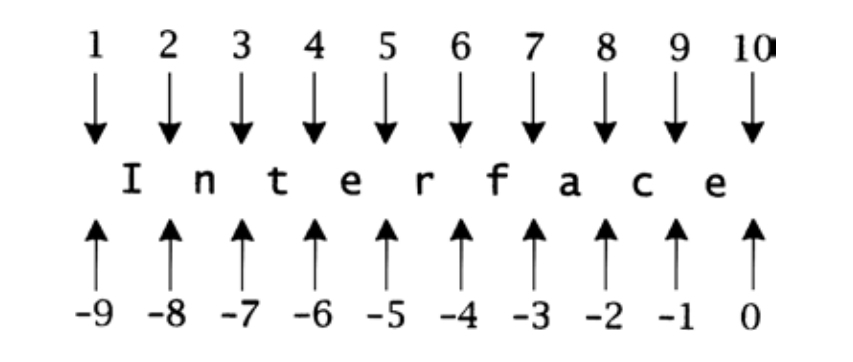
图15-1 Interface中各个字符的位置
C语言本来并非处理字符串的语言,但它确实包含了操纵字符数组的功能,这种字符数组通常称作字符串。按照惯例,一个N个字符的字符串是一个包含N+1字符的数组,最后一个字符是0字符,即其值为0。
该语言本身只有两个特性有助于处理字符串。指向字符的指针可用于遍历字符数组,而字符串常数(literal,指字面常数,本章中均译为常数)可用于初始化字符数组。例如,
char msg[] = "File not found";
是对以下语句的简写:
char msg[] = { 'F', 'i', 'l', 'e', ' ', 'n', 'o', 't',
' ', 'f', 'o', 'u', 'n', 'd', '\0' };
顺便提及,字符常数(如'F')的类型是int,而不是char,这也解释了为何sizeof 'F'等于sizeof(int)。
字符串常数还可以代表初始化为给定字符串的字符数组。例如,
char *msg = "File not found";
等效于
static char t376[] = "File not found"; char *msg = t376;
其中t376是编译器生成的一个内部变量名。
在可以使用只读数组名称的任何位置,都可以使用字符串常数。例如,Fmt的cvt_x在一个表达式中使用了一个字符串常数:
do
*--p = "0123456789abcdef"[m&0xf];
while ((m >>= 4) != 0);
该赋值等效于下述更详细的语句:
{
static char digits[] = "0123456789abcdef";
*p++ = digits[m&0xf];
}
这里digits是编译器生成的变量名。
C库包含了一组操纵0结尾字符串的函数。这些函数定义在标准头文件string.h中,可以复制、搜索、扫描、比较和转换字符串。其中strcat颇具代表性:
char *strcat(char *dst, const char *src)
该函数将字符串src追加到dst的末端,即,它将src字符串中包括结尾0字符在内的所有字符,复制到dst中从0字符开始的连续内存区域中。
strcat说明了string.h中定义的各个函数的两个缺点。首先,客户程序必须为结果分配空间,如strcat中的dst。其次,也是最重要的,所有这些函数都是不安全的,其中任何一个函数都无法检查结果字符串是否包含足够的空间。如果dst没有足够的空间容纳来自src的各个字符,strcat会将这些字符溢出到未分配的空间或用于其他用途的空间中。其中一些函数,如strncat,有额外的参数来限制复制到结果的字符数,这有助于防止此类错误,但分配错误仍然可能发生。
本章描述的Str接口中的函数,可以避免这些缺点,并提供了一个方便的方法来操作其字符串参数的子串。这些函数比string.h中的那些更为安全,因为大部分Str函数会为其结果分配空间。与这些分配操作相关的成本,就是为安全性付出的代价。
通常,这些分配操作时无论如何都需要进行的,因为当string.h函数的结果的长度取决于计算的结果时,客户程序必须为结果分配大小适当的空间。类似于string.h函数,Str函数的客户程序仍然必须释放返回的结果。下一章描述的Text接口会导出另一组字符串处理函数,可以避免Str函数的一些分配开销。
〈str.h 〉≡ #ifndef STR_INCLUDED #define STR_INCLUDED #include <stdarg.h> 〈exported functions 174〉 #undef T #endif
Str接口中的函数的所有字符串参数,都通过一个指向0结尾字符数组的指针和该数组中的位置 给出。类似于Ring中的位置,字符串位置标识了各个字符之间 的位置,以及最后一个非0字符之后的位置。正数位置指定了从字符串左端起的位置,位置1是第一个字符左侧的位置。非正数位置指定了从字符串右侧起的位置,位置0是最后一个字符右侧的位置。例如,图15-1给出了字符串Interface中的各个位置。
图15-1 Interface中各个字符的位置
字符串s中的两个位置i和j指定了两个位置之间的子串,记作s[i:j]。如果s指向字符串Interface,那么s[-4:0]是子串face。这些位置可以按任意顺序给出:s[0:-4]同样指定了子串face。子串可以为NULL,s[3:3]和s[3:-7]都指定了Interface中n和t之间的NULL子串。对任何有效位置i,s[i:i+1]总是i右侧的字符(最右侧的位置除外)。
字符索引是另一种指定子串的方法,这种方法看起来更为自然,但却有不利之处。在用索引指定子串时,顺序很重要。例如,字符串Interface中索引值从0到9(含)。如果用两个索引指定子串,子串从第一个索引之后 开始、在第二个索引之前 结束,那么s[1..6]指定了子串terf。但该约定必须允许使用0字符的索引,才能用s[4..9]指定子串face,而且无法指定字符串起点处的NULL子串。改变该约定,使得子串结束于第二个索引之后 ,那就无法指定NULL子串。其他使用负数索引的约定也可以使用,但与这里的位置约定相比,更显笨拙。 [1]
位置比字符索引要好,因为它们避免了令人迷惑的边界情况。而且非正数位置可以在不知道字符串长度的情况下来访问字符串的尾部 [2] 。
Str接口导出的函数可以创建并返回0结尾字符串,且返回有关其中字符串和位置的信息。创建字符串的函数是:
〈exported functions
174〉≡
extern char *Str_sub(const char *s, int i, int j);
extern char *Str_dup(const char *s, int i, int j, int n);
extern char *Str_cat(const char *s1, int i1, int j1,
const char *s2, int i2, int j2);
extern char *Str_catv(const char *s, ...);
extern char *Str_reverse(const char *s, int i, int j);
extern char *Str_map(const char *s, int i, int j,
const char *from, const char *to);
所有这些函数都会为结果分配空间,它们都可能引发Mem_Failed异常。向该接口中任何函数传递NULL字符串指针都是已检查的运行时错误(下文对Str_catv和Str_map详述的情况除外)。
Str_sub返回s[i:j],它是s中位于位置i和j之间的子串。例如,以下调用
Str_sub("Interface", 6, 10)
Str_sub("Interface", 6, 0)
Str_sub("Interface", -4, 10)
Str_sub("Interface", -4, 0)
都返回face。位置可以按任意顺序给出。向该接口中任何函数传递的i和j未能指定s中的一个子串,都是已检查的运行时错误。
Str_dup返回一个字符串,该字符串是s[i:j]的n个副本。传递负的n值,是一个已检查的运行时错误。Str_dup通常用于复制一个字符串,例如,Str_dup("Interface", 1, 0, 1)返回Interface的一个副本。请注意,使用位置1和0,即指定了Interface整个字符串。
Str_cat返回s1[i1:j1]和s2[i2:j2]两个子串连接构成的字符串,即,该字符串首先包含s1[i1:j1]中的所有字符,后接s2[i2:j2]中的所有字符。Str_catv与之类似,其参数为0或多个三元组,每个三元组指定了一个字符串和两个位置,函数返回所有这些子串连接构成的字符串。参数列表结束于NULL指针参数。例如,
Str_catv("Interface", -4, 0, " plant", 1, 0, NULL)
返回字符串face plant。
Str_reverse返回s[i:j]中字符以与其出现在s中的反序所构成的字符串。
Str_map返回s[i:j]中字符按照from和to映射得到的字符所构成的字符串。对s[i:j]中的每个字符来说,如果其出现在from中,则映射为to中的对应字符。不出现在from中的字符映射到本身。例如,
Str_map(s, 1, 0, "ABCDEFGHIJKLMNOPQRSTUVWXYZ",
"abcdefghijklmnopqrstuvwxyz")
会返回s的一个副本,其中的大写字母都被替换为小写。
如果from和to都是NULL,则使用最近一次调用Str_map时指定的映射。如果s是NULL,则忽略i和j,from和to只用于建立默认映射,Str_map将返回NULL。
以下情况是已检查的运行时错误:from和to中有且仅有一个为NULL,非NULL的from和to字符串长度不同,s、from和to都是NULL,第一次调用Str_map时from和to都是NULL。
Str接口中其余的函数,用于返回字符串中有关字符串或位置的信息,这些函数都不分配空间。
〈exported functions
174〉+≡
extern int Str_pos(const char *s, int i);
extern int Str_len(const char *s, int i, int j);
extern int Str_cmp(const char *s1, int i1, int j1,
const char *s2, int i2, int j2);
Str_pos返回对应于s[i:i]的正数位置。正数位置总是可以通过减1转换为索引,因此在需要索引时通常使用Str_pos。例如,如果s指向字符串Interface,
printf("%s\n", &s[Str_pos(s, -4)-1])
将输出face。
Str_len返回s[i:j]中字符的数目。
Str_cmp根据s1[i1:j1]与s2[i2:j2]的比较结果,对小于、等于、大于三种情形分别返回负值、0、正值。
以下函数搜索字符串,查找字符及其他字符串。在搜索成功时,这些函数返回反映搜索结果的正数位置,在搜索失败时,它们返回0。函数名包含_r时,搜索从其参数字符串的右侧开始,其他函数搜索时从左侧开始。
〈exported functions
174〉+≡
extern int Str_chr (const char *s, int i, int j, int c);
extern int Str_rchr (const char *s, int i, int j, int c);
extern int Str_upto (const char *s, int i, int j,
const char *set);
extern int Str_rupto(const char *s, int i, int j,
const char *set);
extern int Str_find (const char *s, int i, int j,
const char *str);
extern int Str_rfind(const char *s, int i, int j,
const char *str);
Str_chr和Str_rchr分别从s[i:j]的最左侧和最右侧开始搜索字符c,并返回s中该字符之前的位置,如果s[i:j]不包含c则返回0。
Str_upto和Str_rupto分别从s[i:j]的最左侧和最右侧开始搜索set中任意字符,并返回s中该字符之前的位置,如果s[i:j]不包含set中任意字符,那么将返回0。向这些函数传递的set为NULL,则造成已检查的运行时错误。
Str_find和Str_rfind分别从s[i:j]的最左侧和最右侧开始搜索字符串str,并返回s中该子串之前的位置,如果s[i:j]不包含str则返回0。向这些函数传递的str为NULL,则造成已检查的运行时错误。
以下函数
〈exported functions
174〉+≡
extern int Str_any(const char *s, int i,
const char *set);
extern int Str_many(const char *s, int i, int j,
const char *set);
extern int Str_rmany(const char *s, int i, int j,
const char *set);
extern int Str_match(const char *s, int i, int j,
const char *str);
extern int Str_rmatch(const char *s, int i, int j,
const char *str);
将遍历子串,它们返回匹配的子串之后或之前的正数位置。
如果字符s[i:i+1]出现在set中,Str_any返回s中该字符之后的正数位置,否则返回0。
Str_many从s[i:j]开头处查找由set中一个或多个字符构成的连续序列,并返回s中该序列之后的正数位置,如果s[i:j]并不从set中的某个字符开始,那么将返回0。Str_rmany从s[i:j]末端查找set中一个或多个字符构成的连续序列,并返回s中该序列之前的正数位置,如果s[i:j]并不结束于set中的某个字符,将返回0。传递给Str_any、Str_many或Str_rmany的set为NULL,是已检查的运行时错误。
Str_match从s[i:j]开头开始查找str,并返回s中该子串之后的正数位置,如果s[i:j]起始处不是str,则返回0。Str_rmatch从s[i:j]末尾来查找str,并返回s中该子串之前的正数位置,如果s[i:j]不结束于str,则返回0。向Str_match或Str_rmatch传递的str为NULL,是已检查的运行时错误。
Str_rchr、Str_rupto和Str_rfind从其参数字符串的右端开始搜索,但返回其搜索到的字符/字符串左侧的位置。例如,以下调用
Str_find ("The rain in Spain", 1, 0, "rain")
Str_rfind("The rain in Spain", 1, 0, "rain")
都返回5,这是因为rain在其第一个参数中只出现一次。以下调用
Str_find ("The rain in Spain", 1, 0, "in")
Str_rfind("The rain in Spain", 1, 0, "in")
分别返回7和16,因为in在第一个参数中出现了三次。
Str_many和Str_match在字符串中从左到右遍历,并返回其查找到的字符之后的位置。Str_rmany和Str_rmatch从右到左遍历,它们返回查找到的字符之前的位置。例如,
Str_sub(name, 1, Str_rmany(name, 1, 0, " \t"))
将返回name的一个副本,并去除尾部的空格和制表符(如果有的话)。函数basename给出对这种惯例的另一种典型用法。basename接受一个Unix的路径名,返回去除目录信息和特定后缀的文件名,如下例所示。
basename("/usr/jenny/main.c", 1, 0, ".c") main
basename("../src/main.c", 1, 0, "") main.c
basename("main.c", 1, 0, "c") main
basename("main.c", 1, 0, ".obj") main.c
basename("examples/wfmain.c", 1, 0, ".main.c") wf
basename使用Str_rchr来查找最右侧的斜线,使用Str_rmatch来定位后缀。
char *basename(char *path, int i, int j,
const char *suffix) {
i = Str_rchr(path, i, j, '/');
j = Str_rmatch(path, i + 1, 0, suffix);
return Str_dup(path, i + 1, j, 1);
}
Str_rchr的返回值赋值给i,如果能找到斜线,这是最右侧斜线之前的位置,否则为0。在这两种情况下,文件名都起始于位置i+1。Str_match会检查文件名,并返回后缀之前或文件名之后的位置。同样,在这两种情况下,j都设置为文件名之后的位置。str_dup返回path中i+1和j之间的子串。
以下函数
〈exported functions
174〉+≡
extern void Str_fmt(int code, va_list *app,
int put(int c, void *cl), void *cl,
unsigned char flags[], int width, int precision);
是一个转换函数,可以与Fmt接口中的格式化函数协同使用,用于格式化子串。它消耗三个参数:一个字符串指针和两个位置,它按照Fmt中%s指定的风格来格式化子串。字符串指针、app或flags是NULL,则造成已检查的运行时错误。
例如,如果Str_fmt通过下列调用关联到格式码S:
Fmt_register('S', Str_fmt)
那么
Fmt_print("%10S\n", "Interface", -4, 0)
将输出______face,这里_表示空格。
下面给出的例子程序可以输出其输入中的C语言关键字和标识符,该程序说明了Str_fmt的用法,以及检查字符串是否包含某些字符或子串的其他函数的用法。
〈ids.c
〉≡
#include <stdlib.h>
#include <stdio.h>
#include "fmt.h"
#include "str.h"
int main(int argc, char *argv[]) {
char line[512];
static char set[] = "0123456789_"
"abcdefghijklmnopqrstuvwxyz"
"ABCDEFGHIJKLMNOPQRSTUVWXYZ";
Fmt_register('S', Str_fmt);
while (fgets(line, sizeof line, stdin) != NULL) {
int i = 1, j;
while ((i = Str_upto(line, i, 0, &set[10])) > 0){
j = Str_many(line, i, 0, set);
Fmt_print("%S\n", line, i, j);
i = j;
}
}
return EXIT_SUCCESS;
}
内层的while循环扫描line[i:0]查找下一个标识符,i从1开始。Str_upto返回line [i:0]下一个下划线或字母在line中的位置,该位置被赋值给i。在下划线或字母之后,连续的数字、下划线和字母都属于同一标识符,而Str_many将返回该标识符之后的位置。因而,i和j标识了扫描到的下一个标识符,Fmt_print用Str_fmt输出该标识符,它关联到格式码S。将j赋值给i,使得while循环的下一次迭代查找下一个标识符。在line包含上面的main函数声明时,传递给Fmt_print的i和j如图15-2所示。
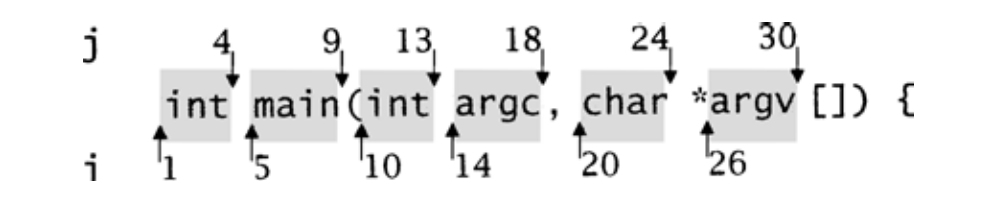
图15-2 各字符的位置
该程序中没有内存分配。在此类应用程序中使用位置通常可以避免内存分配。
〈str.c 〉≡ #include <string.h> #include <limits.h> #include "assert.h" #include "fmt.h" #include "str.h" #include "mem.h" 〈macros 179〉 〈functions 180〉
实现必须处理位置与索引之间的双向转换,因为函数使用索引来访问实际的字符。正数位置i右侧字符的索引是i - 1。负数位置i右侧字符的索引是i + len,len是字符串中字符的数目。下列宏
〈macros 179〉≡ #define idx(i, len ) ((i ) <= 0 ? (i ) + (len ) : (i ) - 1)
封装了以上的定义;给出长度为len的字符串中的位置i,idx(i, len)就是i右侧字符的索引。
Str接口中的函数将其位置转换为索引,然后使用索引访问字符串。convert宏封装了以下转换中的各个步骤:
〈macros 179〉+≡ #define convert(s, i, j ) do { int len; \ assert(s ); len = strlen(s ); \ i = idx(i , len); j = idx(j , len); \ if (i > j ) { int t = i ; i = j ; j = t; } \ assert(i >= 0 && j <= len); } while (0)
位置i和j被转换为从0到s的长度之间的索引值,如有必要会交换i和j,使得i的值不超过j。结尾处的断言确认了i和j是s中有效的索引位置。在转换后,j - i即为指定子串的长度。
Str_sub说明了convert的典型用法。
〈functions
180〉≡
char *Str_sub(const char *s, int i, int j) {
char *str, *p;
convert(s, i, j);
p = str = ALLOC(j - i + 1);
while (i < j)
*p++ = s[i++];
*p = '\0';
return str;
}
指定子串末端的位置被转换为子串之后下一个字符的索引值(可能是结尾0字符的索引值)。因而,j-i即为目标子串的长度,加上0字符在内,需要j-i+1个字节来存储该子串。
Str_sub和其他一些Str函数都可以使用标准C库中的字符串例程来编写,如strncpy,参见习题15.2。
Str_dup为s[i:j]的n个副本加上一个结尾0字符分配空间,然后将s[i:j]复制n次,当然前提是s[i:j]子串非空。
〈functions
180〉+≡
char *Str_dup(const char *s, int i, int j, int n) {
int k;
char *str, *p;
assert(n >= 0);
convert(s, i, j);
p = str = ALLOC(n*(j - i) + 1);
if (j - i > 0)
while (n-- > 0)
for (k = i; k < j; k++)
*p++ = s[k];
*p = '\0';
return str;
}
Str_reverse类似Str_sub,但它反向复制字符:
〈functions
180〉+≡
char *Str_reverse(const char *s, int i, int j) {
char *str, *p;
convert(s, i, j);
p = str = ALLOC(j - i + 1);
while (j > i)
*p++ = s[--j];
*p = '\0';
return str;
}
Str_cat可以调用Str_catv实现,但它使用得比较多,值得给出一个定制的实现:
〈functions
180〉+≡
char *Str_cat(const char *s1, int i1, int j1,
const char *s2, int i2, int j2) {
char *str, *p;
convert(s1, i1, j1);
convert(s2, i2, j2);
p = str = ALLOC(j1 - i1 + j2 - i2 + 1);
while (i1 < j1)
*p++ = s1[i1++];
while (i2 < j2)
*p++ = s2[i2++];
*p = '\0';
return str;
}
Str_catv稍复杂一点,因为它必须对可变数目的参数扫描两遍:
〈functions 180〉+≡ char *Str_catv(const char *s, ...) { char *str, *p; const char *save = s; int i, j, len = 0; va_list ap; va_start(ap, s); 〈len ← the length of the result 182〉 va_end(ap); p = str = ALLOC(len + 1); s = save; va_start(ap, s); 〈copy each s[i:j] to p, increment p 182〉 va_end(ap); *p = '\0'; return str; }
第一遍将各个参数子串的长度求和,以算得结果的长度。在为结果字符串分配空间之后,第二遍扫描将各个三元组给出的子串附加到结果字符串上。第一遍将位置转换为索引来计算每个子串的长度,所有子串长度的总和即为结果字符串的长度:
〈len ← the length of the result
182〉≡
while (s) {
i = va_arg(ap, int);
j = va_arg(ap, int);
convert(s, i, j);
len += j - i;
s = va_arg(ap, const char *);
}
第二遍的过程几乎相同:唯一的差别是,对len的赋值操作替换为复制子串的循环:
〈copy each s[i:j] to p, increment p 182〉≡ while (s) { i = va_arg(ap, int); j = va_arg(ap, int); convert(s, i, j); while (i < j) *p++ = s[i++]; s = va_arg(ap, const char *); }
Str_map建立一个数组map,按from和to指定的映射,字符c即映射到map[c]。因而,将s[i:j]中的字符作为map的索引,即可得到映射结果,而后将其复制到一个新字符串中:
〈map s[i:j] into a new string 182〉≡ char *str, *p; convert(s, i, j); p = str = ALLOC(j - i + 1); while (i < j) *p++ = map[(unsigned char)s[i++]]; *p = '\0';
上述代码中的强制转换,复制值大于127的字符被“符号扩展”为负的索引值。
建立map时,首先将map初始化,使得map[c]等于c,即每个字符都映射到本身。接下来,使用from和to来修改map,将from中的字符作为map的索引值,而将to中的对应字符作为映射值:
〈rebuild
map 182〉≡
unsigned c;
for (c = 0; c < sizeof map; c++)
map[c] = c;
while (*from && *to)
map[(unsigned char)*from++] = *to++;
assert(*from == 0 && *to == 0);
上述代码中的断言,实现了“from和to长度必须相等”的已检查的运行时错误。
Str_map在from和to都不是NULL时使用该代码块,在s不是NULL时使用<map s[i:j] into a new string 182>:
〈functions 182〉+≡ char *Str_map(const char *s, int i, int j, const char *from, const char *to) { static char map[256] = { 0 }; if (from && to) { 〈rebuild map 182〉 } else { assert(from == NULL && to == NULL && s); assert(map['a']); } if (s) { 〈map s[i:j] into a new string 182〉 return str; } else return NULL; }
最初,map的所有元素都是0。在to中没有办法指定一个0字符,因此断言map['a']非零,即实现了“第一次调用Str_map时from和to指针不能为NULL”的已检查的运行时错误。
索引i对应的字符左侧的正数位置是i + 1。Str_pos使用该性质,来返回对应于s中任意位置i的正数位置。它首先将i转换为索引,确认索引的有效性,而后将其转换回正数位置并返回。
〈functions
180〉+≡
int Str_pos(const char *s, int i) {
int len;
assert(s);
len = strlen(s);
i = idx(i, len);
assert(i >= 0 && i <= len);
return i + 1;
}
Str_len返回子串s[i:j]的长度,其做法是将i和j转换为索引,并返回两个索引之间字符的数目:
〈functions
180〉+≡
int Str_len(const char *s, int i, int j) {
convert(s, i, j);
return j - i;
}
Str_cmp的实现简明但乏味,因为它涉及某些簿记工作:
〈functions 180〉+≡ int Str_cmp(const char *s1, int i1, int j1, const char *s2, int i2, int j2) { 〈string compare 184〉 }
Str_cmp首先将i1和j1转换为s1中的索引,i2和j2转换为s2中的索引:
〈string compare
184〉≡
convert(s1, i1, j1);
convert(s2, i2, j2);
接下来,调整s1和s2使之分别指向相应子串的第一个字符。
〈string compare
184〉+≡
s1 += i1;
s2 += i2;
两个子串s1[i1:j1]和s2[i2:j2]中的较短者,将决定需要比较多少个字符,实际的比较由strncmp完成。
〈string compare
184〉+≡
if (j1 - i1 < j2 - i2) {
int cond = strncmp(s1, s2, j1 - i1);
return cond == 0 ? -1 : cond;
} else if (j1 - i1 > j2 - i2) {
int cond = strncmp(s1, s2, j2 - i2);
return cond == 0 ? +1 : cond;
} else
return strncmp(s1, s2, j1 - i1);
在s1[i1:j1]比s2[i2:j2]短且strncmp返回0时,s1[i1:j1]相当于s2[i2:j2]的前缀,因而小于s2[i2:j2]。第二个if语句处理相反的情况,else子句处理两个子串长度相等的情况。
C语言标准规定,strncmp(和memcmp)必须将s1和s2中的字符作为无符号字符处理,这样,在s1或s2中出现大于127的字符值时,函数可以给出良定义的结果。例如,strncmp("\344", "\127", 1)必须返回正值,但strncmp的某些实现不正确地比较了“普通”字符,普通字符可能是有符号的,有可能是无符号的。对于这些实现,strncmp("\344", "\127", 1)可能返回负值。memcmp的某些实现有同样的错误。
剩下的函数会从左到右(或从右到左)检查子串,查找字符或其他字符串。这些函数在搜索成功时返回正数位置,否则返回0。Str_chr很有代表性:
〈functions
180〉+≡
int Str_chr(const char *s, int i, int j, int c) {
convert(s, i, j);
for ( ; i < j; i++)
if (s[i] == c)
return i + 1;
return 0;
}
Str_rchr是类似的,但它从s[i:j]的右侧开始搜索:
〈functions
180〉+≡
int Str_rchr(const char *s, int i, int j, int c) {
convert(s, i, j);
while (j > i)
if (s[--j] == c)
return j + 1;
return 0;
}
这两个函数都返回s[i:j]中字符c出现处左侧的正数位置。
Str_upto和Str_rupto类似于Str_chr和Str_rchr,只是它们会在s[i:j]中查找某个集合中的任意字符:
〈functions
180〉+≡
int Str_upto(const char *s, int i, int j, const char *set) {
assert(set);
convert(s, i, j);
for ( ; i < j; i++)
if (strchr(set, s[i]))
return i + 1;
return 0;
}
int Str_rupto(const char *s, int i, int j, const char *set) {
assert(set);
convert(s, i, j);
while (j > i)
if (strchr(set, s[--j]))
return j + 1;
return 0;
}
Str_find在s[i:j]中搜索字符串。其实现将搜索长度为0或1的字符串作为特例处理。
〈functions
180〉+≡
int Str_find(const char *s, int i, int j, const char *str) {
int len;
convert(s, i, j);
assert(str);
len = strlen(str);
if (len == 0)
return i + 1;
else if (len == 1) {
for ( ; i < j; i++)
if (s[i] == *str)
return i + 1;
} else
for ( ; i + len <= j; i++)
if (〈s[i...] ≡ str[0..len-1] 186〉)
return i + 1;
return 0;
}
如果str没有字符,搜索总是成功。如果str只有一个字符,Str_find等效于Str_chr。在一般情况中,Str_find在s[i:j]中查找str,但要特别小心,不能接受超出子串末尾的匹配:
〈s[i...] ≡ str[0..len-1] 186〉≡ (strncmp(&s[i], str, len) == 0)
Str_rfind同样需要处理这三种情形,但必须反向比较字符串。
〈functions
180〉+≡
int Str_rfind(const char *s, int i, int j,
const char *str) {
int len;
convert(s, i, j);
assert(str);
len = strlen(str);
if (len == 0)
return j + 1;
else if (len == 1) {
while (j > i)
if (s[--j] == *str)
return j + 1;
} else
for ( ; j - len >= i; j--)
if (strncmp(&s[j-len], str, len) == 0)
return j - len + 1;
return 0;
}
Str_rfind不能接受超出子串起点的匹配。
Str_any和相关函数并不搜索字符或字符串,如果在所述子串的开头或结尾发现指定的模式,这些函数将跳过模式字符或字符串。如果s[i:i+1]是set中的一个字符,Str_any将返回Str_pos(s, i)+1:
〈functions
180〉+≡
int Str_any(const char *s, int i, const char *set) {
int len;
assert(s);
assert(set);
len = strlen(s);
i = idx(i, len);
assert(i >= 0 && i <= len);
if (i < len && strchr(set, s[i]))
return i + 2;
return 0;
}
如果测试成功,索引i + 1将转换为正数位置(再加上1),这是Str_any返回i + 2的原因。
Str_many跨过出现在s[i:j]开头、完全由set中一个或多个字符构成的子串:
〈functions
180〉+≡
int Str_many(const char *s, int i, int j, const char *set) {
assert(set);
convert(s, i, j);
if (i < j && strchr(set, s[i])) {
do
i++;
while (i < j && strchr(set, s[i]));
return i + 1;
}
return 0;
}
Str_rmany向后跳过出现在s[i:j]末尾、完全由set中一个或多个字符构成的子串:
〈functions
180〉+≡
int Str_rmany(const char *s, int i, int j, const char *set) {
assert(set);
convert(s, i, j);
if (j > i && strchr(set, s[j-1])) {
do
--j;
while (j >= i && strchr(set, s[j]));
return j + 2;
}
return 0;
}
在do-while循环结束时,j等于i - 1或是第一个不在set中的字符的索引。在前一种情况下,Set_rmany必须返回i + 1,在第二种情况下,它必须返回s[j]右 侧的位置。j + 2在两种情况下都是正确的返回值。
如果str出现在s[i:j]起始处,Str_match返回Str_pos(s, i)+strlen(str)。就像Str_find,搜索长度为0或1的字符串需要特殊处理:
〈functions
180〉+≡
int Str_match(const char *s, int i, int j,
const char *str) {
int len;
convert(s, i, j);
assert(str);
len = strlen(str);
if (len == 0)
return i + 1;
else if (len == 1) {
if (i < j && s[i] == *str)
return i + 2;
} else if (i + len <= j && 〈s[i...] ≡ str[0..len-1] 186〉)
return i + len + 1;
return 0;
}
处理一般情况时必须注意,使得匹配串不能超出s[i:j]的末尾。
类似的情形也出现在Str_rmatch中,其中必须避免超出s[i:j]起始处的匹配串,也需要将长度为0或1的搜索字符串作为特例处理。
〈functions
180〉+≡
int Str_rmatch(const char *s, int i, int j,
const char *str) {
int len;
convert(s, i, j);
assert(str);
len = strlen(str);
if (len == 0)
return j + 1;
else if (len == 1) {
if (j > i && s[j-1] == *str)
return j;
} else if (j - len >= i
&& strncmp(&s[j-len], str, len) == 0)
return j - len + 1;
return 0;
}
最后一个函数是Str_fmt,它属于Fmt接口中提到的转换函数。对转换函数的调用序列在14.1.2节描述。flags、width和precision参数规定了如何格式化字符串。
Str_fmt的重要特性是,对于传递到某个Fmt函数的参数列表的可变部分,Str_fmt会消耗其中三 个参数。这三个参数分别指定了字符串和其中的两个位置。这两个位置给出了子串长度,与flags、width和precision一起确定了如何输出子串。Str_fmt用Fmt_puts来解释这些值并输出该字符串:
〈functions
180〉+≡
void Str_fmt(int code, va_list *app,
int put(int c, void *cl), void *cl,
unsigned char flags[], int width, int precision) {
char *s;
int i, j;
assert(app && flags);
s = va_arg(*app, char *);
i = va_arg(*app, int);
j = va_arg(*app, int);
convert(s, i, j);
Fmt_puts(s + i, j - i, put, cl, flags,
width, precision);
}
[Plauger,1992]简要地批评了string.h中定义的函数,并说明了如何实现它们。[Roberts,1995]描述了一个简单的字符串接口,与Str类似,基于string.h实现。
Str接口的设计几乎是从Icon程序设计语言[Griswold and Griswold,1990]的字符串操作功能逐字照搬过来的。使用位置而不是索引,以及使用非正数位置指定相对于字符串末尾的位置,这些都始自于Icon。
Str的函数仿照了Icon中名称类似的字符串函数。Icon中的函数更为强大,因为它们使用了Icon的目标导向的求值机制(goal-directed evaluation mechanism)。例如,Icon的find函数可以返回一个字符串在另一个字符串中出现的所有 位置,而后一个字符串则是根据调用find的上下文来确定的。Icon还有一种字符串扫描功能也利用了目标导向的求值机制,这是一种强大的模式匹配功能。
Str_map可用于实现数量众多的字符串转换过程。例如,如果s是一个包含7个字符的字符串,
Str_map("abcdefg", 1, 0, "gfedcba", s)
将返回s反向后的串。[Griswold,1980]探讨了对映射机制的此类用法。
15.1 扩展ids.c,使之识别并忽略C语言注释、字符串常数和关键字。推广你的扩展版本,使之能够接受命令行参数,以指定需要忽略的额外的标识符。
15.2 Str的实现可以使用标准C库中的字符串和内存函数来复制字符串,如strncpy和memcpy。
例如,Str_sub可以如下实现。
char *Str_sub(const char *s, int i, int j) {
char *str;
convert(s, i, j);
str = strncpy(ALLOC(j - i + 1), s + i, j - i);
str[j - i] = '\0';
return str;
}
一些C编译器可以识别对string.h函数的调用,并生成内联代码,这可能比C语言中对应的循环机制快得多。高度优化的汇编语言实现通常也更快速。重新实现Str接口,尽可能使用string.h函数,在特定机器上使用特定C编译器来测量结果,然后按照字符串参数的长度,分别度量各个函数的改进情况。
15.3 设计并实现一个函数,来搜索一个子串,以查找通过正则表达式 指定的模式,就像是AWK支持的那样,如[Aho, Kernighan and Weinberger,1988]所述。该函数需要返回两个值:匹配串的起始位置及其长度。
15.4 Icon有很广泛的字符串扫描功能。其?运算符可以建立一个扫描环境,提供一个字符串及其中的一个位置。像find这样的字符串函数调用时可以只用一个参数,函数对字符串及当前扫描环境中的位置进行操作。研究[Griswold and Griswold,1990]中描述的Icon的字符串扫描功能,设计并实现一个提供类似功能的接口。
15.5 string.h定义了下述函数
char *strtok(char *s, const char *set);
该函数将s划分为若干标记,以set中的字符作为分隔符。通过重复地调用strtok,即可将字符串s划分为若干标记。只有第一个调用会传递s作为参数,strtok找到第一个不在set中的字符,这也是第一个标记的起始地址,然后strtok会查找下一个出现在set中的字符,并将其改写为0字符,并返回第一个标记的地址。后续对strtok的调用(形如strtok(NULL, set)),NULL参数使得strtok从上一次搜索完成的位置继续查找,其过程类似,最后将返回此次找到的标记的起始地址。每次调用的set可以是不同的。在搜索失败时,strtok返回NULL。扩展Str接口,增加一个函数提供类似的功能,但不能修改其参数的内容。你可以改进strtok的设计吗?
15.6 Str接口中的函数总是为其结果分配空间,在一些应用程序中这些分配操作可能是不必要的。假定接口中的函数可以接受一个可选的目标,仅当目标为NULL指针时才分配空间。例如,
char *Str_dup(char *dst, int size,
const char *s, int i, int j, int n);
如果dst不是NULL,该函数将导致结果存储在dst[0..size-1]中并返回dst,否则,它将为结果分配空间,与当前版本相同。基于这种方法设计一个接口。请注意,一定要规定size过小时函数的行为。将你的设计与Str接口比较。哪个更简单?哪个不容易出错?
15.7 这里是另一个避免在Str函数中分配内存的提议。假定以下函数
void Str_result(char *dst, int size);
将dst作为下一次调用Str函数时的结果字符串。如果结果字符串不是NULL,Str函数将其结果存储到dst[0..size-1]中,并将结果字符串指针设为NULL。如果结果字符串为NULL,它们将照常为结果分配空间。讨论这个提议的利弊。
[1] 作者实际上忘记了C对索引的天然约定,即所谓的半开区间:假定i、j为基于0的非负索引值,i<=j,s为字符串,s[i:j]指定了从索引i开始、在索引j之前结束的子串;与文中的位置约定相比,这种约定优雅简单,而且具有同样的表示能力。——译者注
[2] 除非字符串尾部的地址已知,否则这是不可能的。——译者注