The fundamental goal of any software development team is to implement a set of features in order to form a product and create direct or indirect business value. This product can be distributed as a package that can be installed on a computer offline or can be internet based and used online. Each programming language has its own packaging methodology; for example, you can use a WAR or JAR file for Java projects or a binary executable for Go projects. We call this monolithic architecture: one or more features/modules are packaged as one product that completes related tasks within a distributable object. When scalability problems arise, alternative solutions like microservice architecture are popular, as the application is decomposed into services based on their business capabilities. This decomposition enables the deployment of each service independently, which we will see in detail in chapter 8. Interservice communication stability is imperative to providing data consistency among services. This chapter will show how important gRPC is for interservice communication.
In monolithic architecture, the different components of a monolithic application are combined into a single-tiered and unified software application that can contain a user interface, a server, and database modules that are all managed in one place. Monolithic architecture is especially helpful when developing the initial version of a product, as it helps you get familiar with business domains without having to tackle nonfunctional challenges. However, it is suggested that you assess your product periodically to understand whether it is the right time to move to microservice architecture. Now that we know what monolithic architecture looks like, let’s look at its pros and cons.
All modern IDEs are designed to support monolithic applications. For example, you can open a multimodule Maven project in IntelliJ IDEA (https://www.jetbrains.com/idea/) or create a modular Go project with GoLand (https://www.jetbrains.com/go/) that you can easily open and navigate within the codebase.
However, problems can arise as your codebase grows. For example, suppose you have many modules within a monolithic application, and you try to open them simultaneously. In that case, it is possible to overload the IDE, which negatively affects productivity; it also may not be necessary to open them all if you don’t need some of them.
Additionally, if you do not have proper isolation for your test cases, you may run all the tests any time you make a small change in your codebase. The bigger the codebase, the longer the compile and testing time.
Deploying a monolithic application means copying a standalone package or folder hierarchy to the server or a container runtime. However, monoliths may be an obstacle to frequent deployments in continuous deployment because they are hard to deploy and test in a reasonable time interval. You need to deploy the entire application, even if you introduce just a small change to a specific component. For example, say that we introduced a small change in the newsletter component responsible for serving the newsletter, and we want to test and deploy it to production. We would need to run all the tests, even though we haven’t changed anything in other components, such as payment, order, and so on. In the same way, we need to build the system to generate one artifact, even though the changes are only in the newsletter component.
However, deploying a monolithic application might have more significant problems, especially if multiple teams share this application. Flaky tests and broken functionalities other teams introduce may interrupt the entire deployment, and you may want to revert it.
Monolithic applications can be quickly scaled by putting them behind a load balancer, which enables client requests to be proxied to downstream monolithic applications in physical servers or to container runtimes. However, it may not make sense from a cost perspective because those applications are exact copies of each other, even if you don’t need all the components to be scaled at the same priority level. Let’s look at a simple example to better understand this utilization problem.
Let’s say that you have a monolithic application that needs 16 GB of memory, and the most critical out of 10 modules is customer service. When you scale this monolithic application by 2, you will end up with 32 GB of memory allocation. Let’s say that the custom module needs 2 GB of memory to run efficiently. Wouldn’t it be better to scale just the customer module that needs an extra 2 GB of memory by 2 instead of 16 GB?
Distributing monolithic application modules to different teams for fast feature implementation is another challenging scaling problem. Once you decide to use monolithic architecture, you commit to the technology stack long term. Layers in monolithic applications are tightly coupled in-process calls developed with the same technology for interoperability. As a developer or architect, it would be harder to try another technology stack (once one became available). Let’s look at the driving factors to scaling next.
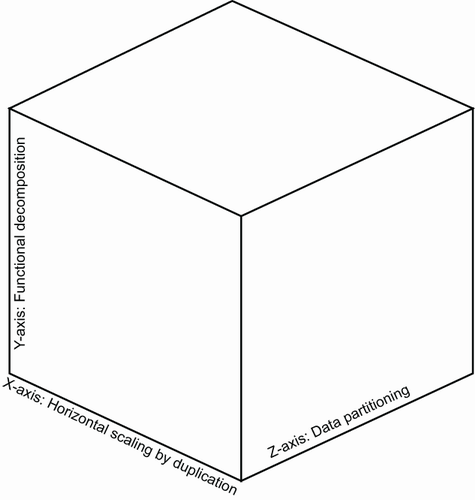
Plenty of driving factors can force you to change your architecture, and scalability is one of them, for performance reasons. A scale cube is a three-dimensional scalability model of an application. Those dimensions are X-axis scaling, Y-axis scaling, and Z-axis scaling, as shown in figure 2.1.
X-axis scaling consists of running multiple copies of the same application behind a load balancer. In Kubernetes, load balancing is handled by Service resources (http://mng.bz/x4Me), which proxy requests to available backend instances that live in Pod resources (https://kubernetes.io/docs/concepts/workloads/pods/), which we will see in chapter 8 in detail. Those instances share the load, so if there are N copies, every instance can handle 1/N of the load. Some of the main drawbacks of this scaling model are that since each copied instance has access to all data, the instances need more memory than required and that there is no advantage to reducing the complexity of growing the codebase.
Z-axis scaling is like X-axis scaling since the application is copied to instances. The main difference is that each application is responsible for just a subset of data, which results in cost savings. Since data is partitioned across services, it also improves fault tolerance, as only some data will be inaccessible to the user.
Building Z-axis scaling is challenging because it introduces extra complexity to the application. You also need to find an effective way to repartition data for data recovery.
In Y-axis scaling, scaling means splitting the application by feature instead of having multiple copies. For example, you might decompose your application into a set of services with a couple of related functions. Now that we understand the pros and cons of monolithic architecture and scalability models, let’s look at how microservices architecture is a form of Y-axis scaling.
Microservice architecture is an architectural style that defines an application as a collection of services. Those applications mainly have the following characteristics:
They are loosely coupled, which allows you to create highly maintainable and testable services.
Each of the services can be deployed and scaled independently.
Each service or set of services can be easily assigned to a dedicated team for code ownership.
There is no need for long-term commitment to the technology stack.
If one of the services fails, other services can continue to be used.
First, you must decide if microservice architecture is well suited for your product architecture. As said previously, starting with monolithic architecture is a best practice because it allows you to understand your business capabilities. Once you start having scalability problems, less productive development, or longer release life cycles, you can reassess your environment to see if functional decomposition is a good fit for your application. Once you decide to use microservice architecture, you might have independently scalable services, small projects that contain specific context during development only, and faster deployments due to faster test verification and small release artifacts.
Let’s assume you are familiar with your business model and know how to decompose your application into small services. You will have other challenges not visible in monolithic applications, such as handling data consistency and interservice communication.
Having consistent data is essential for almost any kind of application. In monolithic architecture, data consistency is generally ensured by transactions. A transaction is a series of actions that should be completed successfully; all operations are automatically rolled back if even one action fails. To have consistent data, the transaction begins first, actual business logic is executed, and then the transaction is committed for a successful case or rolled back in case of failure. As an example, let’s assume that once Order :create() method is executed, it calls a series of actions, such as Payment:create() and Shipping:start(). If both Payment and Shipping operations succeed, it will successfully commit Order status as SUCCESS. Likewise, if the Shipping operation fails, it rolls back the Payment operation and marks the Order operation as FAILED (see figure 2.2).
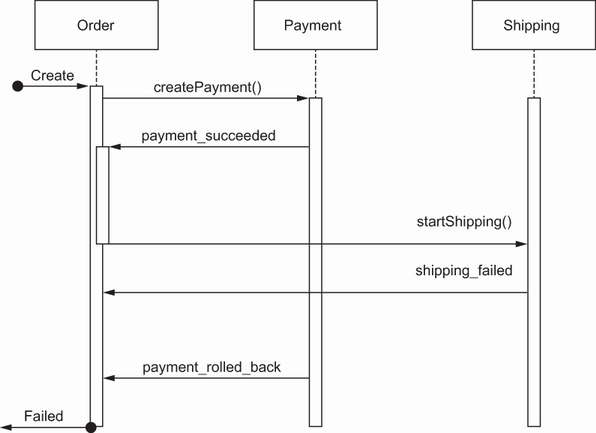
Figure 2.2 The consistency of the Order data is managed by transaction boundaries, which are committed and rolled back.
A typical transaction can be expressed with the steps begin and commit/rollback, during which you begin a transaction and execute the actual operation; then, you may end up committing data to the data store or rolling back the entire operation. Now that we understand that data consistency can be easily handled in monolithic architecture, let’s look at how it is handled in microservice architecture.
Transactions are a critical part of an application responsible for maintaining data consistency. In a monolithic application, there is a single data source in the same application, but once you switch to microservices architecture, the data state is spread across services. Each of the services has its own data store, which means a single transaction cannot handle the data’s consistency. To have data consistency in a distributed system, you have two options: a two-phase commit (2PC) and saga. 2PC coordinates all the processes that form distributed atomic transactions and determines whether they should be committed or aborted. A saga is a sequence of local transactions that updates each service and publishes another message to trigger another local transaction on the next service.
Because transaction steps are spanned across the services, they cannot be handled with an annotation or two lines of code. However, there are widely used practices with saga, so you don’t need to reinvent the wheel for your use cases. Choreography- and orchestrator-based sagas are the most popular patterns for interservice communication to have consistent data.
A choreography-based saga is a pattern in which each service executes its local transaction and publishes an event to trigger the next service to execute its local transaction. Whenever a saga is created, it can be completed in the following patterns:
Service returns the result to the client once the saga is completed. It receives an event to update its domain object’s status as succeeded or failed.
A saga is created, and the client starts to poll the next service to get either a succeeded or failed response. The unique identifier to start polling should be directly returned when the saga is created.
A saga is created, and the client uses a WebSocket connection in which the service sends the result back using WebSocket protocol. A saga will be completed once the succeeded or failed result is returned.
Now let’s look at how to apply one of these notations to a real-life use case for order creation flow.
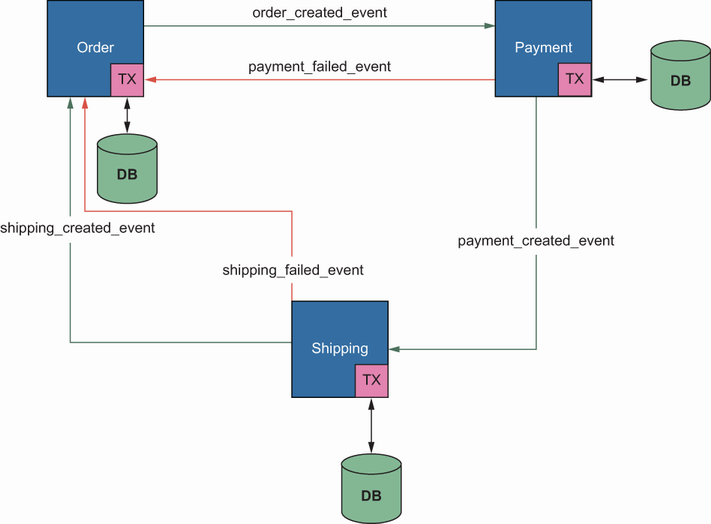
In a typical order creation flow, a saga is created in Order Service, and Order is created with a PENDING state. It sends an event called order_created right after Order is persisted and consumed by Payment Service, which will try to charge the customer and send another event: payment_created or payment_failed. If it fails, Order Service will be notified, and Order will be marked as FAILED. Shipping Service will consume the event and initiate the shipping process if it is successful. Finally, it will create another event for failure or success, which will cause Order’s status to be marked as FAILED or SUCCESS. A high-level diagram of communication with a choreography-based saga is shown in figure 2.3.
Service communications over queue can be handled in two ways:
Command channels—The publisher sends a message directly to the next service with a replyToChannel parameter so that it can notify the consumer once it completes the operation and commits the transaction. The main drawback of this pattern is that the publisher needs to know the location of the next service.
Pub/sub mechanism—The publisher publishes a domain event, and interested consumers can consume messages to process and commit a local transaction. The main disadvantage of this notation is that it is a possible single point of failure since all the subscribers use one broker technology and all the events are sent to consumers.
Let’s look at how we can use command channel notation: asynchronous communication that needs extra information in events to decide what to do next. In addition to the fields that form the actual data, a particular field, called a replyTo channel, is injected so that the consumer service can send the result back to that channel. It is also best practice to add some correlation ID to these events to see the whole picture of a specific series of events, as shown in figure 2.4.
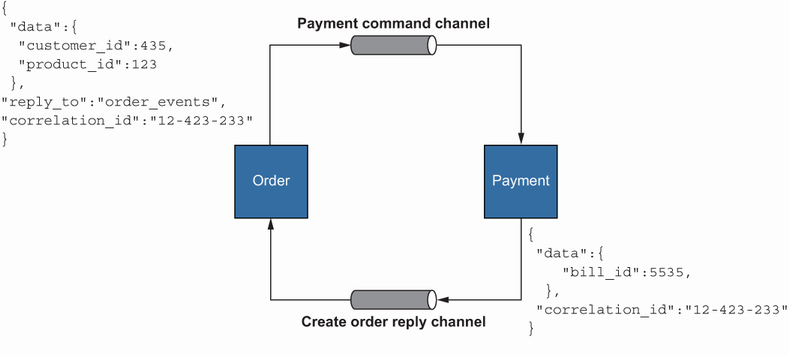
Figure 2.4 The Order service sends an event to the payment command channel after the local transaction. The Payment service charges the customer and sends the ID of the bill, which was created after successful payment, back to the create order reply channel, which is already specified in the Order event.
This type of communication is widely used in another microservice communication pattern called an orchestration-based saga. Let’s look at this pattern to see how data consistency is guaranteed in a microservice architecture.
Let’s rework the Order service’s creation flow to create an order saga using an orchestration-based saga pattern. An orchestration-based saga consists of an orchestrator and participants, and the orchestrator tells participants what to do. The orchestrator can communicate with participants using a command channel or request/response style. It connects participants individually to tell them to execute their local transactions and decides the next step based on this response.
Whenever you send a create order request to the Order service, it initiates a saga responsible for running a series of steps to complete the operations. When it calls the Payment service to charge the customer for that specific order, it can return a success or a failure. If it returns a success, the create order saga continues with the next step, shipping, in our case. If it fails in the Payment service, the saga runs a compensation transaction to undo the operation, which is a refund in this step. If the create order saga runs all the steps successfully, the order status will be saved as succeeded. Remember that if the saga fails at any specific step, it runs compensation transactions from the bottom up. For example, if it fails in shipping, it will execute Payment:refund() and Order:cancel(), such as a rollback operation for order creation, as seen in figure 2.5.
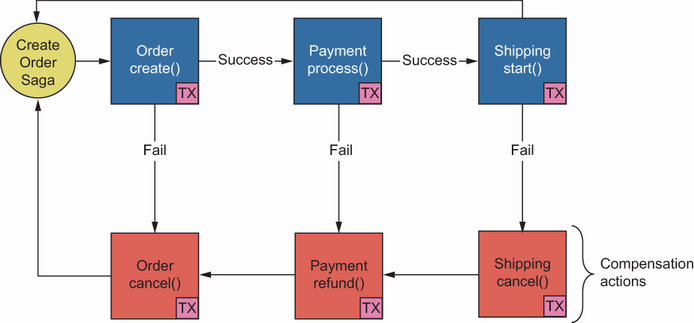
Figure 2.5 An orchestrator for an order creation creates an order and payment process, and the Shipping service starts to complete the order flow. It runs a compensation transaction in case of failure, and this is executed from the bottom up.
We will use the request/response style to complete a saga flow for interservice communication. Each service should know the address of all other services to connect. Let’s take a closer look at how services find each other in microservice architecture.
Service discovery is the operation in which service locations are managed and exposed outside to let each service find the next one for step execution. There are two types of service discovery:
Client-side service discovery—In this notation, a service discovery tool allows applications to report their locations during startup, as shown in figure 2.6. Client applications have direct connections to the service registry, and they query the location of a specific service by providing some criteria, like the service name, or a unique identifier.
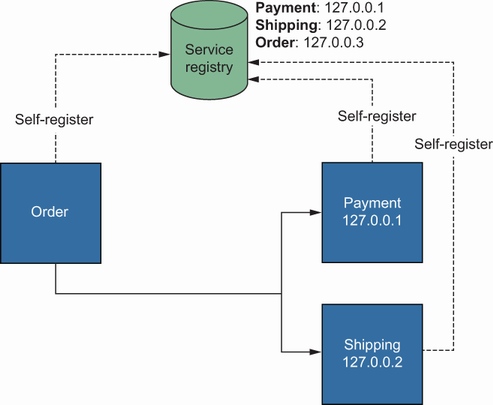
Figure 2.6 The Order service resolves the Payment and Shipping services by using a third-party service discovery tool.
Server-side service discovery—A load balancer integrates with the service registry to resolve downstream services. Client applications connect to services via the load balancer instead of using the service registry to resolve the exact location, as visualized in figure 2.7.
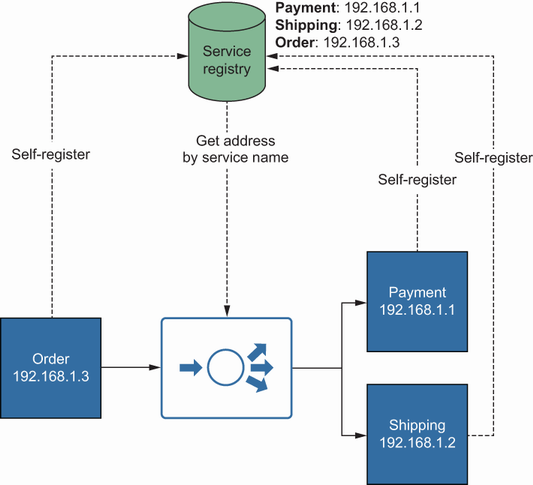
Figure 2.7 Clients use load balancers to find destination services, and each service registers itself during startup.
Apart from those two discovery mechanisms, container orchestration platforms such as Kubernetes have built-in service discovery mechanisms that allow you to access any service by its name, which we will see in detail in chapter 8. Now that we understand service discovery, which enables services to communicate with each other, let’s see how gRPC comes into play.
gRPC is a modern, lightweight communication protocol and a high-performance RPC framework introduced by Google. It can efficiently connect services in a microservices environment with built-in support for load balancing, tracing, health checking, and authentication. gRPC provides easy-to-use and efficient communication using protocol buffers, an open source mechanism for serializing structured data. Let’s consider the minimum set of steps to use gRPC and protocol buffers to make services communicate with each other (i.e., exchange messages) using autogenerated Golang source code.
Let’s revisit the order creation flow to use gRPC and protocol buffers for interservice communication. The ideal steps are as follows:
Define the proto files that contain message and service definitions. These can be inside the current project or in a separate repository independently maintained.
Implement the server-side business logic by using one of the supported languages (https://www.grpc.io/docs/languages/).
Implement the client-side business logic to connect services through the stub.
Any .proto file has message definitions and service functions in common. The message may refer to a request object, response object, and commonly used enums for a typical service in a microservices environment. For example, the Payment service would have a CreatePaymentRequest message to be consumed by the Order service. In the same way, CreatePaymentResponse can return bill_id to the Order service to store it as a separate field in the Order service’s entity. Having just these messages is insufficient, so we need to define services to use those request and response messages. Create service functions can take CreatePaymentRequest as a function parameter and return CreatePaymentResponse as a function return signature. These input and output parameters to service functions are important because they directly affect client-side usability:
message CreatePaymentRequest {
int user_id = 1;
float64 price = 2;
}
message CreatePaymentResponse {
int bill_id = 1;
}
service Payment {
RPC Create(CreatePaymentRequest)
returns (CreatePaymentResponse) {}
}
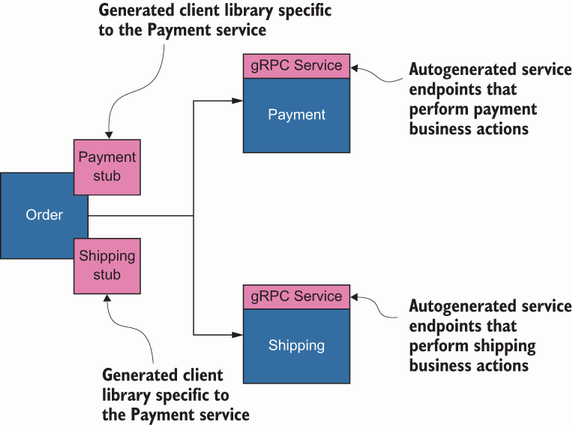
Payment and Shipping stubs can be easily generated via a protocol buffer compiler for multiple languages so that any service, such as Order, can consume them, as shown in figure 2.8. For example, the Order service can call a Create function in the Payment stub, which uses gRPC protocol to access actual service endpoints in Payment. protoc is used to generate Go source codes from protocol buffer description files. In this case, CreatePaymentRequest and CreatePaymentResponse messages will be compiled into Go structs to be used in data exchange operations for marshalling/unmarshalling requests and responses (figure 2.8). Here, marshalling means converting a Golang struct into a byte array. You can see the internals here: http://mng.bz/AoVK.
Now that we understand how to use protocol buffers to define service contracts (there will be more in-depth coverage in chapter 3), let’s look at how to generate source code by using .proto files
A protocol buffer compiler (i.e., protoc), is a tool that generates a language-specific client and server-side implementation using a .proto file. We will see .proto file preparation in detail in chapter 3, but let’s assume we have the following proto definition for the Payment service:
syntax = "proto3"; ❶ option go_package="github.com/huseyinbabal/grpc- ➥ microservices-in-go/listing_2.1/payment"; ❷ message CreatePaymentRequest { float price = 1; } message CreatePaymentResponse { int64 bill_id = 1; } service Payment { RPC Create(CreatePaymentRequest) returns (CreatePaymentResponse) {} }
❷ Package name of the generated source code
You can use the following command to create client and server implementations of that .proto file.
Listing 2.1 Command to generate source code for Go
protoc \
--go_out=. \
--go_opt=paths=source_relative \
--go-grpc_out=. \
--go-grpc_opt=paths=source_relative \
payment.proto
This example is a simple request/response style called Unary RPC and will generate all the Go codes and put them in a location relative to input .proto files. gRPC also allows you to use streaming on both the client and server sides. To have a streaming response, you can modify your service functions in the .proto file:
service Payment {
Create(CreatePaymentRequest)
returns (stream CreatePaymentResponse){}
}
Streaming allows the server side to split data and return it, part by part, to the client side. The server returns a stream of CreatePaymentResponses in response to the client’s request. Once the server sends all the messages, it also sends some metadata to the client to state that the streaming operation is finished on the server side. The client completes its operation after seeing this status.
Server-side streaming is beneficial if the server needs to return bulk data to the client. Streaming can also happen on the client side. For example, payment requests are sent to the server in streaming mode. The server does not need to send multiple messages, and it can return a single message that reports all the payment creation operation responses with their statuses:
service Payment {
Create(stream CreatePaymentRequest)
returns (CreatePaymentResponse){}
}
Streaming on both the client and server sides is called bidirectional streaming. It allows the client to send requests to the server continuously, and the server can return a result as a stream of objects. Since that operation is handled asynchronously, it is better to provide a unique identifier to mark which operation failed:
service Payment {
Create(stream CreatePaymentRequest)
returns (stream CreatePaymentResponse){}
}
Don’t worry; we will examine this concept in detail in chapter 5.
Client–server communication means service-to-service communication in a microservices environment. A service is a typical consumer that uses the client stub of another service. In our case, if you want to connect the Order service to the Payment service, complete the following steps:
Import the Payment service client stub into the Order service as a dependency.
Create a connection by dialing the Payment service from the Order service. Let’s assume we already know the address of the Payment service since we use service discovery.
Create a Payment client using the connection object we created in step 3.
Listing 2.2 Payment stub usage on client side
var opts []grpc.DialOption
conn, err := grpc.Dial(*serverAddr, opts...)
if err != nil {
// handle connection error
}
defer conn.Close()
payment := pb.NewPaymentClient(conn)
result, err := payment.Create(ctx, &CreatePaymentRequest{})
if err != nil {
// handle Payment create error
}
In listing 2.2, we initialize a connection to address and pass this as an argument to PaymentClient. Notice that we use defer conn.Close() to be sure the connection is properly closed after the application closes. We don’t care how the underlying communication is handled while connecting to two services. Everything is abstracted into a client instance, which is autogenerated by protoc into Go.
The protocol buffers compiler also generates a client implementation with a naming convention, New<Service_Name>Client, so that you can create a new reference for the client of a specific service (e.g., NewPaymentClient). When you call a client stub, it can return a success or failure. For resilient communication, it is better to retry failed requests based on some criteria. In the same way, it is better to provide a timeout to this execution to make an operation fail if the client cannot see the response within the requested time interval. These best practices are all about making data more consistent. If you have an order object in a pending state that lives there for hours, it is a sign of an incorrect communication pattern. As you can see in the last example, there is a ctx parameter, even though we did not explicitly define it in the .proto file. The Protobuf compiler just adds a context parameter to all the service functions to allow consumers to pass the reference of their context objects. For example, to cancel an execution if you do not get results in 10 seconds, you can use the following code:
ctx, cancel := context.WithTimeout(context.Background(), 10 * time.Second) defer cancel() ❶ payment := pb.NewPaymentClient(conn) result, err := payment.Create(ctx, &CreatePaymentRequest{}) ❷ if err != nil { // handle Payment create an error }
❶ Calls the cancel() method before exiting the current function
❷ Fails the execution if there is no result within 10 seconds
Monolithic architecture is helpful, especially at the beginning of product implementation, but it is a best practice to switch to microservice architecture after you assess your product for scalability, development, and deployment problems, and then become familiar with your business capabilities and service contexts.
Periodic assessment of your products helps you decide if switching to microservice architecture makes sense (functional decomposition according to the scale cube).
Pub/sub or command channel mechanisms are examples of asynchronous communication, whereas the request/response style is an example of synchronous communication (e.g., gRPC).
Choreography- and orchestrator-based saga patterns provide data consistency within a distributed environment.
Protocol buffers help us define message and service functions to generate server and client stubs by using a protocol buffer compiler (i.e., protoc).