图8-1 参数x和y的链表
关联表 (associative table)是一组键—值对的集合。它很像是数组,只是索引可以是任何类型值。许多应用程序都使用表。例如,编译器要维护符号表,该表将名称映射到名称的属性集合。一些窗口系统会维护表,用于将窗口标题映射到某种窗口相关的数据结构。文档预加工系统使用表来表示索引:例如,索引可能是一个表,键是单字符的字符串(每个字符表示索引中的一个部分),值是另一个表,该表的键是表示索引项的字符串,值是页码列表。
表有许多用途,光是举例就需要一章的篇幅。Table接口的设计,使得它可以满足这些用途中的相当一部分。它维护键—值对,但它从不查看键本身,只有客户程序才通过传递给Table中例程的函数,来查看键。8.2节描述了Table接口的一个典型的客户程序,该程序输出其输入中单词出现的次数。这个程序是wf,它还使用了Atom和Mem接口。
Table接口用一个不透明指针类型来表示关联表:
〈table.h 〉≡ #ifndef TABLE_INCLUDED #define TABLE_INCLUDED #define T Table_T typedef struct T *T; 〈exported functions 84〉 #undef T #endif
导出的函数负责分配和释放Table_T实例、向表添加/删除键—值对,以及访问表中的键—值对。向该接口中任何函数传递的Table_T实例为NULL,或键为NULL,都是已检查的运行时错误。
Table_T通过下列函数分配和释放:
〈exported functions
84〉≡
extern T Table_new (int hint,
int cmp(const void *x, const void *y),
unsigned hash(const void *key));
extern void Table_free(T *table);
Table_new的第一个参数hint,用于估计新的表中预期会容纳的表项数目。无论hint值如何,所有的表都可以容纳任意数目的表项,但准确的hint值可能会提高性能。传递负的hint值,是一个已检查的运行时错误。函数cmp和hash负责操作特定于客户程序的键。给定两个键x和y,cmp(x,y)针对x小于y、x等于y或x大于y的情形,必须分别返回小于零、等于零或大于零的整数。标准库函数strcmp是一个适合于字符串键的比较函数。hash必须针对key返回一个哈希码,如果cmp(x,y)返回零,hash(x)必须等于hash(y)。每个表都可以有自身的hash和cmp函数。
原子通常用作键,因此如果hash是NULL函数指针,那么假定新表中的键是原子,Table的实现提供了一个适当的哈希函数。类似地,如果cmp是NULL函数指针,那么假定表的键为原子,如果x=y,那么键x和y相等。
Table_new可能引发Mem_Failed异常。
Table_new参数包括一个表大小的提示值、一个哈希函数和一个比较函数,提供的信息超出了大多数实现的需要。例如,8.3节中描述的哈希表实现需要一个只测试相等性的比较函数,而使用树的实现则不需要表大小的提示信息或哈希函数。这种复杂性,是容许多种实现的设计所必需的代价;另外,为什么设计好的接口很困难,这种特性就是原因之一。
Table_free释放*table,并将其设置为NULL指针。如果table或*table是NULL,则是已检查的运行时错误。Table_free并不释放键或值,相关内容可参考Table_map。
下列函数
〈exported functions
84〉+≡
extern int Table_length(T table);
extern void *Table_put (T table, const void *key,
void *value);
extern void *Table_get (T table, const void *key);
extern void *Table_remove(T table, const void *key);
其功能分别是:返回表中键的数目、添加一个新的键—值对或改变一个现存键—值对中的值,取得与某个键关联的值,删除一个键—值对。
Table_length返回table中键—值对的数目。
Table_put将由key和value给定的键—值对添加到table。如果table已经包含key键,那么用value覆盖key此前对应的值,Table_put将返回key此前对应的值。否则,将key和value添加到table中,table增长一个表项,Table_put将返回NULL指针。Table_put可能引发Mem_Failed异常。
Table_get搜索table查找key键,如果找到则返回key键相关联的值。如果table并不包含key键,则Table_get返回NULL指针。请注意,如果table包含NULL指针值,那么返回NULL指针是有歧义的。
Table_remove将搜索table查找key键,如果找到则从table删除对应的键—值对,表将会缩减一个表项,并返回被删除的值。如果table并不包含key键,Table_remove对table没有作用,将返回NULL指针。
下列函数中
〈exported functions
84〉+≡
extern void Table_map (T table,
void apply(const void *key, void **value, void *cl),
void *cl);
extern void **Table_toArray(T table, void *end);
Table_toArray访问表中的键—值对,并将其收集到一个数组中。Table_map以未指定的顺序对table中的每个键—值对调用apply指向的函数。apply和cl指定了一个闭包:客户程序可以向Table_map传递一个特定于应用程序的指针cl,在每次调用apply时,该指针又被顺次传递给apply。对table中的每个对,调用apply时会传递其键、指向其值的指针和cl。因为调用*apply时使用的是指向值的指针,因此值可能会被apply修改。Table_map还可以用来在释放表之前释放键或值。例如,假定键是原子
static void vfree(const void *key, void **value,
void *cl) {
FREE(*value);
}
上述函数会释放键—值对中的值,因此
Table_map(table, vfree, NULL); Table_free(&table);
将释放table中所有的值和table本身。
如果apply调用Table_put或Table_remove改变table的内容,则是已检查的运行时错误。
给定一个包含N个键—值对的表,Table_toArray会构建一个有2N+1个元素的数组,并返回指向第一个元素的指针。在数组中键和值交替出现,键出现在偶数编号的元素处,对应的值出现在下一个奇数编号的元素处。最后一个偶数编号的元素位于索引2N处,被赋值为end,end通常是NULL指针。数组中键—值对的顺序是未指定的。8.2节中描述的程序说明了Table_toArray的用法。
Table_toArray可能引发Mem_Failed异常,客户程序必须释放Table_toArray返回的数组。
wf会列出一组文件或标准输入(如果没有指定文件)中每个单词出现的次数。例如:
% wf table.c mem.c table.c: 3 apply 7 array 13 assert 9 binding 18 book 2 break 10 buckets ... 4 y mem.c: 1 allocation 7 assert 12 book 1 stdlib 9 void ...
如上述输出所示,每个文件中的单词按字母顺序列出,单词之前是其在该文件中出现的次数。对于wf来说,单词就是一个字母后接零个或更多字母或下划线,不考虑大小写。
更一般地说,一个单词由first集合中的一个字符开始,后接rest集合中的零或多个字符。这种形式的单词可以由getword识别,它是1.1节中描述的double中的getword的一般化形式。它在本书中使用得很广泛,以至于需要打包到一个独立的接口中:
〈getword.h
〉≡
#include <stdio.h>
extern int getword(FILE *fp, char *buf, int size,
int first(int c), int rest(int c));
getword会从打开的文件fp中读取下一个单词,将其作为0结尾字符串存储到buf [0..size-1]中,并返回1。当它到达文件末尾而无法读取到单词时,将返回0。函数first和rest测试某个字符是否属于first和rest集合。一个单词是一个连续的字符序列,其起始字符用first函数测试时会返回非零值,后接的字符用rest测试时将返回非零值。如果一个单词包含的字符数大于size-2,多出的字符将丢弃。size必须大于1,fp、buf、first和rest都不能为NULL。
〈getword.c 〉≡ #include <ctype.h> #include <string.h> #include <stdio.h> #include "assert.h" #include "getword.h" int getword(FILE *fp, char *buf, int size, int first(int c), int rest(int c)) { int i = 0, c; assert(fp && buf && size > 1 && first && rest); c = getc(fp); for ( ; c != EOF; c = getc(fp)) if (first(c)) { 〈store c in buf if it fits 88〉 c = getc(fp); break; } for ( ; c != EOF && rest(c); c = getc(fp)) 〈store c in buf if it fits 88〉 if (i < size) buf[i] = '\0'; else buf[size-1] = '\0'; if (c != EOF) ungetc(c, fp); return i > 0; } 〈store c in buf if it fits 88〉≡ { if (i < size - 1) buf[i++] = c; }
getword的这个版本比double中的版本要复杂一点,因为当一个字符属于first集合但不属于rest集合时,这个版本必须能够工作。当first返回非零值时,该字符将保持在buf中,仅其后续字符将传递给rest。
wf的main函数处理其参数,参数给出了输入文件的名称。main打开各个文件,并用FILE指针和文件名来调用wf:
〈wf functions 88〉≡ int main(int argc, char *argv[]) { int i; for (i = 1; i < argc; i++) { FILE *fp = fopen(argv[i], "r"); if (fp == NULL) { fprintf(stderr, "%s: can't open '%s' (%s)\n", argv[0], argv[i], strerror(errno)); return EXIT_FAILURE; } else { wf(argv[i], fp); fclose(fp); } } if (argc == 1) wf(NULL, stdin); return EXIT_SUCCESS; } 〈wf includes 88〉≡ #include <stdio.h> #include <stdlib.h> #include <errno.h>
如果没有参数,main用NULL字符串(用作文件名)和表示标准输入的FILE指针来调用wf。NULL字符串文件名告知wf无需输出文件名。
wf使用表来存储单词及其计数。各个单词都转换为小写,再转换为原子,用作表的键。使用原子,使得wf可以利用表提供的默认哈希函数和比较函数。表中存储的值是指针,但wf却需要将一个整数计数关联到各个键。因而它为计数器分配了内存空间,并将指向该空间的指针存储在表中。
〈wf functions 88〉+≡ void wf(char *name, FILE *fp) { Table_T table = Table_new(0, NULL, NULL); char buf[128]; while (getword(fp, buf, sizeof buf, first, rest)) { const char *word; int i, *count; for (i = 0; buf[i] != '\0'; i++) buf[i] = tolower(buf[i]); word = Atom_string(buf); count = Table_get(table, word); if (count) (*count)++; else { NEW(count); *count = 1; Table_put(table, word, count); } } if (name) printf("%s:\n", name); { 〈print the words 90〉 } 〈deallocate the entries and table 91〉 } 〈wf includes 88〉+≡ #include <ctype.h> #include "atom.h" #include "table.h" #include "mem.h" #include "getword.h" 〈wf prototypes 89〉≡ void wf(char *, FILE *);
count是一个指向整数的指针。如果Table_get返回NULL,那么当前单词不在table中,如此wf为该计数器分配空间,并将其初始化为1,来表示该单词的第一次出现,并将其添加到表中。当Table_get返回非NULL指针时,表达式(*count)++会将该指针指向的整数加1。该表达式与*count++有很大不同,后者将count加1,而不是将其指向的整数加1。
字符是否是first和rest集合的成员,是通过同名函数来测试的,这些函数的实现使用了标准头文件ctype.h中定义的谓词:
〈wf functions 88〉+≡ int first(int c) { return isalpha(c); } int rest(int c) { return isalpha(c) || c == '_'; } 〈wf prototypes 89〉+≡ int first(int c); int rest (int c);
在wf读取了所有单词后,它必须排序并输出它们。qsort是标准C库的排序函数,可以对数组排序,因此,如果告知qsort数组中的键—值对应该当做单个元素处理,那么wf就可以对Table_toArray返回的数组进行排序。接下来,程序遍历数组即可输出各个单词及其计数:
〈print the words
90〉≡
int i;
void **array = Table_toArray(table, NULL);
qsort(array, Table_length(table), 2*sizeof (*array),
compare);
for (i = 0; array[i]; i += 2)
printf("%d\t%s\n", *(int *)array[i+1],
(char *)array[i]);
FREE(array);
qsort有4个参数:数组、元素的数目、各个元素的大小(字节数)和比较两个元素时调用的函数。为将键—值对当做单个元素处理,wf告知qsort数组中有N个元素,每个元素占两个指针的空间。
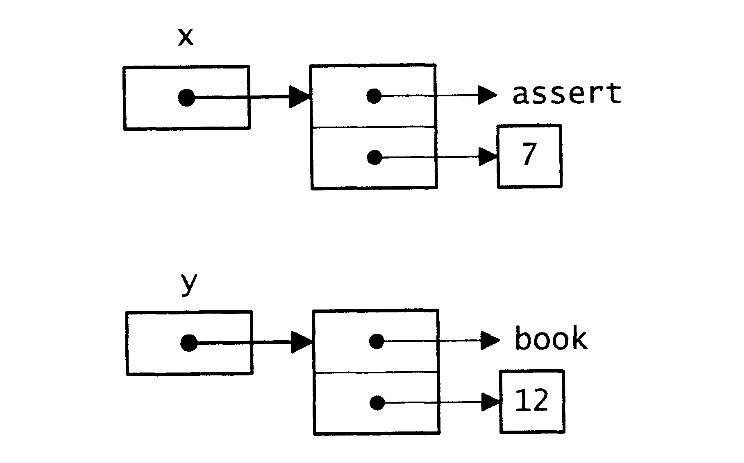
qsort用指向元素的指针作为参数调用比较函数。每个元素本身是两个指针,一个指向单词,另一个指向计数,因此调用比较函数时,其参数是两个指向字符的双重指针。例如,当比较mem.c文件中的assert和book时,参数x和y如图8-1所示。
图8-1 参数x和y的链表
比较函数可以调用strcmp来比较单词:
〈wf functions 88〉+≡ int compare(const void *x, const void *y) { return strcmp(*(char **)x, *(char **)y); } 〈wf includes 88〉+≡ #include <string.h> 〈wf prototypes 89〉+≡ int compare(const void *x, const void *y);
main会对每个文件名参数调用wf函数,因此为节省空间,wf应该在返回之前释放表和计数器。对Table_map的调用释放了各计数器,而Table_free释放了表本身。
〈deallocate the entries and table 91〉≡ Table_map(table, vfree, NULL); Table_free(&table); 〈wf functions 88〉+≡ void vfree(const void *key, void **count, void *cl) { FREE(*count); } 〈wf prototypes 89〉+≡ void vfree(const void *, void **, void *);
键没有释放,因为它们是原子,不能释放。另外,其中一些可能出现在后续的文件中。
收集wf.c的各个片段,就形成了wf程序:
〈wf.c 〉≡ 〈wf includes 88〉 〈wf prototypes 89〉 〈wf functions 88〉
〈table.c 〉≡ #include <limits.h> #include <stddef.h> #include "mem.h" #include "assert.h" #include "table.h" #define T Table_T 〈types 92〉 〈static functions 93〉 〈functions 92〉
在可用于表示关联表的各种显而易见的数据结构中,哈希表是其中之一(树是另一种,参见习题8.2)。因而每个Table_T是一个结构指针,该结构包含了binding结构的一个哈希表,键—值对则包含在binding结构中:
〈types 92〉≡ struct T { 〈fields 92〉 struct binding { struct binding *link; const void *key; void *value; } **buckets; };
buckets指向一个数组,包含适当数目的元素。cmp和hash函数是关联到特定表的,因此它们连同buckets中元素的数目,一同保存在Table_T结构中:
〈fields
92〉≡
int size;
int (*cmp)(const void *x, const void *y);
unsigned (*hash)(const void *key);
Table_new使用其hint参数来选择一个素数作为buckets的大小,它还会保存传递进来的cmp和hash函数指针(或指向静态函数的指针,用于比较和散列原子):
〈functions
92〉≡
T Table_new(int hint,
int cmp(const void *x, const void *y),
unsigned hash(const void *key)) {
T table;
int i;
static int primes[] = { 509, 509, 1021, 2053, 4093,
8191, 16381, 32771, 65521, INT_MAX };
assert(hint >= 0);
for (i = 1; primes[i] < hint; i++)
;
table = ALLOC(sizeof (*table) +
primes[i-1]*sizeof (table->buckets[0]));
table->size = primes[i-1];
table->cmp = cmp ? cmp : cmpatom;
table->hash = hash ? hash : hashatom;
table->buckets = (struct binding **)(table + 1);
for (i = 0; i < table->size; i++)
table->buckets[i] = NULL;
table->length = 0;
table->timestamp = 0;
return table;
}
for循环将i设置为primes中大于等于hint的第一个元素的索引值,primes[i-1]给出了buckets中元素的数目。请注意,该循环从索引1开始。Mem接口的ALLOC宏负责分配Table_T结构和buckets占用的空间。Table接口的实现使用素数作为其哈希表的大小,因为它无法控制键的哈希码如何计算。primes中的值是最接近2n 的素数(n=9…16),由此可以确定哈希表在很大范围内的大小。Atom使用了稍简单的算法,因为它自身会计算哈希码。
如果cmp或hash是NULL函数指针,将使用下列函数
〈static functions
93〉≡
static int cmpatom(const void *x, const void *y) {
return x != y;
}
static unsigned hashatom(const void *key) {
return (unsigned long)key>>2;
}
代替。因为原子x=y即可推出x和y相等,所以cmpatom在x=y时返回0,否则返回1。这个特定的Table实现只需要测试键是否相等,因此cmpatom并不需要测定x和y的相对顺序。原子是一个地址,这个地址本身就可以用作哈希码,右移两位是因为可能每个原子都起始于字边界(word boundary),因此最右侧两位可能是0。
buckets中的每个元素都是一个链表的表头,该链表由binding结构构成,每个binding结构都包含一个键、与之相关联的值以及指向链表中下一个binding结构的指针。图8-2给出了一个例子。同一链表中,所有的键都具有相同的哈希码。
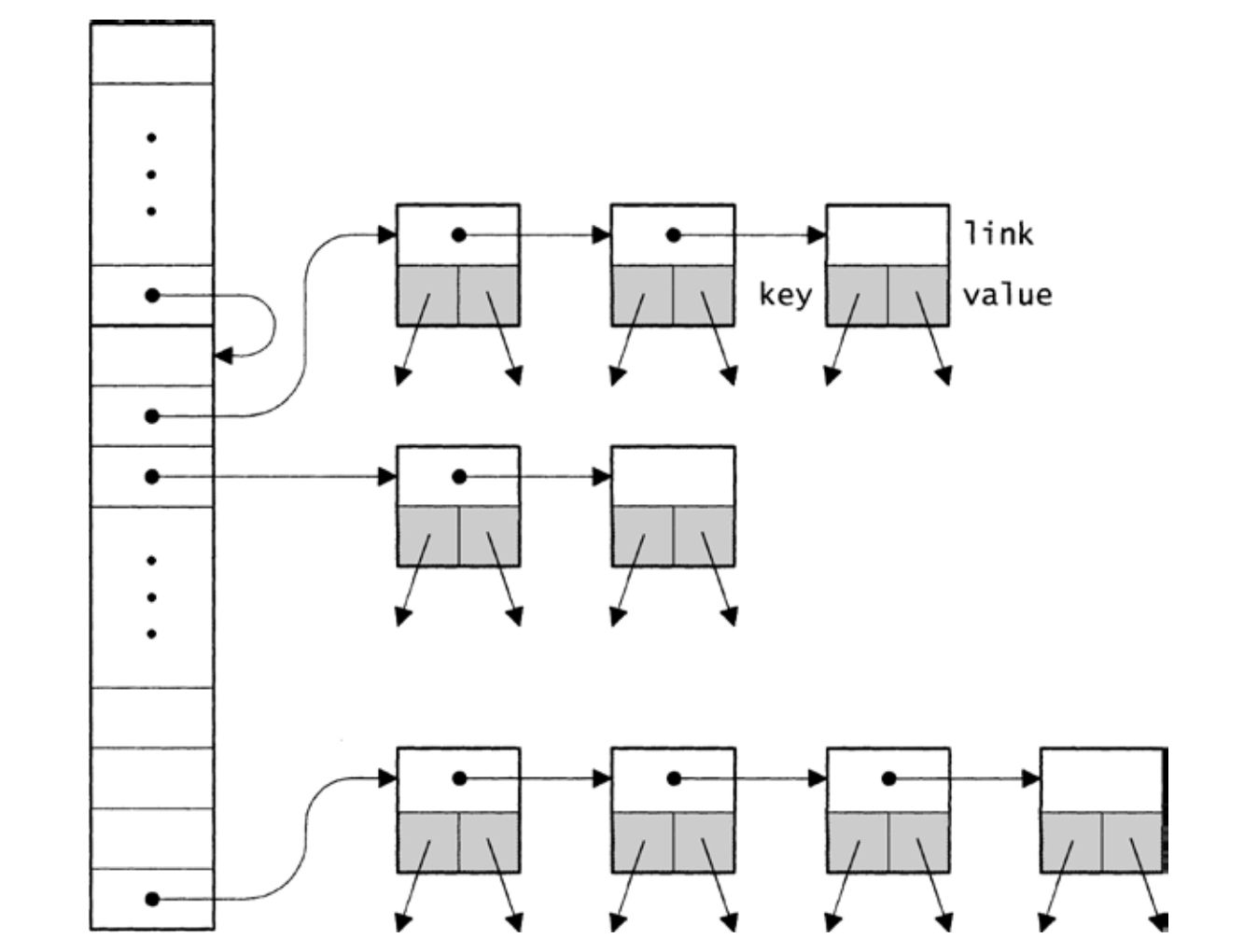
图8-2 表的布局
Table_get查找与键对应的值,它首先散列键得到其哈希码,而后将哈希码对buckets中元素的数目取模,然后搜索对应的链表查找与key相同的键。它调用表的hash和cmp函数。
〈functions 92〉+≡ void *Table_get(T table, const void *key) { int i; struct binding *p; assert(table); assert(key); 〈search table for key 94〉 return p ? p->value : NULL; } 〈search table for key 94〉≡ i = (*table->hash)(key)%table->size; for (p = table->buckets[i]; p; p = p->link) if ((*table->cmp)(key, p->key) == 0) break;
这个for循环在找到键时结束,此时p指向我们关注的binding结构实例。否则,p最终为NULL。
Table_put的流程很相似,它在表中查找一个键,如果找到,则改变相关联的值。如果Table_put找不到键,那么它会分配并初始化一个新的binding结构实例,找到键在buckets中对应的链表,将该实例添加到链表的头部。事实上,可以将新的binding实例添加到链表中任何地方,但添加到表头是最容易也最高效的方案。
〈functions 〉+≡ void *Table_put(T table, const void *key, void *value) { int i; struct binding *p; void *prev; assert(table); assert(key); 〈search table for key 94〉 if (p == NULL) { NEW(p); p->key = key; p->link = table->buckets[i]; table->buckets[i] = p; table->length++; prev = NULL; } else prev = p->value; p->value = value; table->timestamp++; return prev; }
Table_put会将表的两个计数器加1:
〈fields
92〉+≡
int length;
unsigned timestamp;
length是表中binding实例的数目,Table_length函数即返回该值:
〈functions
92〉+≡
int Table_length(T table) {
assert(table);
return table->length;
}
Table_put或Table_remove每次修改表时,表的timestamp也会加1。timestamp用来实现Table_map必须强制实施的一项已检查的运行时错误:在Table_map访问表中各个binding实例时,表不能改变。Table_map在进入时保存了timestamp的值。在每次调用apply之后,它通过断言来检查表的timestamp是否仍然等于该保存值。
〈functions
92〉+≡
void Table_map(T table,
void apply(const void *key, void **value, void *cl),
void *cl) {
int i;
unsigned stamp;
struct binding *p;
assert(table);
assert(apply);
stamp = table->timestamp;
for (i = 0; i < table->size; i++)
for (p = table->buckets[i]; p; p = p->link) {
apply(p->key, &p->value, cl);
assert(table->timestamp == stamp);
}
}
Table_remove也搜索一个键,但它使用了指向binding实例的双重指针,这样在找到对应键的binding实例时,可以删除该binding:
〈functions
92〉+≡
void *Table_remove(T table, const void *key) {
int i;
struct binding **pp;
assert(table);
assert(key);
table->timestamp++;
i = (*table->hash)(key)%table->size;
for (pp = &table->buckets[i]; *pp; pp = &(*pp)->link)
if ((*table->cmp)(key, (*pp)->key) == 0) {
struct binding *p = *pp;
void *value = p->value;
*pp = p->link;
FREE(p);
table->length--;
return value;
}
return NULL;
}
上述for循环与〈search table for key 94〉中的for循环在功能上是等效的,只是pp指向对应于各个键的binding实例的指针。pp最初指向table->buckets[i],而后遍历整个链表,当检查第k+1个binding实例时,pp指向第k个binding实例的link字段,如图8-3所示。
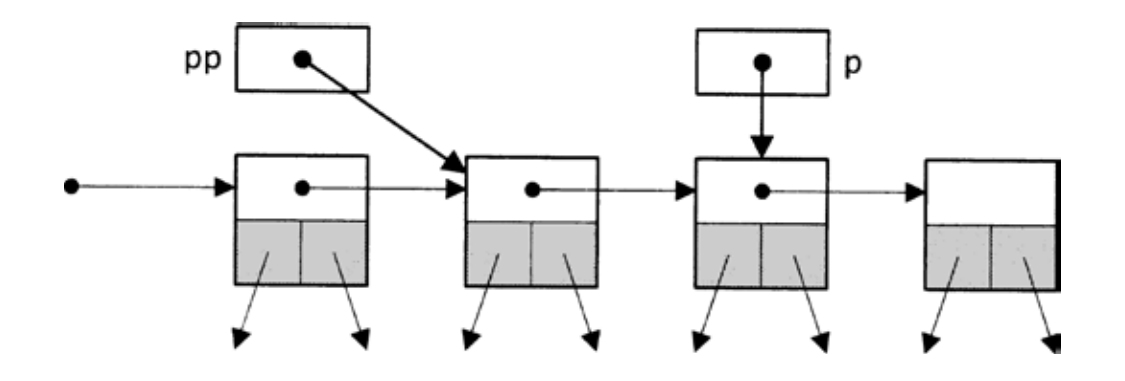
图8-3 检查第k+1个binding实例的情形
如果*pp包含key,那么通过将*pp设置为(*pp)->link,即可从链表断开该binding的链接,p包含*pp的值。如果Table_remove找到键,它也会将表的长度减1。
Table_toArray类似于List_toArray。它分配一个数组来容纳各个键—值对(以及一个结束指针),并访问table中的各个binding实例以填充数组:
〈functions
92〉+≡
void **Table_toArray(T table, void *end) {
int i, j = 0;
void **array;
struct binding *p;
assert(table);
array = ALLOC((2*table->length + 1)*sizeof (*array));
for (i = 0; i < table->size; i++)
for (p = table->buckets[i]; p; p = p->link) {
array[j++] = (void *)p->key;
array[j++] = p->value;
}
array[j] = end;
return array;
}
p->key必须从const void*转换为void*,因为数组并未声明为常量。数组中键—值对的顺序是任意的。
Table_free必须释放各个binding结构实例和Table_T结构本身。仅当表非空时,才需要前一个步骤:
〈functions
92〉+≡
void Table_free(T *table) {
assert(table && *table);
if ((*table)->length > 0) {
int i;
struct binding *p, *q;
for (i = 0; i < (*table)->size; i++)
for (p = (*table)->buckets[i]; p; p = q) {
q = p->link;
FREE(p);
}
}
FREE(*table);
}
表是如此之有用,以至于许多编程语言将其作为内建数据类型。AWK[Aho, Kernighan and Weinberger,1988]是一个新近的例子,但表更早就出现在SNOBOL4[Griswold,1972]中,而后也出现在SNOBOL4的后继者Icon[Griswold and Griswold,1990]中。SNOBOL4和Icon中的表可以用任何类型的值索引,也可以容纳任何类型的值,但AWK中的表(称作数组)只能用字符串和数字索引,也只能容纳字符串和数字。Table接口的实现,使用了Icon[Griswold and Griswold, 1986]中用于实现表的一些技术。
PostScript[Adobe Systems,1990]这种页面描述语言(page-description language)也有表,称之为字典(dictionary)。PostScript表只能通过“名字”来索引,这实际上是PostScript的原子版本,但PostScript表可以容纳任何类型的值(包括字典)。
表也出现在面向对象语言中,或者是内建类型的形式,或者以库的形式提供。SmallTalk和Objective-C的基础库都包括字典,与Table接口所定义的表非常类似。这些类型的对象通常称作容器 对象,因为它们可以容纳很多其他对象。
Table的实现使用了固定大小的哈希表。只要负载系数 (load factor,即表项的数目除以哈希桶的数目)较小,只需查看几项即可找到键。但在负载系数过高时,性能会受损。一旦负载系数超过某个阈值(假定是5),就扩展哈希表,可以将负载系数维持在合理的范围内。习题8.5探讨了动态哈希表 的一种有效但幼稚的实现,该方法会扩展哈希表并重新散列所有现存的表项。[Larson,1988]非常详细地描述了一种更复杂的方法,其中哈希表是逐渐扩展(或收缩)的,每次处理一个哈希链。Larson的方法无需hint,而且可以节省内存,因为它使得所有的表最初都只需要少量的哈希桶。
8.1 关联表ADT有许多可行的方案。例如,在Table的早期版本中,Table_get返回指向值的指针而不是值本身,因此客户程序可以改变表中存储的值。在一种设计中,Table_put总是向表添加一个新的binding实例(即使键已经存在),实际上用同一个键“隐藏”此前存在的binding实例,而Table_remove只删除最近添加的binding实例。但Table_map会访问table中所有的binding实例。讨论这些及其他方案的优缺点。设计并实现一个不同的表ADT。
8.2 Table接口的设计使得可以用其他数据结构类实现表。例如,如果比较函数可以给出两个键的相对顺序,那么就可以使用树来实现Table接口。使用二叉查找树或红黑树重新实现Table接口。这些数据结构的细节,请参见[Sedgewick,1990]。
8.3 Table_map和Table_toArray访问表中各binding实例的顺序是未指定的。假定要修改接口,使得Table_map按binding实例添加到表的顺序来访问各实例,而Table_toArray返回的数组中,各个binding实例也具有相同的顺序。请实现该修正。该行为有什么实际的好处?
8.4 假定Table接口规定,Table_map和Table_toArray按排序次序 访问各binding实例。该规定将使Table的实现复杂化,但将简化需要对binding实例排序的客户程序(如wf)的工作。讨论该提议的优点并实现它。提示:在当前的实现中,Table_put的平均情况运行时间是常数量级,Table_get也几乎是如此。在修改后的实现中,Table_put和Table_get的平均情况运行时间如何?
8.5 Table接口的当前实现中,在buckets分配后不会扩展或收缩。修改Table接口的实现,使得随着键—值对的增删,修改后的实现能够使用一种启发式逻辑来周期性地调整buckets的大小。设计一个测试程序来检验你的启发式逻辑的有效性,并测量其好处。
8.6 实现[Larson,1988]中描述的线性动态散列算法,并对照你对前一道习题的解答,比较二者的性能。
8.7 修改wf.c,以测量因从不释放原子而损失的内存空间数量。
8.8 修改wf.c的compare函数,使之按计数值递减次序对数组进行排序。
8.9 修改wf.c,使之按文件名字母顺序来处理各个文件参数并输出。这样改变后,在8.2节开头给出的例子中,对mem.c的统计将出现在对table.c的统计之前。