Chapter 3. Concepts
The first two chapters of this book covered Rust’s types and traits, which helps provide the vocabulary needed to work with some of the concepts involved in writing Rust code—the subject of this chapter.
The borrow checker and lifetime checks are central to what makes Rust unique; they are also a common stumbling block for newcomers to Rust and so are the focus of the first two Items in this chapter.
The other Items in this chapter cover concepts that are easier to grasp but are nevertheless a bit different from writing code in other languages. This includes the following:
-
Advice on Rust’s
unsafemode and how to avoid it (Item 16) -
Good news and bad news about writing multithreaded code in Rust (Item 17)
-
Advice on avoiding runtime aborts (Item 18)
-
Information about Rust’s approach to reflection (Item 19)
-
Advice on balancing optimization against maintainability (Item 20)
It’s a good idea to try to align your code with the consequences of these concepts. It’s possible to re-create (some of) the behavior of C/C++ in Rust, but why bother to use Rust if you do?
Item 14: Understand lifetimes
This Item describes Rust’s lifetimes, which are a more precise formulation of a concept that existed in previous compiled languages like C and C++—in practice if not in theory. Lifetimes are a required input for the borrow checker described in Item 15; taken together, these features form the heart of Rust’s memory safety guarantees.
Introduction to the Stack
Lifetimes are fundamentally related to the stack, so a quick introduction/reminder is in order.
While a program is running, the memory that it uses is divided up into different chunks, sometimes called segments. Some of these chunks are a fixed size, such as the ones that hold the program code or the program’s global data, but two of the chunks—the heap and the stack—change size as the program runs. To allow for this, they are typically arranged at opposite ends of the program’s virtual memory space, so one can grow downward and the other can grow upward (at least until your program runs out of memory and crashes), as summarized in Figure 3-1.
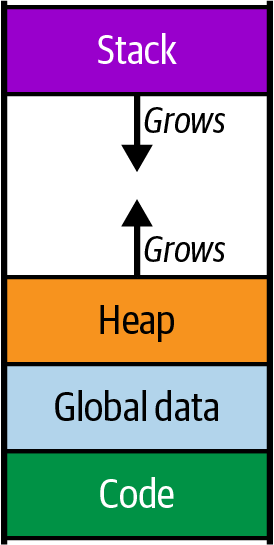
Figure 3-1. Program memory layout, including heap growing up and stack growing down
Of these two dynamically sized chunks, the stack is used to hold state related to the currently executing function. This state can include these elements:
-
The parameters passed to the function
-
The local variables used in the function
-
Temporary values calculated within the function
-
The return address within the code of the function’s caller
When a function f() is called, a new stack frame is added to the stack, beyond where the stack frame for the calling
function ends, and the CPU normally updates a register—the stack pointer—to point to the new
stack frame.
When the inner function f() returns, the stack pointer is reset to where it was before the call, which will be the
caller’s stack frame, intact and unmodified.
If the caller subsequently invokes a different function g(), the process happens again, which means that the stack
frame for g() will reuse the same area of memory that f() previously used (as depicted in Figure 3-2):
fncaller()->u64{letx=42u64;lety=19u64;f(x)+g(y)}fnf(f_param:u64)->u64{lettwo=2u64;f_param+two}fng(g_param:u64)->u64{letarr=[2u64,3u64];g_param+arr[1]}
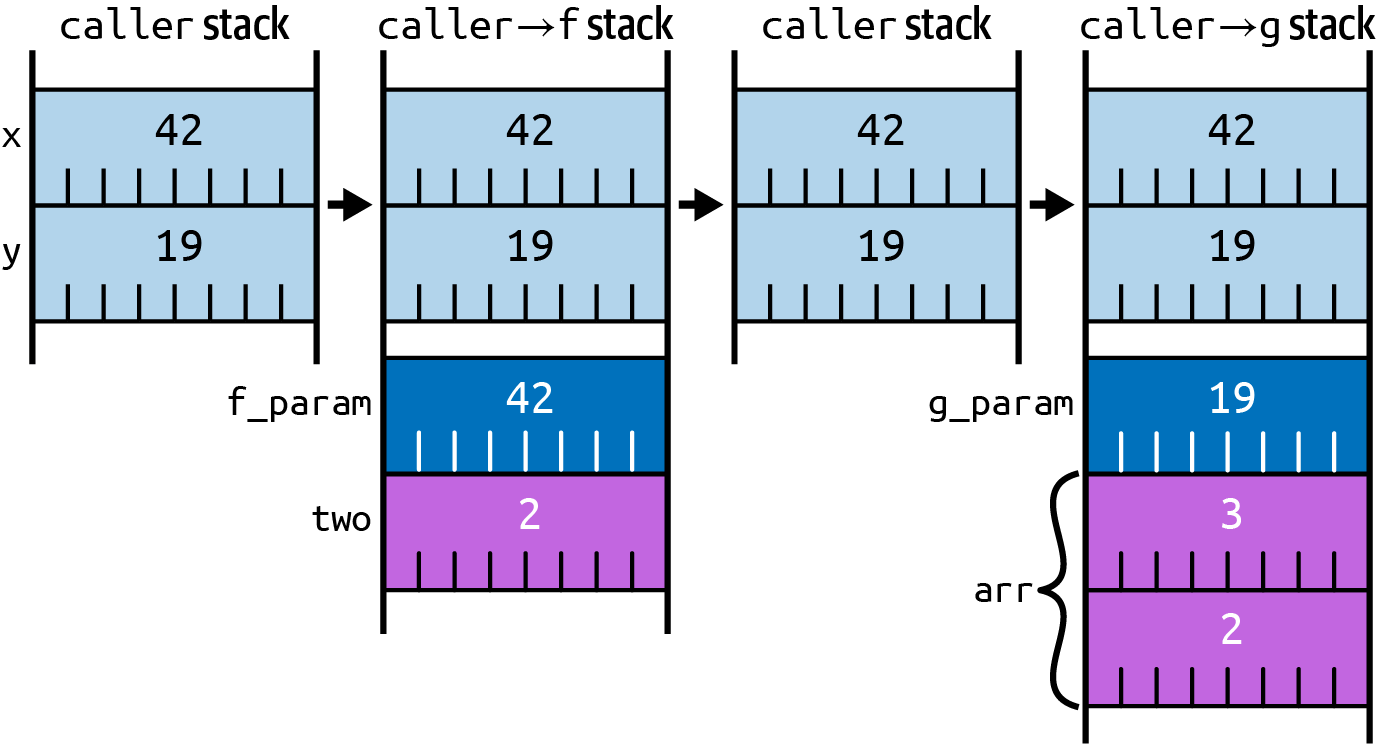
Figure 3-2. Evolution of stack usage as functions are called and returned from
Of course, this is a dramatically simplified version of what really goes on—putting things on and off the stack takes time, and so real processors will have many optimizations. However, the simplified conceptual picture is enough for understanding the subject of this Item.
Evolution of Lifetimes
The previous section explained how parameters and local variables are stored on the stack and pointed out that those values are stored only ephemerally.
Historically, this allowed for some dangerous footguns: what happens if you hold onto a pointer to one of these ephemeral stack values?
Starting back with C, it was perfectly OK to return a pointer to a local variable (although modern compilers will emit a warning for it):
You might get away with this, if you’re unlucky and the calling code uses the returned value immediately:
in caller: file at 0x7ff7bc019408 has fd=3
This is unlucky because it only appears to work. As soon as any other function calls happen, the stack area will be reused and the memory that used to hold the object will be overwritten:
/* C code. */voidinvestigate_file(structFile*f){longarray[4]={1,2,3,4};// put things on the stackprintf("in function: file at %p has fd=%d\n",f,f->fd);}
in function: file at 0x7ff7bc019408 has fd=1592262883
Trashing the contents of the object has an additional bad effect for this example: the file descriptor corresponding to the open file is lost, and so the program leaks the resource that was held in the data structure.
Moving forward in time to C++, this latter problem of losing access to resources was solved by the inclusion of destructors, enabling RAII (see Item 11). Now, the things on the stack have the ability to tidy themselves up: if the object holds some kind of resource, the destructor can tidy it up, and the C++ compiler guarantees that the destructor of an object on the stack gets called as part of tidying up the stack frame:
// C++ code.File::~File(){std::cout<<"~File(): close fd "<<fd<<"\n";close(fd);fd=-1;}
The caller now gets an (invalid) pointer to an object that’s been destroyed and its resources reclaimed:
~File(): close fd 3 in caller: file at 0x7ff7b6a7c438 has fd=-1
However, C++ did nothing to help with the problem of dangling pointers: it’s still possible to hold onto a pointer to an object that’s gone (with a destructor that has been called):
// C++ code.voidinvestigate_file(File*f){longarray[4]={1,2,3,4};// put things on the stackstd::cout<<"in function: file at "<<f<<" has fd="<<f->fd<<"\n";}
in function: file at 0x7ff7b6a7c438 has fd=-183042004
As a C/C++ programmer, it’s up to you to notice this and make sure that you don’t dereference a pointer that points to something that’s gone. Alternatively, if you’re an attacker and you find one of these dangling pointers, you’re more likely to cackle maniacally and gleefully dereference the pointer on your way to an exploit.
Enter Rust. One of Rust’s core attractions is that it fundamentally solves the problem of dangling pointers, immediately solving a large fraction of security problems.1
Doing so requires moving the concept of lifetimes from the background (where
C/C++ programmers just have to know to
watch out for them, without any language support) to the foreground: every type that includes an ampersand & has
an associated lifetime ('a), even if the compiler lets you omit mention of it much of the time.
Scope of a Lifetime
The lifetime of an item on the stack is the period where that item is guaranteed to stay in the same place; in other words, this is exactly the period where a reference (pointer) to the item is guaranteed not to become invalid.
This starts at the point where the item is created, and extends to where it is either dropped (Rust’s equivalent to object destruction in C++) or moved.
The ubiquity of the latter is sometimes surprising for programmers coming from C/C++: Rust moves items from one place on the stack to another, or from the stack to the heap, or from the heap to the stack, in lots of situations.
Precisely where an item gets automatically dropped depends on whether an item has a name or not.
Local variables and function parameters have names, and the corresponding item’s lifetime starts when the item is created and the name is populated:
-
For a local variable: at the
let var = ...declaration -
For a function parameter: as part of setting up the execution frame for the function invocation
The lifetime for a named item ends when the item is either moved somewhere else or when the name goes out of scope:
#[derive(Debug, Clone)]/// Definition of an item of some kind.pubstructItem{contents:u32,}
{letitem1=Item{contents:1};// `item1` created hereletitem2=Item{contents:2};// `item2` created hereprintln!("item1 = {item1:?}, item2 = {item2:?}");consuming_fn(item2);// `item2` moved here}// `item1` dropped here
It’s also possible to build an item “on the fly,” as part of an expression that’s then fed into something else. These unnamed temporary items are then dropped when they’re no longer needed. One oversimplified but helpful way to think about this is to imagine that each part of the expression gets expanded to its own block, with temporary variables being inserted by the compiler. For example, an expression like:
letx=f((a+b)*2);
would be roughly equivalent to:
letx={lettemp1=a+b;{lettemp2=temp1*2;f(temp2)}// `temp2` dropped here};// `temp1` dropped here
By the time execution reaches the semicolon at the end of the original line, the temporaries have all been dropped.
One way to see what the compiler calculates as an item’s lifetime is to insert a deliberate error for the borrow checker (Item 15) to detect. For example, hold onto a reference to an item beyond the scope of the item’s lifetime:
The error message indicates the exact endpoint of item’s lifetime:
error[E0597]: `item` does not live long enough
--> src/main.rs:190:13
|
189 | let item = Item { contents: 42 };
| ---- binding `item` declared here
190 | r = &item;
| ^^^^^ borrowed value does not live long enough
191 | }
| - `item` dropped here while still borrowed
192 | println!("r.contents = {}", r.contents);
| ---------- borrow later used here
Similarly, for an unnamed temporary:
the error message shows the endpoint at the end of the expression:
error[E0716]: temporary value dropped while borrowed
--> src/main.rs:209:46
|
209 | let r: &Item = fn_returning_ref(&mut Item { contents: 42 });
| ^^^^^^^^^^^^^^^^^^^^^ - temporary
| | value is freed at the
| | end of this statement
| |
| creates a temporary value which is
| freed while still in use
210 | println!("r.contents = {}", r.contents);
| ---------- borrow later used here
|
= note: consider using a `let` binding to create a longer lived value
One final point about the lifetimes of references: if the compiler can prove to itself that there is no use of a reference beyond a certain point in the code, then it treats the endpoint of the reference’s lifetime as the last place it’s used, rather than at the end of the enclosing scope. This feature, known as non-lexical lifetimes, allows the borrow checker to be a little bit more generous:
{// `s` owns the `String`.letmuts:String="Hello, world".to_string();// Create a mutable reference to the `String`.letgreeting=&muts[..5];greeting.make_ascii_uppercase();// .. no use of `greeting` after this point// Creating an immutable reference to the `String` is allowed,// even though there's a mutable reference still in scope.letr:&str=&s;println!("s = '{}'",r);// s = 'HELLO, world'}// The mutable reference `greeting` would naively be dropped here.
Algebra of Lifetimes
Although lifetimes are ubiquitous when dealing with references in Rust, you don’t get to specify them in any
detail—there’s no way to say, “I’m dealing with a lifetime that extends from line 17 to line 32 of
ref.rs.” Instead, your code refers to lifetimes with arbitrary names, conventionally 'a, 'b, 'c,
…, and the compiler has its own internal, inaccessible representation of what that equates to in the source code.
(The one exception to this is the 'static lifetime, which is a special case that’s covered in a subsequent section.)
You don’t get to do much with these lifetime names; the main thing that’s possible is to compare one name with another, repeating a name to indicate that two lifetimes are the “same.”
This algebra of lifetimes is easiest to illustrate with function signatures: if the inputs and outputs of a function deal with references, what’s the relationship between their lifetimes?
The most common case is a function that receives a single reference as input and emits a reference as output. The
output reference must have a lifetime, but what can it be? There’s only one possibility (other than 'static) to
choose from: the lifetime of the input, which means that they both share the same name, say, 'a. Adding that name as a
lifetime annotation to both types gives:
pubfnfirst<'a>(data:&'a[Item])->Option<&'aItem>{// ...}
Because this variant is so common, and because there’s (almost) no choice about what the output lifetime can be, Rust has lifetime elision rules that mean you don’t have to explicitly write the lifetime names for this case. A more idiomatic version of the same function signature would be the following:
pubfnfirst(data:&[Item])->Option<&Item>{// ...}
The references involved still have lifetimes—the elision rule just means that you don’t have to make up an arbitrary lifetime name and use it in both places.
What if there’s more than one choice of input lifetimes to map to an output lifetime? In this case, the compiler can’t figure out what to do:
error[E0106]: missing lifetime specifier
--> src/main.rs:56:55
|
56 | pub fn find(haystack: &[u8], needle: &[u8]) -> Option<&[u8]> {
| ----- ----- ^ expected named
| lifetime parameter
|
= help: this function's return type contains a borrowed value, but the
signature does not say whether it is borrowed from `haystack` or
`needle`
help: consider introducing a named lifetime parameter
|
56 | pub fn find<'a>(haystack: &'a [u8], needle: &'a [u8]) -> Option<&'a [u8]> {
| ++++ ++ ++ ++
A shrewd guess based on the function and parameter names is that the intended lifetime for the output here is expected
to match the haystack input:
pubfnfind<'a,'b>(haystack:&'a[u8],needle:&'b[u8],)->Option<&'a[u8]>{// ...}
Interestingly, the compiler suggested a different alternative: having both inputs to the function use the same
lifetime 'a. For example, the following is a function where this combination of lifetimes might make sense:
pubfnsmaller<'a>(left:&'aItem,right:&'aItem)->&'aItem{// ...}
This appears to imply that the two input lifetimes are the “same,” but the scare quotes (here and previously) are included to signify that that’s not quite what’s going on.
The raison d’être of lifetimes is to ensure that references to items don’t outlive the items themselves; with this in
mind, an output lifetime 'a that’s the “same” as an input lifetime 'a just means that the input has to live longer
than the output.
When there are two input lifetimes 'a that are the “same,” that just means that the output lifetime has to be
contained within the lifetimes of both of the inputs:
{letouter=Item{contents:7};{letinner=Item{contents:8};{letmin=smaller(&inner,&outer);println!("smaller of {inner:?} and {outer:?} is {min:?}");}// `min` dropped}// `inner` dropped}// `outer` dropped
To put it another way, the output lifetime has to be subsumed within the smaller of the lifetimes of the two inputs.
In contrast, if the output lifetime is unrelated to the lifetime of one of the inputs, then there’s no requirement for those lifetimes to nest:
{lethaystack=b"123456789";// start of lifetime 'aletfound={letneedle=b"234";// start of lifetime 'bfind(haystack,needle)};// end of lifetime 'bprintln!("found={:?}",found);// `found` used within 'a, outside of 'b}// end of lifetime 'a
Lifetime Elision Rules
In addition to the “one in, one out” elision rule described in “Algebra of Lifetimes”, there are two other elision rules that mean that lifetime names can be omitted.
The first occurs when there are no references in the outputs from a function; in this case, each of the input references automatically gets its own lifetime, different from any of the other input parameters.
The second occurs for methods that use a reference to self (either &self or &mut self); in this case, the
compiler assumes that any output references take the lifetime of self, as this turns out to be (by far) the most
common situation.
Here’s a summary of the elision rules for functions:
-
One input, one or more outputs: assume outputs have the “same” lifetime as the input:
fnf(x:&Item)(&Item,&Item)// ... is equivalent to ...fnf<'a>(x:&'aItem)(&'aItem,&'aItem) -
Multiple inputs, no output: assume all the inputs have different lifetimes:
fnf(x:&Item,y:&Item,z:&Item)i32// ... is equivalent to ...fnf<'a,'b,'c>(x:&'aItem,y:&'bItem,z:&'cItem)i32 -
Multiple inputs including
&self, one or more outputs: assume output lifetime(s) are the “same” as&self’s lifetime:fnf(&self,y:&Item,z:&Item)&Thing// ... is equivalent to ...fnf(&'aself,y:&'bItem,z:&'cItem)&'aThing
Of course, if the elided lifetime names don’t match what you want, you can always explicitly write lifetime names that specify which lifetimes are related to each other. In practice, this is likely to be triggered by a compiler error that indicates that the elided lifetimes don’t match how the function or its caller are using the references involved.
The 'static Lifetime
The previous section described various possible mappings between the input and output reference lifetimes for a function, but it neglected to cover one special case. What happens if there are no input lifetimes, but the output return value includes a reference anyway?
error[E0106]: missing lifetime specifier
--> src/main.rs:471:28
|
471 | pub fn the_answer() -> &Item {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there
is no value for it to be borrowed from
help: consider using the `'static` lifetime
|
471 | pub fn the_answer() -> &'static Item {
| +++++++
The only allowed possibility is for the returned reference to have a lifetime that’s guaranteed to never go out of
scope. This is indicated by the special lifetime 'static, which is also the only lifetime that
has a specific name rather than an arbitrary placeholder name:
pubfnthe_answer()->&'staticItem{
The simplest way to get something with the 'static lifetime is to take a reference to a global variable that’s
been marked as static:
staticANSWER:Item=Item{contents:42};pubfnthe_answer()->&'staticItem{&ANSWER}
The Rust compiler guarantees that a static item always has the same address for the entire duration of the program
and never moves. This means that a reference to a static item has a 'static lifetime, logically enough.
In many cases, a reference to a const item will also be
promoted to have a 'static lifetime, but
there are a couple of minor complications to be aware of. The first is that this promotion doesn’t happen if the type
involved has a destructor or interior
mutability:
error[E0515]: cannot return reference to temporary value
--> src/main.rs:520:9
|
520 | &ANSWER
| ^------
| ||
| |temporary value created here
| returns a reference to data owned by the current function
The second potential complication is that only the value of a const is guaranteed to be the same everywhere; the
compiler is allowed to make as many copies as it likes, wherever the variable is used. If you’re doing nefarious things
that rely on the underlying pointer value behind the 'static reference, be aware that multiple memory
locations may be involved.
There’s one more possible way to get something with a 'static lifetime. The key promise of 'static is that the
lifetime should outlive any other lifetime in the program; a value that’s allocated on the heap but never freed
also satisfies this constraint.
A normal heap-allocated Box<T> doesn’t work for this, because there’s no guarantee (as described in the next section)
that the item won’t get dropped along the way:
error[E0597]: `boxed` does not live long enough
--> src/main.rs:344:32
|
343 | let boxed = Box::new(Item { contents: 12 });
| ----- binding `boxed` declared here
344 | let r: &'static Item = &boxed;
| ------------- ^^^^^^ borrowed value does not live long enough
| |
| type annotation requires that `boxed` is borrowed for `'static`
345 | println!("'static item is {:?}", r);
346 | }
| - `boxed` dropped here while still borrowed
However, the Box::leak function
converts an owned Box<T> to a mutable reference to T. There’s no longer an owner for the value, so it can never be
dropped—which satisfies the requirements for the 'static lifetime:
{letboxed=Box::new(Item{contents:12});// `leak()` consumes the `Box<T>` and returns `&mut T`.letr:&'staticItem=Box::leak(boxed);println!("'static item is {:?}",r);}// `boxed` not dropped here, as it was already moved into `Box::leak()`// Because `r` is now out of scope, the `Item` is leaked forever.
The inability to drop the item also means that the memory that holds the item can never be reclaimed using safe Rust, possibly leading to a permanent memory leak. (Note that leaking memory doesn’t violate Rust’s memory safety guarantees—an item in memory that you can no longer access is still safe.)
Lifetimes and the Heap
The discussion so far has concentrated on the lifetimes of items on the stack, whether function parameters, local variables, or temporaries. But what about items on the heap?
The key thing to realize about heap values is that every item has an owner (excepting special cases like the deliberate
leaks described in the previous section). For example, a simple Box<T> puts the T value on the heap, with the owner
being the variable holding the Box<T>:
{letb:Box<Item>=Box::new(Item{contents:42});}// `b` dropped here, so `Item` dropped too.
The owning Box<Item> drops its contents when it goes out of scope, so the lifetime of the Item on the heap is the
same as the lifetime of the Box<Item> variable on the stack.
The owner of a value on the heap may itself be on the heap rather than the stack, but then who owns the owner?
{letb:Box<Item>=Box::new(Item{contents:42});letbb:Box<Box<Item>>=Box::new(b);// `b` moved onto heap here}// `bb` dropped here, so `Box<Item>` dropped too, so `Item` dropped too.
The chain of ownership has to end somewhere, and there are only two possibilities:
-
The chain ends at a local variable or function parameter—in which case the lifetime of everything in the chain is just the lifetime
'aof that stack variable. When the stack variable goes out of scope, everything in the chain is dropped too. -
The chain ends at a global variable marked as
static—in which case the lifetime of everything in the chain is'static. Thestaticvariable never goes out of scope, so nothing in the chain ever gets automatically dropped.
As a result, the lifetimes of items on the heap are fundamentally tied to stack lifetimes.
Lifetimes in Data Structures
The earlier section on the algebra of lifetimes concentrated on inputs and outputs for functions, but there are similar concerns when references are stored in data structures.
If we try to sneak a reference into a data structure without mentioning an associated lifetime, the compiler brings us up sharply:
error[E0106]: missing lifetime specifier
--> src/main.rs:548:19
|
548 | pub item: &Item,
| ^ expected named lifetime parameter
|
help: consider introducing a named lifetime parameter
|
546 ~ pub struct ReferenceHolder<'a> {
547 | pub index: usize,
548 ~ pub item: &'a Item,
|
As usual, the compiler error message tells us what to do. The first part is simple enough: give the reference type an
explicit lifetime name 'a, because there are no lifetime elision rules when using references in data structures.
The second part is less obvious and has deeper consequences: the data structure itself has to have a
lifetime parameter <'a> that matches the lifetime of the reference contained within it:
// Lifetime parameter required due to field with reference.pubstructReferenceHolder<'a>{pubindex:usize,pubitem:&'aItem,}
The lifetime parameter for the data structure is infectious: any containing data structure that uses the type also has to acquire a lifetime parameter:
// Lifetime parameter required due to field that is of a// type that has a lifetime parameter.pubstructRefHolderHolder<'a>{pubinner:ReferenceHolder<'a>,}
The need for a lifetime parameter also applies if the data structure contains slice types, as these are again references to borrowed data.
If a data structure contains multiple fields that have associated lifetimes, then you have to choose what combination of lifetimes is appropriate. An example that finds common substrings within a pair of strings is a good candidate to have independent lifetimes:
/// Locations of a substring that is present in/// both of a pair of strings.pubstructLargestCommonSubstring<'a,'b>{publeft:&'astr,pubright:&'bstr,}/// Find the largest substring present in both `left`/// and `right`.pubfnfind_common<'a,'b>(left:&'astr,right:&'bstr,)->Option<LargestCommonSubstring<'a,'b>>{// ...}
whereas a data structure that references multiple places within the same string would have a common lifetime:
/// First two instances of a substring that is repeated/// within a string.pubstructRepeatedSubstring<'a>{pubfirst:&'astr,pubsecond:&'astr,}/// Find the first repeated substring present in `s`.pubfnfind_repeat<'a>(s:&'astr)->Option<RepeatedSubstring<'a>>{// ...}
The propagation of lifetime parameters makes sense: anything that contains a reference, no matter how deeply nested, is valid only for the lifetime of the item referred to. If that item is moved or dropped, then the whole chain of data structures is no longer valid.
However, this also means that data structures involving references are harder to use—the owner of the data
structure has to ensure that the lifetimes all line up. As a result, prefer data structures that own their
contents where possible, particularly if the code doesn’t need to be highly optimized (Item 20). Where that’s not
possible, the various smart pointer types (e.g., Rc)
described in Item 8 can help untangle the lifetime
constraints.
Anonymous Lifetimes
When it’s not possible to stick to data structures that own their contents, the data structure will necessarily end up with a lifetime parameter, as described in the previous section. This can create a slightly unfortunate interaction with the lifetime elision rules described earlier in the Item.
For example, consider a function that returns a data structure with a lifetime parameter. The fully explicit signature for this function makes the lifetimes involved clear:
pubfnfind_one_item<'a>(items:&'a[Item])->ReferenceHolder<'a>{// ...}
However, the same signature with lifetimes elided can be a little misleading:
pubfnfind_one_item(items:&[Item])->ReferenceHolder{// ...}
Because the lifetime parameter for the return type is elided, a human reading the code doesn’t get much of a hint that lifetimes are involved.
The anonymous lifetime '_ allows you to mark an elided lifetime as being present, without having to fully
restore all of the lifetime names:
pubfnfind_one_item(items:&[Item])->ReferenceHolder<'_>{// ...}
Roughly speaking, the '_ marker asks the compiler to invent a unique lifetime name for us, which we can use in
situations where we never need to use the name elsewhere.
That means it’s also useful for other lifetime elision scenarios. For example, the declaration for the
fmt method of the
Debug trait uses the anonymous lifetime to indicate that
the Formatter instance has a different lifetime than &self, but it’s not important what that lifetime’s name is:
pubtraitDebug{fnfmt(&self,f:&mutFormatter<'_>)->Result<(),Error>;}
Things to Remember
-
All Rust references have an associated lifetime, indicated by a lifetime label (e.g.,
'a). The lifetime labels for function parameters and return values can be elided in some common cases (but are still present under the covers). -
Any data structure that (transitively) includes a reference has an associated lifetime parameter; as a result, it’s often easier to work with data structures that own their contents.
-
The
'staticlifetime is used for references to items that are guaranteed never to go out of scope, such as global data or items on the heap that have been explicitly leaked. -
Lifetime labels can be used only to indicate that lifetimes are the “same,” which means that the output lifetime is contained within the input lifetime(s).
-
The anonymous lifetime label
'_can be used in places where a specific lifetime label is not needed.
Item 15: Understand the borrow checker
Values in Rust have an owner, but that owner can lend the values out to other places in the code. This borrowing mechanism involves the creation and use of references, subject to rules policed by the borrow checker—the subject of this Item.
Under the covers, Rust’s references use the same kind of pointer values (Item 8) that are so prevalent in C or C++ code but are girded with rules and restrictions to make sure that the sins of C/C++ are avoided. As a quick comparison:
-
Like a C/C++ pointer, a Rust reference is created with an ampersand:
&value. -
Like a C++ reference, a Rust reference can never be
nullptr. -
Like a C/C++ pointer or reference, a Rust reference can be modified after creation to refer to something different.
-
Unlike C++, producing a reference from a value always involves an explicit (
&) conversion—if you see code likef(value), you know thatfis receiving ownership of the value. (However, it may be ownership of a copy of the item, if thevalue’s type implementsCopy—see Item 10.) -
Unlike C/C++, the mutability of a newly created reference is always explicit (
&mut). If you see code likef(&value), you know thatvaluewon’t be modified (i.e., isconstin C/C++ terminology). Only expressions likef(&mut value)have the potential to change the contents ofvalue.2
The most important difference between a C/C++ pointer and a Rust reference is indicated by the term borrow: you can take a reference (pointer) to an item, but you can’t keep that reference forever. In particular, you can’t keep it longer than the lifetime of the underlying item, as tracked by the compiler and explored in Item 14.
These restrictions on the use of references enable Rust to make its memory safety guarantees, but they also mean that you have to accept the cognitive costs of the borrow rules, and accept that it will change how you design your software—particularly its data structures.
This Item starts by describing what Rust references can do, and the borrow checker’s rules for using them. The rest of the Item focuses on dealing with the consequences of those rules: how to refactor, rework, and redesign your code so that you can win fights against the borrow checker.
Access Control
There are three ways to access the contents of a Rust item: via the item’s owner (item), a reference
(&item), or a mutable reference (&mut item). Each of these ways of accessing the item comes with different powers over the item. Putting things roughly in
terms of the CRUD (create/read/update/delete)
model for storage (using Rust’s drop terminology in place of delete):
-
The owner of an item gets to create it, read from it, update it, and drop it.
-
A mutable reference can be used to read from the underlying item and update it.
-
A (normal) reference can be used only to read from the underlying item.
There’s an important Rust-specific aspect to these data access rules: only the item’s owner can move the item. This makes sense if you think of a move as being some combination of creating (in the new location) and dropping the item’s memory (at the old location).
This can lead to some oddities for code that has a mutable reference to an item. For example, it’s OK to overwrite an
Option:
/// Some data structure used by the code.#[derive(Debug)]pubstructItem{pubcontents:i64,}/// Replace the content of `item` with `val`.pubfnreplace(item:&mutOption<Item>,val:Item){*item=Some(val);}
but a modification to also return the previous value falls foul of the move restriction:3
error[E0507]: cannot move out of `*item` which is behind a mutable reference --> src/main.rs:34:24 | 34 | let previous = *item; // move out | ^^^^^ move occurs because `*item` has type | `Option<inner::Item>`, which does not | implement the `Copy` trait | help: consider removing the dereference here | 34 - let previous = *item; // move out 34 + let previous = item; // move out |
Although it’s valid to read from a mutable reference, this code is attempting to move the value out, just prior to replacing the moved value with a new value—in an attempt to avoid making a copy of the original value. The borrow checker has to be conservative and notices that there’s a moment between the two lines when the mutable reference isn’t referring to a valid value.
As humans, we can see that this combined operation—extracting the old value and replacing it with a new
value—is both safe and useful, so the standard library provides the
std::mem::replace function to perform it. Under
the covers, replace uses unsafe (as per Item 16) to perform the swap in one go:
/// Replace the content of `item` with `val`, returning the previous/// contents.pubfnreplace(item:&mutOption<Item>,val:Item)->Option<Item>{std::mem::replace(item,Some(val))// returns previous value}
For Option types in particular, this is a sufficiently common pattern that there is also a
replace method on Option itself:
/// Replace the content of `item` with `val`, returning the previous/// contents.pubfnreplace(item:&mutOption<Item>,val:Item)->Option<Item>{item.replace(val)// returns previous value}
Borrow Rules
There are two key rules to remember when borrowing references in Rust.
The first rule is that the scope of any reference must be smaller than the lifetime of the item that it refers to. Lifetimes are explored in detail in Item 14, but it’s worth noting that the compiler has special behavior for reference lifetimes; the non-lexical lifetimes feature allows reference lifetimes to be shrunk so they end at the point of last use, rather than the enclosing block.
The second rule for borrowing references is that, in addition to the owner of an item, there can be either of the following:
However, there can’t be both (at the same point in the code).
So a function that takes multiple immutable references can be fed references to the same item:
/// Indicate whether both arguments are zero.fnboth_zero(left:&Item,right:&Item)->bool{left.contents==0&&right.contents==0}letitem=Item{contents:0};assert!(both_zero(&item,&item));
but one that takes mutable references cannot:
error[E0499]: cannot borrow `item` as mutable more than once at a time
--> src/main.rs:131:26
|
131 | zero_both(&mut item, &mut item);
| --------- --------- ^^^^^^^^^ second mutable borrow occurs here
| | |
| | first mutable borrow occurs here
| first borrow later used by call
The same restriction is true for a function that uses a mixture of mutable and immutable references:
error[E0502]: cannot borrow `item` as immutable because it is also borrowed
as mutable
--> src/main.rs:159:30
|
159 | copy_contents(&mut item, &item);
| ------------- --------- ^^^^^ immutable borrow occurs here
| | |
| | mutable borrow occurs here
| mutable borrow later used by call
The borrowing rules allow the compiler to make better decisions around aliasing: tracking when two different pointers may or may not refer to the same underlying item in memory. If the compiler can be sure (as in Rust) that the memory location pointed to by a collection of immutable references cannot be altered via an aliased mutable reference, then it can generate code that has the following advantages:
- It’s better optimized
-
Values can be, for example, cached in registers, secure in the knowledge that the underlying memory contents will not change in the meantime.
- It’s safer
-
Data races arising from unsynchronized access to memory between threads (Item 17) are not possible.
Owner Operations
One important consequence of the rules around the existence of references is that they also affect what operations can be performed by the owner of the item. One way to help understand this is to imagine that operations involving the owner are performed by creating and using references under the covers.
For example, an attempt to update the item via its owner is equivalent to making an ephemeral mutable reference and then updating the item via that reference. If another reference already exists, this notional second mutable reference can’t be created:
error[E0506]: cannot assign to `item.contents` because it is borrowed
--> src/main.rs:200:5
|
199 | let r = &item;
| ----- `item.contents` is borrowed here
200 | item.contents = 0;
| ^^^^^^^^^^^^^^^^^ `item.contents` is assigned to here but it was
| already borrowed
...
203 | println!("reference to item is {:?}", r);
| - borrow later used here
On the other hand, because multiple immutable references are allowed, it’s OK for the owner to read from the item while there are immutable references in existence:
letitem=Item{contents:42};letr=&item;letcontents=item.contents;// ^^^ Reading from the item is roughly equivalent to:// let contents = (&item).contents;println!("reference to item is {:?}",r);
but not if there is a mutable reference:
error[E0503]: cannot use `item.contents` because it was mutably borrowed
--> src/main.rs:231:20
|
230 | let r = &mut item;
| --------- `item` is borrowed here
231 | let contents = item.contents; // i64 implements `Copy`
| ^^^^^^^^^^^^^ use of borrowed `item`
232 | r.contents = 0;
| -------------- borrow later used here
Finally, the existence of any sort of active reference prevents the owner of the item from moving or dropping the item, exactly because this would mean that the reference now refers to an invalid item:
error[E0505]: cannot move out of `item` because it is borrowed
--> src/main.rs:170:20
|
168 | let item = Item { contents: 42 };
| ---- binding `item` declared here
169 | let r = &item;
| ----- borrow of `item` occurs here
170 | let new_item = item; // move
| ^^^^ move out of `item` occurs here
171 | println!("reference to item is {:?}", r);
| - borrow later used here
This is a scenario where the non-lexical lifetime feature described in Item 14 is particularly helpful, because (roughly speaking) it terminates the lifetime of a reference at the point where the reference is last used, rather than at the end of the enclosing scope. Moving the final use of the reference up before the move happens means that the compilation error evaporates:
letitem=Item{contents:42};letr=&item;println!("reference to item is {:?}",r);// Reference `r` is still in scope but has no further use, so it's// as if the reference has already been dropped.letnew_item=item;// move works OK
Winning Fights Against the Borrow Checker
Newcomers to Rust (and even more experienced folk!) can often feel that they are spending time fighting against the borrow checker. What kinds of things can help you win these battles?
Local code refactoring
The first tactic is to pay attention to the compiler’s error messages, because the Rust developers have put a lot of effort into making them as helpful as possible:
error[E0716]: temporary value dropped while borrowed
--> src/main.rs:353:23
|
353 | let found = find(&format!("{} to search", "Text"), "ex");
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ - temporary value
| | is freed at the end of this statement
| |
| creates a temporary value which is freed while still in
| use
354 | if let Some(text) = found {
| ----- borrow later used here
|
= note: consider using a `let` binding to create a longer lived value
The first part of the error message is the important part, because it describes what borrowing rule the compiler thinks you have broken and why. As you encounter enough of these errors—which you will—you can build up an intuition about the borrow checker that matches the more theoretical version encapsulated in the previously stated rules.
The second part of the error message includes the compiler’s suggestions for how to fix the problem, which in this case is simple:
lethaystack=format!("{} to search","Text");letfound=find(&haystack,"ex");ifletSome(text)=found{println!("Found '{text}'!");}// `found` now references `haystack`, which outlives it
This is an instance of one of the two simple code tweaks that can help mollify the borrow checker:
- Lifetime extension
-
Convert a temporary (whose lifetime extends only to the end of the expression) into a new named local variable (whose lifetime extends to the end of the block) with a
letbinding. - Lifetime reduction
-
Add an additional block
{ ... }around the use of a reference so that its lifetime ends at the end of the new block.
The latter is less common, because of the existence of non-lexical lifetimes: the compiler can often figure out that a reference is no longer used, ahead of its official drop point at the end of the block. However, if you do find yourself repeatedly introducing an artificial block around similar small chunks of code, consider whether that code should be encapsulated into a method of its own.
The compiler’s suggested fixes are helpful for simpler problems, but as you write more sophisticated code, you’re likely to find that the suggestions are no longer useful and that the explanation of the broken borrowing rule is harder to follow:
error[E0515]: cannot return reference to temporary value
--> src/main.rs:293:35
|
293 | check_item(x.as_ref().map(|r| r.borrow().deref()));
| ----------^^^^^^^^
| |
| returns a reference to data owned by the
| current function
| temporary value created here
In this situation, it can be helpful to temporarily introduce a sequence of local variables, one for each step of a complicated transformation, and each with an explicit type annotation:
error[E0515]: cannot return reference to function parameter `r`
--> src/main.rs:305:40
|
305 | let x3: Option<&Item> = x2.map(|r| r.deref());
| ^^^^^^^^^ returns a reference to
| data owned by the current function
This narrows down the precise conversion that the compiler is complaining about, which in turn allows the code to be restructured:
letx:Option<Rc<RefCell<Item>>>=Some(Rc::new(RefCell::new(Item{contents:42})));letx1:Option<&Rc<RefCell<Item>>>=x.as_ref();letx2:Option<std::cell::Ref<Item>>=x1.map(|r|r.borrow());matchx2{None=>check_item(None),Some(r)=>{letx3:&Item=r.deref();check_item(Some(x3));}}
Once the underlying problem is clear and has been fixed, you’re then free to recoalesce the local variables back together so that you can pretend you got it right all along:
letx=Some(Rc::new(RefCell::new(Item{contents:42})));matchx.as_ref().map(|r|r.borrow()){None=>check_item(None),Some(r)=>check_item(Some(r.deref())),};
Data structure design
The next tactic that helps for battles against the borrow checker is to design your data structures with the borrow checker in mind. The panacea is your data structures owning all of the data that they use, avoiding any use of references and the consequent propagation of lifetime annotations described in Item 14.
However, that’s not always possible for real-world data structures; any time the internal connections of the data
structure form a graph that’s more interconnected than a tree pattern (a Root that owns multiple Branches, each of
which owns multiple Leafs, etc.), then simple single-ownership isn’t possible.
To take a simple example, imagine a simple register of guest details recorded in the order in which they arrive:
#[derive(Clone, Debug)]pubstructGuest{name:String,address:String,// ... many other fields}/// Local error type, used later.#[derive(Clone, Debug)]pubstructError(String);/// Register of guests recorded in order of arrival.#[derive(Default, Debug)]pubstructGuestRegister(Vec<Guest>);implGuestRegister{pubfnregister(&mutself,guest:Guest){self.0.push(guest)}pubfnnth(&self,idx:usize)->Option<&Guest>{self.0.get(idx)}}
If this code also needs to be able to efficiently look up guests by arrival and alphabetically by name, then there are fundamentally two distinct data structures involved, and only one of them can own the data.
If the data involved is both small and immutable, then just cloning the data can be a quick solution:
modcloned{usesuper::Guest;#[derive(Default, Debug)]pubstructGuestRegister{by_arrival:Vec<Guest>,by_name:std::collections::BTreeMap<String,Guest>,}implGuestRegister{pubfnregister(&mutself,guest:Guest){// Requires `Guest` to be `Clone`self.by_arrival.push(guest.clone());// Not checking for duplicate names to keep this// example shorter.self.by_name.insert(guest.name.clone(),guest);}pubfnnamed(&self,name:&str)->Option<&Guest>{self.by_name.get(name)}pubfnnth(&self,idx:usize)->Option<&Guest>{self.by_arrival.get(idx)}}}
However, this approach of cloning copes poorly if the data can be modified. For example, if the address for a Guest
needs to be updated, you have to find both versions and ensure they stay in sync.
Another possible approach is to add another layer of indirection, treating the Vec<Guest> as the owner and using an
index into that vector for the name lookups:
modindexed{usesuper::Guest;#[derive(Default)]pubstructGuestRegister{by_arrival:Vec<Guest>,// Map from guest name to index into `by_arrival`.by_name:std::collections::BTreeMap<String,usize>,}implGuestRegister{pubfnregister(&mutself,guest:Guest){// Not checking for duplicate names to keep this// example shorter.self.by_name.insert(guest.name.clone(),self.by_arrival.len());self.by_arrival.push(guest);}pubfnnamed(&self,name:&str)->Option<&Guest>{letidx=*self.by_name.get(name)?;self.nth(idx)}pubfnnamed_mut(&mutself,name:&str)->Option<&mutGuest>{letidx=*self.by_name.get(name)?;self.nth_mut(idx)}pubfnnth(&self,idx:usize)->Option<&Guest>{self.by_arrival.get(idx)}pubfnnth_mut(&mutself,idx:usize)->Option<&mutGuest>{self.by_arrival.get_mut(idx)}}}
In this approach, each guest is represented by a single Guest item, which allows the named_mut() method to return a
mutable reference to that item. That in turn means that changing a guest’s address works fine—the (single)
Guest is owned by the Vec and will always be reached that way under the covers:
letnew_address="123 Bigger House St";// Real code wouldn't assume that "Bob" exists...ledger.named_mut("Bob").unwrap().address=new_address.to_string();assert_eq!(ledger.named("Bob").unwrap().address,new_address);
However, if guests can deregister, it’s easy to inadvertently introduce a bug:
Now that the Vec can be shuffled, the by_name indexes into it are effectively acting like pointers, and we’ve
reintroduced a world where a bug can lead those “pointers” to point to nothing (beyond the Vec bounds) or to point to
incorrect data:
The code here uses a custom Debug implementation (not shown), in order to reduce the size of the output; this
truncated output is as follows:
Register starts as: {
by_arrival: [{n: 'Alice', ...}, {n: 'Bob', ...}, {n: 'Charlie', ...}]
by_name: {"Alice": 0, "Bob": 1, "Charlie": 2}
}
Register after deregister(0): {
by_arrival: [{n: 'Bob', ...}, {n: 'Charlie', ...}]
by_name: {"Alice": 0, "Bob": 1, "Charlie": 2}
}
Alice is Some(Guest { name: "Bob", address: "234 Bobton" })
Bob is Some(Guest { name: "Charlie", address: "345 Charlieland" })
Charlie is None
The preceding example showed a bug in the deregister code, but even after that bug is fixed, there’s nothing to prevent a
caller from hanging onto an index value and using it with nth()—getting unexpected or invalid results.
The core problem is that the two data structures need to be kept in sync. A better approach for handling this is to use
Rust’s smart pointers instead (Item 8). Shifting to a combination of
Rc and
RefCell avoids the invalidation problems of using indices as
pseudo-pointers. Updating the example—but keeping the bug in it—gives the
following:
Register starts as: {
by_arrival: [{n: 'Alice', ...}, {n: 'Bob', ...}, {n: 'Charlie', ...}]
by_name: [("Alice", {n: 'Alice', ...}), ("Bob", {n: 'Bob', ...}),
("Charlie", {n: 'Charlie', ...})]
}
Register after deregister(0): {
by_arrival: [{n: 'Bob', ...}, {n: 'Charlie', ...}]
by_name: [("Alice", {n: 'Alice', ...}), ("Bob", {n: 'Bob', ...}),
("Charlie", {n: 'Charlie', ...})]
}
Alice is Some(RefCell { value: Guest { name: "Alice",
address: "123 Aliceville" } })
Bob is Some(RefCell { value: Guest { name: "Bob",
address: "234 Bobton" } })
Charlie is Some(RefCell { value: Guest { name: "Charlie",
address: "345 Charlieland" } })
The output no longer has mismatched names, but a lingering entry for Alice remains until we fix the bug by ensuring that the two collections stay in sync:
pubfnderegister(&mutself,idx:usize)->Result<(),Error>{ifidx>=self.by_arrival.len(){returnErr(Error::new("out of bounds"));}letguest:Rc<RefCell<Guest>>=self.by_arrival.remove(idx);self.by_name.remove(&guest.borrow().name);Ok(())}
Register after deregister(0): {
by_arrival: [{n: 'Bob', ...}, {n: 'Charlie', ...}]
by_name: [("Bob", {n: 'Bob', ...}), ("Charlie", {n: 'Charlie', ...})]
}
Alice is None
Bob is Some(RefCell { value: Guest { name: "Bob",
address: "234 Bobton" } })
Charlie is Some(RefCell { value: Guest { name: "Charlie",
address: "345 Charlieland" } })
Smart pointers
The final variation of the previous section is an example of a more general approach: use Rust’s smart pointers for interconnected data structures.
Item 8 described the most common smart pointer types provided by Rust’s standard library:
-
Rcallows shared ownership, with multiple things referring to the same item.Rcis often combined withRefCell. -
RefCellallows interior mutability so that internal state can be modified without needing a mutable reference. This comes at the cost of moving borrow checks from compile time to runtime. -
Arcis the multithreading equivalent toRc. -
Mutex(andRwLock) allows interior mutability in a multithreading environment, roughly equivalent toRefCell.
For programmers who are adapting from C++ to Rust, the most common tool to reach for is Rc<T> (and its
thread-safe cousin Arc<T>), often combined with RefCell (or the thread-safe alternative Mutex). A naive
translation of shared pointers (or even std::shared_ptrs) to Rc<RefCell<T>> instances will
generally give something that works in Rust without too much complaint from the borrow checker.
However, this approach means that you miss out on some of the protections that Rust gives you. In particular,
situations where the same item is mutably borrowed (via
borrow_mut()) while another reference
exists result in a runtime panic! rather than a compile-time error.
For example, one pattern that breaks the one-way flow of ownership in tree-like data structures is when there’s an
“owner” pointer back from an item to the thing that owns it, as shown in Figure 3-3. These owner links are useful
for moving around the data structure; for example, adding a new sibling to a Leaf needs to involve the owning
Branch.
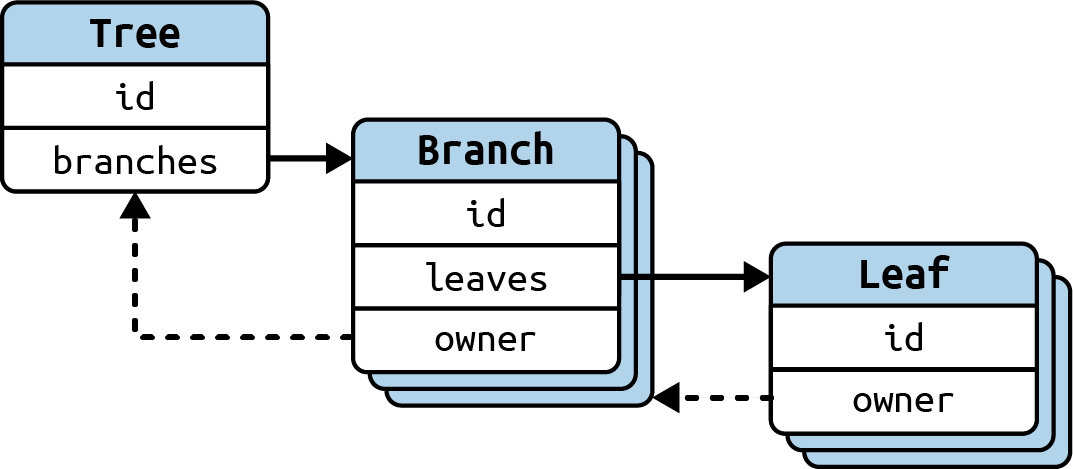
Figure 3-3. Tree data structure layout
Implementing this pattern in Rust can make use of Rc<T>’s more tentative partner,
Weak<T>:
usestd::{cell::RefCell,rc::{Rc,Weak},};// Use a newtype for each identifier type.structTreeId(String);structBranchId(String);structLeafId(String);structTree{id:TreeId,branches:Vec<Rc<RefCell<Branch>>>,}structBranch{id:BranchId,leaves:Vec<Rc<RefCell<Leaf>>>,owner:Option<Weak<RefCell<Tree>>>,}structLeaf{id:LeafId,owner:Option<Weak<RefCell<Branch>>>,}
The Weak reference doesn’t increment the main refcount and so has to explicitly check whether the underlying item has
gone away:
implBranch{fnadd_leaf(branch:Rc<RefCell<Branch>>,mutleaf:Leaf){leaf.owner=Some(Rc::downgrade(&branch));branch.borrow_mut().leaves.push(Rc::new(RefCell::new(leaf)));}fnlocation(&self)->String{match&self.owner{None=>format!("<unowned>.{}",self.id.0),Some(owner)=>{// Upgrade weak owner pointer.lettree=owner.upgrade().expect("owner gone!");format!("{}.{}",tree.borrow().id.0,self.id.0)}}}}
If Rust’s smart pointers don’t seem to cover what’s needed for your data structures, there’s always the final fallback of
writing unsafe code that uses raw (and decidedly un-smart) pointers. However, as per Item 16, this should very
much be a last resort—someone else might have already implemented the semantics you want, inside a safe
interface, and if you search the standard library and crates.io, you might find just the tool for the job.
For example, imagine that you have a function that sometimes returns a reference to one of its inputs but sometimes
needs to return some freshly allocated data. In line with Item 1, an enum that encodes these two possibilities
is the natural way to express this in the type system, and you could then implement various pointer traits
described in Item 8. But you don’t have to: the standard library already includes the
std::borrow::Cow type that covers
exactly this scenario once you know it exists.4
Self-referential data structures
One particular battle with the borrow checker always stymies programmers arriving at Rust from other languages: attempting to create self-referential data structures, which contain a mixture of owned data together with references to within that owned data:
At a syntactic level, this code won’t compile because it doesn’t comply with the lifetime rules described in Item 14:
the reference needs a lifetime annotation, and that means the containing data structure would also need a lifetime
parameter. But a lifetime would be for something external to this SelfRef struct, which is not the intent: the data
being referenced is internal to the struct.
It’s worth thinking about the reason for this restriction at a more semantic level. Data structures in Rust can move:
from the stack to the heap, from the heap to the stack, and from one place to another. If that happens, the “interior”
title pointer would no longer be valid, and there’s no way to keep it in sync.
A simple alternative for this case is to use the indexing approach explored earlier: a range of offsets into the text
is not invalidated by a move and is invisible to the borrow checker because it doesn’t involve references:
structSelfRefIdx{text:String,// Indices into `text` where the title text is.title:Option<std::ops::Range<usize>>,}
However, this indexing approach works only for simple examples and has the same drawbacks as noted previously: the
index itself becomes a pseudo-pointer that can become out of sync or even refer to ranges of the text that no longer
exist.
A more general version of the self-reference problem turns up when the compiler deals with async
code.5 Roughly speaking, the compiler bundles up a pending chunk of
async code into a closure, which holds both the code and any captured parts of the environment that the code works
with (as described in Item 2). This captured environment can include both values and references to those values.
That’s inherently a self-referential data structure, and so async support was a prime motivation for the
Pin type in the standard library. This pointer type “pins”
its value in place, forcing the value to remain at the same location in memory, thus ensuring that internal
self-references remain valid.
So Pin is available as a possibility for self-referential types, but it’s tricky to use correctly—be sure to
read the official docs.
Where possible, avoid self-referential data structures, or try to find library crates that encapsulate the
difficulties for you (e.g., ouroborous).
Things to Remember
-
Rust’s references are borrowed, indicating that they cannot be held forever.
-
The borrow checker allows multiple immutable references or a single mutable reference to an item but not both. The lifetime of a reference stops at the point of last use, rather than at the end of the enclosing scope, due to non-lexical lifetimes.
-
Errors from the borrow checker can be dealt with in various ways:
-
Rust’s smart pointer types provide ways around the borrow checker’s rules and so are useful for interconnected data structures.
-
However, self-referential data structures remain awkward to deal with in Rust.
Item 16: Avoid writing unsafe code
The memory safety guarantees—without runtime overhead—of Rust are its unique selling point; it is the Rust language feature that is not found in any other mainstream language. These guarantees come at a cost: writing Rust requires you to reorganize your code to mollify the borrow checker (Item 15) and to precisely specify the reference types that you use (Item 8).
Unsafe Rust is a superset of the Rust language that weakens some of these restrictions—and the corresponding
guarantees. Prefixing a block with the unsafe keyword switches that block into unsafe mode, which allows things
that are not supported in normal Rust. In particular, it allows the use of raw pointers that work
more like old-style C pointers. These pointers are not subject to the borrowing rules, and the programmer is responsible
for ensuring that they still point to valid memory whenever they’re dereferenced.
So at a superficial level, the advice of this Item is trivial: why move to Rust if you’re just going to write C code in
Rust? However, there are occasions where unsafe code is absolutely required: for low-level library code or for when
your Rust code has to interface with code in other languages (Item 34).
The wording of this Item is quite precise, though: avoid writing unsafe code. The emphasis is on the
“writing,” because much of the time, the unsafe code you’re likely to need has already been written for you.
The Rust standard libraries contain a lot of unsafe code; a quick search finds around 1,000 uses of unsafe in the
alloc library, 1,500 in core, and a further 2,000 in std. This code has been written by experts and is
battle-hardened by use in many thousands of Rust codebases.
Some of this unsafe code happens under the covers in standard library features that we’ve already covered:
-
The smart pointer types—
Rc,RefCell,Arc, and friends—described in Item 8 useunsafecode (often raw pointers) internally to be able to present their particular semantics to their users. -
The synchronization primitives—
Mutex,RwLock, and associated guards—from Item 17 useunsafeOS-specific code internally. Rust Atomics and Locks by Mara Bos (O’Reilly) is recommended if you want to understand the subtle details involved in these primitives.
The standard library also has other functionality covering more advanced
features, implemented with unsafe internally:6
-
std::pin::Pinforces an item to not move in memory (Item 15). This allows self-referential data structures, often a bête noire for new arrivals to Rust. -
std::borrow::Cowprovides a clone-on-write smart pointer: the same pointer can be used for both reading and writing, and a clone of the underlying data happens only if and when a write occurs. -
Various functions (
take,swap,replace) instd::memallow items in memory to be manipulated without falling foul of the borrow checker.
These features may still need a little caution to be used correctly, but the unsafe code has been encapsulated in a
way that removes whole classes of problems.
Moving beyond the standard library, the crates.io ecosystem also includes many crates that
encapsulate unsafe code to provide a frequently used feature:
once_cell-
Provides a way to have something like global variables, initialized exactly once.
rand-
Provides random number generation, making use of the lower-level underlying features provided by the operating system and CPU.
byteorder-
Allows raw bytes of data to be converted to and from numbers.
cxx-
Allows C++ code and Rust code to interoperate (also mentioned in Item 35).
There are many other examples, but hopefully the general idea is clear. If you want to do something that doesn’t
obviously fit within the constraints of Rust (especially Items 14 and 15), hunt through the standard library to see
if there’s existing functionality that does what you need. If you don’t find what you need, try also hunting through
crates.io. After all, it’s unusual to encounter a unique problem that no one else has ever faced before.
Of course, there will always be places where unsafe is forced, for example, when you need to interact with code written
in other languages via a foreign function interface (FFI), as discussed in Item 34. But when it’s necessary,
consider writing a wrapper layer that holds all the unsafe code that’s required so that other programmers
can then follow the advice given in this Item. This also helps to localize problems: when something goes wrong, the unsafe
wrapper can be the first suspect.
Also, if you’re forced to write unsafe code, pay attention to the warning implied by the keyword itself: Hic sunt dracones.
-
Add safety comments that document the preconditions and invariants that the
unsafecode relies on. Clippy (Item 29) has a warning to remind you about this. -
Minimize the amount of code contained in an
unsafeblock, to limit the potential blast radius of a mistake. Consider enabling theunsafe_op_in_unsafe_fnlint so that explicitunsafeblocks are required when performingunsafeoperations, even when those operations are performed in a function that isunsafeitself. -
Write even more tests (Item 30) than usual.
-
Run additional diagnostic tools (Item 31) over the code. In particular, consider running Miri over your
unsafecode—Miri interprets the intermediate level output from the compiler, that allows it to detect classes of errors that are invisible to the Rust compiler. -
Think carefully about multithreaded use, particularly if there’s shared state (Item 17).
Adding the unsafe marker doesn’t mean that no rules apply—it means that you (the programmer) are now
responsible for maintaining Rust’s safety guarantees, rather than the compiler.
Item 17: Be wary of shared-state parallelism
Even the most daring forms of sharing are guaranteed safe in Rust.
The official documentation describes Rust as enabling “fearless concurrency”, but this Item will explore why (sadly) there are still some reasons to be afraid of concurrency, even in Rust.
This Item is specific to shared-state parallelism: where different threads of execution communicate with each other by sharing memory. Sharing state between threads generally comes with two terrible problems, regardless of the language involved:
- Data races
-
These can lead to corrupted data.
- Deadlocks
-
These can lead to your program grinding to a halt.
Both of these problems are terrible (“causing or likely to cause terror”) because they can be very hard to debug in practice: the failures occur nondeterministically and are often more likely to happen under load—which means that they don’t show up in unit tests, integration tests, or any other sort of test (Item 30), but they do show up in production.
Rust is a giant step forward, because it completely solves one of these two problems. However, the other still remains, as we shall see.
Data Races
Let’s start with the good news, by exploring data races and Rust. The precise technical definition of a data race varies from language to language, but we can summarize the key components as follows:
A data race is defined to occur when two distinct threads access the same memory location, under the following conditions:
At least one of them is a write.
There is no synchronization mechanism that enforces an ordering on the accesses.
Data races in C++
The basics of this are best illustrated with an example. Consider a data structure that tracks a bank account:
This example is in C++, not Rust, for reasons that will become clear shortly. However, the same general concepts apply in many other (non-Rust) languages—Java, or Go, or Python, etc.
This class works fine in a single-threaded setting, but consider a multithreaded setting:
BankAccountaccount;account.deposit(1000);// Start a thread that watches for a low balance and tops up the account.std::threadpayer(pay_in,&account);// Start 3 threads that each try to repeatedly withdraw money.std::threadtaker(take_out,&account);std::threadtaker2(take_out,&account);std::threadtaker3(take_out,&account);
Here several threads are repeatedly trying to withdraw from the account, and there’s an additional thread that tops up the account when it runs low:
// Constantly monitor the `account` balance and top it up if low.voidpay_in(BankAccount*account){while(true){if(account->balance()<200){log("[A] Balance running low, deposit 400");account->deposit(400);}// (The infinite loop with sleeps is just for demonstration/simulation// purposes.)std::this_thread::sleep_for(std::chrono::milliseconds(5));}}// Repeatedly try to perform withdrawals from the `account`.voidtake_out(BankAccount*account){while(true){if(account->withdraw(100)){log("[B] Withdrew 100, balance now "+std::to_string(account->balance()));}else{log("[B] Failed to withdraw 100");}std::this_thread::sleep_for(std::chrono::milliseconds(20));}}
Eventually, things will go wrong:
** Oh no, gone overdrawn: -100! **
The problem isn’t hard to spot, particularly with the helpful comment in the withdraw() method: when multiple threads
are involved, the value of the balance can change between the check and the modification. However, real-world bugs
of this sort are much harder to spot—particularly if the compiler is allowed to perform all kinds of tricks and
reorderings of code under the covers (as is the case for C++).
The various sleep calls are included in order to artificially raise the chances of this bug being hit and thus
detected early; when these problems are encountered in the wild, they’re likely to occur rarely and
intermittently—making them very hard to debug.
The BankAccount class is thread-compatible, which means that it can be used in a multithreaded environment as
long as the users of the class ensure that access to it is governed by some kind of external synchronization mechanism.
The class can be converted to a thread-safe class—meaning that it is safe to use from multiple threads—by adding internal synchronization operations:7
// C++ code.classBankAccount{public:BankAccount():balance_(0){}int64_tbalance()const{// Lock mu_ for all of this scope.conststd::lock_guard<std::mutex>with_lock(mu_);if(balance_<0){std::cerr<<"** Oh no, gone overdrawn: "<<balance_<<" **!\n";std::abort();}returnbalance_;}voiddeposit(uint32_tamount){conststd::lock_guard<std::mutex>with_lock(mu_);balance_+=amount;}boolwithdraw(uint32_tamount){conststd::lock_guard<std::mutex>with_lock(mu_);if(balance_<amount){returnfalse;}balance_-=amount;returntrue;}private:mutablestd::mutexmu_;// protects balance_int64_tbalance_;};
The internal balance_ field is now protected by a mutex mu_: a synchronization object that ensures that only one
thread can successfully hold the mutex at a time. A caller can acquire the mutex with a call to std::mutex::lock();
the second and subsequent callers of std::mutex::lock() will block until the original caller invokes
std::mutex::unlock(), and then one of the blocked threads will unblock and proceed through std::mutex::lock().
All access to the balance now takes place with the mutex held, ensuring that its value is consistent between check and
modification. The std::lock_guard is
also worth highlighting: it’s an RAII class (see Item 11) that calls lock() on creation and unlock() on
destruction. This ensures that the mutex is unlocked when the scope exits, reducing the chances of making a mistake
around balancing manual lock() and unlock() calls.
However, the thread safety here is still fragile; all it takes is one erroneous modification to the class:
// Add a new C++ method...voidpay_interest(int32_tpercent){// ...but forgot about mu_int64_tinterest=(balance_*percent)/100;balance_+=interest;}
and the thread safety has been destroyed.8
Data races in Rust
For a book about Rust, this Item has covered a lot of C++, so consider a straightforward translation of this class into Rust:
pubstructBankAccount{balance:i64,}implBankAccount{pubfnnew()->Self{BankAccount{balance:0}}pubfnbalance(&self)->i64{ifself.balance<0{panic!("** Oh no, gone overdrawn: {}",self.balance);}self.balance}pubfndeposit(&mutself,amount:i64){self.balance+=amount}pubfnwithdraw(&mutself,amount:i64)->bool{ifself.balance<amount{returnfalse;}self.balance-=amount;true}}
along with the functions that try to pay into or withdraw from an account forever:
pubfnpay_in(account:&mutBankAccount){loop{ifaccount.balance()<200{println!("[A] Running low, deposit 400");account.deposit(400);}std::thread::sleep(std::time::Duration::from_millis(5));}}pubfntake_out(account:&mutBankAccount){loop{ifaccount.withdraw(100){println!("[B] Withdrew 100, balance now {}",account.balance());}else{println!("[B] Failed to withdraw 100");}std::thread::sleep(std::time::Duration::from_millis(20));}}
This works fine in a single-threaded context—even if that thread is not the main thread:
{letmutaccount=BankAccount::new();let_payer=std::thread::spawn(move||pay_in(&mutaccount));// At the end of the scope, the `_payer` thread is detached// and is the sole owner of the `BankAccount`.}
but a naive attempt to use the BankAccount across multiple threads:
immediately falls foul of the compiler:
error[E0382]: use of moved value: `account`
--> src/main.rs:102:41
|
100 | let mut account = BankAccount::new();
| ----------- move occurs because `account` has type
| `broken::BankAccount`, which does not implement the
| `Copy` trait
101 | let _taker = std::thread::spawn(move || take_out(&mut account));
| ------- ------- variable
| | moved due to
| | use in closure
| |
| value moved into closure here
102 | let _payer = std::thread::spawn(move || pay_in(&mut account));
| ^^^^^^^ ------- use occurs due
| | to use in closure
| |
| value used here after move
The rules of the borrow checker (Item 15) make the problem clear: there are two mutable references to the same item, one more than is allowed. The rules of the borrow checker are that you can have a single mutable reference to an item, or multiple (immutable) references, but not both at the same time.
This has a curious resonance with the definition of a data race at the start of this Item: enforcing that there is a single writer, or multiple readers (but never both), means that there can be no data races. By enforcing memory safety, Rust gets thread safety “for free”.
As with C++, some kind of synchronization is needed to make this struct thread-safe. The most common
mechanism is also called Mutex, but the Rust version
“wraps” the protected data rather than being a standalone object (as in C++):
pubstructBankAccount{balance:std::sync::Mutex<i64>,}
The lock() method on this Mutex generic returns
a MutexGuard object with RAII behavior, like C++’s
std::lock_guard: the mutex is automatically released at the end of the scope when the guard is dropped. (In
contrast to C++, Rust’s Mutex has no methods that manually acquire or release the mutex, as they would expose
developers to the danger of forgetting to keep these calls exactly in sync.)
To be more precise, lock() actually returns a Result that holds the MutexGuard, to cope with the possibility that
the Mutex has been poisoned. Poisoning happens if a thread fails while holding the lock, because this might mean
that any mutex-protected invariants can no longer be relied on. In practice, lock poisoning is sufficiently rare (and
it’s sufficiently desirable that the program terminates when it happens) that it’s common to just .unwrap() the
Result (despite the advice in Item 18).
The MutexGuard object also acts as a proxy for the data that is enclosed by the Mutex, by implementing the Deref and DerefMut traits (Item 8), allowing it to be used both for read operations:
implBankAccount{pubfnbalance(&self)->i64{letbalance=*self.balance.lock().unwrap();ifbalance<0{panic!("** Oh no, gone overdrawn: {}",balance);}balance}}
and for write operations:
implBankAccount{// Note: no longer needs `&mut self`.pubfndeposit(&self,amount:i64){*self.balance.lock().unwrap()+=amount}pubfnwithdraw(&self,amount:i64)->bool{letmutbalance=self.balance.lock().unwrap();if*balance<amount{returnfalse;}*balance-=amount;true}}
There’s an interesting detail lurking in the signatures of these methods: although they are modifying the balance of the
BankAccount, the methods now take &self rather than &mut self. This is inevitable: if multiple threads are going
to hold references to the same BankAccount, by the rules of the borrow checker, those references had better not be
mutable. It’s also another instance of the interior mutability pattern described in Item 8: borrow checks are
effectively moved from compile time to runtime but now with cross-thread synchronization behavior. If a mutable
reference already exists, an attempt to get a second blocks until the first reference is dropped.
Wrapping up shared state in a Mutex mollifies the borrow checker, but there are still lifetime issues (Item 14) to fix:
error[E0373]: closure may outlive the current function, but it borrows `account`
which is owned by the current function
--> src/main.rs:206:40
|
206 | let taker = std::thread::spawn(|| take_out(&account));
| ^^ ------- `account` is
| | borrowed here
| |
| may outlive borrowed value `account`
|
note: function requires argument type to outlive `'static`
--> src/main.rs:206:21
|
206 | let taker = std::thread::spawn(|| take_out(&account));
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
help: to force the closure to take ownership of `account` (and any other
referenced variables), use the `move` keyword
|
206 | let taker = std::thread::spawn(move || take_out(&account));
| ++++
error[E0373]: closure may outlive the current function, but it borrows `account`
which is owned by the current function
--> src/main.rs:207:40
|
207 | let payer = std::thread::spawn(|| pay_in(&account));
| ^^ ------- `account` is
| | borrowed here
| |
| may outlive borrowed value `account`
|
note: function requires argument type to outlive `'static`
--> src/main.rs:207:21
|
207 | let payer = std::thread::spawn(|| pay_in(&account));
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
help: to force the closure to take ownership of `account` (and any other
referenced variables), use the `move` keyword
|
207 | let payer = std::thread::spawn(move || pay_in(&account));
| ++++
The error message makes the problem clear: the BankAccount is going to be dropped at the end of the
block, but there are two new threads that have a reference to it and that may carry on running afterward. (The
compiler’s suggestion for how to fix the problem is less helpful—if the BankAccount item is moved into
the first closure, it will no longer be available for the second closure to receive a reference to it!)
The standard tool for ensuring that an object remains active until all references to it are gone is a reference-counted
pointer, and Rust’s variant of this for multithreaded use is
std::sync::Arc:
letaccount=std::sync::Arc::new(BankAccount::new());account.deposit(1000);letaccount2=account.clone();let_taker=std::thread::spawn(move||take_out(&account2));letaccount3=account.clone();let_payer=std::thread::spawn(move||pay_in(&account3));
Each thread gets its own copy of the reference-counting pointer, moved into the closure, and the underlying
BankAccount will be dropped only when the refcount drops to zero. This combination of Arc<Mutex<T>> is common in
Rust programs that use shared-state parallelism.
Stepping back from the technical details, observe that Rust has entirely avoided the problem of data races that plagues
multithreaded programming in other languages. Of course, this good news is restricted to safe Rust—unsafe
code (Item 16) and FFI boundaries in particular (Item 34) may not be data-race free—but it’s
still a remarkable phenomenon.
Standard marker traits
There are two standard traits that affect the use of Rust objects between threads. Both of these traits are marker traits (Item 10) that have no associated methods but have special significance to the compiler in multithreaded scenarios:
-
The
Sendtrait indicates that items of a type are safe to transfer between threads; ownership of an item of this type can be passed from one thread to another. -
The
Synctrait indicates that items of a type can be safely accessed by multiple threads, subject to the rules of the borrow checker.
Another way of saying this is to observe that Send means T can be transferred between threads,
and Sync means that &T can be transferred between threads.
Both of these traits are auto traits: the compiler automatically
derives them for new types, as long as the constituent parts of the type also implement Send/Sync.
The majority of safe types implement Send and Sync, so much so that it’s clearer to understand what types don’t
implement these traits (written in the form impl !Sync for Type).
A type that doesn’t implement Send is one that can be used only in a single thread. The canonical example of this is
the unsynchronized reference-counting pointer Rc<T> (Item 8).
The implementation of this type explicitly assumes single-threaded use (for speed); there is no attempt at synchronizing
the internal refcount for multithreaded use. As such, transferring an Rc<T> between threads is not allowed; use
Arc<T> (with its additional synchronization overhead) for this case.
A type that doesn’t implement Sync is one that’s not safe to use from multiple threads via non-mut references (as
the borrow checker will ensure there are never multiple mut references). The canonical examples of this are the types
that provide interior mutability in an unsynchronized way, such as
Cell<T> and
RefCell<T>. Use Mutex<T> or
RwLock<T> to provide interior mutability in a multithreaded
environment.
Raw pointer types like *const T and *mut T also implement neither Send nor Sync; see Items 16
and 34.
Deadlocks
Now for the bad news. Although Rust has solved the problem of data races (as previously described), it is still susceptible to the second terrible problem for multithreaded code with shared state: deadlocks.
Consider a simplified multiple-player game server, implemented as a multithreaded application to service many players in parallel. Two core data structures might be a collection of players, indexed by username, and a collection of games in progress, indexed by some unique identifier:
structGameServer{// Map player name to player info.players:Mutex<HashMap<String,Player>>,// Current games, indexed by unique game ID.games:Mutex<HashMap<GameId,Game>>,}
Both of these data structures are Mutex-protected and so are safe from data races. However, code that manipulates both
data structures opens up potential problems. A single interaction between the two might work fine:
implGameServer{/// Add a new player and join them into a current game.fnadd_and_join(&self,username:&str,info:Player)->Option<GameId>{// Add the new player.letmutplayers=self.players.lock().unwrap();players.insert(username.to_owned(),info);// Find a game with available space for them to join.letmutgames=self.games.lock().unwrap();for(id,game)ingames.iter_mut(){ifgame.add_player(username){returnSome(id.clone());}}None}}
However, a second interaction between the two independently locked data structures is where problems start:
implGameServer{/// Ban the player identified by `username`, removing them from/// any current games.fnban_player(&self,username:&str){// Find all games that the user is in and remove them.letmutgames=self.games.lock().unwrap();games.iter_mut().filter(|(_id,g)|g.has_player(username)).for_each(|(_id,g)|g.remove_player(username));// Wipe them from the user list.letmutplayers=self.players.lock().unwrap();players.remove(username);}}
To understand the problem, imagine two separate threads using these two methods, where their execution happens in the order shown in Table 3-1.
| Thread 1 | Thread 2 |
|---|---|
Enters |
|
Enters |
|
Tries to acquire the |
|
Tries to acquire the |
At this point, the program is deadlocked: neither thread will ever progress, nor will any other
thread that does anything with either of the two Mutex-protected data structures.
The root cause of this is a lock inversion: one function acquires the locks in the order players then games,
whereas the other uses the opposite order (games then players). This is a simple example of a more general problem;
the same situation can arise with longer chains of nested locks (thread 1 acquires lock A, then B, then it tries to acquire
C; thread 2 acquires C, then tries to acquire A) and across more threads (thread 1 locks A, then B; thread 2 locks B, then
C; thread 3 locks C, then A).
A simplistic attempt to solve this problem involves reducing the scope of the locks, so there is no point where both locks are held at the same time:
/// Add a new player and join them into a current game.fnadd_and_join(&self,username:&str,info:Player)->Option<GameId>{// Add the new player.{letmutplayers=self.players.lock().unwrap();players.insert(username.to_owned(),info);}// Find a game with available space for them to join.{letmutgames=self.games.lock().unwrap();for(id,game)ingames.iter_mut(){ifgame.add_player(username){returnSome(id.clone());}}}None}/// Ban the player identified by `username`, removing them from/// any current games.fnban_player(&self,username:&str){// Find all games that the user is in and remove them.{letmutgames=self.games.lock().unwrap();games.iter_mut().filter(|(_id,g)|g.has_player(username)).for_each(|(_id,g)|g.remove_player(username));}// Wipe them from the user list.{letmutplayers=self.players.lock().unwrap();players.remove(username);}}
(A better version of this would be to encapsulate the manipulation of the players data structure into add_player()
and remove_player() helper methods, to reduce the chances of forgetting to close out a scope.)
This solves the deadlock problem but leaves behind a data consistency problem: the players and games data
structures can get out of sync with each other, given an execution sequence like the one shown in Table 3-2.
| Thread 1 | Thread 2 |
|---|---|
Enters |
|
Enters |
|
Removes Alice from the |
|
Carries on and acquires the |
At this point, there is a game that includes a player that doesn’t exist, according to the players data structure!
The heart of the problem is that there are two data structures that need to be kept in sync with each other. The best way to do this is to have a single synchronization primitive that covers both of them:
structGameState{players:HashMap<String,Player>,games:HashMap<GameId,Game>,}structGameServer{state:Mutex<GameState>,// ...}
Advice
The most obvious advice for avoiding the problems that arise with shared-state parallelism is simply to avoid shared-state parallelism. The Rust book quotes from the Go language documentation: “Do not communicate by sharing memory; instead, share memory by communicating.”
The Go language has channels that are suitable for this built into the language; for Rust, equivalent functionality is included in the standard library
in the std::sync::mpsc module: the channel() function returns a (Sender, Receiver) pair that allows
values of a particular type to be communicated between threads.
If shared-state concurrency can’t be avoided, then there are some ways to reduce the chances of writing deadlock-prone code:
-
Put data structures that must be kept consistent with each other under a single lock.
-
Keep lock scopes small and obvious; wherever possible, use helper methods that get and set things under the relevant lock.
-
Avoid invoking closures with locks held; this puts the code at the mercy of whatever closure gets added to the codebase in the future.
-
Similarly, avoid returning a
MutexGuardto a caller: it’s like handing out a loaded gun, from a deadlock perspective. -
Include deadlock detection tools in your CI system (Item 32), such as
no_deadlocks, ThreadSanitizer, orparking_lot::deadlock. -
As a last resort: design, document, test, and police a locking hierarchy that describes what lock orderings are allowed/required. This should be a last resort because any strategy that relies on engineers never making a mistake is likely to be doomed to failure in the long term.
More abstractly, multithreaded code is an ideal place to apply the following general advice: prefer code that’s so simple that it is obviously not wrong, rather than code that’s so complex that it’s not obviously wrong.
Item 18: Don’t panic
It looked insanely complicated, and this was one of the reasons why the snug plastic cover it fitted into had the words DON’T PANIC printed on it in large friendly letters.
Douglas Adams
The title of this Item would be more accurately described as prefer returning a Result to using
panic! (but don’t panic is much catchier).
Rust’s panic mechanism is primarily designed for unrecoverable bugs in your program, and by default it terminates the
thread that issues the panic!. However, there are alternatives to this default.
In particular, newcomers to Rust who have come from languages that have an exception system (such as Java or
C++) sometimes pounce on
std::panic::catch_unwind as a way to
simulate exceptions, because it appears to provide a mechanism for catching panics at a point further up the call stack.
Consider a function that panics on an invalid input:
fndivide(a:i64,b:i64)->i64{ifb==0{panic!("Cowardly refusing to divide by zero!");}a/b}
Trying to invoke this with an invalid input fails as expected:
// Attempt to discover what 0/0 is...letresult=divide(0,0);
thread 'main' panicked at 'Cowardly refusing to divide by zero!', main.rs:11:9 note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
A wrapper that uses catch_unwind to catch the panic:
fndivide_recover(a:i64,b:i64,default:i64)->i64{letresult=std::panic::catch_unwind(||divide(a,b));matchresult{Ok(x)=>x,Err(_)=>default,}}
appears to work and to simulate catch:
letresult=divide_recover(0,0,42);println!("result = {result}");
result = 42
Appearances can be deceptive, however. The first problem with this approach is that panics don’t always unwind; there is a compiler option (which is also accessible via a Cargo.toml profile setting) that shifts panic behavior so that it immediately aborts the process:
thread 'main' panicked at 'Cowardly refusing to divide by zero!', main.rs:11:9 note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace /bin/sh: line 1: 29100 Abort trap: 6 cargo run --release
This leaves any attempt to simulate exceptions entirely at the mercy of the wider project settings. It’s also the case that some target platforms (for example, WebAssembly) always abort on panic, regardless of any compiler or project settings.
A more subtle problem that’s surfaced by panic handling is exception safety: if a panic occurs midway through an operation on a data structure, it removes any guarantees that the data structure has been left in a self-consistent state. Preserving internal invariants in the presence of exceptions has been known to be extremely difficult since the 1990s;9 this is one of the main reasons why Google (famously) bans the use of exceptions in its C++ code.
Finally, panic propagation also interacts poorly with
FFI (foreign function interface) boundaries (Item 34); use catch_unwind to prevent panics in Rust
code from propagating to non-Rust calling code across an FFI boundary.
So what’s the alternative to panic! for dealing with error conditions? For library code, the best alternative is to
make the error someone else’s problem, by returning a
Result with an appropriate error type (Item 4). This allows the library user to make their own decisions
about what to do next—which may involve passing the problem on to the next caller in line, via the ? operator.
The buck has to stop somewhere, and a useful rule of thumb is that it’s OK to panic! (or to unwrap(), expect(),
etc.) if you have control of main; at that point, there’s no further caller that the buck could be passed to.
Another sensible use of panic!, even in library code, is in situations where it’s very rare to encounter errors, and
you don’t want users to have to litter their code with .unwrap() calls.
If an error situation should occur only because (say) internal data is corrupted, rather than as a result of invalid
inputs, then triggering a panic! is legitimate.
It can even be occasionally useful to allow panics that can be triggered by invalid input but where such invalid inputs are out of the ordinary. This works best when the relevant entrypoints come in pairs:
-
An “infallible” version whose signature implies it always succeeds (and which panics if it can’t succeed)
-
A “fallible” version that returns a
Result
For the former, Rust’s API guidelines
suggest that the panic! should be documented in a specific section of the inline documentation (Item 27).
The
String::from_utf8_unchecked
and String::from_utf8
entrypoints in the standard library are an example of the latter (although in this case, the panics are actually
deferred to the point where a String constructed from invalid input gets used).
Assuming that you are trying to comply with the advice in this Item, there are a few things to bear in mind. The first
is that panics can appear in different guises; avoiding panic! also involves avoiding the following:
Harder to spot are things like these:
The second observation around avoiding panics is that a plan that involves constant vigilance of humans is never a good idea.
However, constant vigilance of machines is another matter: adding a check to your continuous integration (see Item 32)
system that spots new, potentially panicking code is much more reliable. A simple version could be a simple grep for the
most common panicking entrypoints (as shown previously); a more thorough check could involve additional tooling from the Rust
ecosystem (Item 31), such as setting up a build variant that pulls in the no_panic
crate.
Item 19: Avoid reflection
Programmers coming to Rust from other languages are often used to reaching for reflection as a tool in their toolbox. They can waste a lot of time trying to implement reflection-based designs in Rust, only to discover that what they’re attempting can only be done poorly, if at all. This Item hopes to save that time wasted exploring dead ends, by describing what Rust does and doesn’t have in the way of reflection, and what can be used instead.
Reflection is the ability of a program to examine itself at runtime. Given an item at runtime, it covers these questions:
-
What information can be determined about the item’s type?
-
What can be done with that information?
Programming languages with full reflection support have extensive answers to these questions. Languages with reflection typically support some or all of the following at runtime, based on the reflection information:
-
Determining an item’s type
-
Exploring its contents
-
Modifying its fields
-
Invoking its methods
Languages that have this level of reflection support also tend to be dynamically typed languages (e.g., Python, Ruby), but there are also some notable statically typed languages that also support reflection, particularly Java and Go.
Rust does not support this type of reflection, which makes the advice to avoid reflection easy to follow at this level—it’s just not possible. For programmers coming from languages with support for full reflection, this absence may seem like a significant gap at first, but Rust’s other features provide alternative ways of solving many of the same problems.
C++ has a more limited form of reflection, known as run-time type identification (RTTI). The typeid operator returns a unique identifier
for every type, for objects of polymorphic type (roughly: classes with virtual functions):
typeid-
Can recover the concrete class of an object referred to via a base class reference
dynamic_cast<T>-
Allows base class references to be converted to derived classes, when it is safe and correct to do so
Rust does not support this RTTI style of reflection either, continuing the theme that the advice of this Item is easy to follow.
Rust does support some features that provide similar functionality in the
std::any module, but they’re limited (in ways we will explore) and so
best avoided unless no other alternatives are possible.
The first reflection-like feature from std::any looks like magic at first—a way of determining the name of an
item’s type. The following example uses a user-defined tname() function:
letx=42u32;lety=vec![3,4,2];println!("x: {} = {}",tname(&x),x);println!("y: {} = {:?}",tname(&y),y);
to show types alongside values:
x: u32 = 42 y: alloc::vec::Vec<i32> = [3, 4, 2]
The implementation of tname() reveals what’s up the compiler’s sleeve: the function is generic
(as per Item 12), and so each invocation of it is actually a different function (tname::<u32>
or tname::<Square>):
fntname<T:?Sized>(_v:&T)->&'staticstr{std::any::type_name::<T>()}
The implementation is provided by the
std::any::type_name<T> library
function, which is also generic. This function has access only to compile-time information; there is no code run that
determines the type at runtime. Returning to the trait object types used in Item 12 demonstrates this:
letsquare=Square::new(1,2,2);letdraw:&dynDraw=□letshape:&dynShape=□println!("square: {}",tname(&square));println!("shape: {}",tname(&shape));println!("draw: {}",tname(&draw));
Only the types of the trait objects are available, not the type (Square) of the concrete underlying item:
square: reflection::Square shape: &dyn reflection::Shape draw: &dyn reflection::Draw
The string returned by type_name is suitable only for diagnostics—it’s explicitly a “best-effort” helper whose
contents may change and may not be unique—so don’t attempt to parse type_name results. If you
need a globally unique type identifier, use TypeId
instead:
usestd::any::TypeId;fntype_id<T:'static+?Sized>(_v:&T)->TypeId{TypeId::of::<T>()}
println!("x has {:?}",type_id(&x));println!("y has {:?}",type_id(&y));
x has TypeId { t: 18349839772473174998 }
y has TypeId { t: 2366424454607613595 }
The output is less helpful for humans, but the guarantee of uniqueness means that the result can be used in code.
However, it’s usually best not to use TypeId directly but to use the
std::any::Any trait instead, because the standard
library has additional functionality for working with Any instances (described below).
The Any trait has a single method type_id(),
which returns the TypeId value for the type that implements the trait. You can’t implement this trait yourself, though,
because Any already comes with a blanket implementation for most arbitrary types T:
impl<T:'static+?Sized>AnyforT{fntype_id(&self)->TypeId{TypeId::of::<T>()}}
The blanket implementation doesn’t cover every type T: the T: 'static lifetime bound means that if T
includes any references that have a non-'static lifetime, then TypeId is not implemented for T. This is a
deliberate restriction that’s imposed because lifetimes aren’t fully
part of the type: TypeId::of::<&'a T> would be the same as TypeId::of::<&'b T>, despite the differing lifetimes,
increasing the likelihood of confusion and unsound code.
Recall from Item 8 that a trait object is a fat pointer that holds a pointer to the underlying item,
together with a pointer to the trait implementation’s vtable. For Any, the vtable has a single entry, for a
type_id() method that returns the item’s type, as shown in Figure 3-4:
letx_any:Box<dynAny>=Box::new(42u64);lety_any:Box<dynAny>=Box::new(Square::new(3,4,3));
Figure 3-4. Any trait objects, each with pointers to concrete items and vtables
Aside from a couple of indirections, a dyn Any trait object is effectively a combination of a raw pointer and a type
identifier. This means that the standard library can offer some additional generic methods that are defined for a
dyn Any trait object; these methods are generic over some additional type T:
is::<T>()-
Indicates whether the trait object’s type is equal to some specific other type
T downcast_ref::<T>()-
Returns a reference to the concrete type
T, provided that the trait object’s type matchesT downcast_mut::<T>()-
Returns a mutable reference to the concrete type T, provided that the trait object’s type matches T
Observe that the Any trait is only approximating reflection functionality: the programmer chooses (at compile time) to
explicitly build something (&dyn Any) that keeps track of an item’s compile-time type as well as its location. The
ability to (say) downcast back to the original type is possible only if the overhead of building an Any trait object
has already happened.
There are comparatively few scenarios where Rust has different compile-time and runtime types associated with an item.
Chief among these is trait objects: an item of a concrete type Square can be coerced into a trait
object dyn Shape for a trait that the type implements. This coercion builds a fat pointer (object + vtable) from a
simple pointer (object/item).
Recall also from Item 12 that Rust’s trait objects are not really object-oriented. It’s not the case that a
Square is-a Shape; it’s just that a Square implements Shape’s interface. The same is true for trait
bounds: a trait bound Shape: Draw does not mean is-a; it just means
also-implements because the vtable for Shape includes the entries for the methods of Draw.
For some simple trait bounds:
traitDraw:Debug{fnbounds(&self)->Bounds;}traitShape:Draw{fnrender_in(&self,bounds:Bounds);fnrender(&self){self.render_in(overlap(SCREEN_BOUNDS,self.bounds()));}}
the equivalent trait objects:
letsquare=Square::new(1,2,2);letdraw:&dynDraw=□letshape:&dynShape=□
have a layout with arrows (shown in Figure 3-5; repeated from Item 12) that make the problem clear: given a dyn Shape
object, there’s no immediate way to build a dyn Draw trait object, because there’s no way to get back to the
vtable for impl Draw for Square—even though the relevant part of its contents (the address of the
Square::bounds() method) is theoretically recoverable. (This is likely to change in later versions of Rust; see the
final section of this Item.)
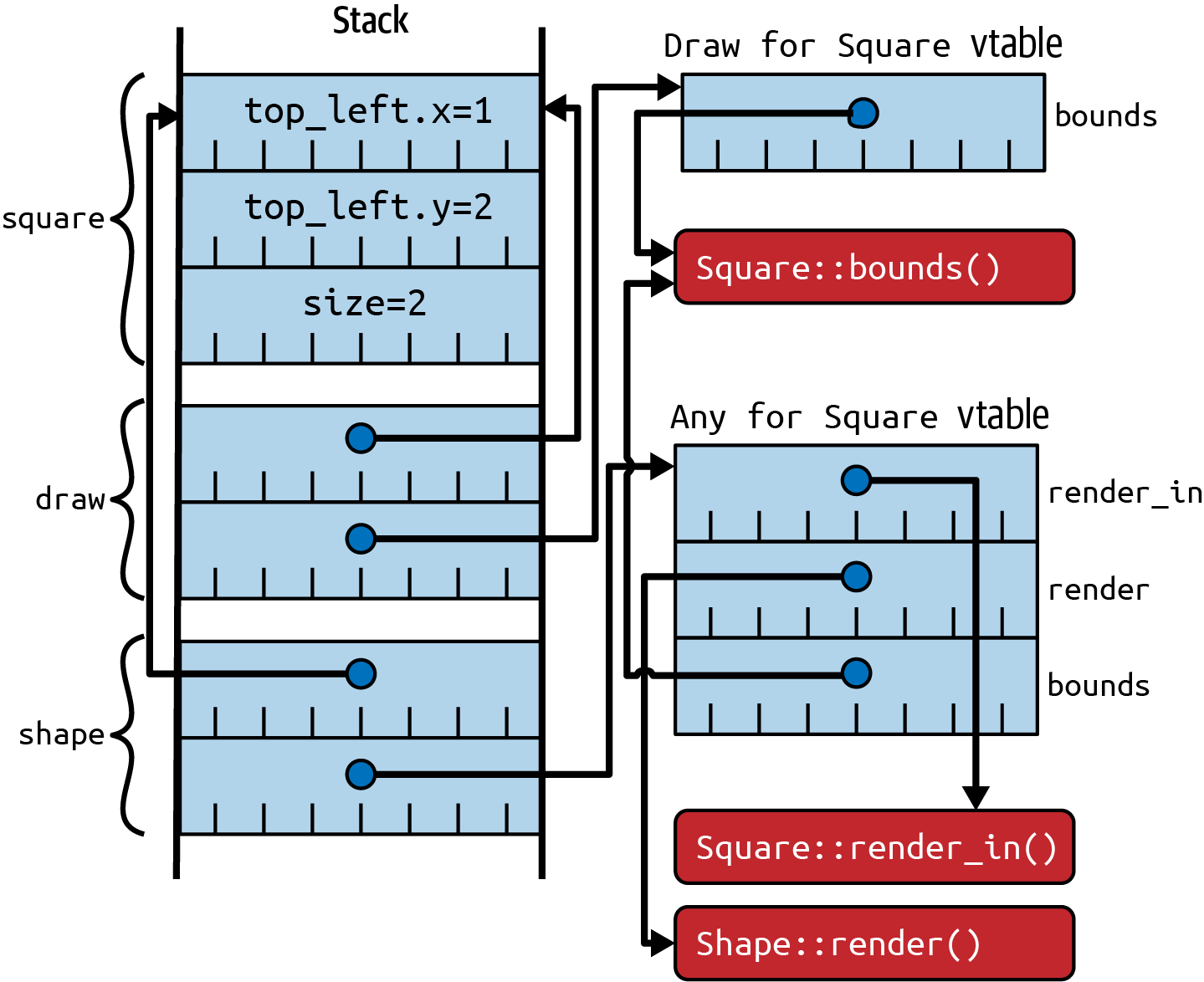
Figure 3-5. Trait objects for trait bounds, with distinct vtables for Draw and Shape
Comparing this with the previous diagram, it’s also clear that an explicitly constructed &dyn Any trait object doesn’t help.
Any allows recovery of the original concrete type of the underlying item, but there is no runtime way to
see what traits it implements, or to get access to the relevant vtable that might allow creation of a trait object.
So what’s available instead?
The primary tool to reach for is trait definitions, and this is in line with advice for other languages—Effective Java Item 65 recommends, “Prefer interfaces to reflection.” If code needs to rely on the availability of certain behavior for an item, encode that behavior as a trait (Item 2). Even if the desired behavior can’t be expressed as a set of method signatures, use marker traits to indicate compliance with the desired behavior—it’s safer and more efficient than (say) introspecting the name of a class to check for a particular prefix.
Code that expects trait objects can also be used with objects having backing code that was not available at program link time,
because it has been dynamically loaded at runtime (via dlopen(3) or equivalent)—which means that
monomorphization of a generic (Item 12) isn’t possible.
Relatedly, reflection is sometimes also used in other languages to allow multiple incompatible versions of the same dependency library to be loaded into the program at once, bypassing linkage constraints that There Can Be Only One. This is not needed in Rust, where Cargo already copes with multiple versions of the same library (Item 25).
Finally, macros—especially derive macros—can be used to auto-generate
ancillary code that understands an item’s type at compile time, as a more efficient and more type-safe equivalent to
code that parses an item’s contents at runtime. Item 28 discusses Rust’s macro system.
Upcasting in Future Versions of Rust
The text of this Item was first written in 2021, and remained accurate all the way until the book was being prepared for publication in 2024—at which point a new feature is due to be added to Rust that changes some of the details.
This new “trait upcasting” feature enables upcasts that
convert a trait object dyn T to a trait object dyn U, when U is one of T’s supertraits (trait T: U {...}).
The feature is gated on #![feature(trait_upcasting)] in advance of its official release, expected to be Rust version
1.76.
For the preceding example, that means a &dyn Shape trait object can now be converted to a &dyn Draw trait object,
edging closer to the is-a relationship of Liskov substitution. Allowing this conversion has a knock-on
effect on the internal details of the vtable implementation, which are likely to become more complex than the versions
shown in Figure 3-5.
However, the central points of this Item are not affected—the Any trait has no supertraits, so the ability to
upcast adds nothing to its functionality.
Item 20: Avoid the temptation to over-optimize
Just because Rust allows you to write super cool non-allocating zero-copy algorithms safely, doesn’t mean every algorithm you write should be super cool, zero-copy and non-allocating.
Most of the Items in this book are designed to help existing programmers become familiar with Rust and its idioms. This Item, however, is all about a problem that can arise when programmers stray too far in the other direction and become obsessed with exploiting Rust’s potential for efficiency—at the expense of usability and maintainability.
Data Structures and Allocation
Like pointers in other languages, Rust’s references allow you to reuse data without making copies. Unlike other languages, Rust’s rules around reference lifetimes and borrows allow you to reuse data safely. However, complying with the borrow checking rules (Item 15) that make this possible can lead to code that’s harder to use.
This is particularly relevant for data structures, where you can choose between allocating a fresh copy of something that’s stored in the data structure or including a reference to an existing copy of it.
As an example, consider some code that parses a data stream of bytes, extracting data encoded as type-length-value (TLV) structures where data is transferred in the following format:
-
One byte describing the type of the value (stored in the
type_codefield here)10 -
One byte describing the length of the value in bytes (used here to create a slice of the specified length)
-
Followed by the specified number of bytes for the value (stored in the
valuefield):
/// A type-length-value (TLV) from a data stream.#[derive(Clone, Debug)]pubstructTlv<'a>{pubtype_code:u8,pubvalue:&'a[u8],}pubtypeError=&'staticstr;// Some local error type./// Extract the next TLV from the `input`, also returning the remaining/// unprocessed data.pubfnget_next_tlv(input:&[u8])->Result<(Tlv,&[u8]),Error>{ifinput.len()<2{returnErr("too short for a TLV");}// The TL parts of the TLV are one byte each.lettype_code=input[0];letlen=input[1]asusize;if2+len>input.len(){returnErr("TLV longer than remaining data");}lettlv=Tlv{type_code,// Reference the relevant chunk of input datavalue:&input[2..2+len],};Ok((tlv,&input[2+len..]))}
This Tlv data structure is efficient because it holds a reference to the relevant chunk of the input data, without
copying any of the data, and Rust’s memory safety ensures that the reference is always valid. That’s perfect for some
scenarios, but things become more awkward if something needs to hang onto an instance of the data structure (as
discussed in Item 15).
For example, consider a network server that is receiving messages in the form of TLVs. The received data can be parsed
into Tlv instances, but the lifetime of those instances will match that of the incoming message—which might be
a transient Vec<u8> on the heap or might be a buffer somewhere that gets reused for multiple messages.
That induces a problem if the server code ever wants to store an incoming message so that it can be consulted later:
pubstructNetworkServer<'a>{// .../// Most recent max-size message.max_size:Option<Tlv<'a>>,}/// Message type code for a set-maximum-size message.constSET_MAX_SIZE:u8=0x01;impl<'a>NetworkServer<'a>{pubfnprocess(&mutself,mutdata:&'a[u8])->Result<(),Error>{while!data.is_empty(){let(tlv,rest)=get_next_tlv(data)?;matchtlv.type_code{SET_MAX_SIZE=>{// Save off the most recent `SET_MAX_SIZE` message.self.max_size=Some(tlv);}// (Deal with other message types)// ..._=>returnErr("unknown message type"),}data=rest;// Process remaining data on next iteration.}Ok(())}}
This code compiles as is but is effectively impossible to use: the lifetime of the NetworkServer has to be smaller
than the lifetime of any data that gets fed into its process() method. That means that a straightforward processing
loop:
fails to compile because the lifetime of the ephemeral data gets attached to the longer-lived server:
error[E0597]: `data` does not live long enough
--> src/main.rs:375:40
|
372 | while !server.done() {
| ------------- borrow later used here
373 | // Read data into a fresh vector.
374 | let data: Vec<u8> = read_data_from_socket();
| ---- binding `data` declared here
375 | if let Err(e) = server.process(&data) {
| ^^^^^ borrowed value does not live
| long enough
...
378 | }
| - `data` dropped here while still borrowed
Switching the code so it reuses a longer-lived buffer doesn’t help either:
This time, the compiler complains that the code is trying to hang on to a reference while also handing out a mutable reference to the same buffer:
error[E0502]: cannot borrow `perma_buffer` as mutable because it is also
borrowed as immutable
--> src/main.rs:353:31
|
353 | read_data_into_buffer(&mut perma_buffer);
| ^^^^^^^^^^^^^^^^^ mutable borrow occurs here
354 | if let Err(e) = server.process(&perma_buffer) {
| -----------------------------
| | |
| | immutable borrow occurs here
| immutable borrow later used here
The core problem is that the Tlv structure references transient data—which is fine for transient processing
but is fundamentally incompatible with storing state for later. However, if the Tlv data structure is converted to
own its contents:
#[derive(Clone, Debug)]pubstructTlv{pubtype_code:u8,pubvalue:Vec<u8>,// owned heap data}
and the get_next_tlv() code is correspondingly tweaked to include an additional call to .to_vec():
// ...lettlv=Tlv{type_code,// Copy the relevant chunk of data to the heap.// The length field in the TLV is a single `u8`,// so this copies at most 256 bytes.value:input[2..2+len].to_vec(),};
then the server code has a much easier job. The data-owning Tlv structure has no lifetime parameter, so the server
data structure doesn’t need one either, and both variants of the processing loop work fine.
Who’s Afraid of the Big Bad Copy?
One reason why programmers can become overly obsessed with reducing copies is that Rust generally makes copies and
allocations explicit. A visible call to a method like .to_vec() or .clone(), or to a function like Box::new(),
makes it clear that copying and allocation are occurring. This is in contrast to C++, where it’s easy to
inadvertently write code that blithely performs allocation under the covers, particularly in a copy-constructor or
assignment operator.
Making an allocation or copy operation visible rather than hidden isn’t a good reason to optimize it away, especially if that happens at the expense of usability. In many situations, it makes more sense to focus on usability first, and fine-tune for optimal efficiency only if performance is genuinely a concern—and if benchmarking (see Item 30) indicates that reducing copies will have a significant impact.
Also, the efficiency of your code is usually important only if it needs to scale up for extensive use. If it turns out that the trade-offs in the code are wrong, and it doesn’t cope well when millions of users start to use it—well, that’s a nice problem to have.
However, there are a couple of specific points to remember. The first was hidden behind the weasel word generally
when pointing out that copies are generally visible. The big exception to this is Copy types, where the compiler
silently makes copies willy-nilly, shifting from move semantics to copy semantics. As such, the advice in Item 10 bears repeating here: don’t implement Copy unless a bitwise copy is valid and fast. But the converse is true
too: do consider implementing Copy if a bitwise copy is valid and fast. For example, enum types that
don’t carry additional data are usually easier to use if they derive Copy.
The second point that might be relevant is the potential trade-off with no_std use. Item 33 suggests that it’s
often possible to write code that’s no_std-compatible with only minor modifications, and code that avoids allocation
altogether makes this more straightforward. However, targeting a no_std environment that supports heap allocation
(via the alloc library, also described in Item 33) may give the best balance of usability and no_std support.
References and Smart Pointers
So very recently, I’ve consciously tried the experiment of not worrying about the hypothetical perfect code. Instead, I call .clone() when I need to, and use Arc to get local objects into threads and futures more smoothly.
And it feels glorious.
Designing a data structure so that it owns its contents can certainly make for better ergonomics, but there are still potential problems if multiple data structures need to make use of the same information. If the data is immutable, then each place having its own copy works fine, but if the information might change (which is very commonly the case), then multiple copies means multiple places that need to be updated, in sync with each other.
Using Rust’s smart pointer types helps solve this problem, by allowing the design to shift from a single-owner model to
a shared-owner model. The Rc (for single-threaded code) and Arc (for multithreaded code) smart
pointers provide reference counting that supports this shared-ownership model. Continuing with the assumption that
mutability is needed, they are typically paired with an inner type that allows interior mutability, independently
of Rust’s borrow checking rules:
RefCell-
For interior mutability in single-threaded code, giving the common
Rc<RefCell<T>>combination Mutex-
For interior mutability in multithreaded code (as per Item 17), giving the common
Arc<Mutex<T>>combination
This transition is covered in more detail in the GuestRegister example in Item 15, but the point here is that you
don’t have to treat Rust’s smart pointers as a last resort. It’s not an admission of defeat if your design uses smart
pointers instead of a complex web of interconnected reference lifetimes—smart pointers can lead to a
simpler, more maintainable, and more usable design.
1 For example, the Chromium project estimates that 70% of security bugs are due to memory safety.
2 Note that all bets are off with expressions like m!(value) that involve a macro (Item 28), because that can expand to arbitrary code.
3 The compiler’s suggestion doesn’t help here, because item is needed on the subsequent line.
4 Cow stands for clone-on-write; a copy of the underlying data is made only if a change (write) needs to be made to it.
5 Dealing with async code is beyond the scope of this book; to understand more about its need for self-referential data structures, see Chapter 8 of Rust for Rustaceans by Jon Gjengset (No Starch Press).
6 In practice, most of this std functionality is actually provided by core and so is available to no_std code as described in Item 33.
7 The third category of behavior is thread-hostile: code that’s dangerous in a multithreaded environment even if all access to it is externally synchronized.
8 The Clang C++ compiler includes a -Wthread-safety option, sometimes known as annotalysis, that allows data to be annotated with information about which mutexes protect which data, and functions to be annotated with information about the locks they acquire. This gives compile-time errors when these invariants are broken, like Rust; however, there is nothing to enforce the use of these annotations in the first place—for example, when a thread-compatible library is used in a multithreaded environment for the first time.
9 Tom Cargill’s 1994 article in the C++ Report explores just how difficult exception safety is for C++ template code, as does Herb Sutter’s Guru of the Week #8 column.
10 The field can’t be named type because that’s a reserved keyword in Rust. It’s possible to work around this restriction by using the raw identifier prefix r# (giving a field r#type: u8), but it’s normally easier just to rename the field.