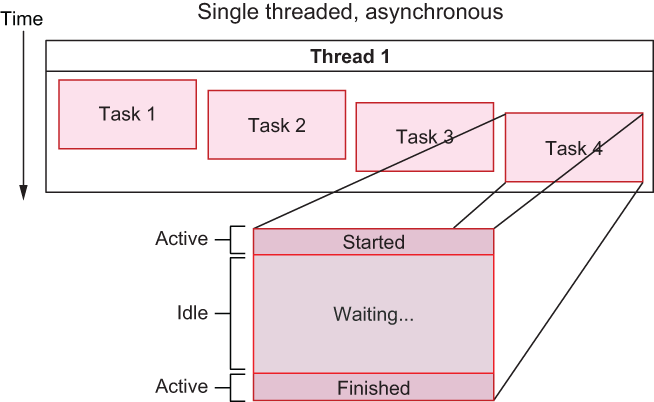
async and .await featuresConcurrency is an important concept in computing, and it’s one of the greatest force multipliers of computers. Concurrency allows us to process inputs and outputs—such as data, network connections, or peripherals—faster than we might be able to without concurrency. And it’s not always about speed but also latency, overhead, and system complexity. We can run thousands or millions of tasks concurrently, as illustrated in figure 8.1, because concurrent tasks tend to be relatively lightweight. We can create, destroy, and manage many concurrent tasks with very little overhead.
Figure 8.1 Tasks executing concurrently within the same thread
Asynchronous programming uses concurrency to take advantage of idle processing time between tasks. Some kinds of tasks, such as I/O, are much slower than ordinary CPU instructions, and after a slow task is started, we can set it aside to work on other tasks while waiting for the slow task to be completed.
Concurrency shouldn’t be confused with parallelism (which I’ll define here as the ability to execute multiple tasks simultaneously). Concurrency differs from parallelism in that tasks may be executed concurrently without necessarily being executed in parallel. With parallelism, it’s possible to execute program code while simultaneously sharing the same region of memory on the host machine, either across multiple CPUs or using context switching at the OS level (a detailed discussion of which is beyond the scope of this book). Figure 8.2 illustrates two threads executing in parallel, simultaneously.
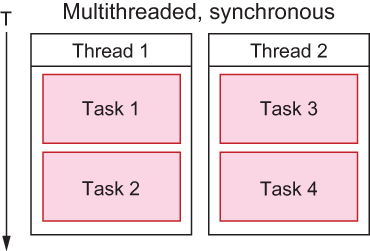
Figure 8.2 Synchronous tasks executing in parallel across two threads
To think about this analogously, consider how humans operate consciously: we can’t do most tasks in parallel, but we can do a lot of things concurrently. For example, try having a conversation with two or more people at the same time—it’s much harder than it sounds. It’s possible to talk to many people at the same time, but you have to context switch between them and pause when switching from one person to another. Humans do concurrency reasonably well, but we suck at parallelism.
In this chapter, we’re going to discuss Rust’s asynchronous concurrency system, which provides both concurrency and parallelism, depending on what your needs are. It’s relatively easy to implement parallelism without async (using threads), but it’s quite difficult to implement concurrency without async. Async is a vast topic, so we’re really only going to cover the basics in this chapter. However, if you’re already familiar with asynchronous programming, you’ll find everything you need to be effective with async in Rust.
Rust’s async is similar to what you may have encountered in other languages, though it has its own unique features in addition to borrowing much of what works well from other languages. If you’re familiar with async from JavaScript, Python, or even C++’s std::async, you should have no problem adjusting to Rust’s async. Rust does have one big difference: the language itself does not provide or prescribe an asynchronous runtime implementation. Rust only provides the Future trait, the async keyword, and the .await statement; implementation details are largely left to third-party libraries. At the time of writing, there are three widely used async runtime implementations, outlined in table 8.1.
Table 8.1 Summary of async runtimes
|
Downloads1 |
||
|---|---|---|
Both async-std and smol provide compatibility with the Tokio runtime; however, it is not practical to mix competing async runtimes within the same context in Rust. While separate runtimes do implement the same async API, you will likely require runtime-specific features for most use cases. As such, the recommendation is to use Tokio for most purposes, as it is the most mature and widely used runtime. It may become easier to swap or interchange runtimes in the future, but for the time being, this is not worth the headache.
Crates that provide async features could, theoretically, use any runtime, but in practice, this is uncommon, as they typically work best with one particular runtime. As such, some bifurcation exists in the Rust async ecosystem, where most crates are designed to work with Tokio, but some are specific to smol or async-std. For these reasons, this book will focus on the Tokio async runtime as the preferred async runtime.
When we talk about asynchronous programming, we are usually referring to a way of handling control flow for any operation that involves waiting for a task to complete, which is often I/O. Examples of this include interacting with the filesystem or a socket, but it could also be slow operations, such as computing a hash or waiting for a timer to finish. Most people are familiar with synchronous I/O, which (with the exception of certain languages like JavaScript) is the default mode of handling I/O. The main advantages of using asynchronous programming (as opposed to synchronous) are as follows:
I/O tends to be very fast with async because there is no need to perform a context switch between threads to support concurrency. Context switching, which often involves synchronization or locking with mutexes, can create a surprising amount of overhead.
It’s often much easier to reason about software that’s written asynchronously because we can avoid many kinds of race conditions.
Asynchronous tasks are very lightweight; thus, we can easily handle thousands or millions of asynchronous tasks simultaneously.
When it comes to I/O operations in particular, the amount of time waiting for operations to complete is often far greater than the amount of time spent processing the result of the I/O operation. Because of this, we can do other work while we’re waiting for tasks to finish, rather than executing every task sequentially. In other words, with async programming, we are effectively breaking up and interleaving our function calls between the gaps created by time spent waiting for an I/O operation to finish.
In figure 8.3, I’ve illustrated the difference with respect to T (time) of blocking versus nonblocking I/O operations. Async I/O is nonblocking, whereas synchronous I/O is blocking. If we assume the time to process the result of an I/O operation is much less than the time spent waiting for I/O to complete, asynchronous I/O will often be faster. It should also be noted that you can use multi-threaded programming with async, but often, it’s faster to simply use a single thread.
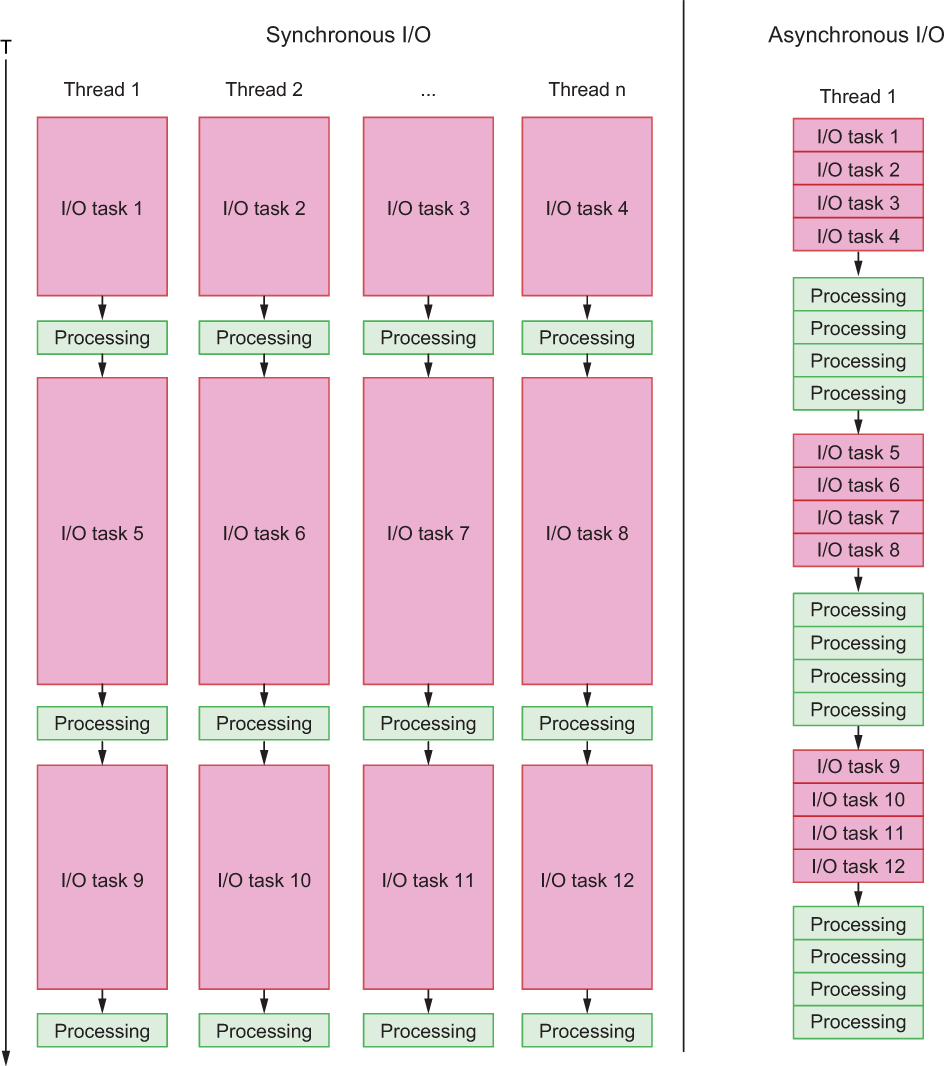
Figure 8.3 Comparing synchronous to asynchronous I/O
There’s no free lunch here; however, if the time to process data from I/O operations becomes greater than the time spent waiting for I/O to complete, we’d see worse performance (assuming single-threaded async). As such, async isn’t necessarily ideal for every use case. The good news is that Tokio provides quite a bit of flexibility in choosing how to execute async tasks, such as how many worker threads to use.
You can also mix parallelism with async, so comparing async directly to synchronous programming is not always meaningful. Async code can run concurrently in parallel across several threads, which acts like a performance multiplier that synchronous code can’t really compete with.
Once you adjust to the mental model required for thinking about async programming, it’s much less complex than synchronous programming, especially compared to multithreaded synchronous programming.
Most async libraries and languages are based on futures, which is a design pattern for handling tasks that return a result in the future (hence the name). When we perform an asynchronous operation, the result of that operation is a future, as opposed to directly returning the value of the operation itself (as we’d see in synchronous programming or an ordinary function call). While futures are a convenient abstraction, they do require a little more work on the part of the programmer to handle correctly.
To better understand futures, let’s consider how a timer works: we can create (or start) an async timer, which returns a future to signal the completion of the timer. Merely creating the timer is not enough; we also need to tell the executor (which is part of the async runtime) to execute the task. In synchronous code, when we want to sleep for 1 second, we can just call the sleep() function.
Note It’s true that you could call sleep() within async code, but you should never do this. An important rule of asynchronous programming is to never block the main thread. While calling sleep() won’t cause your program to crash, it will effectively defeat the purpose of async programming, and it is considered an anti-pattern.
To compare an async timer to a synchronous one, let’s look at what it takes to write a tiny Rust program that sleeps for 1 second and prints "Hello, world!". First, let’s look at the synchronous code:
fn main() {
use std::{thread, time};
let duration = time::Duration::from_secs(1);
thread::sleep(duration);
println!("Hello, world!");
}
The synchronous code looks nice and simple. Next, let’s examine the async version:
fn main() {
use std::time;
let duration = time::Duration::from_secs(1);
tokio::runtime::Builder::new_current_thread()
.enable_time() ❶
.build()
.unwrap()
.block_on(async { ❷
tokio::time::sleep(duration).await;
println!("Hello, world!");
});
}
❶ The runtime supports time or I/O, which can be enabled individually or entirely with enable_all().
❷ We create an async block, which waits on the future returned by tokio::time::sleep() and then prints "Hello, world!".
Yikes! That’s much more complicated. Why do we need all this complexity? In short, async programming requires special control flow, which is mostly managed by the runtime but still requires a different style of programming. The runtime’s scheduler decides what to run when, but we need to yield to the scheduler to allow an opportunity for it to switch between tasks. The runtime will manage most of the details, but we still need to be aware of this to use async effectively. Yielding to the scheduler (in most cases) is as simple as using .await, which we’ll discuss in greater depth in the next section.
Tokio provides a macro for wrapping our main() function, so we can simplify the preceding timer code into the following form if we want:
#[tokio::main]
async fn main() {
use std::time;
let duration = time::Duration::from_secs(1);
tokio::time::sleep(duration).await;
println!("Hello, world!");
}
With the help of some syntax sugar, our code now looks just like the synchronous version. We’ve turned main() into an async function with the async keyword, and the #[tokio::main] handles the boilerplate needed to start the Tokio runtime and create the async context we need.
Remember that the result of any async task is a future, but we need to execute that future on the runtime before anything actually happens. In Rust, this is normally done with the .await statement, which we will discuss in the next section.
The async and .await keywords are quite new in Rust. It’s possible to use futures directly without these, but you’re better off just using async and .await when possible because they handle much of the boilerplate without sacrificing functionality. A function or block of code marked as async will return a future, and .await tells the runtime we want to wait for a result. The syntax of async and .await allows us to write async code that looks like synchronous code but without much of the complexity that comes with working with futures. You can use async with functions, closures, and code blocks. async blocks don’t execute until they’re polled, which you can do with .await.
Under the hood, using .await on a future uses the runtime to call the poll() method from the Future trait and waits for the future’s result. If you never call .await (or explicitly poll a future), the future will never execute.
To use .await, we need to be within an async context. We can create an async context by creating a block of code marked with async and executing that code on the async runtime. You don’t have to use async and .await, but it’s much easier to do things this way, and the Tokio runtime (along with many other async crates) has been designed to be used this way.
For example, consider the following program, which includes a fire-and-forget async code block spawned with tokio::task::spawn():
#[tokio::main]
async fn main() {
async {
println!("This line prints first");
}
.await;
let _future = async {
println!("This line never prints");
};
tokio::task::spawn(async {
println!(
"This line prints sometimes, depending on how quick it runs"
)
});
println!("This line always prints, but it may or may not be last");
}
If you run this code repeatedly, it will (confusingly) print either two or three lines. The first println!() will always print before the others because of the .await statement, which awaits the result of the first future. The second println!() never prints because we didn’t execute the future by calling .await or spawning it on the runtime. The third println!() is spawned onto the Tokio runtime, but we don’t wait for it to complete, so it’s not guaranteed to run, and we don’t know if it will run before or after the last println!(), which will always print.
Why does the third println!() not print consistently? It’s possible that the program will exit before the Tokio runtime’s scheduler gets a chance to execute the code. If we want to guarantee that the code runs before exiting, we need to wait for the future returned by tokio::task::spawn() to complete.
The tokio::task::spawn() function has another important feature: it allows us to launch an async task on the async runtime from outside an async context. It also returns a future (tokio::task::JoinHandle, specifically), which we can pass around like any other object. Tokio’s join handles also allow us to abort tasks if we want. Let’s look at the example in the following listing.
Listing 8.1 Spawning a task with tokio::task::spawn()
use tokio::task::JoinHandle;
fn not_an_async_function() -> JoinHandle<()> { ❶
tokio::task::spawn(async { ❷
println!("Second print statement");
})
}
#[tokio::main]
async fn main() {
println!("First print statement");
not_an_async_function().await.ok(); ❸
}
❶ A normal function, returning a JoinHandle (which implements the Future trait).
❷ Our println!() task is spawned on the runtime.
❸ We use .await on the future returned from our function to wait for it to execute.
In the preceding code listing, we’ve created a normal function that returns a JoinHandle (which is just a type of future). tokio::task::spawn() returns a JoinHandle, which allows us to join the task (i.e., retrieve the result of our code block, which is just a unit in this example).
What happens if you want to use .await outside of an async context? Well, in short, you can’t. You can, however, block on the result of a future to await its result using the tokio::runtime::Handle::block_on() method. To do so, you’ll need to obtain a handle for the runtime, and move that runtime handle into the thread where you want to block. Handles can be cloned and shared, providing access to the async runtime from outside an async context, as shown in the following listing.
Listing 8.2 Using a Tokio Handle to spawn tasks
use tokio::runtime::Handle;
fn not_an_async_function(handle: Handle) {
handle.block_on(async { ❶
println!("Second print statement");
})
}
#[tokio::main]
async fn main() {
println!("First print statement");
let handle = Handle::current(); ❷
std::thread::spawn(move || { ❸
not_an_async_function(handle); ❹
});
}
❶ Spawns a blocking async task on our runtime using a runtime handle
❷ Gets the runtime handle for the current runtime context
❸ Spawns a new thread, capturing variables with a move
❹ Calls our nonasync function in a separate thread, passing the async runtime handle along
That’s not pretty, but it works. There are a few cases in which you might want to do things like this, which we’ll discuss in the next section, but for the most part, you should try to use async and .await when possible.
In short, wrap code blocks (including functions and closures) with async when you want to perform async tasks or return a future, and use .await when you need to wait for an async task. Creating an async block does not execute the future; it still needs to be executed (or spawned with tokio::task::spawn()) on the runtime.
At the beginning of the chapter, I discussed the differences between concurrency and parallelism. With async, we don’t get either concurrency or parallelism for free. We still have to think about how to structure our code to take advantage of these features.
With Tokio, there’s no explicit control over parallelism (aside from launching a blocking task with tokio::task::spawn_blocking(), which always runs in a separate thread). We do have explicit control over concurrency, but we can’t control the parallelism of individual tasks, as those details are left up to the runtime. What Tokio does allow us to configure is the number of worker threads, but the runtime will decide which threads to use for each task.
Introducing concurrency into our code can be accomplished in one of three ways:
Joining multiple futures with tokio::join!(...) or futures::future::join_all()
Using the tokio::select! { ... } macro, which allows us to wait on multiple concurrent code branches (modeled after the UNIX select() system call)
To introduce parallelism, we have to use tokio::task::spawn(), but we don’t get explicit parallelism this way. Instead, when we spawn a task, we’re telling Tokio that this task can be executed on any thread, but Tokio still decides which thread to use. If we launch our Tokio runtime with only one worker thread, for example, all tasks will execute in one thread, even when we use tokio::task::spawn(). We can demonstrate the behavior with some sample code.
Listing 8.3 Demonstrating async concurrency and parallelism
async fn sleep_1s_blocking(task: &str) {
use std::{thread, time::Duration};
println!("Entering sleep_1s_blocking({task})");
thread::sleep(Duration::from_secs(1)); ❶
println!("Returning from sleep_1s_blocking({task})");
}
#[tokio::main(flavor = "multi_thread", worker_threads = 2)] ❷
async fn main() {
println!("Test 1: Run 2 async tasks sequentially");
sleep_1s_blocking("Task 1").await; ❸
sleep_1s_blocking("Task 2").await;
println!("Test 2: Run 2 async tasks concurrently (same thread)");
tokio::join!( ❹
sleep_1s_blocking("Task 3"),
sleep_1s_blocking("Task 4")
);
println!("Test 3: Run 2 async tasks in parallel");
tokio::join!( ❺
tokio::spawn(sleep_1s_blocking("Task 5")),
tokio::spawn(sleep_1s_blocking("Task 6"))
);
}
❶ Here, we intentionally use std::thread::sleep(), which is blocking, to demonstrate parallelism.
❷ We’re explicitly configuring Tokio with two worker threads, which allows us to run tasks in parallel.
❸ Here, we call our sleep_1s() function twice sequentially, with no concurrency or parallelism.
❹ Here we call sleep_1s() twice using tokio::join!(), which introduces concurrency.
❺ Finally, we’re spawning our sleep_1s() and then joining on the result, which introduces parallelism.
Running this code will generate the following output:
Test 1: Run 2 async tasks sequentially
Entering sleep_1s_blocking(Task 1)
Returning from sleep_1s_blocking(Task 1)
Entering sleep_1s_blocking(Task 2)
Returning from sleep_1s_blocking(Task 2)
Test 2: Run 2 async tasks concurrently (same thread)
Entering sleep_1s_blocking(Task 3)
Returning from sleep_1s_blocking(Task 3)
Entering sleep_1s_blocking(Task 4)
Returning from sleep_1s_blocking(Task 4)
Test 3: Run 2 async tasks in parallel
Entering sleep_1s_blocking(Task 5) ❶
Entering sleep_1s_blocking(Task 6)
Returning from sleep_1s_blocking(Task 5)
Returning from sleep_1s_blocking(Task 6)
❶ In the third test, we can see our sleep_1s() function is running in parallel because both functions are entered before returning.
We can see from this output that only in the third test, where we launch each task with tokio::spawn() (which is equivalent to tokio::task::spawn()), does the code execute in parallel. We can tell it’s executing in parallel because we see both of the Entering ... statements before the Returning ... statements. An illustration of the sequence of events is shown in figure 8.4.

Figure 8.4 Diagram showing the sequence of events in blocking sleep
Note that, while the second test is, indeed, running concurrently, it is not running in parallel; thus, the tasks execute sequentially because we used a blocking sleep in listing 8.3. Let’s update the code to add nonblocking sleep as follows:
async fn sleep_1s_nonblocking(task: &str) {
use tokio::time::{sleep, Duration};
println!("Entering sleep_1s_nonblocking({task})");
sleep(Duration::from_secs(1)).await;
println!("Returning from sleep_1s_nonblocking({task})");
}
After updating our main() to add three tests with the nonblocking sleep, we get the following output:
Test 4: Run 2 async tasks sequentially (non-blocking)
Entering sleep_1s_nonblocking(Task 7)
Returning from sleep_1s_nonblocking(Task 7)
Entering sleep_1s_nonblocking(Task 8)
Returning from sleep_1s_nonblocking(Task 8)
Test 5: Run 2 async tasks concurrently (same thread, non-blocking)
Entering sleep_1s_nonblocking(Task 9) ❶
Entering sleep_1s_nonblocking(Task 10)
Returning from sleep_1s_nonblocking(Task 10)
Returning from sleep_1s_nonblocking(Task 9)
Test 6: Run 2 async tasks in parallel (non-blocking)
Entering sleep_1s_nonblocking(Task 11)
Entering sleep_1s_nonblocking(Task 12)
Returning from sleep_1s_nonblocking(Task 12)
Returning from sleep_1s_nonblocking(Task 11)
❶ We can see here that our sleep happens concurrently now that we changed the sleep function to nonblocking.
Figure 8.5 illustrates how both tests 5 and 6 appear to execute in parallel, although only test 6 is actually running in parallel, whereas test 5 is running concurrently. If you again update your Tokio settings and change worker_threads = 1 and then rerun the test, you will see in the blocking sleep version all of the tasks run sequentially, but in the concurrent nonblocking version, they still run concurrently, even with one thread.

Figure 8.5 Diagram showing the sequence of events in nonblocking sleep
It may take some time to wrap your head around concurrency and parallelism with async Rust, so don’t worry if this seems confusing at first. I recommend trying this sample yourself and experimenting with different parameters to get a better understanding of what’s going on.
Let’s look at implementing the observer pattern in async Rust. This pattern happens to be incredibly useful in async programming, so we’ll see what it takes to make it work with async.
Note Async traits are expected to be added to Rust in an upcoming release, though at the time of writing, they are not yet available.
At the time of writing, there is one big limitation to Rust’s async support: we can’t use traits with async methods. For example, the following code is invalid:
trait MyAsyncTrait {
async fn do_thing();
}
Because of this, implementing the observer pattern with async is somewhat tricky. There are a few ways to work around this problem, but I will present a solution that also provides some insight into how Rust implements the async fn syntax sugar.
As mentioned earlier in this chapter, the async and .await features are just convenient syntax for working with futures. When we declare an async function or code block, the compiler is wrapping that code with a future for us. Thus, we can still create the equivalent of an async function with traits, but we have to do it explicitly (without the syntax sugar).
The observer trait looks as follows:
pub trait Observer {
type Subject;
fn observe(&self, subject: &Self::Subject);
}
To convert the observe() method into an async function, the first step is to make it return a Future. We can try something like this as a first step:
pub trait Observer {
type Subject;
type Output: Future<Output = ()>; ❶
fn observe(&self, subject: &Self::Subject) -> Self::Output; ❷
}
❶ Here, we define an associated type with the Future trait bound, returning ().
❷ Now, our observe() method returns the Output associated type.
At first glance, this seems like it should work, and the code compiles. However, as soon as we try to implement the trait, we’ll run into a few problems. For one, because Future is just a trait (not a concrete type), we don’t know what type to specify for Output. Thus, we can’t use an associated type this way. Instead, we need to use a trait object. To do this, we need to return our future within a Box. We’ll update the trait like so:
pub trait Observer {
type Subject;
type Output; ❶
fn observe(
&self,
subject: &Self::Subject,
) -> Box<dyn Future<Output = Self::Output>>; ❷
}
❶ We kept the associated type for the return type here, which adds some flexibility.
❷ Now, we return a Box<dyn Future> instead.
Let’s try to put it together by implementing our new async observer for MyObserver:
struct Subject;
struct MyObserver;
impl Observer for MyObserver {
type Subject = Subject;
type Output = ();
fn observe(
&self,
_subject: &Self::Subject,
) -> Box<dyn Future<Output = Self::Output>> {
Box::new(async { ❶
// do some async stuff here!
use tokio::time::{sleep, Duration};
sleep(Duration::from_millis(100)).await;
})
}
}
❶ Note that we have to box the future we’re returning.
So far, so good! The compiler is happy too. Now, what happens if we try to test it? Let’s write a quick test:
#[tokio::main]
async fn main() {
let subject = Subject;
let observer = MyObserver;
observer.observe(&subject).await;
}
And now we hit our next snag. Trying to compile this will generate the following error:
error[E0277]: `dyn Future<Output = ()>` cannot be unpinned --> src/main.rs:29:31 | 29 | observer.observe(&subject).await; | ^^^^^^ the trait `Unpin` is not ➥ implemented for `dyn Future<Output = ()>` | = note: consider using `Box::pin` = note: required because of the requirements on the impl of `Future` for ➥ `Box<dyn Future<Output = ()>>` = note: required because of the requirements on the impl of `IntoFuture` ➥ for `Box<dyn Future<Output = ()>>` help: remove the `.await` | 29 - observer.observe(&subject).await; 29 + observer.observe(&subject); | For more information about this error, try `rustc --explain E0277`.
What’s happening here? To understand, we need to look at the Future trait from the Rust standard library:
pub trait Future {
type Output;
fn poll(self: Pin<&mut Self>, cx: &mut Context<‘_>) -> Poll<Self::Output>;
}
Notice that, the poll() method takes its self parameter as the type Pin<&mut Self>. In other words, before we can poll a future (which is what .await does), it needs to be pinned. A pinned pointer is a special kind of pointer in Rust that can’t be moved (until it’s unpinned). Lucky for us, obtaining a pinned pointer is easy; we just need to update our Observer trait again as follows:
pub trait Observer {
type Subject;
type Output;
fn observe(
&self,
subject: &Self::Subject,
) -> Pin<Box<dyn Future<Output = Self::Output>>>; ❶
}
❶ Now, we wrap our Box in Pin, which gives us a pinned box.
Next, we’ll update our implementation like so:
impl Observer for MyObserver {
type Subject = Subject;
type Output = ();
fn observe(
&self,
_subject: &Self::Subject,
) -> Pin<Box<dyn Future<Output = Self::Output>>> { ❶
Box::pin(async { ❷
// do some async stuff here!
use tokio::time::{sleep, Duration};
sleep(Duration::from_millis(100)).await;
})
}
}
❶ Now, we return Pin<Box<...>>.
❷ Box::pin() conveniently returns a pinned box for us.
At this point, our code will compile, and it works. You might think we’re out of the woods, but unfortunately, we are not. The implementation for the Observable trait is even more complicated. Let’s take a look at the Observable trait:
pub trait Observable {
type Observer;
fn update(&self);
fn attach(&mut self, observer: Self::Observer);
fn detach(&mut self, observer: Self::Observer);
}
We need to make the update() method from Observable async, but it’s more complicated because, inside update(), we pass self to each of the observers. Passing a self reference inside an async method won’t work without specifying a lifetime for that reference. Additionally, we need each Observer instance to implement both Send and Sync because we want to observe updates concurrently, which requires that our observers can move across threads. The final form of our Observer trait is shown in the following listing.
Listing 8.4 Implementing the async Observer trait
pub trait Observer: Send + Sync { ❶
type Subject;
type Output;
fn observe<'a>( ❷
&'a self, ❸
subject: &'a Self::Subject, ❹
) -> Pin<Box<dyn Future<Output = Self::Output> + 'a + Send>>; ❺
}
❶ We add the Send + Sync supertraits to make sure our observers can be used concurrently across threads.
❷ The 'a lifetime allows us to pass self and subject as references.
❸ Here, we apply 'a to the self reference.
❹ Here, we apply 'a to the subject reference.
❺ We add 'a + Send to the trait bounds to allow moving across threads and ensure the return future doesn’t outlive any captured references for ’a.
Our updated Observable trait is shown in the following listing.
Listing 8.5 Implementing the async Observable trait
pub trait Observable {
type Observer;
fn update<‘a>( ❶
&’a self,
) -> Pin<Box<dyn Future<Output = ()> + ‘a + Send>>;
fn attach(&mut self, observer: Self::Observer);
fn detach(&mut self, observer: Self::Observer);
}
❶ As with Observer, we need to add a lifetime for our references.
Now, we’ll implement Observable for our Subject.
Listing 8.6 Implementing the async Observable trait for Subject
pub struct Subject {
observers:
Vec<Weak<dyn Observer<Subject = Self, Output = ()>>>,
state: String,
}
impl Subject {
pub fn new(state: &str) -> Self {
Self {
observers: vec![],
state: state.into(),
}
}
pub fn state(&self) -> &str {
self.state.as_ref()
}
}
impl Observable for Subject {
type Observer =
Arc<dyn Observer<Subject = Self, Output = ()>>;
fn update<‘a>(&’a self) -> Pin<Box<dyn Future<Output = ()> + ‘a + Send>>
{
let observers: Vec<_> =
self.observers.iter().flat_map(|o| o.upgrade()).collect(); ❶
Box::pin(async move { ❷
futures::future::join_all( ❸
observers.iter().map(|o| o.observe(self)), ❹
)
.await; ❺
})
}
fn attach(&mut self, observer: Self::Observer) {
self.observers.push(Arc::downgrade(&observer));
}
fn detach(&mut self, observer: Self::Observer) {
self.observers
.retain(|f| !f.ptr_eq(&Arc::downgrade(&observer)));
}
}
❶ We generate the list of observers to notify outside the async context and collect this into a new Vec.
❷ We use a move on our async block to move the captured observers list into the async block.
❸ Using join_all() here introduces concurrency across our observers.
❹ Each observer’s observe function is called with the same self reference.
❺ Finally, we .await on the join operation within our async block.
Now, we can finally test our async observer pattern.
Listing 8.7 Testing our async observer pattern
#[tokio::main]
async fn main() {
let mut subject = Subject::new("some subject state");
let observer1 = MyObserver::new("observer1");
let observer2 = MyObserver::new("observer2");
subject.attach(observer1.clone());
subject.attach(observer2.clone());
// ... do something here ...
subject.update().await;
}
Running the preceding code will produce the following output:
observed subject with state="some subject state" in observer1 observed subject with state="some subject state" in observer2
The Rust async ecosystem is growing fast, and many libraries have support for async and .await. However, in spite of this, there are cases where you may need to deal with synchronous and asynchronous code together. We already demonstrated two such examples in the previous section, but let’s elaborate more on that.
Tip As a general rule, you should avoid mixing sync and async. In some cases, it may be worth the effort to add async support when it’s missing or upgrade code that’s using older versions of Tokio that don’t work with the new async and .await syntax.
The most common scenario in which you’ll have to mix sync and async is when you’re using a crate which doesn’t support async, such as a database driver or networking library. For example, if you want to write an HTTP service using the Rocket crate (https://crates.io/crates/rocket) with async, you may need to read or write to a database that doesn’t yet have async support. Adding async support to sufficiently complex libraries might not be the best use of your time, even when it’s a noble cause.
To call synchronous code from within an async context, the preferred way is to use the tokio::task::spawn_blocking() function, which accepts a function and returns a future. When a call to spawn_blocking() is placed, it will execute the function provided on a thread queue managed by Tokio (which can be configured). You can then use .await on the future returned by spawn_blocking(), like you normally would with any async code.
Let’s look at an example of spawn_blocking() in action, by creating code that writes a file asynchronously and then reads it back synchronously:
use tokio::io::{self, AsyncWriteExt};
async fn write_file(filename: &str) -> io::Result<()> { ❶
let mut f = tokio::fs::File::create(filename).await?;
f.write(b"Hello, file!").await?;
f.flush().await?;
Ok(())
}
fn read_file(filename: &str) -> io::Result<String> { ❷
std::fs::read_to_string(filename)
}
#[tokio::main]
async fn main() -> io::Result<()> {
let filename = "mixed-sync-async.txt";
write_file(filename).await?;
let contents =
tokio::task::spawn_blocking(|| read_file(filename)).await??; ❸
println!("File contents: {}", contents);
tokio::fs::remove_file(filename).await?;
Ok(())
}
❶ Writes "Hello, file!" to our file asynchronously
❷ Reads the contents of our file into a string, returning the string synchronously
❸ Note the double ?? because both spawn_blocking() and read_file() return a Result.
In the preceding code, we perform our synchronous I/O within the function called by spawn_blocking(). We can await the result just like any other ordinary async block, except that it’s actually being executed on a separate blocking thread managed by Tokio. We don’t have to worry about the implementation details, except that there needs to be an adequate number of threads allocated by Tokio. In the preceding example, we just use the default values, but you can change the number of blocking threads with the Tokio runtime builder (for which the full list of parameters can be found at http://mng.bz/j1WV).
For the opposite case—using async code within synchronous code—it’s possible to use the runtime handle with block_on(), as shown in the previous section. This, however, is probably not a common use case and is something to be avoided. For a more advanced discussion on this topic, please refer to the Tokio documentation at https://tokio.rs/tokio/topics/bridging.
Asynchronous programming is great for I/O-heavy applications, such as network services. This could be an HTTP server, some other custom network service, or even a program that initiates many network requests (as opposed to responding to requests). Async does bring with it some complexity that you generally don’t need to worry about with synchronous programming, for the reasons outlined throughout this chapter.
It’s reasonable to use async as a general rule but only in cases where concurrency is required. Many programming tasks don’t require concurrency and are best served by synchronous programming. Some examples of this could be a simple CLI tool that reads or writes to a file or standard I/O or a simple HTTP client that makes a few sequential HTTP requests like curl. If you have a curl-like tool that needs to make thousands of concurrent HTTP requests, then, by all means, do use async.
It’s worth noting that adding async after the fact is more difficult than building software with async support up front, so think carefully about whether your use case requires async. In terms of raw performance, there is practically no difference between using and not using async for simple sequential and nonconcurrent tasks; however, Tokio introduces some slight overhead, which may be measurable but is unlikely to be significant for most purposes.
For any sufficiently complex networked application, it’s critical to instrument your code to measure its performance and debug problems. The Tokio project provides a tracing crate (https://crates.io/crates/tracing) for this purpose. The tracing crate supports the OpenTelemetry (https://opentelemetry.io/) standard, which enables integration with a number of popular third-party tracing and telemetry tools, but it can also emit traces as logs.
Enabling tracing with Tokio also unlocks tokio-console (https://github.com/tokio-rs/console), which is a CLI tool similar to the top program you’re likely familiar with from most UNIX systems. tokio-console allows you to analyze Tokio-based async Rust code in real time. Neat! While tokio-console is handy, in most environments, you’d likely emit traces to logs or with OpenTelemetry, as tokio-console is ephemeral and mainly useful as a debug tool. You also cannot attach tokio-console to a program that wasn’t compiled for it ahead of time.
Enabling tracing requires configuring a subscriber to which the traces are emitted. Additionally, to use tracing effectively, you need to instrument functions at the points where you want to measure them. This can be done easily with the #[tracing::instrument] macro. Traces can be emitted at different levels and with a number of options, which are well documented in the tracing docs at https://docs.rs/tracing/latest/tracing/index.html.
Let’s write a small program to demonstrate tracing with tokio-console, which requires some setup and boilerplate. Our program will have three different sleep functions, each instrumented, and they will run forever, concurrently, in a loop:
use tokio::time::{sleep, Duration};
#[tracing::instrument] ❶
async fn sleep_1s() {
sleep(Duration::from_secs(1)).await;
}
#[tracing::instrument]
async fn sleep_2s() {
sleep(Duration::from_secs(2)).await;
}
#[tracing::instrument]
async fn sleep_3s() {
sleep(Duration::from_secs(3)).await;
}
#[tokio::main]
async fn main() {
console_subscriber::init(); ❷
loop {
tokio::spawn(sleep_1s()); ❸
tokio::spawn(sleep_2s());
sleep_3s().await; ❹
}
}
❶ We’ll use the instrument macro from the tracing crate to instrument our three sleep functions.
❷ We have to initialize the console subscriber in our main function to emit the traces.
❸ We’ll fire and forget sleep 1 and sleep 2 and then block on sleep 3.
❹ Here, we block on sleep 3 until 3 seconds have elapsed and then repeat the process forever.
We also need to add the following to our dependencies, specifically to enable the tracing feature in Tokio:
[dependencies]
tokio = { version = "1", features = ["full", "tracing"] } ❶
tracing = "0.1"
console-subscriber = "0.1"
❶ The tracing feature in Tokio is not enabled by "full"; it must be explicitly enabled.
We’ll install tokio-console with cargo install tokio-console, after which we can compile and run our program. However, we need to compile with RUSTFLAGS="--cfg tokio_ unstable" to enable unstable tracing features in Tokio for tokio-console. We’ll do this by running the program directly from Cargo with RUSTFLAGS="--cfg tokio_unstable" cargo run. With our program running, we can now run tokio-console, which will produce the output shown in figure 8.6. In addition to monitoring tasks, we can monitor resources, as shown in figure 8.7. We can also drill down into individual tasks and even see a histogram of poll times, as shown in figure 8.8.
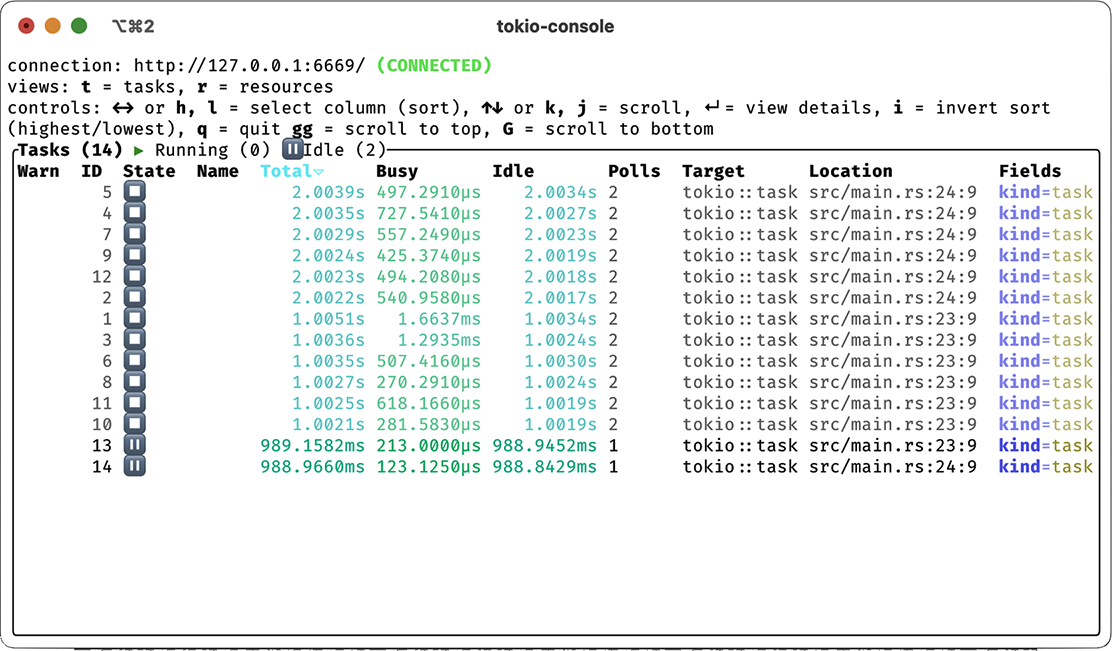
Figure 8.6 Running tasks, as shown in tokio-console
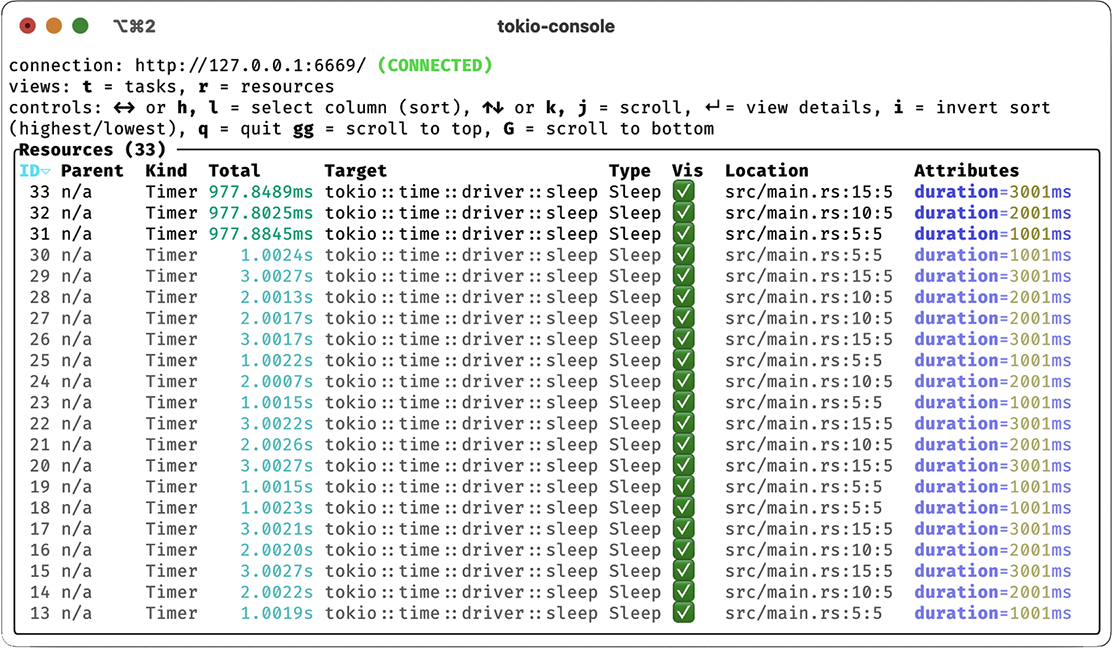
Figure 8.7 Resource usage, as shown in tokio-console
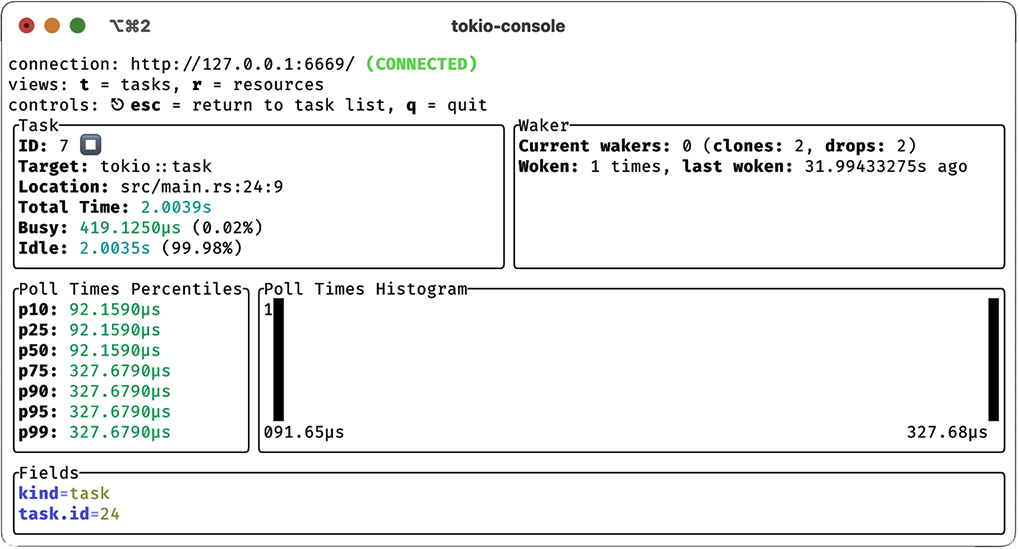
Figure 8.8 Individual task with poll time histogram
With tokio-console, we can see the state of tasks in real time, a variety of metrics associated with each one, additional metadata we may have included, as well as source file locations. tokio-console allows us to see both the tasks we’ve implemented and the Tokio resources separately. All this data will also be made available in traces emitted to another sink, such as a log file or an OpenTelemetry collector.
The last thing we’ll discuss in this chapter is testing async code. When it comes to writing unit or integration tests for async code, there are two strategies:
For most cases, it’s preferable to create and destroy the runtime for each test, but there are exceptions to this rule, where reusing a runtime is more sensible. In particular, it’s reasonable to reuse the runtime if you have many (i.e., hundreds or thousands) of tests.
To reuse a runtime across tests, we can use the lazy_static crate, which we discussed quite a bit in chapter 6. Rust’s testing framework runs tests in parallel across threads, which must be handled correctly using tokio::runtime::Handle, as we demonstrated earlier in this chapter.
For most cases, you can simply use the #[tokio::test] macro, which works exactly like #[test], except that it’s for async functions. The Tokio test macro takes care of setting up the test runtime for you, so you can write your async unit or integration test like you normally would any other test. To demonstrate, consider the following function, which sleeps for 1 second:
async fn sleep_1s() {
sleep(Duration::from_secs(1)).await;
}
We can write a test using the #[tokio::test] macro, which handles creating the runtime for us:
#[tokio::test]
async fn sleep_test() {
let start_time = Instant::now();
sleep(Duration::from_secs(1)).await;
let end_time = Instant::now();
let seconds = end_time
.checked_duration_since(start_time)
.unwrap()
.as_secs();
assert_eq!(seconds, 1);
}
This test runs normally like any other test, except it’s running within an async context. You may certainly manage the runtime yourself if you wish, but as mentioned already, you must be mindful of the fact that Rust’s tests will run in parallel.
Finally, Tokio provides the tokio_test crate, which can be enabled by adding the "test-util" feature (which is not enabled by the "full" feature flag). This includes some helper tools for mocking async tasks as well as some convenience macros for use with Tokio. The tokio_test crate is documented at https://docs.rs/tokio-test/latest/tokio_test/.
Rust provides multiple async runtime implementations, but Tokio is appropriate for most purposes.
Asynchronous programming requires special control flow, and our code must yield to the runtime’s scheduler to allow it an opportunity to switch tasks. We can yield using .await or by spawning futures directly with tokio::task::spawn().
Asynchronous code blocks (e.g., functions) are denoted with the async keyword. Async code blocks always return futures.
We can execute a future with the .await statement but only within an async context (i.e., an async code block).
Async blocks are lazy and will not execute until we call .await or when they spawned explicitly. This differs from most other async implementations.
Using tokio::select! {} or tokio::join!() allows us to introduce explicit concurrency.
Spawning tasks with tokio::task::spawn() allows us to introduce concurrency and parallelism.
If we want to perform blocking operations, we spawn them with tokio::task::spawn_blocking().
The tracing crate provides an easy way to instrument and emit telemetry to logs or OpenTelemetry collectors.
We can use tokio-console with tracing to debug async programs.
Tokio provides testing macros for unit and integration tests, which provide the necessary testing runtime environment. The tokio_test crate, which can be enabled with the "test-util" feature flag on Tokio, provides mocking and assertion tools for use with Tokio.