This chapter describes the process by which the outside world communicates with your operating system (OS). The network constantly interrupts program execution when bytes are ready to be delivered. This means that after connecting to a database (or at any other time), the OS can demand that your application deal with a message. This chapter describes this process and how to prepare your programs for it.
In chapter 9, you learned that a digital clock periodically notifies the OS that time has progressed. This chapter explains how those notifications occur. It also introduces the concept of multiple applications running at the same time via the concept of signals. Signals emerged as part of the UNIX OS tradition. These can be used to send messages between different running programs.
We’ll address both concepts—signals and interrupts—together, as the programming models are similar. But it’s simpler to start with signals. Although this chapter focuses on the Linux OS running on x86 CPUs, that’s not to say that users of other operating systems won’t be able to follow along.
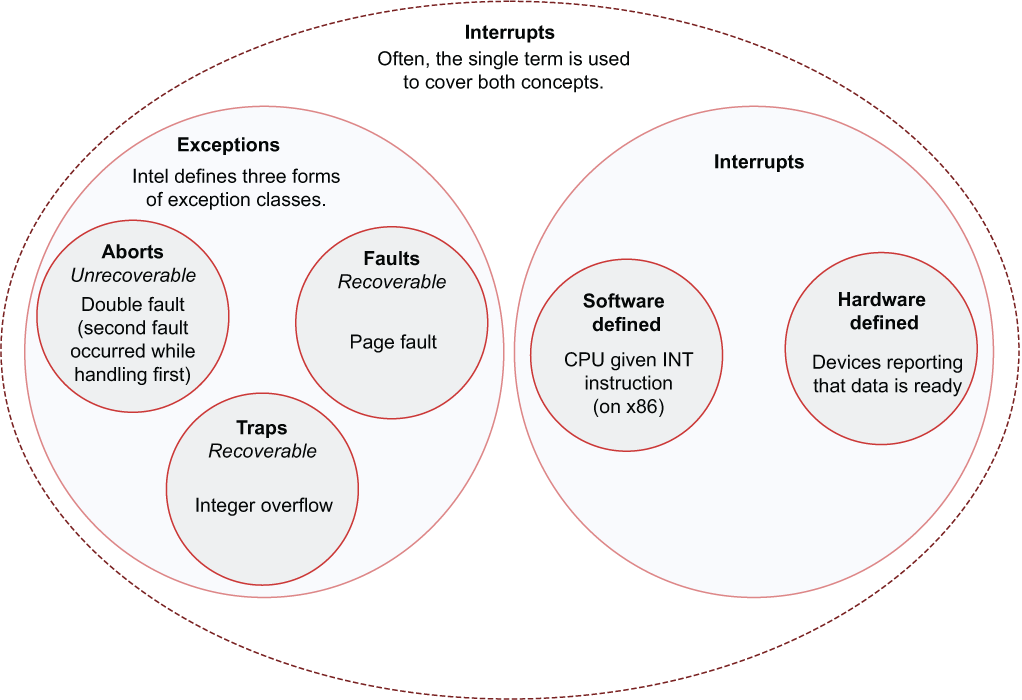
Learning how CPUs, device drivers, applications, and operating systems interact is difficult. There is a lot of jargon to take in. To make matters worse, the terms all look similar, and it certainly does not help that these are often used interchangeably. Here are some examples of the jargon that is used in this chapter. Figure 12.1 illustrates how these interrelate:
Abort—An unrecoverable exception. If an application triggers an abort, the application terminates.
Fault—A recoverable exception that is expected in routine operations such as a page fault. Page faults occur when a memory address is not available and data must be fetched from the main memory chip(s). This process is known as virtual memory and is explained in section 4 of chapter 6.
Exception—Exception is an umbrella term that incudes aborts, faults, and traps. Formally referred to as synchronous interrupts, exceptions are sometimes described as a form of an interrupt.
Hardware interrupt—An interrupt generated by a device such as a keyboard or hard disk controller. Typically used by devices to notify the CPU that data is available to be read from the device.
Interrupt—A hardware-level term that is used in two senses. It can refer only to synchronous interrupts, which include hardware and software interrupts. Depending on context, it can also include exceptions. Interrupts are usually handled by the OS.
Signal—An OS-level term for interruptions to an application’s control flow. Signals are handled by applications.
Software interrupt—An interrupt generated by a program. Within Intel’s x86 CPU family, programs can trigger an interrupt with the INT instruction. Among other uses of this facility, debuggers use software interrupts to set breakpoints.
Trap—A recoverable exception such as an integer overflow detected by the CPU. Integer overflow is explained in section 5.2.
Figure 12.1 A visual taxonomy of how the terms interrupt, exception, trap, and fault interact within Intel’s x86 family of CPUs. Note that signals do not appear within this figure. Signals are not interrupts.
Note The meaning of the term exception may differ from your previous programming experience. Programming languages often use the term exception to refer to any error, whereas the term has a specialized meaning when referring to CPUs.
The two concepts that are most important to distinguish between are signals and interrupts. A signal is a software-level abstraction that is associated with an OS. An interrupt is a CPU-related abstraction that is closely associated with the system’s hardware.
Signals are a form of limited interprocess communication. They don’t contain content, but their presence indicates something. They’re analogous to a physical, audible buzzer. The buzzer doesn’t provide content, but the person who presses it still knows what’s intended as it makes a very jarring sound. To add confusion to the mix, signals are often described as software interrupts. This chapter, however, avoids the use of the term interrupt when referring to a signal.
There are two forms of interrupts, which differ in their origin. One form of interrupt occurs within the CPU during its processing. This is the result of attempting to process illegal instructions and trying to access invalid memory addresses. This first form is known technically as a synchronous interrupt, but you may have heard it referred to by its more common name, exception.
The second form of interrupt is generated by hardware devices like keyboards and accelerometers. This is what’s commonly implied by the term interrupt. This can occur at any time and is formally known as an asynchronous interrupt. Like signals, this can also be generated within software.
Interrupts can be specialized. A trap is an error detected by the CPU, so it gives the OS a chance to recover. A fault is another form of a recoverable problem. If the CPU is given a memory address that it can’t read from, it notifies the OS and asks for an updated address.
Interrupts force an application’s control flow to change, whereas many signals can be ignored if desired. Upon receiving an interrupt, the CPU jumps to handler code, irrespective of the current state of the program. The location of the handler code is predefined by the BIOS and OS during a system’s bootup process.
Let’s work through this challenge by considering a small code example. The following listing shows a simple calculation that sums two integers.
Listing 12.1 A program that calculates the sum of two integers
1 fn add(a: i32, b:i32) -> i32 {
2 a + b
3 }
4
5 fn main() {
6 let a = 5;
7 let b = 6;
8 let c = add(a,b);
9 }
Irrespective of the number of hardware interrupts, c is always calculated. But the program’s wall clock time becomes nondeterministic because the CPU performs different tasks every time it runs.
When an interrupt occurs, the CPU immediately halts execution of the program and jumps to the interrupt handler. The next listing (illustrated in figure 12.2) details what happens when an interrupt occurs between lines 7 and 8 in listing 12.1.
Listing 12.2 Depicting the flow of listing 12.1 as it handles an interrupt
1 #[allow(unused)]
2 fn interrupt_handler() { ①
3 / / ..
4 }
5
6 fn add(a: i32, b:i32) -> i32 {
7 a + b
8 }
9
10 fn main() {
11 let a = 5;
12 let b = 6;
13
14 / / Key pressed on keyboard!
15 interrupt_handler()
16
17 let c = add(a,b);
18 }
① Although presented in this listing as an extra function, the interrupt handler is typically defined by the OS.
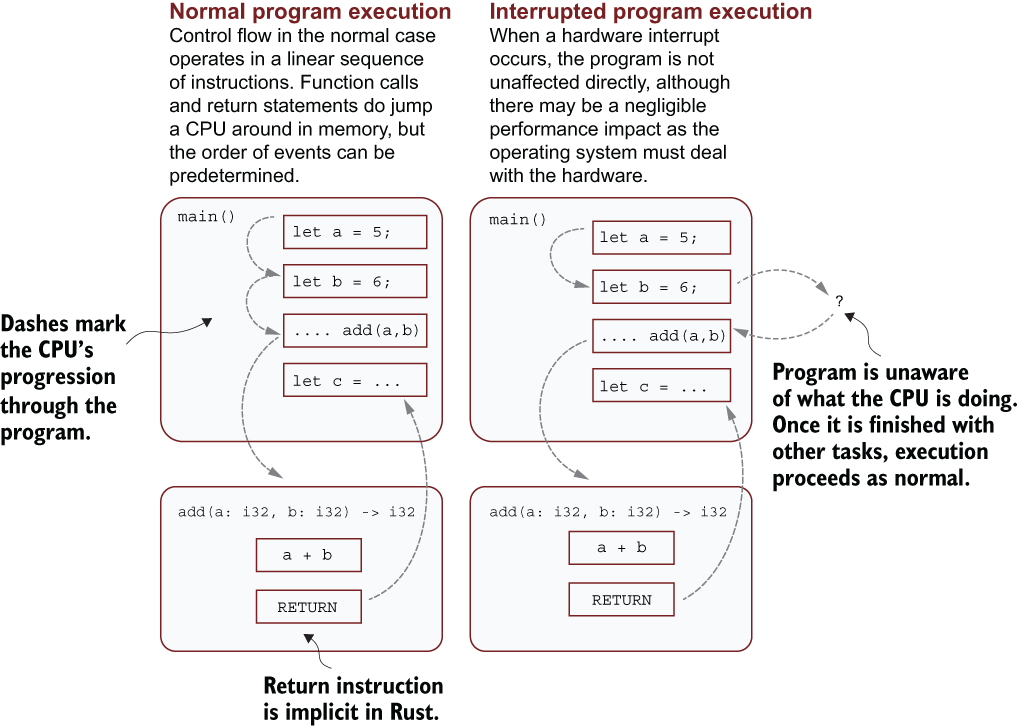
Figure 12.2 Using addition to demonstrate control flow for handling signals
One important point to remember is that, from the program’s perspective, little changes. It isn’t aware that its control flow has been interrupted. Listing 12.1 is still an accurate representation of the program.
Software interrupts are generated by programs sending specific instructions to the CPU. To do this in Rust, you can invoke the asm! macro. The following code, available at ch12/asm.rs, provides a brief view of the syntax:
#![feature(asm)] ①
use std::asm;
fn main() {
unsafe {
asm!("int 42");
}
}
Running the compiled executable presents the following error from the OS:
$ rustc +nightly asm.rs $ ./asm Segmentation fault (core dumped)
As of Rust 1.50, the asm! macro is unstable and requires that you execute the nightly Rust compiler. To install the nightly compiler, use rustup:
$ rustup install nightly
Hardware interrupts have a special flow. Devices interface with a specialized chip, known as the Programmable Interrupt Controller (PIC), to notify the CPU. Figure 12.3 provides a view of how interrupts flow from hardware devices to an application.
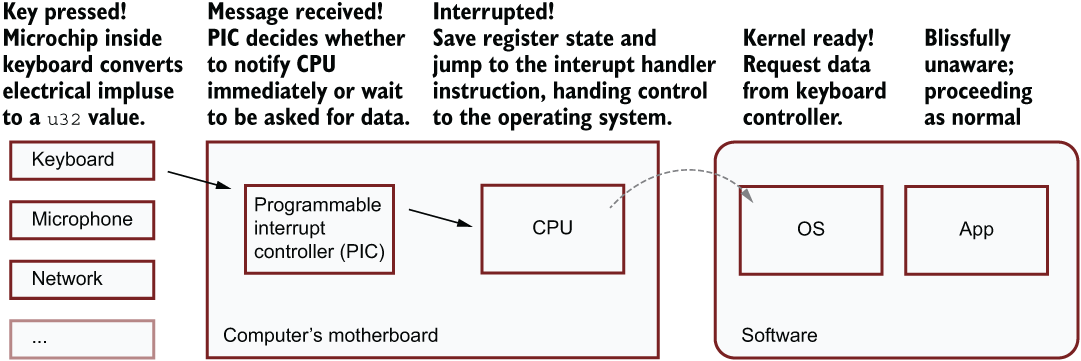
Figure 12.3 How applications are notified of an interrupt generated from a hardware device. Once the OS has been notified that data is ready, it then directly communicates with the device (in this case, the keyboard) to read the data into its own memory.
Signals require immediate attention. Failing to handling a signal typically results in the application being terminated.
Sometimes the best approach is to let the system’s defaults do the work. Code that you don’t need to write is code that’s free from bugs that you inadvertently cause.
The default behavior for most signals is shutting down the application. When an application does not provide a special handler function (we’ll learn how to do that in this chapter), the OS considers the signal to be an abnormal condition. When an OS detects an abnormal condition within an application, things don’t end well for the application—it terminates the application. Figure 12.4 depicts this scenario.

Figure 12.4 An application defending itself from marauding hoards of unwanted signals. Signal handlers are the friendly giants of the computing world. They generally stay out of the way but are there when your application needs to defend its castle. Although not part of everyday control flow, signal handlers are extremely useful when the time is right. Not all signals can be handled. SIGKILL is particularly vicious.
Your application can receive three common signals. The following lists them and their intended actions:
SIGINT—Terminates the program (usually generated by a person)
SIGTERM—Terminates the program (usually generated by another program)
SIGKILL—Immediately terminates the program without the ability to recover
You’ll find many other less common signals. For your convenience, a fuller list is provided in table 12.2.
You may have noticed that the three examples listed here are heavily associated with terminating a running program. But that’s not necessarily the case.
There are two special signals worth mentioning: SIGSTOP and SIGCONT. SIGSTOP halts the program’s execution, and it remains suspended until it receives SIGCONT. UNIX systems use this signal for job control. It’s also useful to know about if you want to manually intervene and halt a running application but would like the ability to recover at some time in the future.
The following snippet shows the structure for the sixty project that we’ll develop in this chapter. To download the project, enter these commands in the console:
$ git clone https:/ /github.com/rust-in-action/code rust-in-action $ cd rust-in-action/ch12/ch12-sixty
To create the project manually, set up a directory structure that resembles the following and populate its contents from listings 12.3 and 12.4:
ch12-sixty ├── src │ └── main.rs ① └── Cargo.toml ②
The following listing shows the initial crate metadata for the sixty project. The source code for this listing is in the ch12/ch12-sixty/ directory.
Listing 12.3 Crate metadata for the sixty project
[package] name = "sixty" version = "0.1.0" authors = ["Tim McNamara <author@rustinaction.com>"] [dependencies]
The next listing provides the code to build a basic application that lives for 60 seconds and prints its progress along the way. You’ll find the source for this listing in ch12/ch12-sixty/src/main.rs.
Listing 12.4 A basic application that receives SIGSTOP and SIGCONT
1 use std::time;
2 use std::process;
3 use std::thread::{sleep};
4
5 fn main() {
6 let delay = time::Duration::from_secs(1);
7
8 let pid = process::id();
9 println!("{}", pid);
10
11 for i in 1..=60 {
12 sleep(delay);
13 println!(". {}", i);
14 }
15 }
Once the code from listing 12.4 is saved to disk, two consoles open. In the first, execute cargo run. A 3–5 digit number appears, followed by a counter that increments by the second. The first line number is the PID or process ID. Table 12.1 shows the operation and expected output.
Table 12.1 How processes can be suspended and resumed with SIGSTOP and SIGCONT
The program flow in table 12.1 follows:
In console 1, move to the project directory (created from listings 12.3 and 12.4).
cargo provides debugging output that is omitted here. When running, the sixty program prints the PID, and then prints some numbers to the console every second. Because it was the PID for this invocation, 23221 appears as output in the table.
In console 2, execute the kill command, specifying -SIGSTOP.
If you are unfamiliar with the shell command kill, its role is to send signals. It’s named after its most common role, terminating programs with either SIGKILL or SIGTERM. The numeric argument (23221) must match the PID provided in step 2.
Console 1 returns to the command prompt as there is no longer anything running in the foreground.
Resume the program by sending SIGCONT to the PID provided in step 2.
The program resumes counting. It terminates when it hits 60, unless interrupted by Ctrl-C (SIGINT).
SIGSTOP and SIGCONT are interesting special cases. Let’s continue by investigating more typical signal behavior.
What are the other signals and what are their default handlers? To find the answer, we can ask the kill command to provide that information:
$ kill -l ①
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGEMT 8) SIGFPE 9) SIGKILL 10) SIGBUS
11) SIGSEGV 12) SIGSYS 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGURG 17) SIGSTOP 18) SIGTSTP 19) SIGCONT 20) SIGCHLD
21) SIGTTIN 22) SIGTTOU 23) SIGIO 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGPWR 30) SIGUSR1
31) SIGUSR2 32) SIGRTMAX
That’s a lot, Linux! To make matters worse, few signals have standardized behavior. Thankfully, most applications don’t need to worry about setting handlers for many of these signals (if any). Table 12.1 shows a much tighter list of signals. These are more likely to be encountered in day-to-day programming.
Table 12.2 List of common signals, their default actions, and shortcuts for sending them from the command line
Note SIGKILL and SIGSTOP have special status: these cannot be handled or blocked by the application. Programs can avoid the others.
The default actions for signals are fairly limited. By default, receiving a signal tends to end badly for applications. For example, if external resources such as database connections are left open, they might not be cleaned up properly when the application ends.
The most common use case for signal handlers is to allow an application to shut down cleanly. Some common tasks that might be necessary when an application shuts down include
To stop the current workload and shut down, a signal handler is required. To set up a signal handler, we need to create a function with the signature f(i32) -> (). That is, the function needs to accept an i32 integer as its sole argument and returns no value.
This poses some software engineering issues. The signal handler isn’t able to access any information from the application except which signal was sent. Therefore, because it doesn’t know what state anything is in, it doesn’t know what needs shutting down beforehand.
There are some additional restrictions in addition to the architectural one. Signal handlers are constrained in time and scope. These must also act quickly within a subset of functionality available to general code for these reasons:
Signal handlers can block other signals of the same type from being handled.
Moving fast reduces the likelihood of operating alongside another signal handler of a different type.
Signal handlers have reduced scope in what they’re permitted to do. For example, they must avoid executing any code that might itself generate signals.
To wriggle out of this constrained environment, the ordinary approach is to use a Boolean flag as a global variable that is regularly checked during a program’s execution. If the flag is set, then you can call a function to shutdown the application cleanly within the context of the application. For this pattern to work, there are two requirements:
The signal handler’s sole responsibility is to mutate the flag.
The application must regularly check the flag to detect whether the flag has been modified.
To avoid race conditions caused by multiple signal handlers running at the same time, signal handlers typically do little. A common pattern is to set a flag via a global variable.
Rust facilitates global variables (variables accessible anywhere within the program) by declaring a variable with the static keyword in global scope. Suppose we want to create a global value SHUT_DOWN that we can set to true when a signal handler believes it’s time to urgently shut down. We can use this declaration:
static mut SHUT_DOWN: bool = false;
Note static mut is read as mutable static, irrespective of how grammatically contorted that is.
Global variables present an issue for Rust programmers. Accessing these (even just for reading) is unsafe. This means that the code can become quite cluttered if it’s wrapped in unsafe blocks. This ugliness is a signal to wary programmers—avoid global state whenever possible.
Listing 12.6 presents a example of a static mut variable that reads from line 12 and writes to lines 7–9. The call to rand::random() on line 8 produces Boolean values. Output is a series of dots. About 50% of the time, you’ll receive output that looks like what’s shown in the following console session:1
$ git clone https:/ /github.com/rust-in-action/code rust-in-action $ cd rust-in-action/ch12/ch2-toy-global $ cargo run -q .
The following listing provides the metadata for listing 12.6. You can access its source code in ch12/ch12-toy-global/Cargo.toml.
Listing 12.5 Crate metadata for listing 12.6
[package] name = "ch12-toy-global" version = "0.1.0" authors = ["Tim McNamara <author@rustinaction.com>"] edition = "2018" [dependencies] rand = "0.6"
The following listing presents our toy example. Its source code is in ch12/ch12-toy-global/src/main.rs.
Listing 12.6 Accessing global variables (mutable statics) in Rust
1 use rand;
2
3 static mut SHUT_DOWN: bool = false;
4
5 fn main() {
6 loop {
7 unsafe { ①
8 SHUT_DOWN = rand::random(); ②
9 }
10 print!(".");
11
12 if unsafe { SHUT_DOWN } {
13 break
14 };
15 }
16 println!()
17 }
① Reading from and writing to a static mut variable requires an unsafe block.
② rand::random() is a shortcut that calls rand::thread_rng().gen() to produce a random value. The required type is inferred from the type of SHUT_DOWN.
Given that signal handlers must be quick and simple, we’ll do the minimal amount of possible work. In the next example, we’ll set a variable to indicate that the program needs to shut down. This technique is demonstrated by listing 12.8, which is structured into these three functions:
register_signal_handlers()—Communicates to the OS via libc, the signal handler for each signal. This function makes use of a function pointer, which treats a function as data. Function pointers are explained in section 11.7.1.
handle_signals()—Handles incoming signals. This function is agnostic as to which signal is sent, although we’ll only deal with SIGTERM.
main()—Initializes the program and iterates through a main loop.
When run, the resulting executable produces a trace of where it is. The following console session shows the trace:
$ git clone https:/ /github.com/rust-in-action/code rust-in-action
$ cd rust-in-action/ch12/ch12-basic-handler
$ cargo run -q
1
SIGUSR1
2
SIGUSR1
3
SIGTERM
4
* ①
① I hope that you will forgive the cheap ASCII art explosion.
Note If the signal handler is not correctly registered, Terminated may appear in the output. Make sure that you add a call to register_signal_handler() early within main(). Listing 12.8 does this on line 38.
The following listing shows the package and dependency for listing 12.8. You can view the source for this listing in ch12/ch12-basic-handler/Cargo.toml.
Listing 12.7 Crate setup for listing 12.10
[package] name = "ch12-handler" version = "0.1.0" authors = ["Tim McNamara <author@rustinaction.com>"] edition = "2018" [dependencies] libc = "0.2"
When executed, the following listing uses a signal handler to modify a global variable. The source for this listing is in ch12/ch12-basic-handler/src/main.rs.
Listing 12.8 Creating a signal handler that modifies a global variable
1 #![cfg(not(windows))] ① 2 3 use std::time::{Duration}; 4 use std::thread::{sleep}; 5 use libc::{SIGTERM, SIGUSR1}; 6 7 static mut SHUT_DOWN: bool = false; 8 9 fn main() { 10 register_signal_handlers(); ② 11 12 let delay = Duration::from_secs(1); 13 14 for i in 1_usize.. { 15 println!("{}", i); 16 unsafe { ③ 17 if SHUT_DOWN { 18 println!("*"); 19 return; 20 } 21 } 22 23 sleep(delay); 24 25 let signal = if i > 2 { 26 SIGTERM 27 } else { 28 SIGUSR1 29 }; 30 31 unsafe { ④ 32 libc::raise(signal); 33 } 34 } 35 unreachable!(); 36 } 37 38 fn register_signal_handlers() { 39 unsafe { ④ 40 libc::signal(SIGTERM, handle_sigterm as usize); 41 libc::signal(SIGUSR1, handle_sigusr1 as usize); 42 } 43 } 44 45 #[allow(dead_code)] ⑤ 46 fn handle_sigterm(_signal: i32) { 47 register_signal_handlers(); ⑥ 48 49 println!("SIGTERM"); 50 51 unsafe { ⑦ 52 SHUT_DOWN = true; 53 } 54 } 55 56 #[allow(dead_code)] ⑤ 57 fn handle_sigusr1(_signal: i32) { 58 register_signal_handlers(); ⑥ 59 60 println!("SIGUSR1"); 61 }
① Indicates that this code won’t run on Windows
② Must occur as soon as possible; otherwise signals will be incorrectly handled
③ Accessing a mutable static is unsafe.
④ Calling libc functions is unsafe; their effects are outside of Rust’s control.
⑤ Without this attribute, rustc warns that these functions are never called.
⑥ Reregisters signals as soon as possible to minimize signal changes affecting the signal handler itself
⑦ Modifying a mutable static is unsafe.
In the preceding listing, there is something special about the calls to libc::signal() on lines 40 and 41. libc::signal takes a signal name (which is actually an integer) and an untyped function pointer (known in C parlance as a void function pointer) as arguments and associates the signal with the function. Rust’s fn keyword creates function pointers. handle_sigterm() and handle_sigusr1() both have the type fn(i32) -> (). We need to cast these as usize values to erase any type information. Function pointers are explained in more detail in section 12.7.1.
Signals can be used as a limited form of messaging. Within your business rules, you can create definitions for SIGUSR1 and SIGUSR2. These are unallocated by design. In listing 12.8, we used SIGUSR1 to do a small task. It simply prints the string SIGUSR1. A more realistic use of custom signals is to notify a peer application that some data is ready for further processing.
Listing 12.8 includes some syntax that might be confusing. For example, on line 40 handle_sigterm as usize appears to cast a function as an integer.
What is happening here? The address where the function is stored is being converted to an integer. In Rust, the fn keyword creates a function pointer.
Readers who have worked through chapter 5 will understand that functions are just data. That is to say, functions are sequences of bytes that make sense to the CPU. A function pointer is a pointer to the start of that sequence. Refer back to chapter 5, especially section 5.7, for a refresher.
A pointer is a data type that acts as a stand-in for its referent. Within an application’s source code, pointers contain both the address of the value referred to as well as its type. The type information is something that’s stripped away in the compiled binary. The internal representation for pointers is an integer of usize. That makes pointers very economical to pass around. In C, making use of function pointers can feel like arcane magic. In Rust, they hide in plain sight.
Every fn declaration is actually declaring a function pointer. That means that listing 12.9 is legal code and should print something similar to the following line:
$ rustc ch12/fn-ptr-demo-1.rs && ./fn-ptr-demo-1 noop as usize: 0x5620bb4af530
Note In the output, 0x5620bb4af530 is the memory address (in hexadecimal notation) of the start of the noop() function. This number will be different on your machine.
The following listing, available at ch12/noop.rs, shows how to cast a function to usize. This demonstrates how usize can be used as a function pointer.
Listing 12.9 Casting a function to usize
fn noop() {}
fn main() {
let fn_ptr = noop as usize;
println!("noop as usize: 0x{:x}", fn_ptr);
}
But what is the type of the function pointer created from fn noop()? To describe function pointers, Rust reuses its function signature syntax. In the case of fn noop(), the type is *const fn() -> (). This type is read as “a const pointer to a function that takes no arguments and returns unit.” A const pointer is immutable. A unit is Rust’s stand-in value for “nothingness.”
Listing 12.10 casts a function pointer to usize and then back again. Its output, shown in the following snippet, should show two lines that are nearly identical:
$ rustc ch12/fn-ptr-demo-2.rs && ./fn-ptr-demo-2 noop as usize: 0x55ab3fdb05c0 noop as *const T: 0x55ab3fdb05c0
Note These two numbers will be different on your machine, but the two numbers will match each other.
Listing 12.10 Casting a function to usize
fn noop() {}
fn main() {
let fn_ptr = noop as usize;
let typed_fn_ptr = noop as *const fn() -> ();
println!("noop as usize: 0x{:x}", fn_ptr);
println!("noop as *const T: {:p}", typed_fn_ptr); ①
}
① Note the use of the pointer format modifier, {:p}.
As noted in table 12.2, most signals terminate the running program by default. This can be somewhat disheartening for the running program attempting to get its work done. (Sometimes the application knows best!) For those cases, many signals can be ignored.
SIGSTOP and SIGKILL aside, the constant SIG_IGN can be provided to libc:: signal() instead of a function pointer. An example of its usage is provided by the ignore project. Listing 12.11 shows its Cargo.toml file, and listing 12.12 shows src/main.rs. These are both available from the ch12/ch12-ignore project directory. When executed, the project prints the following line to the console:
$ cd ch12/ch12-ignore $ cargo run -q ok
The ignore project demonstrates how to ignore selected signals. On line 6 of listing 12.12, libc::SIG_IGN (short for signal ignore) is provided as the signal handler to libc::signal(). The default behavior is reset on line 13. libc::signal() is called again, this time with SIG_DFL (short for signal default) as the signal handler.
Listing 12.11 Project metadata for ignore project
[package] name = "ignore" version = "0.1.0" authors = ["Tim McNamara <author@rustinaction.com>"] edition = "2018" [dependencies] libc = "0.2"
Listing 12.12 Ignoring signals with libc::SIG_IGN
1 use libc::{signal,raise};
2 use libc::{SIG_DFL, SIG_IGN, SIGTERM};
3
4 fn main() {
5 unsafe { ①
6 signal(SIGTERM, SIG_IGN); ②
7 raise(SIGTERM); ③
8 }
9
10 println!("ok");
11
12 unsafe {
13 signal(SIGTERM, SIG_DFL); ④
14 raise(SIGTERM); ⑤
15 }
16
17 println!("not ok"); ⑥
18 }
① Requires an unsafe block because Rust does not control what happens beyond the function boundaries
③ libc::raise() allows code to make a signal; in this case, to itself.
④ Resets SIGTERM to its default
⑥ This code is never reached, and therefore, this string is never printed.
What if our program is deep in the middle of a call stack and can’t afford to unwind? When receiving a signal, the program might want to execute some cleanup code before terminating (or being forcefully terminated). This is sometimes referred to as nonlocal control transfer. UNIX-based operating systems provide some tools to enable you to make use of that machinery via two system calls—setjmp and longjmp:
Why bother with such programming gymnastics? Sometimes using low-level techniques like these is the only way out of a tight spot. These approach the “Dark Arts” of systems programming. To quote the manpage:
“setjmp() and longjmp() are useful for dealing with errors and interrupts encountered in a low-level subroutine of a program.”
—Linux Documentation Project: setjmp(3)
These two tools circumvent normal control flow and allow programs to teleport themselves through the code. Occasionally an error occurs deep within a call stack. If our program takes too long to respond to the error, the OS may simply abort the program, and the program’s data may be left in an inconsistent state. To avoid this, you can use longjmp to shift control directly to the error-handling code.
To understand the significance of this, consider what happens in an ordinary program’s call stack during several calls to a recursive function as produced by the code in listing 12.13. Each call to dive() adds another place that control eventually returns to. See the left-hand side of table 12.3. The longjmp system call, used by listing 12.17, bypasses several layers of the call stack. Its effect on the call stack is visible on the right-hand side of table 12.3.
Table 12.3 Comparing the intended output from listing 12.13 and listing 12.17
On the left side of table 12.3, the call stack grows one step as functions are called, then shrinks by one as each function returns. On the right side, the code jumps directly from the third call to the top to the call stack.
The following listing depicts how the call stack operates by printing its progress as the program executes. The code for this listing is in ch10/ch10-callstack/src/main.rs.
Listing 12.13 Illustrating how the call stack operates
1 fn print_depth(depth:usize) {
2 for _ in 0..depth {
3 print!("#");
4 }
5 println!("");
6 }
7
8 fn dive(depth: usize, max_depth: usize) {
9 print_depth(depth);
10 if depth >= max_depth {
11 return;
12
13 } else {
14 dive(depth+1, max_depth);
15 }
16 print_depth(depth);
17 }
18
19 fn main() {
20 dive(0, 5);
21 }
There’s a lot of work to do to make this happen. The Rust language itself doesn’t have the tools to enable this control-flow trickery. It needs to access some provided by its compiler’s toolchain. Compilers provide special functions known as intrinsics to application programs. Using an intrinsic function with Rust takes some ceremony to set up, but that operates as a standard function once the set-up is in place.
The sjlj project demonstrates contorting the normal control flow of a function. With the help of some assistance from the OS and the compiler, it’s actually possible to create a situation where a function can move to anywhere in the program. Listing 12.17 uses that functionality to bypass several layers of the call stack, creating the output from the right side of table 12.3. Figure 12.5 shows the control flow for the sjlj project.
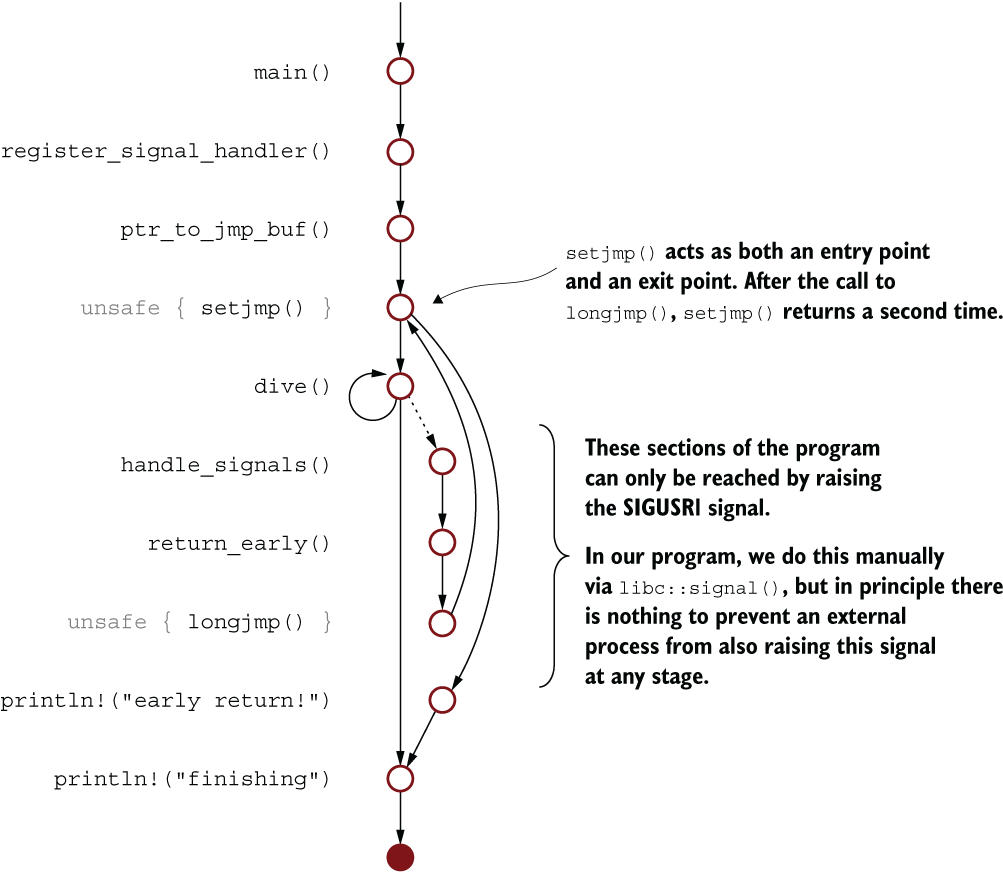
Figure 12.5 Control flow of the sjlj project. The program’s control flow can be intercepted via a signal and then resumed from the point of setjmp().
Listing 12.17 uses two intrinsics, setjmp() and longjmp(). To enable these in our programs, the crate must be annotated with the attribute provided. The following listing provides this documentation.
Listing 12.14 Crate-level attribute required in main.rs
#![feature(link_llvm_intrinsics)]
This raises two immediate questions. We’ll answer the following shortly:
Additionally, we need to tell Rust about the functions that are being provided by LLVM. Rust won’t know anything about them, apart from their type signatures, which means that any use of these must occur within an unsafe block. The following listing shows how to inform Rust about the LLVM functions. The source for this listing is in ch12/ch12-sjlj/src/main.rs.
Listing 12.15 Declaring the LLVM intrinsic functions within listing 12.17
extern "C" {
#[link_name = "llvm.eh.sjlj.setjmp"] ①
pub fn setjmp(_: *mut i8) -> i32; ②
#[link_name = "llvm.eh.sjlj.longjmp"] ①
pub fn longjmp(_: *mut i8);
}
① Provides specific instructions to the linker about where it should look to find the function definitions
② As we’re not using the argument’s name, uses an underscore (_) to make that explicit
This small section of code contains a fair amount of complexity. For example
extern "C" means “This block of code should obey C’s conventions rather than Rust’s.”
The link_name attribute tells the linker where to find the two functions that we’re declaring.
The eh in llvm.eh.sjlj.setjmp stands for exception handling, and the sjlj stands for setjmp/longjmp.
*mut i8 is a pointer to a signed byte. For those with C programming experience, you might recognize this as the pointer to the beginning of a string (e.g., a *char type).
What is an intrinsic function?
Intrinsic functions, generally referred to as intrinsics, are functions made available via the compiler rather than as part of the language. Whereas Rust is largely target-agnostic, the compiler has access to the target environment. This access can facilitate extra functionality. For example, a compiler understands the characteristics of the CPU that the to-be-compiled program will run on. The compiler can make that CPU’s instructions available to the program via intrinsics. Some examples of intrinsic functions include
Atomic operations—Many CPUs provide specialist instructions to optimize certain workloads. For example, the CPU might guarantee that updating an integer is an atomic operation. Atomic here is meant in the sense of being indivisible. This can be extremely important when dealing with concurrent code.
Exception handling—The facilities provided by CPUs for managing exceptions differ. These facilities can be used by programming language designers to create custom control flow. The setjmp and longjmp intrinsics, introduced later in this chapter, fall into this camp.
From the point of view of Rust programmers, LLVM can be considered as a subcomponent of rustc, the Rust compiler. LLVM is an external tool that’s bundled with rustc. Rust programmers can draw from the tools it provides. One set of tools that LLVM provides is intrinsic functions.
LLVM is itself a compiler. Its role is illustrated in figure 12.6.
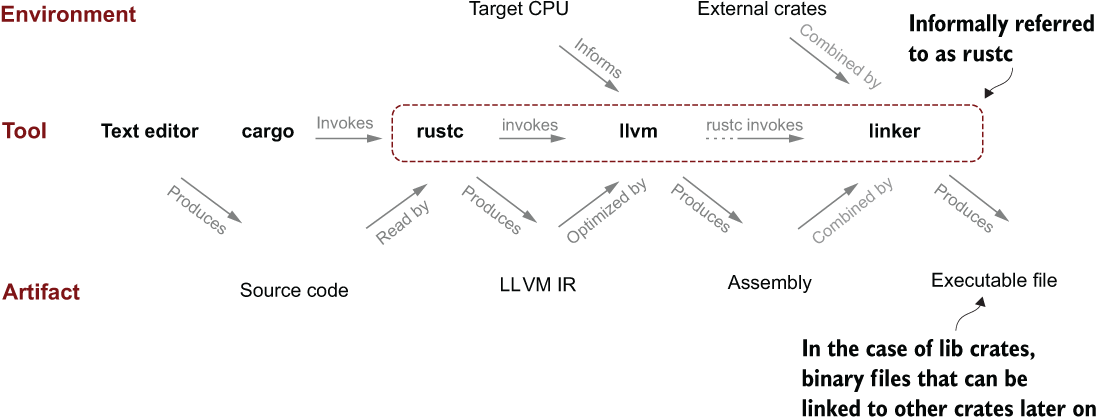
Figure 12.6 Some of the major steps required to generate an executable from Rust source code. LLVM is an essential part of the process but not one that is user-facing.
LLVM translates code produced by rustc, which produces LLVM IR (intermediate language) into machine-readable assembly language. To make matters more complicated, another tool, called a linker, is required to stitch multiple crates together. On Windows, Rust uses link.exe, a program provided by Microsoft as its linker. On other operating systems, the GNU linker ld is used.
Understanding more detail about LLVM implies learning more about rustc and compilation in general. Like many things, getting closer to the truth requires exploring through a fractal-like domain. Learning every subsystem seems to require learning about another set of subsystems. Explaining more here would be a fascinating, but ultimately distracting diversion.
One of the more arcane parts of Rust’s syntax is how to cast between pointer types. You’ll encounter this as you make your way through listing 12.17. But problems can arise because of the type signatures of setjmp() and longjmp(). In this code snippet, extracted from listing 12.17, you can see that both functions take a *mut i8 pointer as an argument:
extern "C" {
#[link_name = "llvm.eh.sjlj.setjmp"]
pub fn setjmp(_: *mut i8) -> i32;
#[link_name = "llvm.eh.sjlj.longjmp"]
pub fn longjmp(_: *mut i8);
}
Requiring a *mut i8 as an input argument is a problem because our Rust code only has a reference to a jump buffer (e.g., &jmp_buf).2 The next few paragraphs work through the process of resolving this conflict. The jmp_buf type is defined like this:
const JMP_BUF_WIDTH: usize =
mem::size_of::<usize>() * 8; ①
type jmp_buf = [i8; JMP_BUF_WIDTH];
① This constant is 64 bits wide (8 × 8 bytes) in 64-bit machines and 32 bits wide (8 × 4 bytes) on 32-bit machines.
The jmp_buf type is a type alias for an array of i8 that is as wide as 8 usize integers. The role of jmp_buf is to store the state of the program, such that the CPU’s registers can be repopulated when needed. There is only one jmp_buf value within listing 12.17, a global mutable static called RETURN_HERE, defined on line 14. The following example shows how jmp_buf is initialized:
static mut RETURN_HERE: jmp_buf = [0; JMP_BUF_WIDTH];
How do we treat RETURN_HERE as a pointer? Within the Rust code, we refer to RETURN_ HERE as a reference (&RETURN_HERE). LLVM expects those bytes to be presented as a *mut i8. To perform the conversion, we apply four steps, which are all packed into a single line:
unsafe { &RETURN_HERE as *const i8 as *mut i8 }
Let’s explain what those four steps are:
Start with &RETURN_HERE, a read-only reference to a global static variable of type [i8; 8] on 64-bit machines or [i8; 4] on 32-bit machines.
Convert that reference to a *const i8. Casting between pointer types is considered safe Rust, but deferencing that pointer requires an unsafe block.
Convert the *const i8 to a *mut i8. This declares the memory as mutable (read/write).
Wrap the conversion in an unsafe block because it deals with accessing a global variable.
Why not use something like &mut RETURN_HERE as *mut i8? The Rust compiler becomes quite concerned about giving LLVM access to its data. The approach provided here, starting with a read-only reference, puts Rust at ease.
We’re now in a position where possible points of confusion about listing 12.17 should be minor. The following snippet again shows the behavior we’re attempting to replicate:
$ git clone https:/ /github.com/rust-in-action/code rust-in-action $ cd rust-in-action/ch12/ch12-sjlj $ cargo run -q # # early return! finishing!
One final note: to compile correctly, the sjlj project requires that rustc is on the nightly channel. If you encounter the error “#![feature] may not be used on the stable release channel,” use rustup install nightly to install it. You can then make use of the nightly compiler by adding the +nightly argument to cargo. The following console output demonstrates encountering that error and recovering from it:
$ cargo run -q error[E0554]: #![feature] may not be used on the stable release channel --> src/main.rs:1:1 | 1 | #![feature(link_llvm_intrinsics)] | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ error: aborting due to previous error For more information about this error, try `rustc --explain E0554`. $ rustup toolchain install nightly ... $ cargo +nightly run -q # ## ### early return! finishing!
The following listing employs LLVM’s compiler to access the operating system’s longjmp facilities. longjmp allows programs to escape their stack frame and jump anywhere within their address space. The code for listing 12.6 is in ch12/ch12-sjlj/Cargo.toml and listing 12.17 is in ch12/ch12-sjlj/src/main.rs.
Listing 12.16 Project metadata for sjlj
[package] name = "sjlj" version = "0.1.0" authors = ["Tim McNamara <code@timmcnamara.co.nz>"] edition = "2018" [dependencies] libc = "0.2"
Listing 12.17 Using LLVM’s internal compiler machinery (intrinsics)
1 #![feature(link_llvm_intrinsics)] 2 #![allow(non_camel_case_types)] 3 #![cfg(not(windows))] ① 4 5 use libc::{ 6 SIGALRM, SIGHUP, SIGQUIT, SIGTERM, SIGUSR1, 7 }; 8 use std::mem; 9 10 const JMP_BUF_WIDTH: usize = 11 mem::size_of::<usize>() * 8; 12 type jmp_buf = [i8; JMP_BUF_WIDTH]; 13 14 static mut SHUT_DOWN: bool = false; ② 15 static mut RETURN_HERE: jmp_buf = [0; JMP_BUF_WIDTH]; 16 const MOCK_SIGNAL_AT: usize = 3; ③ 17 18 extern "C" { 19 #[link_name = "llvm.eh.sjlj.setjmp"] 20 pub fn setjmp(_: *mut i8) -> i32; 21 22 #[link_name = "llvm.eh.sjlj.longjmp"] 23 pub fn longjmp(_: *mut i8); 24 } 25 26 #[inline] ④ 27 fn ptr_to_jmp_buf() -> *mut i8 { 28 unsafe { &RETURN_HERE as *const i8 as *mut i8 } 29 } 30 31 #[inline] ④ 32 fn return_early() { 33 let franken_pointer = ptr_to_jmp_buf(); 34 unsafe { longjmp(franken_pointer) }; ⑤ 35 } 36 37 fn register_signal_handler() { 38 unsafe { 39 libc::signal(SIGUSR1, handle_signals as usize); ⑥ 40 } 41 } 42 43 #[allow(dead_code)] 44 fn handle_signals(sig: i32) { 45 register_signal_handler(); 46 47 let should_shut_down = match sig { 48 SIGHUP => false, 49 SIGALRM => false, 50 SIGTERM => true, 51 SIGQUIT => true, 52 SIGUSR1 => true, 53 _ => false, 54 }; 55 56 unsafe { 57 SHUT_DOWN = should_shut_down; 58 } 59 60 return_early(); 61 } 62 63 fn print_depth(depth: usize) { 64 for _ in 0..depth { 65 print!("#"); 66 } 67 println!(); 68 } 69 70 fn dive(depth: usize, max_depth: usize) { 71 unsafe { 72 if SHUT_DOWN { 73 println!("!"); 74 return; 75 } 76 } 77 print_depth(depth); 78 79 if depth >= max_depth { 80 return; 81 } else if depth == MOCK_SIGNAL_AT { 82 unsafe { 83 libc::raise(SIGUSR1); 84 } 85 } else { 86 dive(depth + 1, max_depth); 87 } 88 print_depth(depth); 89 } 90 91 fn main() { 92 const JUMP_SET: i32 = 0; 93 94 register_signal_handler(); 95 96 let return_point = ptr_to_jmp_buf(); 97 let rc = unsafe { setjmp(return_point) }; 98 if rc == JUMP_SET { 99 dive(0, 10); 100 } else { 101 println!("early return!"); 102 } 103 104 println!("finishing!") 105 }
① Only compile on supported platforms.
② When true, the program exits.
③ Allows a recursion depth of 3
④ An #[inline] attribute marks the function as being available for inlining, which is a compiler optimization technique for eliminating the cost of function calls.
⑤ This is unsafe because Rust cannot guarantee what LLVM does with the memory at RETURN_HERE.
⑥ Asks libc to associate handle_signals with the SIGUSR1 signal
Signals are a “UNIX-ism.” On other platforms, messages from the OS are handled differently. On MS Windows, for example, command-line applications need to provide a handler function to the kernel via SetConsoleCtrlHandler. That handler function is then invoked when a signal is sent to the application.
Regardless of the specific mechanism, the high-level approach demonstrated in this chapter should be fairly portable. Here is the pattern:
Your CPU generates interrupts that require the OS to respond.
Operating systems often delegate responsibility for handling interrupts via some sort of callback system.
At the start of the chapter, we discussed the distinction between signals, interrupts, and exceptions. There was little coverage of exceptions, directly. We have treated these as a special class of interrupts. Interrupts themselves have been modeled as signals.
To wrap up this chapter (and the book), we explored some of the features available in rustc and LLVM. The bulk of this chapter utilized these features to work with signals. Within Linux, signals are the main mechanism that the OS uses to communicate with applications. On the Rust side, we have spent lots of time interacting with libc and unsafe blocks, unpacking function pointers, and tweaking global variables.
Hardware devices, such as the computer’s network card, notify applications about data that is ready to be processed by sending an interrupt to the CPU.
Function pointers are pointers that point to executable code rather than to data. These are denoted in Rust by the fn keyword.
Unix operating systems manage job control with two signals: SIGSTOP and SIGCONT.
Signal handlers do the least amount of work possible to mitigate the risk of triggering race conditions caused when multiple signal handlers operate concurrently. A typical pattern is to set a flag with a global variable. That flag is periodically checked within the program’s main loop.
To create a global variable in Rust, create a “mutable static.” Accessing mutable statics requires an unsafe block.
The OS, signals, and the compiler can be utilized to implement exception handling in programming languages via the setjmp and longjmp syscalls.
Without the unsafe keyword, Rust programs would not be able to interface effectively with the OS and other third-party components.
1.Output assumes a fair random number generator, which Rust uses by default. This assumption holds as long as you trust your operating system’s random number generator.
2.jmp_buf is the conventional name for this buffer, which might be useful for any readers who want to dive deeper themselves.