
Threads are another variation of control flow that allow us to pursue several tasks concurrently. Here, a task is a part of the job that is to be executed by a program such that different tasks can be done with no or little interaction between each other.
Our main example for this will be a primitive game that we call B9 that is a variant of Conway’s game of life (see Gardner [1970]). It models a matrix of primitive “cells” that are born, live, and die according to very simple rules. We divide the game into four different tasks, each of which proceeds iteratively. The cells go through life cycles that compute birth or death events for all cells. The graphical presentation in the terminal goes through drawing cycles, which are updated as fast as the terminal allows. Spread between these are user keystrokes that occur irregularly and that allow the user to add cells at chosen positions. Figure 18.1 shows a schematic view of these tasks for B9.
The four tasks are:
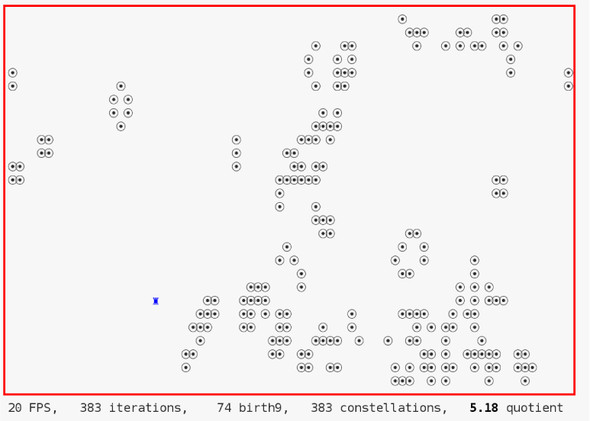
Each such task is executed by a thread that follows its own control flow, much like a simple program of its own. If the platform has several processors or cores, these threads may be executed simultaneously. But even if the platform does not have this capacity, the system will interleave the execution of the threads. The execution as a whole will appear to the user as if the events that are handled by the tasks are concurrent. This is crucial for our example, since we want the game to appear to continue constantly whether the player presses keys on the keyboard or not.
Threads in C are dealt with through two principal function interfaces that can be used to start a new thread and then wait for the termination of such a thread: Here the second argument of thrd_create is a function pointer of type thrd_start_t. This function is executed
#include <threads.h> typedef int (*thrd_start_t)(void*); int thrd_create(thrd_t*, thrd_start_t, void*); int thrd_join(thrd_t, int *);
at the start of the new thread. As we can see from the typedef the function receives a void* pointer and returns an int. The type thrd_t is an opaque type, which will identify the newly created thread.
In our example, four calls in main to thrd_create create the four threads that correspond to the different tasks. These execute concurrently to the original thread of main. At the end, main waits for the four threads to terminate; it joins them. The four threads reach their termination simply when they return from the initial function with which they were started. Accordingly, our four functions are declared as
static int update_thread(void*); static int draw_thread(void*); static int input_thread(void*); static int account_thread(void*);
These four functions are launched in threads of their own by our main, and all four receive a pointer to an object of type life that holds the state of the game:
201 /* Create an object that holds the game's data. */ 202 life L = LIFE_INITIALIZER; 203 life_init(&L, n0, n1, M); 204 /* Creates four threads that all operate on that same object 205 and collects their IDs in "thrd" */ 206 thrd_t thrd[4]; 207 thrd_create(&thrd[0], update_thread, &L); 208 thrd_create(&thrd[1], draw_thread, &L); 209 thrd_create(&thrd[2], input_thread, &L); 210 thrd_create(&thrd[3], account_thread, &L); 211 /* Waits for the update thread to terminate */ 212 thrd_join(thrd[0], 0); 213 /* Tells everybody that the game is over */ 214 L.finished = true; 215 ungetc('q', stdin); 216 /* Waits for the other threads */ 217 thrd_join(thrd[1], 0); 218 thrd_join(thrd[2], 0); 219 thrd_join(thrd[3], 0);
The simplest of the four thread functions is account_thread. As its interface only receives a void*, its first action is to reinterpret it as a life pointer and then to enter a while loop until its work is finished:
99 int account_thread(void* Lv) { 100 life*restrict L = Lv; 101 while (!L->finished) { 102 // Blocks until there is work
117 return 0; 118 }
The core of that loop calls a specific function for the task, life_account, and then checks whether, from its point of view, the game should be finished:
108 life_account(L); 109 if ((L->last + repetition) < L->accounted) { 110 L->finished = true; 111 } 112 // ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Here the condition for termination is whether the game had previously entered the same sequence of repetition game configurations.
The implementations of the other three functions are similar. All reinterpret their argument to be a pointer to life and enter a processing loop until they detect that the game has finished. Then, inside the loop, they have relatively simple logic to fulfill their specific task for this specific iteration. For example, draw_thread’s inner part looks like this:
79 if (L->n0 <= 30) life_draw(L); 80 else life_draw4(L); 81 L->drawn++; 82 // ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
We already have seen two different tools for a control between threads. First, thrd_join allows a thread to wait until another one is finished. We saw this when our main joined the four other threads. This ensures that this main thread effectively only terminates when all other threads have done so, and so the program execution stays alive and consistent until the last thread is gone.
The other tool was the member finished of life. This member holds a bool that has a value that is true whenever one of the threads detects a condition that terminates the game.
Similar to signal handlers, the simultaneous conflicting action of several threads on shared variables must be handled very carefully.
If a thread T0 writes a non-atomic object that is simultaneously read or written by another thread T1, the behavior of the execution becomes undefined.
In general, it will even be difficult to establish what simultaneously should mean when we talk about different threads (as discussed shortly). Our only chance to avoid such situations is to rule out all potential conflicting accesses. If there is such a potential simultaneous unprotected access, we speak of a race condition.
In our example, unless we take specific precautions, even an update of a bool such as finished can be divisible between different threads. If two threads access it in an interleaved way, an update may mix things up and lead to an undefined program state. The compiler cannot know whether a specific object can be subject to a race condition, and therefore we have to tell it explicitly. The simplest way to do so is by using a tool that we also saw with signal handlers: atomics. Here, our life structure has several members that are specified with _Atomic:
40 // Parameters that will dynamically be changed by 41 // different threads 42 _Atomic(size_t) constellations; //< Constellations visited 43 _Atomic(size_t) x0; //< Cursor position, row 44 _Atomic(size_t) x1; //< Cursor position, column 45 _Atomic(size_t) frames; //< FPS for display 46 _Atomic(bool) finished; //< This game is finished.
Access to these members is guaranteed to be atomic. Here, this is the member finished that we already know, and some other members that we use to communicate between input and draw, in particular the current position of the cursor.
In view of execution in different threads, standard operations on atomic objects are indivisible and linearizable.
Here, linearizability ensures that we can also argue with respect to the ordering of computations in two different threads. For our example, if a thread sees that finished is modified (set to true), it knows that the thread setting it has performed all the actions that it is supposed to do. In that sense, linearizability extends the merely syntactical properties of sequencing (section 17.2) to threads.
So operations on atomic objects also help us to determine which parts of our threads are not executed simultaneously, such that no race conditions may occur between them. Later, in section 19.1, we will see how this can be formalized into the happened-before relation.
Because atomic objects differ semantically from normal objects, the primary syntax to declare them is an atomic specifier: as we have seen, the keyword _Atomic followed by parentheses containing the type from which the atomic is derived. There is also another syntax that uses _Atomic as an atomic qualifier similar to the other qualifiers const, volatile, and restrict. In the following specifications, the two different declarations of A and B are equivalent:
extern _Atomic(double (*)[45]) A; extern double (*_Atomic A)[45]; extern _Atomic(double) (*B)[45]; extern double _Atomic (*B)[45];
They refer to the same objects A, an atomic pointer to an array of 45 double elements, and B, a pointer to an array of 45 atomic double elements.
The qualifier notation has a pitfall: it might suggest similarities between _Atomic qualifiers and other qualifiers, but in fact these do not go very far. Consider the following example with three different “qualifiers”:
double var; // Valid: adding const qualification to the pointed-to type extern double const* c = &var; // Valid: adding volatile qualification to the pointed-to type extern double volatile* v = &var; // Invalid: pointers to incompatible types extern double _Atomic* a = &var;
So it is preferable not to fall into the habit of seeing atomics as qualifiers.
Use the specifier syntax _Atomic(T) for atomic declarations.
Another restriction for _Atomic is that it cannot be applied to array types:
_Atomic(double[45]) C; // Invalid: atomic cannot be applied to arrays. _Atomic(double) D[45]; // Valid: atomic can be applied to array base.
Again, this differs from similarly “qualified” types:
typedef double darray[45]; // Invalid: atomic cannot be applied to arrays. darray _Atomic E; // Valid: const can be applied to arrays. darray const F = { 0 }; // Applies to base type double const F[45]; // Compatible declaration
There are no atomic array types.
Later on in this chapter, we will also see another tool that ensures linearizability: mtx_t. But atomic objects are by far the most efficient and easy to use.
Atomic objects are the privileged tool to force the absence of race conditions.
For any data that is shared by threads, it is important that it is initially set into a well-controlled state before any concurrent access is made, and that it is never accessed after it eventually has been destroyed. For initialization, there are several possibilities, presented here in order of preference:
So the latter, call_once, is only needed under very special circumstances:
void call_once(once_flag* flag, void cb(void));
Similar to atexit, call_once registers a callback function cb that should be called at exactly one point of the execution. The following gives a basic example of how this is supposed to be used:
/* Interface */ extern FILE* errlog; once_flag errlog_flag; extern void errlog_fopen(void); /* Incomplete implementation; discussed shortly */ FILE* errlog = 0; once_flag errlog_flag = ONCE_FLAG_INIT; void errlog_fopen(void) { srand(time()); unsigned salt = rand(); static char const format[] = "/tmp/error-\%#X.log" char fname[16 + sizeof format]; snprintf(fname, sizeof fname, format, salt); errlog = fopen(fname, "w"); if (errlog) { setvbuf(errlog, 0, _IOLBF, 0); // Enables line buffering } } /* Usage */ /* ... inside a function before any use ... */ call_once(&errlog_flag, errlog_fopen); /* ... now use it ... */ fprintf(errlog, "bad, we have weird value \%g!\n", weird);
Here we have a global variable (errlog) that needs dynamic initialization (calls to time, srand, rand, snprintf, fopen, and setvbuf) for its initialization. Any usage of that variable should be prefixed with a call to call_once that uses the same once_flag (here, errlog_flag) and the same callback function (here, errlog_fopen).
So in contrast to atexit, the callback is registered with a specific object, namely one of type once_flag. This opaque type guarantees enough state to
Thus, any using thread can be sure that the object is correctly initialized without overwriting an initialization that another thread might have effected. All stream functions (but fopen and fclose) are race-free.
A properly initialized FILE* can be used race-free by several threads.
Here, race-free only means your program will always be in a well-defined state; it does not mean your file may not contain garbled output lines originating from different threads. To avoid that, you’d have to make sure a call to fprintf or similar always prints an entire line.
Concurrent write operations should print entire lines at once.
Race-free destruction of objects can be much more subtle to organize, because the access to data for initialization and destruction is not symmetric. Whereas it often is easy to determine at the beginning of the lifetime of an object that (and when) there is a single user, seeing whether there are still other threads that use an object is difficult if we do not keep track of it.
Destruction and deallocation of shared dynamic objects needs a lot of care.
Imagine your precious hour-long execution that crashes just before the end, when it tries to write its findings into a file.
In our B9 example, we had a simple strategy to ensure that the variable L could be safely used by all created threads. It was initialized before all threads were created, and it only ceased to exist after all created threads were joined.
For the once_flag example, variable errlog, it is not so easy to see when we should close the stream from within one of our threads. The easiest way is to wait until we are sure there are no other threads around, when we are exiting the entire program execution:
/* Complete implementation */ FILE* errlog = 0; static void errlog_fclose(void) { if (errlog) { fputs("*** closing log ***", errlog); fclose(errlog); } } once_flag errlog_flag = ONCE_FLAG_INIT; void errlog_fopen(void) { atexit(errlog_fclose); ...
This introduces another callback (errlog_fclose) that ensures that a last message is printed to the file before closing it. To ensure that this function is executed on program exit, it is registered with atexit as soon as the initializing function errlog_fopen is entered.
The easiest way to avoid race conditions is to strictly separate the data that our threads access. All other solutions, such as the atomics we have seen previously and the mutexes and condition variables that we will see later, are much more complex and much more expensive. The best way to access data local to threads is to use local variables:
Pass thread-specific data through function arguments.
Keep thread-specific state in local variables.
In case this is not possible (or maybe too complicated), a special storage class and a dedicated data type allow us to handle thread-local data. _Thread_local is a storage class specifier that forces a thread-specific copy of the variable that is declared as such. The header threads.h also provides a macro thread_local, which expands to the keyword.
<threads.h>
A thread_local variable has one separate instance for each thread.
That is, thread_local variables must be declared similar to variables with static storage duration: they are declared in file scope, or, if not, they must additionally be declared static (see section 13.2, table 13.1). As a consequence, they cannot be initialized dynamically.
Use thread_local if initialization can be determined at compile time.
If a storage class specifier is not sufficient because we have to do dynamic initialization and destruction, we can use thread-specific storage, tss_t. It abstracts the identification of thread-specific data into an opaque ID, referred to as key, and accessor functions to set or get the data:
void* tss_get(tss_t key); // Returns a pointer to an object int tss_set(tss_t key, void *val); // Returns an error indication
The function that is called at the end of a thread to destroy the thread-specific data is specified as a function pointer of type tss_dtor_t when the key is created:
typedef void (*tss_dtor_t)(void*); // Pointer to a destructor int tss_create(tss_t* key, tss_dtor_t dtor); // Returns an error indication void tss_delete(tss_t key);
Other parts of the life structure cannot be protected as easily. They correspond to larger data, such as the board positions of the game. Perhaps you remember that arrays may not be specified with _Atomic; and even if we were able to do so using some tricks, the result would not be very efficient. Therefore, we not only declare the members Mv (for the game matrix) and visited (to hash already-visited constellations) but also a special member mtx:
15 mtx_t mtx; //< Mutex that protects Mv 16 cnd_t draw; //< cnd that controls drawing 17 cnd_t acco; //< cnd that controls accounting 18 cnd_t upda; //< cnd that controls updating 19 20 void*restrict Mv; //< bool M[n0][n1]; 21 bool (*visited)[life_maxit]; //< Hashing constellations
This member mtx has the special type mtx_t, a mutex type (for mutual exclusion) that also comes with threads.h. It is meant to protect the critical data: Mv, while it is accessed in a well-identified part of the code, a critical section.
<threads.h>
The most simple use case for this mutex is in the center of the input thread, listing 18.1 line 145, where two calls, mtx_lock and mtx_unlock, protect the access to the life data structure L.
121 int input_thread(void* Lv) { 122 termin_unbuffered(); 123 life*restrict L = Lv; 124 enum { len = 32, }; 125 char command[len]; 126 do { 127 int c = getchar(); 128 command[0] = c; 129 switch(c) { 130 case GO_LEFT : life_advance(L, 0, -1); break; 131 case GO_RIGHT: life_advance(L, 0, +1); break; 132 case GO_UP : life_advance(L, -1, 0); break; 133 case GO_DOWN : life_advance(L, +1, 0); break; 134 case GO_HOME : L->x0 = 1; L->x1 = 1; break; 135 case ESCAPE : 136 ungetc(termin_translate(termin_read_esc(len, command)), stdin); 137 continue; 138 case '+': if (L->frames < 128) L->frames++; continue; 139 case '-': if (L->frames > 1) L->frames--; continue; 140 case ' ': 141 case 'b': 142 case 'B': 143 mtx_lock(&L->mtx); 144 // VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV 145 life_birth9(L); 146 // ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ 147 cnd_signal(&L->draw); 148 mtx_unlock(&L->mtx); 149 continue; 150 case 'q': 151 case 'Q': 152 case EOF: goto FINISH; 153 } 154 cnd_signal(&L->draw); 155 } while (!(L->finished || feof(stdin))); 156 FINISH: 157 L->finished = true; 158 return 0; 159 }
This routine is mainly composed of the input loop, which, in turn, contains a big switch to dispatch on different characters that the user typed into the keyboard. Only two of the cases need this kind of protection: 'b' and 'B', which trigger the forced “birth” of a 3 3 cluster of cells around the current cursor position. In all other cases, we only interact with atomic objects, and so we can safely modify these.
The effect of locking and unlocking the mutex is simple. The call to mtx_lock blocks execution of the calling thread until it can be guaranteed that no other thread is inside a critical section that is protected by the same mutex. We say that mtx_lock acquires the lock on the mutex and holds it, and that then mtx_unlock releases it. The use of mtx also provides linearizability similar to the use of atomic objects, as we saw earlier. A thread that has acquired a mutex M can rely on the fact that all operations that were done before other threads released the same mutex M have been effected.
Mutex operations provide linearizability.
C’s mutex lock interfaces are defined as follows:
int mtx_lock(mtx_t*); int mtx_unlock(mtx_t*); int mtx_trylock(mtx_t*); int mtx_timedlock(mtx_t*restrict, const struct timespec*restrict);
The two other calls enable us to test (mtx_trylock) whether another thread already holds a lock (and thus we may avoid waiting) or to wait (mtx_timedlock) for a maximal period (and thus we may avoid blocking forever). The latter is allowed only if the mutex had been initialized as of being of the mtx_timed “type,” as discussed shortly.
There are two other calls for dynamic initialization and destruction:
int mtx_init(mtx_t*, int); void mtx_destroy(mtx_t*);
Other than for more-sophisticated thread interfaces, the use of mtx_init is mandatory; there is no static initialization defined for mtx_t.
Every mutex must be initialized with mtx_init.
The second parameter of mtx_init specifies the “type” of the mutex. It must be one of these four values:
As you probably have guessed, using mtx_plain versus mtx_timed controls the possibility to use mtx_timedlock. The additional property mtx_recursive enables us to call mtx_lock and similar functions successively several times for the same thread, without unlocking it beforehand.
A thread that holds a nonrecursive mutex must not call any of the mutex lock functions for it.
The name mtx_recursive indicates that it is mostly used for recursive functions that call mtx_lock on entry of a critical section and mtx_unlock on exit.
A recursive mutex is only released after the holding thread issues as many calls to mtx_unlock as it has acquired locks.
A locked mutex must be released before the termination of the thread.
A thread must only call mtx_unlock on a mutex that it holds.
From all of this, we can deduce a simple rule of thumb:
Each successful mutex lock corresponds to exactly one call to mtx_unlock.
Depending on the platform, a mutex may bind a system resource that is attributed each time mtx_init is called. Such a resource can be additional memory (such as a call to malloc) or some special hardware. Therefore, it is important to release such resources once a mutex reaches the end of its lifetime.
A mutex must be destroyed at the end of its lifetime.
So in particular, mtx_destroy must be called
While we have seen that the input didn’t need much protection against races, the opposite holds for the account task (see listing 18.2). Its whole job (carried out by the call to life_account) is to scan through the entire position matrix and to account for the number of life neighbors every position has.
99 int account_thread(void* Lv) { 100 life*restrict L = Lv; 101 while (!L->finished) { 102 // Blocks until there is work 103 mtx_lock(&L->mtx); 104 while (!L->finished && (L->accounted == L->iteration)) 105 life_wait(&L->acco, &L->mtx); 106 107 // VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV 108 life_account(L); 109 if ((L->last + repetition) < L->accounted) { 110 L->finished = true; 111 } 112 // ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ 113 114 cnd_signal(&L->upda); 115 mtx_unlock(&L->mtx); 116 } 117 return 0; 118 }
Similarly, the update and draw threads mainly consist of one critical section inside an outer loop: see listings 18.3 and 18.4, which perform the action. After that critical section, we also have a call to life_sleep that suspends the execution for a certain amount of time. This ensures that these threads are only run with a frequency that corresponds to the frame rate of our graphics.
35 int update_thread(void* Lv) { 36 life*restrict L = Lv; 37 size_t changed = 1; 38 size_t birth9 = 0; 39 while (!L->finished && changed) { 40 // Blocks until there is work 41 mtx_lock(&L->mtx); 42 while (!L->finished && (L->accounted < L->iteration)) 43 life_wait(&L->upda, &L->mtx); 44 45 // VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV 46 if (birth9 != L->birth9) life_torus(L); 47 life_count(L); 48 changed = life_update(L); 49 life_torus(L); 50 birth9 = L->birth9; 51 L->iteration++; 52 // ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ 53 54 cnd_signal(&L->acco); 55 cnd_signal(&L->draw); 56 mtx_unlock(&L->mtx); 57 58 life_sleep(1.0/L->frames); 59 } 60 return 0; 61 }
64 int draw_thread(void* Lv) { 65 life*restrict L = Lv; 66 size_t x0 = 0; 67 size_t x1 = 0; 68 fputs(ESC_CLEAR ESC_CLRSCR, stdout); 69 while (!L->finished) { 70 // Blocks until there is work 71 mtx_lock(&L->mtx); 72 while (!L->finished 73 && (L->iteration <= L->drawn) 74 && (x0 == L->x0) 75 && (x1 == L->x1)) { 76 life_wait(&L->draw, &L->mtx); 77 } 78 // VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV 79 if (L->n0 <= 30) life_draw(L); 80 else life_draw4(L); 81 L->drawn++; 82 // ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ 83 84 mtx_unlock(&L->mtx); 85 86 x0 = L->x0; 87 x1 = L->x1; 88 // No need to draw too quickly 89 life_sleep(1.0/40); 90 } 91 return 0; 92 }
In all three threads, the critical section mostly covers the loop body. In addition to the proper computation, there is first a phase in these critical sections where the thread is actually paused until new computing is necessary. More precisely, for the accounting thread, there is a conditional loop that can only be left once either
The body of that loop is a call to life_wait, a function that suspends the calling thread for one second or until a specific event occurs:
18 int life_wait(cnd_t* cnd, mtx_t* mtx) { 19 struct timespec now; 20 timespec_get(&now, TIME_UTC); 21 now.tv_sec += 1; 22 return cnd_timedwait(cnd, mtx, &now); 23 }
Its main ingredient is a call to cnd_timedwait that takes a condition variable of type cnd_t, a mutex, and an absolute time limit.
Such condition variables are used to identify a condition for which a thread might want to wait. Here, in our example, you have seen declarations for three such condition variable members of life: draw, acco, and upda. Each of these corresponds to test conditions that the drawing, the accounting, and the update need in order to proceed to perform their proper tasks. As we have seen, accounting has
104 while (!L->finished && (L->accounted == L->iteration)) 105 life_wait(&L->acco, &L->mtx);
Similarly, update and draw have
42 while (!L->finished && (L->accounted < L->iteration)) 43 life_wait(&L->upda, &L->mtx);
and
72 while (!L->finished 73 && (L->iteration <= L->drawn) 74 && (x0 == L->x0) 75 && (x1 == L->x1)) { 76 life_wait(&L->draw, &L->mtx); 77 }
The conditions in each of these loops reflect the cases when there is work to do for the tasks. Most importantly, we have to be sure not to confound the condition variable, which serves as a sort of identification of the condition, and the condition expression. A call to a wait function for cnd_t may return although nothing concerning the condition expression has changed.
On return from a cnd_t wait, the expression must be checked again.
Therefore, all our calls to life_wait are placed inside loops that check the condition expression.
This may be obvious in our example, since we are using cnd_timedwait under the hood, and the return might just be because the call timed out. But even if we use the untimed interface for the wait condition, the call might return early. In our example code, the call might eventually return when the game is over, so our condition expression always contains a test for L->finished.
cnd_t comes with four principal control interfaces:
int cnd_wait(cnd_t*, mtx_t*); int cnd_timedwait(cnd_t*restrict, mtx_t*restrict, const struct timespec * restrict); int cnd_signal(cnd_t*); int cnd_broadcast(cnd_t*);
The first works analogously to the second, but there is no timeout, and a thread might never come back from the call if the cnd_t parameter is never signaled.
cnd_signal and cnd_broadcast are on the other end of the control. We saw the first applied in input_thread and account_thread. They ensure that a thread (cnd_signal) or all threads (cnd_broadcast) that are waiting for the corresponding condition variable are woken up and return from the call to cnd_wait or cnd_timedwait. For example, the input task signals the drawing task that something in the game constellation has changed and the board should be redrawn:
155 } while (!(L->finished || feof(stdin)));
The mtx_t parameter to the wait-condition functions has an important role. The mutex must be held by the calling thread to the wait function. It is temporarily released during the wait, so other threads can do their job to assert the condition expression. The lock is reacquired just before returning from the wait call so then the critical data can safely be accessed without races.
Figure 18.3 shows a typical interaction between the input and draw threads, the mutex and the corresponding condition variable. It shows that six function calls are involved in the interaction: four for the respective critical sections and the mutex, and two for the condition variable.
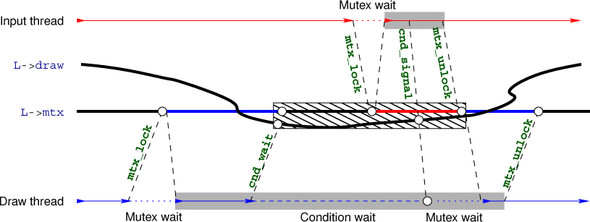
The coupling between a condition variable and the mutex in the wait call should be handled with care.
A condition variable can only be used simultaneously with one mutex.
But it is probably best practice to never change the mutex that is used with a condition variable.
Our example also shows that there can be many condition variables for the same mutex: we use our mutex with three different condition variables at the same time. This will be imperative in many applications, since the condition expressions under which threads will be accessing the same resource depend on their respective roles.
In situations where several threads are waiting for the same condition variable and are woken up with a call to cnd_broadcast, they will not wake up all at once, but one after another as they reacquire the mutex.
Similar to a mutex’s, C’s condition variables may bind precious system resources. So they must be initialized dynamically, and they should be destroyed at the end of their lifetime.
A cnd_t must be initialized dynamically.
A cnd_t must be destroyed at the end of its lifetime.
The interfaces for these are straightforward:
int cnd_init(cnd_t *cond); void cnd_destroy(cnd_t *cond);
Having just seen thread creation and joining in main, we may have the impression that threads are somehow hierarchically organized. But actually they are not: just knowing the ID of a thread, its thrd_t, is sufficient to deal with it. There is only one thread with exactly one special property.
Returning from main or calling exit terminates all threads.
If we want to terminate main after we have created other threads, we have to take some precautions so we do not terminate the other threads preliminarily. An example of such a strategy is given in the following modified version of B9’s main:
210 211 void B9_atexit(void) { 212 /* Puts the board in a nice final picture */ 213 L.iteration = L.last; 214 life_draw(&L); 215 life_destroy(&L); 216 } 217 218 int main(int argc, char* argv[argc+1]) { 219 /* Uses command-line arguments for the size of the board */ 220 size_t n0 = 30; 221 size_t n1 = 80; 222 if (argc > 1) n0 = strtoull(argv[1], 0, 0); 223 if (argc > 2) n1 = strtoull(argv[2], 0, 0); 224 /* Create an object that holds the game's data. */ 225 life_init(&L, n0, n1, M); 226 atexit(B9_atexit); 227 /* Creates four threads that operate on the same object and 228 discards their IDs */ 229 thrd_create(&(thrd_t){0}, update_thread, &L); 230 thrd_create(&(thrd_t){0}, draw_thread, &L); 231 thrd_create(&(thrd_t){0}, input_thread, &L); 232 /* Ends this thread nicely and lets the threads go on nicely */ 233 thrd_exit(0); 234 }
First, we have to use the function thrd_exit to terminate main. Other than a return, this ensures that the corresponding thread just terminates without impacting the other threads. Then, we have to make L a global variable, because we don’t want its life to end when main terminates. To arrange for the necessary cleanup, we also install an atexit handler. The modified control flow is shown in figure 18.4.
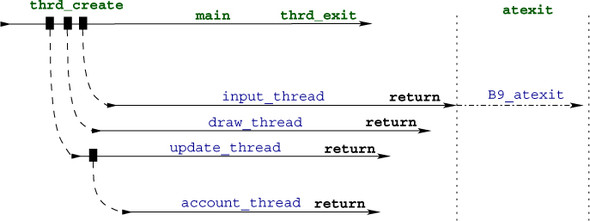
As a consequence of this different management, the four threads that are created are never actually joined. Each thread that is dead but is never joined eats up some resources that are kept until the end of the execution. Therefore, it is good coding style to tell the system that a thread will never be joined: we say that we detach the corresponding thread. We do that by inserting a call to thrd_detach at the beginning of the thread functions. We also start the account thread from there, and not from main as we did previously.
38 /* Nobody should ever wait for this thread. */ 39 thrd_detach(thrd_current()); 40 /* Delegates part of our job to an auxiliary thread */ 41 thrd_create(&(thrd_t){0}, account_thread, Lv); 42 life*restrict L = Lv;
There are six more functions that can be used to manage threads, of which we already met thrd_current, thrd_exit, and thrd_detach:
thrd_t thrd_current(void); int thrd_equal(thrd_t, thrd_t); _Noreturn void thrd_exit(int); int thrd_detach(thrd_t); int thrd_sleep(const struct timespec*, struct timespec*); void thrd_yield(void);
A running C program may have many more threads than it has processing elements at its disposal. Nevertheless, a runtime system should be able to schedule the threads smoothly by attributing time slices on a processor. If a thread actually has no work to do, it should not demand a time slice and should leave the processing resources to other threads that might need them. This is one of the main features of the control data structures mtx_t and cnd_t.
While blocking on mtx_t or cnd_t, a thread frees processing resources.
If this is not enough, there are two other functions that can suspend execution:
Can you implement a parallel algorithm for sorting using two threads that builds on your merge sort implementation (challenges 1 and 14)?
That is, a merge sort that cuts the input array in half and sorts each half in its own thread, and then merges the two halves sequentially as before. Use different sequential sorting algorithms as a base inside each of the two threads.
Can you generalize this parallel sorting to P threads, where P = 2k for k = 1, 2, 3, 4, where k is given on the command line?
Can you measure the speedup that you obtained as a result of your parallelization? Does it match the number of cores that your test platform has?