图11-1 7个值的序列(容量为16)
序列 包含N个值,分别关联到整数索引0到N-1(当N为正值时)。空序列不包含任何值。类似数组,序列中的值可通过索引访问,还可以从序列的两端添加或删除值。序列可根据需要自动扩展,以容纳其内容。其中的值都是指针。
序列是本书中最有用的ADT之一。尽管序列的规格相对简单,但可以用作数组、链表、栈、队列和双端队列,实现这些数据结构的ADT所需的设施通常都包含在序列中。序列可以看作前一章描述的动态数组的更抽象版本。序列将簿记信息和调整大小的相关细节隐藏到其实现中。
序列是Seq接口中定义的不透明指针类型的实例:
〈seq.h 〉≡ #ifndef SEQ_INCLUDED #define SEQ_INCLUDED #define T Seq_T typedef struct T *T; 〈exported functions 123〉 #undef T #endif
向该接口中任何例程传递的T值为NULL,都是已检查的运行时错误。
序列通过下列函数创建:
〈exported functions
123〉≡
extern T Seq_new(int hint);
extern T Seq_seq(void *x, ...);
Seq_new创建并返回一个空序列。hint是对新序列将包含值的最大数目的估计。如果该数值是未知的,可用0作为hint,以创建一个较小的序列。无论hint值如何,序列都会根据需要扩展以容纳其内容。传递负的hint值,是一个已检查的运行时错误。
Seq_seq创建并返回一个序列,用函数的非NULL指针参数来初始化序列中的值。参数列表结束于第一个NULL指针参数。因而
Seq_T names;
...
names = Seq_seq("C", "ML", "C++", "Icon", "AWK", NULL);
将创建一个包含五个值的序列,并将其赋值给names。参数列表中的值将关联到索引0~4。Seq_seq的参数列表的可变部分传递的指针假定为void指针,因此在传递char或void以外的指针时,程序员必须提供转换,参见7.1节。Seq_new和Seq_seq可能引发Mem_Failed异常。
〈exported functions
123〉+≡
extern void Seq_free(T *seq);
释放序列*seq并将*seq清零。如果seq或*seq是NULL指针,则造成已检查的运行时错误。
〈exported functions
123〉+≡
extern int Seq_length(T seq);
该函数返回序列seq中的值的数目。
N值序列中的各个值,分别关联到索引0到N-1。这些值通过下列函数访问:
〈exported functions
123〉+≡
extern void *Seq_get(T seq, int i);
extern void *Seq_put(T seq, int i, void *x);
Seq_get返回seq中的第i个值。Seq_put将第i个值改为x,并返回先前的值。i等于或大于N将造成已检查的运行时错误。Seq_get和Seq_put可以在常数时间内访问第i个值。
向序列两端添加值,即可扩展序列:
〈exported functions
123〉+≡
extern void *Seq_addlo(T seq, void *x);
extern void *Seq_addhi(T seq, void *x);
Seq_addlo将x添加到seq的低端并返回x。添加一个值到序列的开始,会将所有现存值的索引都加1,并将序列的长度加1。Seq_addhi将x添加到seq的高端并返回x。添加一个值到序列的末尾,会将序列的长度加1。Seq_addlo和Seq_addhi可能引发Mem_Failed异常。
类似地,通过从序列两端删除值可以收缩序列:
〈exported functions
123〉+≡
extern void *Seq_remlo(T seq);
extern void *Seq_remhi(T seq);
Seq_remlo删除并返回seq低端的值。在序列的起始处删除值,会将余下所有值的索引都减1,并将序列的长度减1。Seq_remhi删除并返回seq高端的值。在序列末端删除值,会将序列的长度减1。将空序列传递给Seq_remlo或Seq_remhi,是已检查的运行时错误。
本章开头提出,序列是动态数组的高级抽象。因而序列的表示包含了一个动态数组,这不是指向Array_T的一个指针,而是Array_T结构本身的一个实例,其实现同时导入了Array和ArrayRep接口:
〈seq.c 〉≡ #include <stdlib.h> #include <stdarg.h> #include <string.h> #include "assert.h" #include "seq.h" #include "array.h" #include "arrayrep.h" #include "mem.h" #define T Seq_T struct T { struct Array_T array; int length; int head; }; 〈static functions 128〉 〈functions 126〉
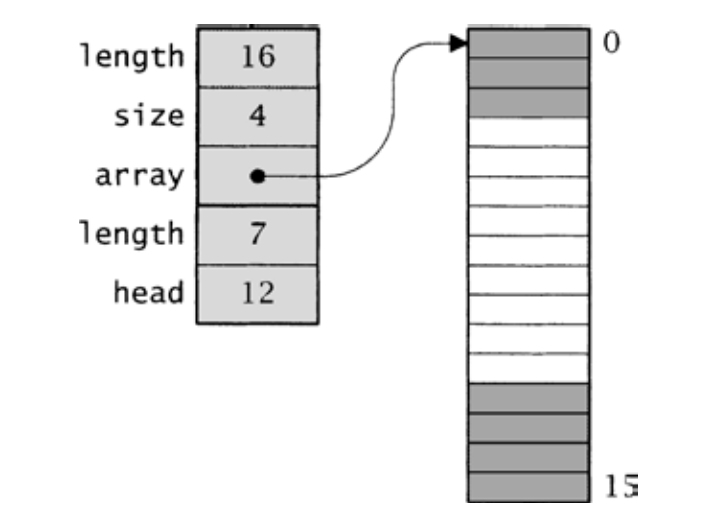
length字段包含了序列中的值的数目,而array字段保存了存储这些值的数组。该数组总是至少包含length个元素,当length小于array.length时,其中一些元素是不使用的。该数组用作一个环形缓冲区,以容纳序列中的值。序列中索引为0的值保存在数组中索引为head的元素处,序列中索引号连续的值,也保存在数组的“连续”元素中(注意:“连续”是同余意义上的)。即如果序列中第i个值保存在数组元素array.length-1中,那么第i+1个值保存在数组元素0中。图11-1给出了在一个16个元素的数组保存包含7个值的序列的方法。左侧的方框是Seq_T及其内嵌的Array_T,以淡色阴影标明。
图11-1 7个值的序列(容量为16)
右侧的方框是数组,其中的阴影标明了被序列中的值占用的元素。
如下文详述,在序列开始处添加值时,需要将head减1,而后对数组长度求模,在序列开始处删除值时,需要将head加1,而后对数组长度求模。序列总是会包含一个数组,即使空序列也是如此。
创建新序列时,会分配一个可以容纳hint个指针的动态数组(如果hint为0,那么可以容纳16个指针):
〈functions
126〉≡
T Seq_new(int hint) {
T seq;
assert(hint >= 0);
NEW0(seq);
if (hint == 0)
hint = 16;
ArrayRep_init(&seq->array, hint, sizeof (void *),
ALLOC(hint*sizeof (void *)));
return seq;
}
使用NEW0将length和head字段初始化为0。Seq_seq调用Seq_new创建一个空序列,然后对参数列表中的参数逐一调用Seq_addhi,将其追加到新序列中:
〈functions
126〉+≡
T Seq_seq(void *x, ...) {
va_list ap;
T seq = Seq_new(0);
va_start(ap, x);
for ( ; x; x = va_arg(ap, void *))
Seq_addhi(seq, x);
va_end(ap);
return seq;
}
Seq_seq使用了处理可变长度参数列表的宏,用法与List_list非常相似,请参见7.1节。
可通过Array_free释放一个序列,这将释放数组及其描述符:
〈functions
126〉+≡
void Seq_free(T *seq) {
assert(seq && *seq);
assert((void *)*seq == (void *)&(*seq)->array);
Array_free((Array_T *)seq);
}
对Array_free的调用之所以能够工作,仅仅因为*seq指向的地址等于&(*seq)->array,如代码中的断言所示。即Array_T结构必须是Seq_T结构中的第一个 字段,这样Seq_new中NEW0返回的指针既指向一个Seq_T实例,同时也指向一个Array_T实例。
Seq_length只是返回序列的length字段:
〈functions
126〉+≡
int Seq_length(T seq) {
assert(seq);
return seq->length;
}
序列中的第i个值,所对应数组元素的索引值为(head + i) mod array.length。通过类型转换,使之可以直接索引数组:
〈seq[i] 127〉≡
((void **)seq->array.array)[
(seq->head + i)%seq->array.length]
Seq_get只是返回上述代码给出的这个数组元素,Seq_put将其设置为x:
〈functions
126〉+≡
void *Seq_get(T seq, int i) {
assert(seq);
assert(i >= 0 && i < seq->length);
return 〈seq[i] 127〉;
}
void *Seq_put(T seq, int i, void *x) {
void *prev;
assert(seq);
assert(i >= 0 && i < seq->length);
prev = 〈seq[i] 127〉;
〈seq[i] 127〉 = x;
return prev;
}
Seq_remlo和Seq_remhi从一个序列中删除值。在这两个函数中,Seq_remhi比较简单,因为它只需要将length字段减1,并返回由length的新值索引的序列值即可:
〈functions
126〉+≡
void *Seq_remhi(T seq) {
int i;
assert(seq);
assert(seq->length > 0);
i = --seq->length;
return 〈seq[i] 127〉;
}
Seq_remlo稍微复杂一些,因为它必须返回由head索引的值(即序列中索引值0对应的值),接下来需要将head加1然后对数组长度取模,并将length减1:
〈functions
126〉+≡
void *Seq_remlo(T seq) {
int i = 0;
void *x;
assert(seq);
assert(seq->length > 0);
x = 〈seq[i] 127〉;
seq->head = (seq->head + 1)%seq->array.length;
--seq->length;
return x;
}
Seq_addlo和Seq_addhi向序列添加值,因而必须处理数组容量用尽的可能性,当length等于array.length时,就会发生这种情况。在发生这种情况时,这两个函数都调用expand来扩大数组,expand进而又调用了Array_resize来完成其工作。在这两个函数中,Seq_addhi仍然是比较简单的那个,因为在检查是否需要扩展数组后,该函数只需将新值保存在由索引值length指定的数组元素处,并将length加1即可:
〈functions
126〉+≡
void *Seq_addhi(T seq, void *x) {
int i;
assert(seq);
if (seq->length == seq->array.length)
expand(seq);
i = seq->length++;
return 〈seq[i] 127〉 = x;
}
Seq_addlo也会检查是否需要扩展数组,但接下来它需要将head减1后对数组长度取模,并将x存储到由head的新值索引的数组元素处,这就是序列中索引值0对应的值:
〈functions
126〉+≡
void *Seq_addlo(T seq, void *x) {
int i = 0;
assert(seq);
if (seq->length == seq->array.length)
expand(seq);
if (--seq->head < 0)
seq->head = seq->array.length - 1;
seq->length++;
return 〈seq[i] 127〉 = x;
}
另外,Seq_addlo也可以通过下列代码,来对seq->head减1并取模:
seq->head = Arith_mod(seq->head - 1, seq->array.length);
expand封装了对Array_resize的调用,这将倍增序列中数组的长度:
〈static functions 128〉≡ static void expand(T seq) { int n = seq->array.length; Array_resize(&seq->array, 2*n); if (seq->head > 0) 〈slide tail down 129〉 }
该代码暗示,expand还必须处理将数组用作环形缓冲区的情形。除非head碰巧是0,否则,原数组后半段的那些元素(从head之后)必须移动到扩展之后的数组末端,以便把中间的区域腾出来,如图11-2所示,同时需要相应地调整head:
〈slide tail down
129〉≡
{
void **old = &((void **)seq->array.array)[seq->head];
memcpy(old+n, old, (n - seq->head)*sizeof (void *));
seq->head += n;
}
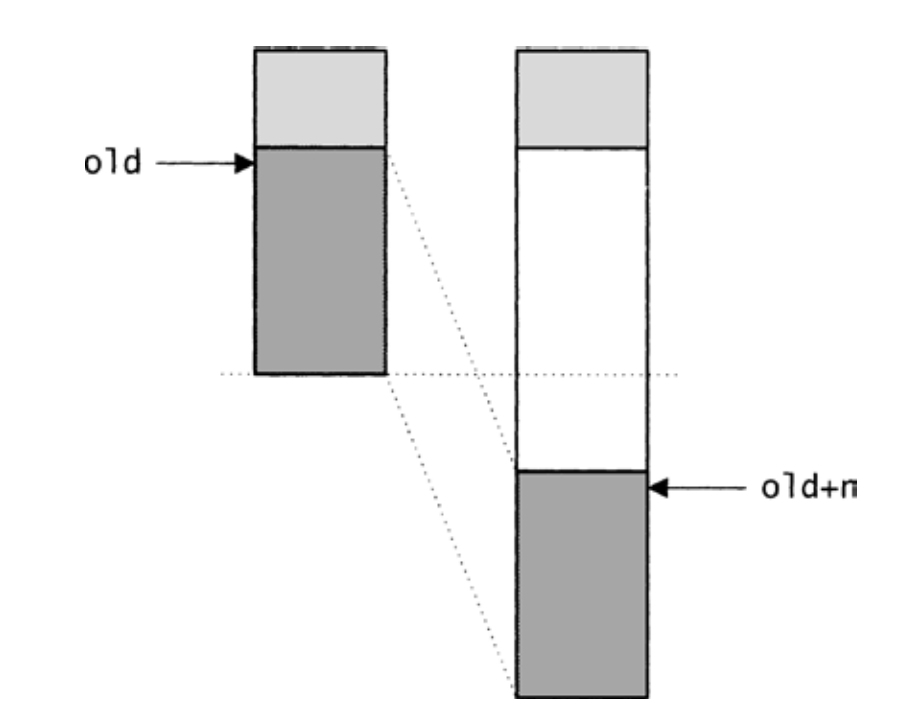
图11-2 扩展序列
序列与Icon[Griswold and Griswold,1990]中的列表几乎是相同的,但相关操作的名称则取自DEC实现的Modula-3[Horning等人,1993]附带的库中的Sequence接口。本章中描述的实现也与DEC的实现类似。习题11.1探讨了Icon的实现。
11.1 Icon用块的双链表实现了列表(序列的Icon版本),每个块可以容纳(假定)M个值。这种表示避免了使用Array_resize,因为新的块可以在调用Seq_addlo和Seq_addhi时根据需要添加到列表的两端。这种表示的不利之处在于,必须遍历各个块才能访问第i个值,这花费的时间正比于i/M。使用这种表示构建Seq接口的一个新实现,并开发一些测试程序来测量其性能。假定访问索引值i对应的值时,通常都会伴随着对索引值i - 1或i + 1对应的值的访问;你能修改实现,使得这种情况能够在常数时间内执行完成吗?
11.2 为Seq接口设计一个实现,不要使用Array_resize。例如,在原来的N元素数组用尽时,可以将其转换为一个指针数组,每个元素都是指向另一个数组(假定可容纳2N个元素)的指针,这样,转换后的序列可容纳2N2 个值。如果N为1024,转换后的序列可容纳超过两百万个元素,每个元素都可以在常数时间内访问。这种“边向量”表示中,每个2N元素数组都可以惰性分配,即仅当有值存储到其中时才分配。
11.3 假定禁用Seq_addlo和Seq_remlo,设计一个渐增式分配空间的实现,但序列中的任何元素都必须能够在对数时间内访问。提示:跳表(skip list,参见[Pugh,1990])。
11.4 序列只扩展,但从不收缩。修改Seq_remlo和Seq_remhi的实现,使之在数组有超过半数空间空闲时,对序列进行收缩,即当seq->length变为小于seq->array.length/2时。在什么情况下,该修改是一个坏 主意?提示:颠簸(指序列反复扩展/收缩)。
11.5 重新实现xref,使用序列而不是集合来容纳行号。由于文件是顺序读取的,不需要对行号排序,因为它们将按递增次序出现在序列中。
11.6 重写Seq_free,使其无需再用现在的断言。请注意,不能使用Array_free。