This chapter explains one of the concepts that trip up most newcomers to Rust—its borrow checker. The borrow checker checks that all access to data is legal, which allows Rust to prevent safety issues. Learning how this works will, at the very least, speed up your development time by helping you avoid run-ins with the compiler. More significantly though, learning to work with the borrow checker allows you to build larger software systems with confidence. It underpins the term fearless concurrency.
This chapter will explain how this system operates and help you learn how to comply with it when an error is discovered. It uses the somewhat lofty example of simulating a satellite constellation to explain the trade-offs relating to different ways to provide shared access to data. The details of borrow checking are thoroughly explored within the chapter. However, a few points might be useful for readers wanting to quickly get the gist. Borrow checking relies on three interrelated concepts—lifetimes, ownership, and borrowing:
Ownership is a stretched metaphor. There is no relationship to property rights. Within Rust, ownership relates to cleaning values when these are no longer needed. For example, when a function returns, the memory holding its local variables needs to be freed. Owners cannot prevent other parts of the program from accessing their values or report data theft to some overarching Rust authority.
A value’s lifetime is the period when accessing that value is valid behavior. A function’s local variables live until the function returns, while global variables might live for the life of the program.
To borrow a value means to access it. This terminology is somewhat confusing as there is no obligation to return the value to its owner. Its meaning is used to emphasize that while values can have a single owner, it’s possible for many parts of the program to share access to those values.
Our strategy for this chapter is to use an example that compiles. Then we’ll make a minor change that triggers an error that appears to emerge without any adjustment to the program’s flow. Working through the fixes to those issues should make the concepts more complete.
The learning example for the chapter is a CubeSat constellation. If you’ve never encountered that phrase before, here are some definitions:
CubeSat—A miniature artificial satellite, as compared to a conventional satellite, that has increasingly expanded the accessibility of space research.
Ground station—An intermediary between the operators and the satellites themselves. It listens on a radio, checking the status of every satellite in the constellation and transmitting messages to and fro. When introduced in our code, it acts as the gateway between the user and the satellites.
Figure 4.1 shows several CubeSats orbiting our ground station.
In figure 4.1, we have three CubeSats. To model this, we’ll create a variable for each. This model can happily implement integers for the moment. We don’t need to model the ground station explicitly because we’re not yet sending messages around the constellations. We’ll omit that model for now. These are the variables:
let sat_a = 0; let sat_b = 1; let sat_c = 2;
To check on the status of each of our satellites, we’ll use a stub function and an enum to represent potential status messages:
#[derive(Debug)]
enum StatusMessage {
Ok, ①
}
fn check_status(sat_id: u64) -> StatusMessage {
StatusMessage::Ok ①
}
① For now, all of our CubeSats function perfectly all the time
The check_status() function would be extremely complicated in a production system. For our purposes, though, returning the same value every time is perfectly sufficient. Pulling these two snippets into a whole program that “checks” our satellites twice, we end up with something like the following listing. You’ll find this code in the file ch4/ch4-check-sats-1.rs.
Listing 4.1 Checking the status of our integer-based CubeSats
1 #![allow(unused_variables)]
2
3 #[derive(Debug)]
4 enum StatusMessage {
5 Ok,
6 }
7
8 fn check_status(sat_id: u64) -> StatusMessage {
9 StatusMessage::Ok
10 }
11
12 fn main () {
13 let sat_a = 0; ①
14 let sat_b = 1; ①
15 let sat_c = 2; ①
16
17 let a_status = check_status(sat_a);
18 let b_status = check_status(sat_b);
19 let c_status = check_status(sat_c);
20 println!("a: {:?}, b: {:?}, c: {:?}", a_status, b_status, c_status);
21
22 // "waiting" ...
23 let a_status = check_status(sat_a);
24 let b_status = check_status(sat_b);
25 let c_status = check_status(sat_c);
26 println!("a: {:?}, b: {:?}, c: {:?}", a_status, b_status, c_status);
27 }
① Each satellite variable is represented by an integer.
Running the code in listing 4.1 should be fairly uneventful. The code compiles, albeit begrudgingly. We encounter the following output from our program:
a: Ok, b: Ok, c: Ok a: Ok, b: Ok, c: Ok
Let’s move closer to idiomatic Rust by introducing type safety. Instead of integers, let’s create a type to model our satellites. A real implementation of a CubeSat type would probably include lots of information about its position, its RF frequency band, and more. In the following listing, we stick with only recording an identifier.
Listing 4.2 Modeling a CubeSat as its own type
#[derive(Debug)]
struct CubeSat {
id: u64,
}
Now that we have a struct definition, let’s inject it into our code. The next listing will not compile (yet). Understanding the details of why it won’t is the goal of much of this chapter. The source for this listing is in ch4/ch4-check-sats-2.rs.
Listing 4.3 Checking the status of our integer-based CubeSats
1 #[derive(Debug)] ① 2 struct CubeSat { 3 id: u64, 4 } 5 6 #[derive(Debug)] 7 enum StatusMessage { 8 Ok, 9 } 10 11 fn check_status( 12 sat_id: CubeSat 13 ) -> StatusMessage { ② 14 StatusMessage::Ok 15 } 16 17 fn main() { 18 let sat_a = CubeSat { id: 0 }; ③ 19 let sat_b = CubeSat { id: 1 }; ③ 20 let sat_c = CubeSat { id: 2 }; ③ 21 22 let a_status = check_status(sat_a); 23 let b_status = check_status(sat_b); 24 let c_status = check_status(sat_c); 25 println!("a: {:?}, b: {:?}, c: {:?}", a_status, b_status, c_status); 26 27 // "waiting" ... 28 let a_status = check_status(sat_a); 29 let b_status = check_status(sat_b); 30 let c_status = check_status(sat_c); 31 println!("a: {:?}, b: {:?}, c: {:?}", a_status, b_status, c_status); 32 }
① Modification 1 adds the definition.
② Modification 2 uses the new type within check_status().
③ Modification 3 creates three new instances.
When you attempt to compile the code for listing 4.3, you will receive a message similar to the following (which has been edited for brevity):
error[E0382]: use of moved value: `sat_a`
--> code/ch4-check-sats-2.rs:26:31
|
20 | let a_status = check_status(sat_a);
| ----- value moved here
...
26 | let a_status = check_status(sat_a);
| ^^^^^ value used here after move
|
= note: move occurs because `sat_a` has type `CubeSat`,
= which does not implement the `Copy` trait
... ①
error: aborting due to 3 previous errors
To trained eyes, the compiler’s message is helpful. It tells us exactly where the problem is and provides us with a recommendation on how to fix it. To less experienced eyes, it’s significantly less useful. We are using a “moved” value and are fully advised to implement the Copy trait on CubeSat. Huh? It turns out that although it is written in English, the term move means something very specific within Rust. Nothing physically moves.
Movement within Rust code refers to movement of ownership, rather than the movement of data. Ownership is a term used within the Rust community to refer to the compile-time process that checks that every use of a value is valid and that every value is destroyed cleanly.
Every value in Rust is owned. In both listings 4.1 and 4.3, sat_a, sat_b, and sat_c own the data that these refer to. When calls to check_status() are made, ownership of the data moves from the variables in the scope of main() to the variable sat_id within the check_status() function. The significant difference is that listing 4.3 places that integer within a CubeSat struct.1 This type change alters the semantics of how the program behaves.
The next listing provides a stripped-down version of the main() function from listing 4.3. It is centered on sat_a and attempts to show how ownership moves from main() into check_status().
Listing 4.4 Extract of listing 4.3, focusing on main()
fn main() {
let sat_a = CubeSat { id: 0 }; ①
// ... ②
let a_status = check_status(sat_a); ③
// ... ②
// "waiting" ...
let a_status = check_status(sat_a); ④
// ... ②
}
① Ownership originates here at the creation of the CubeSat object.
③ Ownership of the object moves to check_status() but is not returned to main().
④ At line 27, sat_a is no longer the owner of the object, making access invalid.
Figure 4.2 provides a visual walk-through of the interrelated processes of control flow, ownership, and lifetimes. During the call to check_status(sat_a), ownership moves to the check_status() function. When check_status() returns a StatusMessage, it drops the sat_a value. The lifetime of sat_a ends here. Yet, sat_a remains in the local scope of main() after the first call to check_status(). Attempting to access that variable will incur the wrath of the borrow checker.
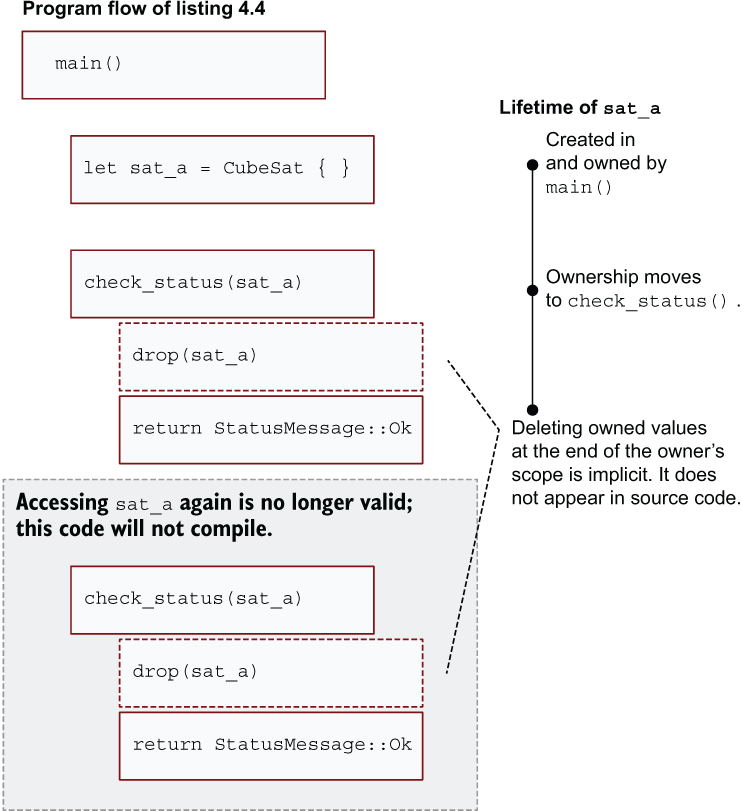
Figure 4.2 Visual explanation of Rust’s ownership movement
The distinction between a value’s lifetime and its scope—which is what many programmers are trained to rely on—can make things difficult to disentangle. Avoiding and overcoming this type of issue makes up the bulk of this chapter. Figure 4.2 helps to shed some light on this.
Before carrying on, it might be wise to explain why listing 4.1 compiled at all. Indeed, the only change that we made in listing 4.3 was to wrap our satellite variables in a custom type. As it happens, primitive types in Rust have special behavior. These implement the Copy trait.
Types implementing Copy are duplicated at times that would otherwise be illegal. This provides some day-to-day convenience at the expense of adding a trap for newcomers. As you grow out from toy programs using integers, your code suddenly breaks.
Formally, primitive types are said to possess copy semantics, whereas all other types have move semantics. Unfortunately, for learners of Rust, that special case looks like the default case because beginners typically encounter primitive types first. Listings 4.5 and 4.6 illustrate the difference between these two concepts. The first compiles and runs; the other does not. The only difference is that these listings use different types. The following listing shows not only the primitive types but also the types that implement Copy.
Listing 4.5 The copy semantics of Rust’s primitive types
1 fn use_value(_val: i32) { ①
2 }
3
4 fn main() {
5 let a = 123 ;
6 use_value(a);
7
8 println!("{}", a); ②
9
10 }
① use_value() takes ownership of the _val argument. The use_value() function is generic as it’s used in the next example.
② It’s perfectly legal to access a after use_value() has returned.
The following listing focuses on those types that do not implement the Copy trait. When used as an argument to a function that takes ownership, values cannot be accessed again from the outer scope.
Listing 4.6 The move semantics of types not implementing Copy
1 fn use_value(_val: Demo) { ①
2 }
3
4 struct Demo {
5 a: i32,
6 }
7
8 fn main() {
9 let demo = Demo { a: 123 };
10 use_value(demo);
11
12 println!("{}", demo.a); ②
13 }
① use_value() takes ownership of _val.
② It’s illegal to access demo.a, even after use_value() has returned.
The figures used in this chapter use a bespoke notation to illustrate the three interrelated concepts of scope, lifetimes, and ownership. Figure 4.3 illustrates this notation.
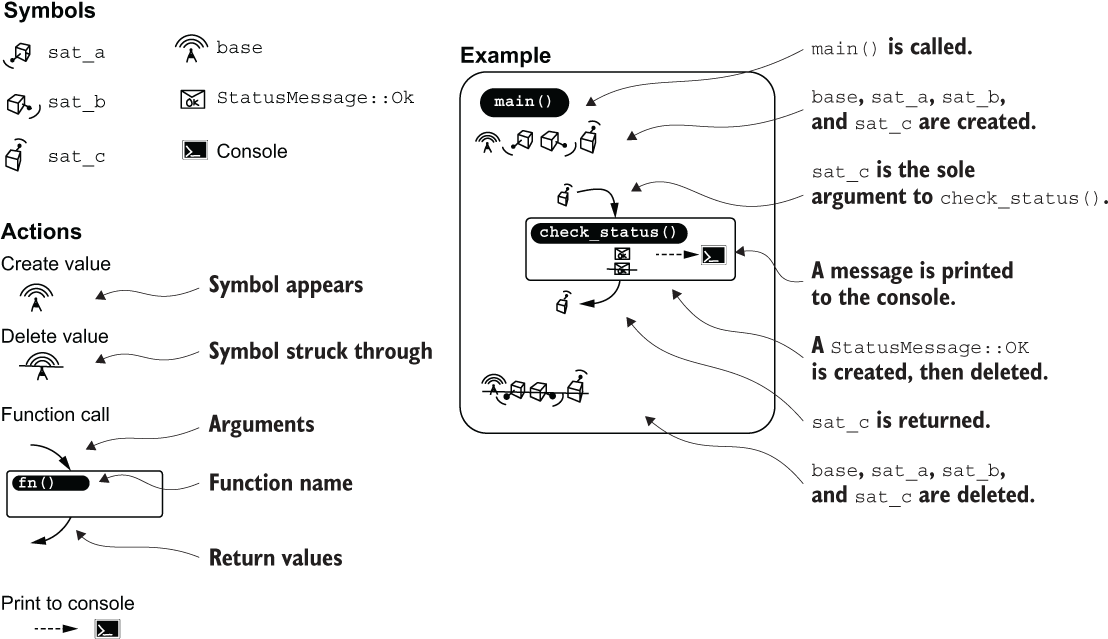
Figure 4.3 How to interpret the figures in this chapter
In the world of Rust, the notion of ownership is rather limited. An owner cleans up when its values’ lifetimes end.
When values go out of scope or their lifetimes end for some other reason, their destructors are called. A destructor is a function that removes traces of the value from the program by deleting references and freeing memory. You won’t find a call to any destructors in most Rust code. The compiler injects that code itself as part of the process of tracking every value’s lifetime.
To provide a custom destructor for a type, we implement Drop. This typically is needed in cases where we have used unsafe blocks to allocate memory. Drop has one method, drop(&mut self), that you can use to conduct any necessary wind-up activities.
An implication of this system is that values cannot outlive their owner. This kind of situation can make data structures built with references, such as trees and graphs, feel slightly bureaucratic. If the root node of a tree is the owner of the whole tree, it can’t be removed without taking ownership into account.
Finally, unlike the Lockean notion of personal property, ownership does not imply control or sovereignty. In fact, the “owners” of values do not have special access to their owned data. Nor do these have the ability to restrict others from trespassing. Owners don’t get a say on other sections of code borrowing their values.
There are two ways to shift ownership from one variable to another within a Rust program. The first is by assignment.2 The second is by passing data through a function barrier, either as an argument or a return value. Revisiting our original code from listing 4.3, we can see that sat_a starts its life with ownership over a CubeSat object:
fn main() {
let sat_a = CubeSat { id: 0 };
// ...
The CubeSat object is then passed into check_status() as an argument. This moves ownership to the local variable sat_id:
fn main() {
let sat_a = CubeSat { id: 0 };
// ...
let a_status = check_status(sat_a);
// ...
Another possibility is that sat_a relinquishes its ownership to another variable within main(). That would look something like this:
fn main() {
let sat_a = CubeSat { id: 0 };
// ...
let new_sat_a = sat_a;
// ...
Lastly, if there is a change in the check_status() function signature, it too could pass ownership of the CubeSat to a variable within the calling scope. Here is our original function:
fn check_status(sat_id: CubeSat) -> StatusMessage {
StatusMessage::Ok
}
And here is an adjusted function that achieves its message notification through a side effect:
fn check_status(sat_id: CubeSat) -> CubeSat {
println!("{:?}: {:?}", sat_id, ①
StatusMessage::Ok);
sat_id ②
}
① Uses the Debug formatting syntax as our types have been annotated with #[derive(Debug)]
② Returns a value by omitting the semicolon at the end of the last line
With the adjusted check_status() function used in conjunction with a new main(), it’s possible to send ownership of the CubeSat objects back to their original variables. The following listing shows the code. Its source is found in ch4/ch4-check-sats-3.rs.
Listing 4.7 Returning ownership back to the original scope
1 #![allow(unused_variables)]
2
3 #[derive(Debug)]
4 struct CubeSat {
5 id: u64,
6 }
7
8 #[derive(Debug)]
9 enum StatusMessage {
10 Ok,
11 }
12
13 fn check_status(sat_id: CubeSat) -> CubeSat {
14 println!("{:?}: {:?}", sat_id, StatusMessage::Ok);
15 sat_id
16 }
17
18 fn main () {
19 let sat_a = CubeSat { id: 0 };
20 let sat_b = CubeSat { id: 1 };
21 let sat_c = CubeSat { id: 2 };
22
23 let sat_a = check_status(sat_a); ①
24 let sat_b = check_status(sat_b);
25 let sat_c = check_status(sat_c);
26
27 // "waiting" ...
28
29 let sat_a = check_status(sat_a);
30 let sat_b = check_status(sat_b);
31 let sat_c = check_status(sat_c);
32 }
① Now that the return value of check_status() is the original sat_a, the new let binding is reset.
The output from the new main() function in listing 4.7 now looks like this:
CubeSat { id: 0 }: Ok
CubeSat { id: 1 }: Ok
CubeSat { id: 2 }: Ok
CubeSat { id: 0 }: Ok
CubeSat { id: 1 }: Ok
CubeSat { id: 2 }: Ok
Figure 4.4 shows a visual overview of the ownership movements within listing 4.7.
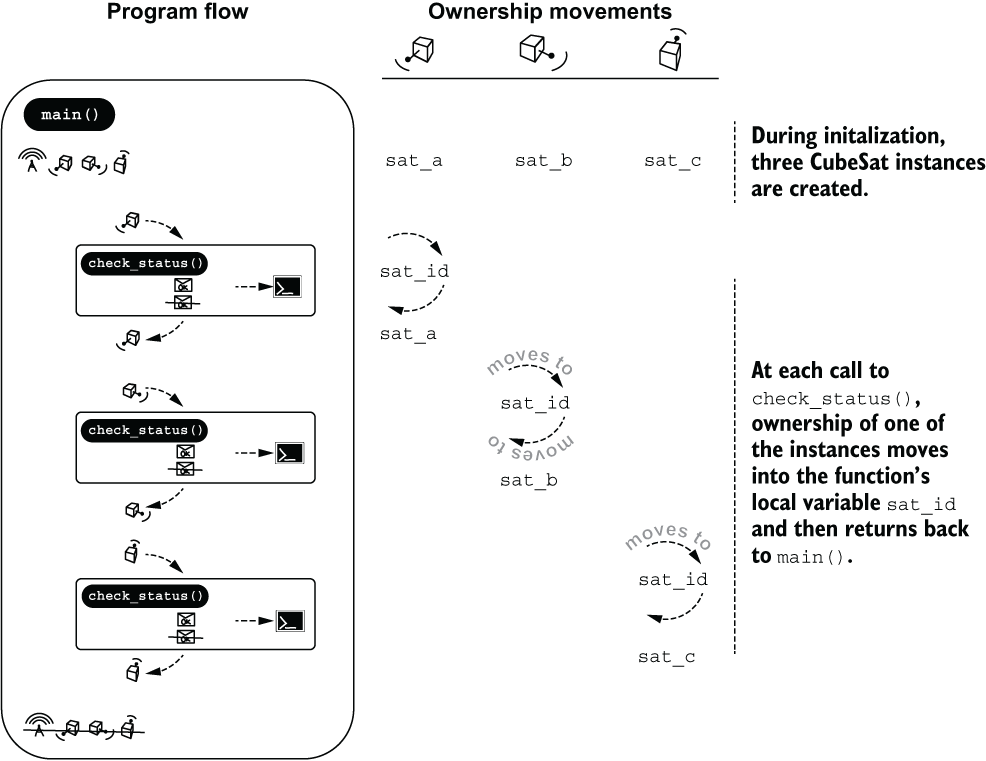
Figure 4.4 The ownership changes within listing 4.7
Rust’s ownership system is excellent. It provides a route to memory safety without needing a garbage collector. There is a “but,” however.
The ownership system can trip you up if you don’t understand what’s happening. This is particularly the case when you bring the programming style from your past experience to a new paradigm. Four general strategies can help with ownership issues:
To examine each of these strategies, let’s extend the capabilities of our satellite network. Let’s give the ground station and our satellites the ability to send and receive messages. Figure 4.5 shows what we want to achieve: create a message at Step 1, then transfer it at Step 2. After Step 2, no ownership issues should arise.
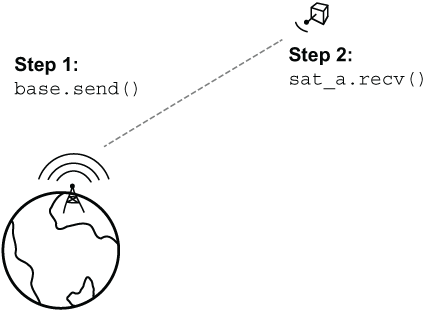
Figure 4.5 Goal: Enable messages to be sent while avoiding ownership issues
Ignoring the details of implementing the methods, we want to avoid code that looks like the following. Moving ownership of sat_a to a local variable in base.send() ends up hurting us. That value will no longer be accessible for the rest of main():
base.send(sat_a, "hello!"); ①
sat_a.recv();
① Moves ownership of sat_a to a local variable in base.send()
To get to a “toy” implementation, we need a few more types to help us out somewhat. In listing 4.8, we add a new field, mailbox, to CubeSat. CubeSat.mailbox is a Mailbox struct that contains a vector of Messages within its messages field. We alias String to Message, giving us the functionality of the String type without needing to implement it ourselves.
Listing 4.8 Adding a Mailbox type to our system
1 #[derive(Debug)]
2 struct CubeSat {
3 id: u64,
4 mailbox: Mailbox,
5 }
6
7 #[derive(Debug)]
8 enum StatusMessage {
9 Ok,
10 }
11
12 #[derive(Debug)]
13 struct Mailbox {
14 messages: Vec<Message>,
15 }
16
17 type Message = String;
Creating a CubeSat instance has become slightly more complicated. To create one now, we also need to create its associated Mailbox and the mailbox’s associated Vec<Message>. The following listing shows this addition.
Listing 4.9 Creating a new CubeSat with Mailbox
CubeSat { id: 100, mailbox: Mailbox { messages: vec![] } }
Another type to add is one that represents the ground station itself. We will use a bare struct for the moment, as shown in the following listing. That allows us to add methods to it and gives us the option of adding a mailbox as a field later on as well.
Listing 4.10 Defining a struct to represent our ground station
struct GroundStation;
Creating an instance of GroundStation should be trivial for you now. The following listing shows this implementation.
Listing 4.11 Creating a new ground station
GroundStation {};
Now that we have our new types in place, let’s put these to work. You’ll see how in the next section.
The most common change you will make to your code is to reduce the level of access you require. Instead of requesting ownership, you can use a “borrow” in your function definitions. For read-only access, use & T. For read-write access, use &mut T.
Ownership might be needed in advanced cases, such as when functions want to adjust the lifetime of their arguments. Table 4.1 compares the two different approaches.
Table 4.1 Comparing ownership and mutable references
Sending messages will eventually be wrapped up in a method, but with essence functions, implementing that modifies the internal mailbox of the CubeSat. For simplicity’s sake, we’ll return () and hope for the best in case of transmission difficulties caused by solar winds.
The following snippet shows the flow that we want to end up with. The ground station can send a message to sat_a with its send() method, and sat_a then receives the message with its recv() method:
base.send(sat_a, "hello!".to_string());
let msg = sat_a.recv();
println!("sat_a received: {:?}", msg); // -> Option("hello!")
The next listing shows the implementations of these methods. To achieve that flow, add the implementations to GroundStation and CubeSat types.
Listing 4.12 Adding the GroundStation.send() and CubeSat.recv() methods
1 impl GroundStation {
2 fn send(
3 &self, ①
4 to: &mut CubeSat, ①
5 msg: Message, ①
6 ) {
7 to.mailbox.messages.push(msg); ②
8 }
9 }
10
11 impl CubeSat {
12 fn recv(&mut self) -> Option<Message> {
13 self.mailbox.messages.pop()
14 }
15 }
① &self indicates that GroundStation.send() only requires a read-only reference to self. The recipient takes a mutable borrow (&mut) of the CubeSat instance, and msg takes full ownership of its Message instance.
② Ownership of the Message instance transfers from msg to messages.push() as a local variable.
Notice that both GroundStation.send() and CubeSat.recv() require mutable access to a CubeSat instance because both methods modify the underlying CubeSat.messages vector. We move ownership of the message that we’re sending into the messages.push(). This provides us with some quality assurance later, notifying us if we access a message after it’s already sent. Figure 4.6 illustrates how we can avoid ownership issues.
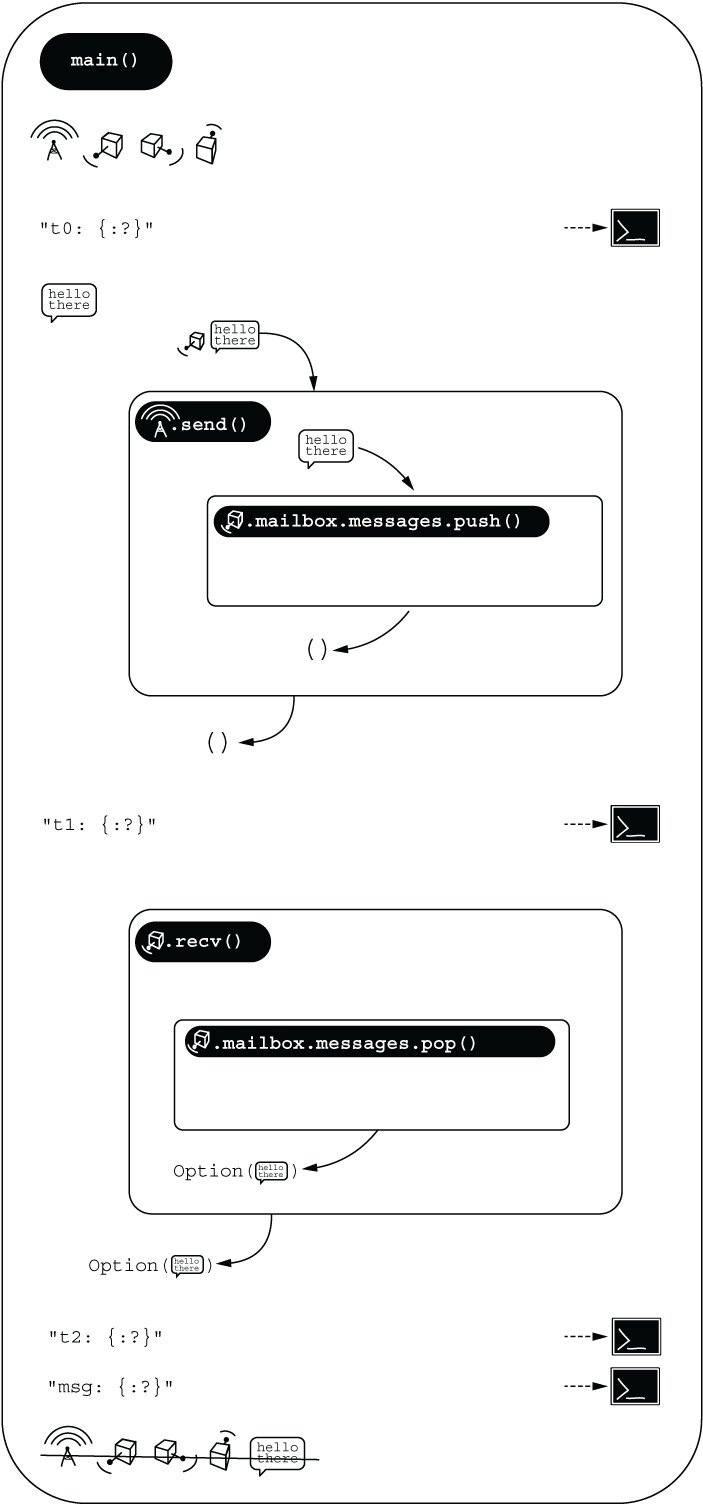
Figure 4.6 Game plan: Use references to avoid ownership issues.
Listing 4.13 (ch4/ch4-sat-mailbox.rs) brings together all of the code snippets in this section thus far and prints the following output. The messages starting with t0 through t2 are added to assist your understanding of how data is flowing through the program:
t0: CubeSat { id: 0, mailbox: Mailbox { messages: [] } }
t1: CubeSat { id: 0, mailbox: Mailbox { messages: ["hello there!"] } }
t2: CubeSat { id: 0, mailbox: Mailbox { messages: [] } }
msg: Some("hello there!")
Listing 4.13 Avoiding ownership issues with references
1 #[derive(Debug)]
2 struct CubeSat {
3 id: u64,
4 mailbox: Mailbox,
5 }
6
7 #[derive(Debug)]
8 struct Mailbox {
9 messages: Vec<Message>,
10 }
11
12 type Message = String;
13
14 struct GroundStation;
15
16 impl GroundStation {
17 fn send(&self, to: &mut CubeSat, msg: Message) {
18 to.mailbox.messages.push(msg);
19 }
20 }
21
22 impl CubeSat {
23 fn recv(&mut self) -> Option<Message> {
24 self.mailbox.messages.pop()
25 }
26 }
27
28 fn main() {
29 let base = GroundStation {};
30 let mut sat_a = CubeSat {
31 id: 0,
32 mailbox: Mailbox {
33 messages: vec![],
34 },
35 };
36
37 println!("t0: {:?}", sat_a);
38
39 base.send(&mut sat_a,
40 Message::from("hello there!")); ①
41
42 println!("t1: {:?}", sat_a);
43
44 let msg = sat_a.recv();
45 println!("t2: {:?}", sat_a);
46
47 println!("msg: {:?}", msg);
48 }
① We don’t have a completely ergonomic way to create Message instances yet. Instead, we’ll take advantage of the String.from() method that converts &str to String (aka Message).
If we have a large, long-standing object such as a global variable, it can be somewhat unwieldy to keep this around for every component of your program that needs it. Rather than using an approach involving long-standing objects, consider making objects that are more discrete and ephemeral. Ownership issues can sometimes be resolved by considering the design of the overall program.
In our CubeSat case, we don’t need to handle much complexity at all. Each of our four variables—base, sat_a, sat_b, and sat_c—live for the duration of main(). In a production system, there can be hundreds of different components and many thousands of interactions to manage. To increase the manageability of this kind of scenario, let’s break things apart. Figure 4.7 presents the game plan for this section.
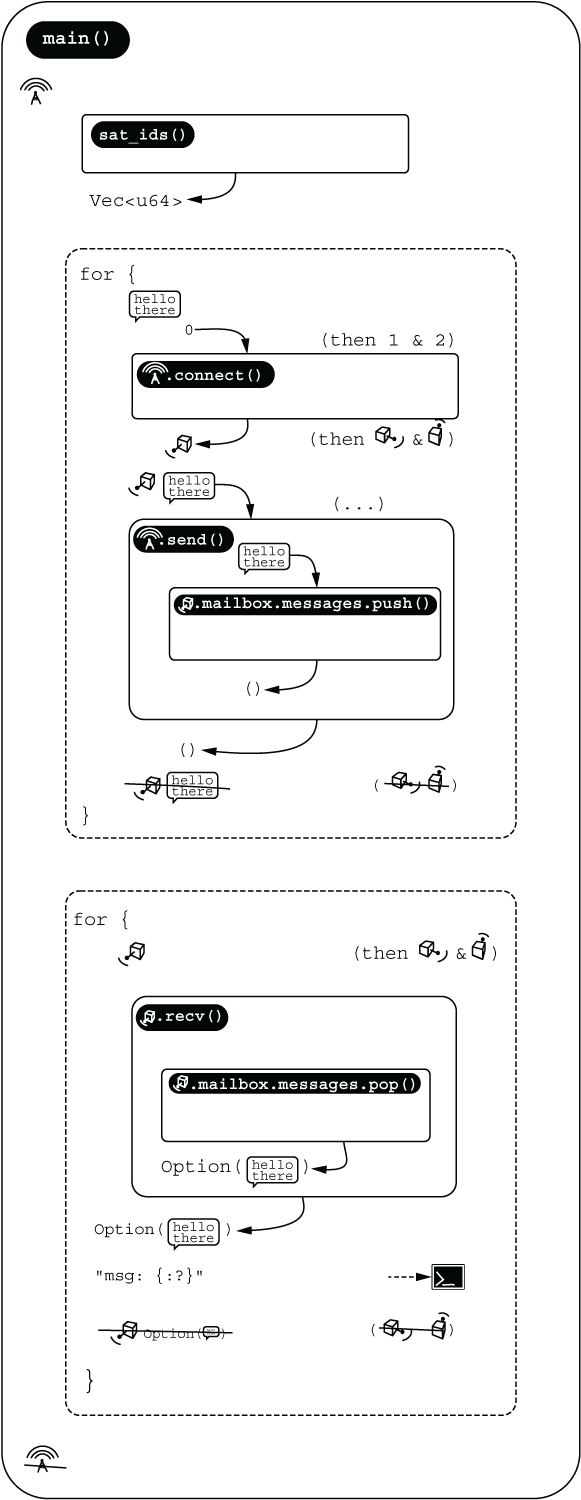
Figure 4.7 Game plan: Short-lived variables to avoid ownership issues
To implement this kind of strategy, we will create a function that returns CubeSat identifiers. That function is assumed to be a black box that’s responsible for communicating with some store of identifiers, such as a database. When we need to communicate with a satellite, we’ll create a new object, as the following code snippet shows. In this way, there is no requirement for us to maintain live objects for the whole of the program’s duration. It also has the dual benefit that we can afford to transfer ownership of our short-lived variables to other functions:
fn fetch_sat_ids() -> Vec<u64> { ①
vec![1,2,3]
}
① Returns a vector of CubeSat IDs
We’ll also create a method for GroundStation. This method allows us to create a CubeSat instance on demand once:
impl GroundStation {
fn connect(&self, sat_id: u64) -> CubeSat {
CubeSat { id: sat_id, mailbox: Mailbox { messages: vec![] } }
}
}
Now we are a bit closer to our intended outcome. Our main function looks like the following code snippet. In effect, we’ve implemented the first half of figure 4.7.
fn main() {
let base = GroundStation();
let sat_ids = fetch_sat_ids();
for sat_id in sat_ids {
let mut sat = base.connect(sat_id);
base.send(&mut sat, Message::from("hello"));
}
}
But there’s a problem. Our CubeSat instances die at the end of the for loop’s scope, along with any messages that base sends to them. To carry on with our design decision of short-lived variables, the messages need to live somewhere outside of the CubeSat instances. In a real system, these would live on the RAM of a device in zero gravity. In our not-really-a-simulator, let’s put these in a buffer object that lives for the duration of our program.
Our message store will be a Vec<Message> (our Mailbox type defined in one of the first code examples of this chapter). We’ll change the Message struct to add a sender and recipient field, as the following code shows. That way our now-proxy CubeSat instances can match their IDs to receive messages:
#[derive(Debug)]
struct Mailbox {
messages: Vec<Message>,
}
#[derive(Debug)]
struct Message {
to: u64,
content: String,
}
We also need to reimplement sending and receiving messages. Up until now, CubeSat objects have had access to their own mailbox object. The central GroundStation also had the ability to sneak into those mailboxes to send messages. That needs to change now because only one mutable borrow can exist per object.
In the modifications in listing 4.14, the Mailbox instance is given the ability to modify its own message vector. When any of the satellites transmit messages, these take a mutable borrow to the mailbox. These then defer the delivery to the mailbox object. According to this API, although our satellites are able to call Mailbox methods, these are not allowed to touch any internal Mailbox data themselves.
Listing 4.14 Modifications to Mailbox
1 impl GroundStation {
2 fn send(
3 &self,
4 mailbox: &mut Mailbox,
5 to: &CubeSat,
6 msg: Message,
7 ) { ①
8 mailbox.post(to, msg);
9 }
10 }
11
12 impl CubeSat {
13 fn recv(
14 &self,
15 mailbox: &mut Mailbox
16 ) -> Option<Message> { ②
17 mailbox.deliver(&self)
18 }
19 }
20
21 impl Mailbox {
22 fn post(&mut self, msg: Message) { ③
23 self.messages.push(msg);
24 }
25
26 fn deliver(
27 &mut self,
28 recipient: &CubeSat
29 ) -> Option<Message> { ④
30 for i in 0..self.messages.len() {
31 if self.messages[i].to == recipient.id {
32 let msg = self.messages.remove(i);
33 return Some(msg); ⑤
34 }
35 }
36
37 None ⑥
38 }
39 }
① Calls Mailbox.post() to send messages, yielding ownership of a Message
② Calls Mailbox.deliver() to receive messages, gaining ownership of a Message
③ Mailbox.post() requires mutable access to itself and ownership over a Message.
④ Mailbox.deliver() requires a shared reference to a CubeSat to pull out its id field.
⑤ When we find a message, returns early with the Message wrapped in Some per the Option type
⑥ When no messages are found, returns None
Note Astute readers of listing 4.14 will notice a strong anti-pattern. On line 32, the self.messages collection is modified while it is being iterated over. In this instance, this is legal because of the return on the next line. The compiler can prove that another iteration will not occur and allows the mutation to proceed.
With that groundwork in place, we’re now able to fully implement the strategy laid out in figure 4.7. Listing 4.15 (ch4/ch4-short-lived-strategy.rs) is the full implementation of the short-lived variables game plan. The output from a compiled version of that listing follows:
CubeSat { id: 1 }: Some(Message { to: 1, content: "hello" })
CubeSat { id: 2 }: Some(Message { to: 2, content: "hello" })
CubeSat { id: 3 }: Some(Message { to: 3, content: "hello" })
Listing 4.15 Implementing the short-lived variables strategy
1 #![allow(unused_variables)]
2
3 #[derive(Debug)]
4 struct CubeSat {
5 id: u64,
6 }
7
8 #[derive(Debug)]
9 struct Mailbox {
10 messages: Vec<Message>,
11 }
12
13 #[derive(Debug)]
14 struct Message {
15 to: u64,
16 content: String,
17 }
18
19 struct GroundStation {}
20
21 impl Mailbox {
22 fn post(&mut self, msg: Message) {
23 self.messages.push(msg);
24 }
25
26 fn deliver(&mut self, recipient: &CubeSat) -> Option<Message> {
27 for i in 0..self.messages.len() {
28 if self.messages[i].to == recipient.id {
29 let msg = self.messages.remove(i);
30 return Some(msg);
31 }
32 }
33
34 None
35 }
36 }
37
38 impl GroundStation {
39 fn connect(&self, sat_id: u64) -> CubeSat {
40 CubeSat {
41 id: sat_id,
42 }
43 }
44
45 fn send(&self, mailbox: &mut Mailbox, msg: Message) {
46 mailbox.post(msg);
47 }
48 }
49
50 impl CubeSat {
51 fn recv(&self, mailbox: &mut Mailbox) -> Option<Message> {
52 mailbox.deliver(&self)
53 }
54 }
55 fn fetch_sat_ids() -> Vec<u64> {
56 vec![1,2,3]
57 }
58
59
60 fn main() {
61 let mut mail = Mailbox { messages: vec![] };
62
63 let base = GroundStation {};
64
65 let sat_ids = fetch_sat_ids();
66
67 for sat_id in sat_ids {
68 let sat = base.connect(sat_id);
69 let msg = Message { to: sat_id, content: String::from("hello") };
70 base.send(&mut mail, msg);
71 }
72
73 let sat_ids = fetch_sat_ids();
74
75 for sat_id in sat_ids {
76 let sat = base.connect(sat_id);
77
78 let msg = sat.recv(&mut mail);
79 println!("{:?}: {:?}", sat, msg);
80 }
81 }
Having a single owner for every object can mean significant up-front planning and/or refactoring of your software. As we saw in the previous section, it can be quite a lot of work to wriggle out of an early design decision.
One alternative to refactoring is to simply copy values. Doing this often is typically frowned upon, however, but it can be useful in a pinch. Primitive types like integers are a good example of that. Primitive types are cheap for a CPU to duplicate—so cheap, in fact, that Rust always copies these if it would otherwise worry about ownership being moved.
Types can opt into two modes of duplication: cloning and copying. Each mode is provided by a trait. Cloning is defined by std::clone::Clone, and the copying mode is defined by std::marker::Copy. Copy acts implicitly. Whenever ownership would otherwise be moved to an inner scope, the value is duplicated instead. (The bits of object a are replicated to create object b.) Clone acts explicitly. Types that implement Clone have a .clone() method that is permitted to do whatever it needs to do to create a new value. Table 4.2 outlines the major differences between the two modes.
Table 4.2 Distinguishing cloning from copying
So why do Rust programmers not always use Copy? There are three main reasons:
The Copy trait implies that there will only be negligible performance impact. This is true for numbers but not true for types that are arbitrarily large, such as String.
Because Copy creates exact copies, it cannot treat references correctly. Naïvely copying a reference to T would (attempt to) create a second owner of T. That would cause problems later on because there would be multiple attempts to delete T as each reference is deleted.
Some types overload the Clone trait. This is done to provide something similar to, yet different from, creating duplicates. For example, std::rc::Rc<T> uses Clone to create additional references when .clone() is called.
Note Throughout your time with Rust, you will normally see the std::clone ::Clone and std::marker::Copy traits referred to simply as Clone and Copy. These are included in every crate’s scope via the standard prelude.
Let’s go back to our original example (listing 4.3), which caused the original movement issue. Here it is replicated for convenience, with sat_b and sat_c removed for brevity:
#[derive(Debug)]
struct CubeSat {
id: u64,
}
#[derive(Debug)]
enum StatusMessage {
Ok,
}
fn check_status(sat_id: CubeSat) -> StatusMessage {
StatusMessage::Ok
}
fn main() {
let sat_a = CubeSat { id: 0 };
let a_status = check_status(sat_a);
println!("a: {:?}", a_status);
let a_status = check_status(sat_a); ①
println!("a: {:?}", a_status);
}
① The second call to check_status(sat_a) is the location of error.
At this early stage, our program consisted of types that contain types, which themselves implement Copy. That’s good because it means implementing it ourselves is fairly straightforward, as the following listing shows.
Listing 4.16 Deriving Copy for types made up of types that implement Copy
#[derive(Copy,Clone,Debug)] ① struct CubeSat { id: u64, } #[derive(Copy,Clone,Debug)] ① enum StatusMessage { Ok, }
① #[derive(Copy,Clone,Debug)] tells the compiler to add an implementation of each of the traits.
The following listing shows how it’s possible to implement Copy manually. The impl blocks are impressively terse.
Listing 4.17 Implementing the Copy trait manually
impl Copy for CubeSat { }
impl Copy for StatusMessage { }
impl Clone for CubeSat { ①
fn clone(&self) -> Self {
CubeSat { id: self.id } ②
}
}
impl Clone for StatusMessage {
fn clone(&self) -> Self {
*self ③
}
}
① Implementing Copy requires an implementation of Clone.
② If desired, we can write out the creation of a new object ourselves...
③ ...but often we can simply dereference self.
Now that we know how to implement them, let’s put Clone and Copy to work. We’ve discussed that Copy is implicit. When ownership would otherwise move, such as during assignment and passing through function barriers, data is copied instead.
Clone requires an explicit call to .clone(). That’s a useful marker in non-trivial cases, such as in listing 4.18, because it warns the programmer that the process may be expensive. You’ll find the source for this listing in ch4/ch4-check-sats-clone-and-copy-traits.rs.
Listing 4.18 Using Clone and Copy
1 #[derive(Debug,Clone,Copy)] ① 2 struct CubeSat { 3 id: u64, 4 } 5 6 #[derive(Debug,Clone,Copy)] ① 7 enum StatusMessage { 8 Ok, 9 } 10 11 fn check_status(sat_id: CubeSat) -> StatusMessage { 12 StatusMessage::Ok 13 } 14 15 fn main () { 16 let sat_a = CubeSat { id: 0 }; 17 18 let a_status = check_status(sat_a.clone()); ② 19 println!("a: {:?}", a_status.clone()); ② 20 21 let a_status = check_status(sat_a); ③ 22 println!("a: {:?}", a_status); ③ 23 }
① Copy implies Clone, so we can use either trait later.
② Cloning each object is as easy as calling .clone().
So far in this chapter, we have discussed Rust’s ownership system and ways to navigate the constraints it imposes. A final strategy that is quite common is to use wrapper types, which allow more flexibility than what is available by default. These, however, incur costs at runtime to ensure that Rust’s safety guarantees are maintained. Another way to phrase this is that Rust allows programmers to opt in to garbage collection.3
To explain the wrapper type strategy, let’s introduce a wrapper type: std:rc::Rc. std:rc::Rc takes a type parameter T and is typically referred to as Rc<T>. Rc<T> reads as “R. C. of T” and stands for “a reference-counted value of type T.” Rc<T> provides shared ownership of T. Shared ownership prevents T from being removed from memory until every owner is removed.
As indicated by the name, reference counting is used to track valid references. As each reference is created, an internal counter increases by one. When a reference is dropped, the count decreases by one. When the count hits zero, T is also dropped.
Wrapping T involves a calling Rc::new(). The following listing, at ch4/ch4-rc-groundstation.rs, shows this approach.
Listing 4.19 Wrapping a user-defined type in Rc
1 use std::rc::Rc; ① 2 3 #[derive(Debug)] 4 struct GroundStation {} 5 6 fn main() { 7 let base = Rc::new(GroundStation {}); ② 8 9 println!("{:?}", base); ③ 10 }
① The use keyword brings modules from the standard library into local scope.
② Wrapping involves enclosing the GroundStation instance in a call to Rc::new().
Rc<T> implements Clone. Every call to base.clone() increments an internal counter. Every Drop decrements that counter. When the internal counter reaches zero, the original instance is freed.
Rc<T> does not allow mutation. To permit that, we need to wrap our wrapper. Rc<RefCell<T>> is a type that can be used to perform interior mutability, first introduced at the end of of chapter 3 in section 3.4.1. An object that has interior mutability presents an immutable façade while internal values are being modified.
In the following example, we can modify the variable base despite being marked as an immutable variable. It’s possible to visualize this by looking at the changes to the internal base.radio_freq:
base: RefCell { value: GroundStation { radio_freq: 87.65 } }
base_2: GroundStation { radio_freq: 75.31 }
base: RefCell { value: GroundStation { radio_freq: 75.31 } }
base: RefCell { value: "<borrowed>" } ①
base_3: GroundStation { radio_freq: 118.52000000000001 }
① value: "<borrowed>" indicates that base is mutably borrowed somewhere else and is no longer generally accessible.
The following listing, found at ch4/ch4-rc-refcell-groundstation.rs, uses Rc<RefCell<T>> to permit mutation within an object marked as immutable. Rc<RefCell<T>> incurs some additional runtime cost over Rc<T> while allowing shared read/write access to T.
Listing 4.20 Using Rc<RefCell<T>> to mutate an immutable object
1 use std::rc::Rc;
2 use std::cell::RefCell;
3
4 #[derive(Debug)]
5 struct GroundStation {
6 radio_freq: f64 // Mhz
7 }
8
9 fn main() {
10 let base: Rc<RefCell<GroundStation>> = Rc::new(RefCell::new(
11 GroundStation {
12 radio_freq: 87.65
13 }
14 ));
15
16 println!("base: {:?}", base);
17
18 { ①
19 let mut base_2 = base.borrow_mut();
20 base_2.radio_freq -= 12.34;
21 println!("base_2: {:?}", base_2);
22 }
23
24 println!("base: {:?}", base);
25
26 let mut base_3 = base.borrow_mut();
27 base_3.radio_freq += 43.21;
28
29 println!("base: {:?}", base);
30 println!("base_3: {:?}", base_3);
31 }
① Introduces a new scope where base can be mutably borrowed
There are two things to note from this example:
Adding more functionality (e.g., reference-counting semantics rather than move semantics) to types by wrapping these in other types typically reduces their run-time performance.
If implementing Clone would be prohibitively expensive, Rc<T> can be a handy alternative. This allows two places to “share” ownership.
Note Rc<T> is not thread-safe. In multithreaded code, it’s much better to replace Rc<T> with Arc<T> and Rc<RefCell<T>> with Arc<Mutex<T>>. Arc stands for atomic reference counter.
A value’s owner is responsible for cleaning up after that value when its lifetime ends.
A value’s lifetime is the period when accessing that value is valid behavior. Attempting to access a value after its lifetime has expired leads to code that won’t compile.
If you find that the borrow checker won’t allow your program to compile, several tactics are available to you. This often means that you will need to rethink the design of your program.
Use shorter-lived values rather than values that stick around for a long time.
Borrows can be read-only or read-write. Only one read-write borrow can exist at any one time.
Duplicating a value can be a pragmatic way to break an impasse with the borrow checker. To duplicate a value, implement Clone or Copy.
It’s possible to opt in to reference counting semantics through Rc<T>.
Rust supports a feature known as interior mutability, which enables types to present themselves as immutable even though their values can change over time.
1.Remember the phrase zero-cost abstractions ? One of the ways this manifests is by not adding extra data around values within structs.
2.Within the Rust community, the term variable binding is preferred because it is more technically correct.
3.Garbage collection (often abbreviated as GC) is a strategy for memory management used by many programming languages, including Python and JavaScript, and all languages built on the JVM (Java, Scala, Kotlin) or the CLR (C#, F#).