We will complete this level with a description of concepts that form an important part of the C architecture model and are therefore a must for experienced programmers. Try to comprehend this last chapter to increase your understanding of how things work, not necessarily to improve your operational skills. Even though we will not go into all the glorious details,[1] things can get a bit bumpy: please remain seated and buckle up.
We will put aside memory_order_consume consistency and thus the dependency-ordered before relation.
If you review the pictures of control flow that we have seen throughout the previous chapters, you see that the interaction of different parts of a program execution can get quite complicated. We have different levels of concurrent access to data:
But access to memory is not the only thing a program does. In fact, the abstract state of a program execution consists of the following:
Changes to this state are usually described as
Or they can affect hidden state such as the lock state of a mtx_t or the initialization state of a once_flag, or set or clear operations on an atomic_flag.
We summarize all these possible changes of the abstract state with the term of effect.
Every evaluation has an effect.
This is because any evaluation has the concept of a next such evaluation that will be performed after it. Even an expression like
(void)0;
that drops the intermediate value sets the point of execution to the next statement, and thus the abstract state has changed.
In a complicated context, it will be difficult to argue about the actual abstract state of an execution in a given moment. Generally, the entire abstract state of a program execution is not even observable; and in many cases, the concept of an overall abstract state is not well defined. This is because we actually don’t know what moment means in this context. In a multithreaded execution that is performed on several physical compute cores, there is no real notion of a reference time between them. So generally, C does not even make the assumption that an overall fine-grained notion of time exists between different threads.
As an analogy, think of two threads A and B as events that happen on two different planets that are orbiting with different speeds around a star. Times on these planets (threads) are relative, and synchronization between them takes place only when a signal that is issued from one planet (thread) reaches the other. The transmission of the signal takes time by itself, and when the signal reaches its destination, its source has moved on. So the mutual knowledge of the two planets (threads) is always partial.
If we want to argue about a program’s execution (its correctness, its performance, and so on), we need to have enough of that partial knowledge about the state of all threads, and we have to know how we can stitch that partial knowledge together to get a coherent view of the whole.
Therefore, we will investigate a relation that was introduced by Lamport [1978]. In C standard terms, it is the happened before relation between two evaluations E and F , denoted by F → E. This is a property between events that we observe a posteriori. Fully spelled out, it would perhaps be better called the knowingly happened before relation, instead.
One part of it consists of evaluations in the same thread that are related by the already-introduced sequenced-before relation:
If F is sequenced before E, then F → E.
To see that, let us revisit listing 18.1 from our input thread. Here, the assignment to command[0] is sequenced before the switch statement. Therefore, we are sure that all cases in the switch statement are executed after the assignment, or at least that they will be perceived as happening later. For example, when passing command to the nested function calls below ungetc, we are sure this will provide the modified value. All of this can be deduced from C’s grammar.
Between threads, the ordering of events is provided by synchronization. There are two types of synchronization: the first is implied by operations on atomics, and the second by certain C library calls. Let us first look into the case of atomics. An atomic object can be used to synchronize two threads, if one thread writes a value and another thread reads the value that was written.
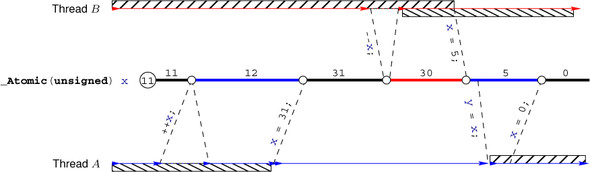
Operations on atomics are guaranteed to be locally consistent; see figure 19.1.
The set of modifications of an atomic object X are performed in an order that is consistent with the sequenced-before relation of any thread that deals with X.
This sequence is called the modification order of X. For example, for the atomic x in the figure, we have six modifications: the initialization (value 11), two increments, and three assignments. The C standard guarantees that each of the two threads A and B perceives all changes to x in an order that is consistent with this modification order.
In the example in the figure, we have only two synchronizations. First, thread B synchronizes with A at the end of its --x operation, because here it has read (and modified) the value 31 that A wrote. The second synchronization occurs when A reads the value 5 that B wrote and stores it into y.
As another example, let us investigate the interplay between the input thread (Listing 18.1) and the account thread (Listing 18.2). Both read and modify the field finished in different places. For the simplicity of the argument, let us assume that there is no other place than in these two functions where finished is modified.
The two threads will only synchronize via this atomic object if either of them modifies it: that is, writes the value true into it. This can happen under two circumstances:
These events are not exclusive, but using an atomic object guarantees that one of the two threads will succeed first in writing to finished.
Observe that these synchronizations are oriented: each synchronization between threads has a “writer” and a “reader” side. We attach two abstract properties to operations on atomics and to certain C library calls that are called release semantics (on the writer side), acquire semantics (for a reader), or acquire-release semantics (for a reader-writer). C library calls with such synchronization properties will be discussed a bit later.
All operations on atomics that we have seen so far and that modify the object are required to have release semantics, and all that read have acquire semantics. Later we will see other atomic operations that have relaxed properties.
An acquire operation E in a thread TE synchronizes with a release operation F if another thread TF if E reads the value that F has written.
The idea of the special construction with acquire and release semantics is to force the visibility of effects across such operations. We say that an effect X is visible at evaluation E if we can consistently replace E with any appropriate read operation or function call that uses the state affected by X. For example, in figure 19.1 the effects that A produces before its x = 31 operation are symbolized by the bar below the thread. They are visible to B once B has completed the --x operation.
If F synchronizes with E, all effects X that happened before F must be visible at all evaluations G that happen after E.
As we saw in the example, there are atomic operations that can read and write atomically in one step. These are called read-modify-write operations:
Such an operation can synchronize on the read side with one thread and on the write side with others. All such read-modify-write operations that we have seen so far have both acquire and release semantics.
The happened-before relation closes the combination of the sequenced-before and synchronizes-with relations transitively. We say that F knowingly happened before E, if there are n and E0 = F, E1, ..., En–1, En = E such that Ei is sequenced before Ei+1 or synchronizes with it, for all 0 ≤ i < n.
We only can conclude that one evaluation happened before another if we have a sequenced chain of synchronizations that links them.
Observe that this happened-before relation is a combination of very different concepts. The sequenced-before relation can in many places be deduced from syntax, in particular if two statements are members of the same basic block. Synchronization is different: besides the two exceptions of thread startup and end, it is deduced through a data dependency on a specific object, such as an atomic or a mutex.
The desired result of all this is that effects in one thread become visible in another.
If an evaluation F happened before E, all effects that are known to have happened before F are also known to have happened before E.
C library functions with synchronizing properties come in pairs: a releasing side and an acquiring side. They are summarized in table 19.1.
Note that for the first three entries, we know which events synchronize with which, namely the synchronization is mainly limited to effects done by thread id. In particular, by transitivity we see that thrd_exit or return always synchronize with thrd_join for the corresponding thread id.
These synchronization features of thrd_create and thrd_join allowed us to draw the lines in figure 18.1. Here, we do not know about any timing of events between the threads that we launched, but within main we know that the order in which we created the threads and the order in which we joined them is exactly as shown. We also know that all effects of any of these threads on data objects are visible to main after we join the last thread: the account thread.
|
Release |
Acquire |
|---|---|
| thrd_create(.., f, x) | Entry to f(x) |
| thrd_exit by thread id or return from f | Start of tss_t destructors for id |
| End of tss_t destructors for id | thrd_join(id) or atexit/at_quick_exit handlers |
| call_once(&obj, g), first call | call_once(&obj, h), all subsequent calls |
| Mutex release | Mutex acquisition |
If we detach our threads and don’t use thrd_join synchronization can only take place between the end of a thread and the start of an atexit or at_quick_exit handler.
The other library functions are a bit more complicated. For the initialization utility call_once, the return from the very first call call_once(&obj, g), the one that succeeds in calling its function g, is a release operation for all subsequent calls with the same object obj. This ensures that all write operations that are performed during the call to g() are known to happen before any other call with obj. Thereby all other such calls also know that the write operations (the initializations) have been performed.
For our example in section 18.2, this means the function errlog_fopen is executed exactly once, and all other threads that might execute the call_once line will synchronize with that first call. So when any of the threads return from the call, they know that the call has been performed (either by themselves or by another thread that was faster) and that all effects such as computing the filename and opening the stream are visible now. Thus all threads that executed the call may use errlog and can be sure it is properly initialized.
For a mutex, a release operation can be a call to a mutex function, mtx_unlock, or the entry into the wait functions for condition variables, cnd_wait and cnd_timedwait. An acquire operation on a mutex is the successful acquisition of the mutex via any of the three mutex calls mtx_lock, mtx_trylock, and mtx_timedlock, or the return from the the wait function cnd_wait or cnd_timedwait.
Critical sections that are protected by the same mutex occur sequentially.
Our input and accounting threads from the example (listings 18.1 and 18.2) access the same mutex L->mtx. In the first, it is used to protect the birth of a new set of cells if the user types a ' ', 'b', or 'B'. In the second, the entire inner block of the while loop is protected by the mutex.
Figure 19.2 schematizes a sequence of three critical sections that are protected by the mutex. The synchronization between the unlock operations (release) and the return from the lock operation (acquire) synchronizes the two threads. This guarantees that the changes applied to *L by the account thread in the first call to life_account are visible in the input thread when it calls life_birth9. Equally, the second call to life_account sees all changes to *L that occur during the call to life_birth9.
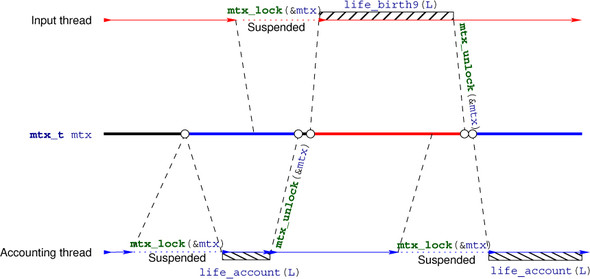
In a critical section that is protected by the mutex mut, all effects of previous critical sections protected by mut are visible.
One of these known effects is always the advancement of the point of execution. In particular, on return from mtx_unlock, the execution point is outside the critical section, and this effect is known to the next thread that newly acquires the lock.
The wait functions for condition variables differ from acquire-release semantics; in fact, they work exactly the other way around.
cnd_wait and cnd_timedwait have release-acquire semantics for the mutex.
That is, before suspending the calling thread, they perform a release operation and then, when returning, an acquire operation. The other peculiarity is that the synchronization goes through the mutex, not through the condition variable itself.
Calls to cnd_signal and cnd_broadcast synchronize via the mutex.
The signaling thread will not necessarily synchronize with the waiting thread if it does not place a call to cnd_signal or cnd_broadcast into a critical section that is protected by the same mutex as the waiter. In particular, non-atomic modifications of objects that constitute the condition expression may not become visible to a thread that is woken up by a signal if the modification is not protected by the mutex. There is a simple rule of thumb to ensure synchronization:
Calls to cnd_signal and cnd_broadcast should occur inside a critical section that is protected by the same mutex as the waiters.
This is what we saw around line 145 in listing 18.1. Here, the function life_birth modifies larger, non-atomic parts of *L, so we must make sure these modifications are properly visible to all other threads that work with *L.
Line 154 shows a use of cnd_signal that is not protected by the mutex. This is only possible here because all data that is modified in the other switch cases is atomic. Thus other threads that read this data, such as L->frames, can synchronize through these atomics and do not rely on acquiring the mutex. Be careful if you use conditional variables like that.
The data consistency for atomic objects that we described earlier, guaranteed by the happened-before relation, is called acquire-release consistency. Whereas the C library calls we have seen always synchronize with that kind of consistency, no more and no less, accesses to atomics can be specified with different consistency models.
As you remember, all atomic objects have a modification order that is consistent with all sequenced-before relations that see these modifications on the same object. Sequential consistency has even more requirements than that; see figure 19.3. Here we illustrate the common timeline of all sequentially consistent operations on top. Even if these operations are performed on different processors and the atomic objects are realized in different memory banks, the platform has to ensure that all threads perceive all these operations as being consistent with this one global linearization.
All atomic operations with sequential consistency occur in one global modification order, regardless of the atomic object they are applied to.
So, sequential consistency is a very strong requirement. Not only that, it enforces acquire-release semantics (a causal partial ordering between events), but it rolls out this partial ordering to a total ordering. If you are interested in parallelizing the execution of your program, sequential consistency may not be the right choice, because it may force sequential execution of the atomic accesses.
The standard provides the following functional interfaces for atomic types. They should conform to the description given by their name and also perform synchronization:
void atomic_store(A volatile* obj, C des); C atomic_load(A volatile* obj); C atomic_exchange(A volatile* obj, C des); bool atomic_compare_exchange_strong(A volatile* obj, C *expe, C des); bool atomic_compare_exchange_weak(A volatile* obj, C *expe, C des); C atomic_fetch_add(A volatile* obj, M operand); C atomic_fetch_sub(A volatile* obj, M operand); C atomic_fetch_and(A volatile* obj, M operand); C atomic_fetch_or(A volatile* obj, M operand); C atomic_fetch_xor(A volatile* obj, M operand); bool atomic_flag_test_and_set(atomic_flag volatile* obj); void atomic_flag_clear(atomic_flag volatile* obj);
Here C is any appropriate data type, A is the corresponding atomic type, and M is a type that is compatible with the arithmetic of C. As the names suggest, for the fetch and operator interfaces the call returns the value that *obj had before the modification of the object. So these interfaces are not equivalent to the corresponding compound assignment operator (+=), since that would return the result after the modification.
All these functional interfaces provide sequential consistency.
All operators and functional interfaces on atomics that don’t specify otherwise have sequential consistency.
Observe also that the functional interfaces differ from the operator forms, because their arguments are volatile qualified.
There is another function call for atomic objects that does not imply synchronization:
void atomic_init(A volatile* obj, C des);
Its effect is the same as a call to atomic_store or an assignment operation, but concurrent calls from different threads can produce a race. View atomic_init as a cheap form of assignment.
A different consistency model can be requested with a complementary set of functional interfaces. For example, an equivalent to the postfix ++ operator with just acquire-release consistency could be specified with
_Atomic(unsigned) at = 67; ... if (atomic_fetch_add_explicit(&at, 1, memory_order_acq_rel)) { ... }
Synchronizing functional interfaces for atomic objects have a form with _explicit appended that allows us to specify their consistency model.
These interfaces accept additional arguments in the form of symbolic constants of type memory_order that specify the memory semantics of the operation:
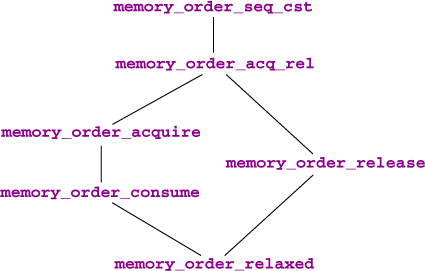
The consistency models can be compared with respect to the restrictions they impose to the platform. Figure 19.4 shows the implication order of the memory_order models.
Whereas memory_order_seq_cst and memory_order_relaxed are admissible for all operations, there are some restrictions for other memory_orders. Operations that can only occur on one side of a synchronization can only specify an order for that side. Therefore, the two operations that only store (atomic_store or atomic_flag_clear) may not specify acquire semantics. Three operations only perform a load and may not specify release or consume semantics: besides atomic_load, these are atomic_compare_exchange_weak and atomic_compare_exchange_strong in case of failure. Thus, the latter two need two memory_order arguments for their _explicit form, such that they can distinguish the requirements for the success and failure cases:
bool atomic_compare_exchange_strong_explicit(A volatile* obj, C *expe, C des, memory_order success, memory_order failure); bool atomic_compare_exchange_weak_explicit(A volatile* obj, C *expe, C des, memory_order success, memory_order failure);
Here, the success consistency must be at least as strong as the failure consistency; see figure 19.4.
Up to now, we have implicitly assumed that the acquire and release sides of a synchronization are symmetric, but they aren’t: whereas there always is just one writer of a modification, there can be several readers. Because moving new data to several processors or cores is expensive, some platforms allow us to avoid the propagation of all visible effects that happened before an atomic operation to all threads that read the new value. C’s consume consistency is designed to map this behavior. We will not go into the details of this model, and you should use it only when you are certain that some effects prior to an atomic read will not affect the reading thread.