Chapter 1. Types
This first chapter of this book covers advice that revolves around Rust’s type system. This type system is more expressive than that of other mainstream languages; it has more in common with “academic” languages such as OCaml or Haskell.
One core part of this is Rust’s enum type, which is considerably more expressive than the enumeration types in
other languages and which allows for algebraic data types.
The Items in this chapter cover the fundamental types that the language provides and how to combine them into data structures that precisely express the semantics of your program. This concept of encoding behavior into the type system helps to reduce the amount of checking and error path code that’s required, because invalid states are rejected by the toolchain at compile time rather than by the program at runtime.
This chapter also describes some of the ubiquitous data structures that are provided by Rust’s standard library:
Options, Results, Errors and Iterators. Familiarity with these standard tools will help you write idiomatic
Rust that is efficient and compact—in particular, they allow use of Rust’s question mark operator, which
supports error handling that is unobtrusive but still type-safe.
Note that Items that involve Rust traits are covered in the following chapter, but there is necessarily a degree of overlap with the Items in this chapter, because traits describe the behavior of types.
Item 1: Use the type system to express your data structures
who called them programers and not type writers
This Item provides a quick tour of Rust’s type system, starting with the fundamental types that the compiler makes available, then moving on to the various ways that values can be combined into data structures.
Rust’s enum type then takes a starring role. Although the basic version is equivalent to what other languages provide,
the ability to combine enum variants with data fields allows for enhanced flexibility and expressivity.
Fundamental Types
The basics of Rust’s type system are pretty familiar to anyone coming
from another statically typed programming language (such as C++, Go, or Java).
There’s a collection of integer types with specific sizes, both signed
(i8,
i16,
i32,
i64,
i128)
and unsigned
(u8,
u16,
u32,
u64,
u128).
There are also signed (isize) and unsigned
(usize) integers whose sizes match the pointer size on
the target system. However, you won’t be doing much in the way of converting between
pointers and integers with Rust, so that size equivalence isn’t really relevant. However, standard collections return their size
as a usize (from .len()), so collection indexing means that usize values are quite common—which is
obviously fine from a capacity perspective, as there can’t be more items in an in-memory collection than there are
memory addresses on the system.
The integral types do give us the first hint that Rust is a stricter world than C++. In Rust, attempting to
put a larger integer type (i32) into a smaller integer type (i16) generates a compile-time error:
error[E0308]: mismatched types
--> src/main.rs:18:18
|
18 | let y: i16 = x;
| --- ^ expected `i16`, found `i32`
| |
| expected due to this
|
help: you can convert an `i32` to an `i16` and panic if the converted value
doesn't fit
|
18 | let y: i16 = x.try_into().unwrap();
| ++++++++++++++++++++
This is reassuring: Rust is not going to sit there quietly while the programmer does things that are risky. Although we can see that the values involved in this particular conversion would be just fine, the compiler has to allow for the possibility of values where the conversion is not fine:
The error output also gives an early indication that while Rust has stronger rules, it also has helpful compiler
messages that point the way to how to comply with the rules. The suggested solution raises the question of how to
handle situations where the conversion would have to alter the value to fit, and we’ll have more to say on both
error handling (Item 4) and using panic! (Item 18) later.
Rust also doesn’t allow some things that might appear “safe,” such as putting a value from a smaller integer type into a larger integer type:
error[E0308]: mismatched types --> src/main.rs:36:18 | 36 | let y: i64 = x; | --- ^ expected `i64`, found `i32` | | | expected due to this | help: you can convert an `i32` to an `i64` | 36 | let y: i64 = x.into(); | +++++++
Here, the suggested solution doesn’t raise the specter of error handling, but the conversion does still need to be explicit. We’ll discuss type conversions in more detail later (Item 5).
Continuing with the unsurprising primitive types, Rust has a
bool type, floating point types
(f32,
f64),
and a unit type ()
(like C’s void).
More interesting is the char character type, which holds a
Unicode value (similar to Go’s rune type). Although this is stored as four bytes internally, there are again no silent
conversions to or from a 32-bit integer.
This precision in the type system forces you to be explicit about what you’re trying to express—a u32 value is
different from a char, which in turn is different from a sequence of UTF-8 bytes, which in turn is different
from a sequence of arbitrary bytes, and it’s up to you to specify exactly which you mean.1 Joel Spolsky’s famous blog post can help you understand which you need.
Of course, there are helper methods that allow you to convert between these different types, but their signatures force
you to handle (or explicitly ignore) the possibility of failure. For example, a Unicode code point can always be represented in 32 bits,2 so 'a' as u32 is allowed, but the other direction is trickier (as there
are some u32 values that are not valid Unicode code points):
char::from_u32-
Returns an
Option<char>, forcing the caller to handle the failure case. char::from_u32_unchecked-
Makes the assumption of validity but has the potential to result in undefined behavior if that assumption turns out not to be true. The function is marked
unsafeas a result, forcing the caller to useunsafetoo (Item 16).
Aggregate Types
Moving on to aggregate types, Rust has a variety of ways to combine related values. Most of these are familiar equivalents to the aggregation mechanisms available in other languages:
- Arrays
-
Hold multiple instances of a single type, where the number of instances is known at compile time. For example,
[u32; 4]is four 4-byte integers in a row. - Tuples
-
Hold instances of multiple heterogeneous types, where the number of elements and their types are known at compile time, for example,
(WidgetOffset, WidgetSize, WidgetColor). If the types in the tuple aren’t distinctive—for example,(i32, i32, &'static str, bool)—it’s better to give each element a name and use a struct. - Structs
-
Also hold instances of heterogeneous types known at compile time but allow both the overall type and the individual fields to be referred to by name.
Rust also includes the tuple struct, which is a crossbreed of a struct and a tuple: there’s a name for the overall
type but no names for the individual fields—they are referred to by number instead: s.0, s.1, and so on:
/// Struct with two unnamed fields.structTextMatch(usize,String);// Construct by providing the contents in order.letm=TextMatch(12,"needle".to_owned());// Access by field number.assert_eq!(m.0,12);
enums
This brings us to the jewel in the crown of Rust’s type system, the enum. With the basic form of an enum, it’s hard to see what there is to get excited about. As with other languages, the enum allows you
to specify a set of mutually exclusive values, possibly with a numeric value attached:
enumHttpResultCode{Ok=200,NotFound=404,Teapot=418,}letcode=HttpResultCode::NotFound;assert_eq!(codeasi32,404);
Because each enum definition creates a distinct type, this can be used to improve readability and maintainability of
functions that take bool arguments. Instead of:
print_page(/* both_sides= */true,/* color= */false);
a version that uses a pair of enums:
pubenumSides{Both,Single,}pubenumOutput{BlackAndWhite,Color,}pubfnprint_page(sides:Sides,color:Output){// ...}
is more type-safe and easier to read at the point of invocation:
print_page(Sides::Both,Output::BlackAndWhite);
Unlike the bool version, if a library user were to accidentally flip the order of the arguments, the compiler would
immediately complain:
error[E0308]: arguments to this function are incorrect
--> src/main.rs:104:9
|
104 | print_page(Output::BlackAndWhite, Sides::Single);
| ^^^^^^^^^^ --------------------- ------------- expected `enums::Output`,
| | found `enums::Sides`
| |
| expected `enums::Sides`, found `enums::Output`
|
note: function defined here
--> src/main.rs:145:12
|
145 | pub fn print_page(sides: Sides, color: Output) {
| ^^^^^^^^^^ ------------ -------------
help: swap these arguments
|
104 | print_page(Sides::Single, Output::BlackAndWhite);
| ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Using the newtype pattern—see Item 6—to wrap a bool also achieves type safety and maintainability; it’s
generally best to use the newtype pattern if the semantics will always be Boolean, and to use an enum if there’s a chance that a new
alternative—e.g., Sides::BothAlternateOrientation—could arise in the future.
The type safety of Rust’s enums continues with the match expression:
error[E0004]: non-exhaustive patterns: `HttpResultCode::Teapot` not covered --> src/main.rs:44:21 |
44|letmsg=matchcode{|^^^^pattern`HttpResultCode::Teapot`notcovered|note:`HttpResultCode`definedhere-->src/main.rs:10:5|7|enumHttpResultCode{|--------------...10|Teapot=418,|^^^^^^notcovered=note:thematchedvalueisoftype`HttpResultCode`help:ensurethatallpossiblecasesarebeinghandledbyaddingamatcharmwithawildcardpatternoranexplicitpatternasshown|46~HttpResultCode::NotFound=>"Not found",47~HttpResultCode::Teapot=>todo!(),|
The compiler forces the programmer to consider all of the possibilities that are represented by the enum,3 even if the result is just to add a default arm _ => {}.
(Note that modern C++ compilers can and do warn about missing switch arms for enums as well.)
enums with Fields
The true power of Rust’s enum feature comes from the fact that each variant can have data that comes along with it,
making it an aggregate type that acts as an algebraic data type (ADT). This is less familiar to programmers of mainstream
languages; in C/C++ terms, it’s like a combination of an enum with a union—only type-safe.
This means that the invariants of the program’s data structures can be encoded into Rust’s type system; states that
don’t comply with those invariants won’t even compile. A well-designed enum makes the creator’s intent clear to
humans as well as to the compiler:
usestd::collections::{HashMap,HashSet};pubenumSchedulerState{Inert,Pending(HashSet<Job>),Running(HashMap<CpuId,Vec<Job>>),}
Just from the type definition, it’s reasonable to guess that Jobs get queued up in the Pending state until the
scheduler is fully active, at which point they’re assigned to some per-CPU pool.
This highlights the central theme of this Item, which is to use Rust’s type system to express the concepts that are associated with the design of your software.
A dead giveaway for when this is not happening is a comment that explains when some field or parameter is valid:
This is a prime candidate for replacement with an enum holding data:
pubenumColor{Monochrome,Foreground(RgbColor),}pubstructDisplayProps{pubx:u32,puby:u32,pubcolor:Color,}
This small example illustrates a key piece of advice: make invalid states inexpressible in your types. Types that support only valid combinations of values mean that whole classes of errors are rejected by the compiler, leading to smaller and safer code.
Ubiquitous enum Types
Returning to the power of the enum, there are two concepts that are so common that Rust’s standard library
includes built-in enum types to express them; these types are ubiquitous in Rust code.
Option<T>
The first concept is that of an Option: either there’s
a value of a particular type (Some(T)) or there isn’t (None). Always use
Option for values that can be absent; never fall back to using sentinel values (-1, nullptr, …) to
try to express the same concept in-band.
There is one subtle point to consider, though. If you’re dealing with a collection of things, you need to decide
whether having zero things in the collection is the same as not having a collection. For most situations, the
distinction doesn’t arise and you can go ahead and use (say) Vec<Thing>: a count of zero things implies an absence of
things.
However, there are definitely other rare scenarios where the two cases need to be distinguished with
Option<Vec<Thing>>—for example, a cryptographic system might need to distinguish between “payload transported separately” and “empty payload provided.” (This is related to the
debates around the NULL marker for columns in SQL.)
Similarly, what’s the best choice for a String that might be absent? Does "" or None make more sense to indicate
the absence of a value? Either way works, but Option<String> clearly communicates the possibility that this value may
be absent.
Result<T, E>
The second common concept arises from error processing: if a function fails, how should that failure be reported?
Historically, special sentinel values (e.g., -errno return values from Linux system calls) or global
variables (errno for POSIX systems) were used. More recently, languages that support multiple or tuple return values
(such as Go) from functions may have a convention of returning a (result, error) pair, assuming the existence of
some suitable “zero” value for the result when the error is non-“zero.”
In Rust, there’s an enum for just this purpose: always encode the result of an operation that might fail as a
Result<T, E>. The T type holds the
successful result (in the Ok variant), and the E type holds error details (in the Err variant) on
failure.
Using the standard type makes the intent of the design clear. It also allows the use of standard transformations (Item 3)
and error processing (Item 4), which in turn makes it possible to streamline error processing with the ? operator as well.
Item 2: Use the type system to express common behavior
Item 1 discussed how to express data structures in the type system; this Item moves on to discuss the encoding of behavior in Rust’s type system.
The mechanisms described in this Item will generally feel familiar, as they all have direct analogs in other languages:
- Functions
-
The universal mechanism for associating a chunk of code with a name and a parameter list.
- Methods
-
Functions that are associated with an instance of a particular data structure. Methods are common in programming languages created after object-orientation arose as a programming paradigm.
- Function pointers
-
Supported by most languages in the C family, including C++ and Go, as a mechanism that allows an extra level of indirection when invoking other code.
- Closures
-
Originally most common in the Lisp family of languages but have been retrofitted to many popular programming languages, including C++ (since C++11) and Java (since Java 8).
- Traits
-
Describe collections of related functionality that all apply to the same underlying item. Traits have rough equivalents in many other languages, including abstract classes in C++ and interfaces in Go and Java.
Of course, all of these mechanisms have Rust-specific details that this Item will cover.
Of the preceding list, traits have the most significance for this book, as they describe so much of the behavior provided by the Rust compiler and standard library. Chapter 2 focuses on Items that give advice on designing and implementing traits, but their pervasiveness means that they crop up frequently in the other Items in this chapter too.
Functions and Methods
As with every other programming language, Rust uses functions to organize code into named chunks for reuse, with inputs to the code expressed as parameters. As with every other statically typed language, the types of the parameters and the return value are explicitly specified:
/// Return `x` divided by `y`.fndiv(x:f64,y:f64)->f64{ify==0.0{// Terminate the function and return a value.returnf64::NAN;}// The last expression in the function body is implicitly returned.x/y}/// Function called just for its side effects, with no return value./// Can also write the return value as `-> ()`.fnshow(x:f64){println!("x = {x}");}
If a function is intimately involved with a particular data structure, it is expressed as a method. A method
acts on an item of that type, identified by self, and is included within an impl DataStructure block. This
encapsulates related data and code together in an object-oriented way that’s similar to other languages; however,
in Rust, methods can be added to enum types as well as to struct types, in keeping with the pervasive
nature of Rust’s enum (Item 1):
enumShape{Rectangle{width:f64,height:f64},Circle{radius:f64},}implShape{pubfnarea(&self)->f64{matchself{Shape::Rectangle{width,height}=>width*height,Shape::Circle{radius}=>std::f64::consts::PI*radius*radius,}}}
The name of a method creates a label for the behavior it encodes, and the method signature gives type
information for its inputs and outputs. The first input for a method will be some variant of self, indicating
what the method might do to the data structure:
-
A
&selfparameter indicates that the contents of the data structure may be read from but will not be modified. -
A
&mut selfparameter indicates that the method might modify the contents of the data structure. -
A
selfparameter indicates that the method consumes the data structure.
Function Pointers
The previous section described how to associate a name (and a parameter list) with some code. However, invoking a function always results in the same code being executed; all that changes from invocation to invocation is the data that the function operates on. That covers a lot of possible scenarios, but what if the code needs to vary at runtime?
The simplest behavioral abstraction that allows this is the function pointer: a pointer to (just) some code, with a type that reflects the signature of the function:
fnsum(x:i32,y:i32)->i32{x+y}// Explicit coercion to `fn` type is required...letop:fn(i32,i32)->i32=sum;
The type is checked at compile time, so by the time the program runs, the value is just the size of a pointer. Function pointers have no other data associated with them, so they can be treated as values in various ways:
// `fn` types implement `Copy`letop1=op;letop2=op;// `fn` types implement `Eq`assert!(op1==op2);// `fn` implements `std::fmt::Pointer`, used by the {:p} format specifier.println!("op = {:p}",op);// Example output: "op = 0x101e9aeb0"
One technical detail to watch out for: explicit coercion to a fn type is needed, because just using the name of a
function doesn’t give you something of fn type:
error[E0369]: binary operation `==` cannot be applied to type
`fn(i32, i32) -> i32 {main::sum}`
--> src/main.rs:102:17
|
102 | assert!(op1 == op2);
| --- ^^ --- fn(i32, i32) -> i32 {main::sum}
| |
| fn(i32, i32) -> i32 {main::sum}
|
help: use parentheses to call these
|
102 | assert!(op1(/* i32 */, /* i32 */) == op2(/* i32 */, /* i32 */));
| ++++++++++++++++++++++ ++++++++++++++++++++++
Instead, the compiler error indicates that the type is something like fn(i32, i32) -> i32 {main::sum}, a type that’s
entirely internal to the compiler (i.e., could not be written in user code) and that identifies the specific function
as well as its signature. To put it another way, the type of sum encodes both the function’s signature and its
location for optimization reasons; this
type can be automatically coerced (Item 5) to a fn type.
Closures
The bare function pointers are limiting, because the only inputs available to the invoked function are those that are explicitly passed as parameter values. For example, consider some code that modifies every element of a slice using a function pointer:
// In real code, an `Iterator` method would be more appropriate.pubfnmodify_all(data:&mut[u32],mutator:fn(u32)->u32){forvalueindata{*value=mutator(*value);}}
This works for a simple mutation of the slice:
fnadd2(v:u32)->u32{v+2}letmutdata=vec![1,2,3];modify_all(&mutdata,add2);assert_eq!(data,vec![3,4,5]);
However, if the modification relies on any additional state, it’s not possible to implicitly pass that into the function pointer:
error[E0434]: can't capture dynamic environment in a fn item
--> src/main.rs:125:13
|
125 | v + amount_to_add
| ^^^^^^^^^^^^^
|
= help: use the `|| { ... }` closure form instead
The error message points to the right tool for the job: a closure. A closure is a chunk of code that looks like the body of a function definition (a lambda expression), except for the following:
-
It can be built as part of an expression, and so it need not have a name associated with it.
-
The input parameters are given in vertical bars
|param1, param2|(their associated types can usually be automatically deduced by the compiler). -
It can capture parts of the environment around it:
letamount_to_add=3;letadd_n=|y|{// a closure capturing `amount_to_add`y+amount_to_add};letz=add_n(5);assert_eq!(z,8);
To (roughly) understand how the capture works, imagine that the compiler creates a one-off, internal type that holds all of the parts of the environment that get mentioned in the lambda expression. When the closure is created, an instance of this ephemeral type is created to hold the relevant values, and when the closure is invoked, that instance is used as additional context:
letamount_to_add=3;// *Rough* equivalent to a capturing closure.structInternalContext<'a>{// references to captured variablesamount_to_add:&'au32,}impl<'a>InternalContext<'a>{fninternal_op(&self,y:u32)->u32{// body of the lambda expressiony+*self.amount_to_add}}letadd_n=InternalContext{amount_to_add:&amount_to_add,};letz=add_n.internal_op(5);assert_eq!(z,8);
The values that are held in this notional context are often references (Item 8) as here, but they can also be mutable
references to things in the environment, or values that are moved out of the environment altogether (by using the move
keyword before the input parameters).
Returning to the modify_all example, a closure can’t be used where a function pointer is expected:
error[E0308]: mismatched types
--> src/main.rs:199:31
|
199 | modify_all(&mut data, |y| y + amount_to_add);
| ---------- ^^^^^^^^^^^^^^^^^^^^^ expected fn pointer,
| | found closure
| |
| arguments to this function are incorrect
|
= note: expected fn pointer `fn(u32) -> u32`
found closure `[closure@src/main.rs:199:31: 199:34]`
note: closures can only be coerced to `fn` types if they do not capture any
variables
--> src/main.rs:199:39
|
199 | modify_all(&mut data, |y| y + amount_to_add);
| ^^^^^^^^^^^^^ `amount_to_add`
| captured here
note: function defined here
--> src/main.rs:60:12
|
60 | pub fn modify_all(data: &mut [u32], mutator: fn(u32) -> u32) {
| ^^^^^^^^^^ -----------------------
Instead, the code that receives the closure has to accept an instance of one of the Fn* traits:
pubfnmodify_all<F>(data:&mut[u32],mutmutator:F)whereF:FnMut(u32)->u32,{forvalueindata{*value=mutator(*value);}}
Rust has three different Fn* traits, which between them express some distinctions around this environment-capturing behavior:
FnOnce-
Describes a closure that can be called only once. If some part of the environment is
moved into the closure’s context, and the closure’s body subsequently moves it out of the closure’s context, then those moves can happen only once—there’s no other copy of the source item tomovefrom—and so the closure can be invoked only once. FnMut-
Describes a closure that can be called repeatedly and that can make changes to its environment because it mutably borrows from the environment.
Fn-
Describes a closure that can be called repeatedly and that only borrows values from the environment immutably.
The compiler automatically implements the appropriate subset of these Fn* traits for any lambda
expression in the code; it’s not possible to manually implement any of these traits (unlike C++’s operator() overload).4
Returning to the preceding rough mental model of closures, which of the traits the compiler auto-implements roughly corresponds to whether the captured environmental context has these elements:
FnOnce-
Any moved values
FnMut-
Any mutable references to values (
&mut T) Fn-
Only normal references to values (
&T)
The latter two traits in this list each have a trait bound of the preceding trait, which makes sense when you consider the things that use the closures:
-
If something expects to call a closure only once (indicated by receiving a
FnOnce), it’s OK to pass it a closure that’s capable of being repeatedly called (FnMut). -
If something expects to repeatedly call a closure that might mutate its environment (indicated by receiving a
FnMut), it’s OK to pass it a closure that doesn’t need to mutate its environment (Fn).
The bare function pointer type fn also notionally belongs at the end of this list; any (not-unsafe) fn type
automatically implements all of the Fn* traits, because it borrows nothing from the environment.
As a result, when writing code that accepts closures, use the most general Fn* trait that works, to allow the
greatest flexibility for callers—for example, accept FnOnce for closures that are used only once. The same
reasoning also leads to advice to prefer Fn* trait bounds over bare function pointers (fn).
Traits
The Fn* traits are more flexible than bare function pointers, but they can still describe only the behavior of a
single function, and even then only in terms of the function’s signature.
However, they are themselves examples of another mechanism for describing behavior in Rust’s type system, the
trait. A trait defines a set of related functions that some underlying item makes publicly available; moreover,
the functions are typically (but don’t have to be) methods, taking some variant of self as their first
argument.
Each function in a trait also has a name, providing a label that allows the compiler to disambiguate functions with the same signature, and more importantly, that allows programmers to deduce the intent of the function.
A Rust trait is roughly analogous to an “interface” in Go and Java, or to an “abstract class” (all virtual methods, no data members) in C++. Implementations of the trait must provide all the functions (but note that the trait definition can include a default implementation; Item 13) and can also have associated data that those implementations make use of. This means that code and data gets encapsulated together in a common abstraction, in a somewhat object-oriented (OO) manner.
Code that accepts a struct and calls functions on it is constrained to only ever work with that specific type. If there
are multiple types that implement common behavior, then it is more flexible to define a trait that encapsulates that
common behavior, and have the code make use of the trait’s functions rather than functions involving a specific struct.
This leads to the same kind of advice that turns up for other OO-influenced languages:5 prefer accepting trait types over concrete types if future flexibility is anticipated.
Sometimes, there is some behavior that you want to distinguish in the type system, but it cannot be expressed as
some specific function signature in a trait definition. For example, consider a Sort trait for sorting
collections; an implementation might be stable (elements that compare the same will appear in the same order before
and after the sort), but there’s no way to express this in the sort method arguments.
In this case, it’s still worth using the type system to track this requirement, using a marker trait:
pubtraitSort{/// Rearrange contents into sorted order.fnsort(&mutself);}/// Marker trait to indicate that a [`Sort`] sorts stably.pubtraitStableSort:Sort{}
A marker trait has no functions, but an implementation still has to declare that it is implementing the
trait—which acts as a promise from the implementer: “I solemnly swear that my implementation sorts stably.” Code
that relies on a stable sort can then specify the StableSort trait bound, relying on the honor system to preserve its
invariants. Use marker traits to distinguish behaviors that cannot be expressed in the trait function
signatures.
Once behavior has been encapsulated into Rust’s type system as a trait, it can be used in two ways:
-
As a trait bound, which constrains what types are acceptable for a generic data type or function at compile time
-
As a trait object, which constrains what types can be stored or passed to a function at runtime
The following sections describe these two possibilities, and Item 12 gives more detail about the trade-offs between them.
Trait bounds
A trait bound indicates that generic code that is parameterized by some type T can be used only when that
type T implements some specific trait. The presence of the trait bound means that the implementation of the
generic can use the functions from that trait, secure in the knowledge that the compiler will ensure that any T that
compiles does indeed have those functions. This check happens at compile time, when the generic is
monomorphized—converted from the generic code that deals with an arbitrary type T into
specific code that deals with one particular SomeType (what C++ would call template
instantiation).
This restriction on the target type T is explicit, encoded in the trait bounds: the trait can be implemented only by
types that satisfy the trait bounds. This contrasts with the equivalent situation in C++, where the constraints on
the type T used in a
template<typename T> are implicit:6 C++ template code still compiles only if all of the referenced functions are available at compile time, but
the checks are purely based on function name and signature. (This “duck typing” can lead to confusion; a C++ template that uses t.pop()
might compile for a T type parameter of either Stack or
Balloon—which is unlikely to be desired
behavior.)
The need for explicit trait bounds also means that a large fraction of generics use trait bounds. To see why this
is, turn the observation around and consider what can be done with a struct Thing<T> where there are no trait bounds
on T. Without a trait bound, the Thing can perform only operations that apply to any type T—basically just
moving or dropping the value. This in turn allows for generic containers, collections, and smart pointers, but not much
else. Anything that uses the type T is going to need a trait bound:
pubfndump_sorted<T>(mutcollection:T)whereT:Sort+IntoIterator,T::Item:std::fmt::Debug,{// Next line requires `T: Sort` trait bound.collection.sort();// Next line requires `T: IntoIterator` trait bound.foritemincollection{// Next line requires `T::Item : Debug` trait boundprintln!("{:?}",item);}}
So the advice here is to use trait bounds to express requirements on the types used in generics, but it’s easy advice to follow—the compiler will force you to comply with it regardless.
Trait objects
A trait object is the other way to make use of the encapsulation defined by a trait, but here, different possible implementations of the trait are chosen at runtime rather than compile time. This dynamic dispatch is analogous to using virtual functions in C++, and under the covers, Rust has “vtable” objects that are roughly analogous to those in C++.
This dynamic aspect of trait objects also means that they always have to be handled indirectly, via a reference
(e.g., &dyn Trait) or a pointer (e.g., Box<dyn Trait>) of some kind. The reason is that the size of the object
implementing the trait isn’t known at compile time—it could be a giant struct or a tiny enum—so
there’s no way to allocate the right amount of space for a bare trait object.
Not knowing the size of the concrete object also means that traits used as trait objects cannot have functions that return the Self type or
arguments (other than the receiver—the object on which the method is being invoked) that use Self. The reason is that the compiled-in-advance code that uses the trait object would have no idea how big that Self might be.
A trait that has a generic function fn some_fn<T>(t:T) allows for the possibility of an infinite number of
implemented functions, for all of the different types T that might exist. This is fine for a trait used as a trait
bound, because the infinite set of possibly invoked generic functions becomes a finite set of actually invoked
generic functions at compile time. The same is not true for a trait object: the code available at compile time has to
cope with all possible Ts that might arrive at runtime.
These two restrictions—no use of Self and no generic functions—are combined in the concept of
object safety. Only object-safe traits
can be used as trait objects.
Item 3: Prefer Option and Result transforms
over explicit match expressions
Item 1 expounded the virtues of enum and showed how match expressions force the programmer to take all
possibilities into account. Item 1 also introduced the two ubiquitous enums that the Rust standard library provides:
Option<T>-
To express that a value (of type
T) may or may not be present Result<T, E>-
For when an operation to return a value (of type
T) may not succeed and may instead return an error (of typeE)
This Item explores situations where you should try to avoid explicit match expressions for these particular enums,
preferring instead to use various transformation methods that the standard library provides for these types. Using these
transformation methods (which are typically themselves implemented as match expressions under the covers) leads to
code that is more compact and idiomatic and has clearer intent.
The first situation where a match is unnecessary is when only the value is relevant and the absence of value (and any
associated error) can just be ignored:
structS{field:Option<i32>,}lets=S{field:Some(42)};match&s.field{Some(i)=>println!("field is {i}"),None=>{}}
For this situation, an if let
expression is one line shorter and, more importantly, clearer:
ifletSome(i)=&s.field{println!("field is {i}");}
However, most of the time the programmer needs to provide the corresponding else arm: the absence of a value
(Option::None), possibly with an associated error (Result::Err(e)), is something that the programmer needs to deal
with. Designing software to cope with failure paths is hard, and most of that is essential complexity that no amount of
syntactic support can help with—specifically, deciding what should happen if an operation fails.
In some situations, the right decision is to perform an ostrich maneuver—put our heads in the sand and
explicitly not cope with failure. You can’t completely ignore the error arm, because Rust requires that the code deal
with both variants of the Error enum, but you can choose to treat a failure as fatal. Performing a panic! on
failure means that the program terminates, but the rest of the code can then be written with the assumption of success.
Doing this with an explicit match would be needlessly
verbose:
letresult=std::fs::File::open("/etc/passwd");letf=matchresult{Ok(f)=>f,Err(_e)=>panic!("Failed to open /etc/passwd!"),};// Assume `f` is a valid `std::fs::File` from here onward.
Both Option and Result provide a pair of methods that extract their inner value and panic! if it’s absent:
unwrap and
expect. The latter allows the error
message on failure to be personalized, but in either case, the resulting code is shorter and simpler—error
handling is delegated to the .unwrap() suffix (but is still present):
letf=std::fs::File::open("/etc/passwd").unwrap();
Be clear, though: these helper functions still panic!, so choosing to use them is the same as choosing to panic!
(Item 18).
However, in many situations, the right decision for error handling is to defer the decision to somebody else. This is
particularly true when writing a library, where the code may be used in all sorts of different environments that can’t
be foreseen by the library author. To make that somebody else’s job easier, prefer Result to Option for
expressing errors, even though this may involve conversions between different error types (Item 4).
Of course, this opens up the question, What counts as an error? In this example, failing to open a file is definitely
an error, and the details of that error (no such file? permission denied?) can help the user decide what to do next. On
the other hand, failing to retrieve the first()
element of a slice because that slice is empty isn’t really an error, and so it is expressed as an Option return type in
the standard library. Choosing between the two possibilities requires judgment, but lean toward Result if
an error might communicate anything useful.
Result also has a #[must_use]
attribute to nudge library
users in the right direction—if the code using the returned Result ignores it, the compiler will generate a
warning:
warning: unused `Result` that must be used --> src/main.rs:63:5 | 63 | f.set_len(0); // Truncate the file | ^^^^^^^^^^^^ | = note: this `Result` may be an `Err` variant, which should be handled = note: `#[warn(unused_must_use)]` on by default help: use `let _ = ...` to ignore the resulting value | 63 | let _ = f.set_len(0); // Truncate the file | +++++++
Explicitly using a match allows an error to propagate, but at the cost of some visible boilerplate (reminiscent of
Go):
pubfnfind_user(username:&str)->Result<UserId,std::io::Error>{letf=matchstd::fs::File::open("/etc/passwd"){Ok(f)=>f,Err(e)=>returnErr(From::from(e)),};// ...}
The key ingredient for reducing boilerplate is Rust’s question mark operator, ?. This piece of
syntactic sugar takes care of matching the Err arm, transforming the error type if necessary, and building the return Err(...) expression, all in a single
character:
pubfnfind_user(username:&str)->Result<UserId,std::io::Error>{letf=std::fs::File::open("/etc/passwd")?;// ...}
Newcomers to Rust sometimes find this disconcerting: the question mark can be hard to spot on first glance, leading to disquiet as to how the code can possibly work. However, even with a single character, the type system is still at work, ensuring that all of the possibilities expressed in the relevant types (Item 1) are covered—leaving the programmer to focus on the mainline code path without distractions.
What’s more, there’s generally no cost to these apparent method invocations: they are all generic functions marked
as #[inline], so
the generated code will typically compile to machine code that’s identical to the manual version.
These two factors taken together mean that you should prefer Option and Result transforms over explicit match
expressions.
In the previous example, the error types lined up: both the inner and outer methods expressed errors as
std::io::Error. That’s often not the case: one function may
accumulate errors from a variety of different sublibraries, each of which uses different error types.
Error mapping in general is discussed in Item 4, but for now, just be aware that a manual mapping:
pubfnfind_user(username:&str)->Result<UserId,String>{letf=matchstd::fs::File::open("/etc/passwd"){Ok(f)=>f,Err(e)=>{returnErr(format!("Failed to open password file: {:?}",e))}};// ...}
could be more succinctly and idiomatically expressed with the following
.map_err()
transformation:
pubfnfind_user(username:&str)->Result<UserId,String>{letf=std::fs::File::open("/etc/passwd").map_err(|e|format!("Failed to open password file: {:?}",e))?;// ...}
Better still, even this may not be necessary—if the outer error type can be created from the inner error type
via an implementation of the From standard trait (Item 10), then the compiler will automatically perform the
conversion without the need for a call to .map_err().
These kinds of transformations generalize more widely. The question mark operator is a big hammer; use transformation
methods on Option and Result types to maneuver them into a position where they can be a nail.
The standard library provides a wide variety of these transformation methods to make this possible. Figure 1-1
shows some of the most common methods (light rectangles) that transform between the relevant types (dark
rectangles). In line with Item 18, methods that can panic! are marked with an asterisk.
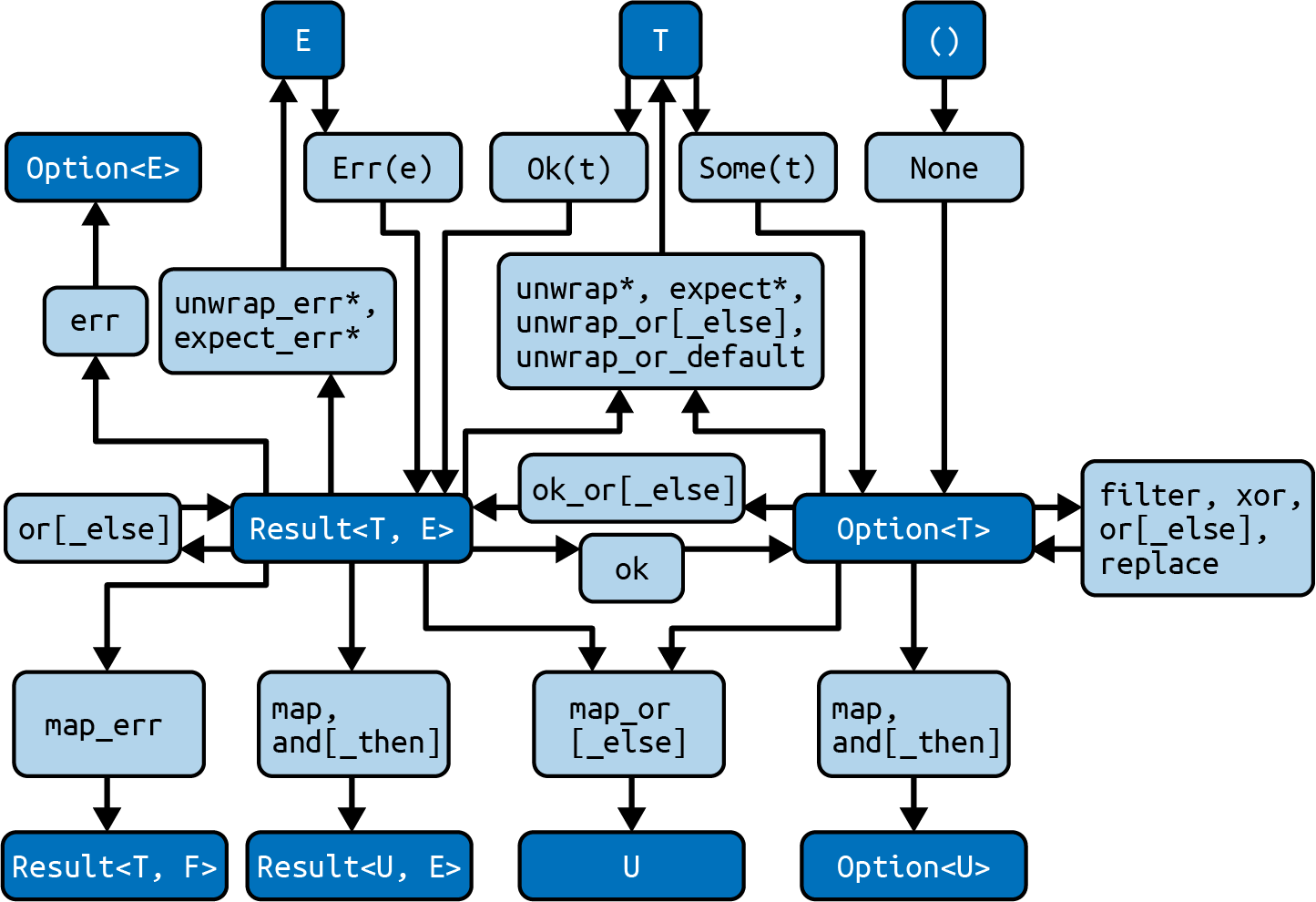
Figure 1-1. Option and Result transformations7
One common situation the diagram doesn’t cover deals with references. For example, consider a structure that optionally holds some data:
structInputData{payload:Option<Vec<u8>>,}
A method on this struct that tries to pass the payload to an encryption function with signature (&[u8]) -> Vec<u8>
fails if there’s a naive attempt to take a reference:
error[E0507]: cannot move out of `self.payload` which is behind a shared
reference
--> src/main.rs:15:18
|
15 | encrypt(&self.payload.unwrap_or(vec![]))
| ^^^^^^^^^^^^ move occurs because `self.payload` has type
| `Option<Vec<u8>>`, which does not implement the
| `Copy` trait
The right tool for this is the
as_ref()
method on Option.8 This method converts a reference-to-an-Option into an Option-of-a-reference:
pubfnencrypted(&self)->Vec<u8>{encrypt(self.payload.as_ref().unwrap_or(&vec![]))}
Things to Remember
-
Get used to the transformations of
OptionandResult, and preferResulttoOption. Use.as_ref()as needed when transformations involve references. -
Use these transformations in preference to explicit
matchoperations onOptionandResult. -
In particular, use these transformations to convert result types into a form where the
?operator applies.
Item 4: Prefer idiomatic Error types
Item 3 described how to use the transformations that the standard library provides for the Option and
Result types to allow concise, idiomatic handling of result types using the ? operator. It stopped
short of discussing how best to handle the variety of different error types E that arise as the second type argument
of a Result<T, E>; that’s the subject of this Item.
This is relevant only when there are a variety of different error types in play. If all of the different errors that a function encounters are already of the same type, it can just return that type. When there are errors of different types, there’s a decision to make about whether the suberror type information should be preserved.
The Error Trait
It’s always good to understand what the standard traits (Item 10) involve, and the relevant trait here is
std::error::Error. The E type parameter for a
Result doesn’t have to be a type that implements Error, but it’s a common convention that allows wrappers to
express appropriate trait bounds—so prefer to implement Error for your error types.
The first thing to notice is that the only hard requirement for Error types is the trait bounds: any type that
implements Error also has to implement the following traits:
-
The
Displaytrait, meaning that it can beformat!ed with{} -
The
Debugtrait, meaning that it can beformat!ed with{:?}
In other words, it should be possible to display Error types to both the user and the programmer.
The only method in the trait is
source(),9 which allows an Error type to expose
an inner, nested error. This method is optional—it comes with a default implementation (Item 13)
returning None, indicating that inner error information isn’t available.
One final thing to note: if you’re writing code for a no_std environment (Item 33), it may not be possible to
implement Error—the Error trait is currently implemented in
std, not core, and so is not available.10
Minimal Errors
If nested error information isn’t needed, then an implementation of the Error type need not be much more than a
String—one rare occasion where a “stringly typed” variable might be appropriate. It does need to be a
little more than a String though; while it’s possible to use String as the E type parameter:
pubfnfind_user(username:&str)->Result<UserId,String>{letf=std::fs::File::open("/etc/passwd").map_err(|e|format!("Failed to open password file: {:?}",e))?;// ...}
a String doesn’t implement Error, which we’d prefer so that other areas of code can deal with Errors. It’s not
possible to impl Error for String, because neither the trait nor the type belong to us (the so-called orphan
rule):
error[E0117]: only traits defined in the current crate can be implemented for
types defined outside of the crate
--> src/main.rs:18:5
|
18 | impl std::error::Error for String {}
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^------
| | |
| | `String` is not defined in the current crate
| impl doesn't use only types from inside the current crate
|
= note: define and implement a trait or new type instead
A type alias doesn’t help either, because it doesn’t create a new type and so doesn’t change the error message:
error[E0117]: only traits defined in the current crate can be implemented for
types defined outside of the crate
--> src/main.rs:41:5
|
41 | impl std::error::Error for MyError {}
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^-------
| | |
| | `String` is not defined in the current crate
| impl doesn't use only types from inside the current crate
|
= note: define and implement a trait or new type instead
As usual, the compiler error message gives a hint to solving the problem. Defining a tuple struct that wraps the
String type (the “newtype pattern,” Item 6) allows the Error trait to be implemented,
provided that Debug and Display are implemented too:
#[derive(Debug)]pubstructMyError(String);implstd::fmt::DisplayforMyError{fnfmt(&self,f:&mutstd::fmt::Formatter<'_>)->std::fmt::Result{write!(f,"{}",self.0)}}implstd::error::ErrorforMyError{}pubfnfind_user(username:&str)->Result<UserId,MyError>{letf=std::fs::File::open("/etc/passwd").map_err(|e|{MyError(format!("Failed to open password file: {:?}",e))})?;// ...}
For convenience, it may make sense to implement the From<String> trait to allow string values to be
easily converted into MyError instances (Item 5):
implFrom<String>forMyError{fnfrom(msg:String)->Self{Self(msg)}}
When it encounters the question mark operator (?), the compiler will automatically apply any relevant
From trait implementations that are needed to reach the destination error return type. This allows further
minimization:
pubfnfind_user(username:&str)->Result<UserId,MyError>{letf=std::fs::File::open("/etc/passwd").map_err(|e|format!("Failed to open password file: {:?}",e))?;// ...}
The error path here covers the following steps:
-
File::openreturns an error of typestd::io::Error. -
format!converts this to aString, using theDebugimplementation ofstd::io::Error. -
?makes the compiler look for and use aFromimplementation that can take it fromStringtoMyError.
Nested Errors
The alternative scenario is where the content of nested errors is important enough that it should be preserved and made available to the caller.
Consider a library function that attempts to return the first line of a file as a string, as long as the line is not too long. A moment’s thought reveals (at least) three distinct types of failure that could occur:
-
The file might not exist or might be inaccessible for reading.
-
The file might contain data that isn’t valid UTF-8 and so can’t be converted into a
String. -
The file might have a first line that is too long.
In line with Item 1, you can use the type system to express and encompass all of these possibilities as an
enum:
#[derive(Debug)]pubenumMyError{Io(std::io::Error),Utf8(std::string::FromUtf8Error),General(String),}
This enum definition includes a derive(Debug), but to satisfy the Error trait, a
Display
implementation is also needed:
implstd::fmt::DisplayforMyError{fnfmt(&self,f:&mutstd::fmt::Formatter<'_>)->std::fmt::Result{matchself{MyError::Io(e)=>write!(f,"IO error: {}",e),MyError::Utf8(e)=>write!(f,"UTF-8 error: {}",e),MyError::General(s)=>write!(f,"General error: {}",s),}}}
It also makes sense to override the default source() implementation for easy access to nested errors:
usestd::error::Error;implErrorforMyError{fnsource(&self)->Option<&(dynError+'static)>{matchself{MyError::Io(e)=>Some(e),MyError::Utf8(e)=>Some(e),MyError::General(_)=>None,}}}
The use of an enum allows the error handling to be concise while still preserving all of the type information across
different classes of error:
usestd::io::BufRead;// for `.read_until()`/// Maximum supported line length.constMAX_LEN:usize=1024;/// Return the first line of the given file.pubfnfirst_line(filename:&str)->Result<String,MyError>{letfile=std::fs::File::open(filename).map_err(MyError::Io)?;letmutreader=std::io::BufReader::new(file);// (A real implementation could just use `reader.read_line()`)letmutbuf=vec![];letlen=reader.read_until(b'\n',&mutbuf).map_err(MyError::Io)?;letresult=String::from_utf8(buf).map_err(MyError::Utf8)?;ifresult.len()>MAX_LEN{returnErr(MyError::General(format!("Line too long: {}",len)));}Ok(result)}
It’s also a good idea to implement the From trait for all of the suberror types (Item 5):
implFrom<std::io::Error>forMyError{fnfrom(e:std::io::Error)->Self{Self::Io(e)}}implFrom<std::string::FromUtf8Error>forMyError{fnfrom(e:std::string::FromUtf8Error)->Self{Self::Utf8(e)}}
This prevents library users from suffering under the orphan rules themselves: they aren’t allowed to implement
From on MyError, because both the trait and the struct are external to them.
Better still, implementing From allows for even more concision, because the question mark operator will
automatically perform any necessary From conversions, removing the need for .map_err():
usestd::io::BufRead;// for `.read_until()`/// Maximum supported line length.pubconstMAX_LEN:usize=1024;
/// Return the first line of the given file.pubfnfirst_line(filename:&str)->Result<String,MyError>{letfile=std::fs::File::open(filename)?;// `From<std::io::Error>`letmutreader=std::io::BufReader::new(file);letmutbuf=vec![];letlen=reader.read_until(b'\n',&mutbuf)?;// `From<std::io::Error>`letresult=String::from_utf8(buf)?;// `From<string::FromUtf8Error>`ifresult.len()>MAX_LEN{returnErr(MyError::General(format!("Line too long: {}",len)));}Ok(result)}
Writing a complete error type can involve a fair amount of boilerplate, which makes it a good candidate for automation
via a derive macro (Item 28). However, there’s no need to write such a macro yourself:
consider using the thiserror crate from David
Tolnay, which provides a high-quality, widely used implementation of just such a macro. The code generated by
thiserror is also careful to avoid making any thiserror types visible in the generated API, which in turn means that
the concerns associated with Item 24 don’t apply.
Trait Objects
The first approach to nested errors threw away all of the suberror detail, just preserving some string output
(format!("{:?}", err)). The second approach preserved the full type information for all possible suberrors but
required a full enumeration of all possible types of suberror.
This raises the question, Is there a middle ground between these two approaches, preserving suberror information without needing to manually include every possible error type?
Encoding the suberror information as a trait object avoids the need for an enum variant for every
possibility but erases the details of the specific underlying error types. The receiver of such an object would have
access to the methods of the Error trait and its trait bounds—source(), Display::fmt(), and Debug::fmt(),
in turn—but wouldn’t know the original static type of the suberror:
It turns out that this is possible, but it’s surprisingly subtle. Part of the difficulty comes from the object safety constraints on trait objects (Item 12), but Rust’s coherence rules also come into play, which (roughly) say that there can be at most one implementation of a trait for a type.
A putative WrappedError type would naively be expected to implement both of the
following:
-
The
Errortrait, because it is an error itself. -
The
From<Error>trait, to allow suberrors to be easily wrapped.
That means that a WrappedError can be created from an
inner
WrappedError, as WrappedError implements Error, and that clashes with the blanket reflexive implementation of From:
error[E0119]: conflicting implementations of trait `From<WrappedError>` for
type `WrappedError`
--> src/main.rs:279:5
|
279 | impl<E: 'static + Error> From<E> for WrappedError {
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: conflicting implementation in crate `core`:
- impl<T> From<T> for T;
David Tolnay’s anyhow is a crate that has already solved these
problems (by adding an extra level of indirection via Box) and that adds other helpful features (such
as stack traces) besides. As a result, it is rapidly becoming the standard recommendation for error handling—a
recommendation seconded here: consider using the anyhow crate for error handling in applications.
Libraries Versus Applications
The final advice from the previous section included the qualification “…for error handling in applications.” That’s because there’s often a distinction between code that’s written for reuse in a library and code that forms a top-level application.11
Code that’s written for a library can’t predict the environment in which the code is used, so it’s preferable to emit
concrete, detailed error information and leave the caller to figure out how to use that information. This leans toward
the enum-style nested errors described previously (and also avoids a dependency on anyhow in the public API of the
library, see Item 24).
However, application code typically needs to concentrate more on how to present errors to the user. It also potentially
has to cope with all of the different error types emitted by all of the libraries that are present in its dependency
graph (Item 25). As such, a more dynamic error type (such as
anyhow::Error) makes error handling simpler and more
consistent across the application.
Things to Remember
-
The standard
Errortrait requires little of you, so prefer to implement it for your error types. -
When dealing with heterogeneous underlying error types, decide whether it’s necessary to preserve those types.
-
If not, consider using
anyhowto wrap suberrors in application code. -
If so, encode them in an
enumand provide conversions. Consider usingthiserrorto help with this.
-
-
Consider using the
anyhowcrate for convenient idiomatic error handling in application code. -
It’s your decision, but whatever you decide, encode it in the type system (Item 1).
Item 5: Understand type conversions
Rust type conversions fall into three categories:
- Manual
-
User-defined type conversions provided by implementing the
FromandIntotraits - Semi-automatic
-
Explicit casts between values using the
askeyword - Automatic
-
Implicit coercion into a new type
The majority of this Item focuses on the first of these, manual conversions of types, because the latter two mostly don’t apply to conversions of user-defined types. There are a couple of exceptions to this, so sections at the end of the Item discuss casting and coercion—including how they can apply to a user-defined type.
Note that in contrast to many older languages, Rust does not perform automatic conversion between numeric types. This even applies to “safe” transformations of integral types:
error[E0308]: mismatched types --> src/main.rs:70:18 | 70 | let y: u64 = x; | --- ^ expected `u64`, found `u32` | | | expected due to this | help: you can convert a `u32` to a `u64` | 70 | let y: u64 = x.into(); | +++++++
User-Defined Type Conversions
As with other features of the language (Item 10), the ability to perform conversions between values of different user-defined types is encapsulated as a standard trait—or rather, as a set of related generic traits.
The four relevant traits that express the ability to convert values of a type are as follows:
From<T>-
Items of this type can be built from items of type
T, and the conversion always succeeds. TryFrom<T>-
Items of this type can be built from items of type
T, but the conversion might not succeed. Into<T>-
Items of this type can be converted into items of type
T, and the conversion always succeeds. TryInto<T>-
Items of this type can be converted into items of type
T, but the conversion might not succeed.
Given the discussion in Item 1 about expressing things in the type system, it’s no surprise to discover that the
difference with the Try... variants is that the sole trait method returns a Result rather than a guaranteed
new item. The Try... trait definitions also require an associated type that gives the type of the error E
emitted for failure situations.
The first piece of advice is therefore to implement (just) the Try... trait if it’s possible for a
conversion to fail, in line with Item 4. The alternative is to ignore the possibility of error (e.g., with
.unwrap()), but that needs to be a deliberate choice, and in most cases it’s best to leave that choice to the caller.
The type conversion traits have an obvious symmetry: if a type T can be transformed into a type U (via Into<U>),
isn’t that the same as it being possible to create an item of type U by transforming from an item of type T (via
From<T>)?
This is indeed the case, and it leads to the second piece of advice: implement the From trait for
conversions. The Rust standard library had to pick just one of the two possibilities, in order to prevent the system
from spiraling around in dizzy circles,12 and it came down on the side of automatically providing Into from a From implementation.
If you’re consuming one of these two traits, as a trait bound on a new generic of your own, then the advice is reversed:
use the Into trait for trait bounds. That way, the bound will be satisfied both by things that directly
implement Into and by things that only directly implement From.
This automatic conversion is highlighted by the documentation for From and Into, but it’s worth reading the relevant
part of the standard library code too, which is a blanket trait implementation:
impl<T,U>Into<U>forTwhereU:From<T>,{fninto(self)->U{U::from(self)}}
Translating a trait specification into words can help with understanding more complex trait bounds. In this case, it’s
fairly simple: “I can implement Into<U> for a type T whenever U already implements From<T>.”
The standard library also includes various implementations of these conversion traits for standard library types. As
you’d expect, there are From implementations for integral conversions where the destination type includes all possible
values of the source type (From<u32> for u64), and TryFrom implementations when the source might not fit in the
destination (TryFrom<u64> for u32).
There are also various other blanket trait implementations in addition to the Into version previously shown; these are
mostly for smart pointer types, allowing the smart pointer to be automatically constructed from an instance of
the type that it holds. This means that generic methods that accept smart pointer parameters can also be called with
plain old items; more on this to come and in Item 8.
The TryFrom trait also has a blanket implementation for any type that already implements the Into trait in the
opposite direction—which automatically includes (as shown previously) any type that implements From in the same
direction. In other words, if you can infallibly convert a T into a U, you can also fallibly obtain a U from a
T; as this conversion will always succeed, the associated error type is the helpfully named Infallible.13
There’s also one very specific generic implementation of From that sticks out, the reflexive implementation:
impl<T>From<T>forT{fnfrom(t:T)->T{t}}
Translated into words, this just says that “given a T, I can get a T.” That’s such an obvious “well,
duh” that it’s worth stopping to understand why this is useful.
Consider a simple newtype struct (Item 6) and a function that operates on it (ignoring that this function would be
better expressed as a method):
/// Integer value from an IANA-controlled range.#[derive(Clone, Copy, Debug)]pubstructIanaAllocated(pubu64);/// Indicate whether value is reserved.pubfnis_iana_reserved(s:IanaAllocated)->bool{s.0==0||s.0==65535}
This function can be invoked with instances of the struct:
lets=IanaAllocated(1);println!("{:?} reserved? {}",s,is_iana_reserved(s));// output: "IanaAllocated(1) reserved? false"
but even if From<u64> is implemented for the newtype wrapper:
implFrom<u64>forIanaAllocated{fnfrom(v:u64)->Self{Self(v)}}
the function can’t be directly invoked for u64 values:
error[E0308]: mismatched types
--> src/main.rs:77:25
|
77 | if is_iana_reserved(42) {
| ---------------- ^^ expected `IanaAllocated`, found integer
| |
| arguments to this function are incorrect
|
note: function defined here
--> src/main.rs:7:8
|
7 | pub fn is_iana_reserved(s: IanaAllocated) -> bool {
| ^^^^^^^^^^^^^^^^ ----------------
help: try wrapping the expression in `IanaAllocated`
|
77 | if is_iana_reserved(IanaAllocated(42)) {
| ++++++++++++++ +
However, a generic version of the function that accepts (and explicitly converts) anything
satisfying Into<IanaAllocated>:
pubfnis_iana_reserved<T>(s:T)->boolwhereT:Into<IanaAllocated>,{lets=s.into();s.0==0||s.0==65535}
allows this use:
ifis_iana_reserved(42){// ...}
With this trait bound in place, the reflexive trait implementation of From<T> makes more sense: it means that the
generic function copes with items that are already IanaAllocated instances, no conversion needed.
This pattern also explains why (and how) Rust code sometimes appears to be doing implicit casts between types: the
combination of From<T> implementations and Into<T> trait bounds leads to code that appears to magically convert at
the call site (but is still doing safe, explicit, conversions under the covers). This pattern becomes even more
powerful when combined with reference types and their related conversion traits; more in Item 8.
Casts
Rust includes the as keyword to perform explicit
casts between
some pairs of types.
The pairs of types that can be converted in this way constitute a fairly limited set, and the only user-defined types it
includes are “C-like” enums (those that have just an associated integer value). General integral conversions are
included, though, giving an alternative to into():
letx:u32=9;lety=xasu64;letz:u64=x.into();
The as version also allows lossy conversions:14
letx:u32=9;lety=xasu16;
which would be rejected by the from/into versions:
error[E0277]: the trait bound `u16: From<u32>` is not satisfied
--> src/main.rs:136:20
|
136 | let y: u16 = x.into();
| ^^^^ the trait `From<u32>` is not implemented for `u16`
|
= help: the following other types implement trait `From<T>`:
<u16 as From<NonZeroU16>>
<u16 as From<bool>>
<u16 as From<u8>>
= note: required for `u32` to implement `Into<u16>`
For consistency and safety, you should prefer from/into conversions over as casts, unless you
understand and need the precise casting semantics (e.g., for C interoperability).
This advice can be reinforced by Clippy (Item 29), which includes several lints about as conversions; however, these lints are
disabled by default.
Coercion
The explicit as casts described in the previous section are a superset of the implicit
coercions that the compiler will silently perform:
any coercion can be forced with an explicit as, but the converse is not true. In particular, the integral
conversions performed in the previous section are not coercions and so will always require as.
Most coercions involve silent conversions of pointer and reference types in ways that are sensible and convenient for the programmer, such as converting the following:
-
A mutable reference to an immutable reference (so you can use a
&mut Tas the argument to a function that takes a&T) -
A reference to a raw pointer (this isn’t
unsafe—the unsafety happens at the point where you’re foolish enough to dereference a raw pointer) -
A closure that happens to not capture any variables into a bare function pointer (Item 2)
-
A concrete item to a trait object, for a trait that the concrete item implements
There are only two coercions whose behavior can be affected by user-defined types. The first happens when a
user-defined type implements the Deref or the
DerefMut trait. These traits indicate that the user-defined
type is acting as a smart pointer of some sort (Item 8), and in this case the compiler will coerce a reference to
the smart pointer item into being a reference to an item of the type that the smart pointer contains (indicated by
its Target).
The second coercion of a user-defined type happens when a concrete item is converted to a trait object. This operation builds a fat pointer to the item; this pointer is fat because it includes both a pointer to the item’s location in memory and a pointer to the vtable for the concrete type’s implementation of the trait—see Item 8.
Item 6: Embrace the newtype pattern
Item 1 described tuple structs, where the fields of a struct have no names and are instead
referred to by number (self.0). This Item focuses on tuple structs that have a single entry of some existing type,
thus creating a new type that can hold exactly the same range of values as the enclosed type. This pattern is
sufficiently pervasive in Rust that it deserves its own Item and has its own name: the newtype pattern.
The simplest use of the newtype pattern is to indicate additional semantics for a type, over and above its normal behavior. To illustrate this, imagine a project that’s going to send a satellite to Mars.16 It’s a big project, so different groups have built different parts of the project. One group has handled the code for the rocket engines:
/// Fire the thrusters. Returns generated impulse in pound-force seconds.pubfnthruster_impulse(direction:Direction)->f64{// ...return42.0;}
while a different group handles the inertial guidance system:
/// Update trajectory model for impulse, provided in Newton seconds.pubfnupdate_trajectory(force:f64){// ...}
Eventually these different parts need to be joined together:
letthruster_force:f64=thruster_impulse(direction);letnew_direction=update_trajectory(thruster_force);
Ruh-roh.17
Rust includes a type alias feature, which allows the different groups to make their intentions clearer:
/// Units for force.pubtypePoundForceSeconds=f64;/// Fire the thrusters. Returns generated impulse.pubfnthruster_impulse(direction:Direction)->PoundForceSeconds{// ...return42.0;}
/// Units for force.pubtypeNewtonSeconds=f64;/// Update trajectory model for impulse.pubfnupdate_trajectory(force:NewtonSeconds){// ...}
However, the type aliases are effectively just documentation; they’re a stronger hint than the doc comments
of the previous version, but nothing stops a PoundForceSeconds value being used where a
NewtonSeconds value is expected:
letthruster_force:PoundForceSeconds=thruster_impulse(direction);letnew_direction=update_trajectory(thruster_force);
Ruh-roh once more.
This is the point where the newtype pattern helps:
/// Units for force.pubstructPoundForceSeconds(pubf64);/// Fire the thrusters. Returns generated impulse.pubfnthruster_impulse(direction:Direction)->PoundForceSeconds{// ...returnPoundForceSeconds(42.0);}
/// Units for force.pubstructNewtonSeconds(pubf64);/// Update trajectory model for impulse.pubfnupdate_trajectory(force:NewtonSeconds){// ...}
As the name implies, a newtype is a new type, and as such the compiler objects when there’s a mismatch of
types—here attempting to pass a PoundForceSeconds value to something that expects a NewtonSeconds value:
error[E0308]: mismatched types
--> src/main.rs:76:43
|
76 | let new_direction = update_trajectory(thruster_force);
| ----------------- ^^^^^^^^^^^^^^ expected
| | `NewtonSeconds`, found `PoundForceSeconds`
| |
| arguments to this function are incorrect
|
note: function defined here
--> src/main.rs:66:8
|
66 | pub fn update_trajectory(force: NewtonSeconds) {
| ^^^^^^^^^^^^^^^^^ --------------------
help: call `Into::into` on this expression to convert `PoundForceSeconds` into
`NewtonSeconds`
|
76 | let new_direction = update_trajectory(thruster_force.into());
| +++++++
As described in Item 5, adding an implementation of the standard From trait:
implFrom<PoundForceSeconds>forNewtonSeconds{fnfrom(val:PoundForceSeconds)->NewtonSeconds{NewtonSeconds(4.448222*val.0)}}
allows the necessary unit—and type—conversion to be performed with .into():
letthruster_force:PoundForceSeconds=thruster_impulse(direction);letnew_direction=update_trajectory(thruster_force.into());
The same pattern of using a newtype to mark additional “unit” semantics for a type can also help to make purely Boolean arguments less ambiguous. Revisiting the example from Item 1, using newtypes makes the meaning of arguments clear:
structDoubleSided(pubbool);structColorOutput(pubbool);fnprint_page(sides:DoubleSided,color:ColorOutput){// ...}
print_page(DoubleSided(true),ColorOutput(false));
If size efficiency or binary compatibility is a concern, then the #[repr(transparent)] attribute ensures that a newtype
has the same representation in memory as the inner type.
That’s the simple use of newtype, and it’s a specific example of Item 1—encoding semantics into the type system, so that the compiler takes care of policing those semantics.
Bypassing the Orphan Rule for Traits
The other common, but more subtle, scenario that requires the newtype pattern revolves around Rust’s orphan rule. Roughly speaking, this says that a crate can implement a trait for a type only if one of the following conditions holds:
-
The crate has defined the trait
-
The crate has defined the type
Attempting to implement a foreign trait for a foreign type:
leads to a compiler error (which in turn points the way back to newtypes):
error[E0117]: only traits defined in the current crate can be implemented for
types defined outside of the crate
--> src/main.rs:146:1
|
146 | impl fmt::Display for rand::rngs::StdRng {
| ^^^^^^^^^^^^^^^^^^^^^^------------------
| | |
| | `StdRng` is not defined in the current crate
| impl doesn't use only types from inside the current crate
|
= note: define and implement a trait or new type instead
The reason for this restriction is due to the risk of ambiguity: if two different crates in the dependency graph
(Item 25) were both to (say) impl std::fmt::Display for rand::rngs::StdRng, then the compiler/linker
has no way to choose between them.
This can frequently lead to frustration: for example, if you’re trying to serialize data that includes a type from
another crate, the orphan rule prevents you from writing impl serde::Serialize for somecrate::SomeType.18
But the newtype pattern means that you’re defining a new type, which is part of the current crate, and so the second part of the orphan trait rule applies. Implementing a foreign trait is now possible:
structMyRng(rand::rngs::StdRng);implfmt::DisplayforMyRng{fnfmt(&self,f:&mutfmt::Formatter<'_>)->Result<(),fmt::Error>{write!(f,"<MyRng instance>")}}
Newtype Limitations
The newtype pattern solves these two classes of problems—preventing unit conversions and bypassing the orphan rule—but it does come with some awkwardness: every operation that involves the newtype needs to forward to the inner type.
On a trivial level, that means that the code has to use thing.0 throughout, rather than just thing, but that’s easy,
and the compiler will tell you where it’s needed.
The more significant awkwardness is that any trait implementations on the inner type are lost: because the newtype is a new type, the existing inner implementation doesn’t apply.
For derivable traits, this just means that the newtype declaration ends up with lots of derives:
#[derive(Debug, Copy, Clone, Eq, PartialEq, Ord, PartialOrd)]pubstructNewType(InnerType);
However, for more sophisticated traits, some forwarding boilerplate is needed to recover the inner type’s implementation, for example:
usestd::fmt;implfmt::DisplayforNewType{fnfmt(&self,f:&mutfmt::Formatter<'_>)->Result<(),fmt::Error>{self.0.fmt(f)}}
Item 7: Use builders for complex types
This Item describes the builder pattern, where complex data structures have an associated builder type that makes it easier for users to create instances of the data structure.
Rust insists that all fields in a struct must be filled in when a new instance of that struct is created. This
keeps the code safe by ensuring that there are never any uninitialized values but does lead to more verbose boilerplate
code than is ideal.
For example, any optional fields have to be explicitly marked as absent with None:
/// Phone number in E164 format.#[derive(Debug, Clone)]pubstructPhoneNumberE164(pubString);#[derive(Debug, Default)]pubstructDetails{pubgiven_name:String,pubpreferred_name:Option<String>,pubmiddle_name:Option<String>,pubfamily_name:String,pubmobile_phone:Option<PhoneNumberE164>,}// ...letdizzy=Details{given_name:"Dizzy".to_owned(),preferred_name:None,middle_name:None,family_name:"Mixer".to_owned(),mobile_phone:None,};
This boilerplate code is also brittle, in the sense that a future change that adds a new field to the struct requires
an update to every place that builds the structure.
The boilerplate can be significantly reduced by implementing and using the
Default trait, as described in
Item 10:
letdizzy=Details{given_name:"Dizzy".to_owned(),family_name:"Mixer".to_owned(),..Default::default()};
Using Default also helps reduce the changes needed when a new field is added, provided that the new field is itself of
a type that implements Default.
That’s a more general concern: the automatically derived implementation of Default works only if all of
the field types implement the Default trait. If there’s a field that doesn’t play along, the derive step doesn’t
work:
error[E0277]: the trait bound `Date: Default` is not satisfied --> src/main.rs:48:9 | 41 | #[derive(Debug, Default)] | ------- in this derive macro expansion ... 48 | pub date_of_birth: time::Date, | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ the trait `Default` is not | implemented for `Date` | = note: this error originates in the derive macro `Default`
The code can’t implement Default for chrono::Utc because of the orphan rule; but even if it could, it wouldn’t
be helpful—using a default value for date of birth is going to be wrong almost all of the time.
The absence of Default means that all of the fields have to be filled out manually:
letbob=Details{given_name:"Robert".to_owned(),preferred_name:Some("Bob".to_owned()),middle_name:Some("the".to_owned()),family_name:"Builder".to_owned(),mobile_phone:None,date_of_birth:time::Date::from_calendar_date(1998,time::Month::November,28,).unwrap(),last_seen:None,};
These ergonomics can be improved if you implement the builder pattern for complex data structures.
The simplest variant of the builder pattern is a separate struct that holds the information needed to construct the
item. For simplicity, the example will hold an instance of the item itself:
pubstructDetailsBuilder(Details);implDetailsBuilder{/// Start building a new [`Details`] object.pubfnnew(given_name:&str,family_name:&str,date_of_birth:time::Date,)->Self{DetailsBuilder(Details{given_name:given_name.to_owned(),preferred_name:None,middle_name:None,family_name:family_name.to_owned(),mobile_phone:None,date_of_birth,last_seen:None,})}}
The builder type can then be equipped with helper methods that fill out the nascent item’s fields. Each such
method consumes self but emits a new Self, allowing different construction methods to be chained:
/// Set the preferred name.pubfnpreferred_name(mutself,preferred_name:&str)->Self{self.0.preferred_name=Some(preferred_name.to_owned());self}/// Set the middle name.pubfnmiddle_name(mutself,middle_name:&str)->Self{self.0.middle_name=Some(middle_name.to_owned());self}
These helper methods can be more helpful than just simple setters:
/// Update the `last_seen` field to the current date/time.pubfnjust_seen(mutself)->Self{self.0.last_seen=Some(time::OffsetDateTime::now_utc());self}
The final method to be invoked for the builder consumes the builder and emits the built item:
/// Consume the builder object and return a fully built [`Details`]/// object.pubfnbuild(self)->Details{self.0}
Overall, this allows clients of the builder to have a more ergonomic building experience:
letalso_bob=DetailsBuilder::new("Robert","Builder",time::Date::from_calendar_date(1998,time::Month::November,28).unwrap(),).middle_name("the").preferred_name("Bob").just_seen().build();
The all-consuming nature of this style of builder leads to a couple of wrinkles. The first is that separating out stages of the build process can’t be done on its own:
error[E0382]: use of moved value: `builder`
--> src/main.rs:256:15
|
247 | let builder = DetailsBuilder::new(
| ------- move occurs because `builder` has type `DetailsBuilder`,
| which does not implement the `Copy` trait
...
254 | builder.preferred_name("Bob");
| --------------------- `builder` moved due to this method
| call
255 | }
256 | let bob = builder.build();
| ^^^^^^^ value used here after move
|
note: `DetailsBuilder::preferred_name` takes ownership of the receiver `self`,
which moves `builder`
--> src/main.rs:60:35
|
27 | pub fn preferred_name(mut self, preferred_name: &str) -> Self {
| ^^^^
This can be worked around by assigning the consumed builder back to the same variable:
letmutbuilder=DetailsBuilder::new("Robert","Builder",time::Date::from_calendar_date(1998,time::Month::November,28).unwrap(),);ifinformal{builder=builder.preferred_name("Bob");}letbob=builder.build();
The other downside to the all-consuming nature of this builder is that only one item can be built; trying to create
multiple instances by repeatedly calling build() on the same builder falls foul of the compiler, as you’d expect:
error[E0382]: use of moved value: `smithy`
--> src/main.rs:159:39
|
154 | let smithy = DetailsBuilder::new(
| ------ move occurs because `smithy` has type `base::DetailsBuilder`,
| which does not implement the `Copy` trait
...
159 | let clones = vec![smithy.build(), smithy.build(), smithy.build()];
| ------- ^^^^^^ value used here after move
| |
| `smithy` moved due to this method call
An alternative approach is for the builder’s methods to take a &mut self and emit a &mut Self:
/// Update the `last_seen` field to the current date/time.pubfnjust_seen(&mutself)->&mutSelf{self.0.last_seen=Some(time::OffsetDateTime::now_utc());self}
This removes the need for self-assignment in separate build stages:
letmutbuilder=DetailsBuilder::new("Robert","Builder",time::Date::from_calendar_date(1998,time::Month::November,28).unwrap(),);ifinformal{builder.preferred_name("Bob");// no `builder = ...`}letbob=builder.build();
However, this version makes it impossible to chain the construction of the builder together with invocation of its setter methods:
error[E0716]: temporary value dropped while borrowed
--> src/main.rs:265:19
|
265 | let builder = DetailsBuilder::new(
| ___________________^
266 | | "Robert",
267 | | "Builder",
268 | | time::Date::from_calendar_date(1998, time::Month::November, 28)
269 | | .unwrap(),
270 | | )
| |_____^ creates a temporary value which is freed while still in use
271 | .middle_name("the")
272 | .just_seen();
| - temporary value is freed at the end of this statement
273 | let bob = builder.build();
| --------------- borrow later used here
|
= note: consider using a `let` binding to create a longer lived value
As indicated by the compiler error, you can work around this by letting the builder item have a name:
letmutbuilder=DetailsBuilder::new("Robert","Builder",time::Date::from_calendar_date(1998,time::Month::November,28).unwrap(),);builder.middle_name("the").just_seen();ifinformal{builder.preferred_name("Bob");}letbob=builder.build();
This mutating builder variant also allows for building multiple items. The signature of the build() method has to
not consume self and so must be as follows:
/// Construct a fully built [`Details`] object.pubfnbuild(&self)->Details{// ...}
The implementation of this repeatable build() method then has to construct a fresh item on each invocation. If the
underlying item implements Clone, this is easy—the builder can hold a template and clone() it for each
build. If the underlying item doesn’t implement Clone, then the builder needs to have enough state to be able to
manually construct an instance of the underlying item on each call to build().
With any style of builder pattern, the boilerplate code is now confined to one place—the builder—rather than being needed at every place that uses the underlying type.
The boilerplate that remains can potentially be reduced still further by use of a macro (Item 28), but if you go down
this road, you should also check whether there’s an existing crate (such as the
derive_builder crate, in particular) that provides what’s needed—assuming
that you’re happy to take a dependency on it (Item 25).
Item 8: Familiarize yourself with reference and pointer types
For programming in general, a reference is a way to indirectly access some data structure, separately from whatever variable owns that data structure. In practice, this is usually implemented as a pointer: a number whose value is the address in memory of the data structure.
A modern CPU will typically police a few constraints on pointers—the memory address should be in a valid range of memory (whether virtual or physical) and may need to be aligned (e.g., a 4-byte integer value might be accessible only if its address is a multiple of 4).
However, higher-level programming languages usually encode more information about pointers in their type systems. In C-derived languages, including Rust, pointers have a type that indicates what kind of data structure is expected to be present at the pointed-to memory address. This allows the code to interpret the contents of memory at that address and in the memory following that address.
This basic level of pointer information—putative memory location and expected data structure layout—is
represented in Rust as a raw pointer. However, safe Rust code does not use raw pointers, because Rust provides
richer reference and pointer types that provide additional safety guarantees and constraints. These reference and
pointer types are the subject of this Item; raw pointers are relegated to Item 16 (which discusses unsafe code).
Rust References
The most ubiquitous pointer-like type in Rust is the reference, with a type that is written as &T for some type
T. Although this is a pointer value under the covers, the compiler ensures that various rules around its use are
observed: it must always point to a valid, correctly aligned instance of the relevant type T, whose lifetime (Item 14) extends beyond its use, and it must satisfy the borrow checking rules (Item 15). These
additional constraints are always implied by the term reference in Rust, and so the bare term pointer is generally
rare.
The constraint that a Rust reference must point to a valid, correctly aligned item is shared by C++’s reference types. However, C++ has no concept of lifetimes and so allows footguns with dangling references:19
Rust’s borrowing and lifetime checks mean that the equivalent code doesn’t even compile:
error[E0515]: cannot return reference to local variable `x`
--> src/main.rs:477:5
|
477 | &x
| ^^ returns a reference to data owned by the current function
A Rust reference &T allows read-only access to the underlying item (roughly equivalent to
C++’s const T&). A
mutable reference that also allows the underlying item to be modified is written as &mut T and is also subject
to the borrow checking rules discussed in Item 15. This naming pattern reflects a slightly different mindset between
Rust and C++:
-
In Rust, the default variant is read-only, and writable types are marked specially (with
mut). -
In C++, the default variant is writable, and read-only types are marked specially (with
const).
The compiler converts Rust code that uses references into machine code that uses simple pointers, which are eight bytes in size on a 64-bit platform (which this Item assumes throughout). For example, a pair of local variables together with references to them:
pubstructPoint{pubx:u32,puby:u32,}letpt=Point{x:1,y:2};letx=0u64;letref_x=&x;letref_pt=&pt;
might end up laid out on the stack as shown in Figure 1-2.
Figure 1-2. Stack layout with pointers to local variables
A Rust reference can refer to items that are located either on the stack or on the heap.
Rust allocates items on the stack by default, but the Box<T> pointer type (roughly equivalent to C++’s
std::unique_ptr<T>) forces allocation to occur on the heap, which in turn means that
the allocated item can outlive the scope of the current block. Under the covers, Box<T> is also a simple eight-byte
pointer value:
letbox_pt=Box::new(Point{x:10,y:20});
This is depicted in Figure 1-3.
Figure 1-3. Stack Box pointer to struct on heap
Pointer Traits
A method that expects a reference argument like &Point can also be fed a &Box<Point>:
fnshow(pt:&Point){println!("({}, {})",pt.x,pt.y);}show(ref_pt);show(&box_pt);
(1, 2) (10, 20)
This is possible because Box<T> implements the Deref
trait, with Target = T. An implementation of this trait for some type means that the trait’s
deref() method can be used to create a reference
to the Target type. There’s also an equivalent
DerefMut trait, which emits a mutable reference to
the Target type.
The Deref/DerefMut traits are somewhat special, because the Rust compiler has specific behavior when dealing with
types that implement them. When the compiler encounters a dereferencing expression
(e.g., *x), it looks for
and uses an implementation of one of these traits, depending on whether the dereference requires mutable access or not.
This Deref coercion allows various smart pointer types to behave like normal references and is one of the few
mechanisms that allow implicit type conversion in Rust (as described in Item 5).
As a technical aside, it’s worth understanding why the Deref traits can’t be generic (Deref<Target>) for the
destination type. If they were, then it would be possible for some type ConfusedPtr to implement both Deref<TypeA>
and Deref<TypeB>, and that would leave the compiler unable to deduce a single unique type for an expression like *x.
So instead, the destination type is encoded as the associated type named
Target.
This technical aside provides a contrast to two other standard pointer traits, the
AsRef and
AsMut traits. These traits don’t induce special
behavior in the compiler but allow conversions to a reference or mutable reference via an explicit call to their
trait functions (as_ref() and
as_mut(), respectively). The destination
type for these conversions is encoded as a type parameter (e.g., AsRef<Point>), which means that a single container
type can support multiple destinations.
For example, the standard String type implements the
Deref trait with Target = str, meaning that an expression like &my_string can be coerced to type &str. But it
also implements the following:
-
AsRef<[u8]>, allowing conversion to a byte slice&[u8] -
AsRef<OsStr>, allowing conversion to an OS string -
AsRef<Path>, allowing conversion to a filesystem path -
AsRef<str>, allowing conversion to a string slice&str(as withDeref)
Fat Pointer Types
Rust has two built-in fat pointer types: slices and trait objects. These are types that act as pointers but hold additional information about the thing they are pointing to.
Slices
The first fat pointer type is the slice: a reference to a subset of some contiguous collection of values. It’s
built from a (non-owning) simple pointer, together with a length field, making it twice the size of a simple pointer (16
bytes on a 64-bit platform). The type of a slice is written as &[T]—a reference to [T], which is the
notional type for a contiguous collection of values of type T.
The notional type [T] can’t be instantiated, but there are two common containers that embody it. The first is the
array: a contiguous collection of values having a size that is known at compile time—an array with five values
will always have five values. A slice can therefore refer to a subset of an array (as depicted in Figure 1-4):
letarray:[u64;5]=[0,1,2,3,4];letslice=&array[1..3];
Figure 1-4. Stack slice pointing into a stack array
The other common container for contiguous values is a Vec<T>. This holds a contiguous collection of
values like an array, but unlike an array, the number of values in the Vec can grow (e.g., with
push(value)) or shrink (e.g., with
pop()).
The contents of the Vec are kept on the heap (which allows for this variation in size) but are always contiguous, and
so a slice can refer to a subset of a vector, as shown in Figure 1-5:
letmutvector=Vec::<u64>::with_capacity(8);foriin0..5{vector.push(i);}letvslice=&vector[1..3];
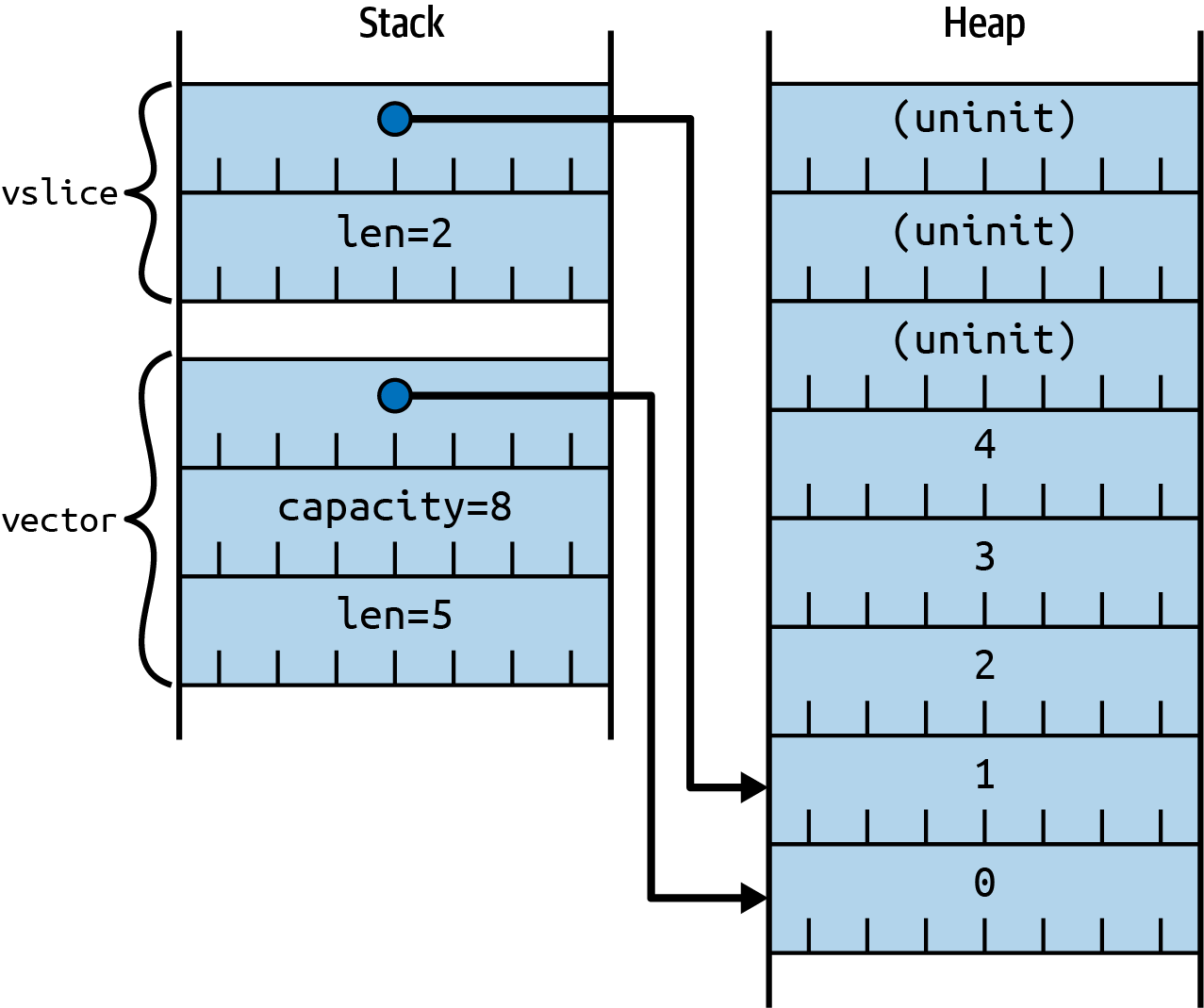
Figure 1-5. Stack slice pointing into Vec contents on the heap
There’s quite a lot going on under the covers for the expression &vector[1..3], so it’s worth breaking it down into its
components:
-
The
1..3part is a range expression; the compiler converts this into an instance of theRange<usize>type, which holds an inclusive lower bound and an exclusive upper bound. -
The
Rangetype implements theSliceIndex<T>trait, which describes indexing operations on slices of an arbitrary typeT(so theOutputtype is[T]). -
The
vector[ ]part is an indexing expression; the compiler converts this into an invocation of theIndextrait’sindexmethod onvector, together with a dereference (i.e.,*vector.index( )).20 -
vector[1..3]therefore invokesVec<T>’s implementation ofIndex<I>, which requiresIto be an instance ofSliceIndex<[u64]>. This works becauseRange<usize>implementsSliceIndex<[T]>for anyT, includingu64. -
&vector[1..3]undoes the dereference, resulting in a final expression type of&[u64].
Trait objects
The second built-in fat pointer type is a trait object: a reference to some item that implements a particular trait. It’s built from a simple pointer to the item, together with an internal pointer to the type’s vtable, giving a size of 16 bytes (on a 64-bit platform). The vtable for a type’s implementation of a trait holds function pointers for each of the method implementations, allowing dynamic dispatch at runtime (Item 12).21
So a simple trait:
traitCalculate{fnadd(&self,l:u64,r:u64)->u64;fnmul(&self,l:u64,r:u64)->u64;}
with a struct that implements it:
structModulo(pubu64);implCalculateforModulo{fnadd(&self,l:u64,r:u64)->u64{(l+r)%self.0}fnmul(&self,l:u64,r:u64)->u64{(l*r)%self.0}}letmod3=Modulo(3);
can be converted to a trait object of type &dyn Trait. The dyn keyword highlights the fact that dynamic dispatch is involved:
// Need an explicit type to force dynamic dispatch.lettobj:&dynCalculate=&mod3;letresult=tobj.add(2,2);assert_eq!(result,1);
The equivalent memory layout is shown in Figure 1-6.
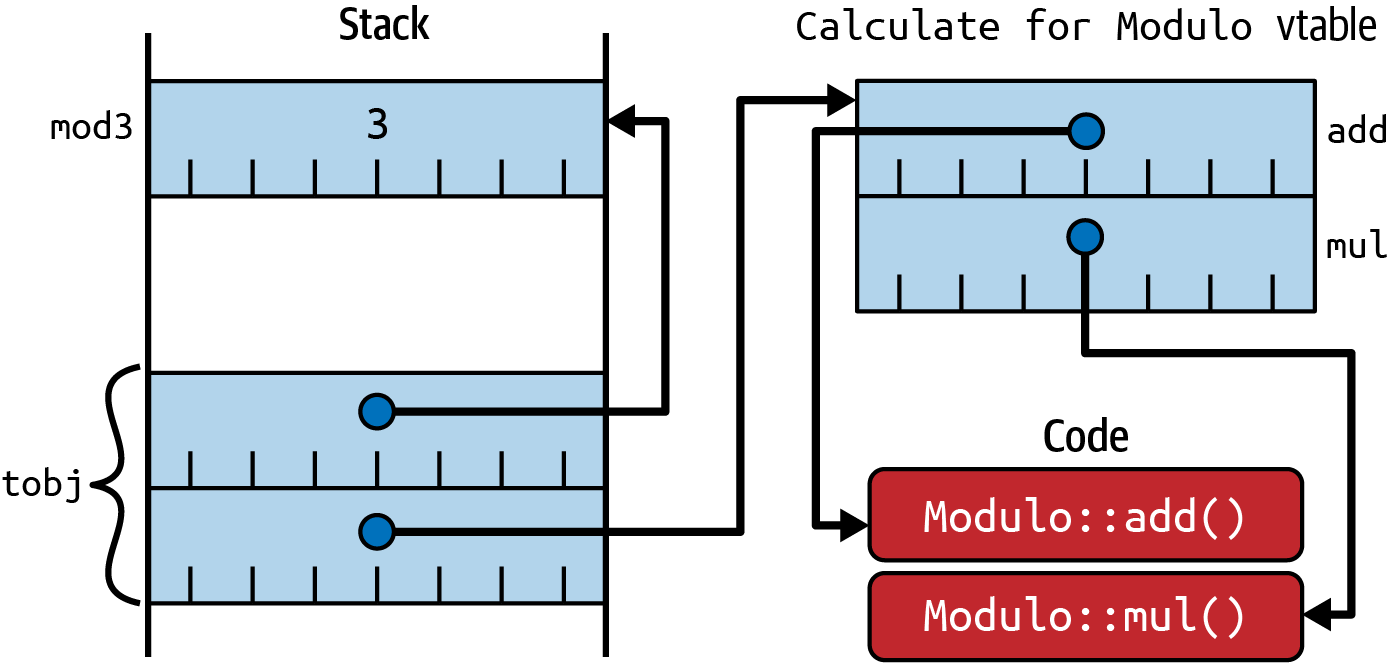
Figure 1-6. Trait object with pointers to concrete item and vtable
Code that holds a trait object can invoke the methods of the trait via the function pointers in the vtable, passing in
the item pointer as the &self parameter; see Item 12 for more information and advice.
More Pointer Traits
“Pointer Traits” described two pairs of traits (Deref/DerefMut, AsRef/AsMut) that are used when dealing
with types that can be easily converted into references. There are a few more standard traits that can also come into
play when working with pointer-like types, whether from the standard library or user defined.
The simplest of these is the Pointer trait, which
formats a pointer value for output. This can be helpful for low-level debugging, and the compiler will reach for this
trait automatically when it encounters the {:p} format specifier.
More intriguing are the Borrow and
BorrowMut traits, which each have a single method
(borrow and
borrow_mut, respectively). This method
has the same signature as the equivalent AsRef/AsMut trait methods.
The key difference in intents between these traits is visible via the blanket implementations that the standard
library provides. Given an arbitrary Rust reference &T, there is a blanket implementation of both AsRef and
Borrow; likewise, for a mutable reference &mut T, there’s a blanket implementation of both AsMut and BorrowMut.
However, Borrow also has a blanket implementation for (non-reference) types: impl<T> Borrow<T> for T.
This means that a method accepting the Borrow trait can cope equally with instances of T as well as references-to-T:
fnadd_four<T:std::borrow::Borrow<i32>>(v:T)->i32{v.borrow()+4}assert_eq!(add_four(&2),6);assert_eq!(add_four(2),6);
The standard library’s container types have more realistic uses of Borrow. For example,
HashMap::get uses Borrow to allow
convenient retrieval of entries whether keyed by value or by reference.
The ToOwned trait builds on the Borrow
trait, adding a to_owned() method that
produces a new owned item of the underlying type. This is a generalization of the Clone trait: where Clone
specifically requires a Rust reference &T, ToOwned instead copes with things that implement Borrow.
This gives a couple of possibilities for handling both references and moved items in a unified way:
-
A function that operates on references to some type can accept
Borrowso that it can also be called with moved items as well as references. -
A function that operates on owned items of some type can accept
ToOwnedso that it can also be called with references to items as well as moved items; any references passed to it will be replicated into a locally owned item.
Although it’s not a pointer type, the
Cow type is worth mentioning at this point, because it provides an alternative
way of dealing with the same kind of situation. Cow is an enum that can hold either owned data or a reference to
borrowed data. The peculiar name stands for “clone-on-write”: a Cow input can remain as borrowed
data right up to the point where it needs to be modified, but it becomes an owned copy at the point where the data needs to
be altered.
Smart Pointer Types
The Rust standard library includes a variety of types that act like pointers to some degree or another, mediated by the
standard library traits previously described. These smart pointer types each come with some particular semantics and
guarantees, which has the advantage that the right combination of them can give fine-grained control over the pointer’s
behavior, but has the disadvantage that the resulting types can seem overwhelming at first (Rc<RefCell<Vec<T>>>,
anyone?).
The first smart pointer type is Rc<T>, which is a
reference-counted pointer to an item (roughly analogous to C++’s std::shared_ptr<T>). It implements all of the
pointer-related traits and so acts like a Box<T> in many ways.
This is useful for data structures where the same item can be reached in different ways, but it removes one of Rust’s
core rules around ownership—that each item has only one owner. Relaxing this rule means that it is now possible
to leak data: if item A has an Rc pointer to item B, and item B has an Rc pointer to A, then the pair will never be
dropped.22 To put it another way: you need Rc to support cyclical data structures, but the downside is that
there are now cycles in your data structures.
The risk of leaks can be ameliorated in some cases by the related
Weak<T> type, which holds a non-owning reference to
the underlying item (roughly analogous to C++’s std::weak_ptr<T>). Holding a weak reference doesn’t
prevent the underlying item from being dropped (when all strong references are removed), so making use of the Weak<T>
involves an upgrade to an Rc<T>—which can fail.
Under the hood, Rc is (currently) implemented as a pair of reference counts together with the referenced item, all
stored on the heap (as depicted in Figure 1-7):
usestd::rc::Rc;letrc1:Rc<u64>=Rc::new(42);letrc2=rc1.clone();letwk=Rc::downgrade(&rc1);
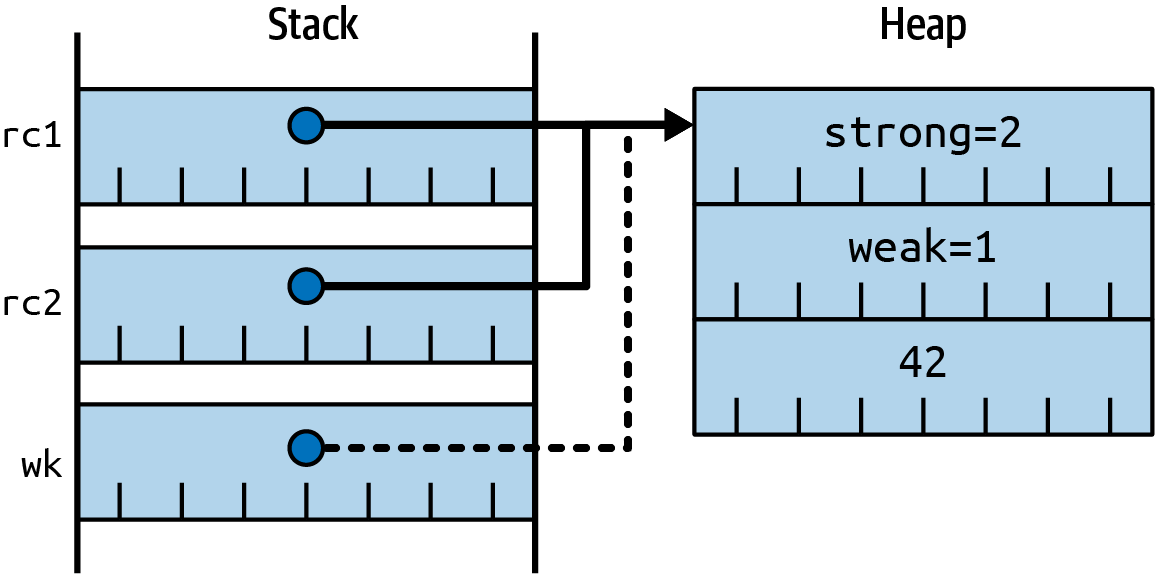
Figure 1-7. Rc and Weak pointers all referring to the same heap item
The underlying item is dropped when the strong reference count drops to zero, but the bookkeeping structure is dropped only when the weak reference count also drops to zero.
An Rc on its own gives you the ability to reach an item in different ways, but when you reach that item, you can
modify it (via get_mut) only if there are no other
ways to reach the item—i.e., there are no other extant Rc or Weak references to the same item. That’s hard
to arrange, so Rc is often combined with RefCell.
The next smart pointer type, RefCell<T>, relaxes the
rule (Item 15) that an item can be mutated only by its owner or by code that holds the (only) mutable reference to the
item. This interior mutability allows for greater flexibility—for example, allowing trait
implementations that mutate internals even when the method signature allows only &self. However, it also incurs
costs: as well as the extra storage overhead (an extra isize to track current borrows, as shown in Figure 1-8), the
normal borrow checks are moved from compile time to runtime:
usestd::cell::RefCell;letrc:RefCell<u64>=RefCell::new(42);letb1=rc.borrow();letb2=rc.borrow();
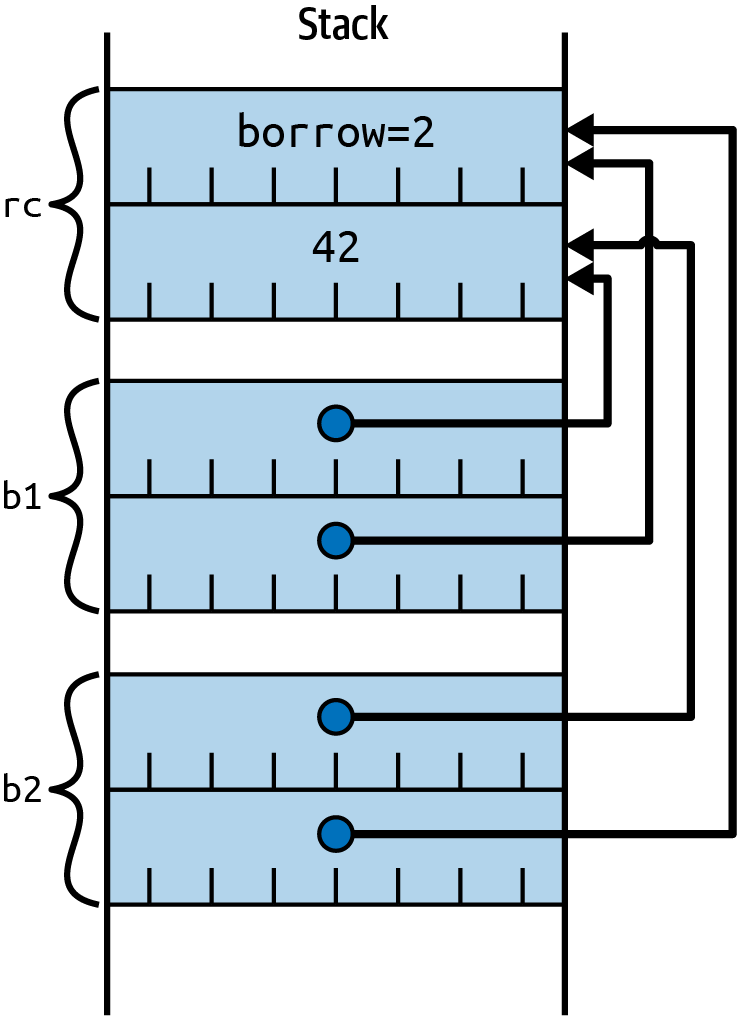
Figure 1-8. Ref borrows referring to a RefCell container
The runtime nature of these checks means that the RefCell user has to choose between two options, neither pleasant:
-
Accept that borrowing is an operation that might fail, and cope with
Resultvalues fromtry_borrow[_mut] -
Use the allegedly infallible borrowing methods
borrow[_mut], and accept the risk of apanic!at runtime (Item 18) if the borrow rules have not been complied with
In either case, this runtime checking means that RefCell itself implements none of the standard pointer traits;
instead, its access operations return a Ref<T> or
RefMut<T> smart pointer type that does implement those
traits.
If the underlying type T implements the Copy trait (indicating that a fast bit-for-bit copy
produces a valid item; see Item 10), then the Cell<T> type allows interior mutation
with less overhead—the get(&self) method copies out the current value, and the set(&self, val) method copies in a new value. The Cell type is used internally by both the Rc and
RefCell implementations, for shared tracking of counters that can be mutated without a &mut self.
The smart pointer types described so far are suitable only for single-threaded use; their implementations assume that there is no concurrent access to their internals. If this is not the case, then smart pointers that include additional synchronization overhead are needed.
The thread-safe equivalent of Rc<T> is Arc<T>,
which uses atomic counters to ensure that the reference counts remain accurate. Like Rc, Arc implements all of the
various pointer-related traits.
However, Arc on its own does not allow any kind of mutable access to the underlying item. This is covered by the
Mutex type, which ensures that only one thread has
access—whether mutably or immutably—to the underlying item. As with RefCell, Mutex itself does not
implement any pointer traits, but its lock() operation returns a value of a type that does:
MutexGuard, which implements Deref[Mut].
If there are likely to be more readers than writers, the
RwLock type is preferable, as it allows multiple
readers access to the underlying item in parallel, provided that there isn’t currently a (single) writer.
In either case, Rust’s borrowing and threading rules force the use of one of these synchronization containers in multithreaded code (but this guards against only some of the problems of shared-state concurrency; see Item 17).
The same strategy—see what the compiler rejects and what it suggests instead—can sometimes be applied with the other smart pointer types. However, it’s faster and less frustrating to understand what the behavior of the different smart pointers implies. To borrow (pun intended) an example from the first edition of the Rust book:
-
Rc<RefCell<Vec<T>>>holds a vector (Vec) with shared ownership (Rc), where the vector can be mutated—but only as a whole vector. -
Rc<Vec<RefCell<T>>>also holds a vector with shared ownership, but here each individual entry in the vector can be mutated independently of the others.
The types involved precisely describe these behaviors.
Item 9: Consider using iterator transforms instead of explicit loops
The humble loop has had a long journey of increasing convenience and increasing abstraction. The
B language (the precursor to C) had only while (condition) { ... }, but with the arrival of C, the common scenario of iterating
through indexes of an array became more convenient with the addition of the for loop:
// C codeinti;for(i=0;i<len;i++){Itemitem=collection[i];// body}
The early versions of C++ further improved convenience and scoping by allowing the loop variable declaration to be
embedded in the for statement (this was also adopted by C in C99):
// C++98 codefor(inti=0;i<len;i++){Itemitem=collection[i];// ...}
Most modern languages abstract the idea of the loop further: the core function of a loop is often to move to the next
item of some container. Tracking the logistics that are required to reach that item (index++ or ++it) is mostly an
irrelevant detail. This realization produced two core concepts:
- Iterators
-
A type whose purpose is to repeatedly emit the next item of a container, until exhausted23
- For-each loops
-
A compact loop expression for iterating over all of the items in a container, binding a loop variable to the item rather than to the details of reaching that item
These concepts allow for loop code that’s shorter and (more importantly) clearer about what’s intended:
// C++11 codefor(Item&item:collection){// ...}
Once these concepts were available, they were so obviously powerful that they were quickly retrofitted to those languages that didn’t already have them (e.g., for-each loops were added to Java 1.5 and C++11).
Rust includes iterators and for-each–style loops, but it also includes the next step in abstraction: allowing the whole
loop to be expressed as an iterator transform (sometimes also referred to as an iterator adaptor). As
with Item 3’s discussion of Option and Result, this Item will attempt to show how these iterator transforms can be
used instead of explicit loops, and will give guidance as to when it’s a good idea. In particular, iterator transforms can
be more efficient than an explicit loop, because the compiler can skip the bounds checks it might otherwise need to
perform.
By the end of this Item, a C-like explicit loop to sum the squares of the first five even items of a vector:
letvalues:Vec<u64>=vec![1,1,2,3,5/* ... */];letmuteven_sum_squares=0;letmuteven_count=0;foriin0..values.len(){ifvalues[i]%2!=0{continue;}even_sum_squares+=values[i]*values[i];even_count+=1;ifeven_count==5{break;}}
should start to feel more natural expressed as a functional-style expression:
leteven_sum_squares:u64=values.iter().filter(|x|*x%2==0).take(5).map(|x|x*x).sum();
Iterator transformation expressions like this can roughly be broken down into three parts:
-
An initial source iterator, from an instance of a type that implements one of Rust’s iterator traits
-
A sequence of iterator transforms
-
A final consumer method to combine the results of the iteration into a final value
The first two of these parts effectively move functionality out of the loop body and into the for expression; the last
removes the need for the for statement altogether.
Iterator Traits
The core Iterator trait has a very simple interface:
a single method next that yields Some
items until it doesn’t (None). The type of the emitted items is given by the trait’s associated Item
type.
Collections that allow iteration over their contents—what would be called iterables in other
languages—implement the IntoIterator trait;
the into_iter method of this trait
consumes Self and emits an Iterator in its stead. The compiler will automatically use this trait for
expressions of the form:
foritemincollection{// body}
effectively converting them to code roughly like:
letmutiter=collection.into_iter();loop{letitem:Thing=matchiter.next(){Some(item)=>item,None=>break,};// body}
or more succinctly and more idiomatically:
letmutiter=collection.into_iter();whileletSome(item)=iter.next(){// body}
To keep things running smoothly, there’s also an implementation of IntoIterator for any Iterator, which just
returns self; after all, it’s easy to convert an Iterator into an Iterator!
This initial form is a consuming iterator, using up the collection as it’s created:
letcollection=vec![Thing(0),Thing(1),Thing(2),Thing(3)];foritemincollection{println!("Consumed item {item:?}");}
Any attempt to use the collection after it’s been iterated over fails:
println!("Collection = {collection:?}");
error[E0382]: borrow of moved value: `collection`
--> src/main.rs:171:28
|
163 | let collection = vec![Thing(0), Thing(1), Thing(2), Thing(3)];
| ---------- move occurs because `collection` has type `Vec<Thing>`,
| which does not implement the `Copy` trait
164 | for item in collection {
| ---------- `collection` moved due to this implicit call to
| `.into_iter()`
...
171 | println!("Collection = {collection:?}");
| ^^^^^^^^^^^^^^ value borrowed here after move
|
note: `into_iter` takes ownership of the receiver `self`, which moves
`collection`
While simple to understand, this all-consuming behavior is often undesired; some kind of borrow of the iterated items is needed.
To ensure that behavior is clear, the examples here use a Thing type that does not implement Copy (Item 10), as
that would hide questions of ownership (Item 15)—the compiler would silently make copies everywhere:
// Deliberately not `Copy`#[derive(Clone, Debug, Eq, PartialEq)]structThing(u64);letcollection=vec![Thing(0),Thing(1),Thing(2),Thing(3)];
If the collection being iterated over is prefixed with &:
foritemin&collection{println!("{}",item.0);}println!("collection still around {collection:?}");
then the Rust compiler will look for an implementation of
IntoIterator for the type &Collection. Properly
designed collection types will provide such an implementation; this implementation will still consume Self, but now
Self is &Collection rather than Collection, and the associated Item type will be a reference &Thing.
This leaves the collection intact after iteration, and the equivalent expanded code is as follows:
letmutiter=(&collection).into_iter();whileletSome(item)=iter.next(){println!("{}",item.0);}
If it makes sense to provide iteration over mutable references,24 then a similar pattern applies for for item in &mut collection: the compiler
looks for and uses an implementation of IntoIterator for &mut Collection, with each Item being of type &mut Thing.
By convention, standard containers also provide an iter() method that returns an iterator over references to the
underlying item, and an equivalent iter_mut() method, if appropriate, with the same behavior as just described. These
methods can be used in for loops but have a more obvious benefit when used as the start of an iterator
transformation:
letresult:u64=(&collection).into_iter().map(|thing|thing.0).sum();
becomes:
letresult:u64=collection.iter().map(|thing|thing.0).sum();
Iterator Transforms
The Iterator trait has a single required method
(next) but also provides default
implementations (Item 13) of a large number of other methods that perform transformations on an iterator.
Some of these transformations affect the overall iteration process:
take(n)-
Restricts an iterator to emitting at most
nitems. skip(n)step_by(n)-
Converts an iterator so it emits only every nth item.
chain(other)-
Glues together two iterators, to build a combined iterator that moves through one then the other.
cycle()-
Converts an iterator that terminates into one that repeats forever, starting at the beginning again whenever it reaches the end. (The iterator must support
Cloneto allow this.) rev()-
Reverses the direction of an iterator. (The iterator must implement the
DoubleEndedIteratortrait, which has an additionalnext_backrequired method.)
Other transformations affect the nature of the Item that’s the subject of the Iterator:
map(|item| {...})-
Repeatedly applies a closure to transform each item in turn. This is the most general version; several of the following entries in this list are convenience variants that could be equivalently implemented as a
map. cloned()-
Produces a clone of all of the items in the original iterator; this is particularly useful with iterators over
&Itemreferences. (This obviously requires the underlyingItemtype to implementClone.) copied()-
Produces a copy of all of the items in the original iterator; this is particularly useful with iterators over
&Itemreferences. (This obviously requires the underlyingItemtype to implementCopy, but it is likely to be faster thancloned(), if that’s the case.) enumerate()-
Converts an iterator over items to be an iterator over
(usize, Item)pairs, providing an index to the items in the iterator. zip(it)-
Joins an iterator with a second iterator, to produce a combined iterator that emits pairs of items, one from each of the original iterators, until the shorter of the two iterators is finished.
Yet other transformations perform filtering on the Items being emitted by the
Iterator:
filter(|item| {...})-
Applies a
bool-returning closure to each item reference to determine whether it should be passed through. take_while()-
Emits an initial subrange of the iterator, based on a predicate. Mirror image of
skip_while. skip_while()-
Emits a final subrange of the iterator, based on a predicate. Mirror image of
take_while.
The flatten() method deals
with an iterator whose items are themselves iterators, flattening the result. On its own, this doesn’t seem that
helpful, but it becomes much more useful when combined with the observation that both
Option and
Result act as iterators: they produce
either zero (for None, Err(e)) or one (for Some(v), Ok(v)) items. This means that flattening a stream of
Option/Result values is a simple way to extract just the valid values, ignoring the rest.
Taken as a whole, these methods allow iterators to be transformed so that they produce exactly the sequence of elements that are needed for most situations.
Iterator Consumers
The previous two sections described how to obtain an iterator and how to transform it into exactly the right shape for precise iteration. This precisely targeted iteration could happen as an explicit for-each loop:
letmuteven_sum_squares=0;forvalueinvalues.iter().filter(|x|*x%2==0).take(5){even_sum_squares+=value*value;}
However, the large collection of Iterator methods includes
many that allow an iteration to be consumed in a single method call, removing the need for an explicit for loop.
The most general of these methods is for_each(|item| {...}), which runs a closure for each item
produced by the Iterator. This can do most of the things that an explicit for loop can do (the exceptions are
described in a later section), but its generality also makes it a little awkward to use—the closure needs to use mutable
references to external state in order to emit anything:
letmuteven_sum_squares=0;values.iter().filter(|x|*x%2==0).take(5).for_each(|value|{// closure needs a mutable reference to state elsewhereeven_sum_squares+=value*value;});
However, if the body of the for loop matches one of a number of common patterns, there are more specific
iterator-consuming methods that are clearer, shorter, and more idiomatic.
These patterns include shortcuts for building a single value out of the collection:
sum()product()min()-
Finds the minimum value of a collection, relative to the Item’s
Ordimplementation (see Item 10). max()-
Finds the maximum value of a collection, relative to the Item’s
Ordimplementation (see Item 10). min_by(f)-
Finds the minimum value of a collection, relative to a user-specified comparison function
f. max_by(f)-
Finds the maximum value of a collection, relative to a user-specified comparison function
f. reduce(f)-
Builds an accumulated value of the
Itemtype by running a closure at each step that takes the value accumulated so far and the current item. This is a more general operation that encompasses the previous methods. fold(f)-
Builds an accumulated value of an arbitrary type (not just the
Iterator::Itemtype) by running a closure at each step that takes the value accumulated so far and the current item. This is a generalization ofreduce. scan(init, f)-
Builds an accumulated value of an arbitrary type by running a closure at each step that takes a mutable reference to some internal state and the current item. This is a slightly different generalization of
reduce.
There are also methods for selecting a single value out of the collection:
find(p)position(p)-
Also finds the first item satisfying a predicate, but this time it returns the index of the item.
nth(n)
There are methods for testing against every item in the collection:
any(p)-
Indicates whether a predicate is
truefor any item in the collection. all(p)-
Indicates whether a predicate is
truefor all items in the collection.
In either case, iteration will terminate early if the relevant counterexample is found.
There are methods that allow for the possibility of failure in the closures used with each item. In each case, if a closure returns a failure for an item, the iteration is terminated and the operation as a whole returns the first failure:
Finally, there are methods that accumulate all of the iterated items into a new collection. The most important of these
is collect(), which can be
used to build a new instance of any collection type that implements the
FromIterator trait.
The FromIterator trait is implemented for all of the standard library collection types
(Vec,
HashMap,
BTreeSet, etc.), but
this ubiquity also means that you often have to use explicit types, because otherwise the
compiler can’t figure out whether you’re trying to assemble (say) a Vec<i32> or HashSet<i32>:
usestd::collections::HashSet;// Build collections of even numbers. Type must be specified, because// the expression is the same for either type.letmyvec:Vec<i32>=(0..10).into_iter().filter(|x|x%2==0).collect();leth:HashSet<i32>=(0..10).into_iter().filter(|x|x%2==0).collect();
This example also illustrates the use of range expressions to generate the initial data to be iterated over.
Other (more obscure) collection-producing methods include the following:
unzip()partition(p)-
Splits an iterator into two collections based on a predicate that is applied to each item
This Item has touched on a wide selection of Iterator methods, but this is only a subset of the methods available;
for more information, consult the iterator documentation or
read Chapter 15 of Programming Rust, 2nd edition (O’Reilly), which has extensive coverage of the possibilities.
This rich collection of iterator transformations is there to be used. It produces code that is more idiomatic, more compact, and has clearer intent.
Expressing loops as iterator transformations can also produce code that is more efficient. In the interests of safety,
Rust performs bounds checking on access to contiguous containers such as vectors and slices; an attempt to
access a value beyond the bounds of the collection triggers a panic rather than an access to invalid data. An old-style
loop that accesses container values (e.g., values[i]) might be subject to these runtime checks, whereas an iterator
that produces one value after another is already known to be within range.
However, it’s also the case that an old-style loop might not be subject to additional bounds checks compared to the equivalent iterator transformation. The Rust compiler and optimizer is very good at analyzing the code surrounding a slice access to determine whether it’s safe to skip the bounds checks; Sergey “Shnatsel” Davidoff’s 2023 article explores the subtleties involved.
Building Collections from Result Values
The previous section described the use of collect() to build collections from iterators, but collect() also has a
particularly helpful feature when dealing with Result values.
Consider an attempt to convert a vector of i64 values into bytes (u8), with the optimistic expectation that they
will all fit:
This works until some unexpected input comes along:
letinputs:Vec<i64>=vec![0,1,2,3,4,512];
and causes a runtime failure:
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: TryFromIntError(())', iterators/src/main.rs:266:36 note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Following the advice given in Item 3, we want to keep the Result type in play and use the ? operator to make any
failure the problem of the calling code. The obvious modification to emit the Result doesn’t really help:
letresult:Vec<Result<u8,_>>=inputs.into_iter().map(|v|<u8>::try_from(v)).collect();// Now what? Still need to iterate to extract results and detect errors.
However, there’s an alternative version of collect(), which can assemble a Result holding a Vec, instead of a
Vec holding Results.
Forcing use of this version requires the turbofish (::<Result<Vec<_>, _>>):
letresult:Vec<u8>=inputs.into_iter().map(|v|<u8>::try_from(v)).collect::<Result<Vec<_>,_>>()?;
Combining this with the question mark operator gives useful behavior:
-
If the iteration encounters an error value, that error value is emitted to the caller and iteration stops.
-
If no errors are encountered, the remainder of the code can deal with a sensible collection of values of the right type.
Loop Transformation
The aim of this Item is to convince you that many explicit loops can be regarded as something to be converted to iterator transformations. This can feel somewhat unnatural for programmers who aren’t used to it, so let’s walk through a transformation step by step.
Starting with a very C-like explicit loop to sum the squares of the first five even items of a vector:
letmuteven_sum_squares=0;letmuteven_count=0;foriin0..values.len(){ifvalues[i]%2!=0{continue;}even_sum_squares+=values[i]*values[i];even_count+=1;ifeven_count==5{break;}}
The first step is to replace vector indexing with direct use of an iterator in a for-each loop:
letmuteven_sum_squares=0;letmuteven_count=0;forvalueinvalues.iter(){ifvalue%2!=0{continue;}even_sum_squares+=value*value;even_count+=1;ifeven_count==5{break;}}
An initial arm of the loop that uses continue to skip over some items is naturally expressed as a filter():
letmuteven_sum_squares=0;letmuteven_count=0;forvalueinvalues.iter().filter(|x|*x%2==0){even_sum_squares+=value*value;even_count+=1;ifeven_count==5{break;}}
Next, the early exit from the loop once five even items have been spotted maps to a take(5):
letmuteven_sum_squares=0;forvalueinvalues.iter().filter(|x|*x%2==0).take(5){even_sum_squares+=value*value;}
Every iteration of the loop uses only the item squared, in the value * value combination, which makes it an ideal target
for a map():
letmuteven_sum_squares=0;forval_sqrinvalues.iter().filter(|x|*x%2==0).take(5).map(|x|x*x){even_sum_squares+=val_sqr;}
These refactorings of the original loop result in a loop body that’s the perfect nail to fit under the hammer of
the sum() method:
leteven_sum_squares:u64=values.iter().filter(|x|*x%2==0).take(5).map(|x|x*x).sum();
When Explicit Is Better
This Item has highlighted the advantages of iterator transformations, particularly with respect to concision and clarity. So when are iterator transformations not appropriate or idiomatic?
-
If the loop body is large and/or multifunctional, it makes sense to keep it as an explicit body rather than squeezing it into a closure.
-
If the loop body involves error conditions that result in early termination of the surrounding function, these are often best kept explicit—the
try_..()methods help only a little. However,collect()’s ability to convert a collection ofResultvalues into aResultholding a collection of values often allows error conditions to still be handled with the?operator. -
If performance is vital, an iterator transform that involves a closure should get optimized so that it is just as fast as the equivalent explicit code. But if performance of a core loop is that important, measure different variants and tune appropriately:
-
Be careful to ensure that your measurements reflect real-world performance—the compiler’s optimizer can give overoptimistic results on test data (as described in Item 30).
-
The Godbolt compiler explorer is an amazing tool for exploring what the compiler spits out.
-
Most importantly, don’t convert a loop into an iteration transformation if the conversion is forced or awkward. This is a matter of taste to be sure—but be aware that your taste is likely to change as you become more familiar with the functional style.
1 The situation gets muddier still if the filesystem is involved, since filenames on popular platforms are somewhere in between arbitrary bytes and UTF-8 sequences: see the std::ffi::OsString documentation.
2 Technically, a Unicode scalar value rather than a code point.
3 The need to consider all possibilities also means that adding a new variant to an existing enum in a library is a breaking change (Item 21): library clients will need to change their code to cope with the new variant. If an enum is really just a C-like list of related numerical values, this behavior can be avoided by marking it as a non_exhaustive enum; see Item 21.
4 At least not in stable Rust at the time of writing. The unboxed_closures and fn_traits experimental features may change this in the future.
5 For example, Joshua Bloch’s Effective Java (3rd edition, Addison-Wesley) includes Item 64: Refer to objects by their interfaces.
6 The addition of concepts in C++20 allows explicit specification of constraints on template types, but the checks are still performed only when the template is instantiated, not when it is declared.
7 The online version of this diagram is clickable; each box links to the relevant documentation.
8 Note that this method is separate from the AsRef trait, even though the method name is the same.
9 Or at least the only nondeprecated, stable method.
10 At the time of writing, Error has been moved to core but is not yet available in stable Rust.
11 This section is inspired by Nick Groenen’s “Rust: Structuring and Handling Errors in 2020” article.
12 More properly known as the trait coherence rules.
13 For now—this is likely to be replaced with the ! “never” type in a future version of Rust.
14 Allowing lossy conversions in Rust was probably a mistake, and there have been discussions around trying to remove this behavior.
15 Rust refers to these conversions as “subtyping,” but it’s quite different from the definition of “subtyping” used in object-oriented languages.
16 Specifically, the Mars Climate Orbiter.
17 See “Mars Climate Orbiter” on Wikipedia for more on the cause of failure.
18 This is a sufficiently common problem for serde that it includes a mechanism to help.
19 Albeit with a warning from modern compilers.
20 The equivalent trait for mutable expressions is IndexMut.
21 This is somewhat simplified; a full vtable also includes information about the size and alignment of the type, together with a drop() function pointer so that the underlying object can be safely dropped.
22 Note that this doesn’t affect Rust’s memory safety guarantees: the items are still safe, just inaccessible.
23 In fact, the iterator can be more general—the idea of emitting next items until completion need not be associated with a container.
24 This method can’t be provided if a mutation to the item might invalidate the container’s internal guarantees. For example, changing the item’s contents in a way that alters its Hash value would invalidate the internal data structures of a HashMap.