述函数实现了z=z+x*y,其中x有n个数位,y有m个数位。z必须足以容纳n+m个数位:XP_mul将n+m个数位的乘积x*y,加到z上。当z初始化为0时,XP_mul将z[0..n+m-1]设置为x*y。XP_mul的返回值,是x和y的乘积最高有效位的进位输出。如果z与x或y为同一XP_T实例,则造成未检查的运行时错误。
XP_mul说明了const限定符可以发挥作用的情形,const有助于标识输入/输出参数,还可以作为文档,以防止此类运行时错误。下述声明
extern int XP_mul(T z, int n, const unsigned char *x,
int m, const unsigned char *y);
明确地规定了XP_mul从x和y读取并写入到z,因而隐含地指出了z不应该与x或y相同。对x和y不能使用const T的语法,因为这将意味着“指向unsigned char的常数指针”,而不是我们预期的“指向unsigned char常数的指针”(参见2.4节)。习题19.5探讨了能够与const限定符正常协作的一些其他形式的T定义。
但const限定符并不能防止同一XP_T实例分别作为x和z(或y和z)传递,因为unsigned char *类型的值可以传递给const unsigned char *类型的参数。但const的这种用法,确实允许将一个const unsigned char *类型的值作为x和y传递,在XP接口声明的上述XP_mul函数中,必须使用类型转换来传递这些值。在XP接口中,const的少量好处,很难平衡其冗长啰嗦的缺点。
以下函数
〈exported functions
214〉+≡
extern int XP_div(int n, T q, T x, int m, T y, T r,T tmp);
实现了除法:它计算了q=x/y和r=x mod y,q和x有n个数位,r和y有m个数位。如果y为0,XP_div返回0,不改变q和r,否则,它将返回1。tmp必须能够容纳至少n+m+2个数位。q或r与x和y中之一相同、q和r是同一XP_T实例、tmp能够容纳的数位太少,都是未检查的运行时错误。
以下函数
〈exported functions
214〉+≡
extern int XP_sum (int n, T z, T x, int y);
extern int XP_diff (int n, T z, T x, int y);
extern int XP_product (int n, T z, T x, int y);
extern int XP_quotient(int n, T z, T x, int y);
实现了n个数位的XP_T实例x和单个数位的整数值y(基数28 )之间的加法、减法、乘法和除法。XP_sum将z[0..n - 1]设置为x+y的值,并返回最高有效位的进位输出。XP_diff将z[0..n - 1]设置为x-y的值,并返回最高有效位的借位输出。对于XP_sum和XP_diff,y必须为正数且不能大于基数28 。
XP_product将z[0..n - 1]设置为x*y的值,并返回最高有效位的进位输出,进位最大为28 -1。XP_quotient将z[0..n - 1]设置为x/y的值并返回余数x mod y,余数最大为y-1。对于XP_product和XP_quotient,y不能大于28 -1。
〈exported functions
214〉+≡
extern int XP_neg(int n, T z, T x, int carry);
该函数将z[0..n - 1]设置为~x + carry的值,并返回最高有效位的进位输出。在carry为0时,XP_neg实现了取反(one's complement negation),在carry为1时,XP_neg实现了求补(two's complement negation)。
XP_T实例通过下列函数比较
〈exported functions
〉+≡
extern int XP_cmp(int n, T x, T y);
对于x<y、x=y或x>y三种情形,该函数分别返回负值、0、正值。
可以用下列函数对XP_T进行移位操作:
〈exported functions
214〉+≡
extern void XP_lshift(int n, T z, int m, T x,
int s, int fill);
extern void XP_rshift(int n, T z, int m, T x,
int s, int fill);
上述两个函数分别将x左移/右移s个比特位得到的值赋值给z,其中z有n个数位,x有m个数位。当n大于m时,x高位缺失的那些数位,如果进行左移,则其中的比特位当做0处理,如果进行右移,其中的比特位当做fill处理。空出的比特位用fill填充,fill必须为0或1。fill为0时,XP_rshift实现了逻辑右移(logical right shift),fill为1时,XP_rshift可用于实现算术右移(arithmetic right shift)。
〈exported functions
214〉+≡
extern int XP_length (int n, T x);
extern unsigned long XP_fromint(int n, T z,
unsigned long u);
extern unsigned long XP_toint (int n, T x);
XP_length返回x中数位的数目,即,它返回x[0..n-1]中最高非零数位的索引加1。XP_fromint将z [ 0..n – 1]设置为u mod 28n 并返回u/28n ,即返回u中z无法容纳的那些比特位。XP_toint返回x mod (ULONG_MAX+1),即x中最低8 * sizeof(unsigned long)个比特位。
剩余的XP函数负责在字符串和XP_T之间进行双向转换。
〈exported functions
214〉+≡
extern int XP_fromstr(int n, T z, const char *str,
int base, char **end);
extern char *XP_tostr (char *str, int size, int base,
int n, T x);
XP_fromstr类似C库中的strtoul,它将str中的字符串解释为以base为基数的无符号整数。该函数忽略字符串开头的空白字符,并处理其后以base为基数的一个或多个数位。对于11~36的基数来说,XP_fromstr将小写或大写字母解释为大于九的数位。base小于2或大于36,则为已检查的运行时错误。
在计算 str指定的整数时,将使用通常的乘法算法,逐位累积计算,保存至n数位的XP_T实例z:
for (p = str; *p is a digit ; p++) z ← base*z + *p's value
函数的实现中,不会将z初始化为0,客户程序必须正确地初始化z值。在一系列的base * z乘法运算中,当第一次出现非零进位输出时,该进位输出值将用作XP_fromstr的返回值,如果始终都没有非零进位输出,则返回0。因而,如果z无法容纳str指定的数字,则XP_fromstr将返回非零值。
如果end不是NULL,函数会将*end指向XP_fromstr的解释过程结束的那个字符,此时可能发生了乘法上溢或扫描到非数字字符。如果str中的各个字符不是基数base下的整数,那么XP_fromstr将返回0,并将*end设置为str(如果end不是NULL)。str是NULL,则造成已检查的运行时错误。
XP_tostr将x在基数base下的字符表示填充到str中(以0结尾),并返回str。x将设置为零。在base大于10时,大写字母用于表示大于9的数位。base小于2或大于36,则为已检查的运行时错误。str为NULL或size太小,也是已检查的运行时错误,size太小,是指x的字符表示加上一个0字符,超出size个字符的情形。
〈xp.c 〉≡ #include <ctype.h> #include <string.h> #include "assert.h" #include "xp.h" #define T XP_T #define BASE (1<<8) 〈data 229〉 〈functions 217〉
XP_fromint和XP_toint说明了XP函数必须执行的各种算术操作。XP_fromint初始化一个XP_T,使之等于某个指定的unsigned long值:
〈functions
217〉≡
unsigned long XP_fromint(int n, T z, unsigned long u) {
int i = 0;
do
z[i++] = u%BASE;
while ((u /= BASE) > 0 && i < n);
for ( ; i < n; i++)
z[i] = 0;
return u;
}
严格来说,u%BASE不是必需的,因为对z[i]的赋值隐含地进行了模操作。所有实现算术操作的XP函数都执行了此类显式操作,以便协助说明函数使用的算法。由于基数是2的常数次幂,大多数编译器会将基数相关的乘法、除法、取模转换为等效的左移、右移、逻辑与。
XP_toint是XP_fromint的逆:它将XP_T的最低8 * sizeof(unsigned long)个比特位当做unsigned long返回。
〈functions
217〉+≡
unsigned long XP_toint(int n, T x) {
unsigned long u = 0;
int i = (int)sizeof u;
if (i > n)
i = n;
while (--i >= 0)
u = BASE*u + x[i];
return u;
}
一个非零的n数位XP_T,如果其最高位部分是一个或多个连续的0,那么其有效数位的数目要少于n。XP_length返回有效数位的数目,不计算最高有效位之前的0数位:
〈functions
217〉+≡
int XP_length(int n, T x) {
while (n > 1 && x[n-1] == 0)
n--;
return n;
}
实现加减法的算法,实际上是小学里笔算技巧的系统化再现。假定基数为10,下述例子很好地说明了加法z=x+y:
加法的过程从最低有效位到最高有效位进行,在本例中,进位值的初始值为0。每一步都建立和值S=carry+xi +yi ,zi 的值为S mod b,新的进位值为S/b,其中b为基数,本例中为10。顶行中以小号字体显示的数字是进位值,底部一行中以两个数位显示的数字是S的值。在本例中,进位输出为1,因为4个数位无法容纳和值。XP_add精确地实现了本算法,并返回最终的进位值:
〈functions
217〉+≡
int XP_add(int n, T z, T x, T y, int carry) {
int i;
for (i = 0; i < n; i++) {
carry += x[i] + y[i];
z[i] = carry%BASE;
carry /= BASE;
}
return carry;
}
循环的每一次迭代中,carry暂时保存了对应于当前数位的和值S,而后的除法,使得carry只包含进位值。各个数位都是0和b-1之间的一个数字,进位值可以为0或1,因此对单个数位来说,和值S的最大值为(b-1)+(b-1)+1=2b-1=511,很容易放入一个int值中。
减法z=x-y,类似于加法:
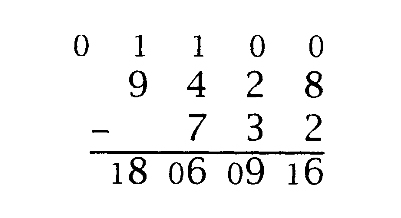
减法的过程从最低有效位到最高有效位进行,在本例中,借位值的初始值为0。每一步都形成差值D=xi +b-borrow-yi ,zi 的值为D mod b,新的借位值为1-D/b。顶行中以小号字体显示的数字是借位值,底部一行中以两个数位显示的数字是D的值。
〈functions
217〉+≡
int XP_sub(int n, T z, T x, T y, int borrow) {
int i;
for (i = 0; i < n; i++) {
int d = (x[i] + BASE) - borrow - y[i];
z[i] = d%BASE;
borrow = 1 - d/BASE;
}
return borrow;
}
D至多为(b-1)+b-0-0=2b-1=511,很容易放入一个int值中。如果最终的借位值非零,那么x小于y。
单数位加减法 [1] 比通用的函数简单些,它们使用第二个操作数作为进位或借位:
〈functions
217〉+≡
int XP_sum(int n, T z, T x, int y) {
int i;
for (i = 0; i < n; i++) {
y += x[i];
z[i] = y%BASE;
y /= BASE;
}
return y;
}
int XP_diff(int n, T z, T x, int y) {
int i;
for (i = 0; i < n; i++) {
int d = (x[i] + BASE) - y;
z[i] = d%BASE;
y = 1 - d/BASE;
}
return y;
}
XP_neg类似单数位加法,但x的各个数位在加法之前会取反:
〈functions
217〉+≡
int XP_neg(int n, T z, T x, int carry) {
int i;
for (i = 0; i < n; i++) {
carry += (unsigned char)~x[i];
z[i] = carry%BASE;
carry /= BASE;
}
return carry;
}
到unsigned char的类型转换确保了~x[i]的值小于b。
如果x有n个数位而y有m个数位,z=x*y会形成m个部分积,每个部分积都有n个数位,这m个部分积的和有n+m个数位。以下例子说明了当z的初始值为0、n为4、m为3的情形下,乘法执行的过程:
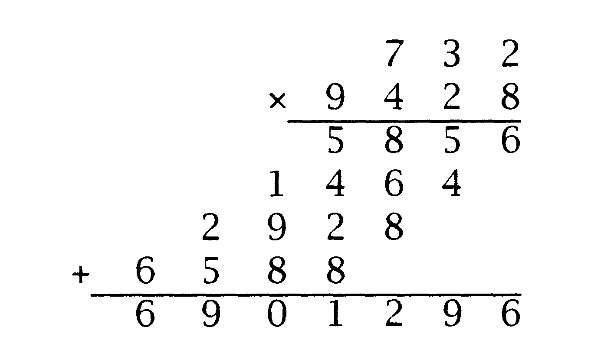
部分积不必明确地计算出来,在计算乘积中的的各个数位时,每个部分积都会加到z上。例如,第一个部分积8 * 732中的各个数位,会从最低有效位到最高有效位进行计算。该部分积的第i个数位将加到z的第i个数位,同时还会应用加法中的进位计算。第二个部分积2 * 732的第i个数位,加到z的第i+1个数位。一般来说,当计算涉及xi 的部分积时,该部分积的各个数位将从z的第i个数位开始,加到z上。
〈functions
217〉+≡
int XP_mul(T z, int n, T x, int m, T y) {
int i, j, carryout = 0;
for (i = 0; i < n; i++) {
unsigned carry = 0;
for (j = 0; j < m; j++) {
carry += x[i]*y[j] + z[i+j];
z[i+j] = carry%BASE;
carry /= BASE;
}
for ( ; j < n + m - i; j++) {
carry += z[i+j];
z[i+j] = carry%BASE;
carry /= BASE;
}
carryout |= carry;
}
return carryout;
}
因为在第一个嵌套循环中,来自部分积的各个数位加到z上,进位值最大可以达到b-1,因此保存在carry中的和值,最大可以达到(b-1)(b-1)+(b-1)=b2 -b=65 280,unsigned类型完全可以容纳该值。在将一个部分积加到z之后,第二个嵌套循环将进位值加到z中余下的数位上,并记录“这次”加法中z的最高位的进位。如果该进位值为1,则z+x*y的进位输出为1。
单数位乘法相当于XP_mul的特例,即m等于1、z初始化为0的情形:
〈functions
217)+≡
int XP_product(int n, T z, T x, int y) {
int i;
unsigned carry = 0;
for (i = 0; i < n; i++) {
carry += x[i]*y;
z[i] = carry%BASE;
carry /= BASE;
}
return carry;
}
除法是最复杂的算术函数。有几种算法可以使用,其各有优缺点。可能其中最容易理解的算法,来自于计算q=x/y和r=x mod y的下述数学规则。
if x < y then q ← 0, r ← x else q′ ← x /2y , r′ ← x mod 2y if r′ < y then q ← 2q′ , r ← r′ else q ← 2q′ + 1, r ← r′ - y
当然,涉及q′和r′的中间计算必须使用XP_T完成。
这个递归算法的问题在于对q′和r′的内存分配。这种分配可能多达lg x次(这里,lg是以2为底的对数),因为lg x是递归深度的最大值。XP接口禁止这种隐含的内存分配。
对于x≥y且y至少有两个有效数位的一般情形,XP_div使用了一种高效的迭代算法,对x<y的情形和y只有一个数位的情形,将使用更为简单的算法。
〈functions 217〉+≡ int XP_div(int n, T q, T x, int m, T y, T r, T tmp) { int nx = n, my = m; n = XP_length(n, x); m = XP_length(m, y); if (m == 1) { 〈single-digit division 222〉 } else if (m > n) { memset(q, '\0', nx); memcpy(r, x, n); memset(r + n, '\0', my - n); } else { 〈long division 223〉 } return 1; }
XP_div首先检查是否为单数位除法,该情形隐含了对除以零的处理。
单数位除法很容易,因为商的各个数位可以使用C语言中普通的无符号整数除法计算。除法从最高位到最低位进行,进位值的初始值为零。十进制下的9428除以7,即说明了除法涉及的各个步骤:
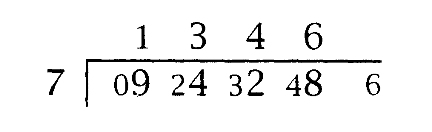
在每一步,部分被除数R=carry*b+xi ,商的数位qi =R/y0 ,新的进位值为R mod y0 。进位值是上图中以小号字体显示的数位。进位值的最终值即为余数。这正是XP_quotient所实现的操作,该函数返回余数:
〈functions
217〉+≡
int XP_quotient(int n, T z, T x, int y) {
int i;
unsigned carry = 0;
for (i = n - 1; i >= 0; i--) {
carry = carry*BASE + x[i];
z[i] = carry/y;
carry %= y;
}
return carry;
}
R在XP_quotient中赋值给carry,其最大值为(b-1)b+(b-1)=b2 -1=65535,unsigned类型值可以容纳该值。
在XP_div中,调用XP_quotient返回的是r的最低有效位,因此其余数位必须明确设置为0:
〈single-digit division
222〉≡
if (y[0] == 0)
return 0;
r[0] = XP_quotient(nx, q, x, y[0]);
memset(r + 1, '\0', my - 1);
在一般情况下,n个数位的被除数除以m个数位的除数,其中n≥m且m>1。在基数10下,将615 367除以296,就说明了除法的计算过程。被除数最高位之前会补一个0数位,使得n大于m:
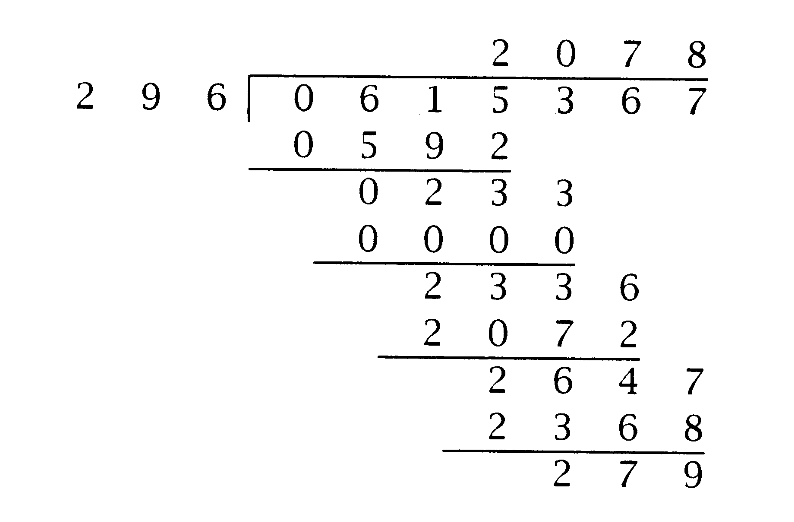
高效地计算商的每个数位qk ,是比较长的除法问题的关键,因为其中的计算涉及m个数位的操作数。
暂且假定我们知道如何计算商的各个数位,那么以下伪代码勾勒出了长除法的一个实现。
rem ← x最高位前补0
for (k = n - m; k >= 0; k--) {
compute qk
dq ← y*qk
q->digits[k] = qk;
rem ← rem - dq*b
k
}
r ← rem
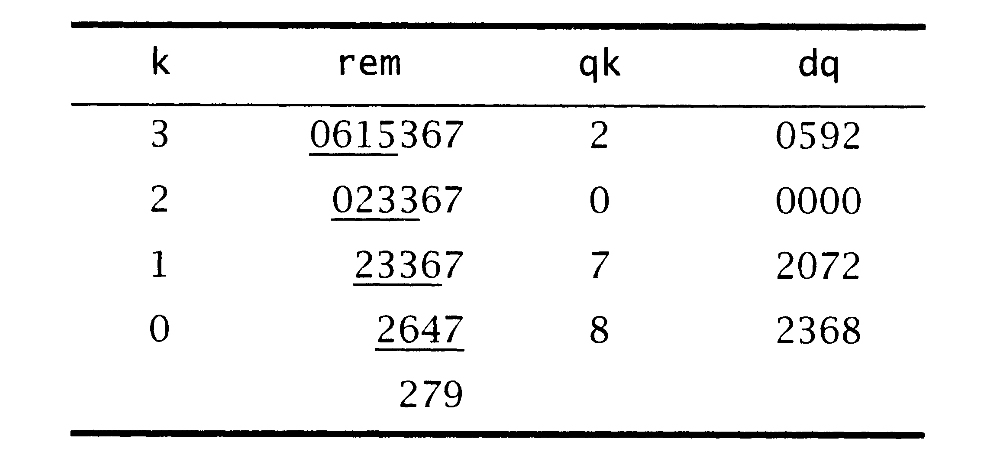
rem的初始值等于x,最高位前补0。循环中计算了商的n-m+1个数位,首先将rem的前m+1个数位作为被除数,除以m个数位的除数,计算得到商的最高有效位。在每次迭代结束时,从rem减去qk和y的乘积,这会将rem减少一个数位。对上例来说,n=6,m=3,循环体执行了四次,k值分别为6-3=3、2、1、0。下表列出了每个迭代中k、rem、qk和dq的值。第二列中的下划线标识出了rem中除以y的前缀部分,即296。
XP_div需要空间来容纳两个临时变量rem和dq的各个数位,它需要为rem分配n+1个字节、需要为dq分配m+1个字节,这是tmp必须至少为n+m+2个字节长的原因。在上述的伪代码框架中填入实际内容,用于长除法的代码块即演变为如下的形式:
〈long division 223〉≡ int k; unsigned char *rem = tmp, *dq = tmp + n + 1; assert(2 <= m && m <= n); memcpy(rem, x, n); rem[n] = 0; for (k = n - m; k >= 0; k--) { int qk; 〈compute qk, dq ← y*qk 224〉 q[k] = qk; 〈rem ← rem - dq*bk 225〉 } memcpy(r, rem, m); 〈fill out q and r with 0s 224〉
tmp[0..n]容纳了rem的n+1个数位,而tmp[n+1..n+1+m]容纳了dq的m+1个数位。在tmp[0..k+m]中,总是包含rem的k+m+1个数位。下列代码计算了一个n - m + 1个数位的商,和一个m个数位的余数,q和r中其余的数位必须都设置为0:
〈fill out q and r with 0s 224〉≡ { int i; for (i = n-m+1; i < nx; i++) q[i] = 0; for (i = m; i < my; i++) r[i] = 0; }
到这里,只缺少计算商的各个数位所需的逻辑。一个简单但不当的方法是:将qk的初值设置为b-1,然后在一个循环中,只要y * qk大于rem的前m+1个数位,就将qk减1:
qk = BASE-1;
dq ← y*qk;
while (rem[k..k+m] < dq) {
qk--;
dq ← y*qk;
}
这种方法太慢:该循环可能需要b-1次迭代,每个迭代需要m个数位的乘法和m+1个数位的比较。更好的方法是使用通常的整数运算更精确地估计qk的值,并在估计错误时进行校正。实际上,用rem的前三个数位除以y的前两个数位,即可得到对qk的估计值,该值可能是正确的,或者比正确值大1。因而,上述的循环可以替换为一个简单的测试:
〈compute
qk, dq ← y*qk 224〉≡
{
int i;
assert(2 <= m && m <= k+m && k+m <= n);
〈qk ← y[m-2..m-1]/rem[k+m-2..k+m] 225〉
dq[m] = XP_product(m, dq, y, qk);
for (i = m; i > 0; i--)
if (rem[i+k] != dq[i])
break;
if (rem[i+k] < dq[i])
dq[m] = XP_product(m, dq, y, --qk);
}
上述代码块使用XP_product计算y[0..m - 1] * qk,将结果赋值给dq,返回最终的进位值,即dq的最高一个数位。for循环逐数位比较rem[k..k+m]和dq。如果dq大于rem的前m+1个数位,则qk比实际的正确值大1,所以将qk减1并重新计算dq。
可以利用普通的整数除法来估算qk:
〈qk ← y[m-2..m-1]/rem[k+m-2..k+m] 225〉≡
{
int km = k + m;
unsigned long y2 = y[m-1]*BASE + y[m-2];
unsigned long r3 = rem[km]*(BASE*BASE) +
rem[km-1]*BASE + rem[km-2];
qk = r3/y2;
if (qk >= BASE)
qk = BASE - 1;
}
r3最大为(b-1)b2 +(b-1)b+(b-1)=b3 -1=16777215,unsigned long类型可以容纳r3。这个计算,实际上限制了对BASE值的选择。unsigned long可以容纳小于232 的值,这要求b3 -1<232 ,因此BASE必须小于210.6666 ,即BASE不能大于1625。在2的各个幂中,256是不大于1625的最高次幂,而且刚好是另一个内建类型(unsigned char)所能容纳的最大值。
解决长除法问题,最后一步是从rem的前m+1个数位中减去dq,这减小了rem,并使其减少一个数位。在概念上,可以先算出dq左移k个数位后的值,并从rem减去该值,即可完成该减法。上文给出的XP_sub,可用于完成这个减法运算,只需要将指向适当数位的指针传递给XP_Sub即可:
〈rem ← rem - dq*bk
225〉≡
{
int borrow;
assert(0 <= k && k <= k+m);
borrow = XP_sub(m + 1, &rem[k], &rem[k], dq, 0);
assert(borrow == 0);
}
<compute qk, dq←y*qk 224>中的代码说明,可以通过从最高有效位开始逐一比较各个数位,来比较两个多数位的数字。XP_cmp刚好是用这个方法来比较两个XP_T参数的:
〈functions
217〉+≡
int XP_cmp(int n, T x, T y) {
int i = n - 1;
while (i > 0 && x[i] == y[i])
i--;
return x[i] - y[i];
}
XP的实现中,有两个函数可以将XP_T左移/右移指定数目的比特位。移位s个比特位,通过两步完成:第一步移位8 * (s/8)个比特位,每次移动一个字节,第二步移位剩余的s mod 8个比特位,一次完成。fill设置为全1或全0的字节值(即0xff或0),以便使用该值一次填充一个字节,如下所示。
〈functions 217〉+≡ void XP_lshift(int n, T z, int m, T x, int s, int fill) { fill = fill ? 0xFF : 0; 〈shift left by s/8 bytes 226〉 s %= 8; if (s > 0) 〈shift z left by s bits 227〉 }
图17-1说明了这些步骤,图中原本是一个六个数位的XP_T,包含44个值为1的比特位,在左移13个比特位后,形成了一个八个数位的XP_T,在右侧的浅色阴影标识了移位后空出的比特位,这些将设置为fill。
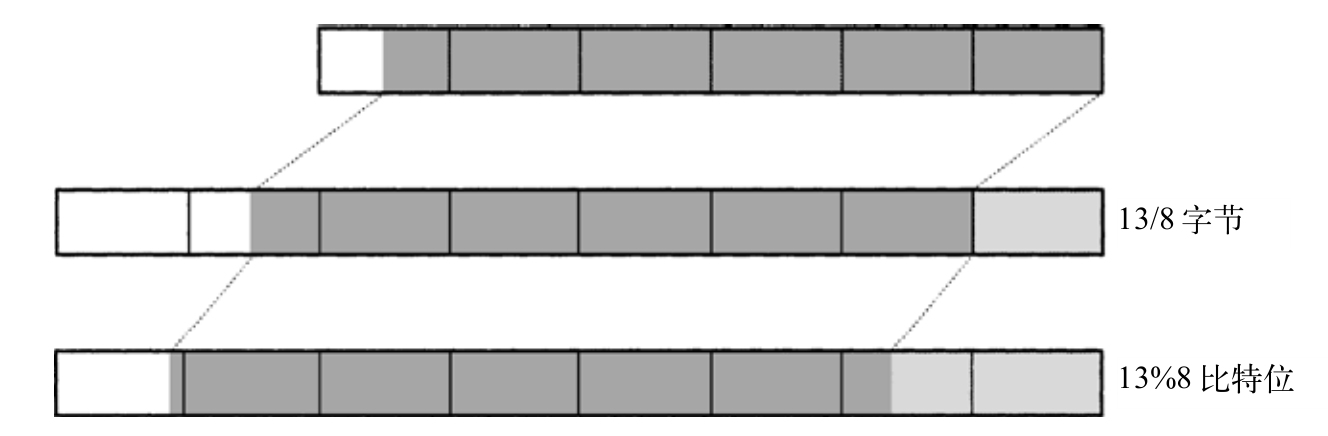
图17-1 左移13个比特位
左移s/8个字节,可以通过下列赋值操作概述。
z[m+(s/8)..n-1] ← 0 z[s/8..m+(s/8)-1] ← x[0..m-1] z[0..(s/8)-1] ← fill.
第一个赋值操作,将z中不出现(在x左移s/8字节后)的数位清零。在第二个赋值操作中,xi 复制到zi+s/8 ,首先复制最高有效字节;第三个赋值操作,将z的s/8个最低有效字节设置为fill。这些赋值操作都涉足到循环,初始化代码会处理n小于m的情形:
〈shift left by s/8 bytes 226〉≡ { int i, j = n - 1; if (n > m) i = m - 1; else i = n - s/8 - 1; for ( ; j >= m + s/8; j--) z[j] = 0; for ( ; i >= 0; i--, j--) z[j] = x[i]; for ( ; j >= 0; j--) z[j] = fill; }
在第二步中,s已经简化为需要移位的比特位数目。
这种移位等效于将z乘以2s ,然后将z的s个最低有效比特位设置为fill。
〈shift z left by s bits 227〉≡ { XP_product(n, z, z, 1<<s); z[0] |= fill>>(8-s); }
fill是0或0xFF,因此fill >> (8-s)形成了s个填充比特位,可用于字节的最低s个比特位。
右移也使用了一个类似的两步过程:第一步右移s/8个字节,第二步右移余下的s mod 8个比特位。
〈functions 217〉+≡ void XP_rshift(int n, T z, int m, T x, int s, int fill) { fill = fill ? 0xFF : 0; 〈shift right by s/8 bytes 228〉 s %= 8; if (s > 0) 〈shift z right by s bits 228〉 }
将一个六个数位的XP_T(包含44个值为1的比特位)右移13个比特位,到一个八数位的XP_T中,这一过程说明了右移的步骤,如图17-2所示,左侧的浅色阴影同样标识了空出和过多的比特位,这些比特位将设置为fill。
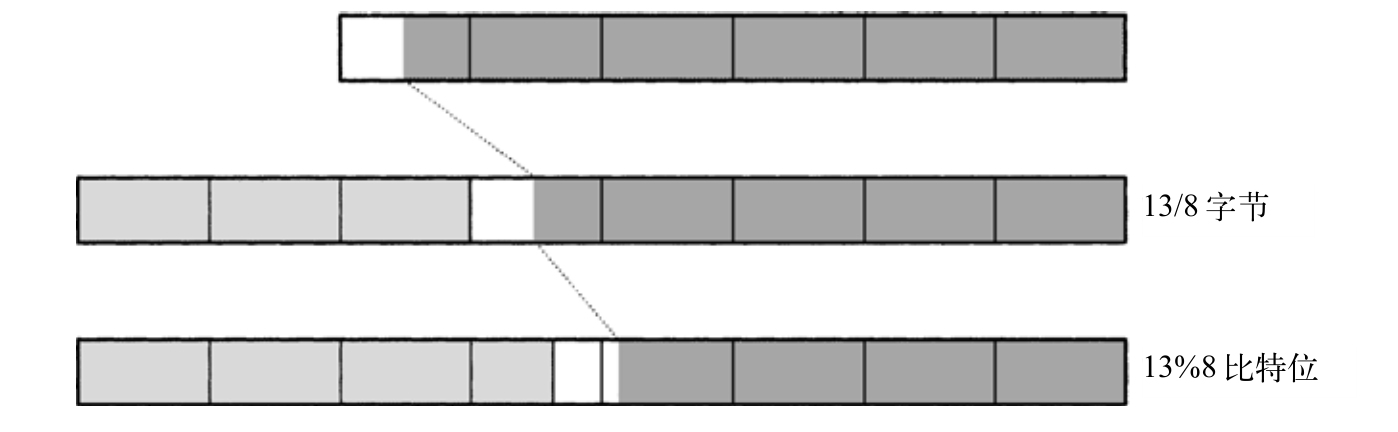
图17-2 右移13个比特位
概述右移过程的三个赋值操作如下
z[0..m-(s/8)-1] ← x[s/8..m-1] z[m-(s/8)..m-1] ← fill z[m..n-1] ← fill.
第一个赋值操作将xi 复制到zi-s/8 ,首先复制最低有效字节,从字节s/8开始复制。第二个赋值操作将空出的字节设置为fill,第三个赋值操作将z中未出现在x中的数位设置为fill。当然,第二个和第三个赋值操作可以通过同一个循环完成:
〈shift right by s/8 bytes 228〉≡ { int i, j = 0; for (i = s/8; i < m && j < n; i++, j++) z[j] = x[i]; for ( ; j < n; j++) z[j] = fill; }
第二步将z右移s个比特位,等效于将z除以2s :
〈shift z right by s bits 228〉≡ { XP_quotient(n, z, z, 1<<s); z[n-1] |= fill<<(8-s); }
表达式fill << (8-s)形成了s个填充比特位,可用于字节的最高s个比特位,可以按位或到z的最高有效字节中。
XP的最后二个函数用于XP_T与字符串的双向转换。XP_fromstr将字符串转换为XP_T,该函数可处理的字符串,首先是可选的空格,后接一个或多个数位(数位值受指定基数的限制,基数的范围在2~36)。对于大于10的基数,用字母来表示大于9的数位。在遇到非法字符或0字符时,或乘法的进位输出非零时,XP_fromstr停止扫描字符串参数。
〈functions 217〉+≡ int XP_fromstr(int n, T z, const char *str, int base, char **end) { const char *p = str; assert(p); assert(base >= 2 && base <= 36); 〈skip white space 229〉 if (〈*p is a digit in base 229〉) { int carry; for ( ; 〈*p is a digit in base 229〉; p++) { carry = XP_product(n, z, z, base); if (carry) break; XP_sum(n, z, z, map[*p-'0']); } if (end) *end = (char *)p; return carry; } else { if (end) *end = (char *)str; return 0; } } 〈skip white space 229〉≡ while (*p && isspace(*p)) p++;
如果end不是NULL,XP_fromstr将*end设置为指向停止扫描时的字符。
如果c为数位字符,map[c-'0']是对应的数位值,例如,map['F' - '0']为15。
〈data
229〉≡
static char map[] = {
0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
36, 36, 36, 36, 36, 36, 36,
10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22,
23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35,
36, 36, 36, 36, 36, 36,
10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22,
23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35
};
在ASCII字符'0'和'z'之间,对于少量无效的数位字符c来说,map[c - '0']为36。这样,在以base为基数时,只要map[c - '0']小于base,那么c就是一个合法的数位字符。因而,XP_fromstr可以用下述方式来测试*p是否为数位字符:
〈*p is a digit in base
229〉≡
(*p && isalnum(*p) && map[*p-'0'] < base)
XP_tostr使用通常的算法来计算x的字符串表示,首先剥离最后一个数位,当然,XP_tostr使用了XP接口中现有的函数来执行计算。
〈functions 217〉+≡ char *XP_tostr(char *str, int size, int base, int n, T x) { int i = 0; assert(str); assert(base >= 2 && base <= 36); do { int r = XP_quotient(n, x, x, base); assert(i < size); str[i++] = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ"[r]; while (n > 1 && x[n-1] == 0) n--; } while (n > 1 || x[0] != 0); assert(i < size); str[i] = '\0'; 〈reverse str 230〉 return str; }
str中的各个字符是前后反向的,因此XP_tostr在结束前需要将这些字符逆转过来。
〈reverse
str 230〉≡
{
int j;
for (j = 0; j < --i; j++) {
char c = str[j];
str[j] = str[i];
str[i] = c;
}
}
XP中大部分算术函数都直接了当地实现了小学生水平的四则运算算法。[Hennessy and Patterson,1994]中的第4章和[Knuth,1981]中的4.3节都描述了实现算术操作的经典算法。[Knuth,1981]很好地综述了这些算法的悠久历史。
除法的实现比较困难,因为在计算商的各个数位时,有一些强加的约束。XP_div中使用的算法取自[Brinch-Hansen,1994],该论文包含了对“商数位估计值最多只大1”结论的证明。Brinch-Hansen还说明了,可以通过按比例放大操作数,在大多数情况下都可以避免校正qk。按比例放大,只需要一次额外的单数位乘法和除法,但在大多数情况下可以避免(因qk必须减1而导致的)第二次乘法运算。
17.1 实现递归式除法算法,并对照XP_div中使用的Brinch-Hansen算法,比较算法执行的时间和空间性能。是否在某些情况下,递归算法更可取?
17.2 实现[Hennessy and Patterson,1994]的第4章中描述的“移位相减”式除法算法,并对照XP_div中使用的Brinch-Hansen算法,比较其性能。
17.3 XP接口中的大部分函数,执行时间都与操作数中数位的数目成正比。因而,以216 为基数来表示XP_T,将使这些函数运行速度提高到原来的两倍。但除法有个问题,因为
(216 )3 -1=28 147 497 610 655.
在大多数32位计算机上该值都大于ULONG_MAX,无法使用普通的C语言整数运算(以一种可移植的方式)来估算商的数位。设计一种方法绕过这个问题,使用216 为基数实现XP接口,并测量这种做法带来的好处。这种做法带来了好处,但是否值得为此而增加除法实现的复杂性?
17.4 针对基数232 ,重新完成习题17.3。
17.5 使用更大基数如232 的扩展精度算术,通常更容易用汇编语言实现,因为许多机器提供了双精度指令,通常也很容易获得进位和借位值。而且,汇编语言实现也总是更快。请读者在喜爱的计算机上用汇编语言重新实现XP接口,并测定其在速度方面的改进。
17.6 实现一个XP函数,可以在指定范围内生成均匀分布的随机数。
[1] 有一个操作数只有单个数位。——译者注