图14-1 转换限定符的语法
标准C库函数printf、fprintf和vprintf可以格式化数据并输出,而sprintf和vsprintf可以将数据格式化到字符串中。这些函数调用时的参数包括一个格式串和一组参数列表,列表中的参数将被格式化。格式化的过程,由嵌入到格式串中的转换限定符(conversion specifier,形如%c)控制,第i个%c描述了格式串之后的参数列表中第i个参数如何格式化。格式串中其他字符逐字复制。例如,如果name是字符串Array,而count为8,
sprintf(buf, "The %s interface has %d functions\n",
name, count)
会将字符串"The Array interface has 8 functions\n"填充到buf中,其中\n表示换行符。转换限定符还可以包含宽度、精度和填充字符等说明信息。例如,如果在上述的格式串中使用%06d而不是%d,那么会将字符串"The Array interface has 000008 functions\n"填充到buf中。
这些函数毫无疑问很有用,但却至少有4个缺点。首先,转换限定符的集合是固定的,因而无法提供特定于客户程序的代码。其次,格式化的结果,只能输出或存储到字符串中,无法指定特定于客户程序的输出例程。再次,也是最危险的缺点是,sprintf和vsprintf可能试图在输出缓冲区中存储超出其容量的字符,同时又无法指定输出缓冲区的大小。最后,对于参数列表的可变部分传递的各个参数,没有对应的类型检查机制。Fmt接口改正了前三个缺点。
Fmt接口导出了11个函数、一个类型、一个变量和一个异常:
〈fmt.h 〉≡ #ifndef FMT_INCLUDED #define FMT_INCLUDED #include <stdarg.h> #include <stdio.h> #include "except.h" #define T Fmt_T typedef void (*T)(int code, va_list *app, int put(int c, void *cl), void *cl, unsigned char flags[256], int width, int precision); extern char *Fmt_flags; extern const Except_T Fmt_Overflow; 〈exported functions 155〉 #undef T #endif
从技术上讲,Fmt不是一个抽象数据类型,但它确实导出了一个类型Fmt_T,它定义了与每个格式化代码关联的格式转换函数的类型,下文将详细阐述。
两个主要的格式化函数是:
〈exported functions
155〉≡
extern void Fmt_fmt (int put(int c, void *cl), void *cl,
const char *fmt, ...);
extern void Fmt_vfmt(int put(int c, void *cl), void *cl,
const char *fmt, va_list ap);
Fmt_fmt按照第三个参数fmt给出的格式串来格式化其第四个和后续参数;并调用put(c, cl)来输出每个格式化完毕的字符c;c当做unsigned char处理,因此传递到put的c值总是正的。Fmt_vfmt按照fmt给出的格式串来格式化ap指向的各个参数,具体过程类似Fmt_fmt,如下所述。
参数cl可以指向客户程序提供的数据,它会直接传递给客户程序提供的put函数而不作解释。put函数返回一个整数,通常是其参数。Fmt函数并不使用该功能,但这种设计使得可以某些机器上将标准I/O函数fputc用作put函数(同时,需要作为cl传递FILE*)。例如,
Fmt_fmt((int (*)(int, void *))fputc, stdout,
"The %s interface has %d functions\n", name, count)
输出
The Array interface has 8 functions
到标准输出,此时name为Array而count为8。其中的转换是必要的,因为fputc的类型为int (*)(int, FILE*),而put的类型为int (*)(int, void*)。仅当FILE指针的表示与void指针相同时,这种用法才是正确的。
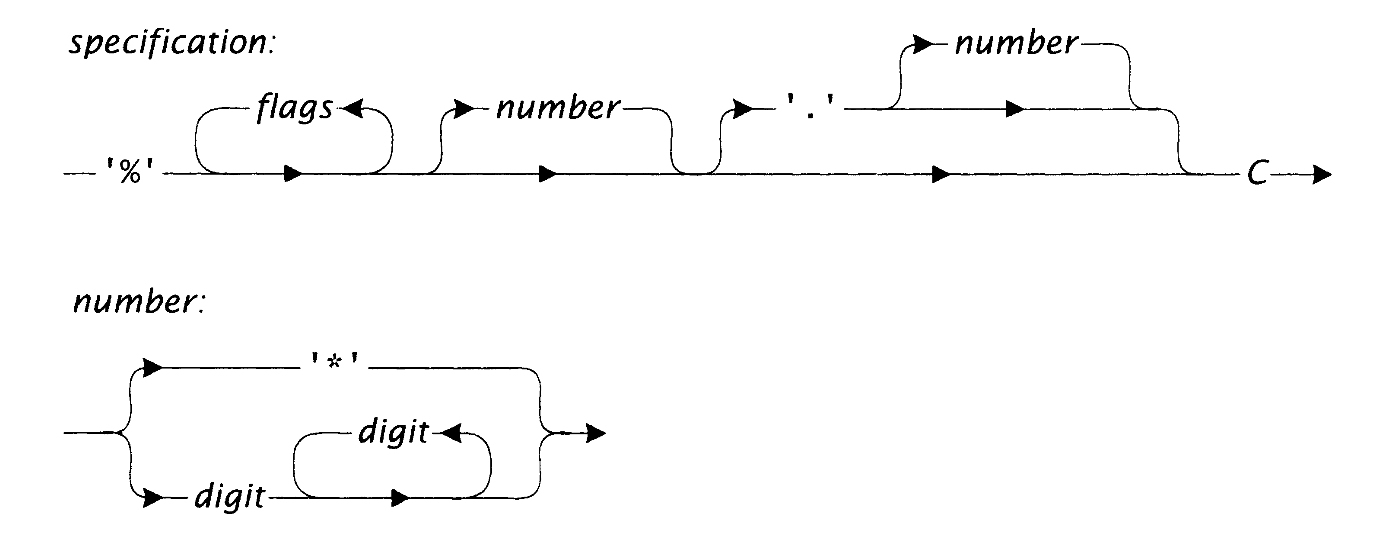
图14-1给出的语法图定义了转换限定符的语法。转换限定符中的字符定义了一条穿过语法图的路径,有效的限定符会从头到尾遍历一条路径。限定符以%开头,后接可选的标志字符,其解释取决于格式码,接下来是可选的字段宽度、周期和精度,最后以单字符的格式码结束,由图14-1中的C表示。有效的标志字符是那些出现在Fmt_flags指向的字符串中的字符,它们通常指定了对齐(justification)、填充(padding)和截断(truncation)信息。如果一个标志字符在一个限定符中出现多于255次,则是已检查的运行时错误。如果字段宽度或精度显示为星号,那么假定下一个参数为整数,且用作宽度或精度。因而,一个限定符可能消耗零或多个参数,这取决于星号的出现与否以及与格式码关联的具体转换函数。如果指定的宽度或精度值等于INT_MIN(最小的负整数),则是已检查的运行时错误。
图14-1 转换限定符的语法
标志、宽度和精度的准确的解释,取决于与转换限定符关联的转换函数。所调用的转换函数,是调用Fmt_fmt时已注册的那些函数。
默认的转换限定符及与之相关的转换函数,是标准I/O库中printf和相关函数功能的一个子集。Fmt_flags的初始值指向字符串"-+ 0",其中的字符是有效的标志字符。-使得被转换的字符串按给定的字段宽度向左对齐,否则,字符串将向右对齐。+使得符号转换的结果以-或+开始。空格使得符号转换的结果以空格开始(如果是正的)。0使得数字转换的结果在前部用0补齐,直至达到字段宽度为止,否则使用空格补齐。负数宽度解释为-标志加上对应的正数宽度值。负数精度解释为没有指定精度。
表14-1综述了默认的转换限定符。这些是标准C库中的定义的限定符的一个子集。
表14-1 默认的转换限定符

以下函数
〈exported functions
155〉+≡
extern void Fmt_print (const char *fmt, ...);
extern void Fmt_fprint(FILE *stream,
const char *fmt, ...);
extern int Fmt_sfmt (char *buf, int size,
const char *fmt, ...);
extern int Fmt_vsfmt(char *buf, int size,
const char *fmt, va_list ap);
类似于C库函数printf、fprintf、sprintf和vsprintf。
Fmt_fprint按照fmt给定的格式串来格式化第三个和后续参数,并将格式化输出写到指定的流中。Fmt_print将格式化输出写到标准输出。
Fmt_sfmt按照fmt给定的格式串来格式化第四个和后续参数,将格式化输出以0结尾字符串形式,存储到buf[0..size - 1]中。Fmt_vsfmt的语义类似,但其参数则取自于可变长度参数列表ap。这两个函数都会返回存储到buf中字符的数目,不计算结尾的0字符。如果Fmt_sfmt和Fmt_vsfmt输出的字符数多于size(包含结尾的0字符),则引发Fmt_Overflow异常。如果size不是正值,则造成已检查的运行时错误。
以下两个函数
〈exported functions
155〉+≡
extern char *Fmt_string (const char *fmt, ...);
extern char *Fmt_vstring(const char *fmt, va_list ap);
类似Fmt_sfmt和Fmt_vsfmt,但它们会分配足够大的字符串来容纳格式化输出结果,并返回这些字符串。客户程序负责释放返回的字符串。Fmt_string和Fmt_vstring可能引发Mem_Failed异常。
如果传递给上述任一格式化函数的参数put、buf或fmt为NULL,则造成已检查的运行时错误。
每个格式符C都关联到一个转换函数。这些关联可以通过调用下述函数来改变:
〈exported functions
155〉+≡
extern T Fmt_register(int code, T cvt);
Fmt_register将cvt设置为code指定的格式符对应的转换函数,并返回指向先前转换函数的指针。因而,客户程序可以临时替换转换函数,而后又恢复到原来的转换函数。code小于1或大于255,都是已检查的运行时错误。如果格式串使用的转换限定符没有相关联的转换函数,同样是已检查的运行时错误。
许多转换函数,都是%d和%s转换限定符对应的转换函数的变体。Fmt导出了两个实用函数,供对应于数值和字符串的内部转换函数使用。
〈exported functions
155〉+≡
extern void Fmt_putd(const char *str, int len,
int put(int c, void *cl), void *cl,
unsigned char flags[256], int width, int precision);
extern void Fmt_puts(const char *str, int len,
int put(int c, void *cl), void *cl,
unsigned char flags[256], int width, int precision);
Fmt_putd假定str[0..len-1]包含了一个有符号数的字符串表示,它将按照flags、width和precision指定的转换,如表14-1中的%d所述,来输出该字符串。类似地,Fmt_puts按照flags、width和precision指定的转换,如%s所述,来输出str[0..len - 1]。如果传递给Fmt_putd或Fmt_puts的str为NULL、len为负值、flags为NULL或put为NULL,则是已检查的运行时错误。
Fmt_putd和Fmt_puts本身不是转换函数,但可以被转换函数调用。在编写特定于客户程序的转换函数时,这两个函数特别有用,如下文说明。
类型Fmt_T定义了转换函数的签名,即其参数的类型和返回类型。转换函数调用时有七个参数。前两个是格式码和指向可变长度参数列表指针的指针,该参数列表用于访问被格式化的数据。第三个和第四个参数是客户程序的输出函数和相关数据。最后三个参数是标志、字段宽度和精度。标志通过一个256个元素的字符数组给出,第i个元素等于标志字符i在转换限定符中出现的次数。width和precision在没有显式给出时等于INT_MIN。
转换函数必须使用如下的表达式
va_arg(*app, type
)
来取得参数,并根据与该转换函数相关联的格式码进行格式化。type 是该参数的预期类型。该表达式取得参数的值,然后将*app加1使之指向下一个参数。如果转换函数使*app不正确地递增,则造成未检查的运行时错误。
Fmt用于限定符%s的私有转换函数,说明了如何编写转换函数,以及如何使用Fmt_puts。限定符%s类似printf的%s:其转换函数将输出对应的参数字符串中的字符,直至遇到0字符为止,或输出字符的数目已经达到了可选精度的限制。-标志或负数宽度指定了左对齐。转换函数使用va_arg从可变长度参数列表中取得参数并调用Fmt_puts:
〈conversion functions
159〉≡
static void cvt_s(int code, va_list *app,
int put(int c, void *cl), void *cl,
unsigned char flags[], int width, int precision) {
char *str = va_arg(*app, char *);
assert(str);
Fmt_puts(str, strlen(str), put, cl, flags,
width, precision);
}
Fmt_puts解释flags、width和precision,并据此输出字符串
〈functions 159〉≡ void Fmt_puts(const char *str, int len, int put(int c, void *cl), void *cl, unsigned char flags[], int width, int precision) { assert(str); assert(len >= 0); assert(flags); 〈normalize width and flags 159〉 if (precision >= 0 && precision < len) len = precision; if (!flags['-']) pad(width - len, ' '); 〈emit str[0..len-1] 159〉 if ( flags['-']) pad(width - len, ' '); } 〈emit str[0..len-1] 159〉≡ { int i; for (i = 0; i < len; i++) put((unsigned char)*str++, cl); }
到unsigned char的转换确保了传递给put的值总是较小的正整数,正如Fmt的规格所限定。
在忽略宽度或精度时,width和precision等于INT_MIN。该接口提供了特定于客户程序的转换函数所需的灵活性,使之能够对宽度和精度使用显式设置/省略值的所有组合,还可以使用重复的标志。但默认转换函数不需要这种一般性,它们将省略的宽度视为显式将宽度设置为0,负数宽度视为-标志连同对应的正数宽度,负数精度视为省略精度,重复出现的标志被视作只出现一次。如果有显式设置的精度,则忽略0标志,而且如上所示,至多会输出str中的precision个字符。
〈normalize width and flags 159〉≡ 〈normalize width 160〉 〈normalize flags 160〉 〈normalize width 160〉≡ if (width == INT_MIN) width = 0; if (width < 0) { flags['-'] = 1; width = -width; } 〈normalize flags 160〉≡ if (precision >= 0) flags['0'] = 0;
如对pad的调用所示,必须输出width-len个空格来正确地对齐输出:
〈macros 160〉≡ #define pad(n,c ) do { int nn = (n ); \ while (nn-- > 0) \ put((c ), cl); } while (0)
pad是一个宏,因为它需要访问put和cl。
下一节将描述其他默认转换函数的实现。
Fmt的实现包括接口中定义的各个函数,与默认转换限定符关联的转换函数,以及将转换限定符映射到转换函数的表。
〈fmt.c 〉≡ #include <stdarg.h> #include <stdlib.h> #include <stdio.h> #include <string.h> #include <limits.h> #include <float.h> #include <ctype.h> #include <math.h> #include "assert.h" #include "except.h" #include "fmt.h" #include "mem.h" #define T Fmt_T 〈types 162〉 〈macros 160〉 〈conversion functions 159〉 〈data 160〉 〈static functions 161〉 〈functions 159〉 〈data 160〉≡ const Except_T Fmt_Overflow = { "Formatting Overflow" };
Fmt_vfmt是实现的核心,因为所有其他接口函数都调用它来完成实际的格式化工作。Fmt_fmt是最简单的例子,它初始化一个va_list指针,指向其参数列表的可变部分,并调用Fmt_vfmt:
〈functions
159〉+≡
void Fmt_fmt(int put(int c, void *), void *cl,
const char *fmt, ...) {
va_list ap;
va_start(ap, fmt);
Fmt_vfmt(put, cl, fmt, ap);
va_end(ap);
}
Fmt_print和Fmt_fprint调用Fmt_vfmt时,将outc作为put函数,将对应于标准输出的流或给定的流作为相关的数据:
〈static functions 161〉≡ static int outc(int c, void *cl) { FILE *f = cl; return putc(c, f); } 〈functions 159〉+≡ void Fmt_print(const char *fmt, ...) { va_list ap; va_start(ap, fmt); Fmt_vfmt(outc, stdout, fmt, ap); va_end(ap); } void Fmt_fprint(FILE *stream, const char *fmt, ...) { va_list ap; va_start(ap, fmt); Fmt_vfmt(outc, stream, fmt, ap); va_end(ap); }
Fmt_sfmt调用Fmt_vsfmt:
〈functions
159〉+≡
int Fmt_sfmt(char *buf, int size, const char *fmt, ...) {
va_list ap;
int len;
va_start(ap, fmt);
len = Fmt_vsfmt(buf, size, fmt, ap);
va_end(ap);
return len;
}
Fmt_vsfmt调用Fmt_vfmt时,传递了一个put函数和一个指向结构的指针,该结构跟踪了需要格式化输出到buf的字符串和buf能够容纳的字符数:
〈types
162〉≡
struct buf {
char *buf;
char *bp;
int size;
};
buf和size实际上是复制了Fmt_vsfmt的名称类似的参数,而bp则指向buf中输出下一个被格式化字符的位置。Fmt_vsfmt会初始化该结构的一个局部变量实例,并将指向该实例的一个指针传递给Fmt_vfmt:
〈functions
159〉+≡
int Fmt_vsfmt(char *buf, int size, const char *fmt,
va_list ap) {
struct buf cl;
assert(buf);
assert(size > 0);
assert(fmt);
cl.buf = cl.bp = buf;
cl.size = size;
Fmt_vfmt(insert, &cl, fmt, ap);
insert(0, &cl);
return cl.bp - cl.buf - 1;
}
上述对Fmt_vfmt的调用,内部又调用了私有函数insert,参数是每一个需要输出的字符和指向Fmt_vsfmt的局部buf结构实例的指针。insert会检查是否有空间容纳需要输出的字符,并将该字符存储到bp字段指向的位置,并将bp字段加1:
〈static functions
161〉+≡
static int insert(int c, void *cl) {
struct buf *p = cl;
if (p->bp >= p->buf + p->size)
RAISE(Fmt_Overflow);
*p->bp++ = c;
return c;
}
Fmt_string和Fmt_vstring的工作原理同上,只是使用了不同的put函数。Fmt_string调用了Fmt_vstring:
〈functions
159〉+≡
char *Fmt_string(const char *fmt, ...) {
char *str;
va_list ap;
assert(fmt);
va_start(ap, fmt);
str = Fmt_vstring(fmt, ap);
va_end(ap);
return str;
}
Fmt_vstring将buf结构实例初始化为一个可容纳256个字符的字符串,并将执行该实例的指针传递给Fmt_vfmt:
〈functions
159〉+≡
char *Fmt_vstring(const char *fmt, va_list ap) {
struct buf cl;
assert(fmt);
cl.size = 256;
cl.buf = cl.bp = ALLOC(cl.size);
Fmt_vfmt(append, &cl, fmt, ap);
append(0, &cl);
return RESIZE(cl.buf, cl.bp - cl.buf);
}
append类似于Fmt_vsfmt的put,只是它会在必要时将buf的容量加倍,使之能够容纳格式化输出的字符。
〈static functions
161〉+≡
static int append(int c, void *cl) {
struct buf *p = cl;
if (p->bp >= p->buf + p->size) {
RESIZE(p->buf, 2*p->size);
p->bp = p->buf + p->size;
p->size *= 2;
}
*p->bp++ = c;
return c;
}
当Fmt_vstring完成时,buf字段指向的内存空间可能过长,这也是Fmt_vstring调用RESIZE释放过多空间的原因。
Fmt_vfmt是所有格式化函数的终点。它会解释格式串,并对每个格式限定符调用适当的转换函数。对格式串中的其他字符,它调用put函数:
〈functions 159〉+≡ void Fmt_vfmt(int put(int c, void *cl), void *cl, const char *fmt, va_list ap) { assert(put); assert(fmt); while (*fmt) if (*fmt != '%' || *++fmt == '%') put((unsigned char)*fmt++, cl); else 〈format an argument 164〉 }
<format an argument 164>代码块中的大部分工作,都是在逐一处理各个标志、字段宽度和精度设置,以及处理转换限定符没有对应的转换函数的可能性。在该代码块中(如下),width给出了字段宽度,而precision给出了精度。
〈format an argument 164〉≡ { unsigned char c, flags[256]; int width = INT_MIN, precision = INT_MIN; memset(flags, '\0', sizeof flags); 〈get optional flags 165〉 〈get optional field width 165〉 〈get optional precision 166〉 c = *fmt++; assert(cvt[c]); (*cvt[c])(c, &ap, put, cl, flags, width, precision); }
cvt是指向转换函数的指针的数组,它通过格式符索引。在上述的代码块中需要将c声明为unsigned char,这确保了将*fmt解释为0~255范围内的整数。
cvt初始化时,只设置了对应默认转换限定符的转换函数,假定字符使用ASCII编码:
〈data
160〉+≡
static T cvt[256] = {
/* 0- 7 */ 0, 0, 0, 0, 0, 0, 0, 0,
/* 8- 15 */ 0, 0, 0, 0, 0, 0, 0, 0,
/* 16- 23 */ 0, 0, 0, 0, 0, 0, 0, 0,
/* 24- 31 */ 0, 0, 0, 0, 0, 0, 0, 0,
/* 32- 39 */ 0, 0, 0, 0, 0, 0, 0, 0,
/* 40- 47 */ 0, 0, 0, 0, 0, 0, 0, 0,
/* 48- 55 */ 0, 0, 0, 0, 0, 0, 0, 0,
/* 56- 63 */ 0, 0, 0, 0, 0, 0, 0, 0,
/* 64- 71 */ 0, 0, 0, 0, 0, 0, 0, 0,
/* 72- 79 */ 0, 0, 0, 0, 0, 0, 0, 0,
/* 80- 87 */ 0, 0, 0, 0, 0, 0, 0, 0,
/* 88- 95 */ 0, 0, 0, 0, 0, 0, 0, 0,
/* 96-103 */ 0, 0, 0, cvt_c, cvt_d, cvt_f, cvt_f, cvt_f,
/* 104-111 */ 0, 0, 0, 0, 0, 0, 0, cvt_o,
/* 112-119 */ cvt_p, 0, 0, cvt_s, 0, cvt_u, 0, 0,
/* 120-127 */ cvt_x, 0, 0, 0, 0, 0, 0, 0
};
Fmt_register通过将cvt中适当的元素设置为相应的函数指针,来设置一个新的转换函数。它返回该元素的原值:
〈functions
159〉+≡
T Fmt_register(int code, T newcvt) {
T old;
assert(0 < code
&& code < (int)(sizeof (cvt)/sizeof (cvt[0])));
old = cvt[code];
cvt[code] = newcvt;
return old;
}
扫描转换限定符的代码块遵循图14-1给出的语法,扫描过程中会逐次对fmt加1。第一个代码块处理标志:
〈data 160〉+≡ char *Fmt_flags = "-+ 0"; 〈get optional flags 165〉≡ if (Fmt_flags) { unsigned char c = *fmt; for ( ; c && strchr(Fmt_flags, c); c = *++fmt) { assert(flags[c] < 255); flags[c]++; } }
接下来处理字段宽度:
〈get optional field width 165〉≡ if (*fmt == '*' || isdigit(*fmt)) { int n; 〈n ← next argument or scan digits 165〉 width = n; }
宽度或精度设置中都可能出现星号,而在这种情况下下一个整数参数提供了对应的值。
〈n ← next argument or scan digits
165〉≡
if (*fmt == '*') {
n = va_arg(ap, int);
assert(n != INT_MIN);
fmt++;
} else
for (n = 0; isdigit(*fmt); fmt++) {
int d = *fmt - '0';
assert(n <= (INT_MAX - d)/10);
n = 10*n + d;
}
如该代码所示,在参数指定了宽度或精度时,其值不能为INT_MIN,该值是保留的,作为默认值。在宽度或精度显式给出时,它不能大于INT_MAX,这等效于约束10 * n + d≤ INT_MAX,即10 * n + d不会上溢。我们必须在不导致上溢的情况下进行该测试,这也是在上述的断言中将约束重写的原因。
句点表明接下来是一个可选的精度设置:
〈get optional precision 166〉≡ if (*fmt == '.' && (*++fmt == '*' || isdigit(*fmt))) { int n; 〈n ← next argument or scan digits 165〉 precision = n; }
请注意,句点如果没有后接星号或数字,那么将处理以及解释为显式忽略的精度。
cvt_s是对应于%s的转换函数,在14.1.2节给出。cvt_d是对应于%d的转换函数,在格式化数字的转换函数中具有代表性。它会获取整数参数,将其转换为无符号整数,并在局部缓冲区中生成适当的字符串(转换从最高有效位开始)。它接下来调用Fmt_putd输出字符串。
〈conversion functions 159〉+≡ static void cvt_d(int code, va_list *app, int put(int c, void *cl), void *cl, unsigned char flags[], int width, int precision) { int val = va_arg(*app, int); unsigned m; 〈declare buf and p, initialize p 166〉 if (val == INT_MIN) m = INT_MAX + 1U; else if (val < 0) m = -val; else m = val; do *--p = m%10 + '0'; while ((m /= 10) > 0); if (val < 0) *--p = '-'; Fmt_putd(p, (buf + sizeof buf) - p, put, cl, flags, width, precision); } 〈declare buf and p, initialize p 166〉≡ char buf[43]; char *p = buf + sizeof buf;
cvt_d使用无符号算术的原因,与Atom_int相同,请参见3.2节,其中还解释了为何buf有43个字符。
〈functions 159〉+≡ void Fmt_putd(const char *str, int len, int put(int c, void *cl), void *cl, unsigned char flags[], int width, int precision) { int sign; assert(str); assert(len >= 0); assert(flags); 〈normalize width and flags 159〉 〈compute the sign 167〉 { 〈emit str justified in width 167〉 } }
Fmt_putd必须按照flags、width和precision的规定输出str中的字符串。如果精度已经给出,那么它指定了必须输出的最小位数。必须输出精度指定的那么多位数,这可能需要在前部补0。Fmt_putd首先确定是否需要输出符号或在前部添加空格,然后将sign设置给该字符:
〈compute the sign
167〉≡
if (len > 0 && (*str == '-' || *str == '+')) {
sign = *str++;
len--;
} else if (flags['+'])
sign = '+';
else if (flags[' '])
sign = ' ';
else
sign = 0;
<compute the sign 167>代码块中if语句的次序,实现了+标志优先于空格标志的规则。转换结果的长度n,取决于精度、被转换的值和符号:
〈emit str justified in width 167〉≡ int n; if (precision < 0) precision = 1; if (len < precision) n = precision; else if (precision == 0 && len == 1 && str[0] == '0') n = 0; else n = len; if (sign) n++;
n被赋值为需要输出的字符数,该代码还处理了以精度0对值0进行转换的特例,在这种情况下转换结果没有输出字符。
如果输出是左对齐的,那么Fmt_putd现在可以输出符号,如果输出是右对齐的,需要前部补0,那么现在可以输出符号和填充字符,而如果输出是右对齐,需要在前部添加空格,那么可以输出填充字符和符号。
〈emit str justified in width 167〉+≡ if (flags['-']) { 〈emit the sign 168〉 } else if (flags['0']) { 〈emit the sign 168〉 pad(width - n, '0'); } else { pad(width - n, ' '); 〈emit the sign 168〉 } 〈emit the sign 168〉≡ if (sign) put(sign, cl);
Fmt_putd最后可以输出转换结果,这可能包括前部添加的0(为满足精度要求),以及填充字符(如果输出是左对齐的):
〈emit str justified in width 167〉+≡ pad(precision - len, '0'); 〈emit str[0..len-1] 159〉 if (flags['-']) pad(width - n, ' ');
cvt_u比cvt_d简单,但它可以使用Fmt_putd输出转换结果的所有机制。它将输出下一个无符号整数的十进制表示:
〈conversion functions 159〉+≡ static void cvt_u(int code, va_list *app, int put(int c, void *cl), void *cl, unsigned char flags[], int width, int precision) { unsigned m = va_arg(*app, unsigned); 〈declare buf and p, initialize p 166〉 do *--p = m%10 + '0'; while ((m /= 10) > 0); Fmt_putd(p, (buf + sizeof buf) - p, put, cl, flags, width, precision); }
八进制和十六进制转换类似于无符号十进制转换,但输出的基不同,这又简化了转换的过程。
〈conversion functions 159〉+≡ static void cvt_o(int code, va_list *app, int put(int c, void *cl), void *cl, unsigned char flags[], int width, int precision) { unsigned m = va_arg(*app, unsigned); 〈declare buf and p, initialize p 166〉 do *--p = (m&0x7) + '0'; while ((m >>= 3) != 0); Fmt_putd(p, (buf + sizeof buf) - p, put, cl, flags, width, precision); } static void cvt_x(int code, va_list *app, int put(int c, void *cl), void *cl, unsigned char flags[], int width, int precision) { unsigned m = va_arg(*app, unsigned); 〈declare buf and p, initialize p 166〉 〈emit m in hexadecimal 169〉 } 〈emit m in hexadecimal 169〉≡ do *--p = "0123456789abcdef"[m&0xf]; while ((m >>= 4) != 0); Fmt_putd(p, (buf + sizeof buf) - p, put, cl, flags, width, precision);
cvt_p将指针作为十六进制数输出。精度和-以外的所有标志都忽略。参数被解释为指针,它首先被转换为unsigned long,因为unsigned的位宽可能不足以容纳指针 [1] 。
〈conversion functions 159〉+≡ static void cvt_p(int code, va_list *app, int put(int c, void *cl), void *cl, unsigned char flags[], int width, int precision) { unsigned long m = (unsigned long)va_arg(*app, void*); 〈declare buf and p, initialize p 166〉 precision = INT_MIN; 〈emit m in hexadecimal 169〉 }
cvt_c是与%c相关的转换函数,它格式化输出一个字符,左对齐或右对齐width个字符。它忽略精度和其他标志。
〈conversion functions 159〉+≡ static void cvt_c(int code, va_list *app, int put(int c, void *cl), void *cl, unsigned char flags[], int width, int precision) { 〈normalize width 160〉 if (!flags['-']) pad(width - 1, ' '); put((unsigned char)va_arg(*app, int), cl); if ( flags['-']) pad(width - 1, ' '); }
cvt_c获取的参数是一个整数而不是字符,因为通过参数列表的可变部分传递的字符参数,会经由默认的参数类型“提升”而转换为整数进行传递。cvt_c将由此得到的整数转换unsigned char,这样有符号、无符号和普通的字符都能够以同样的方式输出。
将浮点值精确地转换为十进制表示的过程,很难以与机器无关的方式完成。与机器相关的算法更快速且准确,因此与转换限定符e、f和g关联的转换函数使用了下述代码块:
〈format a double argument into buf 170〉≡ { static char fmt[] = "%.dd?"; assert(precision <= 99); fmt[4] = code; fmt[3] = precision%10 + '0'; fmt[2] = (precision/10)%10 + '0'; sprintf(buf, fmt, va_arg(*app, double)); }
将val的绝对值转换到buf中,接下来输出buf。
浮点转换限定符之间的差别在于,它们格式化浮点值各部分的方式不同。限定符%.99f的输出最长,可能需要DBL_MAX_10_EXP+1+1+99+1个字符。DBL_MAX_10_EXP和DBL_MAX定义在标准头文件float.h中。DBL_MAX是可以表示为double的值中最大的值,而DBL_MAX_10_EXP是log10 DBL_MAX,即,它是可以通过double表示的最大的十进制指数值。对应IEEE 754格式下的64位double值,DBL_MAX是1.797693*10308 ,而DBL_MAX_10_EXP是308。对fmt[2]和fmt[3]的赋值假定使用了ASCII码。
因而,如果用转换限定符%.99f转换DBL_MAX,结果的数位情况是:小数点之前可能有DBL_MAX_10_EXP+1个数位、小数点、小数点之后可能有99个数位、结束的0字符。将精度限制为99,可以限制用于容纳转换结果的缓冲区的大小,使得缓冲区的最大长度在编译时已知。其他转换限定符%e和%g的转换结果,比%f的结果字符数要少。cvt_f处理所有三种格式码:
〈conversion functions 159〉+≡ static void cvt_f(int code, va_list *app, int put(int c, void *cl), void *cl, unsigned char flags[], int width, int precision) { char buf[DBL_MAX_10_EXP+1+1+99+1]; if (precision < 0) precision = 6; if (code == 'g' && precision == 0) precision = 1; 〈format a double argument into buf 170〉 Fmt_putd(buf, strlen(buf), put, cl, flags, width, precision); }
[Plauger,1992]描述了C库中printf一族输出函数的实现,包括字符串与浮点值之间双向转换的底层代码。他的代码还说明了如何实现其他printf风格的格式化标志和格式码。
[Hennessy and Patterson,1994]一书的4.8节描述了IEEE 754浮点标准,以及浮点加法和乘法的实现。[Goldberg,1991]综述了程序员最关心的浮点运算性质。
浮点转换已经实现过多次,但转换得不精确或速度太慢,很容易使得这些转换变为拙劣的工作。对这些转换正确性的判断测试是:如果给定浮点值x,输出转换由x生成一个字符串,输入转换从该字符串重新创建一个浮点值y,那么要求x和y“按位”相等(即x和y的二进制表示是完全相同的)。[Clinger,1990]描述了如何精确地进行输入转换,该论文还阐明,对某些x,这种转换需要任意精度算术的支持。[Steele and White,1990]描述了如何进行精确的输出转换。
14.1 Fmt_vstring使用RESIZE来释放它返回的字符串中不使用的部分。设计一种方法,仅在释放空间可以带来回报时进行释放操作,即被释放的空间值得上释放操作的代价。
14.2 使用[Steele and White,1990]中描述的算法实现e、f和g转换。
14.3 编写一个转换函数,从下一个整数参数获取转换限定符,并将该函数关联到@。例如,
Fmt_string("The offending value is %@\n", x.format, x.value);
将根据x.format中的格式码来格式化x.value。
14.4 编写一个转换函数,将一个Bit_T中的元素以整数序列的形式输出,其中连续的1输出为范围表示,例如,1 32-45 68 70-71。
[1] 位宽是体系结构/编译器高度相关的,目前的主流编译器gcc/icc/msvc中,32位环境下,sizeof(int)==sizeof (long)==sizeof(void*)==4,64位环境下,sizeof(int)==sizeof(long)==4,sizeof(void*)==sizeof (long long)==8。——译者注