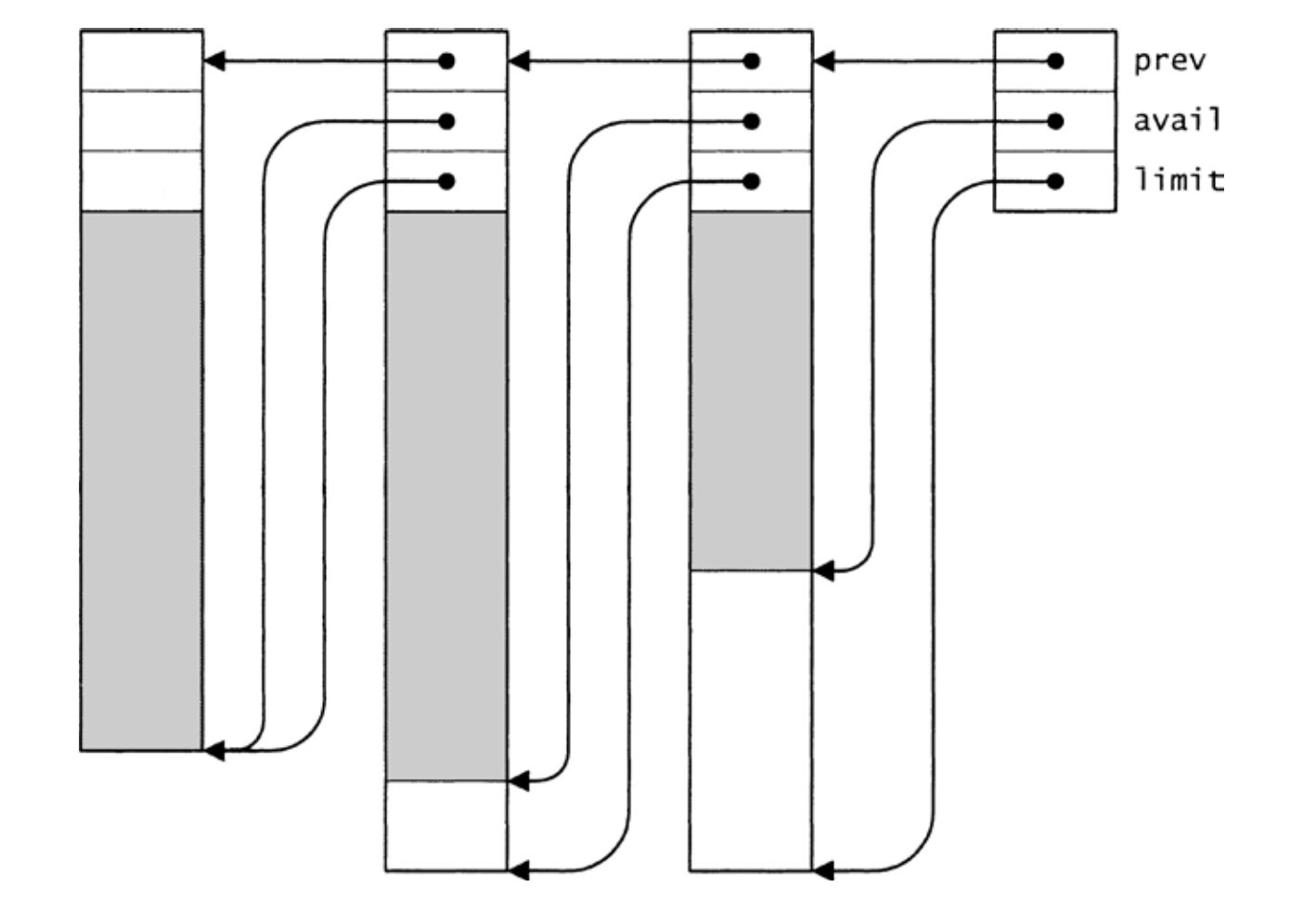
图6-1 包含三个大内存块的内存池
malloc和free的大多数实现,都会使用基于分配对象大小的内存管理算法。前一章中使用的最先适配算法就是一个例子。在一些应用程序中,内存释放操作是成组同时发生的。图形用户界面就是一个例子。用于滚动条、按钮等控件的内存空间,在一个窗口创建时分配,在该窗口销毁时释放。编译器是另一个例子。例如,lcc在编译一个函数时分配内存,在完成编译该函数时立即释放所有这些内存。
对于此类应用程序来说,基于对象生命周期的内存管理算法通常更好。基于栈的分配是此类分配算法的一个例子,但仅当对象生命周期有嵌套关系时才适用,通常情况下并非如此。
本章将描述一种内存管理接口及其实现,接口的实现使用了基于内存池(arena)的算法,其分配的内存来自一个内存池,使用完毕后立即释放整个内存池。调用malloc,则必须有对应的free调用。如前一章所述,很容易忘记调用free,或者,(更糟的是)释放一个已经被释放的对象或不应该被释放的对象。
利用基于内存池的分配器,不必像malloc/free那样,对每次调用malloc返回的指针调用free,只需要一个调用,即可释放上一次释放操作以来内存池中分配的所有内存。这使得分配和释放都更为高效,内存泄漏也没有了。但该方案最重要的好处是,它简化了代码。所谓的合用算法(applicative algorithm),一般只分配新数据结构,而不修改现存的数据结构。基于内存池的分配器促使采用简单的合用算法,以代替那些可能更省空间、但也更复杂的算法,因为后者必须记录何时调用free。
基于内存池的方案有两个缺点:它可能使用更多的内存,而且可能造成悬挂指针。如果一个对象通过错误的内存池分配,而在程序用完该对象之前相应的内存池已经释放,程序将引用未分配的内存或已经被其他内存池(可能是毫无关系的内存池)重用的内存。还有一种可能,即内存池中分配的对象的释放时间迟于预期,这会造成内存泄漏。但实际上,内存池的管理是如此容易,以至于这些问题很少发生。
Arena接口规定了两个异常,以及管理内存池并从内存池中分配内存的函数:
〈arena.h 〉≡ #ifndef ARENA_INCLUDED #define ARENA_INCLUDED #include "except.h" #define T Arena_T typedef struct T *T; extern const Except_T Arena_NewFailed; extern const Except_T Arena_Failed; 〈exported functions 66〉 #undef T #endif
内存池通过下列函数创建和销毁:
〈exported functions
66〉≡
extern T Arena_new (void);
extern void Arena_dispose(T *ap);
Arena_new创建一个新的内存池并返回指向新建内存池的一个不透明指针。该指针将传递给其他需要指定内存池参数的函数。如果Arena_new无法分配内存池,将引发Arena_NewFailed异常。Arena_dispose释放与*ap内存池关联的内存,释放内存池本身,并将*ap清零。传递给Arena_dispose的ap或*ap为NULL指针,是一个已检查的运行时错误。
内存分配函数是Arena_alloc和Arena_calloc,它们比较类似于Mem接口中名称相似的函数,只是从内存池分配内存而已。
〈exported functions
66〉+≡
extern void *Arena_alloc (T arena, long nbytes,
const char *file, int line);
extern void *Arena_calloc(T arena, long count,
long nbytes, const char *file, int line);
extern void Arena_free (T arena);
Arena_alloc在内存池中分配一个至少nbytes长的内存块,并返回指向第一个字节的指针。该内存块对齐到地址边界,能够适合于具有最严格对齐要求的数据。该块的内容是未初始化的。Arena_calloc在内存池中分配一个足够大的内存块,可以容纳count个元素的数组,每个数组元素的大小为nbytes字节,并返回指向第一个字节的指针。该内存块的对齐与Arena_alloc类似,其内容初始化为0。count或nbytes不是正数,是已检查的运行时错误。
Arena_alloc和Arena_calloc的最后二个参数是函数被调用处的文件名和行号。如果Arena_alloc或Arena_calloc无法分配所要的内存,则引发Arena_Failed异常,并将file和line参数传递给Except_raise,这样,抛出的异常就给出了调用相应函数的位置。如果file是NULL指针,这两个函数将提供其实现内部引发Arena_Failed的源代码的位置。
Arena_free释放内存池中所有的内存,相当于释放内存池中自创建或上一次调用Arena_free以来已分配的所有内存块。
向该接口中任何例程传递的T值为NULL,都是已检查的运行时错误。该接口中的例程可以与Mem接口中的例程和其他基于malloc和free的分配器协同使用。
〈arena.c 〉≡ #include <stdlib.h> #include <string.h> #include "assert.h" #include "except.h" #include "arena.h" #define T Arena_T const Except_T Arena_NewFailed = { "Arena Creation Failed" }; const Except_T Arena_Failed = { "Arena Allocation Failed" }; 〈macros 71〉 〈types 67〉 〈data 70〉 〈functions 68〉
一个内存池描述了一大块内存:
〈types
67〉≡
struct T {
T prev;
char *avail;
char *limit;
};
prev字段指向大内存块的起始,此处保存了一个Arena_T结构实例(具体在下文讲述),limit字段指向大内存块的结束处 [1] 。avail字段指向大内存块中第一个空闲位置,从avail开始、在limit之前的空间可用于分配。
为分配N字节的内存空间,在N不大于limit-avail时,将avail加N,返回avail的原值即可。如果N大于limit-avail,则需要调用malloc分配一个新的大内存块,*arena的当前值被“下推”(存储到新的大内存块的起始处),并初始化arena的各个字段使之描述新的大内存块,然后分配操作继续进行。
因而,位于各个大内存块头部的Arena_T结构实例形成了一个链表,链表指针是其中的prev字段。图6-1展示了分配三个大内存块之后内存池的状态。阴影部分表示已经分配的空间,各个大内存块可能大小不同,而且其结束处可能是未分配的空间(如果分配操作未能刚好用尽该块)。
图6-1 包含三个大内存块的内存池
Arena_new分配并返回一个Arena_T结构实例,其各个字段均设置为NULL指针,这表示一个空的内存池:
〈functions
68〉≡
T Arena_new(void) {
T arena = malloc(sizeof (*arena));
if (arena == NULL)
RAISE(Arena_NewFailed);
arena->prev = NULL;
arena->limit = arena->avail = NULL;
return arena;
}
Arena_dispose调用Arena_free释放内存池中的各个大内存块,接下来它释放Arena_T结构本身并将指向内存池的指针清零:
〈functions
68〉+≡
void Arena_dispose(T *ap) {
assert(ap && *ap);
Arena_free(*ap);
free(*ap);
*ap = NULL;
}
内存池使用malloc和free而不是其他分配器(例如Mem_alloc和Mem_free),这使得它独立于其他分配器。
大多数分配都是平凡的:将请求分配的内存长度向上舍入到适当的对齐边界,将avail指针加上舍入后的长度,并返回avail的原值。
〈functions 68〉+≡ void *Arena_alloc(T arena, long nbytes, const char *file, int line) { assert(arena); assert(nbytes > 0); 〈round nbytes up to an alignment boundary 69〉 while (nbytes > arena->limit - arena->avail) { 〈get a new chunk 69〉 } arena->avail += nbytes; return arena->avail - nbytes; }
像Mem接口的稽核实现那样,下述联合的大小
〈types
67〉+≡
union align {
int i;
long l;
long *lp;
void *p;
void (*fp)(void);
float f;
double d;
long double ld;
};
给出了宿主机上最低的对齐要求。其字段是那些最可能具有最严格对齐要求的类型,该联合用于对nbytes向上舍入:
〈round nbytes up to an alignment boundary 69〉≡ nbytes = ((nbytes + sizeof (union align) - 1)/ (sizeof (union align)))*(sizeof (union align));
对大多数调用来说,nbytes小于arena->limit-arena->avail,即,内存池中的大内存块至少有nbytes长的空闲空间,如此上述Arena_alloc中的while循环体不会执行。如果当前的大内存块无法满足分配请求,则必须分配一个新的大内存块。这会浪费当前大内存块末端的空闲空间,图6-1链表中的第二个大内存块就说明了这一点。
在分配一个新的大内存块之后,*arena的当前值保存到该块的起始处,并初始化arena的各个字段使之指向新块,分配操作将继续进行:
〈get a new chunk 69〉≡ T ptr; char *limit; 〈ptr ← a new chunk 70〉 *ptr = *arena; arena->avail = (char *)((union header *)ptr + 1); arena->limit = limit; arena->prev = ptr; 〈types 67〉+≡ union header { struct T b; union align a; };
代码中的结构赋值操作*ptr=*arena,将*arena“下推”,保存在新的大内存块的起始处。header联合确保了arena->avail指向一个适当对齐的地址,这使得在新的大内存块中的第一次分配不会出错。
如下所示,Arena_free将释放的大内存块维护在一个发源于freechunks的空闲链表上,以减少调用malloc的次数。该链表将大内存块头部的Arena_T结构实例的prev字段用作链表指针,这些结构实例的limit字段只是指向其所处大内存块的结束处。nfree是链表中大内存块的数目。Arena_alloc会从该链表获取空闲的大内存块或调用malloc来分配,而且在上述的<get a new chunk 69>代码块中设置了Arena_alloc的局部变量limit,供后续使用:
〈data 70〉+≡ static T freechunks; static int nfree; 〈ptr ← a new chunk 70〉≡ if ((ptr = freechunks) != NULL) { freechunks = freechunks->prev; nfree--; limit = ptr->limit; } else { long m = sizeof (union header) + nbytes + 10*1024; ptr = malloc(m); if (ptr == NULL) 〈raise Arena_Failed 70〉 limit = (char *)ptr + m; }
如果必须分配一个新的大内存块,则会分配一个足够大的内存块,以容纳Arena_T结构实例、nbytes字节要分配的空间以及10KB剩余的可用空间。如果malloc返回NULL,分配操作失败,Arena_alloc将引发Arena_Failed异常:
〈raise
Arena_Failed 70〉≡
{
if (file == NULL)
RAISE(Arena_Failed);
else
Except_raise(&Arena_Failed, file, line);
}
在内存池的各个字段指向新的大内存块后,Arena_alloc中的while循环将再次尝试进行分配。这一次仍然可能失败:如果新的大内存块来自freechunks,可能也会比较小以至于无法满足请求,这就是需要用while循环而不是if语句的原因。
Arena_calloc只是调用Arena_alloc:
〈functions
68〉+≡
void *Arena_calloc(T arena, long count, long nbytes,
const char *file, int line) {
void *ptr;
assert(count > 0);
ptr = Arena_alloc(arena, count*nbytes, file, line);
memset(ptr, '\0', count*nbytes);
return ptr;
}
释放内存池时,需要将其中的大内存块添加到空闲大内存块的链表,因为此操作会遍历内存池中的大内存块链表,因而*arena会恢复到初始状态。
〈functions 68〉+≡ void Arena_free(T arena) { assert(arena); while (arena->prev) { struct T tmp = *arena->prev; 〈free the chunk described by arena 71〉 *arena = tmp; } assert(arena->limit == NULL); assert(arena->avail == NULL); }
到tmp的结构赋值将arena->prev指向的Arena_T实例的所有字段值复制到tmp。因而,这个赋值操作以及赋值*arena=tmp,在由大内存块链表形成的Arena_T结构的栈中,弹出了栈顶的Arena_T结构。在遍历整个链表后,arena的所有字段值都应该是NULL。
freechunks会累积来自所有内存池的空闲大内存块,该链表可能变得很大。链表的长度变大不是问题,但其中包含的空闲内存太多就可能引起问题。例如对于其他分配器来说,freechunks链表上的大内存块就像是已经分配的内存,因而可能造成对malloc的调用失败。为避免占用太多内存,Arena_free在freechunks链表上仅仅保留
〈macros
71〉≡
#define THRESHOLD 10
THRESHOLD个空闲大内存块。在nfree值到达THRESHOLD后,后续到达的大内存块将通过调用free释放:
〈free the chunk described by
arena 71〉≡
if (nfree < THRESHOLD) {
arena->prev->prev = freechunks;
freechunks = arena->prev;
nfree++;
freechunks->limit = arena->limit;
} else
free(arena->prev);
在图6-2中,Arena_free即将释放左侧的大内存块。在nfree小于THRESHOLD时,该块将添加到freechunks链表。释放后的大内存块显示在右侧,虚线描绘了上述代码中的三个赋值操作对相关指针的影响。
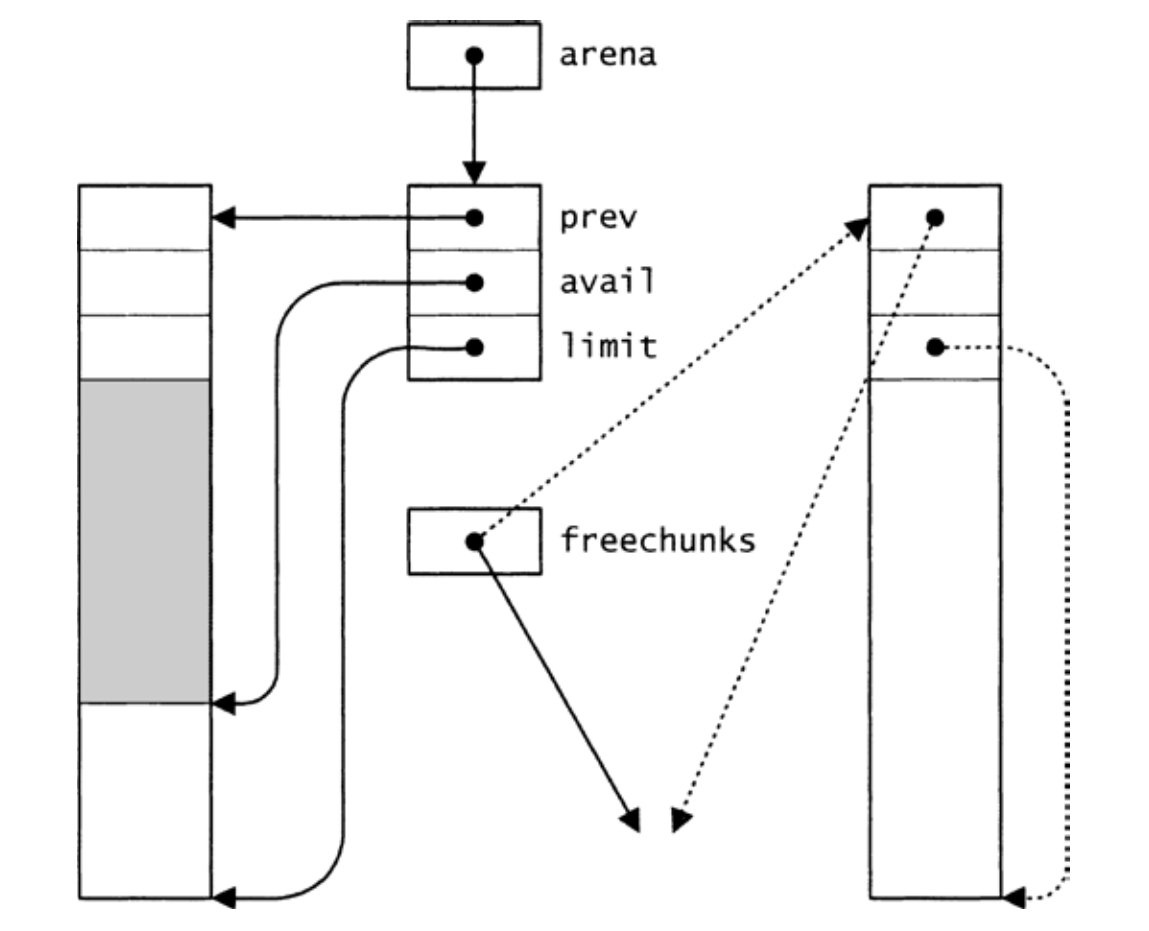
图6-2 当nfree小于THRESHOLD时,释放内存块
基于内存池的分配器(也称为pool allocators)在历史上已经描述过若干次。[Hanson,1990]一文中的内存池分配器最初是为供lcc [Fraser and Hanson,1995]使用而开发的。lcc的分配器比Arena稍微简单些:其内存池是静态分配的,其反分配器不会调用free。在其最初版本中,分配是通过宏直接操作内存池结构完成的,只在需要新的大内存块时才调用函数。
[Barrett and Zorn,1993]一文描述了如何自动选择适当的内存池。他们的实验建议,通向某个分配操作位置的执行路径,很好地预言了在该位置分配的内存块的生命周期。该信息包括调用链和分配位置的地址,可使用该信息来从几种特定于应用程序的内存池中选择。
Vmalloc [Vo,1996]是一个更为通用的分配器,可用于实现Mem和Arena接口。Vmalloc允许客户程序将内存组织为区,并提供函数分别管理每个区中的内存。Vmalloc库包括了malloc接口的一个实现,能够像Mem的稽核实现那样提供类似内存检查,这些检查可以通过设置环境变量来控制。
基于内存池的分配将许多显式释放操作合并为一个。垃圾收集器 (garbage collector)更进一步:它们避免了所有的显式释放操作。在具备垃圾收集器的语言中,程序员几乎可以忽略内存分配,内存分配bug(几乎)不可能发生。这种特性是如此之优越,以至于无论怎么讲都不过分。
有了垃圾收集器,内存空间将根据需要自动地回收(通常是在内存分配请求无法满足时)。垃圾收集器会找到所有被程序变量引用的内存块,以及这些块中的字段引用的所有内存块,以此类推。这些是可访问的内存块,其他的内存块是不可访问的,因而可以重用。有大量关于垃圾收集的文献:[Appel,1991]是一份简要的综述,其中强调了最新的算法,而[Knuth,1973a]和[Cohen, 1981]则更深入地涵盖了较旧的算法。
为找到可访问的内存块,大多数垃圾收集器都必须知道哪些变量指向内存块,内存块中的哪些字段指向其他内存块。垃圾收集器通常用于具有足够的编译时或运行时数据提供相关必要信息的语言。例子包括LISP、Icon、SmallTalk、ML和Modula-3。保守式垃圾收集器 (conservative collector,见[Boehm and Weiser,1988])可以用于那些不能提供足够类型信息的语言,如C和C++。它们假定,任何对齐正确、看起来像是指针的位模式都是指针,而其指向的内存块是可访问的。因而保守式垃圾收集器会将某些不可访问的内存块标记为可访问的(即被占用),这显然过高估计了可访问内存块集合的大小。尽管有这个明显的障碍,保守式垃圾收集器在有些程序中工作得惊人的好[Zorn,1993]。
6.1 Arena_alloc只查看arena描述的大内存块。如果这个大内存块中空闲空间不足,即使链表中的其他大内存块有足够的空间,它也会分配一个新的大内存块。修改Arena_alloc,以便在某个现存的大内存块有足够空间的情况下,在该块中分配内存空间,并测量修改带来的好处。能找到一个应用程序,经过此修改后,其内存使用量大幅降低吗?
6.2 在Arena_alloc需要一个新的大内存块时,则从空闲链表上取得第一个(如果有的话)。更好的选择是找到满足该请求的最大的空闲大内存块,仅当freechunks链表不包含适当的大内存块时才分配一个新的大内存块。在这个方案中,通过跟踪freechunks链表中最大的大内存块,可以避免不必要的遍历操作。经过这项修改,Arena_alloc中的while循环可以替换为一个if语句。实现该方案并测量其好处。它是否使Arena_alloc显著变慢?它对内存的使用是否更有效率?
6.3 将THRESHOLD设置为10意味着,空闲链表不会包含多于大约100KB内存,因为Arena_alloc分配的大内存块至少为10KB。设计一种方法,使得Arena_alloc和Arena_free能够监控分配和释放模式,并基于模式来动态地计算THRESHOLD。目标是使空闲链表尽可能小,并使调用malloc的次数最少。
6.4 解释Arena接口不支持下列函数的原因
void *Arena_resize(void **ptr, long nbytes,
const char *file, int line)
该函数类似Mem_resize,会将*ptr指向内存块长度改变为nbytes,并返回一个指针指向调整大小后的内存块,该块与*ptr指向的内存块位于同一内存池中(但不见得位于同一大内存块上)。如何修改实现才能支持该函数?该函数的实现将支持何种已检查的运行时错误?
6.5 在基于栈的分配器中,分配操作会将新的内存空间推入指定栈的栈顶,并返回指向该内存块第一个字节的指针。标记一个栈,就是返回编码了栈当前高度的一个值,而释放操作则是将栈顶的空间弹出,使栈回复到此前的高度。为栈分配器设计和实现一个接口。你可以提供哪些已检查的运行时错误来捕获内存释放方面的错误?这种错误的例子,如在一个比当前栈顶高的位置上进行释放,或在一个此前已经释放而后又再次分配出去的位置上进行释放。 [2]
6.6 拥有多个内存分配接口的一个问题是,在不知道哪个分配接口最适合于某个特定应用程序时,其他的接口必须选择某个分配接口。设计并实现一个单一的接口来支持第5章和第6章的两种分配器。例如,该接口可以提供一个类似Mem_alloc的分配函数,但分配函数在某种“分配环境”下运作,而“分配环境”可以由其他函数来更改。这种“环境”将指定内存管理的细节,如使用何种分配器和内存池(如果指定了基于内存池的分配方案)。举例来说,其他函数可以将当前环境推入到一个内部栈上并建立一个新环境,而后可以弹出栈顶的环境,以恢复此前的环境设置。在你的设计中,可以研究这种及其他变体。
[1] 即最后一个字节之后的位置。——译者注
[2] 作者的描述可能并不易懂;实际上,基于栈的分配器相当于在运行栈/调用栈中分配临时内存空间,有点接近于局部变量;分配空间时,只需要将调用栈的栈顶下推即可,一般不需要释放,函数返回时会自动释放;微软的C库提供了一个_alloca函数,就是栈分配器。——译者注