本章主要内容
net/http
标准库的使用方法
net/http
库提供HTTP服务的方法
在第2章中,我们看到了一个简单的网上论坛Web应用是由什么组件构成的,也了解到了这些组件是如何组织成一个Go Web应用的。虽然我们已经对构成Go Web应用的各个组件有了基本的了解,但关于这些组件还有很多值得深入的事情。在接下来的几章里,我们将更为深入地了解这些组件的细节,并详细地探讨这些组件是如何组合起来的。
本章和下一章将对Web应用的“大脑”(也就是负责接收和处理客户端请求的处理器)进行讨论。在本章中,我们将要学习的是如何使用Go语言去创建一个Web服务器,以及如何处理客户端发送的请求。
在进行Web应用开发的时候,使用成熟并且复杂的Web应用框架通常会使开发变得更加迅速和简便,但这也意味着开发者必须接受框架自身的一套约定和模式。虽然很多框架都认为自己提供的约定和模式是最佳实践(best practice),但是如果开发者没有正确地理解这些最佳实践,那么对最佳实践的应用就可能会发展为货物崇拜编程 (cargo cult programming):开发者如果不了解这些约定和模式的用法,就可能会在不必要甚至有害的情况下盲目地使用它们。
货物崇拜编程
第二次世界大战期间,盟军为了对战事提供支援,在太平洋的多个岛屿上设立了空军基地,以空投的方式向部队以及支援部队的岛民投送了大量生活用品以及军事设备,从而极大地改善了部队以及岛民的生活,岛民也因此第一次看到了人工生产的衣物、罐头食品以及其他物品。在战争结束之后,这些空军基地便被废弃了,货物空投自然也停止了。此时,岛民做了一件非常符合其本性的事情——他们把自己打扮成空管员、士兵以及水手,使用机场上的指挥棒挥舞着着陆信号,进行地面阅兵演习,试图让飞机继续空投货物,货物崇拜一词也因此而诞生。
尽管货物崇拜程序员并没有像岛民一样挥舞指挥棒,但他们却大量地复制和粘贴从StackOverflow这类网站上找来的代码,这些代码虽然能够运行,但是他们却对这些代码的工作原理一点也不了解。这样做的结果是,他们通常无法扩展和修改这些代码。与此类似,货物崇拜程序员通常会在既不了解框架为什么使用特定的模式或约定,也不知道框架做了何种取舍的情况下,盲目地使用Web框架。
举个例子来说,因为HTTP是一种无连接协议(connection-less protocol),通过这种协议发送给服务器的请求对服务器之前处理过的请求一无所知,所以应用程序才会以cookie的方式在客户端实现数据持久化,并以会话的方式在服务器上实现数据持久化,而不了解这一点的人是很难理解为什么要在不同连接之间使用cookie和会话实现信息持久化的。为了降低使用cookie和会话带来的复杂性,Web应用框架通常都会提供一个统一的接口(uniform interface),用于在连接之间实现持久化。这样做的结果是,很多新手程序员都会想当然地假设在连接之间进行持久化唯一要做的就是使用框架提供的接口。但是由于这类接口通常都是根据框架自身的习惯制定的,因此不同框架提供的接口可能会有所不同。更糟糕的是,不同的框架可能会提供一些名字相同的接口,但是这些同名接口之间的实现却又千差万别、各不相同,因此给开发者带来不必要的困惑。通过这个例子可以看出,使用框架进行Web应用开发意味着将框架与应用进行绑定,之后无论是将应用迁移至另一个框架,还是对应用进行扩展,又或者为应用添加新的特性,都需要对框架本身有深入的了解,在某些情况下可能还需要对框架进行定制。
本书的目的并不是让大家抛弃框架、约定和模式——一个好的框架通常是快速构建可扩展且健壮的Web应用的最好方法,但理解那些隐藏在框架之下的底层概念和基础设施也是非常重要的。只要对框架的实现原理有了正确的认识,我们就可以更加清晰地了解到这些约定和模式是如何形成的,从而避免陷阱、理清思路,不再盲目地使用模式。
对Go语言来说,隐藏在框架之下的通常是net/http
和html/template
这两个标准库,本章和接下来的第4章将介绍net/http
库,而之后的第5章将介绍html/template
库。
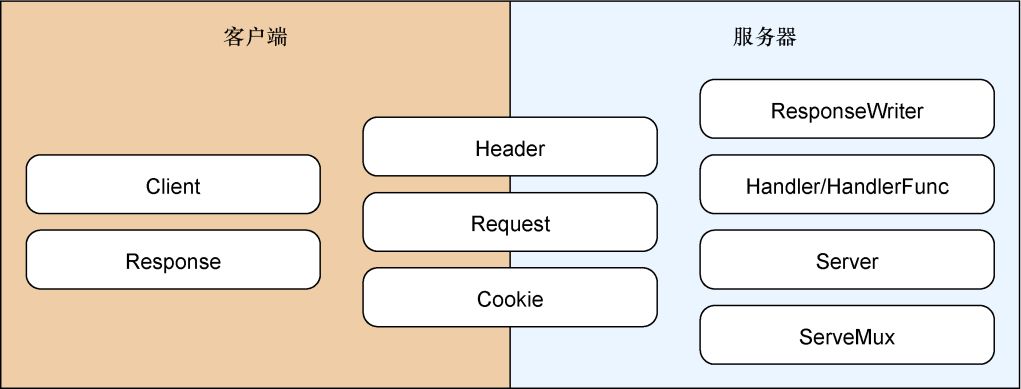
如图3-1所示,net/http
标准库可以分为客户端和服务器两个部分,库中的结构和函数有些只支持客户端和服务器这两者中的一个,而有些则同时支持客户端和服务器:
Client
、Response
、Header
、Request
和
Cookie
对客户端
进行支持;
Server
、ServeMux
、Handler/HandleFunc
、ResponseWriter
、Header
、Request
和
Cookie
则对
服务器
进行支持。本章接下来将会展示如何把net/http
标准库用作服务器以及如何使用Go语言接收客户端发送的HTTP请求。在之后的第4章,我们还会继续使用net/http
标准库,但焦点会放在如何处理请求上面。
在本书中,我们主要关注的是如何使用net/http
标准库的服务器功能而非客户端功能。
图3-1 net/http
标准库的各个组成部分
如图3-2所示,通过net/http
标准库,我们可以启动一个HTTP服务器,然后让这个服务器接收请求并向请求返回响应。除此之外,net/http
标准库还提供了一个连接多路复用器(multiplexer)的接口以及一个默认的多路复用器。
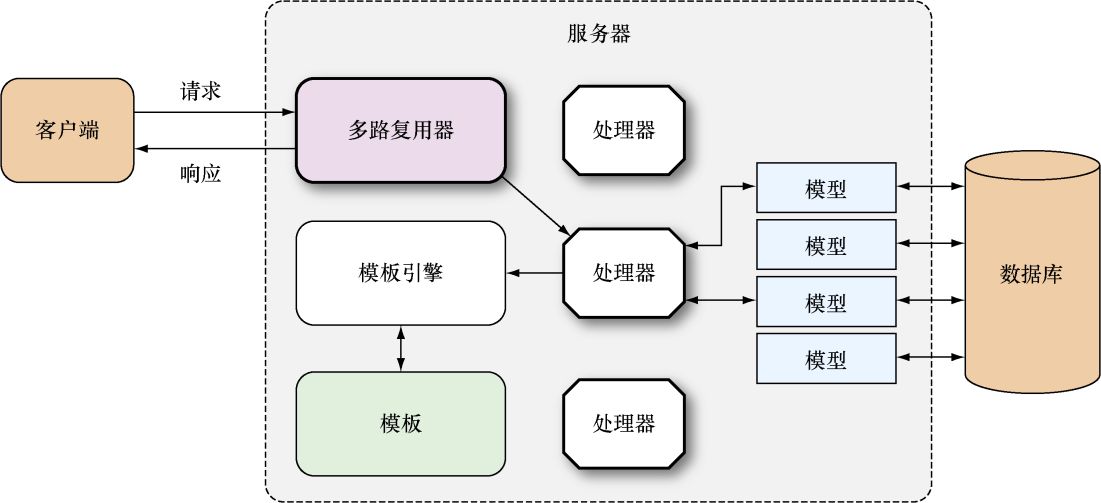
图3-2 通过Go服务器处理请求
跟其他编程语言里面的绝大多数标准库不一样,Go提供了一系列用于创建Web服务器的标准库。正如代码清单3-1所示,创建一个服务器的步骤非常简单,只要调用ListenAndServe
并传入网络地址以及负责处理请求的处理器(handler)作为参数就可以了。如果网络地址参数为空字符串,那么服务器默认使用80端口进行网络连接;如果处理器参数为nil
,那么服务器将使用默认的多路复用器DefaultServeMux
。
代码清单3-1 最简单的Web服务器
package main
import (
"net/http"
)
func main() {
http.ListenAndServe("", nil)
}
用户除了可以通过ListenAndServe
的参数对服务器的网络地址和处理器进行配置之外,还可以通过Server
结构对服务器进行更详细的配置,其中包括为请求读取操作设置超时时间、为响应写入操作设置超时时间以及为Server
结构设置错误日志记录器等。
代码清单3-2和代码清单3-1的作用基本上是相同的,它们之间的唯一区别在于代码清单3-2可以通过Server
结构对服务器进行更多的配置。
代码清单3-2 带有附加配置的Web服务器
package main
import (
"net/http"
)
func main() {
server := http.Server{
Addr: "127.0.0.1:8080",
Handler: nil,
}
server.ListenAndServe()
}
代码清单3-3展示了Server
结构所有可选的配置选项。
代码清单3-3 Server
结构的配置选项
type Server struct {
Addr string
Handler Handler
ReadTimeout time.Duration
WriteTimeout time.Duration
MaxHeaderBytes int
TLSConfig *tls.Config
TLSNextProto map[string]func(*Server, *tls.Conn, Handler)
ConnState func(net.Conn, ConnState)
ErrorLog *log.Logger
}
当客户端和服务器需要共享密码或者信用卡信息这样的私密信息时,大多数网站都会使用HTTPS对客户端和服务器之间的通信进行加密和保护。在一些情况下,这种保护甚至是强制性的。比如说,如果一个网站提供了信用卡支付功能,那么按照支付卡行业数据安全标准(Payment Card Industry Data Security Standard),这个网站就必须对客户端和服务器之间的通信进行加密。像Gmail和Facebook这样带有隐私性质的网站甚至在整个网站上都启用了HTTPS。如果你打算开发一个网站,而这个网站又需要提供用户登录功能,那么你也需要在这个网站上启用HTTPS。
HTTPS实际上就是将HTTP通信放到SSL之上进行。通过使用ListenAndServeTLS
函数,我们可以让之前展示过的简单Web应用也提供HTTPS服务,代码清单3-4展示了具体的实现代码。
代码清单3-4 通过HTTPS提供服务
package main
import (
"net/http"
)
func main() {
server := http.Server{
Addr: "127.0.0.1:8080",
Handler: nil,
}
server.ListenAndServeTLS("cert.pem", "key.pem")
}
这段代码中的cert.pem
文件是SSL证书
,而key.pem
则是服务器的私钥
(private key)。在生产环境中使用的SSL证书需要通过VeriSign、Thawte或者Comodo SSL这样的CA取得,但如果是出于测试目的才使用证书和私钥,那么使用自行生成的证书就可以了。生成证书的办法有很多种,其中一种就是使用Go标准库中的crypto
包群(library group)。
SSL、TLS和HTTPS
SSL(Secure Socket Layer,安全套接字层)是一种通过公钥基础设施(Public Key Infrastructure,PKI)为通信双方提供数据加密和身份验证的协议,其中通信的双方通常是客户端和服务器。SSL最初由Netscape公司开发,之后由IETF(Internet Engineering Task Force,互联网工程任务组)接手并将其改名为TLS(Transport Layer Security,传输层安全协议)。HTTPS,即SSL之上的HTTP,实际上就是在SSL/TLS连接的上层进行HTTP通信。
HTTPS需要使用SSL/TLS证书来实现数据加密以及身份验证(本书使用SSL证书这一名称,因为它更常用)。SSL证书存储在服务器之上,它是一种使用X.509格式进行格式化的数据,这些数据包含了公钥以及其他一些相关信息。为了保证证书的可靠性,证书一般由证书分发机构(Certificate Authority,CA)签发。服务器在接收到客户端发送的请求之后,会将证书和响应一并返回给客户端,而客户端在确认证书的真实性之后,就会生成一个随机密钥(random key),并使用证书中的公钥对随机密钥进行加密,此次加密产生的对称密钥(symmetric key)就是客户端和服务器在进行通信时,负责对通信实施加密的实际密钥(actual key)。
虽然我们不会在生产环境中使用自行生成的证书和私钥,但了解SSL证书和私钥的生成方法,并学会如何在开发和测试的过程中使用证书和私钥,也是一件非常有意义的事情。代码清单3-5展示了生成SSL证书以及服务器私钥的具体代码。
代码清单3-5 生成个人使用的SSL证书以及服务器私钥
package main
import (
"crypto/rand"
"crypto/rsa"
"crypto/x509"
"crypto/x509/pkix"
"encoding/pem"
"math/big"
"net"
"os"
"time"
)
func main() {
max := new(big.Int).Lsh(big.NewInt(1), 128)
serialNumber, _ := rand.Int(rand.Reader, max)
subject := pkix.Name{
Organization: []string{"Manning Publications Co."},
OrganizationalUnit: []string{"Books"},
CommonName: "Go Web Programming",
}
template := x509.Certificate{
SerialNumber: serialNumber,
Subject: subject,
NotBefore: time.Now(),
NotAfter: time.Now().Add(365 * 24 * time.Hour),
KeyUsage: x509.KeyUsageKeyEncipherment | x509.KeyUsageDigitalSignature,
ExtKeyUsage: []x509.ExtKeyUsage{x509.ExtKeyUsageServerAuth},
IPAddresses: []net.IP{net.ParseIP("127.0.0.1")},
}
pk, _ := rsa.GenerateKey(rand.Reader, 2048)
derBytes, _ := x509.CreateCertificate(rand.Reader, &template,
➥&template, &pk.PublicKey, pk)
certOut, _ := os.Create("cert.pem")
pem.Encode(certOut, &pem.Block{Type: "CERTIFICATE", Bytes: derBytes})
certOut.Close()
keyOut, _ := os.Create("key.pem")
pem.Encode(keyOut, &pem.Block{Type: "RSA PRIVATE KEY", Bytes:
➥x509.MarshalPKCS1PrivateKey(pk)})
keyOut.Close()
}
生成SSL证书和密钥的步骤并不是特别复杂。因为SSL证书实际上就是一个将扩展密钥用法(extended key usage)设置成了服务器身份验证操作的X.509证书,所以程序在生成证书时使用了crypto/x509
标准库。此外,因为创建证书需要用到私钥,所以程序在使用私钥成功创建证书之后,会将私钥单独保存在一个存放服务器私钥的文件里面。
让我们来仔细分析一下代码清单3-5中的主要代码吧。首先,程序使用一个Certificate
结构来对证书进行配置:
template := x509.Certificate{
SerialNumber: serialNumber,
Subject: subject,
NotBefore: time.Now(),
NotAfter: time.Now().Add(365*24*time.Hour),
KeyUsage: x509.KeyUsageKeyEncipherment | x509.KeyUsageDigitalSignature,
ExtKeyUsage: []x509.ExtKeyUsage{x509.ExtKeyUsageServerAuth},
IPAddresses: []net.IP{net.ParseIP("127.0.0.1")},
}
结构中的证书序列号(SerialNumber
)用于记录由CA分发的唯一号码,为了能让我们的Web应用运行起来,程序在这里生成了一个非常长的随机整数来作为证书序列号。之后,程序创建了一个专有名称(distinguished name),并将它设置成了证书的标题(subject)。此外,程序还将证书的有效期设置成了一年,而结构中KeyUsage
字段和ExtKeyUsage
字段的值则表明了这个X.509证书是用于进行服务器身份验证操作的。最后,程序将证书设置成了只能在IP地址127.0.0.1之上运行。
SSL证书
X.509是国际电信联盟电信标准化部门(ITU-T)为公钥基础设施制定的一个标准,这个标准包含了公钥证书的标准格式。
一个X.509证书(简称SSL证书)实际上就是一个经过编码的ASN.1(Abstract Syntax Notation One,抽象语法表示法/1)格式的电子文档。ASN.1既是一个标准,也是一种表示法,它描述了表示电信以及计算机网络数据的规则和结构。
X.509证书可以使用多种格式编码,其中一种编码格式是BER(Basic Encoding Rules,基本编码规则)。BER格式指定了一种自解释并且自定义的格式用于对ASN.1数据结构进行编码,而DER格式则是BER的一个子集。DER只提供了一种编码ASN.1值的方法,这种方法被广泛地应用于密码学当中,尤其是对X.509证书进行加密。
SSL证书可以以多种不同的格式保存,其中一种是PEM(Privacy Enhanced Email,隐私增强邮件)格式,这种格式会对DER格式的X.509证书实施Base64编码,并且这种格式的文件都以
-----BEGIN CERTIFICATE-----开头,以-----END CERTIFICATE-----结尾(除了用作文件格式之外,PEM和此处讨论的SSL证书关系并不大)。
在此之后,程序通过调用crypto/rsa
标准库中的GenerateKey
函数生成了一个RSA私钥:
pk, _ := rsa.GenerateKey(rand.Reader, 2048)
程序创建的RSA私钥的结构里面包含了一个能够公开访问的公钥(public key),这个公钥在使用x509.CreateCertificate
函数创建SSL证书的时候就会用到:
derBytes, _ := x509.CreateCertificate(rand.Reader, &template, &template,
➥&pk.PublicKey, pk)
CreateCertificate
函数接受Certificate
结构、公钥和私钥等多个参数,创建出一个经过DER编码格式化的字节切片。后续代码的意图也非常简单明了,它们首先使用encoding/pem
标准库将证书编码到cert.pem
文件里面:
certOut, _ := os.Create("cert.pem")
pem.Encode(certOut, &pem.Block{Type: "CERTIFICATE", Bytes: derBytes})
certOut.Close()
然后继续以PEM编码的方式把之前生成的密钥编码并保存到key.pem文件
里面:
keyOut, _ := os.Create("key.pem")
pem.Encode(keyOut, &pem.Block{Type: "RSA PRIVATE KEY", Bytes:
➥x509.MarshalPKCS1PrivateKey(pk)})
keyOut.Close()
最后需要提醒的是,如果证书是由CA签发的,那么证书文件中将同时包含服务器签名以及CA签名,其中服务器签名在前,CA签名在后。
在前面的内容中,我们启动了一个Web服务器,但是因为这个服务器尚未实现任何功能,所以现在访问这个服务器只会获得一个404 HTTP响应代码。出现这一问题的原因在于我们尚未为服务器编写任何处理器,所以服务器的多路复用器在接收到请求之后找不到任何处理器来处理请求,因此它只能返回一个404响应。为了让服务器能够产生实际的行为,我们需要为之编写处理器。
前面的第1章和第2章曾经简单地介绍过处理器以及处理器函数,现在是时候详细地谈谈它们的定义了。在Go语言中,一个处理器就是一个拥有ServeHTTP
方法的接口,这个ServeHTTP
方法需要接受两个参数:第一个参数是一个ResponseWriter
接口,而第二个参数则是一个指向Request
结构的指针。换句话说,任何接口只要拥有一个ServeHTTP
方法,并且该方法带有以下签名(signature),那么它就是一个处理器:
ServeHTTP(http.ResponseWriter, *http.Request)
现在,让我们暂时离题一下,回答一个在阅读本章时可能会出现在你脑海里面的问题:既然ListenAndServe
接受的第二个参数是一个处理器,那么为何它的默认值却是多路复用器DefaultServeMux
呢?
这是因为DefaultServeMux
多路复用器是ServeMux
结构的一个实例,而后者也拥有上面提到的ServeHTTP
方法,并且这个方法的签名与成为处理器所需的签名完全一致。换句话说,DefaultServeMux
既是ServeMux
结构的实例,也是Handler
结构的实例,因此DefaultServeMux
不仅是一个多路复用器,它还是一个处理器。不过DefaultServeMux
处理器和其他一般的处理器不同,DefaultServeMux
是一个特殊的处理器,它唯一要做的就是根据请求的URL将请求重定向到不同的处理器。在了解了这些知识之后,我们现在只需要自行编写一个处理器并使用它去代替默认的多路复用器,就可以让服务器正常地对客户端进行响应了,具体如代码清单3-6所示。
代码清单3-6 处理请求
package main
import (
"fmt"
"net/http"
)
type MyHandler struct{}
func (h *MyHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hello World!")
}
func main() {
handler := MyHandler{}
server := http.Server{
Addr: "127.0.0.1:8080",
Handler: &handler,
}
server.ListenAndServe()
}
现在,只要按照2.7节介绍过的方法启动服务器,并使用浏览器访问地址http://localhost:8080/,我们就可以在浏览器里面看到Hello World响应了。
有趣的是,如果我们使用浏览器访问http://localhost:8080/anything/at/all,同样会看到相同的Hello World响应。造成这个问题的原因非常明显:在代码清单3-6中,程序创建了一个处理器并将它与服务器进行了绑定,以此来代替原本正在使用的默认多路复用器。这意味着服务器不会再通过URL匹配来将请求路由至不同的处理器,而是直接使用同一个处理器来处理所有请求,因此无论浏览器访问什么地址,服务器返回的都是同样的Hello World响应。
这也是我们在Web应用中使用多路复用器的原因:对某些特殊用途的服务器来说,只使用一个处理器也许就可以很好地完成工作了,但是在大部分情况下,我们还是希望服务器可以根据不同的URL请求返回不同的响应,而不是一成不变地只返回一种响应。
在大部分情况下,我们并不希望像代码清单3-6那样,使用一个处理器去处理所有请求,而是希望使用多个处理器去处理不同的 URL。为了做到这一点,我们不再在Server
结构的Handler
字段中指定处理器,而是让服务器使用默认的DefaultServeMux
作为处理器,然后通过http.Handle
函数将处理器绑定至DefaultServeMux
。需要注意的是,虽然Handle
函数来源于http
包,但它实际上是ServeMux
结构的方法:这些函数是为了操作便利而创建的函数,调用它们等同于调用DefaultServeMux
的某个方法。比如说,调用http.Handle
实际上就是在调用DefaultServeMux
的Handle
方法。
在代码清单3-7中,程序创建了两个处理器,并将它们与各自的URL进行了绑定。现在,访问地址http://localhost:8080/hello将会看到“Hello!”,而访问地http://localhost:8080/world则会看到“World!”。
代码清单3-7 使用多个处理器对请求进行处理
package main
import (
"fmt"
"net/http"
)
type HelloHandler struct{}
func (h *HelloHandler) ServeHTTP (w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hello!")
}
type WorldHandler struct{}
func (h *WorldHandler) ServeHTTP (w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "World!")
}
func main() {
hello := HelloHandler{}
world := WorldHandler{}
server := http.Server{
Addr: "127.0.0.1:8080",
}
http.Handle("/hello", &hello)
http.Handle("/world", &world)
server.ListenAndServe()
}
上一小节对处理器进行了介绍,那么什么是处理器函数呢?处理器函数实际上就是与处理器拥有相同行为的函数:这些函数与ServeHTTP
方法拥有相同的签名,也就是说,它们接受ResponseWriter
和指向Request
结构的指针作为参数。代码清单3-8展示了如何在服务器中使用处理器函数。
代码清单3-8 使用处理器函数处理请求
package main
import (
"fmt"
"net/http"
)
func hello(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hello!")
}
func world(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "World!")
}
func main() {
server := http.Server{
Addr: "127.0.0.1:8080",
}
http.HandleFunc("/hello", hello)
http.HandleFunc("/world", world)
server.ListenAndServe()
}
处理器函数的实现原理是这样的:Go语言拥有一种HandlerFunc
函数类型,它可以把一个带有正确签名的函数f
转换成一个带有方法f
的Handler
。比如说,对下面这个hello
函数来说:
func hello(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hello!")
}
程序只需要执行以下代码:
helloHandler := HandlerFunc(hello)
就可以把helloHandler
设置成一个Handler
。如果你对此感到疑惑,那么不妨回顾一下之前展示过的接受处理器的服务器代码:
package main
import (
"fmt"
"net/http"
}
type HelloHandler struct{}
func (h*HelloHandler) ServeHTTP(w thhp.ResponseWriter, r *http.Request){
fmt.Fprintf(w, "Hello! ")
}
type WorldHandler struct{}
func (h *WorldHandler) ServeHTTP (w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w,"World!")
}
func main () {
hello := HelloHandler{}
world := WorldHandler{}
server := thhp.Server{
Addr: "127.0.0.1:8080",
}
http.Handle("/hello",&hello)
http.Handle("/world",&world)
server.ListenAndServe()
}
这个程序使用了以下这行代码来绑定URL地址/hello
和hello
函数:
http.Handle("/hello", &hello)
这行代码向我们展示了Handle
函数将一个处理器绑定至URL的具体方法。此外,在接受处理器函数的代码清单3-8中,HandleFunc
函数会将hello
函数转换成一个Handler
,并将它与DefaultServeMux
进行绑定,以此来简化创建并绑定Handler
的工作。换句话说,处理器函数只不过是创建处理器的一种便利的方法而已。代码清单3-9展示了http.HandleFunc
函数的具体定义。
代码清单3-9 http.HandleFunc
函数的源代码
func HandleFunc(pattern string, handler func(ResponseWriter, *Request)) {
DefaultServeMux.HandleFunc(pattern, handler)
}
而下面是ServeMux.HandleFunc
方法的定义:
func (mux *ServeMux) HandleFunc(pattern string, handler func(ResponseWriter,
*Request)) {
mux.Handle(pattern, HandlerFunc(handler))
}
注意这个方法是如何使用HandlerFunc
函数将传入的handler
函数转换成真正的处理器的。
虽然处理器函数能够完成跟处理器一样的工作,并且使用处理器函数的代码比使用处理器的代码更为整洁,但是处理器函数并不能完全代替处理器。这是因为在某些情况下,代码可能已经包含了某个接口或者某种类型,这时我们只需要为它们添加ServeHTTP
方法就可以将它们转变为处理器了,并且这种转变也有助于构建出更为模块化的Web应用。
尽管Go语言并不是一门函数式编程语言,但它也拥有一些函数式编程语言的特性,如函数类型、匿名函数和闭包。正如前面的代码所示,在Go语言里面,程序可以将一个函数传递给另一个函数,又或者通过标识符去引用一个具名函数。这意味着,程序可以像图3-3展示的那样,将函数f1
传递给另一个函数f2
,然后在函数f2
执行完某些操作之后调用f1
。
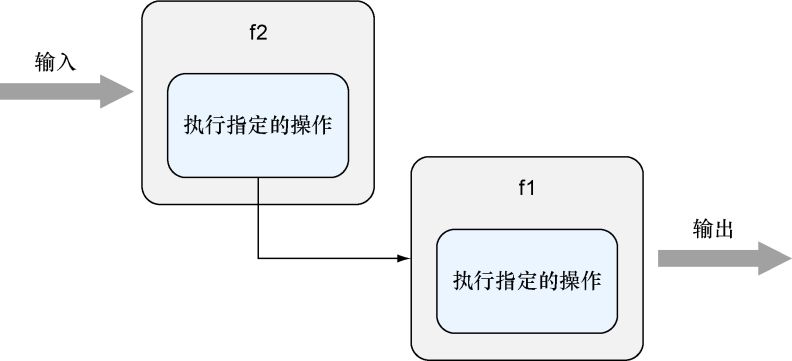
图3-3 串联起多个处理器
来看一个完整的例子:假设我们想要在每个处理器被调用时,在某个地方记录下相应的调用信息。为此,我们可以在处理器里面添加一些额外的代码,又或者像第2章那样,将这些记录代码重构成一个工具函数,然后让每个处理器都去调用这个工具函数。虽然实现上面提到的两种方法并不困难,但引入额外代码的做法会给程序的编写带来麻烦,并导致处理器需要包含与处理请求无关的代码。
诸如日志记录、安全检查和错误处理这样的操作通常被称为横切关注点 (cross-cutting concern),虽然这些操作非常常见,但是为了防止代码重复和代码依赖问题,我们又不希望这些操作和正常的代码搅和在一起。为此,我们可以使用串联 (chaining)技术分隔代码中的横切关注点。代码清单3-10展示了一个串联多个处理器的例子。
代码清单3-10 串联两个处理器函数
package main
import (
"fmt"
"net/http"
"reflect"
"runtime"
)
func hello(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hello!")
}
func log(h http.HandlerFunc) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
name := runtime.FuncForPC(reflect.ValueOf(h).Pointer()).Name()
fmt.Println("Handler function called - " + name)
h(w, r)
}
}
func main() {
server := http.Server{
Addr: "127.0.0.1:8080",
}
http.HandleFunc("/hello", log(hello))
server.ListenAndServe()
}
除处理器函数hello
之外,这个代码清单还包含了一个log
函数。log
函数接受一个HandlerFunc
类型的函数作为参数,然后返回另一个HandlerFunc
类型的函数作为值。因为hello
函数就是一个HandlerFunc
类型的函数,所以代码log(hello)
实际上就是将hello
函数发送至log
函数之内,换句话说,这段代码串联起了log
函数和hello
函数。
log
函数的返回值是一个匿名函数,因为这个匿名函数接受一个ResponseWriter
和一个Request
指针作为参数,所以它实际上也是一个HandlerFunc
。在匿名函数内部,程序首先会获取被传入的HandlerFunc
的名字,然后再调用这个HandlerFunc
。作为结果,如果我们使用浏览器访问地址http://localhost:8080/hello,那么浏览器页面将显示以下信息:
Handler function called – main.hello
就像搭积木一样,既然我们可以串联起两个函数,那么自然也可以串联起更多函数。串联多个函数可以让程序执行更多动作,这种做法有时候也称为管道处理 (pipeline processing),如图3-4所示。
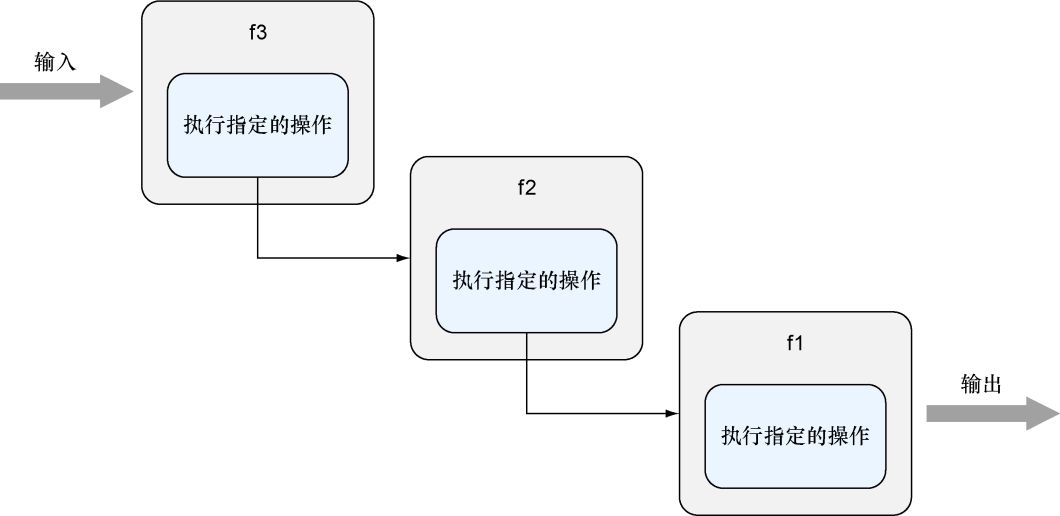
图3-4 串联更多处理器
举个例子,如果我们还有一个protect
函数,它会在调用传入的处理器之前验证用户的身份:
func protect(h http.HandlerFunc) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
. . . ❶
h(w, r)
}
}
❶ 为了节省篇幅,这里省略了一段用于检测用户登录情况的代码
那么我们只需要把protect
函数跟之前的函数串联在一起,就可以正常使用这个函数了:
http.HandleFunc("/hello", protect(log(hello)))
你可能已经注意到了,虽然我们一直讨论的都是如何串联处理器,但代码清单3-10实际上却是在串联处理器函数。不过正如代码清单3-11所示,串联处理器的方法实际上和串联处理器函数的方法是非常相似的。
代码清单3-11 串联多个处理器
package main
import (
"fmt"
"net/http"
)
type HelloHandler struct{}
func (h HelloHandler) ServeHTTP (w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hello!")
}
func log(h http.Handler) http.Handler {
return http.HandlerFunc (func(w http.ResponseWriter, r *http.Request) {
fmt.Printf("Handler called - %T\n", h)
h.ServeHTTP (w, r)
})
}
func protect(h http.Handler) http.Handler {
return http.HandlerFunc (func(w http.ResponseWriter, r *http.Request) {
. . . ❶
h.ServeHTTP (w, r)
})
}
func main() {
server := http.Server{
Addr: "127.0.0.1:8080",
}
hello := HelloHandler{}
http.Handle("/hello", protect(log(hello)))
server.ListenAndServe()
}
❶ 为了节省篇幅,这里省略了一段用于检测用户登录情况的代码
让我们来观察一下代码清单3-11和代码清单3-10有什么区别。代码清单3-11中的Hello Handler
在前面的代码清单中已经展示过,它跟代码清单3-10中的hello
函数一样,都位于串联链的末尾。至于log
函数则不再接受和返回HandlerFunc
类型的函数,而是接受并返回Handler
类型的处理器:
func log(h http.Handler) http.Handler {
return http.HandlerFunc (func(w http.ResponseWriter, r *http.Request) {
fmt.Printf("Handler called - %T\n", h)
h.ServeHTTP (w, r)
})
}
log
函数和protect
函数现在不再返回匿名函数,而是使用HandlerFunc
直接将匿名函数转换成一个Handler
,然后返回这个Handler
。程序现在也不再直接执行处理器函数了,而是调用处理器的ServeHTTP
函数。最后的一点变化是,程序现在绑定的是处理器而不是处理器函数:
hello := HelloHandler{}
http.Handle("/hello", protect(log(hello)))
除了以上提到的区别之外,两个程序的其余代码基本上都是相同的。
串联处理器和处理器函数是一种非常常见的惯用法,很多Web应用框架都使用了这一技术。
本章和前一章都对ServeMux
和DefaultServeMux
进行了介绍。ServeMux
是一个HTTP请求多路复用器,它负责接收HTTP请求并根据请求中的URL将请求重定向到正确的处理器,如图3-5所示。
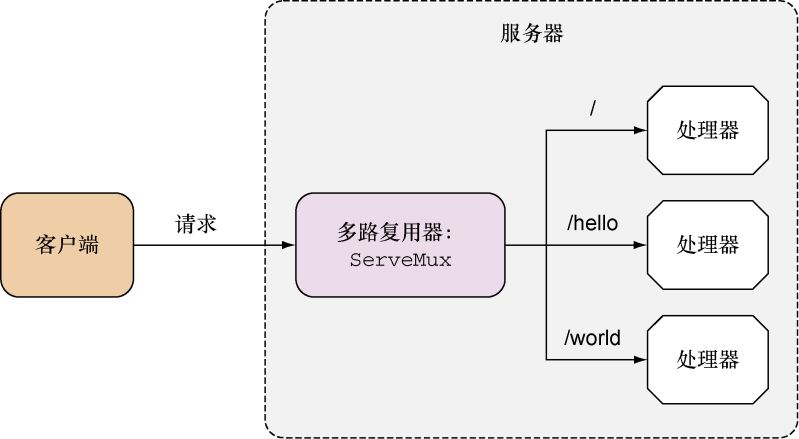
图3-5 通过多路复用器将请求转发给各个处理器
ServeMux
结构包含了一个映射,这个映射会将URL映射至相应的处理器。正如之前所说,因为ServeMux
结构也实现了ServeHTTP
方法,所以它也是一个处理器。当ServeMux
的ServeHTTP
方法接收到一个请求的时候,它会在结构的映射里面找出与被请求URL最为匹配的URL,然后调用与之相对应的处理器的ServeHTTP
方法,如图3-6所示。
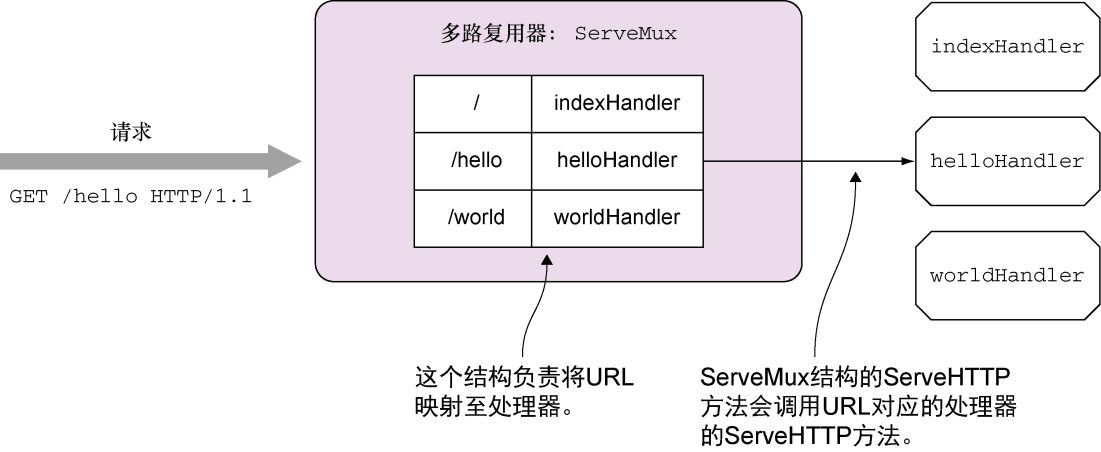
图3-6 多路复用器的工作原理
在介绍完ServeMux
之后,让我们来了解一下DefaultServeMux
。因为ServeMux
是一个结构而不是一个接口,所以DefaultServeMux
并不是ServeMux
的实现。Default-ServeMux
实际上是ServeMux
的一个实例,并且所有引入了net/http
标准库的程序都可以使用这个实例。当用户没有为Server
结构指定处理器时,服务器就会使用DefaultServeMux
作为ServeMux
的默认实例。
此外,因为ServeMux
也是一个处理器
,所以用户也可以在有需要的情况下对其实例实施处理器串联。
在上面的几个例子中,被请求的URL /hello
完美地匹配了与多路复用器绑定的URL,但如果浏览器访问的是/random
或者/hello/there
,那么服务器又会返回什么响应呢?
这个问题的答案跟我们绑定URL的方法有关:如果我们像图3-6那样绑定根URL(/
),那么匹配不成功的URL将会根据URL的层级进行下降,并最终降落在根URL之上。当浏览器访问/random
的时候,因为服务器无法找到负责处理这个URL的处理器,所以它会把这个URL交给根URL的处理器处理(对于图中所示的例子来说,就是使用indexHandler
来处理这个URL)。
那么服务器又是如何处理/hello/there
的呢?根据最小惊讶原则
(The Principle of Least Surprise),因为程序已经为/hello
绑定了处理器,所以在默认情况下,程序似乎应该使用helloHandler
处理/hello/there
。但是对图3-6所示的例子来说,服务器实际上会使用indexHandler
去处理对/hello/there
的请求。
最小惊讶原则
最小惊讶原则,也称最小意外原则,是设计包括软件在内的一切事物的一条通用规则,它指的是我们在进行设计的时候,应该做那些合乎常理的事情,使事物的行为总是显而易见、始终如一并且合乎情理。
举个例子,如果我们在一扇门的旁边放置一个按钮,那么人们就会认为这个按钮与这扇门有关,比如,按下按钮门铃会响或者门会自动打开,等等。但是,如果这个按钮被按下时会关掉走廊的灯光,它就违反了最小惊讶原则,因为这一行为不符合人们对这个按钮的预期。
产生这种行为的原因在于程序在绑定helloHandler
时使用的URL是/hello
而不是/hello/
。如果被绑定的URL不是以/
结尾,那么它只会与完全相同的URL匹配;但如果被绑定的URL以/
结尾,那么即使请求的URL只有前缀部分与被绑定URL相同,ServeMux
也会认定这两个URL是匹配的。
这也就是说,如果与helloHandler
处理器绑定的URL是/hello/
而不是/hello
,那么当浏览器请求/hello/there
的时候,服务器在找不到与之完全匹配的处理器时,就会退而求其次,开始寻找能够与/hello/
匹配的处理器,并最终找到helloHandler
处理器。
因为创建一个处理器和多路复用器唯一需要做的就是实现ServeHTTP
方法,所以通过自行创建多路复用器来代替net/http
包中的ServeMux
是完全可行的,并且目前市面上已经出现了很多第三方的多路复用器可供使用,比如,Gorilla Toolkit(www.gorillatoolkit.org)就是一个非常优秀的第三方多路复用器包,它提供了mux
和pat
这两个工作方式非常不同的多路复用器,而本节将要介绍的则是另一个高效的轻量级第三方多路复用器——HttpRouter。
ServeMux
的一个缺陷是无法使用变量实现URL模式匹配。虽然在浏览器请求/threads
的时候,使用ServeMux
可以很好地获取并显示论坛中的所有帖子,但如果浏览器请求的是/thread/123
,那么要获取并显示论坛里面ID为123的帖子就会变得非常困难。程序必须对URL进行语法分析才能提取出URL当中的帖子ID。此外,因为受ServeMux
实现URL模式匹配的方式所限,如果我们想要通过/thread/123/post/456
这样的URL从ID为123的帖子中获取ID为456的回复,就必须在程序里面进行大量复杂的语法分析,并因此给程序带来额外的复杂度。
与ServeMux
不同,HttpRouter
包并没有上面提到的这些限制。本节将对HttpRouter
包最重要的一部分特性进行介绍,关于这个包的更详细的说明可以在它的文档页面里面看到:https://github.com/julienschmidt/httprouter。代码清单3-12展示了一个使用HttpRouter实现的服务器。
代码清单3-12 使用HttpRouter实现的服务器
package main
import (
"fmt"
"github.com/julienschmidt/httprouter"
"net/http"
)
func hello(w http.ResponseWriter, r *http.Request, p httprouter.Params) {
fmt.Fprintf(w, "hello, %s!\n", p.ByName("name"))
}
func main() {
mux := httprouter.New()
mux.GET("/hello/:name", hello)
server := http.Server{
Addr: "127.0.0.1:8080",
Handler: mux,
}
server.ListenAndServe()
}
这个程序中的大部分代码都和之前展示过的代码一样,只是涉及多路复用器的部分代码跟之前有所不同。在这段代码里,程序通过调用New
函数来创建一个多路复用器:
mux := httprouter.New()
这个程序不再使用HandleFunc
绑定处理器函数,而是直接把处理器函数与给定的HTTP方法进行绑定:
mux.GET("/hello/:name", hello)
这段代码会把给定URL的GET
方法与hello
处理器函数进行绑定,当浏览器向这个URL发送GET
请求时,hello
函数就会被调用,但如果浏览器向这个URL发送除GET
请求之外的其他请求,hello
函数则不会被调用。需要注意的是,被绑定的URL包含了具名参数
(named parameter),这些具名参数会被URL中的具体值所代替,并且程序可以在处理器里面获取这些值。
跟之前的处理器函数相比,现在的hello
处理器函数也发生了变化,它不再接受两个参数,而是接受3个参数。其中第三个参数Params
就包含了之前提到的具名参数,具名参数的值可以在处理器内部通过ByName
方法获取:
func hello(w http.ResponseWriter, r *http.Request, p httprouter.Params) {
fmt.Fprintf(w, "hello, %s!\n", p.ByName("name"))
}
程序的最后一个变化是它不再使用默认的DefaultServeMux
,而是通过将HttpRouter传递给Server
结构来使用这个多路复用器:
server := http.Server{
Addr: "127.0.0.1:8080",
Handler: mux,
}
server.ListenAndServe()
现在,如果我们在终端上执行go build
命令,那么编译器将返回一个错误:
$ go build
server.go:5:5: cannot find package "github.com/julienschmidt/httprouter" in
any of:
/usr/local/go/src/github.com/julienschmidt/httprouter (from $GOROOT)
/Users/sausheong/gws/src/github.com/julienschmidt/httprouter (from $GOPATH)
出现这个错误的原因在于,我们虽然指定了HttpRoter库,但这个第三方库在我们的电脑上并不存在,得益于Go语言强大且易用的包管理系统,我们只需要执行以下命令就可以解决这个问题了:
$ go get github.com/julienschmidt/httprouter
在电脑连接了网络的情况下,这个命令会从HttpRouter的GitHub主页上下载HttpRouter包的源代码,并将其存储到$GOPATH/src
目录中。在此之后,当我们再次执行go build
命令尝试编译代码清单3-12所示的服务器时,编译器就会导入HttpRouter的代码,并对整个服务器进行编译。
在本章的最后,让我们来了解一下如何使用HTTP/2构建本章介绍的Web服务器。
本书在第1章已经对HTTP/2做过简单的介绍,并且提到过在1.6或以上版本的Go语言中,如果使用HTTPS模式启动服务器,那么服务器将默认使用HTTP/2。但是,在默认情况下,版本低于1.6版本的Go语言将不会安装http2
包,因此用户需要通过手动执行以下命令来获取这个包:
go get "golang.org/x/net/http2"
为了让代码清单3-6中构建的Web服务器用上HTTP/2,我们需要给这个服务器导入http2
包,并通过添加一些代码行来让服务器打开对HTTP/2的支持。为了做到这一点,我们需要调用http2
包中的ConfigureServer
方法,并将服务器配置传递给它,修改后的服务器代码如代码清单3-13所示。
代码清单3-13 启用HTTP/2
package main
import (
"fmt"
"golang.org/x/net/http2"
"net/http"
)
type MyHandler struct{}
func (h *MyHandler) ServeHTTP (w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hello World!")
}
func main() {
handler := MyHandler{}
server := http.Server{
Addr: "127.0.0.1:8080",
Handler: &handler,
}
http2.ConfigureServer(&server, &http2.Server{})
server.ListenAndServeTLS("cert.pem", "key.pem")
}
现在,我们只要执行以下代码就可以启动这个打开了HTTP/2功能的Web服务器了:
go run server.go
为了检查服务器是否运行在HTTP/2模式之下,我们可以使用cURL对服务器进行检查。因为cURL在很多平台上都是可用的,所以本书会经常使用它作为检测工具,因此现在是时候来学习一下如何使用cURL了。
cURL
cURL是一个命令行工具,它可以获取指定URL上的文件,又或者向指定的URL发送文件。cURL支持数量庞大的常用互联网协议,其中就包括HTTP和HTTPS。cURL默认安装在包括OS X在内的很多Unix变种之上,并且它同样可以在Windows系统上使用。手动下载和安装cURL的方法可以通过页面http://curl.haxx.se/download.html看到。
cURL从7.43.0版本开始支持HTTP/2,用户在发送请求的时候,只需要打开--http2
标志(flag)就可以发送HTTP/2请求了。此外,为了让cURL能够支持HTTP/2,用户还必须将cURL与nghttp2
这个提供HTTP/2支持的C语言库进行链接(link)。在撰写本节的时候,包括OS X平台在内的很多默认的cURL实现都还没有提供对HTTP/2的支持,因此我们可能需要重新编译cURL,将它与nghttp2
库进行链接,然后用编译后的新版cURL代替原有的cURL。
在完成重新编译cURL的工作之后,我们可以使用以下命令去检查代码清单3-13展示的Web应用是否启用了HTTP/2:
curl -I --http2 --insecure https://localhost:8080/
在默认情况下,cURL在以HTTP/2形式访问一个Web应用的时候,会对应用的证书进行验证,并在验证无法通过时拒绝访问。因为我们的Web应用使用的是自行创建的证书和密钥,它们默认是无法通过这一验证的,所以上面的命令在调用cURL的时候使用了insecure
标志,这个标志会让cURL强制接受我们创建的证书,从而使访问可以顺利进行。
如果一切顺利,cURL将返回以下输出:
HTTP/2.0 200
content-type:text/plain; charset=utf-8
content-length:12
date:Mon, 15 Feb 2016 05:33:01 GMT
本章虽然详细介绍了如何接收HTTP请求,但是并没有具体地说明如何处理接收到的请求,以及如何向客户端返回响应。虽然处理器和处理器函数是使用Go编写Web应用的关键,但如何处理请求以及如何发送响应才是Web应用真正安身立命之所在。在接下来的一章中,我们将深入学习请求和响应的细节,了解如何从请求中提取信息,以及如何通过响应传递信息。
net/http
和
html/template
,这些标准库可以用于构建Web应用。
net/http
标准库可以将HTTP通信放到SSL之上进行,也就是通过HTTPS方式创建出更为安全的通信连接。
ServeHTTP
方法的结构,其中
ServeHTTP
方法需要接收两个参数:第一个参数是一个
ResponseWriter
接口,而第二个参数则是一个指向
Request
结构的指针。
ServeHTTP
方法拥有相同的签名。
,
ServeMux就是一个HTTP请求多路复用器,它接受HTTP请求并根据请求中的URL将请求重定向到正确的处理器。
DefaultServeMux
是
ServeMux
的一个公开的实例,这个实例会被用作默认的多路复用器。
net/http
标准库默认支持HTTP/2。版本低于1.6的Go语言如果想要获得HTTP/2支持,就需要手动添加
http2
包。