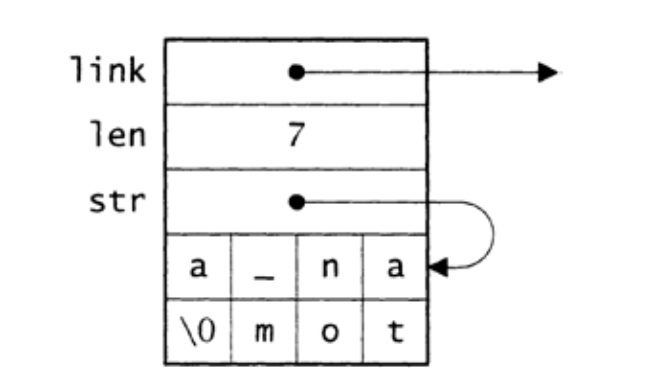
图3-1 表示原子的struct atom实例的“小端序”布局
原子 (atom)是一个指针,指向一个唯一的、不可变的序列,序列中包含零或多个字节(字节值任意)。大多数原子都指向0结尾字符串,但也可以是指向任一字节序列的指针。任一原子都只会出现一次,这也是它被称为原子的原因。如果两个原子指向相同的位置,那么二者是相同的。原子的一个优点是,只通过比较两个指针,即可比较两个字节序列是否相等。使用原子的另一个优点是节省空间,因为任一序列都只会出现一次。
在数据结构中,如果使用任意字节的序列作为索引(而不使用整数),那么通常将原子用作键。第8章和第9章中的表和集合就是例子。
Atom接口很简单:
〈atom.h
〉≡
#ifndef ATOM_INCLUDED
#define ATOM_INCLUDED
extern int Atom_length(const char *str);
extern const char *Atom_new (const char *str, int len);
extern const char *Atom_string(const char *str);
extern const char *Atom_int (long n);
#endif
Atom_new的参数包括一个指向字节序列的指针,以及该序列中的字节数目。如果必要的话,它将该序列的一个副本添加到原子表并返回该原子,即指向原子表中该序列副本的指针。Atom_new从不返回NULL指针。在原子创建后,它在客户程序的整个执行时间内都存在。原子总是以零字符结束,Atom_new在必要时会添加零字符。
Atom_string与Atom_new类似,它迎合了将字符串用作原子的通常用法。该函数接受一个0结尾字符串作为参数,(如有必要)将该字符串的一个副本添加到原子表,并返回该原子。Atom_int返回对应于以字符串表示长整数n的原子,这是另一种常见的用法。最后,Atom_length返回其参数原子的长度。
向本接口中的任何函数传递NULL指针、向Atom_new传递的len参数为负值或者向Atom_length传递的指针并非原子,这些都是已检查的运行时错误。修改原子指向的字节,属于未检查的运行时错误。Atom_length的执行时间与原子的数目成正比。Atom_new、Atom_string和Atom_int都可能引发Mem_Failed异常。
Atom的实现需要维护原子表。Atom_new、Atom_string和Atom_int搜索原子表并可能向其中添加新元素,而Atom_length只是搜索原子表。
〈atom.c 〉≡ 〈includes 25〉 〈macros 28〉 〈data 26〉 〈functions 25〉 〈includes 25〉≡ #include "atom.h"
Atom_string和Atom_int可以在不了解原子表表示细节的情况下实现。例如,Atom_string只是调用了Atom_new:
〈functions 25〉≡ const char *Atom_string(const char *str) { assert(str); return Atom_new(str, strlen(str)); } 〈includes 25〉+≡ #include <string.h> #include "assert.h"
Atom_int首先将其参数转换为一个字符串,然后调用Atom_new:
〈functions 25〉+≡ const char *Atom_int(long n) { char str[43]; char *s = str + sizeof str; unsigned long m; if (n == LONG_MIN) m = LONG_MAX + 1UL; else if (n < 0) m = -n; else m = n; do *--s = m%10 + '0'; while ((m /= 10) > 0); if (n < 0) *--s = '-'; return Atom_new(s, (str + sizeof str) - s); } 〈includes 25〉+≡ #include <limits.h>
Atom_int必须要处理二进制补码表示的整数的非对称范围,以及C语言的除法和模运算的二义性。无符号数的除法和模运算是良定义的,因此Atom_int可以通过使用无符号运算来避免带符号运算符的二义性。
对于有符号的最小负值长整数来说,其绝对值是无法表示的,因为在二进制编码系统中,负数比正数多一个。因而,Atom_new首先检验这种单一的异常情况,然后将其参数的绝对值赋值给无符号长整数m。LONG_MAX的值定义在标准头文件limits.h中。
接下来的循环从右到左建立m的十进制字符串表示,它首先计算最右侧的位,然后将m除以10,依次类推,直至m变为零。随着每个位的得出,相应的字符存储在--s指向的位置,这相当于在str中逆向移动指针s的位置。如果n是负值,还需要在字符串开始处存储一个负号。
当转换完成时,s指向所要的字符串,该字符串包含&str[43]-s个字符。str数组可容纳43个字符,在任何机器上这都足以容纳任何整数的十进制表示。例如,假定long类型的位宽为128个bit。对任意的128位有符号整数来说,它在八进制下的字符串表示可以放到128/3+1=43个字符中 [1] 。十进制表示用的位数不会比八进制表示更多,因此43个字符是足够的。
str定义中的43,就是所谓“魔数”(magic number)的一个例子,通常更好的代码风格要求为这样的值定义一个符号名,以确保代码中各处使用的值是相同的。但在这里,该值只出现一次,而且每次引用该值时都使用了sizeof运算符。定义一个符号名可能使代码更容易读,但也会使代码更长且扰乱命名空间。本书中,仅当相关值出现多次时,或者该值是接口的一部分时,才定义符号名,下文中哈希表buckets的长度(2048),是该约定的另一个例子。
对原子表来说,选择哈希表作为数据结构是显然的。这里的哈希表是一个指针数组,每个指针指向一个链表,链表中的每个表项保存了一个原子:
〈data
26〉≡
static struct atom {
struct atom *link;
int len;
char *str;
} *buckets[2048];
发源自buckets[i]的链表保存了那些散列到i的原子。链表项的link字段指向链表中下一个表项,len字段保存了字节序列的长度,而str字段指向序列本身。例如,在字长32比特、字符位宽8比特的小端序计算机上,Atom_string("an atom")将分配如图3-1所示的struct atom,其中下划线字符(_)表示空格。每个链表项的大小都刚好足够容纳其字节序列。图3-2给出了哈希表的整体结构。
图3-1 表示原子的struct atom实例的“小端序”布局
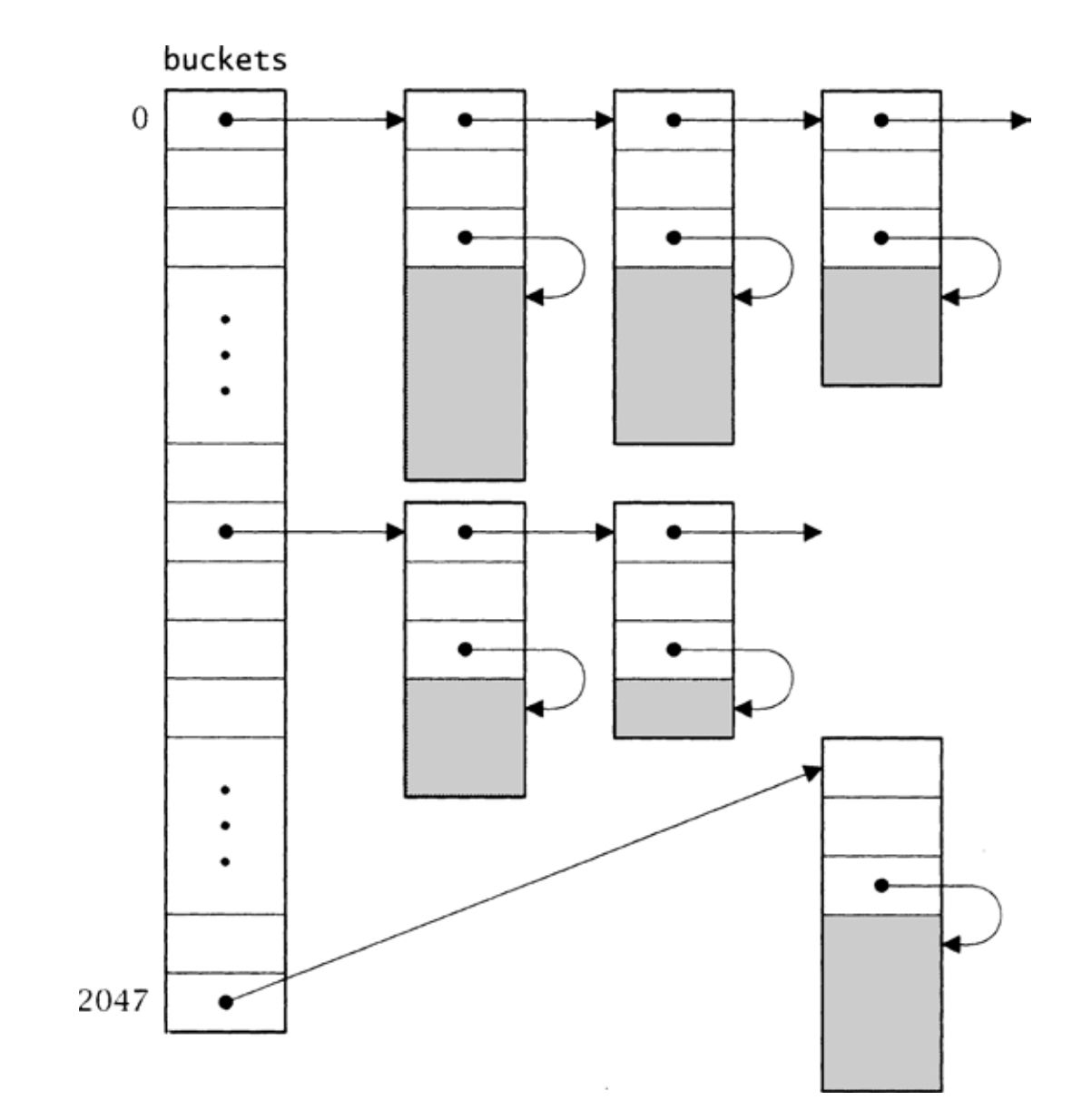
图3-2 哈希表的结构
Atom_new对序列str[0..len-1](或空序列,如果len为零)计算一个哈希码,将该哈希码对哈希桶的数目取模得到一个索引值,并搜索该索引值对应的哈希桶(即链表)。如果函数发现str[0..len-1]已经在表中,就只返回对应的原子:
〈functions 25〉+≡ const char *Atom_new(const char *str, int len) { unsigned long h; int i; struct atom *p; assert(str); assert(len >= 0); 〈h ← hash str[0..len-1] 29〉 h %= NELEMS(buckets); for (p = buckets[h]; p; p = p->link) if (len == p->len) { for (i = 0; i < len && p->str[i] == str[i]; ) i++; if (i == len) return p->str; } 〈allocate a new entry 28〉 return p->str; } 〈macros 28〉≡ #define NELEMS(x) ((sizeof (x))/(sizeof ((x)[0])))
NELEMS的定义说明了一种常见的C语言惯用法:数组中元素的数目,就是数组的大小除以每个数组元素的大小。sizeof是一个编译时运算符,因此该计算只适用于在编译时大小已知的数组。如该定义所示,宏参数用斜体印刷,以标明宏功能体中使用宏参数之处。
如果str[0..len-1]不在表中,Atom_new分配一个struct atom和足够的附加空间来容纳该序列,将str[0..len-1]复制到分配的附加空间中,并将新的表项添加到buckets[h]链表的头部,从而将该序列添加到哈希表中。该链表项也可以添加到链表的尾部,但添加到链表头部比较简单。
〈allocate a new entry 28〉≡ p = ALLOC(sizeof (*p) + len + 1); p->len = len; p->str = (char *)(p + 1); if (len > 0) memcpy(p->str, str, len); p->str[len] = '\0'; p->link = buckets[h]; buckets[h] = p; 〈includes 25〉+≡ #include "mem.h"
ALLOC是Mem接口用于分配内存的主要函数,它模仿了标准库函数malloc:其参数是所需分配的字节数。Atom_new不能使用Mem接口的NEW(在Stack_push中说明过),因为需要分配的字节数取决于len,仅当需要分配的字节数在编译时已知,才能应用NEW。上述对ALLOC的调用,同时为atom结构和字节序列分配了空间,字节序列紧接着结构之后存储。
对传递给Atom_new的序列进行散列,就是计算出表示该序列的一个无符号数。理想情况下,对N个输入序列,所算得的哈希码应该均匀地分布在0到NELEMS(buckets)-1的范围内。如果它们的分布确实如此,那么buckets中的每个链表将有N/NELEMS(buckets)个表项,搜索一个字节序列的平均时间将是N/(2*NELEMS(buckets))。如果(假定)N小于2*NELEMS(buckets),那么搜索时间实质上是一个常数。
散列是一个已经充分研究过的主题,有许多好的哈希函数可用。Atom_new使用一个简单的查表算法:
〈h ← hash
str[0..len-1] 29〉≡
for (h = 0, i = 0; i < len; i++)
h = (h<<1) + scatter[(unsigned char)str[i]];
scatter是一个256项的数组,它将字节值映射到随机数,这些随机数是通过调用标准库函数rand生成的。经验表明,这种简单的方法有助于使哈希值分布更均匀。将str[i]转换为无符号字符可以避免C语言有关“普通”字符的二义性:字符可以是有符号或无符号的。如果不转换,在使用带符号字符的机器上,超过127的str[i]值将产生负的索引值。
〈data
26〉+≡
static unsigned long scatter[] = {
2078917053, 143302914, 1027100827, 1953210302, 755253631, 2002600785,
1405390230, 45248011, 1099951567, 433832350, 2018585307, 438263339,
813528929, 1703199216, 618906479, 573714703, 766270699, 275680090,
1510320440, 1583583926, 1723401032, 1965443329, 1098183682, 1636505764,
980071615, 1011597961, 643279273, 1315461275, 157584038, 1069844923,
471560540, 89017443, 1213147837, 1498661368, 2042227746, 1968401469,
1353778505, 1300134328, 2013649480, 306246424, 1733966678, 1884751139,
744509763, 400011959, 1440466707, 1363416242, 973726663, 59253759,
1639096332, 336563455, 1642837685, 1215013716, 154523136, 593537720,
704035832, 1134594751, 1605135681, 1347315106, 302572379, 1762719719,
269676381, 774132919, 1851737163, 1482824219, 125310639, 1746481261,
1303742040, 1479089144, 899131941, 1169907872, 1785335569, 485614972,
907175364, 382361684, 885626931, 200158423, 1745777927, 1859353594,
259412182, 1237390611, 48433401, 1902249868, 304920680, 202956538,
348303940, 1008956512, 1337551289, 1953439621, 208787970, 1640123668,
1568675693, 478464352, 266772940, 1272929208, 1961288571, 392083579,
871926821, 1117546963, 1871172724, 1771058762, 139971187, 1509024645,
109190086, 1047146551, 1891386329, 994817018, 1247304975, 1489680608,
706686964, 1506717157, 579587572, 755120366, 1261483377, 884508252,
958076904, 1609787317, 1893464764, 148144545, 1415743291, 2102252735,
1788268214, 836935336, 433233439, 2055041154, 2109864544, 247038362,
299641085, 834307717, 1364585325, 23330161, 457882831, 1504556512,
1532354806, 567072918, 404219416, 1276257488, 1561889936, 1651524391,
618454448, 121093252, 1010757900, 1198042020, 876213618, 124757630,
2082550272, 1834290522, 1734544947, 1828531389, 1982435068, 1002804590,
1783300476, 1623219634, 1839739926, 69050267, 1530777140, 1802120822,
316088629, 1830418225, 488944891, 1680673954, 1853748387, 946827723,
1037746818, 1238619545, 1513900641, 1441966234, 367393385, 928306929,
946006977, 985847834, 1049400181, 1956764878, 36406206, 1925613800,
2081522508, 2118956479, 1612420674, 1668583807, 1800004220, 1447372094,
523904750, 1435821048, 923108080, 216161028, 1504871315, 306401572,
2018281851, 1820959944, 2136819798, 359743094, 1354150250, 1843084537,
1306570817, 244413420, 934220434, 672987810, 1686379655, 1301613820,
1601294739, 484902984, 139978006, 503211273, 294184214, 176384212,
281341425, 228223074, 147857043, 1893762099, 1896806882, 1947861263,
1193650546, 273227984, 1236198663, 2116758626, 489389012, 593586330,
275676551, 360187215, 267062626, 265012701, 719930310, 1621212876,
2108097238, 2026501127, 1865626297, 894834024, 552005290, 1404522304,
48964196, 5816381, 1889425288, 188942202, 509027654, 36125855,
365326415, 790369079, 264348929, 513183458, 536647531, 13672163,
313561074, 1730298077, 286900147, 1549759737, 1699573055, 776289160,
2143346068, 1975249606, 1136476375, 262925046, 92778659, 1856406685,
1884137923, 53392249, 1735424165, 1602280572
};
Atom_length无法散列其参数,因为其长度是未知的。但该参数必须是一个原子,因此Atom_length只需遍历buckets中的的各个链表,一一比较指针即可。如果找到该原子,则返回其长度:
〈functions
25〉+≡
int Atom_length(const char *str) {
struct atom *p;
int i;
assert(str);
for (i = 0; i < NELEMS(buckets); i++)
for (p = buckets[i]; p; p = p->link)
if (p->str == str)
return p->len;
assert(0);
return 0;
}
assert(0)实现了一个已检查的运行时错误,即Atom_length必须只对原子调用,而不能对指向其他字符串的指针进行调用。assert(0)也用于指明一些假定不会发生的情况,即所谓“不可能发生”的情况。
原子已经在LISP中长期使用,这也是其名称的来源,它在字符串处理语言中也有很久的使用历史,如SNOBOL4实现的字符串几乎刚好如本章所述[Griswold,1972]。C编译器lcc [Fraser and Hanson,1995]有一个类似于Atom的模块,它是Atom的前任实现。lcc将表示源程序中所有标识符和常数的字符串都存储在一个表中,从来不会释放。这样做从未消耗太多内存,因为与源程序的规模相比,C程序中不同字符串的数目非常少。
[Sedgewick,1990]和[Knuth,1973b]两书详细描述了散列,并给出了编写良好的哈希函数的指导原则。Atom(和lcc)中使用的哈希函数是Hans Boehm建议的。
3.1 大多数教科书推荐将buckets的容量设置为素数。使用素数和良好的哈希函数,通常会使buckets中的链表长度具有更好的分布。Atom使用了2的幂作为buckets的容量,这种做法有时被明确地作为“反面典型”引用。编写一个程序来生成或读入(假定)10000个有代表性的字符串,并测量Atom_new的速度和哈希表中各个链表长度的分布。接下来改变buckets,使之包含2039项(小于2048的最大素数),重复上述测量。使用素数有改进吗?读者的结论在多大程度上取决于你用来测试的具体机器?
3.2 查阅文献寻找更好的哈希函数,可能的来源包括[Knuth,1973b]一书、算法和数据结构方面类似的教科书及其引用的论文、以及编译器方面的教科书,如[Aho, Sethi and Ullman,1986]一书。尝试这些函数并测量其改进情况。
3.3 解释Atom_new不使用标准C库函数strncmp比较字节序列的原因。
3.4 以下是另一种声明原子结构的方法:
struct atom {
struct atom *link;
int len;
char str[1];
};
分配一个包含长度为len的字符串的struct atom实例时,需要用ALLOC(sizeof(*p)+len),这为link和len字段分配了空间,而且为str字段分配的空间足以容纳len+1个字节。正文中将str声明为指针会引入一层额外的间接,这种方法则避免了间接方式所带来的时间和空间开销。遗憾的是,这种“技巧”违反了C语言标准,因为客户程序需要访问超出str[0]的各字节,这种访问的效果是未定义的。实现这种方法,并测量间接方式的开销。为了这些节省,是否值得违反标准?
3.5 Atom_new会比较struct atom实例的len字段与输入的字节序列的长度,以避免比较长度不同的序列。如果每个原子的哈希码(而不是buckets的索引)也存储在struct atom中,还可以比较哈希码。实现并测量这种“改进”。这种做法值得吗?
3.6 Atom_length执行得比较慢。修改Atom的实现,使得Atom_length的运行时间与Atom_new大致相同。
3.7 Atom接口之所以演变到现在的形式,是因为其中的各个函数是客户程序最常用的。还可能使用其他的函数和设计,这里和后续的各习题将探讨这些可能性。请实现
extern void Atom_init(int hint);
其中hint是对客户程序预期创建的原子数目的估计。在可能调用Atom_init时,读者会添加何种已检查的运行时错误以约束其行为?
3.8 在对Atom接口的扩展中,可能提供几种函数来释放原子。例如下述函数:
extern void Atom_free (const char *str); extern void Atom_reset(void);
可以分别释放str指定的原子及所有原子。请实现这些函数。不要忘记指定并实现适当的已检查的运行时错误。
3.9 一些客户程序开始执行时,会将大量字符串设置为原子,供后续使用。请实现
extern void Atom_vload(const char *str, ...); extern void Atom_aload(const char *strs[]);
Atom_vload会将可变长度参数列表中的字符串创建为原子,直至遇到NULL指针为止,而Atom_aload对一个指针数组做同样的操作(即各数组项为指向字符串的指针,遇到NULL指针表示数组结束)。
3.10 如果客户程序承诺不释放字符串,那么可以避免复制字符串,对于字符串常数来说这是一个简单的事实。请实现
extern const char *Atom_add(const char *str, int len);
其工作方式如同Atom_new,但并不复制字节序列。如果读者提供Atom_add和Atom_free(以及习题3.8中的Atom_reset),必须指定并实现何种已检查的运行时错误?
[1] 这个不是很严谨,其实应该是127/3+1=44个字符,这里的除法应当向上舍入;应当不影响10进制下的讨论。——译者注