Chapter 2. Traits
The second core pillar of Rust’s type system is the use of traits, which allow the encoding of behavior that is
common across distinct types. A trait is roughly equivalent to an interface type in other languages, but they are
also tied to Rust’s generics (Item 12), to allow interface reuse without runtime overhead.
The Items in this chapter describe the standard traits that the Rust compiler and the Rust toolchain make available, and provide advice on how to design and use trait-encoded behavior.
Item 10: Familiarize yourself with standard traits
Rust encodes key behavioral aspects of its type system in the type system itself, through a collection of fine-grained standard traits that describe those behaviors (see Item 2).
Many of these traits will seem familiar to programmers coming from C++, corresponding to concepts such as copy-constructors, destructors, equality and assignment operators, etc.
As in C++, it’s often a good idea to implement many of these traits for your own types; the Rust compiler will give you helpful error messages if some operation needs one of these traits for your type and it isn’t present.
Implementing such a large collection of traits may seem daunting, but most of the common ones can be automatically
applied to user-defined types, using derive macros. These derive macros generate code
with the “obvious” implementation of the trait for that type (e.g., field-by-field comparison for Eq on a struct);
this normally requires that all constituent parts also implement the trait. The auto-generated
implementation is
usually what you want, but there are occasional exceptions discussed in each trait’s section that follows.
The use of the derive macros does lead to type definitions like:
#[derive(Clone, Copy, Debug, PartialEq, Eq, PartialOrd, Ord, Hash)]enumMyBooleanOption{Off,On,}
where auto-generated implementations are triggered for eight different traits.
This fine-grained specification of behavior can be disconcerting at first, but it’s important to be familiar with the most common of these standard traits so that the available behaviors of a type definition can be immediately understood.
Common Standard Traits
This section discusses the most commonly encountered standard traits. Here are rough one-sentence summaries of each:
Clone-
Items of this type can make a copy of themselves when asked, by running user-defined code.
Copy-
If the compiler makes a bit-for-bit copy of this item’s memory representation (without running any user-defined code), the result is a valid new item.
Default-
It’s possible to make new instances of this type with sensible default values.
PartialEq-
There’s a partial equivalence relation for items of this type—any two items can be definitively compared, but it may not always be true that
x==x. Eq-
There’s an equivalence relation for items of this type—any two items can be definitively compared, and it is always true that
x==x. PartialOrd-
Some items of this type can be compared and ordered.
Ord-
All items of this type can be compared and ordered.
Hash-
Items of this type can produce a stable hash of their contents when asked.
Debug-
Items of this type can be displayed to programmers.
Display-
Items of this type can be displayed to users.
These traits can all be derived for user-defined types, with the exception of Display (included here because of its
overlap with Debug). However, there are occasions when a manual implementation—or no implementation—is
preferable.
The following sections discuss each of these common traits in more detail.
Clone
The Clone trait indicates that it’s possible to make a new copy of an item, by calling the
clone() method. This is roughly equivalent to
C++’s copy-constructor but is more explicit: the compiler will never silently invoke this method on its own (read on to
the next section for that).
Clone can be derived for a type if all of the item’s fields implement Clone themselves. The derived
implementation clones an aggregate type by cloning each of its members in turn; again, this is roughly equivalent to a
default copy-constructor in C++. This makes the trait opt-in (by adding #[derive(Clone)]), in contrast to the opt-out
behavior in C++ (MyType(const MyType&) = delete;).
This is such a common and useful operation that it’s more interesting to investigate the situations where you shouldn’t
or can’t implement Clone, or where the default derive implementation isn’t appropriate.
-
You shouldn’t implement
Cloneif the item embodies unique access to some resource (such as an RAII type; Item 11), or when there’s another reason to restrict copies (e.g., if the item holds cryptographic key material). -
You can’t implement
Cloneif some component of your type is un-Cloneable in turn. Examples include the following:-
Fields that are mutable references (
&mut T), because the borrow checker (Item 15) allows only a single mutable reference at a time. -
Standard library types that fall into the previous category, such as
MutexGuard(embodies unique access) orMutex(restricts copies for thread safety).
-
-
You should manually implement
Cloneif there is anything about your item that won’t be captured by a (recursive) field-by-field copy or if there is additional bookkeeping associated with item lifetimes. For example, consider a type that tracks the number of extant items at runtime for metrics purposes; a manualCloneimplementation can ensure the counter is kept accurate.
Copy
The Copy trait has a trivial declaration:
pubtraitCopy:Clone{}
There are no methods in this trait, meaning that it is a marker trait (as described in Item 2): it’s used to indicate some constraint on the type that’s not directly expressed in the type system.
In the case of Copy, the meaning of this marker is that a bit-for-bit copy of the memory holding an item gives a
correct new item. Effectively, this trait is a marker that says that a type is a “plain old data” (POD) type.
This also means that the Clone trait bound can be slightly confusing: although a Copy type has to implement Clone,
when an instance of the type is copied, the clone() method is not invoked—the compiler builds the new item
without any involvement of user-defined code.
In contrast to user-defined marker traits (Item 2), Copy has a special significance to the compiler (as do several of the other marker traits in std::marker) over and above being available for trait bounds—it shifts
the compiler from move semantics to copy semantics.
With move semantics for the assignment operator, what the right hand giveth, the left hand taketh away:
error[E0382]: borrow of moved value: `k`
--> src/main.rs:60:23
|
58 | let k = KeyId(42);
| - move occurs because `k` has type `main::KeyId`, which does
| not implement the `Copy` trait
59 | let k2 = k; // value moves out of k into k2
| - value moved here
60 | println!("k = {k:?}");
| ^^^^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl`
help: consider cloning the value if the performance cost is acceptable
|
59 | let k2 = k.clone(); // value moves out of k into k2
| ++++++++
With copy semantics, the original item lives on:
#[derive(Debug, Clone, Copy)]structKeyId(u32);letk=KeyId(42);letk2=k;// value bitwise copied from k to k2println!("k = {k:?}");
This makes Copy one of the most important traits to watch out for: it fundamentally changes the behavior of
assignments—including parameters for method invocations.
In this respect, there are again overlaps with C++’s copy-constructors, but it’s worth emphasizing a key distinction: in
Rust there is no way to get the compiler to silently invoke user-defined code—it’s either explicit (a call to
.clone()) or it’s not user-defined (a bitwise copy).
Because Copy has a Clone trait bound, it’s possible to .clone() any Copy-able item. However, it’s not a good
idea: a bitwise copy will always be faster than invoking a trait method. Clippy (Item 29) will warn you about
this:
warning: using `clone` on type `KeyId` which implements the `Copy` trait --> src/main.rs:79:14 | 79 | let k3 = k.clone(); | ^^^^^^^^^ help: try removing the `clone` call: `k` |
As with Clone, it’s worth exploring when you should or should not implement Copy:
-
The obvious: don’t implement
Copyif a bitwise copy doesn’t produce a valid item. That’s likely to be the case ifCloneneeded a manual implementation rather than an automaticallyderived implementation. -
It may be a bad idea to implement
Copyif your type is large. The basic promise ofCopyis that a bitwise copy is valid; however, this often goes hand in hand with an assumption that making the copy is fast. If that’s not the case, skippingCopyprevents accidental slow copies. -
You can’t implement
Copyif some component of your type is un-Copyable in turn. -
If all of the components of your type are
Copyable, then it’s usually worth derivingCopy. The compiler has an off-by-default lintmissing_copy_implementationsthat points out opportunities for this.
Default
The Default trait defines a default constructor, via a
default() method. This trait can be
derived for user-defined types, provided that all of the subtypes involved have a Default implementation of
their own; if they don’t, you’ll have to implement the trait manually. Continuing the comparison with C++, notice that a
default constructor has to be explicitly triggered—the compiler does not create one automatically.
The Default trait can also be derived for enum types, as long as there’s a #[default] attribute to give the
compiler a hint as to which variant is, well, default:
#[derive(Default)]enumIceCreamFlavor{Chocolate,Strawberry,#[default]Vanilla,}
The most useful aspect of the Default trait is its combination with struct update syntax. This syntax allows
struct fields to be initialized by copying or moving their contents from an existing instance of the same struct,
for any fields that aren’t explicitly initialized. The template to copy from is given at the end of the initialization,
after .., and the Default trait provides an ideal template to use:
#[derive(Default)]structColor{red:u8,green:u8,blue:u8,alpha:u8,}letc=Color{red:128,..Default::default()};
This makes it much easier to initialize structures with lots of fields, only some of which have nondefault values. (The builder pattern, Item 7, may also be appropriate for these situations.)
PartialEq and Eq
The PartialEq and Eq traits allow you to define equality for user-defined types. These traits have
special significance because if they’re present, the compiler will automatically use them for equality (==) checks,
similarly to operator== in C++. The default derive implementation does this with a recursive field-by-field
comparison.
The Eq version is just a marker trait extension of PartialEq that adds the assumption of
reflexivity: any type T that claims to support Eq should ensure that x == x is true for any x: T.
This is sufficiently odd to immediately raise the question, When wouldn’t x == x? The primary rationale behind this
split relates to floating point numbers,1 and specifically to the special “not a
number” value NaN (f32::NAN / f64::NAN in Rust). The floating point specifications require
that nothing compares equal to NaN, including NaN itself; the PartialEq trait is the knock-on effect of this.
For user-defined types that don’t have any float-related peculiarities, you should implement Eq whenever you
implement PartialEq. The full Eq trait is also required if you want to use the type as the key in a
HashMap (as well as the Hash trait).
You should implement PartialEq manually if your type contains any fields that do not affect the item’s identity,
such as internal caches and other performance optimizations. (Any manual implementation will also be used for Eq if
it is defined, because Eq is just a marker trait that has no methods of its own.)
PartialOrd and Ord
The ordering traits PartialOrd and Ord allow comparisons between two items of a type, returning Less,
Greater, or Equal. The traits require equivalent equality traits to be implemented (PartialOrd requires
PartialEq; Ord requires Eq), and the two have to agree with each other (watch out for this with manual
implementations in particular).
As with the equality traits, the comparison traits have special significance because the compiler will automatically use
them for comparison operations (<, >, <=, >=).
The default implementation produced by derive compares fields (or enum variants) lexicographically in the order
they’re defined, so if this isn’t correct, you’ll need to implement the traits manually (or reorder the fields).
Unlike PartialEq, the PartialOrd trait does correspond to a variety of real situations. For example, it could be
used to express a subset relationship among collections:2 {1, 2} is a
subset of {1, 2, 4}, but {1, 3} is not a subset of {2, 4}, nor vice versa.
However, even if a partial order does accurately model the behavior of your type, be wary of implementing just
PartialOrd and not Ord (a rare occasion that contradicts the advice in Item 2 to encode behavior in the type
system)—it can lead to surprising results:
Hash
The Hash trait is used to produce a single value that has a high probability of being different for different
items. This hash value is used as the basis for hash-bucket–based data structures like
HashMap and
HashSet; as such, the type of the keys in these
data structures must implement Hash (and Eq).
Flipping this around, it’s essential that the “same” items (as per Eq) always produce the same hash: if x == y (via
Eq), then it must always be true that hash(x) == hash(y). If you have a manual Eq implementation, check
whether you also need a manual implementation of Hash to comply with this requirement.
Debug and Display
The Debug and Display traits allow a type to specify how it should be included in output, for either
normal ({} format argument) or debugging purposes ({:?} format argument), roughly analogous to an operator<<
overload for iostream in C++.
The differences between the intents of the two traits go beyond which format specifier is needed, though:
-
Debugcan be automatically derived,Displaycan only be manually implemented. -
The layout of
Debugoutput may change between different Rust versions. If the output will ever be parsed by other code, useDisplay. -
Debugis programmer-oriented;Displayis user-oriented. A thought experiment that helps with this is to consider what would happen if the program was localized to a language that the authors don’t speak—Displayis appropriate if the content should be translated,Debugif not.
As a general rule, add an automatically generated Debug implementation for your types unless they contain
sensitive information (personal details, cryptographic material, etc.). To make this advice easier to comply with, the
Rust compiler includes a
missing_debug_implementations
lint that points out types without Debug. This lint is disabled by default but can be enabled for your code with either of the following:
#![warn(missing_debug_implementations)]
#![deny(missing_debug_implementations)]
If the automatically generated implementation of Debug would emit voluminous amounts of detail, then it may be more
appropriate to include a manual implementation of Debug that summarizes the type’s contents.
Implement Display if your types are designed to be shown to end users in textual output.
Standard Traits Covered Elsewhere
In addition to the common traits described in the previous section, the standard library also includes other standard traits that are less ubiquitous. Of these additional standard traits, the following are the most important, but they are covered in other Items and so are not covered here in depth:
Fn,FnOnce, andFnMut-
Items implementing these traits represent closures that can be invoked. See Item 2.
Error-
Items implementing this trait represent error information that can be displayed to users or programmers, and that may hold nested suberror information. See Item 4.
Drop-
Items implementing this trait perform processing when they are destroyed, which is essential for RAII patterns. See Item 11.
FromandTryFrom-
Items implementing these traits can be automatically created from items of some other type but with a possibility of failure in the latter case. See Item 5.
DerefandDerefMut-
Items implementing these traits are pointer-like objects that can be dereferenced to get access to an inner item. See Item 8.
Iteratorand friends-
Items implementing these traits represent collections that can be iterated over. See Item 9.
Send-
Items implementing this trait are safe to transfer between multiple threads. See Item 17.
Sync-
Items implementing this trait are safe to be referenced by multiple threads. See Item 17.
Operator Overloads
The final category of standard traits relates to operator overloads, where Rust allows various built-in unary and binary
operators to be overloaded for user-defined types, by implementing various standard traits from the std::ops module. These traits are not derivable and are typically needed only
for types that represent “algebraic” objects, where there is a natural interpretation of these operators.
However, experience from C++ has shown that it’s best to avoid overloading operators for unrelated types as
it often leads to code that is hard to maintain and has unexpected performance properties (e.g., x + y silently invokes
an expensive O(N) method).
To comply with the principle of least astonishment, if you implement any operator overloads, you should implement a coherent set of operator overloads. For example, if x + y has an overload
(Add), and -y
(Neg) does too, then you should also implement x - y
(Sub) and make sure it gives the same answer as x + (-y).
The items passed to the operator overload traits are moved, which means that non-Copy types will be consumed by
default. Adding implementations for &'a MyType can help with this but requires more boilerplate to cover all of the
possibilities (e.g., there are 4 = 2 × 2 possibilities for combining reference/non-reference arguments to a binary
operator).
Summary
This item has covered a lot of ground, so some tables that summarize the standard traits that have been touched on are
in order. First, Table 2-1 covers the traits that this Item covers in depth, all of which can be automatically
derived except Display.
| Trait | Compiler use | Bound | Methods |
|---|---|---|---|
Clone |
clone |
||
Copy |
let y = x; |
Clone |
Marker trait |
Default |
default |
||
PartialEq |
x == y |
eq |
|
Eq |
x == y |
PartialEq |
Marker trait |
PartialOrd |
x < y, x <= y, … |
PartialEq |
partial_cmp |
Ord |
x < y, x <= y, … |
Eq + PartialOrd |
cmp |
Hash |
hash |
||
Debug |
format!("{:?}", x) |
fmt |
|
Display |
format!("{}", x) |
fmt |
The operator overloads are summarized in Table 2-2. None of these can be derived.
| Trait | Compiler use | Bound | Methods |
|---|---|---|---|
Add |
x + y |
add |
|
AddAssign |
x += y |
add_assign |
|
BitAnd |
x & y |
bitand |
|
BitAndAssign |
x &= y |
bitand_assign |
|
BitOr |
x | y |
bitor |
|
BitOrAssign |
x |= y |
bitor_assign |
|
BitXor |
x ^ y |
bitxor |
|
BitXorAssign |
x ^= y |
bitxor_assign |
|
Div |
x / y |
div |
|
DivAssign |
x /= y |
div_assign |
|
Mul |
x * y |
mul |
|
MulAssign |
x *= y |
mul_assign |
|
Neg |
-x |
neg |
|
Not |
!x |
not |
|
Rem |
x % y |
rem |
|
RemAssign |
x %= y |
rem_assign |
|
Shl |
x << y |
shl |
|
ShlAssign |
x <<= y |
shl_assign |
|
Shr |
x >> y |
shr |
|
ShrAssign |
x >>= y |
shr_assign |
|
Sub |
x - y |
sub |
|
SubAssign |
x -= y |
sub_assign |
|
a Some of the names here are a little cryptic—e.g., | |||
For completeness, the standard traits that are covered in other items are included in Table 2-3; none of these
traits are deriveable (but Send and Sync may be automatically implemented by the compiler).
| Trait | Compiler use | Bound | Methods | Item |
|---|---|---|---|---|
Fn |
x(a) |
FnMut |
call |
Item 2 |
FnMut |
x(a) |
FnOnce |
call_mut |
Item 2 |
FnOnce |
x(a) |
call_once |
Item 2 | |
Error |
Display + Debug |
[source] |
Item 4 | |
From |
from |
Item 5 | ||
TryFrom |
try_from |
Item 5 | ||
Into |
into |
Item 5 | ||
TryInto |
try_into |
Item 5 | ||
AsRef |
as_ref |
Item 8 | ||
AsMut |
as_mut |
Item 8 | ||
Borrow |
borrow |
Item 8 | ||
BorrowMut |
Borrow |
borrow_mut |
Item 8 | |
ToOwned |
to_owned |
Item 8 | ||
Deref |
*x, &x |
deref |
Item 8 | |
DerefMut |
*x, &mut x |
Deref |
deref_mut |
Item 8 |
Index |
x[idx] |
index |
Item 8 | |
IndexMut |
x[idx] = ... |
Index |
index_mut |
Item 8 |
Pointer |
format("{:p}", x) |
fmt |
Item 8 | |
Iterator |
next |
Item 9 | ||
IntoIterator |
for y in x |
into_iter |
Item 9 | |
FromIterator |
from_iter |
Item 9 | ||
ExactSizeIterator |
Iterator |
(size_hint) |
Item 9 | |
DoubleEndedIterator |
Iterator |
next_back |
Item 9 | |
Drop |
} (end of scope) |
drop |
Item 11 | |
Sized |
Marker trait | Item 12 | ||
Send |
cross-thread transfer | Marker trait | Item 17 | |
Sync |
cross-thread use | Marker trait | Item 17 |
Item 11: Implement the Drop trait for RAII patterns
Never send a human to do a machine’s job.
Agent Smith
RAII stands for “Resource Acquisition Is Initialization,” which is a programming pattern where the lifetime of a value is exactly tied to the lifecycle of some additional resource. The RAII pattern was popularized by the C++ programming language and is one of C++’s biggest contributions to programming.
The correlation between the lifetime of a value and the lifecycle of a resource is encoded in an RAII type:
-
The type’s constructor acquires access to some resource
-
The type’s destructor releases access to that resource
The result of this is that the RAII type has an invariant: access to the underlying resource is available if and only if the item exists. Because the compiler ensures that local variables are destroyed at scope exit, this in turn means that the underlying resources are also released at scope exit.3
This is particularly helpful for maintainability: if a subsequent change to the code alters the control flow, item and
resource lifetimes are still correct. To see this, consider some code that manually locks and unlocks a mutex, without
using the RAII pattern; this code is in C++, because Rust’s Mutex doesn’t allow this kind of error-prone usage!
// C++ codeclassThreadSafeInt{public:ThreadSafeInt(intv):value_(v){}voidadd(intdelta){mu_.lock();// ... more code herevalue_+=delta;// ... more code heremu_.unlock();}
A modification to catch an error condition with an early exit leaves the mutex locked:
However, encapsulating the locking behavior into an RAII class:
// C++ code (real code should use std::lock_guard or similar)classMutexLock{public:MutexLock(Mutex*mu):mu_(mu){mu_->lock();}~MutexLock(){mu_->unlock();}private:Mutex*mu_;};
means the equivalent code is safe for this kind of modification:
// C++ codevoidadd_with_modification(intdelta){MutexLockwith_lock(&mu_);// ... more code herevalue_+=delta;// Check for overflow.if(value_>MAX_INT){return;// Safe, with_lock unlocks on the way out}// ... more code here}
In C++, RAII patterns were often originally used for memory management, to ensure that manual allocation (new,
malloc()) and deallocation (delete, free()) operations were kept in sync. A general version of this memory
management was added to the
C++ standard library in C++11: the std::unique_ptr<T> type ensures that a single
place has “ownership” of memory but allows a pointer to the memory to be “borrowed” for ephemeral use
(ptr.get()).
In Rust, this behavior for memory pointers is built into the language (Item 15), but the general principle of RAII is
still useful for other kinds of resources.4 Implement Drop for any
types that hold resources that must be released, such as the following:
-
Access to operating system resources. For Unix-derived systems, this usually means something that holds a file descriptor; failing to release these correctly will hold onto system resources (and will also eventually lead to the program hitting the per-process file descriptor limit).
-
Access to synchronization resources. The standard library already includes memory synchronization primitives, but other resources (e.g., file locks, database locks, etc.) may need similar encapsulation.
-
Access to raw memory, for
unsafetypes that deal with low-level memory management (e.g., for foreign function interface [FFI] functionality).
The most obvious instance of RAII in the Rust standard library is the
MutexGuard item returned by
Mutex::lock() operations, which tend to be widely
used for programs that use the shared-state parallelism discussed in Item 17. This is roughly analogous to the
final C++ example shown earlier, but in Rust the MutexGuard item acts as a proxy to the mutex-protected data in addition to
being an RAII item for the held lock:
usestd::sync::Mutex;structThreadSafeInt{value:Mutex<i32>,}implThreadSafeInt{fnnew(val:i32)->Self{Self{value:Mutex::new(val),}}fnadd(&self,delta:i32){letmutv=self.value.lock().unwrap();*v+=delta;}}
Item 17 advises against holding locks for large sections of code; to ensure this, use blocks to restrict the scope of RAII items. This leads to slightly odd indentation, but it’s worth it for the added safety and lifetime precision:
implThreadSafeInt{fnadd_with_extras(&self,delta:i32){// ... more code here that doesn't need the lock{letmutv=self.value.lock().unwrap();*v+=delta;}// ... more code here that doesn't need the lock}}
Having proselytized the uses of the RAII pattern, an explanation of how to implement it is in order. The
Drop trait allows you to add user-defined behavior to the
destruction of an item. This trait has a single method,
drop, which the compiler runs just before the
memory holding the item is released:
#[derive(Debug)]structMyStruct(i32);implDropforMyStruct{fndrop(&mutself){println!("Dropping {self:?}");// Code to release resources owned by the item would go here.}}
The drop method is specially reserved for the compiler and can’t be manually invoked:
error[E0040]: explicit use of destructor method --> src/main.rs:70:7 | 70 | x.drop(); | --^^^^-- | | | | | explicit destructor calls not allowed | help: consider using `drop` function: `drop(x)`
It’s worth understanding a little bit about the technical details here. Notice that the Drop::drop method has a
signature of drop(&mut self) rather than drop(self): it takes a mutable reference to the item rather than having the
item moved into the method. If Drop::drop acted like a normal method, that would mean the item would still be
available for use afterward—even though all of its internal state has been tidied up and resources released!
The compiler suggested a straightforward alternative, which is to call the
drop() function to manually drop an item. This
function does take a moved argument, and the implementation of drop(_item: T) is just an empty body { }—so
the moved item is dropped when that scope’s closing brace is reached.
Notice also that the signature of the drop(&mut self) method has no return type, which means that it has no way to
signal failure. If an attempt to release resources can fail, then you should probably have a separate release method
that returns a Result, so it’s possible for users to detect this failure.
Regardless of the technical details, the drop method is nevertheless the key place for implementing RAII patterns; its
implementation is the ideal place to release resources associated with an item.
Item 12: Understand the trade-offs between generics and trait objects
Item 2 described the use of traits to encapsulate behavior in the type system, as a collection of related methods, and observed that there are two ways to make use of traits: as trait bounds for generics or in trait objects. This Item explores the trade-offs between these two possibilities.
As a running example, consider a trait that covers functionality for displaying graphical objects:
#[derive(Debug, Copy, Clone)]pubstructPoint{x:i64,y:i64,}#[derive(Debug, Copy, Clone)]pubstructBounds{top_left:Point,bottom_right:Point,}/// Calculate the overlap between two rectangles, or `None` if there is no/// overlap.fnoverlap(a:Bounds,b:Bounds)->Option<Bounds>{// ...}/// Trait for objects that can be drawn graphically.pubtraitDraw{/// Return the bounding rectangle that encompasses the object.fnbounds(&self)->Bounds;// ...}
Generics
Rust’s generics are roughly equivalent to C++’s templates: they allow the programmer to write
code that works for some arbitrary type T, and specific uses of the generic code are generated at compile time—a
process known as monomorphization in Rust, and template instantiation in C++. Unlike C++, Rust explicitly
encodes the expectations for the type T in the type system, in the form of trait bounds for the generic.
For the example, a generic function that uses the trait’s bounds() method has an explicit Draw trait bound:
/// Indicate whether an object is on-screen.pubfnon_screen<T>(draw:&T)->boolwhereT:Draw,{overlap(SCREEN_BOUNDS,draw.bounds()).is_some()}
This can also be written more compactly by putting the trait bound after the generic parameter:
pubfnon_screen<T:Draw>(draw:&T)->bool{overlap(SCREEN_BOUNDS,draw.bounds()).is_some()}
or by using impl Trait as the type of the argument:5
pubfnon_screen(draw:&implDraw)->bool{overlap(SCREEN_BOUNDS,draw.bounds()).is_some()}
If a type implements the trait:
#[derive(Clone)]// no `Debug`structSquare{top_left:Point,size:i64,}implDrawforSquare{fnbounds(&self)->Bounds{Bounds{top_left:self.top_left,bottom_right:Point{x:self.top_left.x+self.size,y:self.top_left.y+self.size,},}}}
then instances of that type can be passed to the generic function, monomorphizing it to produce code that’s specific to one particular type:
letsquare=Square{top_left:Point{x:1,y:2},size:2,};// Calls `on_screen::<Square>(&Square) -> bool`letvisible=on_screen(&square);
If the same generic function is used with a different type that implements the relevant trait bound:
#[derive(Clone, Debug)]structCircle{center:Point,radius:i64,}implDrawforCircle{fnbounds(&self)->Bounds{// ...}}
then different monomorphized code is used:
letcircle=Circle{center:Point{x:3,y:4},radius:1,};// Calls `on_screen::<Circle>(&Circle) -> bool`letvisible=on_screen(&circle);
In other words, the programmer writes a single generic function, but the compiler outputs a different monomorphized version of that function for every different type that the function is invoked with.
Trait Objects
In comparison, trait objects are fat pointers (Item 8) that combine a pointer to the underlying concrete item with a pointer to a vtable that in turn holds function pointers for all of the trait implementation’s methods, as depicted in Figure 2-1:
letsquare=Square{top_left:Point{x:1,y:2},size:2,};letdraw:&dynDraw=□
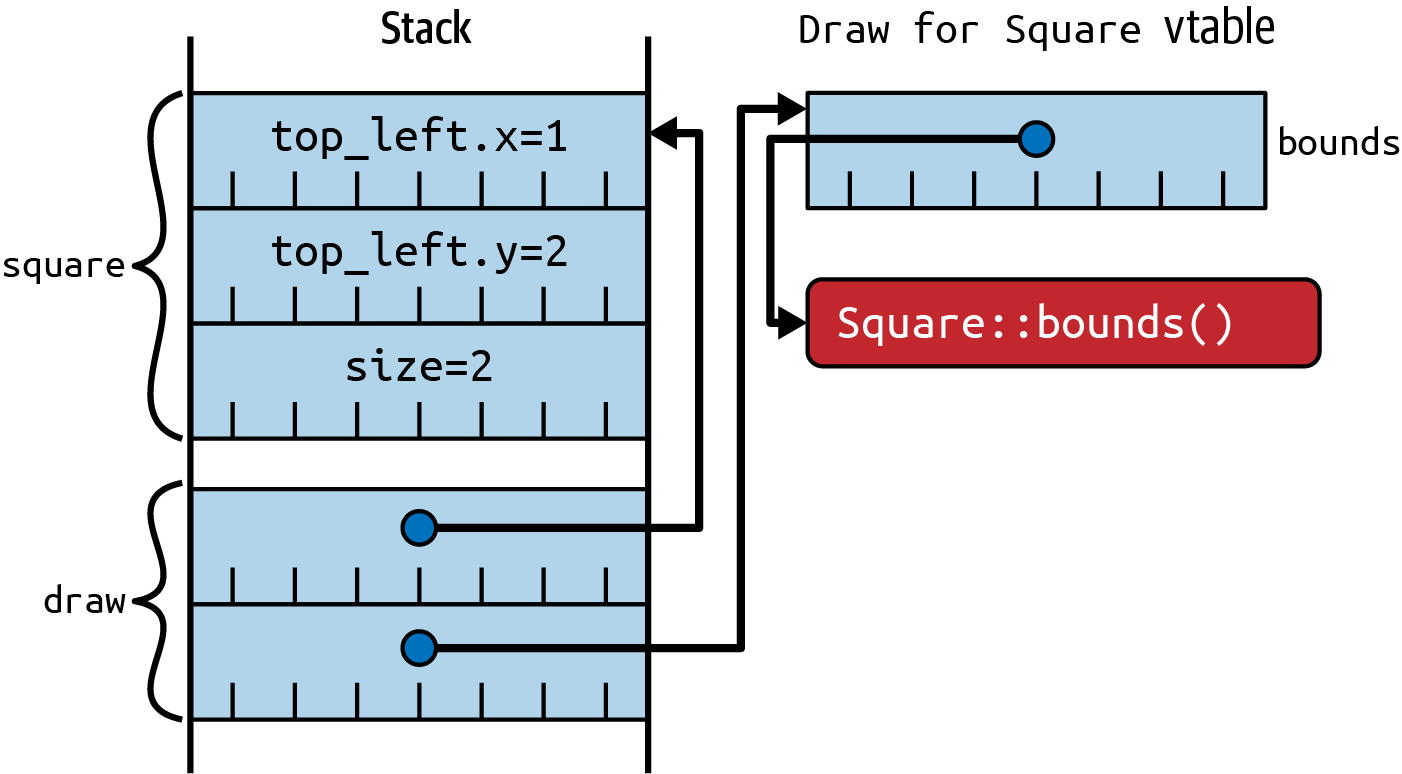
Figure 2-1. Trait object layout, with pointers to concrete item and vtable
This means that a function that accepts a trait object doesn’t need to be generic and doesn’t need monomorphization: the programmer writes a function using trait objects, and the compiler outputs only a single version of that function, which can accept trait objects that come from multiple input types:
/// Indicate whether an object is on-screen.pubfnon_screen(draw:&dynDraw)->bool{overlap(SCREEN_BOUNDS,draw.bounds()).is_some()}
// Calls `on_screen(&dyn Draw) -> bool`.letvisible=on_screen(&square);// Also calls `on_screen(&dyn Draw) -> bool`.letvisible=on_screen(&circle);
Basic Comparisons
These basic facts already allow some immediate comparisons between the two possibilities:
-
Generics are likely to lead to bigger code sizes, because the compiler generates a fresh copy (
on_screen::<T>(&T)) of the code for every typeTthat uses the generic version of theon_screenfunction. In contrast, the trait object version (on_screen(&dyn T)) of the function needs only a single instance. -
Invoking a trait method from a generic will generally be ever-so-slightly faster than invoking it from code that uses a trait object, because the latter needs to perform two dereferences to find the location of the code (trait object to vtable, vtable to implementation location).
-
Compile times for generics are likely to be longer, as the compiler is building more code and the linker has more work to do to fold duplicates.
In most situations, these aren’t significant differences—you should use optimization-related concerns as a primary decision driver only if you’ve measured the impact and found that it has a genuine effect (a speed bottleneck or a problematic occupancy increase).
A more significant difference is that generic trait bounds can be used to conditionally make different functionality available, depending on whether the type parameter implements multiple traits:
// The `area` function is available for all containers holding things// that implement `Draw`.fnarea<T>(draw:&T)->i64whereT:Draw,{letbounds=draw.bounds();(bounds.bottom_right.x-bounds.top_left.x)*(bounds.bottom_right.y-bounds.top_left.y)}// The `show` method is available only if `Debug` is also implemented.fnshow<T>(draw:&T)whereT:Debug+Draw,{println!("{:?} has bounds {:?}",draw,draw.bounds());}
letsquare=Square{top_left:Point{x:1,y:2},size:2,};letcircle=Circle{center:Point{x:3,y:4},radius:1,};// Both `Square` and `Circle` implement `Draw`.println!("area(square) = {}",area(&square));println!("area(circle) = {}",area(&circle));// `Circle` implements `Debug`.show(&circle);// `Square` does not implement `Debug`, so this wouldn't compile:// show(&square);
A trait object encodes the implementation vtable only for a single trait, so doing something equivalent is much more
awkward. For example, a combination DebugDraw trait could be defined for the show() case, together with a
blanket implementation to make life easier:
traitDebugDraw:Debug+Draw{}/// Blanket implementation applies whenever the individual traits/// are implemented.impl<T:Debug+Draw>DebugDrawforT{}
However, if there are multiple combinations of distinct traits, it’s clear that the combinatorics of this approach rapidly become unwieldy.
More Trait Bounds
In addition to using trait bounds to restrict what type parameters are acceptable for a generic function, you can also apply them to trait definitions themselves:
/// Anything that implements `Shape` must also implement `Draw`.traitShape:Draw{/// Render that portion of the shape that falls within `bounds`.fnrender_in(&self,bounds:Bounds);/// Render the shape.fnrender(&self){// Default implementation renders that portion of the shape// that falls within the screen area.ifletSome(visible)=overlap(SCREEN_BOUNDS,self.bounds()){self.render_in(visible);}}}
In this example, the render() method’s default implementation (Item 13) makes use of the trait bound, relying
on the availability of the bounds() method from Draw.
Programmers coming from object-oriented languages often confuse trait bounds with inheritance, under the mistaken
impression that a trait bound like this means that a Shape is-a Draw. That’s not the case: the relationship
between the two types is better expressed as Shape also-implements Draw.
Under the covers, trait objects for traits that have trait bounds:
letsquare=Square{top_left:Point{x:1,y:2},size:2,};letdraw:&dynDraw=□letshape:&dynShape=□
have a single combined vtable that includes the methods of the top-level trait, plus the methods of all of the
trait bounds. This is shown in Figure 2-2: the vtable for Shape includes the bounds method from the Draw trait,
as well as the two methods from the Shape trait itself.
At the time of writing (and as of Rust 1.70), this means that there is no way to “upcast” from Shape to
Draw, because the (pure) Draw vtable can’t be recovered at runtime; there is no way to convert between related
trait objects, which in turn means there is no Liskov substitution. However, this is likely to change in
later versions of Rust—see Item 19 for more on this.
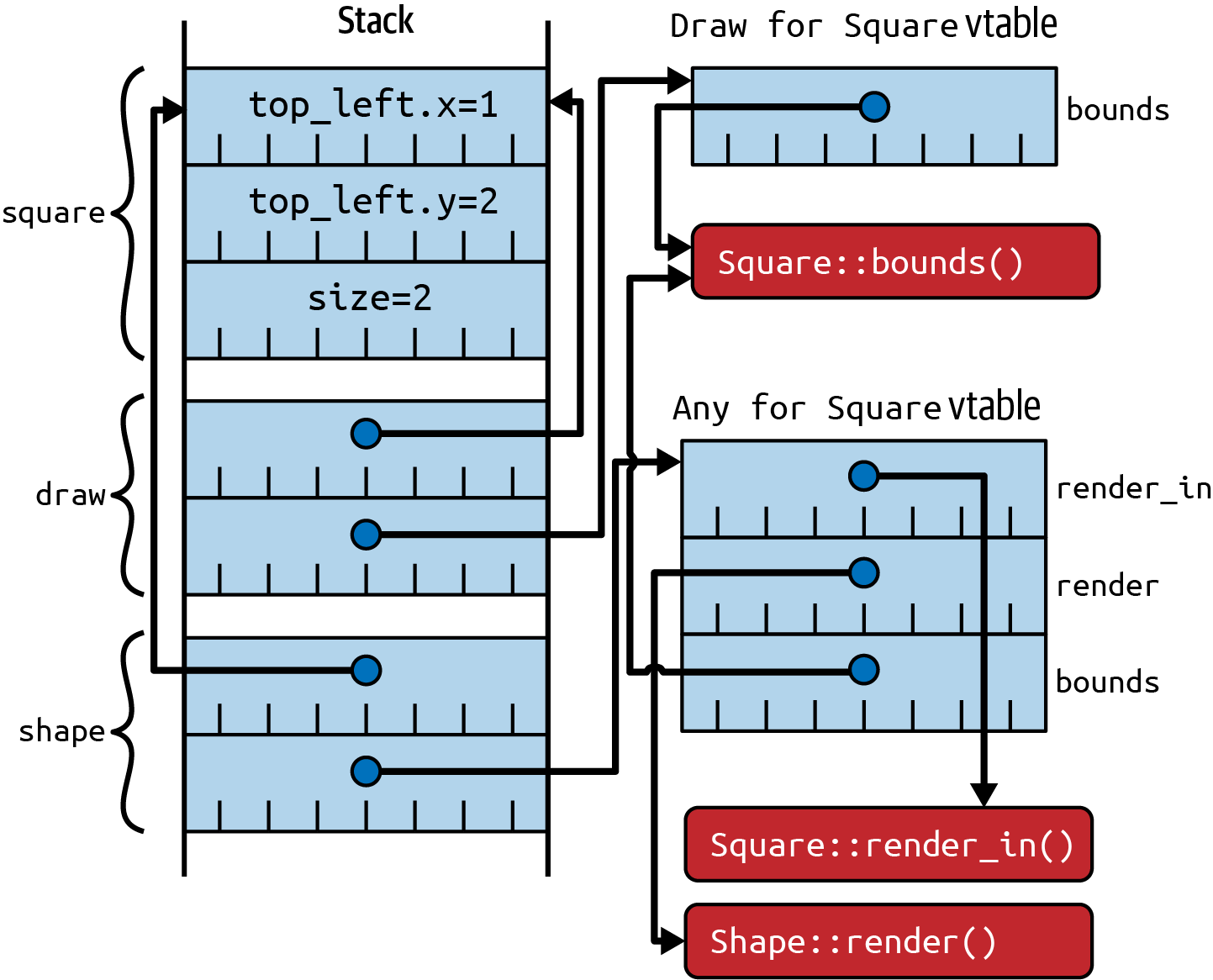
Figure 2-2. Trait objects for trait bounds, with distinct vtables for Draw and Shape
Repeating the same point in different words, a method that accepts a Shape trait object has the following characteristics:
-
It can make use of methods from
Draw(becauseShapealso-implementsDraw, and because the relevant function pointers are present in theShapevtable). -
It cannot (yet) pass the trait object onto another method that expects a
Drawtrait object (becauseShapeis-notDraw, and because theDrawvtable isn’t available).
In contrast, a generic method that accepts items that implement Shape has these
characteristics:
-
It can use methods from
Draw. -
It can pass the item on to another generic method that has a
Drawtrait bound, because the trait bound is monomorphized at compile time to use theDrawmethods of the concrete type.
Trait Object Safety
Another restriction on trait objects is the requirement for object safety: only traits that comply with the following two rules can be used as trait objects:
-
The trait’s methods must not be generic.
-
The trait’s methods must not involve a type that includes
Self, except for the receiver (the object on which the method is invoked).
The first restriction is easy to understand: a generic method f is really an infinite set of methods, potentially
encompassing f::<i16>, f::<i32>, f::<i64>, f::<u8>, etc. The trait object’s vtable, on the other hand, is
very much a finite collection of function pointers, and so it’s not possible to fit the infinite set of monomorphized
implementations into it.
The second restriction is a little bit more subtle but tends to be the restriction that’s hit more often in
practice—traits that impose Copy or Clone trait bounds (Item 10) immediately fall under
this rule, because they return Self. To see why it’s disallowed, consider code that has a trait object in its hands;
what happens if that code calls (say) let y = x.clone()? The calling code needs to reserve enough space for y on the
stack, but it has no idea of the size of y because Self is an arbitrary type. As a result, return types that mention Self lead to a trait that is not object safe.6
There is an exception to this second restriction. A method returning some Self-related type does not affect object
safety if Self comes with an explicit restriction to types whose size is known at compile time,
indicated by the Sized marker trait as a trait bound:
/// A `Stamp` can be copied and drawn multiple times.traitStamp:Draw{fnmake_copy(&self)->SelfwhereSelf:Sized;}
letsquare=Square{top_left:Point{x:1,y:2},size:2,};// `Square` implements `Stamp`, so it can call `make_copy()`.letcopy=square.make_copy();// Because the `Self`-returning method has a `Sized` trait bound,// creating a `Stamp` trait object is possible.letstamp:&dynStamp=□
This trait bound means that the method can’t be used with trait objects anyway, because trait objects refer to something
that’s of unknown size (dyn Trait), and so the method is irrelevant for object safety:
Trade-Offs
The balance of factors so far suggests that you should prefer generics to trait objects, but there are situations where trait objects are the right tool for the job.
The first is a practical consideration: if generated code size or compilation time is a concern, then trait objects will perform better (as described earlier in this Item).
A more theoretical aspect that leads toward trait objects is that they fundamentally involve type erasure: information about the concrete type is lost in the conversion to a trait object. This can be a downside (see Item 19), but it can also be useful because it allows for collections of heterogeneous objects—because the code just relies on the methods of the trait, it can invoke and combine the methods of items that have different concrete types.
The traditional OO example of rendering a list of shapes is one example of this: the same
render() method could be used for squares, circles, ellipses, and stars in the same loop:
letshapes:Vec<&dynShape>=vec![&square,&circle];forshapeinshapes{shape.render()}
A much more obscure potential advantage for trait objects is when the available types are not known at compile time. If
new code is dynamically loaded at runtime (e.g., via dlopen(3)),
then items that implement traits in the new code can be invoked only via a trait object, because there’s no source code
to monomorphize over.
Item 13: Use default implementations to minimize required trait methods
The designer of a trait has two different audiences to consider: the programmers who will be implementing the trait and those who will be using the trait. These two audiences lead to a degree of tension in the trait design:
-
To make the implementor’s life easier, it’s better for a trait to have the absolute minimum number of methods to achieve its purpose.
-
To make the user’s life more convenient, it’s helpful to provide a range of variant methods that cover all of the common ways that the trait might be used.
This tension can be balanced by including the wider range of methods that makes the user’s life easier, but with default implementations provided for any methods that can be built from other, more primitive, operations on the interface.
A simple example of this is the
is_empty() method for an
ExactSizeIterator, which is an Iterator
that knows how many things it is iterating over.7 This method has a default implementation that relies on the
len() trait method:
fnis_empty(&self)->bool{self.len()==0}
The existence of a default implementation is just that: a default. If an implementation of the trait has a different
way of determining whether the iterator is empty, it can replace the default is_empty() with its own.
This approach leads to trait definitions that have a small number of required methods, plus a much larger number of default-implemented methods. An implementor for the trait has to implement only the former and gets all of the latter for free.
It’s also an approach that is widely followed by the Rust standard library; perhaps the best example there is the
Iterator trait, which has a single required method
(next()) but includes a panoply of
pre-provided methods (Item 9), over 50 at the time of
writing.
Trait methods can impose trait bounds, indicating that a method is only available if the types involved
implement particular traits. The Iterator trait also shows that this is useful in combination with default
method implementations. For example, the
cloned() iterator method has a
trait bound and a default implementation:
fncloned<'a,T>(self)->Cloned<Self>whereT:'a+Clone,Self:Sized+Iterator<Item=&'aT>,{Cloned::new(self)}
In other words, the cloned() method is available only if the underlying Item type implements
Clone; when it does, the implementation is automatically
available.
The final observation about trait methods with default implementations is that new ones can usually be safely added to a trait even after an initial version of the trait is released. An addition like this preserves backward compatibility (see Item 21) for users and implementors of the trait, as long as the new method name does not clash with the name of a method from some other trait that the type implements.8
So follow the example of the standard library and provide a minimal API surface for implementors but a convenient and comprehensive API for users, by adding methods with default implementations (and trait bounds as appropriate).
1 Of course, comparing floats for equality is always a dangerous game, as there is typically no guarantee that rounded calculations will produce a result that is bit-for-bit identical to the number you first thought of.
2 More generally, any lattice structure also has a partial order.
3 This also means that RAII as a technique is mostly available only in languages that have a predictable time of destruction, which rules out most garbage-collected languages (although Go’s defer statement achieves some of the same ends).
4 RAII is also still useful for memory management in low-level unsafe code, but that is (mostly) beyond the scope of this book.
5 Using “impl Trait in argument position” isn’t exactly equivalent to the previous two versions, because it removes the ability for a caller to explicitly specify the type parameter with something like on_screen::<Circle>(&c).
6 At the time of writing, the restriction on methods that return Self includes types like Box<Self> that could be safely stored on the stack; this restriction might be relaxed in the future.
7 The is_empty() method is currently a nightly-only experimental function.
8 If the new method happens to match a method of the same name in the concrete type, then the concrete method—known as an inherent implementation—will be used ahead of the trait method. The trait method can be explicitly selected instead by casting: <Concrete as Trait>::method().